Supervisión del rendimiento de iftask y NPU en QvPC-DI
Opciones de descarga
-
ePub (183.5 KB)
Visualice en diferentes aplicaciones en iPhone, iPad, Android, Sony Reader o Windows Phone -
Mobi (Kindle) (143.3 KB)
Visualice en dispositivo Kindle o aplicación Kindle en múltiples dispositivos
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Introducción
Este documento describe cómo monitorear el rendimiento de iftask / NPU en QvPC-DI.
También proporciona más información sobre algunos conceptos clave de iftask.
Componentes Utilizados
La información de este documento se basa en QvPC-DI.
La información que contiene este documento se creó a partir de los dispositivos en un ambiente de laboratorio específico. Todos los dispositivos que se utilizan en este documento se pusieron en funcionamiento con una configuración verificada (predeterminada). Si tiene una red en vivo, asegúrese de entender el posible impacto de cualquier comando.
Arquitectura Iftask
iftask es un proceso en QvPC-DI. Habilita la funcionalidad del kit de desarrollo de plano de datos (DPDK) en la tarjeta virtual de función de servicio (SF) y la tarjeta virtual de función de control (CF) para los puertos de red DI y los puertos de servicio. DPDK es una forma más eficaz de gestionar la entrada/salida en entornos virtualizados.
Los controladores de dispositivos de los controladores de interfaz de red (NIC) de alto rendimiento ahora se trasladan al espacio de usuario, lo que evita los costosos switches de contexto (espacio de usuario/espacio de núcleo).
Los controladores se ejecutan en modo no interrumpible en el espacio de usuario y los subprocesos tienen acceso directo a las colas de hardware/búferes de timbre de estos controladores NIC.
La documentación sobre la arquitectura está disponible en:
Introducción a la Plataforma de Servicios Ultra (USP) de la Guía de Administración del Sistema de la Plataforma Ultra Gateway.
Disponibilidad para diferentes versiones.
En profundidad, si la arquitectura de tareas (para SF) se ve en este diagrama:
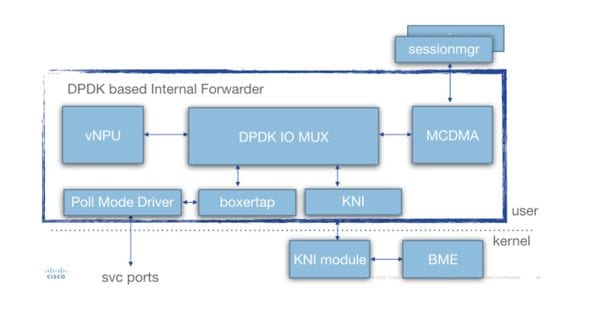
Hay varios componentes presentes:
Controlador de modo de sondeo (PMD): Esta es la función que está sondeando continuamente las colas de hardware desde las NIC (en el caso de SR-IOV) o las memorias intermedias de anillo SW (en el caso del tipo de interfaces virtio/vmxnet). Esta es la razón por la que la CPU asociada con estos PMD está continuamente vinculada al 100%.
Durante la implementación, los números de CPU asignados a iftask y a diversas funciones dentro de iftask se pueden asignar estáticamente a través del archivo param.cfg.
Boxertap: conexión/eliminación de metadatos de staros (encabezado MEH) a paquetes en función de la procedencia del paquete (por ejemplo: Di puerto/puerto de servicio) y a dónde debe enviarse (por ejemplo: vNPU local)
IOMUX: Tiene una biblioteca BIA con todos los destinos (sessmgr/ports/vNPU/..). Esta función básicamente enruta los paquetes en función de su BIA
vNPU: -clasificación/búsqueda de flujo. Esto es comparable a la NPU de los sistemas basados en hardware (ASR5000/ASR5500).
Los flujos en vNPU siguen siendo programados por NPUmgr (que obtiene su información de demuxmgr, sessmgr, etc.) en la memoria compartida a la que vNPU puede acceder.
-Además, se crea una API de modo que npumgr/sessmgr pueda consultar la vNPU para obtener estadísticas o configuración
MCDMA: los paquetes destinados a sessmgr se escriben en la interfaz MCDMA (a través de los diversos núcleos/subprocesos MCDMA disponibles). Estos paquetes se ponen a disposición de sessmgr a través de DMA. Esto proporciona un aumento real del rendimiento, ya que el núcleo está involucrado solo de una manera limitada. Esto se explica con más detalle en este artículo.
