Introducción
Este documento describe cómo funciona Instant Message and Presence (IM&P) High Availability en un entorno de IM&P empresarial y cómo resolver problemas.
Prerequisites
Requirements
Cisco recomienda que tenga conocimiento sobre estos temas:
- IM&P de Cisco Unified
- Clientes de Cisco Jabber
Componentes Utilizados
- Cisco Unified IM&P 10.0 y posterior
- Clientes Cisco Jabber 9.6 y posteriores
La información de este documento se creó a partir de los componentes de un entorno de laboratorio específico. Todos los componentes utilizados en este documento comenzaron con una configuración desactivada (predeterminada). Si tiene una red en vivo, asegúrese de entender el posible impacto de cualquier comando.
IM y alta disponibilidad de presencia (HA)
El servidor de servicios de mensajería instantánea y presencia ofrece una alta disponibilidad o redundancia en forma de grupos de servidores lógicos en la configuración de CUCM. Esta configuración se pasa a IM and Presence y, a continuación, se utiliza para permitir la redundancia en caso de que se produzca un fallo en el servidor o en un servicio de IM and Presence. Cuando se produce un evento de HA, las sesiones del usuario final se mueven del servidor que ha fallado a la copia de seguridad. Cuando el servidor se ha restaurado a un estado normal, el administrador mueve las sesiones de usuario hacia atrás automática o manualmente.
