Was ist der Expressway-Cluster und wie funktioniert er?
Download-Optionen
-
ePub (936.5 KB)
In verschiedenen Apps auf iPhone, iPad, Android, Sony Reader oder Windows Phone anzeigen
Inklusive Sprache
In dem Dokumentationssatz für dieses Produkt wird die Verwendung inklusiver Sprache angestrebt. Für die Zwecke dieses Dokumentationssatzes wird Sprache als „inklusiv“ verstanden, wenn sie keine Diskriminierung aufgrund von Alter, körperlicher und/oder geistiger Behinderung, Geschlechtszugehörigkeit und -identität, ethnischer Identität, sexueller Orientierung, sozioökonomischem Status und Intersektionalität impliziert. Dennoch können in der Dokumentation stilistische Abweichungen von diesem Bemühen auftreten, wenn Text verwendet wird, der in Benutzeroberflächen der Produktsoftware fest codiert ist, auf RFP-Dokumentation basiert oder von einem genannten Drittanbieterprodukt verwendet wird. Hier erfahren Sie mehr darüber, wie Cisco inklusive Sprache verwendet.
Informationen zu dieser Übersetzung
Cisco hat dieses Dokument maschinell übersetzen und von einem menschlichen Übersetzer editieren und korrigieren lassen, um unseren Benutzern auf der ganzen Welt Support-Inhalte in ihrer eigenen Sprache zu bieten. Bitte beachten Sie, dass selbst die beste maschinelle Übersetzung nicht so genau ist wie eine von einem professionellen Übersetzer angefertigte. Cisco Systems, Inc. übernimmt keine Haftung für die Richtigkeit dieser Übersetzungen und empfiehlt, immer das englische Originaldokument (siehe bereitgestellter Link) heranzuziehen.
Inhalt
Einleitung
In diesem Dokument wird beschrieben, wie die Expressway-Cluster die Ausfallsicherheit und Kapazität einer Expressway-Installation verbessern.
Hintergrundinformationen
Kapazität. Expressway-Cluster können die Kapazität einer Expressway-Bereitstellung im Vergleich zu einem einzelnen Expressway um einen Faktor von maximal vier erhöhen. Expressway-Peers in einem Cluster teilen sich die Bandbreitennutzung sowie Routing, Zone, FindMe und andere Konfigurationen.
Ausfallsicherheit. Expressway-Cluster können Redundanz bereitstellen, während sich ein Expressway im Wartungsmodus befindet, oder falls der Zugriff auf ihn aufgrund eines Netzwerk- oder Stromausfalls oder aus anderen Gründen nicht möglich ist. Endpunkte können sich bei allen Peers in einem Cluster registrieren. Wenn die Verbindung des Endpunkts mit dem ursprünglichen Peer unterbrochen wird, kann die Anmeldung bei einem anderen Endpunkt im Cluster rückgängig gemacht werden.
Spezifikationen
Ein Expressway kann Teil eines Clusters von bis zu sechs Expressways sein. Wenn Sie einen Cluster erstellen, wählen Sie einen Peer als primären aus, dessen Konfiguration auf die anderen Peers repliziert wird. Jeder Expressway-Peer im Cluster muss über die gleichen Routing-Funktionen verfügen. Wenn ein Expressway einen Anruf an ein Ziel weiterleiten kann, wird davon ausgegangen, dass alle Expressway-Peers in diesem Cluster einen Anruf an dieses Ziel weiterleiten können.
Kapazität
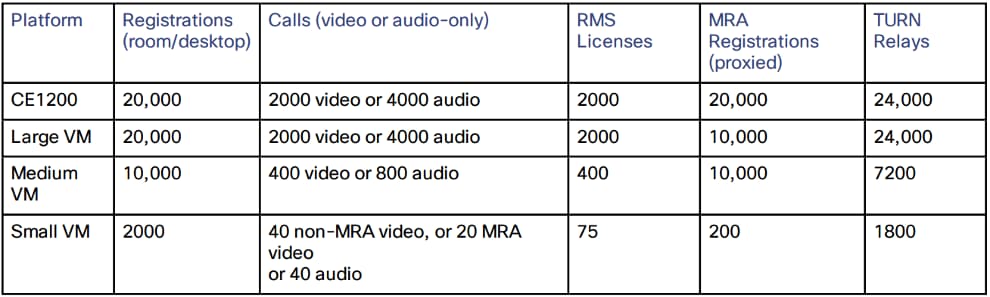
Nach vier Peers gibt es keinen Kapazitätsgewinn mehr. In einem Cluster mit sechs Peers erhöhen der fünfte und sechste Expressway keine zusätzliche Anrufkapazität für den Cluster. Die Ausfallsicherheit wird durch die zusätzlichen Peers verbessert, jedoch nicht durch die Kapazität.
- Bei kleinen virtuellen Systemen (VMs) dient der Cluster nur zur Redundanz und nicht zur Skalierung, und es erfolgt keine Kapazitätssteigerung durch den Cluster.
- In der Cluster-Konfiguration mit 4 Peers wird die auf Kapazität basierende Kapazität im nächsten Bild angezeigt:
Wichtige Seitenelemente

Anforderungen
- Grundkenntnisse von Secure Shell (SSH)
- Ein Cluster darf nur einen Expressway-C-Knoten oder nur einen Expressway-E-Knoten enthalten.
- Alle Peers müssen dieselbe Softwareversion verwenden.
- Alle Peers nutzen Hardwareplattformen, Appliances oder virtuelle Systeme (VM) mit vergleichbaren Funktionen.
- Expressway unterstützt eine Round-Trip-Verzögerung von bis zu 80 ms.
- Der H323-Modus ist auf jedem Peer aktiviert.
- Auf allen Peers sind die gleichen Optionsschlüssel installiert, mit den nächsten Ausnahmen:
- Für Video Control Server (VCS): Lizenzen für Anrufe mit und ohne Anrufweiterleitung
- Für Expressway: Rich Media-Sitzungen
- Für Expressway: Raumsystem- und Desktop-System-Registrierungslizenzen
Alle anderen Lizenzschlüssel müssen auf jedem Peer identisch sein.
- Zwischen Cluster-Peers darf es keine Network Address Translation (NAT) geben.