MCDMA también proporciona capacidades de procesamiento por lotes (para manejar muchos paquetes en una llamada del sistema).
KNI: interfaz para paquetes que necesitan ir hacia el kernel de Linux (DI control/ARP/icmp/routing/...)
Iftask Flujo De Paquetes
El siguiente diagrama explica el flujo de paquetes de un paquete del plano de control. Ejemplo: GTPv2 Crear solicitud de sesión
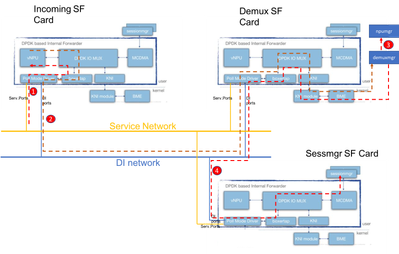
Paso 1: El paquete CSR GTPv2 entrará a través del puerto de servicio en cualquiera de los SF disponibles. Se colocará en las colas Rx de la NIC de la interfaz de servicio y será recogido por uno de los núcleos PMD del proceso iftask. Boxertap colocará el encabezado MEH y el paquete se reenviará a través de IOMux a la vNPU local para la búsqueda de flujo.
Dado que se trata de una nueva sesión, la vNPU no tiene ningún flujo específico programado para esto, y tendrá que rutear el paquete al demuxmgr en la tarjeta de demux.
Paso 2: vNPU cambia el encabezado MEH (con un nuevo BIA para el proceso de demux relevante). IOMUX sabe que tiene que enviar esto a través de la red DI hacia la tarjeta de demux. Si el proceso de tarea en la tarjeta Demux manejará el paquete entrante, e IOMux lo ruteará al módulo KNI (que es la interfaz hacia el núcleo). A través del kernal terminará finalmente en el proceso demuxmgr (egtpinmgr en este caso).
Paso 3: El Demuxmgr realizará sus tareas. Seleccione un sessmgr y programe npumgr con los flujos para los paquetes GTPv2 subsiguientes
Las vNPU de todas las tarjetas podrán acceder a la memoria compartida que npumgr utiliza para programar estos flujos.
Paso 4: El GTPv2 CSR ahora se reenvía al sessmgr seleccionado. Es MEH se cambia de nuevo, y se reenvía fuera de la tarjeta Demux, en la red DI hacia la tarjeta Sessmgr SF. El proceso IOMUX en esa tarjeta reenviará el paquete a través de la interfaz MCDMA hacia el sessmgr seleccionado. A partir de aquí, sessmgr gestionará todo el tráfico GTPv2 para esta sesión. Una vez que se negocian los TEID de GTPU, programará los flujos a través de NPUmgr de modo que los paquetes GTPU subsiguientes también puedan ir directamente de la tarjeta SF entrante a la tarjeta SF de sessmgr.
vCPU en iftask
Durante la implementación, se asigna estáticamente cierta cantidad de unidades de procesamiento central virtual (vCPU) al proceso iftask. Esto reduce la cantidad de núcleos para las aplicaciones de espacio de usuario (sessmgr, etc.), pero mejora en gran medida el rendimiento de E/S.
Esta asignación se realiza a través del parámetro siguiente en la plantilla param.cfg que se asocia a cada SF/CF durante la implementación:
- IFTASK_CORES (% de núcleos disponibles que se asignarán a iftask)
- (IFTASK_CRYPTO_CORES - (% de núcleos disponibles que se asignarán para el procesamiento criptográfico (en el caso de EPDG))
- (IFTASK_MCDMA_CORES - (para ajustar aún más el número de núcleos asignados a la funcionalidad MCDMA)
- En un SF, el proceso iftask distribuirá internamente sus núcleos asignados en:
- Controladores de modo de sondeo (PMD) vCPU (realizando actividad tx/rx/vnpu)
- vCPU de MCDMA, realizando la transferencia de paquetes de iftask a sessmgr y viceversa
- En un CF, no se requieren vCPU de MCDMA, ya que los SF no alojan procesos sessmgr.