Configuración del grupo de redundancia
El grupo de redundancia es el par de servidores lógicos que permite la asignación de un servidor al subclúster de IM y presencia, así como la configuración para HA. Para acceder a esta parte de la configuración, búsquela en la página web del servidor de CUCM.
System > Presence Redundancy Groups
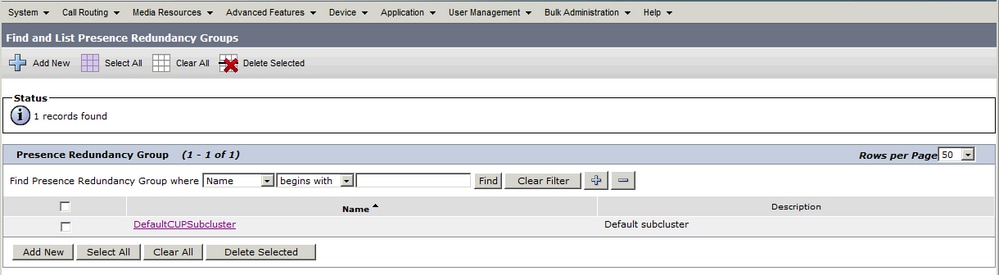
Cuando el administrador agrega el editor de IM&P a la configuración System > Server en CUCM y se guarda el servidor de IM&P, se crea el grupo de redundancia DefaultCUPSubCluster con el editor asignado.
Cuando se crea, el Grupo de Redundancia tiene el siguiente aspecto:
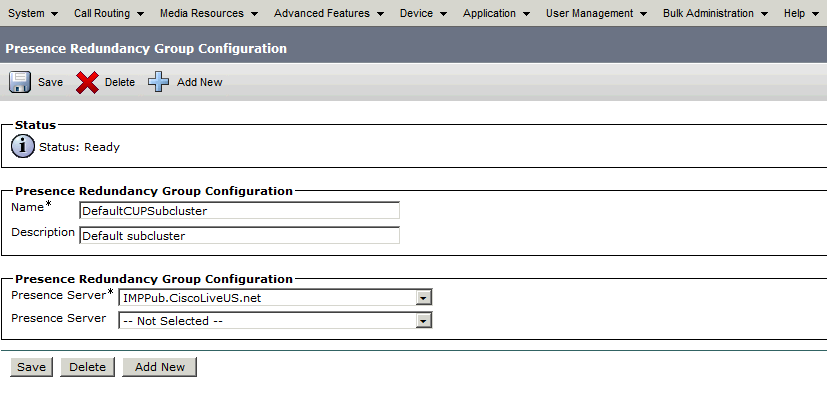
Este grupo de redundancia se traduce al subclúster de IM y presencia. En el estado actual de la configuración del grupo de redundancia en CUCM, este sería el aspecto que tendría en la página web de topología de clúster de presencia y mensajería instantánea:
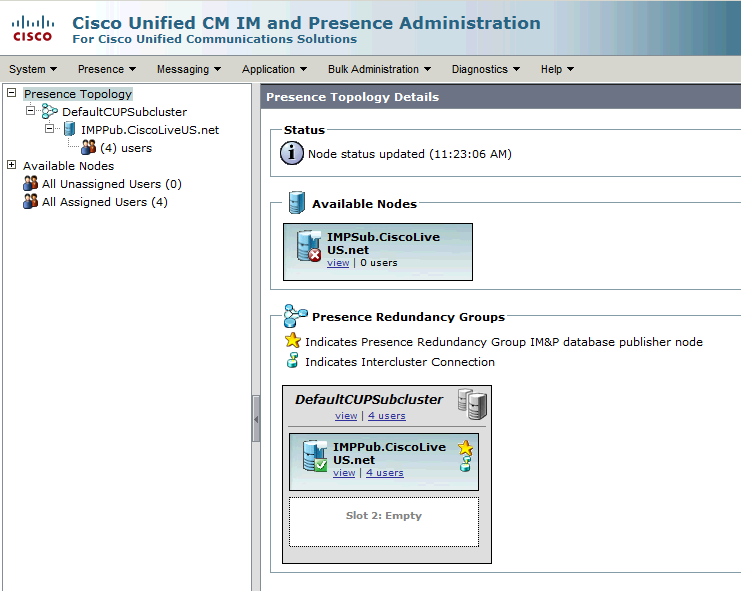
Verá que el editor de IM&P está asignado al subclúster CUPSpredeterminado y que el servidor del suscriptor no lo está. Esto se debe a que el servidor de suscriptor de IM&P no está asignado al grupo de redundancia en la configuración de CUCM.
