Introducción
Este documento describe cómo diagnosticar problemas de réplica de base de datos y proporciona los pasos necesarios para resolverlos.
Pasos para diagnosticar la réplica de base de datos
En esta sección se describen los escenarios en los que se interrumpe la replicación de la base de datos y se proporciona la metodología de solución de problemas para diagnosticar y aislar el problema.
Paso 1. Verificar que la Replicación de la Base de Datos esté Dañada
Para determinar si la réplica de base de datos está dañada, debe conocer los diversos estados de la herramienta de monitoreo en tiempo real (RTMT) para la replicación.
| Valor |
Significado |
Descripción |
|
0
|
Estado de inicialización
|
La replicación está en proceso de configuración. Se puede producir un error de configuración si la replicación permanece en este estado durante más de una hora.
|
|
1
|
El número de réplicas es incorrecto.
|
La configuración aún está en curso. Este estado rara vez se ve en las versiones 6.x y 7.x; en la versión 5.x, se indica que la configuración aún está en curso.
|
|
2
|
La replicación es buena
|
Se establecen conexiones lógicas y las tablas coinciden con los otros servidores del clúster.
|
|
3
|
Tablas no coincidentes
|
Se establecen conexiones lógicas, pero existe una incertidumbre sobre si las tablas coinciden.
En las versiones 6.x y 7.x, todos los servidores pueden mostrar el estado 3, incluso si un servidor está inactivo en el clúster.
Este problema puede ocurrir porque los otros servidores no están seguros de si hay una actualización de la función orientada al usuario (UFF) que no se ha transmitido del suscriptor al otro dispositivo en el clúster.
|
|
4
|
Falló/se descartó la configuración
|
El servidor ya no tiene una conexión lógica activa para recibir cualquier tabla de base de datos a través de la red. No se produce ninguna replicación en este estado.
|
Para verificar la replicación de la base de datos, ejecute el comando utils dbreplication runtimestate desde la CLI del nodo del editor, como se muestra en esta imagen.
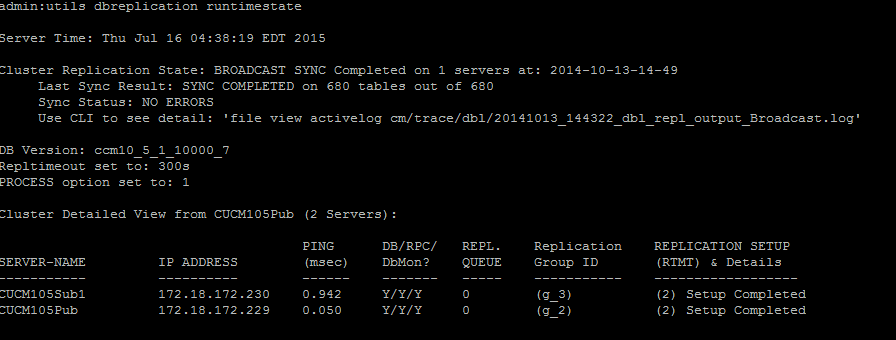
En el resultado, asegúrese de que el estado de replicación del clúster no contenga la información de sincronización anterior. Marque la misma opción y utilice Timestamp.
Si la sincronización de difusión no se actualiza con una fecha reciente, ejecute el comando utils dbreplication status para verificar todas las tablas y la replicación. Si se descubre algún error o discordancia, se muestra en la salida y el estado de RTMT cambia en consecuencia.
Después de ejecutar el comando, se verifica la coherencia de todas las tablas y se muestra un estado de replicación preciso.
Nota: Deje que se comprueben todas las tablas y, a continuación, continúe con la resolución de problemas.

Una vez que se muestra un estado de replicación preciso, verifique la configuración de replicación (RTMT) y los detalles como se muestran en el primer resultado. Debe verificar el estado de cada nodo. Si algún nodo tiene un estado distinto de 2, continúe con la resolución de problemas.
Paso 2. Recopile el estado de la base de datos CM de la página Cisco Unified Reporting en CUCM
- Después de completar el paso 1, elija la opción Cisco Unified Reporting en la lista desplegable Navegación del editor de Cisco Unified Communications Manager (CUCM), como se muestra en esta imagen.
2. Navegue hasta Informes del sistema y haga clic en Estado de base de datos de Unified CM como se muestra en esta imagen.
3. Genere un nuevo informe, haga clic en el icono Generar Nuevo Informe como se muestra en esta imagen.