El comando 'show cloud hardware iftask' proporciona más detalles sobre esto en su implementación de QVPC-DI:
[local]UGP# show cloud hardware iftask Card 1: Total number of cores on VM: 8 Number of cores for PMD only: 0 Number of cores for VNPU only: 0 Number of cores for PMD and VNPU: 2 <-- CF: 2 out of 8 cores are assigned to iftask PMD/VNPU Number of cores for MCDMA: 0 <-- CF: no cores allocated to MCDMA as there is no sessmgr process on CF Number of cores for Crypto: 0 Hugepage size: 2048 kB Total hugepages: 3670016 kB NPUSHM hugepages: 0 kB CPU flags: avx sse sse2 ssse3 sse4_1 sse4_2 Poll CPU's: 1 2 KNI reschedule interval: 5 us ... Card 3: Total number of cores on VM: 8 Number of cores for PMD only: 0 Number of cores for VNPU only: 0 Number of cores for PMD and VNPU: 2 <-- SF: 2 out of 8 core are assigned to iftask PMD/VNPU
Number of cores for MCDMA: 1 <-- SF: 1 out of 8 cores is assigned to iftak MCDMA
Number of cores for Crypto: 0
Hugepage size: 2048 kB
Total hugepages: 4718592 kB
NPUSHM hugepages: 0 kB
CPU flags: avx sse sse2 ssse3 sse4_1 sse4_2
Poll CPU's: 1 2 3
KNI reschedule interval: 5 us
El comando 'show cloud configuration' proporcionará más detalles sobre los parámetros utilizados:
[local]UGP# show cloud configuration Card 1: Config Disk Params: ------------------------- CARDSLOT=1 CPUID=0 CARDTYPE=0x40010100 DI_INTERFACE=BOND:TYPE:ixgbevf-1,TYPE:ixgbevf-2 DI_INTERFACE_VLANID=2111 VNFM_INTERFACE=MAC:fa:16:3e:23:aa:e9 VNFM_PROXY_ADDRS=172.16.180.3,172.16.180.5,172.16.180.6 MGMT_INTERFACE=MAC:fa:16:3e:87:23:9b VNFM_IPV4_ENABLE=true VNFM_IPV4_DHCP_ENABLE=true Local Params: ------------------------- CARDSLOT=1 CARDTYPE=0x40010100 CPUID=0 ... Card 3: Config Disk Params: ------------------------- CARDSLOT=3 CPUID=0 CARDTYPE=0x42030100 DI_INTERFACE=BOND:TYPE:ixgbevf-1,TYPE:ixgbevf-2 SERVICE1_INTERFACE=BOND:TYPE:ixgbevf-3,TYPE:ixgbevf-4 SERVICE2_INTERFACE=BOND:TYPE:ixgbevf-5,TYPE:ixgbevf-6 DI_INTERFACE_VLANID=2111 VNFM_INTERFACE=MAC:fa:16:3e:29:c6:b7 IFTASK_CORES=30 VNFM_IPV4_ENABLE=true VNFM_IPV4_DHCP_ENABLE=true Local Params: ------------------------- CARDSLOT=3 CARDTYPE=0x42010100 CPUID=0
Aspectos del diseño:
Hay una serie de factores que deben tenerse en cuenta al asignar vCPU a iftask.
-vCPU total disponible para el SF vs iftask vCPU: La configuración predeterminada especifica el 30% de vCPU asociada a iftask a través del parámetro IFTASK_CORES en el archivo param.cfg. Pero esto puede variar dependiendo de la aplicación (MME vs SPGW vs ePDG) —> Para ser consultado con ingeniería.
-iftask vCPU asignada a PMD vs iftask vCPU asignada a MCDMA. Para comprobar si está equilibrada, consulte la sección de rendimiento de iftask a continuación.
-iftask vCPU de MCDMA frente a vCPU restantes para todas las aplicaciones. Normalmente es bueno tener una distribución 1/x de iftask MCDMA vCPU contra el vCPU restante para las aplicaciones (sessmgr/aaamgr/...).
Ejemplo:
Núcleos totales 38 disponibles para SF:
-14 asignados a iftask (6 PMD, 8 MCDMA)
-dejando 24 asignados a otros procesos
Lo que significa que hay 1 vCPU de MCDMA por cada 3 vCPU de aplicación.
esto ayuda a garantizar la carga equivalente para cada vCPU de MCDMA.
Supervisar el rendimiento de iftask
El proceso iftask se puede supervisar de varias maneras.
Consolide la lista de comandos show:
show subscribers data-rate show npumgr dinet utilization pps show npumgr dinet utilization pps show cloud monitor di-network summary show cloud hardware iftask show cloud configuration show iftask stats summary show port utilization table show npu utilization table show npumgr utilization information show processes cpu
El comando #show cpu info verbose no proporcionará información sobre los núcleos iftask. Siempre aparecerán con una utilización del 100%.