Asigne el suscriptor al grupo de redundancia.
Para asignar el servidor del suscriptor al grupo de redundancia, simplemente elija el servidor del suscriptor del menú desplegable, luego guarde el cambio de configuración.
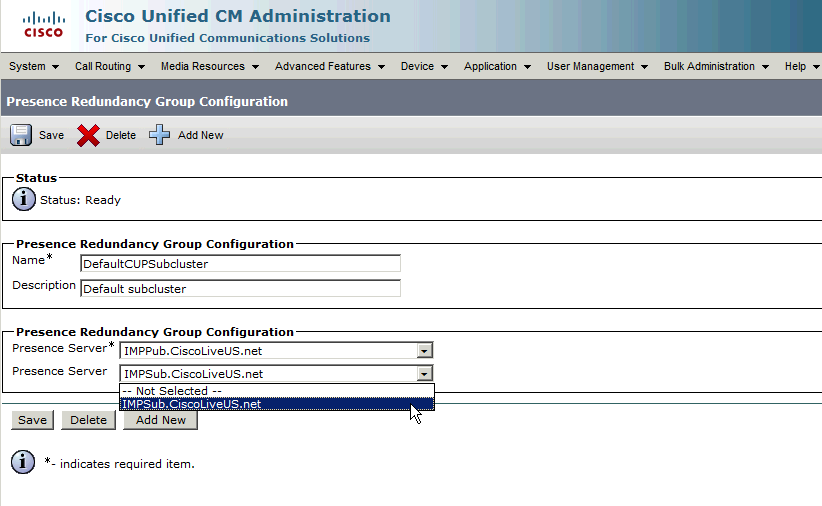
Después de agregar el suscriptor de IM&P al grupo de redundancia:
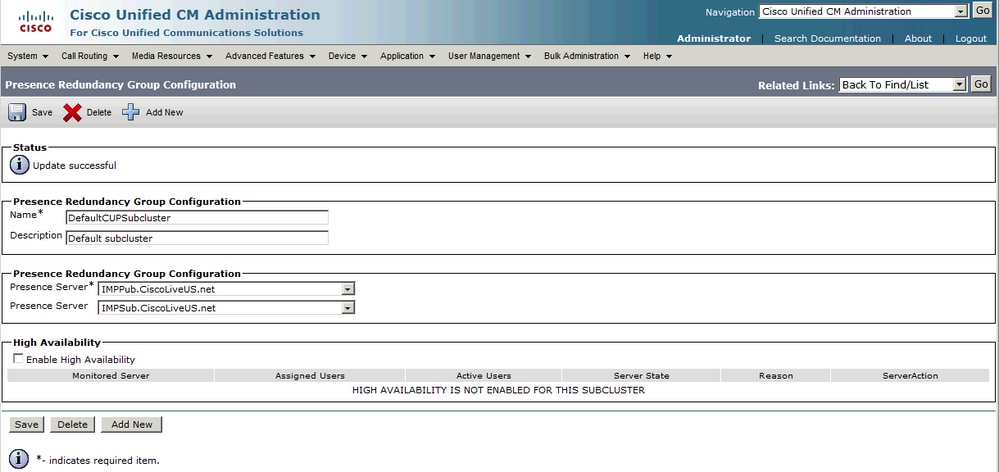
Después de agregar el nodo secundario (el suscriptor), verá que se puede seleccionar la opción Alta disponibilidad. Para activar la alta disponibilidad, solo tiene que seleccionar la casilla de verificación Enable High Availability y Save the configuration change.
Después de habilitar la alta disponibilidad:
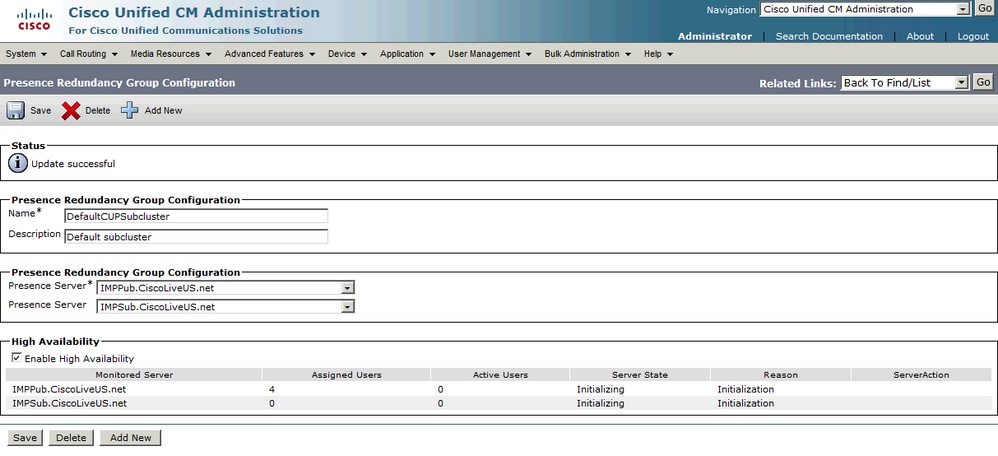
A continuación, la página actualiza automáticamente el estado y el motivo del servidor. Cuando el servidor se encuentra en un estado de inicialización, esto significa que los dos servidores pueden comunicarse. Los servidores verificarían el estado del servicio antes de que el estado pase al estado Normal. Si los dos servidores pueden conectarse entre sí y todos los servicios supervisados están activos en ambos, obtendría un estado Normal-Normal. Esto significa que todos los servicios supervisados están activos en los servidores IM&P.
