Überwachung der iftask- und NPU-Leistung auf QvPC-DI
Download-Optionen
-
ePub (183.8 KB)
In verschiedenen Apps auf iPhone, iPad, Android, Sony Reader oder Windows Phone anzeigen
Inklusive Sprache
In dem Dokumentationssatz für dieses Produkt wird die Verwendung inklusiver Sprache angestrebt. Für die Zwecke dieses Dokumentationssatzes wird Sprache als „inklusiv“ verstanden, wenn sie keine Diskriminierung aufgrund von Alter, körperlicher und/oder geistiger Behinderung, Geschlechtszugehörigkeit und -identität, ethnischer Identität, sexueller Orientierung, sozioökonomischem Status und Intersektionalität impliziert. Dennoch können in der Dokumentation stilistische Abweichungen von diesem Bemühen auftreten, wenn Text verwendet wird, der in Benutzeroberflächen der Produktsoftware fest codiert ist, auf RFP-Dokumentation basiert oder von einem genannten Drittanbieterprodukt verwendet wird. Hier erfahren Sie mehr darüber, wie Cisco inklusive Sprache verwendet.
Informationen zu dieser Übersetzung
Cisco hat dieses Dokument maschinell übersetzen und von einem menschlichen Übersetzer editieren und korrigieren lassen, um unseren Benutzern auf der ganzen Welt Support-Inhalte in ihrer eigenen Sprache zu bieten. Bitte beachten Sie, dass selbst die beste maschinelle Übersetzung nicht so genau ist wie eine von einem professionellen Übersetzer angefertigte. Cisco Systems, Inc. übernimmt keine Haftung für die Richtigkeit dieser Übersetzungen und empfiehlt, immer das englische Originaldokument (siehe bereitgestellter Link) heranzuziehen.
Einleitung
In diesem Dokument wird beschrieben, wie die Leistung von iftask/NPU auf QvPC-DI überwacht wird.
Außerdem finden Sie hier weitere Informationen zu einigen Schlüsselkonzepten von iftask.
Verwendete Komponenten
Die Informationen in diesem Dokument basieren auf QvPC-DI.
Die Informationen in diesem Dokument beziehen sich auf Geräte in einer speziell eingerichteten Testumgebung. Alle Geräte, die in diesem Dokument benutzt wurden, begannen mit einer gelöschten (Nichterfüllungs) Konfiguration. Wenn Ihr Netzwerk in Betrieb ist, stellen Sie sicher, dass Sie die möglichen Auswirkungen aller Befehle kennen.
Iftask-Architektur
iftask ist ein Prozess in QvPC-DI. Er aktiviert die Funktionen des DPDK (Data Plane Development Kit) auf der SF (Service Function Virtual Card) und der CF (Control Function Virtual Card) für die DI-Netzwerk-Ports und die Service-Ports. DPDK ist eine effizientere Möglichkeit zur Verarbeitung von Ein-/Ausgängen in virtualisierten Umgebungen.
Die Gerätetreiber von Hochleistungs-Netzwerkschnittstellen-Controllern (NIC) werden nun in den Userspace verschoben, wodurch teure Kontext-Switches (Userspace/Kernelspace) vermieden werden.
Die Treiber werden im Benutzerbereich im unterbrechungsfreien Modus ausgeführt, und die Threads haben direkten Zugriff auf die HW-Warteschlangen/Ringpuffer in diesen NIC-Treibern.
Eine Dokumentation über die Architektur finden Sie unter:
Ultra Services Platform (USP) Einführung von Ultra Gateway Platform System Administration Guide.
Verfügbarkeit für verschiedene Versionen.
In diesem Diagramm wird eine detaillierte iftask-Architektur (für SF) veranschaulicht:
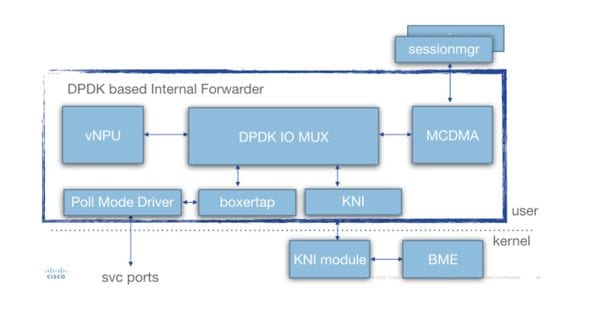
Verschiedene Komponenten sind vorhanden:
Umfragemodustreiber (PMD): Dabei handelt es sich um die Funktion, die die HW-Warteschlangen kontinuierlich von den NICs (bei SR-IOV) oder den SW-Ringpuffern (bei Schnittstellen vom Typ "virtio/vmxnet") abfragt. Aus diesem Grund werden die CPUs, die diesen PMDs zugeordnet sind, kontinuierlich mit 100 % gekoppelt.
Während der Bereitstellung können die nr's von CPU's, die iftask und verschiedenen Funktionen innerhalb iftask zugeordnet sind, statisch über die Datei param.cfg zugewiesen werden.
