Sustitución del servidor controlador UCS C240 M4 - CPAR
Opciones de descarga
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Contenido
Introducción
Este documento describe los pasos necesarios para reemplazar un servidor controlador defectuoso en una configuración Ultra-M.
Este procedimiento se aplica a un entorno Openstack que utiliza la versión NEWTON en la que Elastic Services Controller (ESC) no gestiona Cisco Prime Access Registrar (CPAR) y CPAR se instala directamente en la máquina virtual implementada en Openstack.
Antecedentes
Ultra-M es una solución de núcleo de paquetes móviles virtualizados previamente empaquetada y validada que se ha diseñado para simplificar la implementación de VNF. OpenStack es el Virtualized Infrastructure Manager (VIM) para Ultra-M y consta de los siguientes tipos de nodos:
- Informática
- Disco de almacenamiento de objetos - Informática (OSD - Informática)
- Controlador
- Plataforma OpenStack - Director (OSPD)
En esta imagen se muestra la arquitectura de alto nivel de Ultra-M y los componentes implicados:
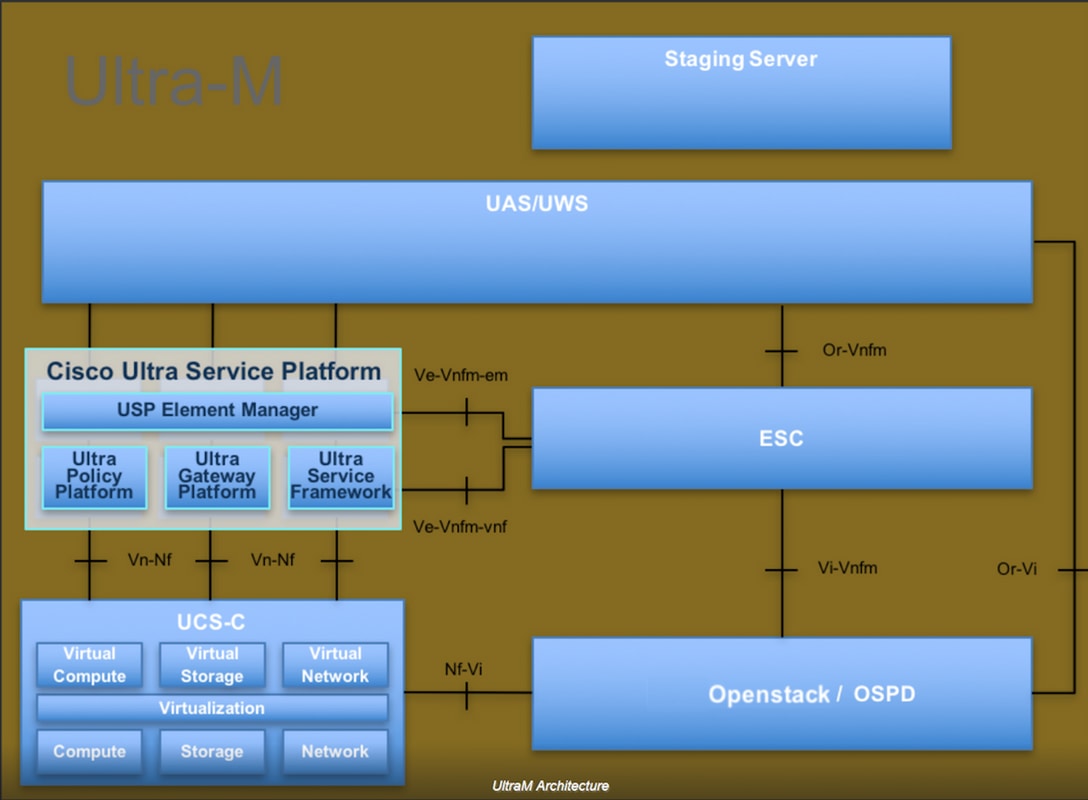
Este documento está dirigido al personal de Cisco que está familiarizado con la plataforma Cisco Ultra-M y detalla los pasos que se deben realizar en OpenStack y Redhat OS.
Nota: Se considera la versión Ultra M 5.1.x para definir los procedimientos en este documento.
Abreviaturas
| FREGAR | Método de procedimiento |
| OSD | Discos de almacenamiento de objetos |
| OSPD | Plataforma OpenStack - Director |
| HDD | Disco duro |
| SSD | Unidad de estado sólido |
| VIM | Administrador de infraestructura virtual |
| VM | Máquina virtual |
| EM | Administrador de elementos |
| UAS | Servicios de ultra automatización |
| UUID | Identificador único universal |
Flujo de trabajo del MOP
Esta imagen muestra el flujo de trabajo de alto nivel del procedimiento de reemplazo.

Prerequisites
Respaldo
En caso de recuperación, Cisco recomienda realizar una copia de seguridad de la base de datos OSPD (DB) con el uso de estos pasos:
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql
[root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql
/etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack
tar: Removing leading `/' from member names
Comprobación preliminar del estado
Es importante comprobar el estado actual del entorno y los servicios de OpenStack y asegurarse de que funcionan correctamente antes de continuar con el procedimiento de sustitución. Puede ayudar a evitar complicaciones en el momento del proceso de reemplazo de Controller.
Paso 1. Compruebe el estado de OpenStack y la lista de nodos:
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack stack list --nested
[stack@director ~]$ ironic node-list
[stack@director ~]$ nova list
Paso 2. Verifique el estado del marcapasos en los controladores:
Inicie sesión en uno de los controladores activos y compruebe el estado del marcapasos. Todos los servicios deben ejecutarse en los controladores disponibles y detenerse en el controlador con errores.
[stack@pod2-stack-controller-0 ~]# pcs status <snip> Online: [ pod2-stack-controller-0 pod2-stack-controller-1 ] Offline: [ pod2-stack-controller-2 ] Full list of resources: ip-11.120.0.109 (ocf::heartbeat:IPaddr2): Started pod2-stack-controller-0 ip-172.25.22.109 (ocf::heartbeat:IPaddr2): Started pod2-stack-controller-1 ip-192.200.0.107 (ocf::heartbeat:IPaddr2): Started pod2-stack-controller-0 Clone Set: haproxy-clone [haproxy] Started: [ pod2-stack-controller-0 pod2-stack-controller-1 ] Stopped: [ pod2-stack-controller-2 ] Master/Slave Set: galera-master [galera] Masters: [ pod2-stack-controller-0 pod2-stack-controller-1 ] Stopped: [ pod2-stack-controller-2 ] ip-11.120.0.110 (ocf::heartbeat:IPaddr2): Started pod2-stack-controller-0 ip-11.119.0.110 (ocf::heartbeat:IPaddr2): Started pod2-stack-controller-1 Clone Set: rabbitmq-clone [rabbitmq] Started: [ pod2-stack-controller-0 pod2-stack-controller-1 ] Stopped: [ pod2-stack-controller-2 ] Master/Slave Set: redis-master [redis] Masters: [ pod2-stack-controller-0 ] Slaves: [ pod2-stack-controller-1 ] Stopped: [ pod2-stack-controller-2 ] ip-11.118.0.104 (ocf::heartbeat:IPaddr2): Started pod2-stack-controller-1 openstack-cinder-volume (systemd:openstack-cinder-volume): Started pod2-stack-controller-0 my-ipmilan-for-controller-6 (stonith:fence_ipmilan): Started pod2-stack-controller-1 my-ipmilan-for-controller-4 (stonith:fence_ipmilan): Started pod2-stack-controller-0 my-ipmilan-for-controller-7 (stonith:fence_ipmilan): Started pod2-stack-controller-0 Failed Actions: Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
En este ejemplo, Controller-2 está desconectado. Por lo tanto, se sustituye. Controller-0 y Controller-1 están operativos y ejecutan los servicios de clúster.