Estado del grupo de redundancia normal-normal:
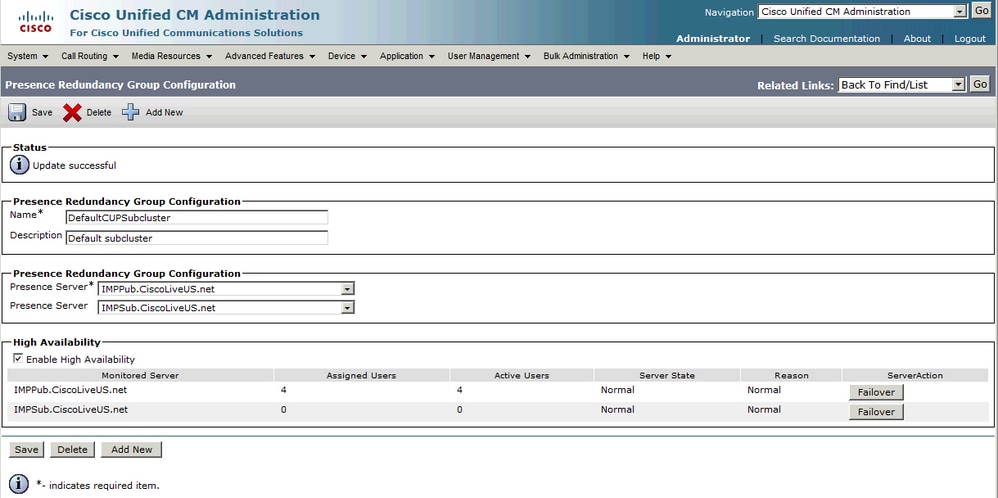
Estado de alta disponibilidad normal-normal en la página de topología de IM&P:
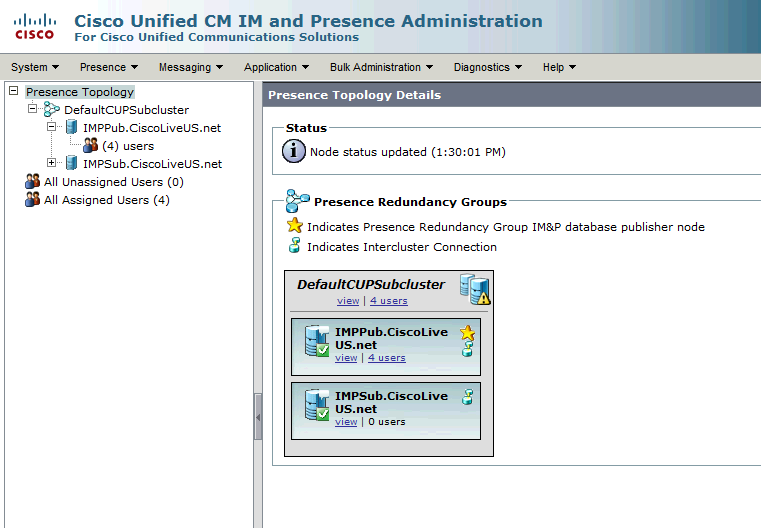
Servicios de presencia y mensajería instantánea supervisados
Dado que puede tener varios modelos de implementación: solo IM, mensajería instantánea con federación SIP/XMPP, mensajería instantánea con cumplimiento, mensajería instantánea con chat persistente, solo control remoto de llamadas, etc., la lista real de los procesos que se van a supervisar es dinámica. De forma predeterminada, estos elementos siempre se supervisan cuando se habilita HA:
- Base de datos IDS
- Presence Engine (si está activado)
- Router XCP
El Administrador de recuperación de servidor comprueba si se ha configurado y activado el cumplimiento (Archivador de mensajes), el chat persistente (Administrador de conferencias de texto), la federación SIP (Administrador de conexiones de federación SIP) y la federación XMPP (Administrador de conexiones de federación XMPP).
Si están configurados y activados, el Administrador de recuperación del servidor (SRM) también supervisa esos servicios.
Precaución: antes de continuar con el reinicio de uno o más de los servicios supervisados, debe deshabilitar la alta disponibilidad de los grupos de redundancia de presencia en el servidor de CUCM. Lo mismo se aplica cuando se reinicia uno o más de los nodos IM&P.