Anmerkung: Wenn Expressway-E einen einzigen NIC (Network Interface Controller) verwendet, muss es eine öffentliche IP verwenden. Wenn Expressway-E eine duale NIC verwendet, muss die interne Schnittstelle zum Erstellen des Clusters verwendet werden.
- IP-Adresse, Domain Name Service (DNS) und Network Time Protocol (NTP) müssen konfiguriert werden.
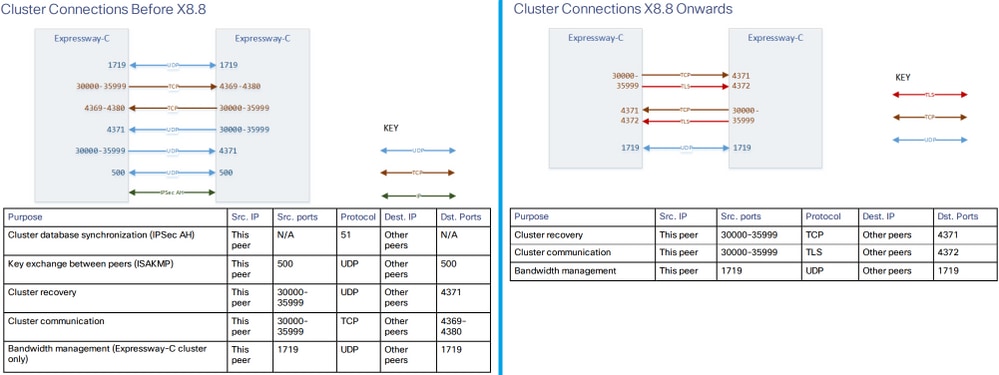
Cluster-Verbindungen und -Ports
Konfigurationen
Neuen Cluster erstellen
- Öffnen Sie die Expressway-Webschnittstelle.
- Navigieren Sie zu System > Clustering.
- Geben Sie die nächsten Werte ein:
Anmerkung: Sie müssen zuerst einen Cluster aus einem (primären) Peer erstellen und den primären Peer neu starten, bevor Sie weitere Peers hinzufügen. Sie können weitere Peers hinzufügen, nachdem Sie einen Cluster von einem erstellt haben.
Primärkonfiguration: 1
Cluster-IP-Version: Wählen Sie IPv4 oder IPv6 aus, um das Netzwerkadressschema abzugleichen.
Optionen für den TLS-Verifizierungsmodus: Permissive (Standard) oder Enforce (Durchsetzen).
Permissiv bedeutet, dass die Peers die Zertifikate der anderen Peers nicht validieren, wenn die TLS-Verbindungen (Transport Layer Security) innerhalb des Clusters eingerichtet sind.
Die Erzwingung ist sicherer, erfordert jedoch, dass jeder Peer über ein gültiges Zertifikat verfügt und dass die Zertifizierungsstelle (Certificate Authority, CA) von allen anderen Peers als vertrauenswürdig angesehen wird.
Peer-1-Adresse: Geben Sie die Adresse dieses Expressway (den primären Peer) ein. Wenn der TLS-Verifizierungsmodus auf "Erzwingen" festgelegt ist, müssen Sie einen FQDN (Fully Qualified Domain Name) eingeben, der mit dem Common Name (CN) des Antragstellers oder einem SAN (Subject Alternative Name) auf dem Zertifikat dieses Peers übereinstimmt.
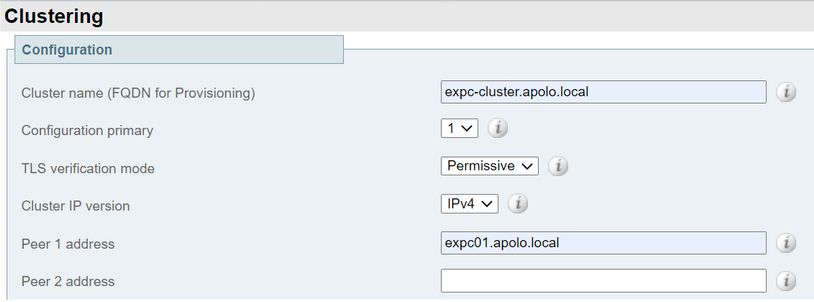
- Wählen Sie Speichern aus.
- Starten Sie den Server neu.
- Navigieren Sie zu Maintenance > Restart options, wählen Sie dann Restart (Neustart) aus, und bestätigen Sie OK.
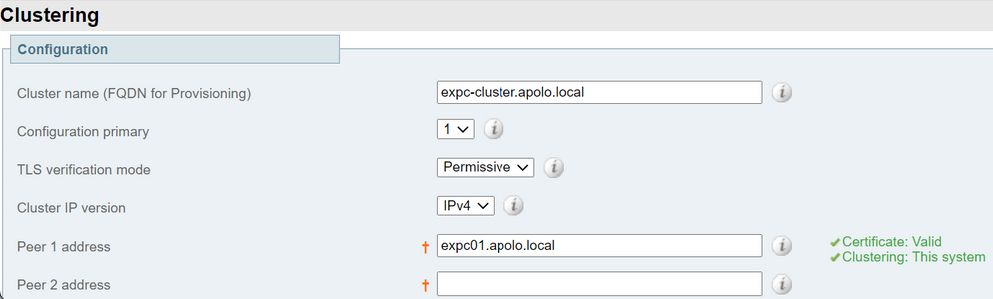
- Validieren Sie die Gültigkeit des Zertifikats, wie im folgenden Bild gezeigt:
Hinzufügen zusätzlicher Peers zum Cluster
Führen Sie die folgenden Schritte aus, um einen weiteren Peer hinzuzufügen:
- Navigieren Sie zu System > Clustering auf dem primären Expressway.
- Geben Sie im ersten leeren Feld die Adresse des neuen Expressway-Peers ein.
- Wählen Sie Speichern aus.
- Peer 1 muss Dieses System angeben. Der neue Peer muss Unbekannt anzeigen und dann mit einer Aktualisierung Fehlgeschlagen anzeigen, da er dem Cluster noch nicht vollständig beigetreten ist.