Paso 3. Verifique el estado de MariaDB en los controladores activos:
[stack@director] nova list | grep control
| b896c73f-d2c8-439c-bc02-7b0a2526dd70 | pod2-stack-controller-0 | ACTIVE | - | Running | ctlplane=192.200.0.113 |
| 2519ce67-d836-4e5f-a672-1a915df75c7c | pod2-stack-controller-1 | ACTIVE | - | Running | ctlplane=192.200.0.105 |
[stack@director ~]$ for i in 192.200.0.113 192.200.0.105 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_state_comment'\" ; sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_cluster_size'\""; done
*** 192.200.0.113 ***
Variable_nameValue
wsrep_local_state_comment Synced
Variable_nameValue
wsrep_cluster_size 2
*** 192.200.0.105 ***
Variable_nameValue
wsrep_local_state_comment Synced
Variable_nameValue
wsrep_cluster_size 2
Verifique que estas líneas estén presentes para cada controlador activo:
wsrep_local_state_comment: Sincronizado
wsrep_cluster_size: 2
Steo 4. Compruebe el estado de Rabbitmq en los controladores activos. El controlador que ha fallado no debe aparecer en la lista de nodos que se ejecutan.
[heat-admin@pod2-stack-controller-0 ~] sudo rabbitmqctl cluster_status
Cluster status of node 'rabbit@pod2-stack-controller-0' ...
[{nodes,[{disc,['rabbit@pod2-stack-controller-0','rabbit@pod2-stack-controller-1',
'rabbit@pod2stack-controller-2']}]},
{running_nodes,['rabbit@pod2-stack-controller-1',
'rabbit@pod2-stack-controller-0']},
{cluster_name,<<"rabbit@pod2-stack-controller-2.localdomain">>},
{partitions,[]},
{alarms,[{'rabbit@pod2-stack-controller-1',[]},
{'rabbit@pod2-stack-controller-0',[]}]}]
[heat-admin@pod2-stack-controller-1 ~] sudo rabbitmqctl cluster_status
Cluster status of node 'rabbit@pod2-stack-controller-1' ...
[{nodes,[{disc,['rabbit@pod2-stack-controller-0','rabbit@pod2-stack-controller-1',
'rabbit@pod2-stack-controller-2']}]},
{running_nodes,['rabbit@pod2-stack-controller-0',
'rabbit@pod2-stack-controller-1']},
{cluster_name,<<"rabbit@pod2-stack-controller-2.localdomain">>},
{partitions,[]},
{alarms,[{'rabbit@pod2-stack-controller-0',[]},
{'rabbit@pod2-stack-controller-1',[]}]}]
Paso 5. Compruebe si todos los servicios en la nube están cargados, activos y en ejecución desde el nodo OSP-D.
[stack@director ~]$ systemctl list-units "openstack*" "neutron*" "openvswitch*"
UNIT LOAD ACTIVE SUB DESCRIPTION
neutron-dhcp-agent.service loaded active running OpenStack Neutron DHCP Agent
neutron-openvswitch-agent.service loaded active running OpenStack Neutron Open vSwitch Agent
neutron-ovs-cleanup.service loaded active exited OpenStack Neutron Open vSwitch Cleanup Utility
neutron-server.service loaded active running OpenStack Neutron Server
openstack-aodh-evaluator.service loaded active running OpenStack Alarm evaluator service
openstack-aodh-listener.service loaded active running OpenStack Alarm listener service
openstack-aodh-notifier.service loaded active running OpenStack Alarm notifier service
openstack-ceilometer-central.service loaded active running OpenStack ceilometer central agent
openstack-ceilometer-collector.service loaded active running OpenStack ceilometer collection service
openstack-ceilometer-notification.service loaded active running OpenStack ceilometer notification agent
openstack-glance-api.service loaded active running OpenStack Image Service (code-named Glance) API server
openstack-glance-registry.service loaded active running OpenStack Image Service (code-named Glance) Registry server
openstack-heat-api-cfn.service loaded active running Openstack Heat CFN-compatible API Service
openstack-heat-api.service loaded active running OpenStack Heat API Service
openstack-heat-engine.service loaded active running Openstack Heat Engine Service
openstack-ironic-api.service loaded active running OpenStack Ironic API service
openstack-ironic-conductor.service loaded active running OpenStack Ironic Conductor service
openstack-ironic-inspector-dnsmasq.service loaded active running PXE boot dnsmasq service for Ironic Inspector
openstack-ironic-inspector.service loaded active running Hardware introspection service for OpenStack Ironic
openstack-mistral-api.service loaded active running Mistral API Server
openstack-mistral-engine.service loaded active running Mistral Engine Server
openstack-mistral-executor.service loaded active running Mistral Executor Server
openstack-nova-api.service loaded active running OpenStack Nova API Server
openstack-nova-cert.service loaded active running OpenStack Nova Cert Server
openstack-nova-compute.service loaded active running OpenStack Nova Compute Server
openstack-nova-conductor.service loaded active running OpenStack Nova Conductor Server
openstack-nova-scheduler.service loaded active running OpenStack Nova Scheduler Server
openstack-swift-account-reaper.service loaded active running OpenStack Object Storage (swift) - Account Reaper
openstack-swift-account.service loaded active running OpenStack Object Storage (swift) - Account Server
openstack-swift-container-updater.service loaded active running OpenStack Object Storage (swift) - Container Updater
openstack-swift-container.service loaded active running OpenStack Object Storage (swift) - Container Server
openstack-swift-object-updater.service loaded active running OpenStack Object Storage (swift) - Object Updater
openstack-swift-object.service loaded active running OpenStack Object Storage (swift) - Object Server
openstack-swift-proxy.service loaded active running OpenStack Object Storage (swift) - Proxy Server
openstack-zaqar.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server
openstack-zaqar@1.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server Instance 1
openvswitch.service loaded active exited Open vSwitch
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
37 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
Deshabilitar la delimitación en el clúster de controladores
[root@pod2-stack-controller-0 ~]# sudo pcs property set stonith-enabled=false
[root@pod2-stack-controller-0 ~]# pcs property show
Cluster Properties:
cluster-infrastructure: corosync
cluster-name: tripleo_cluster
dc-version: 1.1.15-11.el7_3.4-e174ec8
have-watchdog: false
maintenance-mode: false
redis_REPL_INFO: pod2-stack-controller-2
stonith-enabled: false
Node Attributes:
pod2-stack-controller-0: rmq-node-attr-last-known-rabbitmq=rabbit@pod2-stack-controller-0
pod2-stack-controller-1: rmq-node-attr-last-known-rabbitmq=rabbit@pod2-stack-controller-1
pod2-stack-controller-2: rmq-node-attr-last-known-rabbitmq=rabbit@pod2-stack-controller-2
Instalación del nuevo nodo de controlador
Los pasos para instalar un nuevo servidor UCS C240 M4 y los pasos de configuración iniciales se pueden consultar en: Guía de instalación y servicio del servidor Cisco UCS C240 M4
Paso 1. Inicie sesión en el servidor con el uso de la IP de CIMC.
Paso 2. Realice la actualización del BIOS si el firmware no es conforme a la versión recomendada utilizada anteriormente. A continuación se indican los pasos para actualizar la BIOS: Guía de actualización del BIOS del servidor de montaje en bastidor Cisco UCS C-Series
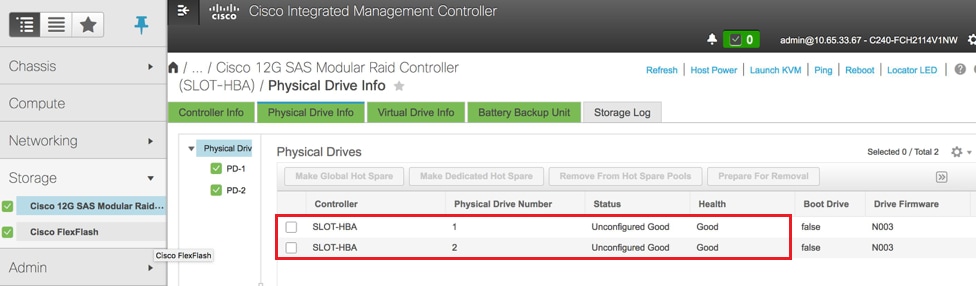
Paso 3. Para verificar el estado de las unidades físicas, que es Unconfigured Good, navegue hasta Storage > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Physical Drive Info, como se muestra en la imagen.