En el siguiente ejemplo, el núcleo 1,2,3 está asociado con iftask, y se enumeran con una utilización del 100%, esto es de esperar.
Card 3, CPU 0:
Status : Standby, Kernel Running, Tasks Running
Load Average : 3.12, 3.12, 3.13 (3.95 max)
Total Memory : 16384M
Kernel Uptime : 4D 21H 56M
Last Reading:
CPU Usage All : 1.9% user, 0.3% sys, 0.0% io, 0.0% irq, 97.8% idle
Core 0 : 5.8% user, 0.2% sys, 0.0% io, 0.0% irq, 94.0% idle
Core 1 : Not Averaged (Poll CPU)
Core 2 : Not Averaged (Poll CPU)
Core 3 : Not Averaged (Poll CPU)
Core 4 : 2.2% user, 0.2% sys, 0.0% io, 0.0% irq, 97.6% idle
Core 5 : 0.8% user, 0.5% sys, 0.0% io, 0.0% irq, 98.7% idle
Core 6 : 0.4% user, 0.5% sys, 0.0% io, 0.0% irq, 99.1% idle
Core 7 : 0.1% user, 0.3% sys, 0.0% io, 0.0% irq, 99.6% idle
Poll CPUs : 3 (1, 2, 3)
Core 1 : 100.0% user, 0.0% sys, 0.0% io, 0.0% irq, 0.0% idle
Core 2 : 100.0% user, 0.0% sys, 0.0% io, 0.0% irq, 0.0% idle
Core 3 : 100.0% user, 0.0% sys, 0.0% io, 0.0% irq, 0.0% idle
Processes / Tasks : 143 processes / 16 tasks
Network mcdmaN : 0.002 kpps rx, 0.001 mbps rx, 0.002 kpps tx, 0.001 mbps tx
File Usage : 1504 open files, 1627405 available
Memory Usage : 7687M 46.9% used
Memory Details:
Static : 330M kernel, 144M image
System : 10M tmp, 0M buffers, 54M kcache, 79M cache
Process/Task : 6963M (120M small, 684M huge, 6158M other)
Other : 104M shared data
Free : 8696M free
Usable : 5810M usable (8696M free, 0M reclaimable, 2885M reserved by tasks)El comando #show npu utilization table proporcionará un buen resumen sobre la utilización de cada núcleo asociado con el proceso iftask (en cada tarjeta).
Nota: Es importante identificar si algunos núcleos tienen una utilización más alta que otros núcleos.
[local]UGP# show npu utilization table
-------iftask-------
lcore now 5min 15min
-------- ------ ------ ------
01/0/1 0% 0% 0%
01/0/2 0% 0% 0%
02/0/1 0% 0% 0%
02/0/2 2% 1% 0%
03/0/1 0% 0% 0%
03/0/2 0% 0% 0%
03/0/3 0% 0% 0%
04/0/1 0% 0% 0%
04/0/2 0% 0% 0%
04/0/3 0% 0% 0%
05/0/1 0% 0% 0%
05/0/2 0% 0% 0%
05/0/3 0% 0% 0%Comando #show npumgr utilization information (comando oculto)
Este comando brinda más información sobre cada núcleo iftask y qué consume la CPU en estos núcleos.
Nota: Los núcleos PMD están consumiendo su CPU en PortRX, PortTX, KNI, Cypher. Los núcleos de MCDMA están consumiendo su CPU por MCDMA.
Los núcleos PMD y MCDMA deben tener una carga bastante uniforme.
Si este no es el caso, podría ser necesario realizar algunos ajustes (por ejemplo, asignar más/menos núcleos de MDMA).
