Introducción
Este documento describe cómo configurar Splunk para analizar los registros de tráfico DNS desde una cubeta S3 administrada por Cisco.
Overview
Splunk es una herramienta para el análisis de registros. Proporciona una interfaz potente para analizar grandes fragmentos de datos, como los registros proporcionados por Cisco Umbrella para el tráfico DNS. En este artículo se describe cómo:
- Configure la cubeta S3 gestionada por Cisco en el panel.
- Asegúrese de que se cumplen los requisitos previos de AWS Command Line Interface (AWS CLI).
- Cree un trabajo cron para recuperar archivos de la cubeta y almacenarlos localmente en su servidor.
- Configure Splunk para leer desde un directorio local.
Prerequisites
Creación de un trabajo cron en el servidor Splunk
-
Cree una secuencia de comandos shell denominada pull-umbrella-logs.sh con el contenido proporcionado, que se ejecuta en un trabajo cron programado:
s3://cisco-managed-/1_2xxxxxxxxxxxxxxxxxa120c73a7c51fa6c61a4b6/dnslogs/ ).
-
Guarde el script de shell y establezca el permiso de ejecución. El script debe ser propiedad de root.
$ chmod u+x pull-umbrella-logs.sh
-
Ejecute el pull-umbrella-logs.sh script manualmente para confirmar que el proceso de sincronización funciona correctamente. No es necesario completarlo completamente; este paso confirma que las credenciales y la lógica del script son correctas.
-
Agregue esta línea a su crontab de servidor Splunk:
*/5 * * * * root root /path/to/pull-umbrella-logs.sh &2>1 >/var/log/pull-umbrella-logs.txt
Asegúrese de editar la línea para utilizar la ruta correcta al script. Esto ejecuta una sincronización cada cinco minutos. El directorio de almacenamiento S3 se actualiza cada 10 minutos y los datos permanecen en el almacenamiento S3 durante 30 días. Esto mantiene a los dos en sincronía.
Configurar Splunk para leer desde un directorio local
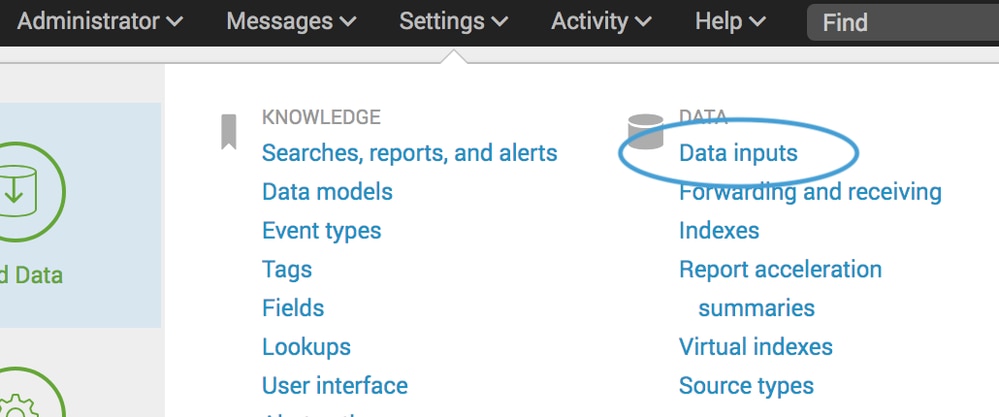
- En Splunk, navegue hasta Configuraciones > Entradas de datos > Archivos y directorios y seleccione Nuevo.
 360002731126
360002731126
 360002731146
360002731146
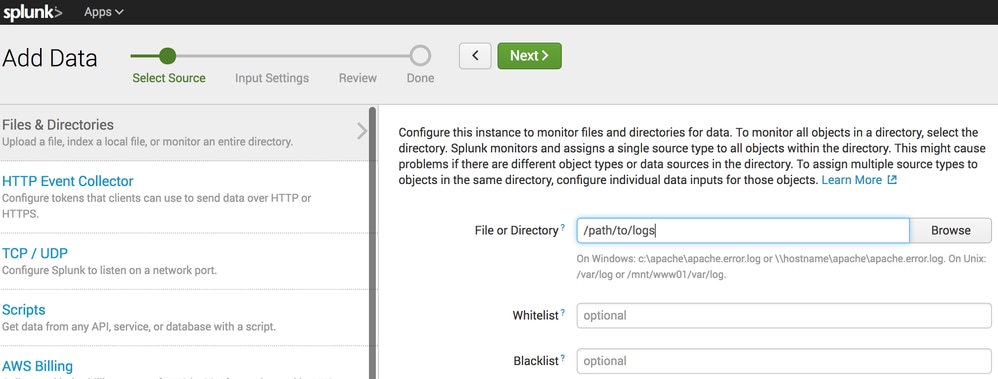
- En el campo Archivo o Directorio, especifique el directorio local donde la sincronización S3 coloca los archivos.
 360002731106
360002731106
- Haga clic en Next y complete el asistente con la configuración predeterminada.
Una vez que haya datos en el directorio local y se haya configurado Splunk, los datos pueden estar disponibles para consultar e informar sobre ellos en Splunk.

 Comentarios
Comentarios