Boxertap: Anhängen/Entfernen von Staros-Metadaten (MEH-Header) an Pakete, abhängig davon, woher das Paket stammt (z. B.: Di-Port/Service-Port), und wo er versendet werden soll (z. B.: lokaler vNPU)
IOMUX: Verfügt über eine BIA-Bibliothek mit allen Zielen (sessmgr/ports/vNPU's/...). Diese Funktion leitet die Pakete basierend auf ihrer BIA weiter.
vNPU: -Flussklassifizierung/Suche. Dies ist vergleichbar mit der NPU in den HW-basierten Systemen (ASR5000/ASR5500).
Die Flows in vNPU werden weiterhin von NPUmgr (der seine Informationen von demuxmgr/sessmgr usw. erhält) im gemeinsamen Speicher programmiert, auf den vNPU zugreifen kann.
- Zusätzlich wird eine API erstellt, sodass npumgr/sessmgr die vNPU nach Statistiken/Konfigurationen abfragen kann.
MCDMA: Pakete, die für den Sessmgr bestimmt sind, werden an die MCDMA-Schnittstelle geschrieben (über die verschiedenen verfügbaren MCDMA-Cores/Threads). Diese Pakete werden dann via DMA für den Sessmgr verfügbar gemacht. Dies sorgt für einen echten Leistungsschub, da der Kernel nur in begrenzter Weise beteiligt ist. Dies wird in diesem Artikel weiter erläutert.
MCDMA bietet auch Batch-Funktionen (zur Verarbeitung vieler Pakete in einem Systemanruf).
KNI: Schnittstelle für Pakete, die zum Linux-Kernel gehen müssen (DI control/ARP/icmp/routing/...)
iftask - Paketfluss
Im folgenden Diagramm wird der Paketfluss eines Pakets auf der Kontrollebene erläutert. Beispiel: GTPv2-Sitzungsanfrage erstellen
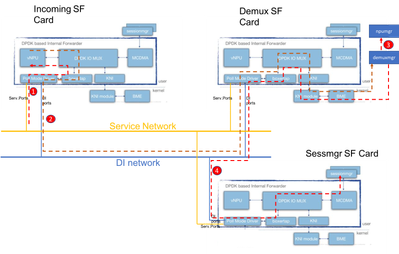
Schritt 1: Das GTPv2-CSR-Paket wird über den Service-Port eines beliebigen verfügbaren SF übermittelt. Er wird in die Rx-Warteschlangen der Service-Schnittstellen-NIC gestellt und von einem der PMD-Kerne des iftask-Prozesses abgerufen. Boxertap stellt den MEH-Header, und das Paket wird über IOMux an die lokale vNPU zur Flow-Suche weitergeleitet.
Da es sich um eine neue Sitzung handelt, ist für die vNPU kein spezifischer Fluss programmiert, und das Paket muss an den demuxmgr auf der Demux-Karte geroutet werden.
Phase 2: vNPU ändert den MEH-Header (mit einer neuen BIA für den relevanten Demux-Prozess). IOMUX weiß, dass es dies über das DI-Netzwerk an die Demux-Karte senden muss. Der Iftask-Prozess auf der Demux-Karte verarbeitet das eingehende Paket, und IOMux leitet es an das KNI-Modul weiter (das die Schnittstelle zum Kernel darstellt). Durch den Kernel wird es schließlich in den demuxmgr Prozess (in diesem Fall egtpinmgr) gelangen.
Schritt 3: Der Demuxmgr führt seine Aufgaben aus. Wählen Sie einen Sessmgr aus, und programmieren Sie npumgr mit den Flows für die nachfolgenden GTPv2-Pakete.
Die vNPUs aller Karten können auf den gemeinsamen Speicher zugreifen, den npumgr zur Programmierung dieser Datenflüsse verwendet.
Schritt 4: Der GTPv2-CSR wird nun an den ausgewählten Sessmgr weitergeleitet. Es ist MEH wird wieder geändert, und von der Demux-Karte, auf dem DI-Netz in Richtung der Sessmgr SF-Karte weitergeleitet. Der IOMUX-Prozess auf dieser Karte leitet das Paket über die MCDMA-Schnittstelle an den ausgewählten Sessmgr weiter. Von hier an verarbeitet sessmgr den gesamten GTPv2-Datenverkehr für diese Sitzung. Sobald die GTPU-TEIDs verhandelt wurden, werden die Flüsse über NPUmgr so programmiert, dass nachfolgende GTPU-Pakete auch direkt von der eingehenden SF-Karte zur Sessmgr-SF-Karte gelangen können.
vCPUs in iftask
Während der Bereitstellung wird eine bestimmte Anzahl virtueller zentraler Verarbeitungseinheiten (vCPUs) dem iftask-Prozess statisch zugewiesen. Dadurch wird die Anzahl der Kerne für Benutzeranwendungen (Sessmgr usw.) reduziert, die E/A-Leistung jedoch erheblich verbessert.