******** show npumgr utilization information 3/0/0 *******
5-Sec Avg: lcore01| lcore02| lcore03| lcore04| lcore05| lcore06| lcore07| lcore08| lcore09| lcore10| lcore11| lcore12| lcore13| lcore14| lcore15| lcore16|
Idle: 31%| 37%| 32%| 35%| 41%| 48%| 47%| 38%| 57%| 56%| 55%| 56%| 46%| 56%| 54%| 52%|
PortRX: 28%| 26%| 27%| 26%| 0%| 0%| 0%| 0%| 12%| 14%| 11%| 11%| 0%| 0%| 0%| 0%|
PortTX: 5%| 5%| 6%| 5%| 8%| 8%| 8%| 14%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%|
KniRX: 6%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%|
Kni: 1%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%|
McdmaRX: 0%| 0%| 0%| 0%| 34%| 29%| 29%| 32%| 0%| 0%| 0%| 0%| 35%| 28%| 28%| 28%|
Mcdma: 0%| 0%| 0%| 0%| 11%| 7%| 4%| 6%| 0%| 0%| 0%| 0%| 14%| 7%| 7%| 7%|
Vnpu: 28%| 29%| 28%| 32%| 0%| 0%| 0%| 0%| 30%| 28%| 33%| 28%| 0%| 0%| 0%| 0%|
McdmaFlush: 0%| 0%| 0%| 0%| 6%| 8%| 12%| 10%| 0%| 0%| 0%| 0%| 6%| 10%| 11%| 14%|
Cipher: 1%| 2%| 6%| 2%| 0%| 0%| 0%| 0%| 1%| 2%| 1%| 5%| 0%| 0%| 0%| 0%|
rx kbits/sec: 728563| 736103| 647535| 626595| 811362| 698724| 717147| 799281| 617199| 595268| 623670| 633132| 819270| 672732| 790849| 719498|
rx frames/sec: 94409| 95586| 91107| 84997| 109526| 97466| 98557| 107690| 81122| 82076| 86959| 87960| 114114| 96198| 108108| 100259|
tx kbits/sec: 715038| 722181| 634227| 614221| 827124| 712740| 731329| 814782| 605373| 583318| 611001| 620328| 835692| 686575| 806395| 733924|
tx frames/sec: 94310| 95491| 90969| 84896| 109526| 97466| 98557| 107690| 81002| 81986| 86858| 87859| 114114| 96198| 108108| 100259|
5-Min Avg: ...
15-Min Avg: ...más explicación:
La CPU se contabiliza de la siguiente manera para un paquete que entra en el proceso iftask a través del puerto de servicio o del puerto DI.
La búsqueda de Vnpu es la parte más intensiva de la cpu.
Si después de la búsqueda de Vnpu:
- Si el paquete se envía al núcleo MCDMA, el tiempo de la CPU se contabilizará en el McdmaRx del núcleo MCDMA correspondiente.
-Si el paquete se envía a otro núcleo de tareas, el tiempo de la CPU se contabilizará en Vnpu
-el paquete se envía en el mismo si el núcleo de tareas, el tiempo de la CPU se contabilizará en PortRx
-el paquete se envía en el mismo si el núcleo de tareas, el tiempo de la CPU se contabilizará bajoKniRx
PortRx también incluye una sobrecarga general significativa para extraer paquetes de las colas de recepción y enviarlos/ponerlos en cola a donde deben ir
Comandos #show npumgr dinet utilization pps, #show npumgr dinet utilization bbps y tabla de utilización de puertos #show
Proporcionan información sobre la carga en los puertos de ID y los puertos de servicios.
El rendimiento real depende de la asignación de NIC/CPU y CPU a iftask.
[local]UGP# show npumgr dinet utilization pps
------ Average DINet Port Utilization (in kpps) ------
Port Type Current 5min 15min
Rx Tx Rx Tx Rx Tx
----- ------------------------ ------- ------- ------- ------- ------- -------
1/0 Virtual Ethernet 0 0 0 0 0 0
2/0 Virtual Ethernet 0 0 0 0 0 0
3/0 Virtual Ethernet 0 0 0 0 0 0
4/0 Virtual Ethernet 0 0 0 0 0 0
5/0 Virtual Ethernet 0 0 0 0 0 0
[local]UGP# show npumgr dinet utilization bps
------ Average DINet Port Utilization (in mbps) ------
Port Type Current 5min 15min
Rx Tx Rx Tx Rx Tx
----- ------------------------ ------- ------- ------- ------- ------- -------
1/0 Virtual Ethernet 1 1 1 1 1 1
2/0 Virtual Ethernet 1 0 1 0 1 0
3/0 Virtual Ethernet 0 0 0 0 0 0
4/0 Virtual Ethernet 0 0 0 0 0 0
5/0 Virtual Ethernet 0 0 0 0 0 0
[local]UGP# show port utilization table
------ Average Port Utilization (in mbps) ------
Port Type Current 5min 15min
Rx Tx Rx Tx Rx Tx
----- ------------------------ ------- ------- ------- ------- ------- -------
1/1 Virtual Ethernet 0 0 0 0 0 0
2/1 Virtual Ethernet 0 0 0 0 0 0
3/10 Virtual Ethernet 0 0 0 0 0 0
3/11 Virtual Ethernet 0 0 0 0 0 0
4/10 Virtual Ethernet 0 0 0 0 0 0
4/11 Virtual Ethernet 0 0 0 0 0 0
5/10 Virtual Ethernet 0 0 0 0 0 0
5/11 Virtual Ethernet 0 0 0 0 0 0Comando #show cloud monitor di-network summary
Este comando monitorea el estado de la red DI. Las tarjetas se envían latidos entre sí, y se monitorea la Pérdida. En un sistema sano, no se informa de ninguna pérdida.
