Handle-Fehler beider Boot-Laufwerke auf UCS 240M4-Server - vEPC
Download-Optionen
-
ePub (208.2 KB)
In verschiedenen Apps auf iPhone, iPad, Android, Sony Reader oder Windows Phone anzeigen
Inklusive Sprache
In dem Dokumentationssatz für dieses Produkt wird die Verwendung inklusiver Sprache angestrebt. Für die Zwecke dieses Dokumentationssatzes wird Sprache als „inklusiv“ verstanden, wenn sie keine Diskriminierung aufgrund von Alter, körperlicher und/oder geistiger Behinderung, Geschlechtszugehörigkeit und -identität, ethnischer Identität, sexueller Orientierung, sozioökonomischem Status und Intersektionalität impliziert. Dennoch können in der Dokumentation stilistische Abweichungen von diesem Bemühen auftreten, wenn Text verwendet wird, der in Benutzeroberflächen der Produktsoftware fest codiert ist, auf RFP-Dokumentation basiert oder von einem genannten Drittanbieterprodukt verwendet wird. Hier erfahren Sie mehr darüber, wie Cisco inklusive Sprache verwendet.
Informationen zu dieser Übersetzung
Cisco hat dieses Dokument maschinell übersetzen und von einem menschlichen Übersetzer editieren und korrigieren lassen, um unseren Benutzern auf der ganzen Welt Support-Inhalte in ihrer eigenen Sprache zu bieten. Bitte beachten Sie, dass selbst die beste maschinelle Übersetzung nicht so genau ist wie eine von einem professionellen Übersetzer angefertigte. Cisco Systems, Inc. übernimmt keine Haftung für die Richtigkeit dieser Übersetzungen und empfiehlt, immer das englische Originaldokument (siehe bereitgestellter Link) heranzuziehen.
Inhalt
Einleitung
In diesem Dokument werden die Schritte beschrieben, die erforderlich sind, um in einem Ultra-M-Setup, das StarOS Virtual Network Functions (VNFs) hostet, beide fehlerhaften Festplatten im Server auszutauschen.
Hintergrundinformationen
Ultra-M ist eine vorkonfigurierte und validierte virtualisierte Mobile Packet Core-Lösung zur Vereinfachung der Bereitstellung von VNFs. OpenStack ist der Virtualized Infrastructure Manager (VIM) für Ultra-M und besteht aus den folgenden Knotentypen:
- Computing
- Objektspeicherplatte - Computing (OSD - Computing)
- Controller
- OpenStack-Plattform - Director (OSPD)
Die High-Level-Architektur von Ultra-M und die beteiligten Komponenten sind in diesem Bild dargestellt:
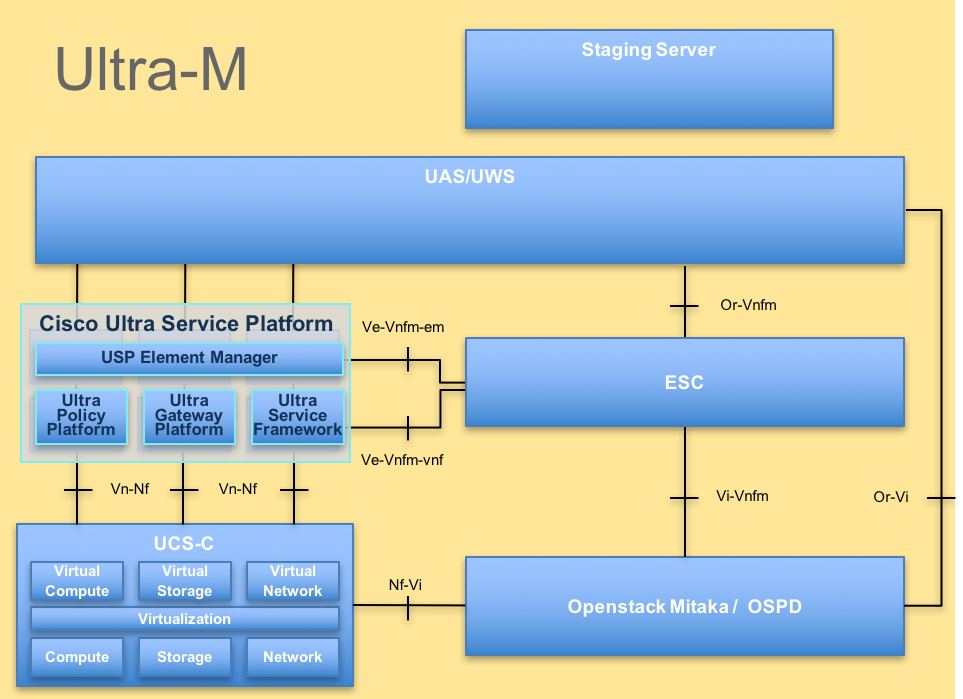 UltraM-Architektur
UltraM-Architektur
Dieses Dokument richtet sich an Cisco Mitarbeiter, die mit der Cisco Ultra-M-Plattform vertraut sind. Es beschreibt die erforderlichen Schritte, die auf OpenStack- und StarOS VNF-Ebene zum Zeitpunkt des Controller-Server-Austauschs durchgeführt werden müssen.