4. Espere a que el nuevo informe se genere correctamente.

5. Una vez generado, haga clic en el icono para descargar el informe y guardarlo para que se pueda proporcionar a un ingeniero del TAC en caso de que sea necesario abrir una solicitud de servicio (SR).

Paso 3. Revisar el informe de base de datos de Unified CM de cualquier componente marcado como error
Si hay algún error en los componentes, los errores se marcan con un icono de X rojo, como se muestra en esta imagen.
- En caso de error, verifique la conectividad de red entre los nodos. Verifique si el servicio A Cisco DB se ejecuta desde la CLI del nodo y utiliza el comando utils service list.
- Si el servicio A de base de datos de Cisco está inactivo, ejecute el comando utils service start A Cisco DB para iniciar el servicio. Si esto falla, comuníquese con el TAC de Cisco.
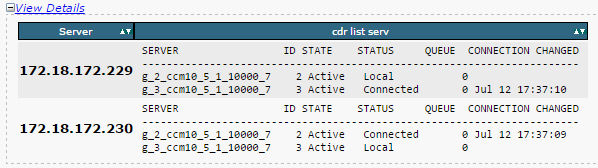
- Asegúrese de que la lista de servidores de replicación (cdr list serv) se complete para todos los nodos.
Esta imagen ilustra una salida ideal.
Si la lista del Replicador de bases de datos de Cisco (CDR) está vacía para algunos nodos, consulte el Paso 8.
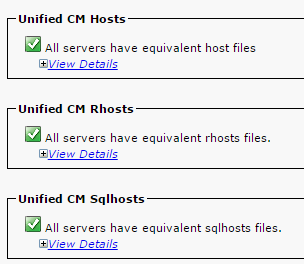
- Asegúrese de que los hosts de Unified CM, los Rhosts y los Sqlhosts sean equivalentes en todos los nodos.
Este es un paso importante. Como se muestra en esta imagen, los hosts de Unified CM, los Rhosts y los Sqlhosts son equivalentes en todos los nodos.
Los archivos de hosts no coinciden:
Existe la posibilidad de una actividad incorrecta cuando una dirección IP cambia o se actualiza al nombre de host en el servidor.
Consulte este enlace para cambiar la dirección IP al nombre de host para CUCM.
Cambios en la dirección IP y el nombre de host
Reinicie estos servicios desde la CLI del servidor del editor y verifique si se elimina la discordancia. En caso afirmativo, vaya al paso 8. En caso negativo, póngase en contacto con el TAC de Cisco. Genere un nuevo informe cada vez que realice un cambio en la GUI/CLI para verificar si los cambios están incluidos.
Cluster Manager ( utils service restart Cluster Manager)
A Cisco DB ( utils service restart A Cisco DB)
Los archivos de Rhosts no coinciden:
Si los archivos de Rhosts no coinciden con los archivos de host, siga los pasos mencionados en Los archivos de Hosts no coinciden. Si solo los archivos de Rhosts no coinciden, ejecute los comandos desde la CLI:
A Cisco DB ( utils service restart A Cisco DB )
Cluster Manager ( utils service restart Cluster Manager)
Genere un nuevo informe y verifique si los archivos de Rhost son equivalentes en todos los servidores. En caso afirmativo, vaya al paso 8. En caso negativo, póngase en contacto con el TAC de Cisco.
Los Sqlhosts no coinciden:
Si los Sqlhosts no coinciden con los archivos de host, siga los pasos mencionados en Los archivos de hosts no coinciden. Si solo los archivos de Sqlhosts no coinciden, ejecute el comando desde la CLI:
utils service restart A Cisco DB
Genere un nuevo informe y verifique si los archivos de Sqlhost son equivalentes en todos los servidores. En caso afirmativo, vaya al paso 8. En caso negativo, póngase en contacto con el TAC de Cisco
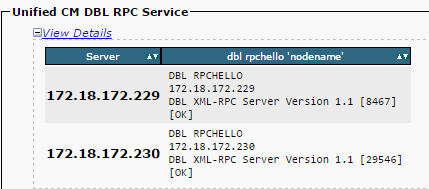
Si el saludo de RPC no funciona para un nodo en particular:
- Garantizar la conectividad de red entre el nodo en particular y el publicador.
- Asegúrese de que el número de puerto 1515 esté permitido en la red.
Consulte este enlace para obtener detalles sobre el uso del puerto TCP / UDP:
Uso de los puertos TCP y UDP de Cisco Unified Communications Manager
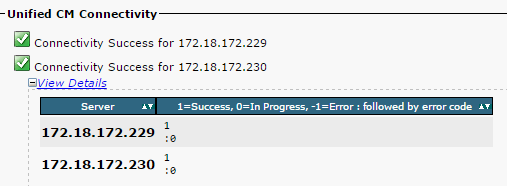
- Asegúrese que la conectividad de red se realice correctamente entre los nodos, como se muestra en esta imagen:

Si la conectividad de red falla para los nodos:
- Asegúrese de que la disponibilidad de la red esté presente entre los nodos.
- Asegúrese de que los números de puerto TCP/UDP adecuados estén permitidos en la red.
Genere un nuevo informe y verifique que la conexión sea correcta. En caso de una conexión fallida, vaya al paso 8.
Paso 4. Compruebe los componentes individuales que utilizan el comando de comprobación de diagnóstico Utils
El comando utils diagnose test verifica todos los componentes y devuelve un valor aprobado/fallido. Los componentes que son esenciales para el correcto funcionamiento de la réplica de base de datos son:
El comando validate_network verifica todos los aspectos de la conectividad de red con todos los nodos del clúster. Si hay un problema con la conectividad, a menudo se muestra un error en el servidor de nombres de dominio / servidor de nombres de dominio inverso (DNS / RDNS). El comando validate_network completa la operación en 300 segundos. Los mensajes de error comunes que se ven en las pruebas de conectividad de red:
1. Error "La comunicación dentro del clúster está dañada", como se muestra en esta imagen.

Este error se produce cuando uno o más nodos del clúster tienen un problema de conectividad de red. Asegúrese de que todos los nodos tengan disponibilidad de ping.
Si se interrumpe la comunicación dentro del clúster, se producen problemas de réplica de base de datos.
2. Falló la búsqueda de DNS inversa.
Este error se produce cuando la búsqueda inversa de DNS falla en un nodo. Sin embargo, puede verificar si el DNS está configurado y funciona correctamente cuando utiliza estos comandos:
utils network eth0 all - Shows the DNS configuration (if present)
utils network host <ip address/Hostname> - Checks for resolution of ip address/Hostname
Si el DNS no funciona correctamente, puede causar problemas de replicación de la base de datos cuando se definen los servidores y se utilizan los nombres de host.
El NTP es responsable de mantener la hora del servidor sincronizada con el reloj de referencia. El publicador siempre sincroniza la hora con el dispositivo cuya IP aparece como servidores NTP; mientras que los suscriptores sincronizan la hora con el publicador.
Es extremadamente importante que el NTP sea totalmente funcional para evitar cualquier problema de réplica de base de datos.
Es esencial que el estrato NTP (número de saltos al reloj de referencia principal) debe ser menor que 5 o de lo contrario se considera no confiable.
Complete estos pasos para verificar el estado de NTP:
- Utilice el comando utils diagnose test para verificar el resultado, como se muestra en esta imagen.
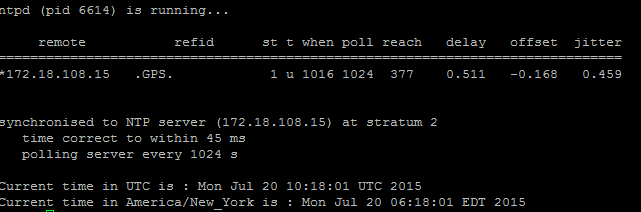
2. Además, puede ejecutar este comando:
utils ntp status
Paso 5. Verifique el estado de la conectividad de todos los nodos y asegúrese de que estén autenticados
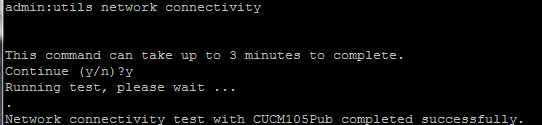
- Después de completar el paso 4, si no se informan problemas, ejecute el comando utils network connectivity en todos los nodos para verificar que la conectividad a las bases de datos se realice correctamente, como se muestra en esta imagen.