Diese Zuweisung erfolgt über den folgenden Parameter in der param.cfg-Vorlage, die während der Bereitstellung jeder SF/CF zugeordnet ist:
- IFTASK_CORES (% der verfügbaren Kerne, die mit iftask zugewiesen werden)
- (IFTASK_CRYPTO_CORES - (% der verfügbaren Kerne, die für die Verschlüsselungsverarbeitung zugewiesen werden müssen (im Fall von EPDG))
- (IFTASK_MCDMA_CORES - zur weiteren Abstimmung der Anzahl der MCDMA-Funktionen zugewiesenen Kerne)
- Auf einem SF verteilt der iftask-Prozess intern die zugewiesenen Kerne wie folgt:
- PMD-vCPUs (Abfragemodus-Treiber) (Ausführung von tx/rx/vnpu-Aktivität)
- MCDMA vCPUs für die Übertragung von Paketen von iftask an sessmgr und zurück
- Auf einem CF sind keine MCDMA vCPUs erforderlich, da SFs keine Sessmgr-Prozesse hosten.
Der Befehl "show cloud hardware iftask" gibt weitere Details dazu in Ihrer QVPC-DI-Bereitstellung:
[local]UGP# show cloud hardware iftask Card 1: Total number of cores on VM: 8 Number of cores for PMD only: 0 Number of cores for VNPU only: 0 Number of cores for PMD and VNPU: 2 <-- CF: 2 out of 8 cores are assigned to iftask PMD/VNPU Number of cores for MCDMA: 0 <-- CF: no cores allocated to MCDMA as there is no sessmgr process on CF Number of cores for Crypto: 0 Hugepage size: 2048 kB Total hugepages: 3670016 kB NPUSHM hugepages: 0 kB CPU flags: avx sse sse2 ssse3 sse4_1 sse4_2 Poll CPU's: 1 2 KNI reschedule interval: 5 us ... Card 3: Total number of cores on VM: 8 Number of cores for PMD only: 0 Number of cores for VNPU only: 0 Number of cores for PMD and VNPU: 2 <-- SF: 2 out of 8 core are assigned to iftask PMD/VNPU
Number of cores for MCDMA: 1 <-- SF: 1 out of 8 cores is assigned to iftak MCDMA
Number of cores for Crypto: 0
Hugepage size: 2048 kB
Total hugepages: 4718592 kB
NPUSHM hugepages: 0 kB
CPU flags: avx sse sse2 ssse3 sse4_1 sse4_2
Poll CPU's: 1 2 3
KNI reschedule interval: 5 us
Der Befehl "show cloud configuration" gibt weitere Details zu den verwendeten Parametern:
[local]UGP# show cloud configuration Card 1: Config Disk Params: ------------------------- CARDSLOT=1 CPUID=0 CARDTYPE=0x40010100 DI_INTERFACE=BOND:TYPE:ixgbevf-1,TYPE:ixgbevf-2 DI_INTERFACE_VLANID=2111 VNFM_INTERFACE=MAC:fa:16:3e:23:aa:e9 VNFM_PROXY_ADDRS=172.16.180.3,172.16.180.5,172.16.180.6 MGMT_INTERFACE=MAC:fa:16:3e:87:23:9b VNFM_IPV4_ENABLE=true VNFM_IPV4_DHCP_ENABLE=true Local Params: ------------------------- CARDSLOT=1 CARDTYPE=0x40010100 CPUID=0 ... Card 3: Config Disk Params: ------------------------- CARDSLOT=3 CPUID=0 CARDTYPE=0x42030100 DI_INTERFACE=BOND:TYPE:ixgbevf-1,TYPE:ixgbevf-2 SERVICE1_INTERFACE=BOND:TYPE:ixgbevf-3,TYPE:ixgbevf-4 SERVICE2_INTERFACE=BOND:TYPE:ixgbevf-5,TYPE:ixgbevf-6 DI_INTERFACE_VLANID=2111 VNFM_INTERFACE=MAC:fa:16:3e:29:c6:b7 IFTASK_CORES=30 VNFM_IPV4_ENABLE=true VNFM_IPV4_DHCP_ENABLE=true Local Params: ------------------------- CARDSLOT=3 CARDTYPE=0x42010100 CPUID=0
Überlegungen zum Netzwerkdesign:
Es gibt eine Reihe von Faktoren, die bei der Zuweisung von vCPUs zu iftask berücksichtigt werden müssen.
-Gesamt-vCPUs verfügbar für SF vs. iftask vCPUs: Die Standardkonfiguration gibt 30 % der vCPUs an, die iftask über den Parameter IFTASK_CORES in der Datei param.cfg zugeordnet sind. Dies kann jedoch je nach Anwendung variieren (MME vs SPGW vs ePDG) —> Wird vom Engineering konsultiert.
-iftask vCPUs, die PMD zugewiesen sind, und iftask vCPUs, die MCDMA zugewiesen sind. Um zu überprüfen, ob dies ausgeglichen ist, lesen Sie bitte den unten stehenden iftask Performance-Abschnitt.