- Navigieren Sie zu System > Clustering auf einem der untergeordneten Peers, die sich bereits im Cluster befinden, und bearbeiten Sie die folgenden Felder:

- Wiederholen Sie den vorherigen Schritt für jeden untergeordneten Peer, der sich bereits im Cluster befindet.
- Wählen Sie Speichern aus.
- Der Expressway löst einen Alarm wegen eines Fehlers bei der Clusterkommunikation aus. Der Alarm wird nach dem erforderlichen Neustart gelöscht.
- Starten Sie den Expressway neu.
- Warten Sie nach dem Neustart ca. 2 Minuten. Dies ist die Häufigkeit, mit der Konfigurationen von der primären Instanz kopiert werden.
- Validieren Sie den Cluster-Datenbankstatus.

- Stellen Sie sicher, dass die Konfiguration auf einem untergeordneten Peer repliziert wird.

TLS-Verifizierung erzwingen
Vorsicht: Bevor Sie fortfahren, stellen Sie sicher, dass die Zertifikat-SANs die FQDNs enthalten, die sich in den Peer-N-Adressfeldern befinden. Bevor Sie fortfahren, müssen Sie grüne Statusmeldungen für Clustering und Zertifikate neben den einzelnen Adressfeldern sehen.


- Legen Sie auf dem primären Peer den TLS-Verifizierungsmodus auf Enforce (Erzwingen) fest.
Vorsicht: Es wird eine Warnung angezeigt, wenn Zertifikate ungültig sind, und der Cluster wird im erzwungenen TLS-Überprüfungsmodus nicht ordnungsgemäß ausgeführt.
- Der neue TLS-Verifizierungsmodus wird im gesamten Cluster repliziert.
- Vergewissern Sie sich, dass der TLS-Verifizierungsmodus jetzt auf jedem anderen Peer durchgesetzt wird.
- Wählen Sie Speichern, und starten Sie den primären Peer neu.
- Wenn der primäre Peer wieder online ist, starten Sie jeden Peer einzeln neu.
- Warten Sie, bis sich der Cluster stabilisiert hat, und stellen Sie sicher, dass für alle Peers der Status Clustering und Certificate grün angezeigt wird.

Ändern des primären Peers
Anmerkung: Sie können diesen Prozess auch dann durchführen, wenn auf den aktuellen primären Peer nicht zugegriffen werden kann.
- Navigieren Sie auf dem neuen primären Expressway zu System > Clustering.
- Wählen Sie im Dropdown-Menü Primär der Konfiguration die ID-Nummer des Peer-Eintrags aus, auf dem Dieses System steht.
- Wählen Sie Speichern aus.
Anmerkung: Ignorieren Sie während der Ausführung dieses Prozesses alle Alarme auf Expressway, die primäre Cluster-Diskrepanzen oder Cluster-Replikationsfehler melden.
- Beginnen Sie auf allen anderen Expressway-Peers mit dem alten primären Peer (sofern dieser noch verfügbar ist).
- Navigieren Sie zu System > Clustering.
- Wählen Sie im Dropdown-Menü Primär konfigurieren die ID-Nummer des neuen primären Expressway aus.
- Wählen Sie Speichern aus.
- Vergewissern Sie sich, dass die Änderung an der primären Konfiguration akzeptiert wurde, navigieren Sie zu System > Clustering, und aktualisieren Sie die Seite.
- Wenn Expressways die Änderung nicht akzeptiert haben, wiederholen Sie den gleichen Vorgang.
- Überprüfen Sie, ob der Status der Clusterdatenbank als Aktiv gemeldet wird.
Cluster ändern, um FQDNs zu verwenden
Anmerkung: Während dieses Verfahrens wird die Kommunikation zwischen Peers vorübergehend beeinträchtigt. Dies bedeutet, dass weiterhin Warnungen ausgegeben werden, bis die Änderungen abgeschlossen sind und der Cluster die neuen Adressen akzeptiert.
- Melden Sie sich bei allen Cluster-Peers an, und navigieren Sie zu System > Clustering.
- Wählen Sie aus, welche Peer-Adresse geändert werden soll. Es wird empfohlen, mit der Peer-1-Adresse zu beginnen.
- Führen Sie auf jedem Peer im Cluster die folgenden Schritte aus:
- Ändern Sie das Feld für die ausgewählte Peer-Adresse von der IP-Adresse in den entsprechenden FQDN.
- Wählen Sie Speichern aus.
- Wechseln Sie zu dem Peer, der durch die geänderte Peer-Adresse identifiziert wird, und starten Sie den Server neu.
- Warten Sie, bis alle vorübergehenden Cluster-Alarme aufgelöst sind.
- Wählen Sie die nächste Peer-Adresse aus, die geändert werden soll, und wiederholen Sie dann die Schritte 3 bis 7.
- Wiederholen Sie dieses Verfahren, bis Sie alle Peer-Adressen geändert und alle Peers neu gestartet haben.
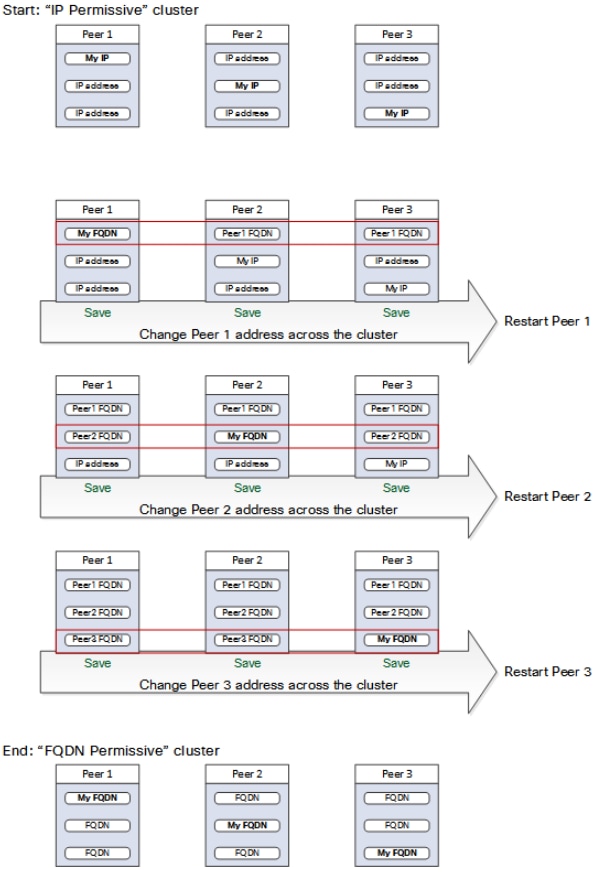
Cluster-Adressenzuordnung für Expressway-E
Für sichere Bereitstellungen wie Mobile and Remote Access (MRA) muss jeder Expressway-E-Peer über ein Zertifikat mit einem SAN verfügen, das seinen öffentlichen FQDN enthält. Der FQDN wird im öffentlichen DNS der öffentlichen IP-Adresse des Expressway-E zugeordnet.