Proceso de failover de usuario
Cuando se produce una conmutación por error (automática o manual), el punto principal que hay que recordar es que la cuenta de usuario no se mueve de un servidor al otro, sino que sólo se mueve la sesión de usuario en Presence Engine. En las versiones anteriores a 10 de IM and Presence, la asignación de usuario se trasladaba de un servidor a otro. Este traslado de usuario resultaba muy costoso para los recursos del servidor y se añadía a la carga que había en el servidor. En 10.X y versiones posteriores, el usuario permanece alojado en el servidor al que está asignado y la sesión de usuario backend en el motor de presencia se mueve del nodo con error al nodo funcional. El usuario no tiene que salir de Jabber y volver a iniciar sesión cuando se produzca el cambio con el Administrador de recuperación de servidores (SRM).
Temporizador de reconexión del cliente Jabber
Para que la sesión de usuario se vuelva completamente activa en el nodo de IM&P secundario después de un evento de failover, el usuario debe intentar iniciar sesión en ese servidor a través de SOAP (Agente de perfil de cliente). Esto sucede automáticamente con la contraseña de un solo uso que se pasa desde la base de datos IMDB. Dado que los recursos del servidor de IM and Presence tienen un coste muy elevado para los inicios de sesión, debe haber una forma de limitar los inicios de sesión cuando se produce un evento de conmutación por fallo. Este acelerador o búfer permite a todos los usuarios iniciar sesión en el nodo secundario sin interrupción del servicio para los usuarios del nodo secundario. Los mecanismos que se utilizan para limitar los inicios de sesión de los usuarios son los parámetros de servicio Client Re-Login Lower Limit y Client Re-Login Upper Limit Server Recovery Manager (SRM).
Límite inferior de reinicio de sesión del cliente: parámetro que define la cantidad mínima de tiempo (en segundos) que el cliente Jabber espera antes de que el cliente intente iniciar sesión en el servidor secundario en caso de un evento HA.
Límite superior de reinicio de sesión del cliente - el parámetro que define la cantidad máxima de tiempo (en segundos) que el cliente Jabber espera antes de que el cliente intente iniciar sesión en el servidor secundario en caso de un evento HA.
El cliente Jabber recibe estos parámetros al iniciar sesión en el servidor y almacena en caché los valores para su uso futuro. Cuando recibe un evento HA del servidor IM&P, el cliente elige un número aleatorio de segundos entre los límites superior e inferior y espera esa cantidad de tiempo antes de que el cliente Jabber intente iniciar sesión en el secundario. Una vez que caduca el temporizador, el cliente intenta iniciar sesión en SOAP en el nodo secundario.
Tipos de reserva de IM y presencia
Si hay failover de usuario, debe haber fallback de usuario cuando se restaura el servicio en el servidor problemático. Existen dos tipos de reserva de servidor:
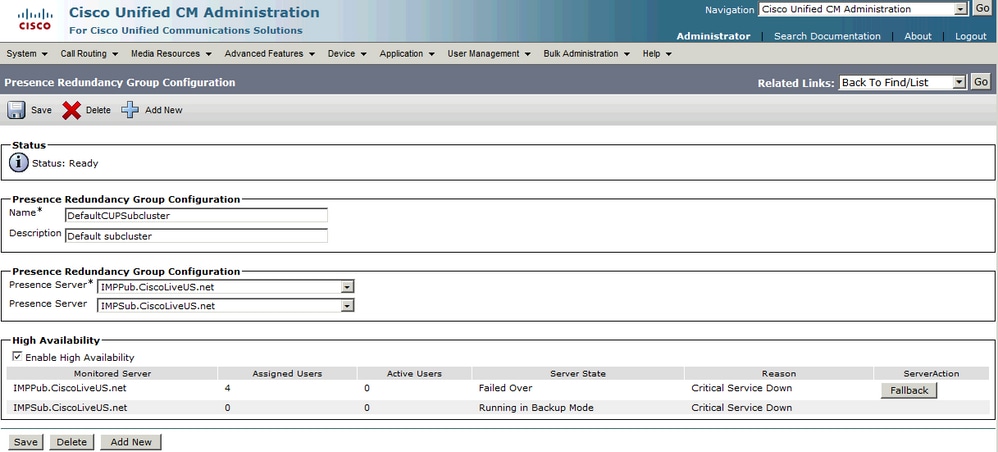
Reserva manual
La reserva manual (configuración predeterminada para el Administrador de recuperación del servidor) tiene lugar cuando se ha restaurado el servicio y el grupo de redundancia permite el botón de reserva. Cuando se selecciona este botón, las sesiones de usuario que se han movido al nodo secundario se mueven de nuevo a su nodo alojado. A continuación, el cliente Jabber aplica los límites superior e inferior de reconexión para el repliegue.