-iftask MCDMA vCPUs vs rest vCPUs for all applications. Normalerweise ist es gut, eine 1/x Verteilung von iftask MCDMA vCPUs gegen die verbleibenden vCPUs für die Anwendungen (sessmgr/aaamgr/...) zu haben.
Beispiel:
Gesamtanzahl der für SF verfügbaren Kerne 38:
-14 zugewiesen zu iftask (6 PMD, 8 MCDMA)
-24 anderen Prozessen zugewiesen
Das bedeutet, dass es eine MCDMA vCPU für jeweils drei Anwendungs vCPUs gibt.
Dies trägt dazu bei, eine gleichmäßige Belastung für jede MCDMA vCPU sicherzustellen.
Überwachen der Bitaufgabenleistung
Der iftask-Prozess kann auf verschiedene Weise überwacht werden.
Konsolidierte Liste von show-Befehlen:
show subscribers data-rate show npumgr dinet utilization pps show npumgr dinet utilization pps show cloud monitor di-network summary show cloud hardware iftask show cloud configuration show iftask stats summary show port utilization table show npu utilization table show npumgr utilization information show processes cpu
Der Befehl #show cpu info verbose gibt keine Informationen über die iftask-Kerne. Sie werden immer bei 100% Auslastung aufgelistet.
Im folgenden Beispiel wird der Core 1,2,3 mit iftask verknüpft und bei 100 % Auslastung aufgeführt.
Card 3, CPU 0:
Status : Standby, Kernel Running, Tasks Running
Load Average : 3.12, 3.12, 3.13 (3.95 max)
Total Memory : 16384M
Kernel Uptime : 4D 21H 56M
Last Reading:
CPU Usage All : 1.9% user, 0.3% sys, 0.0% io, 0.0% irq, 97.8% idle
Core 0 : 5.8% user, 0.2% sys, 0.0% io, 0.0% irq, 94.0% idle
Core 1 : Not Averaged (Poll CPU)
Core 2 : Not Averaged (Poll CPU)
Core 3 : Not Averaged (Poll CPU)
Core 4 : 2.2% user, 0.2% sys, 0.0% io, 0.0% irq, 97.6% idle
Core 5 : 0.8% user, 0.5% sys, 0.0% io, 0.0% irq, 98.7% idle
Core 6 : 0.4% user, 0.5% sys, 0.0% io, 0.0% irq, 99.1% idle
Core 7 : 0.1% user, 0.3% sys, 0.0% io, 0.0% irq, 99.6% idle
Poll CPUs : 3 (1, 2, 3)
Core 1 : 100.0% user, 0.0% sys, 0.0% io, 0.0% irq, 0.0% idle
Core 2 : 100.0% user, 0.0% sys, 0.0% io, 0.0% irq, 0.0% idle
Core 3 : 100.0% user, 0.0% sys, 0.0% io, 0.0% irq, 0.0% idle
Processes / Tasks : 143 processes / 16 tasks
Network mcdmaN : 0.002 kpps rx, 0.001 mbps rx, 0.002 kpps tx, 0.001 mbps tx
File Usage : 1504 open files, 1627405 available
Memory Usage : 7687M 46.9% used
Memory Details:
Static : 330M kernel, 144M image
System : 10M tmp, 0M buffers, 54M kcache, 79M cache
Process/Task : 6963M (120M small, 684M huge, 6158M other)
Other : 104M shared data
Free : 8696M free
Usable : 5810M usable (8696M free, 0M reclaimable, 2885M reserved by tasks)Befehl #show npu usage table gibt eine gute Übersicht über die Nutzung jedes mit dem iftask-Prozess verbundenen Kerns (auf jeder Karte).
Anmerkung: Wichtig ist hierbei, festzustellen, ob einige Kerne durchweg eine höhere Auslastung aufweisen als andere.
[local]UGP# show npu utilization table
-------iftask-------
lcore now 5min 15min
-------- ------ ------ ------
01/0/1 0% 0% 0%
01/0/2 0% 0% 0%
02/0/1 0% 0% 0%
02/0/2 2% 1% 0%
03/0/1 0% 0% 0%
03/0/2 0% 0% 0%
03/0/3 0% 0% 0%
04/0/1 0% 0% 0%
04/0/2 0% 0% 0%
04/0/3 0% 0% 0%
05/0/1 0% 0% 0%
05/0/2 0% 0% 0%
05/0/3 0% 0% 0%Befehl #show npumgr usage information (versteckter Befehl)
Dieser Befehl liefert weitere Informationen über jeden iftask-Core und was die CPU auf diesen Cores verbraucht.
Anmerkung: Die CPU der PMD-Kerne ist für PortRX, PortTX, KNI und Cipher ausgelastet. Die CPU der MCDMA-Kerne wird von MCDMA beansprucht.
Sowohl die PMD- als auch die MCDMA-Kerne sollten eine relativ gleichmäßige Last aufweisen.
Ist dies nicht der Fall, ist möglicherweise eine Anpassung erforderlich (z. B. die Zuweisung von mehr/weniger MDMA-Cores).