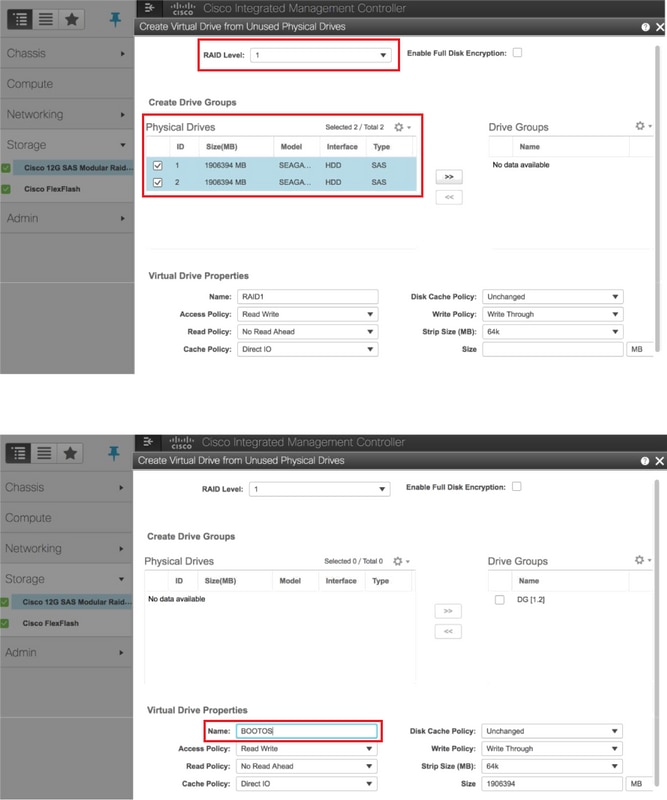
Paso 4. Para crear una unidad virtual a partir de las unidades físicas con el nivel RAID 1, navegue hasta Almacenamiento > Controlador RAID modular SAS 12G de Cisco (SLOT-HBA) > Información del controlador > Crear unidad virtual a partir de unidades físicas no utilizadas.
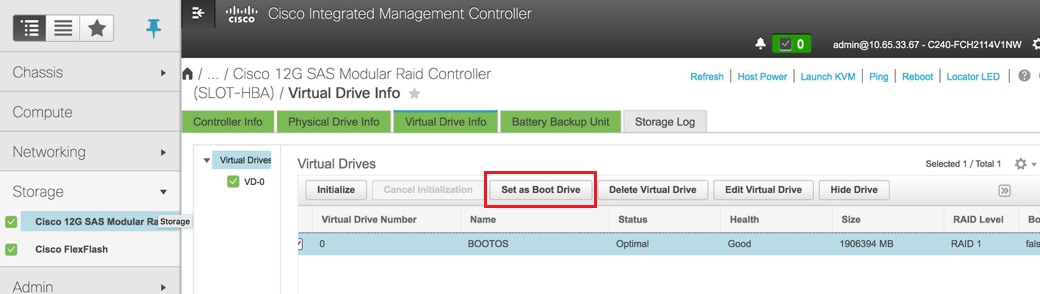
- Seleccione el VD y configureSet as Boot Drive:
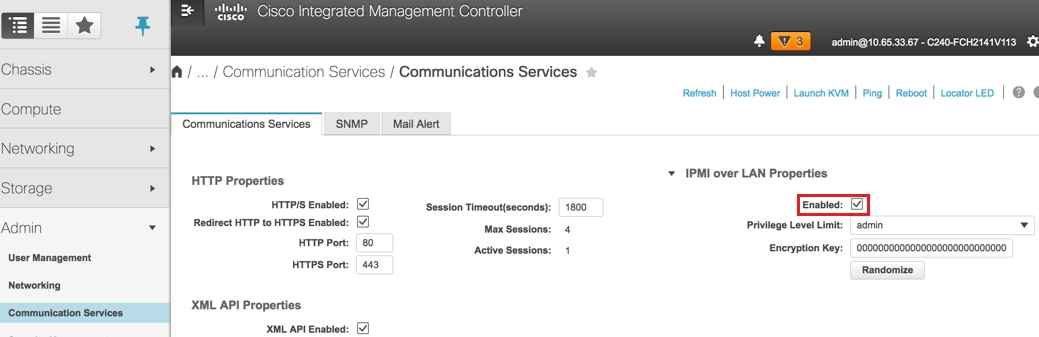
Paso 5. Para habilitar IPMI sobre LAN, navegue hasta Admin > Communication Services > Communication Services.
Paso 6. Para inhabilitar el hyperthreading, navegue hasta Compute > BIOS > Configure BIOS > Advanced > Processor Configuration.
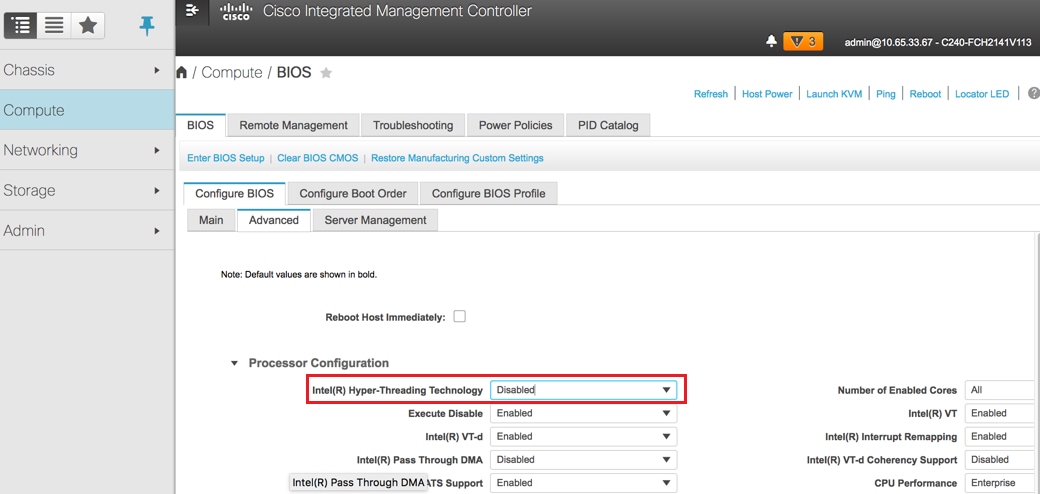
Nota: La imagen que se muestra aquí y los pasos de configuración mencionados en esta sección hacen referencia a la versión de firmware 3.0(3e) y puede haber ligeras variaciones si trabaja en otras versiones.
Sustitución del nodo del controlador en la nube excesiva
Esta sección cubre los pasos necesarios para reemplazar el controlador defectuoso por el nuevo en la nube. Para esto, el archivo deploy.shscript que se utilizó para activar la pila se reutilizaría. En el momento de la implementación, en la fase posterior a la implementación de nodos de controlador, la actualización fallaría debido a algunas limitaciones en los módulos de posición libre. Se requiere la intervención manual antes de reiniciar el script de implementación.