Anmerkung: Die Ultra M 5.1.x-Version wird bei der Definition der in diesem Dokument beschriebenen Verfahren berücksichtigt.
Abkürzungen
| VNF | Virtuelle Netzwerkfunktion |
| KF | Kontrollfunktion |
| SF | Dienstfunktion |
| WSA | Elastischer Service-Controller |
| MOPP | Verfahrensweise |
| OSD | Objektspeicherplatten |
| Festplatte | Festplattenlaufwerk |
| SSD | Solid-State-Laufwerk |
| VIM | Manager für virtuelle Infrastruktur |
| VM | Virtuelles System |
| EM | Element-Manager |
| USA | Ultra-Automatisierungsservices |
| UUID | Universeller eindeutiger IDentifier |
Ausfall beider HDDs
Jeder Bare-Metal-Server wird mit zwei Festplattenlaufwerken ausgestattet, um in der RAID-1-Konfiguration als BOOT-DISK fungieren zu können. Bei Ausfall einer einzelnen Festplatte kann aufgrund der Redundanz auf RAID-1-Ebene die fehlerhafte Festplatte im laufenden Betrieb ausgetauscht werden. Wenn jedoch beide HDDs ausfallen, ist der Server ausgefallen, und Sie verlieren den Zugriff auf den Server. Um den Zugriff auf den Server und die Dienste wiederherzustellen, ist es erforderlich, um beide Festplatten auszutauschen und den Server dem vorhandenen Overcloud-Stack hinzuzufügen.
Auf das Verfahren zum Ersetzen einer fehlerhaften Komponente auf dem UCS C240 M4-Server kann verwiesen werden von Ersetzen der Serverkomponenten.
Wenn beide HDDs ausfallen, ersetzen Sie nur diese beiden fehlerhaften HDDs im gleichen UCS 240M4-Server. Das BIOS-Upgrade-Verfahren ist nach dem Austausch neuer Festplatten nicht mehr erforderlich.
In einer OpenStack-basierten Ultra-M-Lösung übernimmt der UCS 240M4 Bare-Metal-Server eine der folgenden Rollen: Compute, OSD-Compute, Controller oder OSPD. In diesen Abschnitten werden die erforderlichen Schritte zur Behandlung von Festplattenausfällen in jeder dieser Serverrollen beschrieben.
Anmerkung: In Szenarien, in denen beide HDDs fehlerfrei sind, aber eine andere Hardware im UCS 240M4-Server defekt ist, ersetzen Sie den UCS 240M4 durch die neue Hardware. Verwenden Sie jedoch dieselben HDDs erneut. In diesem Fall sind nur die Festplatten fehlerhaft. Verwenden Sie daher denselben UCS 240M4 erneut, und ersetzen Sie die fehlerhaften Festplatten durch neue Festplatten.
Ausfall beider HDDs auf Compute Server
Wenn der Ausfall beider HDDs beim UCS 240M4 beobachtet wird, der als Rechenknoten fungiert, befolgen Sie das Austauschverfahren gemäß dem Compute Server Replacement Procedure.
Ausfall beider HDDs auf Controller-Server
Wenn der Ausfall beider HDDs im UCS 240M4 beobachtet wird, der als Controller-Knoten fungiert, befolgen Sie den in angegebenen Austauschvorgang.
Da der Controller-Server, der beide Festplatten-Ausfälle beobachtet, nicht über Secure Shell (SSH) erreichbar ist, melden Sie sich bei einem anderen Controller-Knoten an, um das in der genannten Verbindung aufgeführte Verfahren zum ordnungsgemäßen Herunterfahren durchzuführen.
Beide HDDs schlagen auf dem OSD-Compute-Server fehl
Wenn der Ausfall beider HDDs im UCS 240M4 beobachtet wird, der als OSD-Rechenknoten fungiert, befolgen Sie den Ersetzungsvorgang wie in dargestellt.
Bei dem hier erwähnten Verfahren kann das sanfte Herunterfahren des Ceph-Speichers nicht durchgeführt werden, da beide Fehler zur Unerreichbarkeit des Servers führen. Ignorieren Sie daher diese Schritte.
Ausfall beider Festplatten auf OSPD-Server
Wenn der Ausfall beider HDDs im UCS 240M4 beobachtet wird, der als sn OSPD-Knoten fungiert, befolgen Sie das Ersatzverfahren wie in dargestellt.
In diesem Fall wird das zuvor gespeicherte OSPD-Backup für die Wiederherstellung nach dem Austausch der Festplatte benötigt. Andernfalls wird es sich um eine vollständige Stack-Neubereitstellung handeln.
Beiträge von Cisco Ingenieuren
- Padmaraj RamanoudjamCisco Advanced Services
- Partheeban RajagopalCisco Advanced Services
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)