******** show npumgr utilization information 3/0/0 *******
5-Sec Avg: lcore01| lcore02| lcore03| lcore04| lcore05| lcore06| lcore07| lcore08| lcore09| lcore10| lcore11| lcore12| lcore13| lcore14| lcore15| lcore16|
Idle: 31%| 37%| 32%| 35%| 41%| 48%| 47%| 38%| 57%| 56%| 55%| 56%| 46%| 56%| 54%| 52%|
PortRX: 28%| 26%| 27%| 26%| 0%| 0%| 0%| 0%| 12%| 14%| 11%| 11%| 0%| 0%| 0%| 0%|
PortTX: 5%| 5%| 6%| 5%| 8%| 8%| 8%| 14%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%|
KniRX: 6%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%|
Kni: 1%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%|
McdmaRX: 0%| 0%| 0%| 0%| 34%| 29%| 29%| 32%| 0%| 0%| 0%| 0%| 35%| 28%| 28%| 28%|
Mcdma: 0%| 0%| 0%| 0%| 11%| 7%| 4%| 6%| 0%| 0%| 0%| 0%| 14%| 7%| 7%| 7%|
Vnpu: 28%| 29%| 28%| 32%| 0%| 0%| 0%| 0%| 30%| 28%| 33%| 28%| 0%| 0%| 0%| 0%|
McdmaFlush: 0%| 0%| 0%| 0%| 6%| 8%| 12%| 10%| 0%| 0%| 0%| 0%| 6%| 10%| 11%| 14%|
Cipher: 1%| 2%| 6%| 2%| 0%| 0%| 0%| 0%| 1%| 2%| 1%| 5%| 0%| 0%| 0%| 0%|
rx kbits/sec: 728563| 736103| 647535| 626595| 811362| 698724| 717147| 799281| 617199| 595268| 623670| 633132| 819270| 672732| 790849| 719498|
rx frames/sec: 94409| 95586| 91107| 84997| 109526| 97466| 98557| 107690| 81122| 82076| 86959| 87960| 114114| 96198| 108108| 100259|
tx kbits/sec: 715038| 722181| 634227| 614221| 827124| 712740| 731329| 814782| 605373| 583318| 611001| 620328| 835692| 686575| 806395| 733924|
tx frames/sec: 94310| 95491| 90969| 84896| 109526| 97466| 98557| 107690| 81002| 81986| 86858| 87859| 114114| 96198| 108108| 100259|
5-Min Avg: ...
15-Min Avg: ...weitere Erläuterungen:
Die CPU wird wie folgt für ein Paket berücksichtigt, das über einen Service-Port oder einen DI-Port beim iftask-Prozess eingeht.
Die vNPU-Suche ist der CPU-intensivste Teil.
Wenn nach der VPN-Suche:
-das Paket an den MCDMA-Core gesendet wird, wird die CPU-Zeit auf dem MCDMArx des entsprechenden MCDMA-Core abgerechnet.
-Das Paket wird an einen anderen iftask-Core gesendet, die CPU-Zeit wird unter Vnpu abgerechnet
- das Paket wird auf demselben iftask core gesendet, die CPU-Zeit wird unter PortRx abgerechnet
-das Paket wird auf dem gleichen iftask core ausgesendet, die CPU-Zeit wird unterKniRx abgerechnet
PortRx beinhaltet außerdem einen erheblichen allgemeinen Overhead für das Entfernen von Paketen aus den Empfangswarteschlangen und das Versenden/Warteschlangenzuweisen an den gewünschten Zielort.
Befehle #show npumgr dinet usage pps, #show npumgr dinet usage bbps und #show port usage table
Sie liefern Informationen über die Auslastung der DI-Ports und der Service-Ports.
Die tatsächliche Leistung hängt von den NICs/CPUs und der CPU-Zuweisung zu iftask ab.
[local]UGP# show npumgr dinet utilization pps
------ Average DINet Port Utilization (in kpps) ------
Port Type Current 5min 15min
Rx Tx Rx Tx Rx Tx
----- ------------------------ ------- ------- ------- ------- ------- -------
1/0 Virtual Ethernet 0 0 0 0 0 0
2/0 Virtual Ethernet 0 0 0 0 0 0
3/0 Virtual Ethernet 0 0 0 0 0 0
4/0 Virtual Ethernet 0 0 0 0 0 0
5/0 Virtual Ethernet 0 0 0 0 0 0
[local]UGP# show npumgr dinet utilization bps
------ Average DINet Port Utilization (in mbps) ------
Port Type Current 5min 15min
Rx Tx Rx Tx Rx Tx
----- ------------------------ ------- ------- ------- ------- ------- -------
1/0 Virtual Ethernet 1 1 1 1 1 1
2/0 Virtual Ethernet 1 0 1 0 1 0
3/0 Virtual Ethernet 0 0 0 0 0 0
4/0 Virtual Ethernet 0 0 0 0 0 0
5/0 Virtual Ethernet 0 0 0 0 0 0
[local]UGP# show port utilization table
------ Average Port Utilization (in mbps) ------
Port Type Current 5min 15min
Rx Tx Rx Tx Rx Tx
----- ------------------------ ------- ------- ------- ------- ------- -------
1/1 Virtual Ethernet 0 0 0 0 0 0
2/1 Virtual Ethernet 0 0 0 0 0 0
3/10 Virtual Ethernet 0 0 0 0 0 0
3/11 Virtual Ethernet 0 0 0 0 0 0
4/10 Virtual Ethernet 0 0 0 0 0 0
4/11 Virtual Ethernet 0 0 0 0 0 0
5/10 Virtual Ethernet 0 0 0 0 0 0
5/11 Virtual Ethernet 0 0 0 0 0 0Befehl #show cloud monitor di-network summary
Dieser Befehl überwacht den Zustand des DI-Netzwerks. Karten senden Heartbeats an einander, und der Verlust wird überwacht. In einem gesunden System wird kein Verlust gemeldet.