[local]UGP# show cloud monitor di-network summary Card 3 Heartbeat Results: ToCard Health 5MinLoss 60MinLoss 1 Good 0.00% 0.00% 2 Good 0.00% 0.00% 4 Good 0.00% 0.00% 5 Good 0.00% 0.00% Card 4 Heartbeat Results: ToCard Health 5MinLoss 60MinLoss 1 Good 0.00% 0.00% 2 Good 0.00% 0.00% 3 Good 0.00% 0.00% 5 Good 0.00% 0.00% Card 5 Heartbeat Results: ToCard Health 5MinLoss 60MinLoss 1 Good 0.00% 0.00% 2 Good 0.00% 0.00% 3 Good 0.00% 0.00% 4 Good 0.00% 0.00%
Comando #show iftask stats summary
Con cargas de NPU más altas, es posible que se interrumpa el tráfico.
Para evaluar esto, se puede tomar el comando show iftask stats summary.
Nota: DISCARDS puede ser distinto de cero, todos los demás contadores deberían permanecer idealmente en 0.
[local]VPC# show iftask stats summary Thursday January 18 16:01:29 IST 2018 ----------------------------------------------------------------------------------------------- Counter SF3 SF4 SF5 SF6 SF7 SF8 SF9 SF10 SF11 SF12 ___TOTAL___ ------------------------------------------------------------------------------------------------ svc_rx 32491861127 16545600654 37041906441 37466889835 32762859630 34931554543 38861410897 16025531220 33566817747 32823851780 312518283874 svc_tx 46024774071 14811663244 40316226774 39926898585 40803541378 48718868048 35252698559 1738016438 4249156512 40356388348 312198231957 di_rx 42307187425 14637310721 40072487209 39584697117 41150445596 44534022642 31867253533 1731310419 4401095653 40711142205 300996952520 di_tx 28420090751 16267050562 36423298668 36758561246 32731606974 30366650898 35201117980 16009902791 33536789041 32815316570 298530385481 __ALL_DROPS__ 1932492 252 17742 790473 11228 627018 844812 60402 0 460830 4745249 svc_tx_drops 0 0 0 0 0 0 0 0 0 0 0 di_rx_drops 0 1 0 0 49 113 579 30200 0 4888 35830 di_tx_drops 0 0 0 0 0 0 0 0 0 0 0 sw_rss_enq_drops 0 0 0 0 0 0 0 0 0 0 0 kni_thread_drops 0 0 0 0 0 0 0 0 0 0 0 kni_drops 0 1 0 0 0 0 124 30200 0 0 30325 mcdma_drops 0 0 0 168 80 194535 758500 0 0 11628 964911 mux_deliver_hop_drops 0 0 0 0 0 0 0 0 0 1019 1019 mux_deliver_drops 0 0 0 0 0 0 0 0 0 0 0 mux_xmit_failure_drops 0 3 0 0 0 0 7 2 0 0 12 mc_dma_thread_enq_drops 0 0 0 0 49 113 580 0 0 3457 4199 sw_tx_egress_enq_drops 1904329 0 0 787971 9004 429214 85022 0 0 429810 3645350 cpeth0_drops 0 0 0 0 0 0 0 0 0 0 0 mcdma_summary_drops 28163 247 17742 2334 2046 3043 0 0 0 10028 63603 fragmentation_err 0 0 0 0 0 0 0 0 0 0 0 reassembly_err 0 0 0 0 0 0 0 0 0 0 0 reassembly_ring_enq_err 0 0 0 0 0 0 0 0 0 0 0 __DISCARDS__ 20331090 9051092 23736055 23882896 23807520 24231716 24116576 8944291 22309474 20135799 20135799
SW-RSS y HW-RSS
RSS es una función que puede distribuir el tráfico entrante procedente de una NIC a través de varios procesadores DPDK. Normalmente, la NIC admite RSS en hardware, lo que le permite distribuir el tráfico a través de varios núcleos de tareas ifg.