Preparación para Eliminar el Nodo de Controlador Fallido
Paso 1. Identifique el índice del controlador fallido. El índice es el sufijo numérico en el nombre del controlador en el resultado de la lista de servidores OpenStack. En este ejemplo, el índice es 2:
[stack@director ~]$ nova list | grep controller
| b896c73f-d2c8-439c-bc02-7b0a2526dd70 | pod2-stack-controller-0 | ACTIVE | - | Running | ctlplane=192.200.0.113 |
| 2519ce67-d836-4e5f-a672-1a915df75c7c | pod2-stack-controller-1 | ACTIVE | - | Running | ctlplane=192.200.0.105 |
| e19b9625-5635-4a52-a369-44310f3e6a21 | pod2-stack-controller-2 | ACTIVE | - | Running | ctlplane=192.200.0.120 |
Paso 2. Cree un archivo Yaml~templates/remove-controller.yamlque defina el nodo que desea eliminar. Utilice el índice encontrado en el paso anterior para la entrada de la lista de recursos:
[stack@director ~]$ cat templates/remove-controller.yaml
parameters:
ControllerRemovalPolicies:
[{'resource_list': [‘2’]}]
parameter_defaults:
CorosyncSettleTries: 5
Paso 3. Realice una copia del script de implementación que se utiliza para instalar la nube excesiva e inserte una línea para incluir el archivo remove-controller.yamlfile creado anteriormente:
[stack@director ~]$ cp deploy.sh deploy-removeController.sh
[stack@director ~]$ cat deploy-removeController.sh
time openstack overcloud deploy --templates \
-r ~/custom-templates/custom-roles.yaml \
-e /home/stack/templates/remove-controller.yaml \
-e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml \
-e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml \
-e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml \
-e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml \
-e ~/custom-templates/network.yaml \
-e ~/custom-templates/ceph.yaml \
-e ~/custom-templates/compute.yaml \
-e ~/custom-templates/layout-removeController.yaml \
-e ~/custom-templates/rabbitmq.yaml \
--stack pod2-stack \
--debug \
--log-file overcloudDeploy_$(date +%m_%d_%y__%H_%M_%S).log \
--neutron-flat-networks phys_pcie1_0,phys_pcie1_1,phys_pcie4_0,phys_pcie4_1 \
--neutron-network-vlan-ranges datacentre:101:200 \
--neutron-disable-tunneling \
--verbose --timeout 180
Paso 4. Identifique la ID del controlador a reemplazar, con el uso de los comandos mencionados aquí y muévala al modo de mantenimiento:
[stack@director ~]$ nova list | grep controller
| b896c73f-d2c8-439c-bc02-7b0a2526dd70 | pod2-stack-controller-0 | ACTIVE | - | Running | ctlplane=192.200.0.113 |
| 2519ce67-d836-4e5f-a672-1a915df75c7c | pod2-stack-controller-1 | ACTIVE | - | Running | ctlplane=192.200.0.105 |
| e19b9625-5635-4a52-a369-44310f3e6a21 | pod2-stack-controller-2 | ACTIVE | - | Running | ctlplane=192.200.0.120 |
[stack@director ~]$ openstack baremetal node list | grep e19b9625-5635-4a52-a369-44310f3e6a21
| e7c32170-c7d1-4023-b356-e98564a9b85b | None | e19b9625-5635-4a52-a369-44310f3e6a21 | power off | active | False |
[stack@b10-ospd ~]$ openstack baremetal node maintenance set e7c32170-c7d1-4023-b356-e98564a9b85b
[stack@director~]$ openstack baremetal node list | grep True
| e7c32170-c7d1-4023-b356-e98564a9b85b | None | e19b9625-5635-a369-44310f3e6a21 | power off | active | True |
Paso 5. Para asegurarse de que la BD se ejecuta en el momento del procedimiento de reemplazo, quite Galera del control del marcapasos y ejecute este comando en uno de los controladores activos:
[root@pod2-stack-controller-0 ~]# sudo pcs resource unmanage galera
[root@pod2-stack-controller-0 ~]# sudo pcs status Cluster name: tripleo_cluster Stack: corosync Current DC: pod2-stack-controller-0 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum Last updated: Thu Nov 16 16:51:18 2017 Last change: Thu Nov 16 16:51:12 2017 by root via crm_resource on pod2-stack-controller-0 3 nodes and 22 resources configured Online: [ pod2-stack-controller-0 pod2-stack-controller-1 ] OFFLINE: [ pod2-stack-controller-2 ] Full list of resources: ip-11.120.0.109 (ocf::heartbeat:IPaddr2): Started pod2-stack-controller-0 ip-172.25.22.109 (ocf::heartbeat:IPaddr2): Started pod2-stack-controller-1 ip-192.200.0.107 (ocf::heartbeat:IPaddr2): Started pod2-stack-controller-0 Clone Set: haproxy-clone [haproxy] Started: [ pod2-stack-controller-0 pod2-stack-controller-1 ] Stopped: [ pod2-stack-controller-2 ] Master/Slave Set: galera-master [galera] (unmanaged) galera (ocf::heartbeat:galera): Master pod2-stack-controller-0 (unmanaged) galera (ocf::heartbeat:galera): Master pod2-stack-controller-1 (unmanaged) Stopped: [ pod2-stack-controller-2 ] ip-11.120.0.110 (ocf::heartbeat:IPaddr2): Started pod2-stack-controller-0 ip-11.119.0.110 (ocf::heartbeat:IPaddr2): Started pod2-stack-controller-1 <snip>
Preparación para agregar un nuevo nodo de controlador
Paso 1. Cree un archivo acontrollerRMA.json sólo con los nuevos detalles del controlador. Asegúrese de que el número de índice del nuevo controlador no se haya utilizado antes. Normalmente, se incrementa al siguiente número de controlador más alto.
Ejemplo: El controlador anterior más alto era el controlador 2, así que cree el controlador 3.
Nota: Tenga en cuenta el formato json.
[stack@director ~]$ cat controllerRMA.json
{
"nodes": [
{
"mac": [
<MAC_ADDRESS>
],
"capabilities": "node:controller-3,boot_option:local",
"cpu": "24",
"memory": "256000",
"disk": "3000",
"arch": "x86_64",
"pm_type": "pxe_ipmitool",
"pm_user": "admin",
"pm_password": "<PASSWORD>",
"pm_addr": "<CIMC_IP>"
}
]
}
Paso 2. Importe el nuevo nodo con el uso del archivo json creado en el paso anterior:
[stack@director ~]$ openstack baremetal import --json controllerRMA.json
Started Mistral Workflow. Execution ID: 67989c8b-1225-48fe-ba52-3a45f366e7a0
Successfully registered node UUID 048ccb59-89df-4f40-82f5-3d90d37ac7dd
Started Mistral Workflow. Execution ID: c6711b5f-fa97-4c86-8de5-b6bc7013b398
Successfully set all nodes to available.
[stack@director ~]$ openstack baremetal node list | grep available
| 048ccb59-89df-4f40-82f5-3d90d37ac7dd | None | None | power off | available | False
Paso 3. Establezca el nodo para administrar el estado:
[stack@director ~]$ openstack baremetal node manage 048ccb59-89df-4f40-82f5-3d90d37ac7dd
[stack@director ~]$ openstack baremetal node list | grep off
| 048ccb59-89df-4f40-82f5-3d90d37ac7dd | None | None | power off | manageable | False |
Paso 4. Ejecute la introspección:
[stack@director ~]$ openstack overcloud node introspect 048ccb59-89df-4f40-82f5-3d90d37ac7dd --provide
Started Mistral Workflow. Execution ID: f73fb275-c90e-45cc-952b-bfc25b9b5727
Waiting for introspection to finish...
Successfully introspected all nodes.
Introspection completed.