[local]UGP# show cloud monitor di-network summary Card 3 Heartbeat Results: ToCard Health 5MinLoss 60MinLoss 1 Good 0.00% 0.00% 2 Good 0.00% 0.00% 4 Good 0.00% 0.00% 5 Good 0.00% 0.00% Card 4 Heartbeat Results: ToCard Health 5MinLoss 60MinLoss 1 Good 0.00% 0.00% 2 Good 0.00% 0.00% 3 Good 0.00% 0.00% 5 Good 0.00% 0.00% Card 5 Heartbeat Results: ToCard Health 5MinLoss 60MinLoss 1 Good 0.00% 0.00% 2 Good 0.00% 0.00% 3 Good 0.00% 0.00% 4 Good 0.00% 0.00%
Befehl #show iftask - Statistikübersicht
Bei höheren NPU-Auslastungen kann es vorkommen, dass der Datenverkehr verworfen wird.
Um dies auszuwerten, kann der Befehl #show iftask stats summary ausgegeben werden.
Anmerkung: VERWERFUNGEN können ungleich null sein, alle anderen Zähler sollten idealerweise 0 bleiben.
[local]VPC# show iftask stats summary Thursday January 18 16:01:29 IST 2018 ----------------------------------------------------------------------------------------------- Counter SF3 SF4 SF5 SF6 SF7 SF8 SF9 SF10 SF11 SF12 ___TOTAL___ ------------------------------------------------------------------------------------------------ svc_rx 32491861127 16545600654 37041906441 37466889835 32762859630 34931554543 38861410897 16025531220 33566817747 32823851780 312518283874 svc_tx 46024774071 14811663244 40316226774 39926898585 40803541378 48718868048 35252698559 1738016438 4249156512 40356388348 312198231957 di_rx 42307187425 14637310721 40072487209 39584697117 41150445596 44534022642 31867253533 1731310419 4401095653 40711142205 300996952520 di_tx 28420090751 16267050562 36423298668 36758561246 32731606974 30366650898 35201117980 16009902791 33536789041 32815316570 298530385481 __ALL_DROPS__ 1932492 252 17742 790473 11228 627018 844812 60402 0 460830 4745249 svc_tx_drops 0 0 0 0 0 0 0 0 0 0 0 di_rx_drops 0 1 0 0 49 113 579 30200 0 4888 35830 di_tx_drops 0 0 0 0 0 0 0 0 0 0 0 sw_rss_enq_drops 0 0 0 0 0 0 0 0 0 0 0 kni_thread_drops 0 0 0 0 0 0 0 0 0 0 0 kni_drops 0 1 0 0 0 0 124 30200 0 0 30325 mcdma_drops 0 0 0 168 80 194535 758500 0 0 11628 964911 mux_deliver_hop_drops 0 0 0 0 0 0 0 0 0 1019 1019 mux_deliver_drops 0 0 0 0 0 0 0 0 0 0 0 mux_xmit_failure_drops 0 3 0 0 0 0 7 2 0 0 12 mc_dma_thread_enq_drops 0 0 0 0 49 113 580 0 0 3457 4199 sw_tx_egress_enq_drops 1904329 0 0 787971 9004 429214 85022 0 0 429810 3645350 cpeth0_drops 0 0 0 0 0 0 0 0 0 0 0 mcdma_summary_drops 28163 247 17742 2334 2046 3043 0 0 0 10028 63603 fragmentation_err 0 0 0 0 0 0 0 0 0 0 0 reassembly_err 0 0 0 0 0 0 0 0 0 0 0 reassembly_ring_enq_err 0 0 0 0 0 0 0 0 0 0 0 __DISCARDS__ 20331090 9051092 23736055 23882896 23807520 24231716 24116576 8944291 22309474 20135799 20135799
SW-RSS und HW-RSS
RSS ist eine Funktion, die den von einer Netzwerkkarte eingehenden Datenverkehr über mehrere DPDK-Prozessoren verteilt. In der Regel unterstützt die Netzwerkkarte RSS in der HW und ermöglicht so die Verteilung des Datenverkehrs auf mehrere IP-Taskkerne.