El proceso iftask en Staros ha implementado una versión de software de rss que se puede habilitar si:
-nic no soporta HW rss (y por lo tanto todo el tráfico tx/rx aterrizará en una sola CPU iftask).
-nic no tiene suficientes colas tx/rx (menos colas que las CPU tx/rx disponibles asignadas a iftask). En ese caso, el SW-RSS (integral) permite una distribución adecuada entre todos los núcleos de tareas if disponibles asignados para rx/tx.
Esta función solo funciona para el tráfico que entra a través de los puertos de servicio. El tráfico de ID no se tiene en cuenta.
Existen 3 modos de configuración:
-no iftask sw-rss - sw-rss desactivado. El sistema se basa en RSS de hardware.
-iftask sw-rss integral: uso de sw rss para todo el tráfico. SW RSS se puede ejecutar junto con HW RSS. No es necesario desactivar el RSS de hardware. Pero el SW RSS será responsable del balanceo de carga real del tráfico SERVICE a los núcleos iftask.
-iftask sw-rss suplemental - uso de sw rss sólo para el tráfico que no admite hw-rss (ejemplo: tráfico MPLS)
Con HW y SW RSS, es importante entender cómo el tráfico se trocea en los diversos procesadores iftask/dpdk.
HW RSS: el hashing depende del hardware. Debajo tiene un ejemplo:
[root@host]# ethtool -n enp10s0f1
4 RX rings available
Total 0 rules
[root@host] # ethtool -n enp10s0f0 rx-flow-hash udp4
UDP over IPV4 flows use these fields for computing Hash flow key:
IP SA
IP DA
SW RSS: A partir de Staros 21.6, el hash de la versión SW RSS se comporta de la siguiente manera:
1. In case of IPV6
we only support L3( IP src/dst ) based hashing (same as the old behaviour).
2. In case of IPV4
a. For TCP we support IP src/dst + tcp ports src/dst
b. For UDP fragmented - only IP src/dst
c. For UDP non-fragmented not gtpu ( I.e. Port !=2152) ? IP src/dst + udp port src/dst
d. For UDP non-fragmented and gtpu ( I.e. Port ==2152) - IP src/dst + udp port src/dst + gtp tunnel id
e. Any other protocol ? we default back to IP src/dst
Importante: RSS para tráfico de ID cifrado:
En ausencia de SW-RSS (suplementario/completo), podría ser posible que todo el tráfico de ID cifrado se trocee en un solo núcleo en iftask.
Esto hará que este núcleo tenga de manera consistente una mayor utilización que los demás.
Desde CSCvi06080  , esto ahora puede ser mitigado por este comando de configuración:
, esto ahora puede ser mitigado por este comando de configuración:
iftask di-net-encrypt-rss
Después de la integración de CSCvm41257 , esta opción se convertirá en predeterminada.
Información más detallada sobre SW RSS:
El objetivo del sw-rss es equilibrar la carga de los núcleos PMD y evitar situaciones de limitación del rendimiento en las que un núcleo PMD se maximice cuando los otros tienen una capacidad disponible significativa.
Todos los paquetes de ingreso de puerto de servicio son extraídos de NIC y reciben encapsulación MEH por el núcleo PMD que atiende la cola Rx en la que llegan.
En este punto, iftask no sabe a dónde enviar el paquete. La VNPU debe procesar los paquetes para determinar el destino interno. Prácticamente todos estos paquetes pasan por la búsqueda de IOC/flujo cuando se transfieren a la VNPU. Las excepciones se refieren a descartes por razones como vlan no configurada/inhabilitada o MAC de destino no válido (también está el escenario de reenvío L3, pero esto es poco común).
Si no se configura sw-rss, el procesamiento de búsqueda de flujo/IOC de VNPU ocurre en el mismo núcleo inmediatamente después de la encapsulación MEH. Si se configura sw-rss, los paquetes se ponen en cola en un núcleo para el procesamiento de VNPU basado en un hash. La operación de búsqueda de flujo/IOC de VNPU es la función iftask más costosa; sw-rss nos permite equilibrar esa carga de trabajo en todos los núcleos PMD.