Started Mistral Workflow. Execution ID: a892b456-eb15-4c06-b37e-5bc3f6c37c65
Successfully set all nodes to available
[stack@director ~]$ openstack baremetal node list | grep available
| 048ccb59-89df-4f40-82f5-3d90d37ac7dd | None | None | power off | available | False |
Paso 5. Marque el nodo disponible con las nuevas propiedades del controlador. Asegúrese de utilizar el ID de controlador designado para el nuevo controlador, como se utiliza en el archivo controllerRMA.json:
[stack@director ~]$ openstack baremetal node set --property capabilities='node:controller-3,profile:control,boot_option:local' 048ccb59-89df-4f40-82f5-3d90d37ac7dd
Paso 6. En el script de implementación, hay una plantilla personalizada llamada layout.yaml que, entre otras cosas, especifica qué direcciones IP se asignan a los controladores para las diversas interfaces. En una nueva pila, hay 3 direcciones definidas para Controller-0, Controller-1 y Controller-2. Cuando agregue un nuevo controlador, asegúrese de agregar una siguiente dirección IP en secuencia para cada subred:
ControllerIPs:
internal_api:
- 11.120.0.10
- 11.120.0.11
- 11.120.0.12
- 11.120.0.13
tenant:
- 11.117.0.10
- 11.117.0.11
- 11.117.0.12
- 11.117.0.13
storage:
- 11.118.0.10
- 11.118.0.11
- 11.118.0.12
- 11.118.0.13
storage_mgmt:
- 11.119.0.10
- 11.119.0.11
- 11.119.0.12
- 11.119.0.13
Paso 7. Ahora ejecute el archivo deploy-removecontroller.shque se creó anteriormente, para quitar el nodo antiguo y agregar el nuevo.
Nota: Se espera que este paso falle en ControllerNodesDeployment_Step1. En ese momento, se requiere la intervención manual.
[stack@b10-ospd ~]$ ./deploy-addController.sh
START with options: [u'overcloud', u'deploy', u'--templates', u'-r', u'/home/stack/custom-templates/custom-roles.yaml', u'-e', u'/usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml', u'-e', u'/usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml', u'-e', u'/usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml', u'-e', u'/usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml', u'-e', u'/home/stack/custom-templates/network.yaml', u'-e', u'/home/stack/custom-templates/ceph.yaml', u'-e', u'/home/stack/custom-templates/compute.yaml', u'-e', u'/home/stack/custom-templates/layout-removeController.yaml', u'-e', u'/home/stack/custom-templates/rabbitmq.yaml', u'--stack', u'newtonoc', u'--debug', u'--log-file', u'overcloudDeploy_11_15_17__07_46_35.log', u'--neutron-flat-networks', u'phys_pcie1_0,phys_pcie1_1,phys_pcie4_0,phys_pcie4_1', u'--neutron-network-vlan-ranges', u'datacentre:101:200', u'--neutron-disable-tunneling', u'--verbose', u'--timeout', u'180']
:
DeploymentError: Heat Stack update failed
END return value: 1
real 42m1.525s
user 0m3.043s
sys 0m0.614s
El progreso/estado de la implementación se puede monitorear con estos comandos:
[stack@director~]$ openstack stack list --nested | grep -iv complete
+--------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------------+----------------------+----------------------+--------------------------------------+
| ID | Stack Name | Stack Status | Creation Time | Updated Time | Parent |
+--------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------------+----------------------+----------------------+--------------------------------------+
| c1e338f2-877e-4817-93b4-9a3f0c0b3d37 | pod2-stack-AllNodesDeploySteps-5psegydpwxij-ComputeDeployment_Step1-swnuzjixac43 | UPDATE_FAILED | 2017-10-08T14:06:07Z | 2017-11-16T18:09:43Z | e90f00ef-2499-4ec3-90b4-d7def6e97c47 |
| 1db4fef4-45d3-4125-bd96-2cc3297a69ff | pod2-stack-AllNodesDeploySteps-5psegydpwxij-ControllerDeployment_Step1-hmn3hpruubcn | UPDATE_FAILED | 2017-10-08T14:03:05Z | 2017-11-16T18:12:12Z | e90f00ef-2499-4ec3-90b4-d7def6e97c47 |
| e90f00ef-2499-4ec3-90b4-d7def6e97c47 | pod2-stack-AllNodesDeploySteps-5psegydpwxij | UPDATE_FAILED | 2017-10-08T13:59:25Z | 2017-11-16T18:09:25Z | 6c4b604a-55a4-4a19-9141-28c844816c0d |
| 6c4b604a-55a4-4a19-9141-28c844816c0d | pod2-stack | UPDATE_FAILED | 2017-10-08T12:37:11Z | 2017-11-16T17:35:35Z | None |
+--------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------------+----------------------+----------------------+--------------------------------------+
Intervención manual
Paso 1. En el servidor OSP-D, ejecute el comando de lista de servidores OpenStack para enumerar los controladores disponibles. El controlador recién agregado debe aparecer en la lista:
[stack@director ~]$ openstack server list | grep controller-3
| 3e6c3db8-ba24-48d9-b0e8-1e8a2eb8b5ff | pod2-stack-controller-3 | ACTIVE | ctlplane=192.200.0.103 | overcloud-full |
Paso 2. Conéctese a uno de los controladores activos (no al controlador recién agregado) y mire el archivo/etc/corosync/corosycn.conf. Encuentre el endosque asigna anodeida cada controlador. Busque la entrada para el nodo fallido y observe itsnodeid:
[root@pod2-stack-controller-0 ~]# cat /etc/corosync/corosync.conf
totem {
version: 2
secauth: off
cluster_name: tripleo_cluster
transport: udpu
token: 10000
}
nodelist {
node {
ring0_addr: pod2-stack-controller-0
nodeid: 5
}
node {
ring0_addr: pod2-stack-controller-1
nodeid: 7
}
node {
ring0_addr: pod2-stack-controller-2
nodeid: 8
}
}
Paso 3. Inicie sesión en cada controlador activo. Quite el nodo con error y reinicie el servicio. En este caso, removepod2-stack-controller-2. No realice esta acción en el controlador recién agregado:
[root@pod2-stack-controller-0 ~]# sudo pcs cluster localnode remove pod2-stack-controller-2
pod2-stack-controller-2: successfully removed!
[root@pod2-stack-controller-0 ~]# sudo pcs cluster reload corosync
Corosync reloaded
[root@pod2-stack-controller-1 ~]# sudo pcs cluster localnode remove pod2-stack-controller-2
pod2-stack-controller-2: successfully removed!
[root@pod2-stack-controller-1 ~]# sudo pcs cluster reload corosync
Corosync reloaded
Paso 4. Ejecute este comando desde uno de los controladores activos para eliminar el nodo fallido del clúster:
[root@pod2-stack-controller-0 ~]# sudo crm_node -R pod2-stack-controller-2 --force
Paso 5. Ejecute este comando desde uno de los controladores activos para eliminar el nodo fallido de therabbitmqcluster:
[root@pod2-stack-controller-0 ~]# sudo rabbitmqctl forget_cluster_node rabbit@pod2-stack-controller-2
Removing node 'rabbit@newtonoc-controller-2' from cluster ...
Paso 6. Suprima el nodo fallido de MongoDB. Para hacer esto, debe encontrar el nodo Mongo activo. Usenetstatpara encontrar la dirección IP del host:
[root@pod2-stack-controller-0 ~]# sudo netstat -tulnp | grep 27017
tcp 0 0 11.120.0.10:27017 0.0.0.0:* LISTEN 219577/mongod
Paso 7. Inicie sesión en el nodo y verifique si es el maestro con el uso de la dirección IP y el número de puerto del comando anterior:
[heat-admin@pod2-stack-controller-0 ~]$ echo "db.isMaster()" | mongo --host 11.120.0.10:27017
MongoDB shell version: 2.6.11
connecting to: 11.120.0.10:27017/test
{
"setName" : "tripleo",
"setVersion" : 9,
"ismaster" : true,
"secondary" : false,
"hosts" : [
"11.120.0.10:27017",
"11.120.0.12:27017",
"11.120.0.11:27017"
],
"primary" : "11.120.0.10:27017",
"me" : "11.120.0.10:27017",
"electionId" : ObjectId("5a0d2661218cb0238b582fb1"),
"maxBsonObjectSize" : 16777216,
"maxMessageSizeBytes" : 48000000,
"maxWriteBatchSize" : 1000,
"localTime" : ISODate("2017-11-16T18:36:34.473Z"),
"maxWireVersion" : 2,
"minWireVersion" : 0,
"ok" : 1
}
Si el nodo no es el principal, inicie sesión en el otro controlador activo y realice el mismo paso.