Der iftask-Prozess in Staros hat eine Softwareversion von rss implementiert, die aktiviert werden kann, wenn:
-nic unterstützt kein HW-RSS (daher landet der gesamte TX/RX-Datenverkehr auf einer einzigen iftask-CPU).
-nic verfügt nicht über genügend tx/rx-Warteschlangen (weniger Warteschlangen als verfügbare tx/rx-CPUs, die iftask zugewiesen sind). In diesem Fall ermöglicht das SW-RSS (umfassend) eine korrekte Verteilung auf alle verfügbaren iftask-Cores, die für rx/tx zugewiesen sind.
Diese Funktion ist nur für Datenverkehr geeignet, der über Service-Ports eingeht. DI-Datenverkehr wird nicht berücksichtigt.
Es gibt drei Konfigurationsmodi:
-no iftask sw-rss - sw-rss disabled (Keine iftask sw-rss) Das System verlässt sich auf HW RSS.
-iftask sw-rss complex - sw rss wird für den gesamten Datenverkehr verwendet. SW RSS kann zusammen mit HW RSS ausgeführt werden. HW RSS muss nicht deaktiviert werden. Der SW-RSS ist jedoch für den tatsächlichen Lastenausgleich des SERVICE-Datenverkehrs zu den iftask-Cores verantwortlich.
-iftask sw-rss additional - sw rss wird nur für den Datenverkehr verwendet, der von hw-rss nicht unterstützt wird (Beispiel: MPLS-Datenverkehr)
Bei HW- und SW-RSS ist es wichtig zu verstehen, wie der Datenverkehr in die verschiedenen iftask/dpdk-Prozessoren gehasht wird.
HW-RSS: Hashing hängt von der Hardware ab. Hier ein Beispiel:
[root@host]# ethtool -n enp10s0f1
4 RX rings available
Total 0 rules
[root@host] # ethtool -n enp10s0f0 rx-flow-hash udp4
UDP over IPV4 flows use these fields for computing Hash flow key:
IP SA
IP DA
SW-RSS: Ab Staros 21.6 verhält sich das SW RSS Version Hashing wie folgt:
1. In case of IPV6
we only support L3( IP src/dst ) based hashing (same as the old behaviour).
2. In case of IPV4
a. For TCP we support IP src/dst + tcp ports src/dst
b. For UDP fragmented - only IP src/dst
c. For UDP non-fragmented not gtpu ( I.e. Port !=2152) ? IP src/dst + udp port src/dst
d. For UDP non-fragmented and gtpu ( I.e. Port ==2152) - IP src/dst + udp port src/dst + gtp tunnel id
e. Any other protocol ? we default back to IP src/dst
Wichtig: RSS für verschlüsselten DI-Datenverkehr:
In Ermangelung von SW-RSS (zusätzlich/umfassend) kann es möglich sein, dass der gesamte verschlüsselte DI-Datenverkehr in einem einzelnen Core auf iftask gehasht wird.
Dies führt dazu, dass dieser Core durchweg eine höhere Auslastung aufweist als die anderen.
Seit CSCvi06080  kann dies jetzt durch folgenden Konfigurationsbefehl abgeschwächt werden:
kann dies jetzt durch folgenden Konfigurationsbefehl abgeschwächt werden:
iftask di-net-encrypt-rss
Nach Integration von CSCvm41257 , wird diese Option als Standardeinstellung festgelegt.
Ausführlichere Informationen zu SW RSS:
Der Zweck von sw-rss besteht darin, die PMD-Kerne auszugleichen und Szenarien zur Durchsatzbegrenzung zu vermeiden, bei denen sich ein PMD-Kern maximal durchsetzt, wenn die anderen über eine beträchtliche verfügbare Kapazität verfügen.
Alle Eingangspakete des Service-Ports werden von der Netzwerkkarte abgezogen und mit MEH verkapselt, indem der PMD-Core die Rx-Warteschlange bedient, bei der sie eintreffen.
An diesem Punkt weiß iftask nicht, wohin das Paket gesendet werden soll. Pakete müssen von VNPU verarbeitet werden, um das interne Ziel zu bestimmen. Fast alle diese Pakete durchlaufen bei der Weiterleitung an VNPU eine IOC/Flow-Suche. Die Ausnahmen beziehen sich auf Verwerfungen aus Gründen wie unkonfiguriertes/deaktiviertes VLAN oder ungültige MAC-Zieladresse (es gibt auch das L3-Weiterleitungsszenario, aber das ist nicht üblich).
Wenn sw-rss nicht konfiguriert ist, erfolgt die Verarbeitung der VNPU-IOC/Flow-Suche im selben Core unmittelbar nach dem MEH-Encap. Wenn sw-rss konfiguriert ist, werden Pakete zur VNPU-Verarbeitung auf Basis eines Hashs in eine Warteschlange gestellt. Die IOC-/Flow-Suche im VNPU ist die teuerste Einzelaufgabenfunktion. Mit sw-rss können wir diese Arbeitslast auf alle PMD-Kerne verteilen.