Anmerkung: Wenn Sie einfach Cisco Expressway-E-Peers in Clustern zusammenfassen möchten und keine TLS-Verifizierung zwischen ihnen benötigen, können Sie den Cluster mit den privaten IP-Adressen der Knoten bilden. Sie benötigen keine Cluster-Adresszuordnung.
Cluster-Adressenzuordnungen sind FQDN:IP-Paare, die im Cluster gemeinsam genutzt werden - ein Paar pro Peer. Die Peers konsultieren die Zuordnungstabelle, bevor sie DNS abfragen, und wenn sie eine Übereinstimmung finden, fragen sie DNS nicht ab.
Wenn Sie TLS erzwingen möchten, müssen die Peers auch die Namen der Zertifikate der anderen Peers aus dem SAN-Feld lesen und jeden Namen mit der FQDN-Seite der Zuordnung vergleichen.
Es wird dringend empfohlen, die Zuordnungen auf dem primären Peer einzugeben. Adressenzuordnungen werden dynamisch über den Cluster repliziert. Um die Adresszuordnung zu konfigurieren, gehen Sie wie folgt vor:
- Wechseln Sie zum System > Clustering auf dem primären Peer, und ändern Sie die Cluster-Adresszuordnung aktiviert Dropdown-Liste auf Ein (Standard ist Aus). Die Felder für die Cluster-Adresszuordnung werden angezeigt.
- Bearbeiten Sie die Zuordnungen so, dass die öffentlichen FQDNs der Expressway-E-Peers den IP-Adressen ihrer internen NICs entsprechen.
- Wählen Sie Speichern.

Vorsicht: Verwenden Sie den öffentlichen DNS nicht, um die öffentlichen FQDNs der Peers ihren privaten IP-Adressen zuzuordnen. Dadurch kann die externe Verbindung unterbrochen werden.
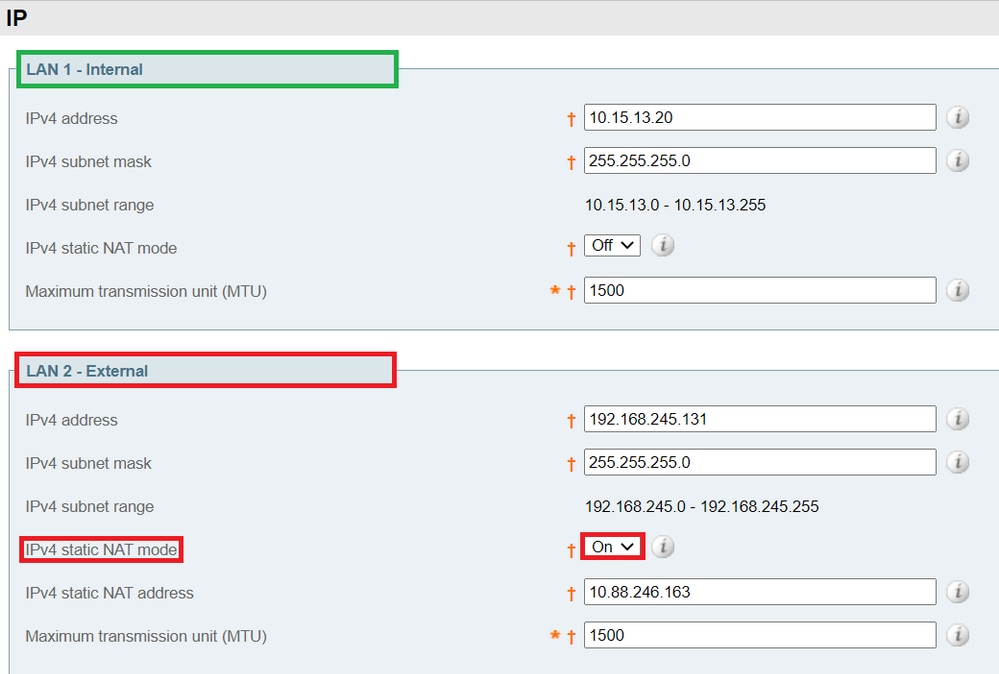
Cluster mit einer NIC
Wenn die Expressway-E-Peers in einem Cluster die Identitäten der jeweils anderen Person mit Zertifikaten überprüfen sollen, können Sie ihnen gestatten, DNS zum Auflösen von Cluster-Peer-FQDNs in ihre öffentlichen IP-Adressen zu verwenden. Dies ist eine vollkommen akzeptable Methode, einen Cluster zu bilden, wenn die Expressway-E-Knoten Folgendes aufweisen:
- Nur eine NIC
- Keine statische NAT konfiguriert
- Routbare IP-Adressen
Fehlerbehebung
Was löst ein Zurücksetzen auf die Werkseinstellungen aus?
Wenn Sie alle Peer-Adressfelder von der Clustering-Seite löschen und die Konfiguration speichern, führt Expressway beim nächsten Neustart standardmäßig ein Factory Reset durch. Das bedeutet, dass alle Konfigurationen gelöscht werden, mit Ausnahme der grundlegenden Netzwerkkonfiguration für die LAN1-Schnittstelle (Local Area Network 1), die alle Konfigurationen enthält, die nach Löschen der Felder und dem nächsten Neustart durchgeführt wurden.
Tipp: Wenn Sie das Zurücksetzen auf die Werkseinstellungen vermeiden müssen, stellen Sie die Felder für die Cluster-Peer-Adresse wieder her. Ersetzen Sie die ursprünglichen Peer-Adressen in der gleichen Reihenfolge, und speichern Sie die Konfiguration, um das Banner zu löschen.