Paso 1. Desde el maestro, enumere los nodos disponibles con el uso del comando thers.status(). Busque el nodo antiguo o que no responde e identifique el nombre del nodo mongo.
[root@pod2-stack-controller-0 ~]# mongo --host 11.120.0.10
MongoDB shell version: 2.6.11
connecting to: 11.120.0.10:27017/test
<snip>
tripleo:PRIMARY> rs.status()
{
"set" : "tripleo",
"date" : ISODate("2017-11-14T13:27:14Z"),
"myState" : 1,
"members" : [
{
"_id" : 0,
"name" : "11.120.0.10:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 418347,
"optime" : Timestamp(1510666033, 1),
"optimeDate" : ISODate("2017-11-14T13:27:13Z"),
"electionTime" : Timestamp(1510247693, 1),
"electionDate" : ISODate("2017-11-09T17:14:53Z"),
"self" : true
},
{
"_id" : 2,
"name" : "11.120.0.12:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 418347,
"optime" : Timestamp(1510666033, 1),
"optimeDate" : ISODate("2017-11-14T13:27:13Z"),
"lastHeartbeat" : ISODate("2017-11-14T13:27:13Z"),
"lastHeartbeatRecv" : ISODate("2017-11-14T13:27:13Z"),
"pingMs" : 0,
"syncingTo" : "11.120.0.10:27017"
},
{
"_id" : 3,
"name" : "11.120.0.11:27017
"health" : 0,
"state" : 8,
"stateStr" : "(not reachable/healthy)",
"uptime" : 0,
"optime" : Timestamp(1510610580, 1),
"optimeDate" : ISODate("2017-11-13T22:03:00Z"),
"lastHeartbeat" : ISODate("2017-11-14T13:27:10Z"),
"lastHeartbeatRecv" : ISODate("2017-11-13T22:03:01Z"),
"pingMs" : 0,
"syncingTo" : "11.120.0.10:27017"
}
],
"ok" : 1
}
Paso 2. Desde el maestro, elimine el nodo fallido con el uso de thers.removecommand. Se observan algunos errores al ejecutar este comando, pero verifique el estado una vez más para encontrar que el nodo ha sido eliminado:
[root@pod2-stack-controller-0 ~]$ mongo --host 11.120.0.10
<snip>
tripleo:PRIMARY> rs.remove('11.120.0.12:27017')
2017-11-16T18:41:04.999+0000 DBClientCursor::init call() failed
2017-11-16T18:41:05.000+0000 Error: error doing query: failed at src/mongo/shell/query.js:81
2017-11-16T18:41:05.001+0000 trying reconnect to 11.120.0.10:27017 (11.120.0.10) failed
2017-11-16T18:41:05.003+0000 reconnect 11.120.0.10:27017 (11.120.0.10) ok
tripleo:PRIMARY> rs.status()
{
"set" : "tripleo",
"date" : ISODate("2017-11-16T18:44:11Z"),
"myState" : 1,
"members" : [
{
"_id" : 3,
"name" : "11.120.0.11:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 187,
"optime" : Timestamp(1510857848, 3),
"optimeDate" : ISODate("2017-11-16T18:44:08Z"),
"lastHeartbeat" : ISODate("2017-11-16T18:44:11Z"),
"lastHeartbeatRecv" : ISODate("2017-11-16T18:44:09Z"),
"pingMs" : 0,
"syncingTo" : "11.120.0.10:27017"
},
{
"_id" : 4,
"name" : "11.120.0.10:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 89820,
"optime" : Timestamp(1510857848, 3),
"optimeDate" : ISODate("2017-11-16T18:44:08Z"),
"electionTime" : Timestamp(1510811232, 1),
"electionDate" : ISODate("2017-11-16T05:47:12Z"),
"self" : true
}
],
"ok" : 1
}
tripleo:PRIMARY> exit
bye
Paso 3. Ejecute este comando para actualizar la lista de nodos del controlador activo. Incluya el nuevo nodo de controlador en esta lista:
[root@pod2-stack-controller-0 ~]# sudo pcs resource update galera wsrep_cluster_address=gcomm://pod2-stack-controller-0,pod2-stack-controller-1,pod2-stack-controller-2
Paso 4. Copie estos archivos de un controlador que ya existe al nuevo controlador:
/etc/sysconfig/clustercheck
/root/.my.cnf
On existing controller:
[root@pod2-stack-controller-0 ~]# scp /etc/sysconfig/clustercheck stack@192.200.0.1:/tmp/.
[root@pod2-stack-controller-0 ~]# scp /root/.my.cnf stack@192.200.0.1:/tmp/my.cnf
On new controller:
[root@pod2-stack-controller-3 ~]# cd /etc/sysconfig
[root@pod2-stack-controller-3 sysconfig]# scp stack@192.200.0.1:/tmp/clustercheck .
[root@pod2-stack-controller-3 sysconfig]# cd /root
[root@pod2-stack-controller-3 ~]# scp stack@192.200.0.1:/tmp/my.cnf .my.cnf
Paso 5. Ejecute el comando cluster node addcommand desde uno de los controladores que ya existe:
[root@pod2-stack-controller-1 ~]# sudo pcs cluster node add pod2-stack-controller-3
Disabling SBD service...
pod2-stack-controller-3: sbd disabled
pod2-stack-controller-0: Corosync updated
pod2-stack-controller-1: Corosync updated
Setting up corosync...
pod2-stack-controller-3: Succeeded
Synchronizing pcsd certificates on nodes pod2-stack-controller-3...
pod2-stack-controller-3: Success
Restarting pcsd on the nodes in order to reload the certificates...
pod2-stack-controller-3: Success
Paso 6. Inicie sesión en cada controlador y vea el archivo/etc/corosync/corosync.conf. Asegúrese de que el nuevo controlador aparezca en la lista y de que el nodo asignado a ese controlador sea el siguiente número en la secuencia que no se haya utilizado previamente. Asegúrese de que este cambio se realice en los 3 controladores:
[root@pod2-stack-controller-1 ~]# cat /etc/corosync/corosync.conf
totem {
version: 2
secauth: off
cluster_name: tripleo_cluster
transport: udpu
token: 10000
}
nodelist {
node {
ring0_addr: pod2-stack-controller-0
nodeid: 5
}
node {
ring0_addr: pod2-stack-controller-1
nodeid: 7
}
node {
ring0_addr: pod2-stack-controller-3
nodeid: 6
}
}
quorum {
provider: corosync_votequorum
}
logging {
to_logfile: yes
logfile: /var/log/cluster/corosync.log
to_syslog: yes
}
Por ejemplo/etc/corosync/corosync.confafter modification:
totem {
version: 2
secauth: off
cluster_name: tripleo_cluster
transport: udpu
token: 10000
}
nodelist {
node {
ring0_addr: pod2-stack-controller-0
nodeid: 5
}
node {
ring0_addr: pod2-stack-controller-1
nodeid: 7
}
node {
ring0_addr: pod2-stack-controller-3
nodeid: 9
}
}
quorum {
provider: corosync_votequorum
}
logging {
to_logfile: yes
logfile: /var/log/cluster/corosync.log
to_syslog: yes
}
Paso 7. Reinicie corosyncon los controladores activos. No inicie corosyncon el nuevo controlador:
[root@pod2-stack-controller-0 ~]# sudo pcs cluster reload corosync
[root@pod2-stack-controller-1 ~]# sudo pcs cluster reload corosync
Paso 8. Inicie el nuevo nodo de controlador desde uno de los controladores que actúan:
[root@pod2-stack-controller-1 ~]# sudo pcs cluster start pod2-stack-controller-3
Paso 9. Reinicie Galera desde uno de los controladores que actúan:
[root@pod2-stack-controller-1 ~]# sudo pcs cluster start pod2-stack-controller-3
pod2-stack-controller-0: Starting Cluster...