Tras la búsqueda de VNPU IOC/flujo, el paquete se transmite a otro SF mediante transmisión DINet o se coloca en cola en la aplicación local mediante transferencia MCDMA (de nuevo, hay excepciones, pero no creo que sean relevantes para esta conversación).
Los paquetes enviados a otro SF se colocan directamente en cola en el canal MCDMA apropiado en la tarjeta de destino después de DINet Rx. No requieren un (segundo) pase VNPU.
Colas TX/RX
En los registros de iftask, podemos ver registros como:
Tue May 7 15:26:48 2019 PID:8188 APP: max rx queues supported 16 ...
Tue May 7 15:26:48 2019 PID:8188 APP: max tx queues supported 8 ...
Tue May 7 15:26:48 2019 PID:8188 APP: hw rx requested 2 ...
Tue May 7 15:26:48 2019 PID:8188 APP: hw tx requested tx 5
Esto se relaciona con el número admitido de colas rx y tx que el hardware real soporta frente al número de colas tx/rx que satisfacen las solicitudes de tarea.
¿Qué pasa si las solicitudes de tareas están estrechamente relacionadas con el número de procesadores asignados a iftask.
Nota: Cada conductor es diferente. Algunos host de consultas, algunos tienen código.
El conteo de hw tx solicitados es el número de núcleos que usa dpdk. Esto es típicamente uno más que el total de núcleos asignados a iftask porque dpdk incluye el núcleo en el que se ejecuta el subproceso de control/ipc. Este núcleo se comparte con boxer y se programa como una cpu de uso general (el subproceso dpdk control/ipc no utiliza gran cantidad de cpu).
El conteo de hw rx solicitado es típicamente el número de núcleos PMD.
Siftask asigna el mínimo (solicitado, máximo) para cada puerto y lo distribuye a través de los núcleos. El algoritmo de distribución es un poco complicado. El objetivo es distribuir la carga de trabajo de la forma más uniforme posible entre todos los núcleos.
Iftask txbatch
Desde la versión 21.9, staros tiene las siguientes opciones de configuración iftask predeterminadas que son importantes para la agrupación (agregación de tráfico). Esto tiene algún impacto negativo en el rendimiento cuando el nodo está bajo prueba con suscriptores únicos (o pocos).
# iftask mcdmatxbatch burst size 32 # iftask mcdmatxbatch latency 200 # iftask txbatch burst size 32 # iftask txbatch latency 200
Encontrará más información al respecto en otro documento:
Estadísticas globales
El esquema Bulkstat se ha desarrollado para el rendimiento QPVC-DI relacionado con iftask/dinet. Esto es útil para monitorear la utilización de dinet, los puertos de servicio y la npu desde una perspectiva de rendimiento/carga:
card schema iftask-dinet format EMS,IFTASKDINET,%date%,%time%,%dinet-rxpkts-curr%,%dinet-txpkts-curr%,%dinet-rxpkts-5minave%,%dinet-txpkts-5minave%,%dinet-rxpkts-15minave%,%dinet-txpkts-15minave%,%dinet-txdrops-curr%,%dinet-txdrops-5minave%,%dinet-txdrops-15minave%,%npuutil-now% file 2 port schema iftask-port format EMS,IFTASKPORT,%date%,%time%,%util-rxpkts-curr%,%util-txpkts-curr%,%util-rxpkts-5min%,%util-txpkts-5min%,%util-rxpkts-15min%,%util-txpkts-15min%,%util-txdrops-curr%,%util-txdrops-5min%,%util-txdrops-15min% file 3 card schema npu-util format EMS,NPUUTIL,%date%,%time%,%npuutil-now%,%npuutil-5minave%,%npuutil-15minave%,%npuutil-rxbytes-5secave%,%npuutil-txbytes-5secave%,%npuutil-rxbytes-5minave%,%npuutil-txbytes-5minave%,%npuutil-rxbytes-15minave%,%npuutil-txbytes-15minave%,%npuutil-rxpkts-5secave%,%npuutil-txpkts-5secave%,%npuutil-rxpkts-5minave%,%npuutil-txpkts-5minave%,%npuutil-rxpkts-15minave%,%npuutil-txpkts-15minave%
Historial de revisiones
| Revisión | Fecha de publicación | Comentarios |
|---|---|---|
1.0 |
09-Jun-2018
|
Versión inicial |
Con la colaboración de ingenieros de Cisco
- Steven Loos
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)