Das Zurücksetzen auf die Werkseinstellungen wird beim Neustart des Peers automatisch ausgelöst, um vertrauliche Daten und die Cluster-Konfiguration zu entfernen. Beim Zurücksetzen werden alle Konfigurationen mit Ausnahme der nächsten grundlegenden Netzwerkinformationen gelöscht:
Anmerkung: Wenn Sie die Option mit zwei NICs verwenden, beachten Sie, dass alle LAN2-Konfigurationen durch das Zurücksetzen vollständig entfernt werden.
- IP-Adressen ・ Admin- und Root-Konten und Kennwörter
- SSH-Schlüssel
- Optionstasten
- HTTPS-Zugriff (Hypertext Transfer Protocol Secure) aktiviert
- SSH-Zugriff aktiviert
Anmerkung: In Version X12.6 werden durch das Zurücksetzen auf die Werkseinstellungen das Serverzertifikat, der zugeordnete private Schlüssel und die Einstellungen des CA Trust Store vom Peer entfernt. In früheren Versionen der Expressway-Software bleiben diese Einstellungen erhalten.
Zurücksetzungsfehler auf Werkseinstellungen
Das Zurücksetzen auf Werkseinstellungen kann fehlschlagen. Dies kann passieren, wenn der Expressway eine neu installierte Open Virtualization Appliance (OVA) ist und nicht aktualisiert wurde.
Um dies zu beheben, befolgen Sie bitte eine der folgenden Optionen:
- Aktualisieren Sie alle Knoten auf dieselbe Softwareversion mit der Datei tar.gz. Starten Sie am Ende des Upgrade-Vorgangs den Server neu, und lösen Sie dann das Zurücksetzen auf die Werkseinstellungen aus.
- Laden Sie die Datei tar.gz direkt in den Ordner zum Zurücksetzen auf die Werkseinstellungen mit WinSCP (/mnt/harddisk/factory-reset/) hoch. Starten Sie den Computer dann neu, um das Zurücksetzen auf die Werkseinstellungen zu initiieren, oder setzen Sie ihn über die CLI auf die Werkseinstellungen zurück.
Anmerkung: Stellen Sie sicher, dass Sie vor einem Upgrade, einer Änderung des Zertifikats oder vor einer Warnung über das Zurücksetzen auf die Werkseinstellungen die richtigen Sicherungen durchführen.
Sequenz neu starten
Wenn ein Neustart des Clusters oder eines Peers erforderlich ist, führen Sie die folgenden Schritte aus:
- Starten Sie den primären Peer neu, und warten Sie, bis er über die Webschnittstelle erreichbar ist.
- Validieren Sie den Cluster-Replikationsstatus auf dem primären Server und den Status aller Peers. Warten Sie einige Minuten, und aktualisieren Sie gelegentlich die Webschnittstellen des Peers.
- Starten Sie ggf. jeweils einen anderen Peer neu. Warten Sie jedes Mal einige Minuten, nachdem der Zugriff möglich ist, und validieren Sie den Replikationsstatus.
Anmerkung: Sie müssen nach dem Vornehmen von Cluster-Änderungen möglicherweise ca. 5 Minuten warten, bevor die Expressway-Peers den Status als erfolgreich melden.
Alarme und Warnungen
Die Alarme der Cluster-Fehler werden im folgenden Format angezeigt: Cluster-Replikationsfehler: (Details) Die manuelle Synchronisierung der Konfiguration ist erforderlich. Hier einige Beispiele:
- Cluster-Replikationsfehler: Die Konfiguration muss manuell synchronisiert werden.
- Cluster-Replikationsfehler: Die primäre oder Peer-Konfigurationsdatei dieses Untergebenen kann nicht gefunden werden. Eine manuelle Synchronisierung der Konfiguration ist erforderlich.
- Cluster-Replikationsfehler: Konfiguration primäre ID ist inkonsistent, manuelle Synchronisierung der Konfiguration erforderlich.
- Cluster-Replikationsfehler: Wenn die Konfiguration des Peers mit der Konfiguration des primären Peers in Konflikt steht, muss die Konfiguration manuell synchronisiert werden.
Wenn ein untergeordneter Expressway den erwähnten Alarm meldet, gehen Sie wie folgt vor:
- Melden Sie sich auf einer SSH- oder einer anderen CLI-Schnittstelle als admin an.
- Führen Sie den nächsten Befehl aus: xcommand ForceConfigUpdate
Anmerkung: Stellen Sie sicher, dass Sie vor einem Upgrade, einer Änderung des Zertifikats oder vor einer Warnung über das Zurücksetzen auf die Werkseinstellungen die richtigen Sicherungen durchführen.
- Dieser Befehl löscht die untergeordnete Expressway-Konfiguration und zwingt sie dann, ihre Konfiguration vom primären Expressway zu aktualisieren.
Wenn das Problem weiterhin besteht, kann es sich auf den Verschlüsselungsschlüssel pro Cluster-Peer beziehen. Tritt in der Regel auf, wenn Peers in der falschen Reihenfolge aktualisiert werden, untergeordnete Peers nicht mit dem primären synchronisiert werden. Wenn xcommand forceconfigupdate also nicht funktioniert, befolgen Sie das nächste Verfahren:
- Melden Sie sich beim primären Peer an, und prüfen Sie, ob dieser in einem einwandfreien Zustand ist.
- Stellen Sie sicher, dass dieser Peer in der Clusterkonfiguration als primärer Peer angezeigt wird.
- Führen Sie erneut ein Upgrade des primären Systems durch. Verwenden Sie dabei dasselbe Paket, das Sie ursprünglich für das Upgrade verwendet haben.
Der Replikationsalarm wird gelöscht, nachdem der primäre Peer aktualisiert und neu gestartet wurde. Dies geschieht normalerweise innerhalb von zehn Minuten nach dem Neustart, kann aber auch bis zu zwanzig Minuten nach dem Neustart dauern.
Häufige Alarme
Ungültige Clusterkonfiguration: Der H.323-Modus muss aktiviert sein - beim Clustering wird die H.323-Kommunikation zwischen Peers verwendet.