Nach der VNPU IOC/Flow-Suche wird das Paket entweder per DINet-Übertragung an einen anderen SF übertragen oder per MCDMA-Übertragung an eine lokale Anwendung in die Warteschlange gestellt (auch hier gibt es Ausnahmen, die meiner Ansicht nach jedoch für dieses Gespräch nicht relevant sind).
Pakete, die an einen anderen SF gesendet werden, werden direkt dem entsprechenden MCDMA-Kanal auf der Zielkarte entsprechend DINet Rx in die Warteschlange gestellt. Sie erfordern keinen (zweiten) VNPU-Pass.
TX-/RX-Warteschlangen
In den iftask-Protokollen werden Protokolle wie folgt angezeigt:
Tue May 7 15:26:48 2019 PID:8188 APP: max rx queues supported 16 ...
Tue May 7 15:26:48 2019 PID:8188 APP: max tx queues supported 8 ...
Tue May 7 15:26:48 2019 PID:8188 APP: hw rx requested 2 ...
Tue May 7 15:26:48 2019 PID:8188 APP: hw tx requested tx 5
Dies hängt mit der unterstützten Anzahl von RX- und TX-Warteschlangen zusammen, die von der Hardware unterstützt werden, und mit der Anzahl von TX-/RX-Warteschlangen, die Anfragen stellen.
Was iftask-Anfragen sind, hängt eng mit der Anzahl der iftask-Prozessoren zusammen.
Anmerkung: Jeder Fahrer ist anders. Einige Abfrage-Hosts, andere haben feste Codes.
Die Anzahl der angeforderten HW-TX ist die Anzahl der von dpdk verwendeten Kerne. Dies ist in der Regel einer mehr als die gesamten Kerne, die iftask zugeordnet sind, da dpdk den Kern enthält, auf dem der Steuerungs-/IPC-Thread ausgeführt wird. Dieser Kern wird mit boxer gemeinsam genutzt und als allgemeine CPU geplant (der dpdk control/ipc thread verwendet nicht viel CPU).
Die angeforderte Anzahl von hw rx entspricht in der Regel der Anzahl der PMD-Kerne.
Iftask weist jedem Port die Min. (angefordert, max.) zu und verteilt sie auf die Kerne. Der Verteilungsalgorithmus ist etwas kompliziert. Ziel ist es, die Arbeitslast möglichst gleichmäßig auf alle Kerne zu verteilen.
Iftask-Texbatch
Seit Version 21.9 verfügt staros über die folgenden Standard-iftask-Konfigurationsoptionen, die für das Batching (Aggregation von Datenverkehr) wichtig sind. Dies wirkt sich negativ auf die Leistung aus, wenn der Knoten mit einem (oder wenigen) Abonnenten getestet wird.
# iftask mcdmatxbatch burst size 32 # iftask mcdmatxbatch latency 200 # iftask txbatch burst size 32 # iftask txbatch latency 200
Weitere Erläuterungen hierzu finden Sie in einem separaten Dokument:
Bulkstats
Das Bulkstat-Schema wurde für QPVC-DI-Leistung im Zusammenhang mit iftask/dinet entwickelt. Dies ist nützlich, um die Dinet-, Service-Ports- und CPU-Auslastung im Hinblick auf Leistung/Auslastung zu überwachen:
card schema iftask-dinet format EMS,IFTASKDINET,%date%,%time%,%dinet-rxpkts-curr%,%dinet-txpkts-curr%,%dinet-rxpkts-5minave%,%dinet-txpkts-5minave%,%dinet-rxpkts-15minave%,%dinet-txpkts-15minave%,%dinet-txdrops-curr%,%dinet-txdrops-5minave%,%dinet-txdrops-15minave%,%npuutil-now% file 2 port schema iftask-port format EMS,IFTASKPORT,%date%,%time%,%util-rxpkts-curr%,%util-txpkts-curr%,%util-rxpkts-5min%,%util-txpkts-5min%,%util-rxpkts-15min%,%util-txpkts-15min%,%util-txdrops-curr%,%util-txdrops-5min%,%util-txdrops-15min% file 3 card schema npu-util format EMS,NPUUTIL,%date%,%time%,%npuutil-now%,%npuutil-5minave%,%npuutil-15minave%,%npuutil-rxbytes-5secave%,%npuutil-txbytes-5secave%,%npuutil-rxbytes-5minave%,%npuutil-txbytes-5minave%,%npuutil-rxbytes-15minave%,%npuutil-txbytes-15minave%,%npuutil-rxpkts-5secave%,%npuutil-txpkts-5secave%,%npuutil-rxpkts-5minave%,%npuutil-txpkts-5minave%,%npuutil-rxpkts-15minave%,%npuutil-txpkts-15minave%
Revisionsverlauf
| Überarbeitung | Veröffentlichungsdatum | Kommentare |
|---|---|---|
1.0 |
09-Jun-2018
|
Erstveröffentlichung |
Beiträge von Cisco Ingenieuren
- Steven Loos
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)