[root@pod2-stack-controller-1 ~]# sudo pcs resource cleanup galera
Cleaning up galera:0 on pod2-stack-controller-0, removing fail-count-galera
Cleaning up galera:0 on pod2-stack-controller-1, removing fail-count-galera
Cleaning up galera:0 on pod2-stack-controller-3, removing fail-count-galera
* The configuration prevents the cluster from stopping or starting 'galera-master' (unmanaged)
Waiting for 3 replies from the CRMd... OK
[root@pod2-stack-controller-1 ~]#
[root@pod2-stack-controller-1 ~]# sudo pcs resource manage galera
Paso 10. El cluster está en modo de mantenimiento. Inhabilite el modo de mantenimiento para que los servicios comiencen:
[root@pod2-stack-controller-2 ~]# sudo pcs property set maintenance-mode=false --wait
Paso 11. Verifique el estado de los PC para Galera hasta que los 3 controladores estén listados como maestros en Galera:
Nota: En el caso de configuraciones grandes, la sincronización de las bases de datos puede tardar algún tiempo.
[root@pod2-stack-controller-1 ~]# sudo pcs status | grep galera -A1
Master/Slave Set: galera-master [galera]
Masters: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-3 ]
Paso 12. Cambie el clúster al modo de mantenimiento:
[root@pod2-stack-controller-1~]# sudo pcs property set maintenance-mode=true --wait
[root@pod2-stack-controller-1 ~]# pcs cluster status
Cluster Status:
Stack: corosync
Current DC: pod2-stack-controller-0 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Thu Nov 16 19:17:01 2017 Last change: Thu Nov 16 19:16:48 2017 by root via cibadmin on pod2-stack-controller-1
*** Resource management is DISABLED ***
The cluster will not attempt to start, stop or recover services
PCSD Status:
pod2-stack-controller-3: Online
pod2-stack-controller-0: Online
pod2-stack-controller-1: Online
Paso 13. Vuelva a ejecutar el archivo de comandos de implementación que ejecutó anteriormente. Esta vez debería tener éxito.
[stack@director ~]$ ./deploy-addController.sh
START with options: [u'overcloud', u'deploy', u'--templates', u'-r', u'/home/stack/custom-templates/custom-roles.yaml', u'-e', u'/usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml', u'-e', u'/usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml', u'-e', u'/usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml', u'-e', u'/usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml', u'-e', u'/home/stack/custom-templates/network.yaml', u'-e', u'/home/stack/custom-templates/ceph.yaml', u'-e', u'/home/stack/custom-templates/compute.yaml', u'-e', u'/home/stack/custom-templates/layout-removeController.yaml', u'--stack', u'newtonoc', u'--debug', u'--log-file', u'overcloudDeploy_11_14_17__13_53_12.log', u'--neutron-flat-networks', u'phys_pcie1_0,phys_pcie1_1,phys_pcie4_0,phys_pcie4_1', u'--neutron-network-vlan-ranges', u'datacentre:101:200', u'--neutron-disable-tunneling', u'--verbose', u'--timeout', u'180']
options: Namespace(access_key='', access_secret='***', access_token='***', access_token_endpoint='', access_token_type='', aodh_endpoint='', auth_type='', auth_url='https://192.200.0.2:13000/v2.0', authorization_code='', cacert=None, cert='', client_id='', client_secret='***', cloud='', consumer_key='', consumer_secret='***', debug=True, default_domain='default', default_domain_id='', default_domain_name='', deferred_help=False, discovery_endpoint='', domain_id='', domain_name='', endpoint='', identity_provider='', identity_provider_url='', insecure=None, inspector_api_version='1', inspector_url=None, interface='', key='', log_file=u'overcloudDeploy_11_14_17__13_53_12.log', murano_url='', old_profile=None, openid_scope='', os_alarming_api_version='2', os_application_catalog_api_version='1', os_baremetal_api_version='1.15', os_beta_command=False, os_compute_api_version='', os_container_infra_api_version='1', os_data_processing_api_version='1.1', os_data_processing_url='', os_dns_api_version='2', os_identity_api_version='', os_image_api_version='1', os_key_manager_api_version='1', os_metrics_api_version='1', os_network_api_version='', os_object_api_version='', os_orchestration_api_version='1', os_project_id=None, os_project_name=None, os_queues_api_version='2', os_tripleoclient_api_version='1', os_volume_api_version='', os_workflow_api_version='2', passcode='', password='***', profile=None, project_domain_id='', project_domain_name='', project_id='', project_name='admin', protocol='', redirect_uri='', region_name='', roles='', timing=False, token='***', trust_id='', url='', user='', user_domain_id='', user_domain_name='', user_id='', username='admin', verbose_level=3, verify=None)
Auth plugin password selected
Starting new HTTPS connection (1): 192.200.0.2
"POST /v2/action_executions HTTP/1.1" 201 1696
HTTP POST https://192.200.0.2:13989/v2/action_executions 201
Overcloud Endpoint: http://172.25.22.109:5000/v2.0
Overcloud Deployed
clean_up DeployOvercloud:
END return value: 0
real 54m17.197s
user 0m3.421s
sys 0m0.670s
Verificar servicios en la nube en el controlador
Asegúrese de que todos los servicios administrados se ejecuten correctamente en los nodos del controlador.
[heat-admin@pod2-stack-controller-2 ~]$ sudo pcs status
Finalización de los routers del agente L3
Verifique los routers para asegurarse de que los agentes L3 estén alojados correctamente. Asegúrese de crear el origen del archivo overcloudrc cuando realice esta comprobación.
Paso 1. Busque el nombre del router:
[stack@director~]$ source corerc
[stack@director ~]$ neutron router-list
+--------------------------------------+------+-------------------------------------------------------------------+-------------+------+
| id | name | external_gateway_info | distributed | ha |
+--------------------------------------+------+-------------------------------------------------------------------+-------------+------+
| d814dc9d-2b2f-496f-8c25-24911e464d02 | main | {"network_id": "18c4250c-e402-428c-87d6-a955157d50b5", | False | True |
En este ejemplo, el nombre del router es main.