Um diesen Alarm zu löschen und sicherzustellen, dass der H.323-Modus aktiviert ist, navigieren Sie zu Configuration > Protocols > H.323 (Konfiguration > Protokolle > H.323).
Expressway-Datenbankfehler: Wenden Sie sich an Ihren Cisco Support-Ansprechpartner.
Um diese Art von Alarm zu beheben, gehen Sie wie folgt vor:
- Erstellen Sie einen System-Snapshot, und stellen Sie ihn Ihrem Support-Mitarbeiter zur Verfügung.
- Entfernen Sie den Expressway aus dem Cluster.
- Stellen Sie die Datenbank des Expressway aus einer zuvor auf diesem Expressway erstellten Sicherung wieder her.
- Fügen Sie den Expressway zurück zum Cluster.
Eine zweite Methode ist möglich, wenn die Datenbank nicht wiederhergestellt wird:
- Erstellen Sie einen System-Snapshot, und stellen Sie ihn dem Technical Assistance Center (TAC) zur Verfügung.
- Entfernen Sie den Expressway aus dem Cluster.
- Melden Sie sich als root an, und führen Sie den nächsten Befehl clusterdb_destroy_and_purge_data.sh aus.
- Stellen Sie die Datenbank des Expressway aus einer zuvor auf diesem Expressway erstellten Sicherung wieder her.
- Fügen Sie den Expressway zurück zum Cluster.
Anmerkung: Stellen Sie sicher, dass Sie vor einem Upgrade, einer Änderung des Zertifikats oder vor einer Warnung über das Zurücksetzen auf die Werkseinstellungen die richtigen Sicherungen durchführen.
Vorsicht: clusterdb_destroy_and_purge_data.sh ist so gefährlich, wie es sich anhört - verwenden Sie diese Option als letztes Mittel.
Systemschlüssel-bezogene Probleme
Anmerkung: Die nächsten Informationen gelten ab der Version X14.
Fehler beim Aktualisieren der Schlüsseldatei-Alarme werden auf Expressways in einem Einzelknotenszenario ausgelöst.
Befolgen Sie die folgenden Schritte, um diese Art von Alarm zu beheben:
- Melden Sie sich über die CLI als admin an (standardmäßig über SSH und über den seriellen Port in Hardwareversionen verfügbar).
- Führen Sie den nächsten Befehl aus: xCommand ForceSystemKeyUpdate.
Fehler beim Aktualisieren der Schlüsseldatei-Alarme werden auf Expressways in einem Clusterszenario ausgelöst.
Befolgen Sie die folgenden Schritte, um diese Art von Alarm zu beheben:
- Melden Sie sich über die CLI (standardmäßig über SSH und über den seriellen Port auf Hardwareversionen verfügbar) als admin beim Knoten an, wenn dieser Alarm nicht ausgelöst wird.
- Führen Sie den nächsten Befehl aus: xCommand ForceSystemKeyUpdate.
Protokolldetails
Wie jedes andere Protokoll auf Expressway können Sie mit TCP-Dumps Diagnoseprotokolle aktivieren.
Im Normalzustand wird die DB-Synchronisierung auf dem Master-Knoten in den Protokollen als nächste Ausgabe angezeigt:
2020-07-21T15:16:50.321-05:00 expc01 replication: UTCTime="2020-07-21 20:16:50,321" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationsynchroniser(270)" Detail="Starting synchronisation"
2020-07-21T15:16:50.330-05:00 expc01 replication: UTCTime="2020-07-21 20:16:50,330" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationutils(750)" AlternateIPAddresses="[u'(10.15.13.15 expc01)', u'(10.15.13.16 expc02)']" ConfigurationMasterIndex="0" LocalPeerIndex="0"
2020-07-21T15:16:50.433-05:00 expc01 replication: UTCTime="2020-07-21 20:16:50,433" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationsynchroniser(257)" Detail="This peer is the cluster master, local configuration has already been replicated to the other peers"
2020-07-21T15:16:50.437-05:00 expc01 replication: UTCTime="2020-07-21 20:16:50,437" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationsynchroniser(336)" Detail="Synchronisation completed successfully"Aus Sicht des Peerknotens wird er als nächste Ausgabe angezeigt:
2020-07-21T15:16:46.900-05:00 expc02 replication: UTCTime="2020-07-21 20:16:46,899" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationsynchroniser(270)" Detail="Starting synchronisation"
2020-07-21T15:16:46.908-05:00 expc02 replication: UTCTime="2020-07-21 20:16:46,908" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationutils(750)" AlternateIPAddresses="[u'(10.15.13.15 expc01)', u'(10.15.13.16 expc02)']" ConfigurationMasterIndex="0" LocalPeerIndex="1"
2020-07-21T15:16:46.947-05:00 expc02 replication: UTCTime="2020-07-21 20:16:46,946" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationsynchroniser(254)" Detail="This peer is not the cluster master, local configuration is already up to date"
2020-07-21T15:16:46.950-05:00 expc02 replication: UTCTime="2020-07-21 20:16:46,950" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationsynchroniser(336)" Detail="Synchronisation completed successfully"In der nächsten Ausgabe wird eine Peer-Trennung angezeigt:
2020-08-12T14:57:43.353-05:00 expc01 UTCTime="2020-08-12 19:57:43,353" Module="developer.clusterdb.cdb" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.159.0>" Detail="Processed mnesia_down event from accessible node" Node="clusterdb@expc02.apolo.local"
2020-08-12T14:57:43.354-05:00 expc01 UTCTime="2020-08-12 19:57:43,353" Module="developer.clusterdb.cdb" Level="ERROR" Node="clusterdb@expc01.apolo.local" PID="<0.159.0>" Detail="Inconsistent Database" Context="from mnesia system - mnesia down" Node="clusterdb@expc02.apolo.local"