Reserva automática
La reserva automática tiene lugar cuando el servidor supervisa los servicios y el servicio Administrador de recuperación del servidor (SRM) reserva automáticamente a los usuarios a sus nodos alojados. La clave de esta configuración es que el servicio Administrador de recuperación del servidor (SRM) espera 30 minutos a que un servicio o servidor que ha fallado permanezca activo antes de que se inicie una reserva automática. Una vez establecido este tiempo de actividad de 30 minutos, las sesiones de usuario se mueven de nuevo a sus nodos alojados. A continuación, el cliente Jabber aplica los límites superior e inferior de reconexión para el repliegue.

Nota: La reserva automática no es la configuración predeterminada, pero se puede activar. Para habilitar la reserva automática, cambie el parámetro Enable Automatic Fallback (Habilitar reserva automática) en Server Recovery Manager Service Parameters al valor True.
Troubleshoot
Esta sección proporciona la información que puede utilizar para resolver problemas de su configuración.
Al solucionar problemas de alta disponibilidad en el servidor de servicio IM&P, hay dos temporizadores importantes que debe tener en cuenta.
- Los servidores intercambian 4 señales de mantenimiento cada 60 segundos. Si no hay respuesta después de los 60 segundos, Cisco Service Recovery Manager (SRM) considera que el nodo que no responde se desconectó y activa un comando Fail Over. Como muestra el siguiente fragmento, el último latido ocurrió hace 62 segundos.
2021-05-13 02:48:48,244 INFO[HS]rsrm.RsrmHeartBeatHandler - RsrmHeartBeatHandler: peer down, time since last heartbeat[s]= 62
2021-05-13 02:48:48,244 INFO [HS] rsrm.RsrmAutomaticFallback - RsrmAutomaticFallback: peer states vector changed to [Normal,Running in Backup Mode]
Sugerencia: en este caso, si ha detectado latencia en la red, se recomienda aumentar el temporizador de tiempo de espera de latido de 60 a 90 segundos.
Vaya a la página web de administración de CUCM > Sistema > Configuración de parámetros del servicio > Seleccione el servidor IM&P> Seleccione Configuración de Cisco Recovery Manager. En el tiempo de espera de Mantener activo (latido), aumente el número a 90 segundos.
- El servidor de suscriptor de IM&P espera 90 segundos. Si detecta que uno o más de los servicios monitoreados están inactivos, el servidor del Suscriptor toma el control.
Registros que se recopilarán para solucionar problemas
- Los registros del Administrador de recuperación del servidor (SRM) se inician antes y después del evento de conmutación por error (nivel de depuración si es posible).
- El resultado del comando a través de la interfaz de línea de comandos de IM&P ejecuta sql select * desde enterprisesubcluster.
- La tabla de subclúster empresarial de IM&P contiene la configuración del grupo de redundancia.
- El resultado del comando a través de la interfaz de línea de comandos de IM&P ejecuta sql select * from enterprisenode.
- La tabla enterprisenode muestra la información del nodo y la asignación del subclúster del nodo.
- Si la conmutación por error la produce un servicio que se está deteniendo, recopile:
- Registros del sistema del visor de eventos
- Registros de aplicación del visor de eventos
- Registros del servicio que se detienen.
 Comentarios
Comentarios