Paso 2. Enumere todos los agentes L3 para encontrar el UUID del nodo fallido y el nuevo nodo:
[stack@director ~]$ neutron agent-list | grep "neutron-l3-agent"
| 70242f5c-43ab-4355-abd6-9277f92e4ce6 | L3 agent | pod2-stack-controller-0.localdomain | nova | :-) | True | neutron-l3-agent |
| 8d2ffbcb-b6ff-42cd-b5b8-da31d8da8a40 | L3 agent | pod2-stack-controller-2.localdomain | nova | xxx | True | neutron-l3-agent |
| a410a491-e271-4938-8a43-458084ffe15d | L3 agent | pod2-stack-controller-3.localdomain | nova | :-) | True | neutron-l3-agent |
| cb4bc1ad-ac50-42e9-ae69-8a256d375136 | L3 agent | pod2-stack-controller-1.localdomain | nova | :-) | True | neutron-l3-agent |
En este ejemplo, el agente L3 que corresponde a pod2-stack-controller-2.localdomaindebe eliminarse del router y el que corresponde a pod2-stack-controller-3.localdomaindebe agregarse al router:
[stack@director ~]$ neutron l3-agent-router-remove 8d2ffbcb-b6ff-42cd-b5b8-da31d8da8a40 main
Removed router main from L3 agent
[stack@director ~]$ neutron l3-agent-router-add a410a491-e271-4938-8a43-458084ffe15d main
Added router main to L3 agent
Paso 3. Compruebe la lista actualizada de agentes L3:
[stack@director ~]$ neutron l3-agent-list-hosting-router main
+--------------------------------------+-----------------------------------+----------------+-------+----------+
| id | host | admin_state_up | alive | ha_state |
+--------------------------------------+-----------------------------------+----------------+-------+----------+
| 70242f5c-43ab-4355-abd6-9277f92e4ce6 | pod2-stack-controller-0.localdomain | True | :-) | standby |
| a410a491-e271-4938-8a43-458084ffe15d | pod2-stack-controller-3.localdomain | True | :-) | standby |
| cb4bc1ad-ac50-42e9-ae69-8a256d375136 | pod2-stack-controller-1.localdomain | True | :-) | active |
+--------------------------------------+-----------------------------------+----------------+-------+----------+
Paso 4. Enumere los servicios que se ejecutan desde el nodo de controlador eliminado y elimínelos:
[stack@director ~]$ neutron agent-list | grep controller-2
| 877314c2-3c8d-4666-a6ec-69513e83042d | Metadata agent | pod2-stack-controller-2.localdomain | | xxx | True | neutron-metadata-agent |
| 8d2ffbcb-b6ff-42cd-b5b8-da31d8da8a40 | L3 agent | pod2-stack-controller-2.localdomain | nova | xxx | True | neutron-l3-agent |
| 911c43a5-df3a-49ec-99ed-1d722821ec20 | DHCP agent | pod2-stack-controller-2.localdomain | nova | xxx | True | neutron-dhcp-agent |
| a58a3dd3-4cdc-48d4-ab34-612a6cd72768 | Open vSwitch agent | pod2-stack-controller-2.localdomain | | xxx | True | neutron-openvswitch-agent |
[stack@director ~]$ neutron agent-delete 877314c2-3c8d-4666-a6ec-69513e83042d
Deleted agent(s): 877314c2-3c8d-4666-a6ec-69513e83042d
[stack@director ~]$ neutron agent-delete 8d2ffbcb-b6ff-42cd-b5b8-da31d8da8a40
Deleted agent(s): 8d2ffbcb-b6ff-42cd-b5b8-da31d8da8a40
[stack@director ~]$ neutron agent-delete 911c43a5-df3a-49ec-99ed-1d722821ec20
Deleted agent(s): 911c43a5-df3a-49ec-99ed-1d722821ec20
[stack@director ~]$ neutron agent-delete a58a3dd3-4cdc-48d4-ab34-612a6cd72768
Deleted agent(s): a58a3dd3-4cdc-48d4-ab34-612a6cd72768
[stack@director ~]$ neutron agent-list | grep controller-2
[stack@director ~]$
Finalización de servicios informáticos
Paso 1. Checknova service-list items left from the remove node and delete them:
[stack@director ~]$ nova service-list | grep controller-2
| 615 | nova-consoleauth | pod2-stack-controller-2.localdomain | internal | enabled | down | 2017-11-16T16:08:14.000000 | - |
| 618 | nova-scheduler | pod2-stack-controller-2.localdomain | internal | enabled | down | 2017-11-16T16:08:13.000000 | - |
| 621 | nova-conductor | pod2-stack-controller-2.localdomain | internal | enabled | down | 2017-11-16T16:08:14.000000 | -
[stack@director ~]$ nova service-delete 615
[stack@director ~]$ nova service-delete 618
[stack@director ~]$ nova service-delete 621
stack@director ~]$ nova service-list | grep controller-2
Paso 2. Asegúrese de que consoleauthprocess se ejecute en todos los controladores o reinícielo con el uso de este comando:pcs resource restart openstack-nova-consoleauth:
[stack@director ~]$ nova service-list | grep consoleauth
| 601 | nova-consoleauth | pod2-stack-controller-0.localdomain | internal | enabled | up | 2017-11-16T21:00:10.000000 | - |
| 608 | nova-consoleauth | pod2-stack-controller-1.localdomain | internal | enabled | up | 2017-11-16T21:00:13.000000 | - |
| 622 | nova-consoleauth | pod2-stack-controller-3.localdomain | internal | enabled | up | 2017-11-16T21:00:13.000000 | -
Reinicie la delimitación en los nodos del controlador
Paso 1. Verifique todos los controladores para la ruta IP a la nube subyacente 192.0.0.0/8:
[root@pod2-stack-controller-3 ~]# ip route
default via 10.225.247.203 dev vlan101
10.225.247.128/25 dev vlan101 proto kernel scope link src 10.225.247.212
11.117.0.0/24 dev vlan17 proto kernel scope link src 11.117.0.10
11.118.0.0/24 dev vlan18 proto kernel scope link src 11.118.0.10
11.119.0.0/24 dev vlan19 proto kernel scope link src 11.119.0.10
11.120.0.0/24 dev vlan20 proto kernel scope link src 11.120.0.10
169.254.169.254 via 192.200.0.1 dev eno1
192.200.0.0/24 dev eno1 proto kernel scope link src 192.200.0.113
Paso 2. Verifique la configuración de stonithactual. Elimine cualquier referencia al nodo de controlador anterior:
[root@pod2-stack-controller-3 ~]# sudo pcs stonith show --full
Resource: my-ipmilan-for-controller-6 (class=stonith type=fence_ipmilan)
Attributes: pcmk_host_list=pod2-stack-controller-1 ipaddr=192.100.0.1 login=admin passwd=Csco@123Starent lanplus=1
Operations: monitor interval=60s (my-ipmilan-for-controller-6-monitor-interval-60s)
Resource: my-ipmilan-for-controller-4 (class=stonith type=fence_ipmilan)
Attributes: pcmk_host_list=pod2-stack-controller-0 ipaddr=192.100.0.14 login=admin passwd=Csco@123Starent lanplus=1
Operations: monitor interval=60s (my-ipmilan-for-controller-4-monitor-interval-60s)
Resource: my-ipmilan-for-controller-7 (class=stonith type=fence_ipmilan)
Attributes: pcmk_host_list=pod2-stack-controller-2 ipaddr=192.100.0.15 login=admin passwd=Csco@123Starent lanplus=1
Operations: monitor interval=60s (my-ipmilan-for-controller-7-monitor-interval-60s)
[root@pod2-stack-controller-3 ~]# pcs stonith delete my-ipmilan-for-controller-7
Attempting to stop: my-ipmilan-for-controller-7...Stopped
Paso 3. Addstonithconfiguration para el nuevo controlador:
[root@pod2-stack-controller-3 ~]sudo pcs stonith create my-ipmilan-for-controller-8 fence_ipmilan pcmk_host_list=pod2-stack-controller-3 ipaddr=<CIMC_IP> login=admin passwd=<PASSWORD> lanplus=1 op monitor interval=60s
Paso 4. Reinicie la delimitación desde cualquier controlador y verifique el estado:
[root@pod2-stack-controller-1 ~]# sudo pcs property set stonith-enabled=true
[root@pod2-stack-controller-3 ~]# pcs status
<snip>
my-ipmilan-for-controller-1 (stonith:fence_ipmilan): Started pod2-stack-controller-3
my-ipmilan-for-controller-0 (stonith:fence_ipmilan): Started pod2-stack-controller-3
my-ipmilan-for-controller-3 (stonith:fence_ipmilan): Started pod2-stack-controller-3
Con la colaboración de ingenieros de Cisco
- Karthikeyan DachanamoorthyCisco Advance Services
- Harshita BhardwajCisco Advance Services
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)