2020-08-12T14:57:43.354-05:00 expc01 UTCTime="2020-08-12 19:57:43,354" Module="developer.clusterdb.cdb" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.159.0>" Detail="Connecting database on mnesia running_partitioned_network event" Node="clusterdb@expc02.apolo.local"
2020-08-12T14:57:43.354-05:00 expc01 UTCTime="2020-08-12 19:57:43,354" Module="developer.clusterdb.cdb" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.14215.425>" Detail="Ready to perform node connection transaction" Node="clusterdb@expc02.apolo.local"
2020-08-12T14:57:43.354-05:00 expc01 UTCTime="2020-08-12 19:57:43,354" Module="developer.clusterdb.cdb" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.14215.425>" Detail="Running node connection transaction" Node="clusterdb@expc02.apolo.local"
2020-08-12T14:57:43.354-05:00 expc01 UTCTime="2020-08-12 19:57:43,354" Module="developer.clusterdb.synchronise" Level="WARN" Node="clusterdb@expc01.apolo.local" PID="<0.14215.425>" Detail="Failed connecting to node" Node="clusterdb@expc02.apolo.local" Reason="{ badrpc, { EXIT, { aborted, { noproc, { gen_server, call, [ kernel_safe_sup, { start_child, { dets_sup, { dets_sup, start_link, }, permanent, 1000, supervisor, [ dets_sup ] } }, infinity ] } } } } }"
2020-08-12T14:57:43.524-05:00 expc01 alarm: Level="WARN" Event="Alarm Raised" Id="20006" UUID="0f96695e-d954-4f6f-85c1-2ef1eae6f764" Severity="warning" Detail="Cluster database communication failure: The database is unable to replicate with one or more of the cluster peers" UTCTime="2020-08-12 19:57:43,524"
2020-08-12T14:57:43.771-05:00 expc01 alarm: Level="WARN" Event="Alarm Raised" Id="20004" UUID="3bca6888-f622-11df-93be-07cc953d7b99" Severity="warning" Detail="Cluster communication failure: The system is unable to communicate with one or more of the cluster peers" UTCTime="2020-08-12 19:57:43,771"
2020-08-12T14:57:53.872-05:00 expc01 tvcs: UTCTime="2020-08-12 19:57:53,871" Module="network.h323" Level="INFO": Action="Sent" Dst-ip="10.15.13.16" Dst-port="1719" Detail="Sending RAS SCI SeqNum=52319 Retransmit=True"
2020-08-12T14:57:54.872-05:00 expc01 tvcs: UTCTime="2020-08-12 19:57:54,871" Module="network.h323" Level="INFO": Action="Sent" Dst-ip="10.15.13.16" Dst-port="1719" Detail="Sending RAS LRQ SeqNum=52320 Retransmit=True"
2020-08-12T14:57:56.872-05:00 expc01 tvcs: UTCTime="2020-08-12 19:57:56,871" Module="network.h323" Level="INFO": Action="Sent" Dst-ip="10.15.13.16" Dst-port="1719" Detail="Sending RAS LRQ SeqNum=52320 Retransmit=True"
2020-08-12T14:57:57.871-05:00 expc01 tvcs: UTCTime="2020-08-12 19:57:57,871" Module="network.h323" Level="INFO": Action="Sent" Dst-ip="10.15.13.16" Dst-port="1719" Detail="Sending RAS SCI SeqNum=52319 Retransmit=True"
2020-08-12T14:57:58.871-05:00 expc01 tvcs: Event="External Server Communications Failure" Reason="gatekeeper timed out" Service="NeighbourGatekeeper" Detail="name:10.15.13.16:1719" Level="1" UTCTime="2020-08-12 19:57:58,871"
2020-08-12T14:57:58.871-05:00 expc01 tvcs: UTCTime="2020-08-12 19:57:58,871" Module="network.h323" Level="INFO": Action="Sent" Dst-ip="10.15.13.16" Dst-port="1719" Detail="Sending RAS LRQ SeqNum=52320 Timeout=True"
2020-08-12T14:57:59.601-05:00 expc01 UTCTime="2020-08-12 19:57:59,601" Module="developer.clusterdb.peernameresolver" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.145.0>" Detail="Triggering forced peer update of peers which failed DNS and queueing next run" Queue-Time-ms="300000"
2020-08-12T14:58:01.871-05:00 expc01 tvcs: UTCTime="2020-08-12 19:58:01,871" Module="network.h323" Level="INFO": Action="Sent" Dst-ip="10.15.13.16" Dst-port="1719" Detail="Sending RAS SCI SeqNum=52319 Timeout=True"
Die Änderung zu "TLS Enforcing" auf dem Master-Knoten wird in der nächsten Ausgabe angezeigt:
2020-08-12T15:13:24.970-05:00 expc01 UTCTime="2020-08-12 20:13:24,969" Module="developer.cdbtable.cdb.clusterConfiguration" Level="DEBUG" Node="clusterdb@expc01.apolo.local" PID="<0.345.0>" Detail="Inserting into table" TableName="clusterConfiguration"
2020-08-12T15:13:24.976-05:00 expc01 UTCTime="2020-08-12 20:13:24,975" Event="System Configuration Changed" Node="clusterdb@expc01.apolo.local" PID="<0.345.0>" Detail="xconfiguration clusterConfiguration tls_verify - changed from: Permissive to: Enforcing"
2020-08-12T15:13:24.976-05:00 expc01 httpd[15060]: web: Event="System Configuration Changed" Detail="configuration/cluster/tls_verify - changed from: 'Permissive' to: 'Enforcing'" Src-ip="10.15.13.30" Src-port="53155" User="admin" Level="1" UTCTime="2020-08-12 20:13:24"
2020-08-12T15:13:24.979-05:00 expc01 management: UTCTime="2020-08-12 20:13:24,978" Module="developer.management.databasemanager" Level="INFO" CodeLocation="databasemanager(312)" Detail="Cluster configuration change detected"
2020-08-12T15:13:24.980-05:00 expc01 UTCTime="2020-08-12 20:13:24,980" Module="developer.cdbtable.cdb.clusterConfiguration" Level="DEBUG" Node="clusterdb@expc01.apolo.local" PID="<0.345.0>" Detail="Inserting into table" TableName="clusterConfiguration"
2020-08-12T15:13:24.986-05:00 expc01 management: UTCTime="2020-08-12 20:13:24,986" Module="developer.management.databasemanager" Level="INFO" CodeLocation="databasemanager(405)" Detail="TLS Verify change status" Startup="False" New="True"