2. Si recibe el mensaje de error "No se pueden enviar paquetes TCP/UDP", compruebe si hay retransmisiones en la red o bloquee los puertos TCP/UDP. El comando show network cluster busca la autenticación de todos los nodos.
3. Si el estado del nodo no es autenticado, asegúrese de que la conectividad de red y la contraseña de seguridad sean las mismas en todos los nodos, como se muestra en esta imagen.
Consulte los enlaces para cambiar/recuperar las contraseñas de seguridad:
Cómo restablecer contraseñas en CUCM
Recuperación de la contraseña del administrador del sistema operativo CUCM
Paso 6. El Comando Utils Dbreplication Runtimestate Muestra los Estados No Sincronizados o No Solicitados
Es importante comprender que la réplica de base de datos es una tarea intensiva en la red, ya que envía las tablas reales a todos los nodos del clúster. Asegúrese de lo siguiente:
utils dbreplication setprocess <1-40>
Nota: Al cambiar este parámetro, mejora el rendimiento de la configuración de replicación, pero consume recursos adicionales del sistema.
Server 1-5 = 1 Minute Per Server Servers 6-10 = 2 Minutes Per Server Servers >10 = 3 Minutes Per Server.
Example: 12 Servers in Cluster : Server 1-5 * 1 min = 5 min, + 6-10 * 2 min = 10 min, + 11-12 * 3 min = 6 min,
Repltimeout should be set to 21 Minutes.
Comandos para verificar/definir el tiempo de espera de la replicación:
show tech repltimeout ( To check the current replication timeout value )
utils dbreplication setrepltimeout ( To set the replication timeout )
Los pasos 7 y 8 deben realizarse después de completar la lista de comprobación:
Lista de Verificación:
- Todos los nodos tienen conectividad entre sí. Consulte el paso 5.
- RPC está disponible. Consulte el paso 3.
- Consulte a Cisco TAC antes de continuar con los pasos 7 y 8 en caso de que los nodos sean mayores que 8.
- Realice el procedimiento fuera del horario comercial.
Paso 7. Reparar Todas/Tablas Selectivas para Replicación de Base de Datos
Si el comando utils dbreplication runtimestate muestra que hay tablas de error/no coincidentes, ejecute el comando:
Utils dbreplication repair all
Ejecute el comando utils dbreplication runtimestate para comprobar el estado nuevamente.
Continúe con el paso 8 si el estado no cambia.
Paso 8. Restablezca la Replicación de la Base de Datos desde el Principio
Consulte la secuencia para restablecer la replicación de la base de datos e iniciar el proceso desde el principio.
utils dbreplication stop all (Only on the publisher)
utils dbreplication dropadmindb (First on all the subscribers one by one then the publisher)
utils dbreplication reset all ( Only on the publisher )
Para monitorear el proceso, ejecute el comando RTMT/utils dbreplication runtimestate.
Consulte la secuencia para restablecer la réplica de base de datos para un nodo en particular:
utils dbreplication stop <sub name/IP> (Only on the publisher)
utils dbreplcation dropadmindb (Only on the affected subscriber)
utils dbreplication reset <sub name/IP> (Only on the publisher )
En caso de que se ponga en contacto con el TAC de Cisco para obtener más ayuda, asegúrese de que se proporcionan estos resultados y los informes:
utils dbreplication runtimestate
utils diagnose test
utils network connectivity
Informes:
- Informe de base de datos de Cisco Unified Reporting CM (consulte el paso 2).
- El comando utils create report database de la CLI. Descargue el archivo .tar y utilice un servidor SFTP.
Información Relacionada
 Comentarios
Comentarios