2020-08-12T15:13:25.022-05:00 expc01 UTCTime="2020-08-12 20:13:25,022" Event="System Configuration Changed" Node="clusterdb@expc01.apolo.local" PID="<0.557.0>" Detail="xconfiguration alternatesConfiguration - Changed"
2020-08-12T15:13:25.022-05:00 expc01 UTCTime="2020-08-12 20:13:25,022" Module="developer.clusterdb.peernameresolver" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.145.0>" Detail="Notifying databasemanager (Management Framework)"
2020-08-12T15:13:25.022-05:00 expc01 UTCTime="2020-08-12 20:13:25,022" Module="developer.clusterdb.alternatesmanager" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.142.0>" Detail="alternate peer changed info recieved"
2020-08-12T15:13:25.031-05:00 expc01 UTCTime="2020-08-12 20:13:25,031" Event="System Configuration Changed" Node="clusterdb@expc01.apolo.local" PID="<0.557.0>" Detail="xconfiguration alternatesConfiguration - Changed"
2020-08-12T15:13:25.192-05:00 expc01 management: UTCTime="2020-08-12 20:13:25,192" Module="developer.diagnostics.alarmmanager" Level="INFO" CodeLocation="alarmmanager(173)" Detail="Raising alarm" UUID="e2b8e3d1-b731-4d7d-b606-4682a8f0c2e6" Parameters="null"
2020-08-12T15:13:25.195-05:00 expc01 management: Level="WARN" Event="Alarm Raised" Id="20007" UUID="e2b8e3d1-b731-4d7d-b606-4682a8f0c2e6" Severity="warning" Detail="Restart required: Cluster configuration has been changed, however a restart is required for this to take effect" UTCTime="2020-08-12 20:13:25,194"
Aus der Perspektive des Peer-Knotens wird er in der nächsten Ausgabe dargestellt:
2020-08-12T15:13:24.976-05:00 expc02 UTCTime="2020-08-12 20:13:24,976" Event="System Configuration Changed" Node="clusterdb@expc02.apolo.local" PID="<0.390.0>" Detail="xconfiguration clusterConfiguration tls_verify - changed from: Permissive to: Enforcing"
2020-08-12T15:13:24.979-05:00 expc02 management: UTCTime="2020-08-12 20:13:24,978" Module="developer.management.databasemanager" Level="INFO" CodeLocation="databasemanager(312)" Detail="Cluster configuration change detected"
2020-08-12T15:13:24.982-05:00 expc02 management: UTCTime="2020-08-12 20:13:24,982" Module="developer.management.databasemanager" Level="INFO" CodeLocation="databasemanager(405)" Detail="TLS Verify change status" Startup="False" New="True"
2020-08-12T15:13:25.040-05:00 expc02 UTCTime="2020-08-12 20:13:25,040" Module="developer.clusterdb.peernameresolver" Level="INFO" Node="clusterdb@expc02.apolo.local" PID="<0.136.0>" Detail="Notifying databasemanager (Management Framework)"
2020-08-12T15:13:25.040-05:00 expc02 UTCTime="2020-08-12 20:13:25,040" Module="developer.clusterdb.alternatesmanager" Level="INFO" Node="clusterdb@expc02.apolo.local" PID="<0.143.0>" Detail="alternate peer changed info recieved"
2020-08-12T15:13:25.041-05:00 expc02 UTCTime="2020-08-12 20:13:25,041" Event="System Configuration Changed" Node="clusterdb@expc02.apolo.local" PID="<0.543.0>" Detail="xconfiguration alternatesConfiguration - Changed"
2020-08-12T15:13:25.042-05:00 expc02 UTCTime="2020-08-12 20:13:25,042" Event="System Configuration Changed" Node="clusterdb@expc02.apolo.local" PID="<0.543.0>" Detail="xconfiguration alternatesConfiguration - Changed"
2020-08-12T15:13:25.046-05:00 expc02 UTCTime="2020-08-12 20:13:25,046" Module="developer.clusterdb.alternatesmanager" Level="INFO" Node="clusterdb@expc02.apolo.local" PID="<0.143.0>" Detail="alternate peer changed info recieved"
2020-08-12T15:13:25.047-05:00 expc02 UTCTime="2020-08-12 20:13:25,046" Module="developer.clusterdb.peernameresolver" Level="INFO" Node="clusterdb@expc02.apolo.local" PID="<0.136.0>" Detail="Notifying databasemanager (Management Framework)"
2020-08-12T15:13:25.047-05:00 expc02 UTCTime="2020-08-12 20:13:25,047" Event="System Configuration Changed" Node="clusterdb@expc02.apolo.local" PID="<0.543.0>" Detail="xconfiguration alternatesConfiguration - Changed"
2020-08-12T15:13:25.049-05:00 expc02 UTCTime="2020-08-12 20:13:25,049" Event="System Configuration Changed" Node="clusterdb@expc02.apolo.local" PID="<0.543.0>" Detail="xconfiguration alternatesConfiguration - Changed"
2020-08-12T15:13:25.136-05:00 expc02 management: UTCTime="2020-08-12 20:13:25,136" Module="developer.diagnostics.alarmmanager" Level="INFO" CodeLocation="alarmmanager(173)" Detail="Raising alarm" UUID="e2b8e3d1-b731-4d7d-b606-4682a8f0c2e6" Parameters="null"
2020-08-12T15:13:25.139-05:00 expc02 management: Level="WARN" Event="Alarm Raised" Id="20007" UUID="e2b8e3d1-b731-4d7d-b606-4682a8f0c2e6" Severity="warning" Detail="Restart required: Cluster configuration has been changed, however a restart is required for this to take effect" UTCTime="2020-08-12 20:13:25,139"
Videos
Die nächsten Videos könnten nützlich sein:
Erstellen und Hinzufügen eines Peers zu einem Expressway-Cluster
Entfernen eines Peers aus einem Expressway-Cluster
Beheben des Expressway-Replikationsfehlers "Peer-Konfigurationskonflikte mit primärem"
Expressway-Cluster - Neustartprozedur
So aktualisieren Sie einen Expressway-ClusterErstellen eines CSR für MRA/Cluster-Expressways
Revisionsverlauf
| Überarbeitung | Veröffentlichungsdatum | Kommentare |
|---|---|---|
1.0 |
02-Jul-2021
|
Erstveröffentlichung |
Beiträge von Cisco Ingenieuren
- Jefferson Madriz
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)