Wählen Sie im Navigationsfenster Troubleshoot > Cluster Status aus.
Der Cluster-Status zeigt den Status aller Server im Cisco Secure Workload-Rack an. Ein funktionierender Server kann den Status "Kommissioniert" und "Aktiv" anzeigen, wie hier dargestellt.
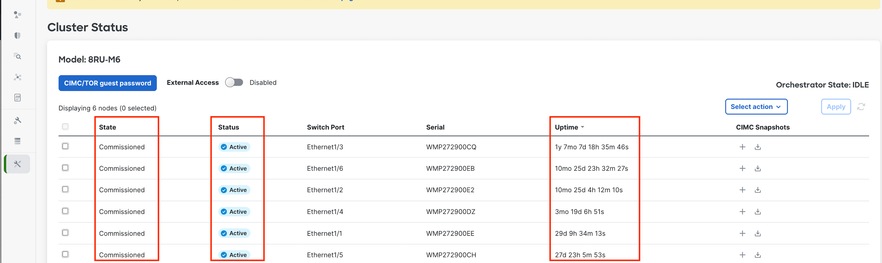

Vorsicht: Wenn Sie auf der Cluster-Statusseite einen Knoten feststellen, der als inaktiv markiert ist, erstellen Sie einen CIMC-Snapshot, und erstellen Sie ein TAC-Ticket, einschließlich des Snapshots.
Wenn der Status als Inaktiv angezeigt wird, bedeutet dies in der Regel, dass der Server entweder ausgeschaltet ist oder aufgrund eines Hardware-, Kabel- oder Verbindungsproblems ausfällt.
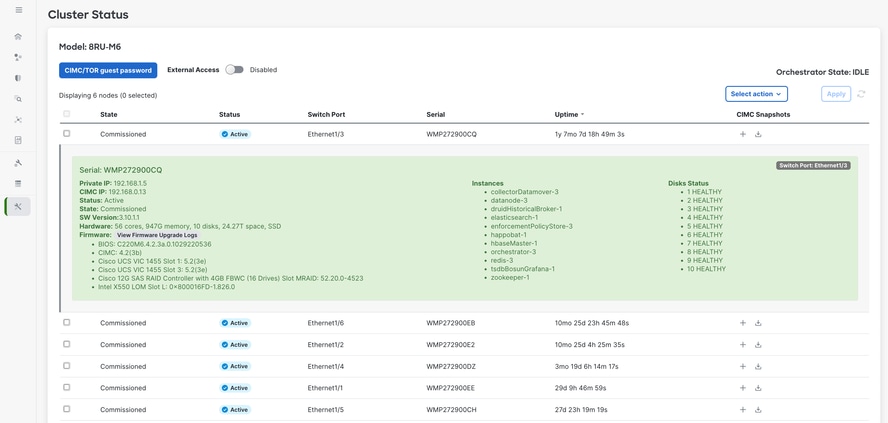
Wenn Sie auf einen Server in der Liste klicken, werden weitere Details angezeigt, z. B.
・ Die virtuellen Systeme (Instanzen), die auf diesem physischen Server ausgeführt werden
・ Die private IP-Adresse des Servers im Cluster
・ CIMC-IP-Adresse (Management)
・ Aktuelle Firmware-Versionen für BIOS, CIMC, VIC-Karte, LOM-Karte und RAID-Controller
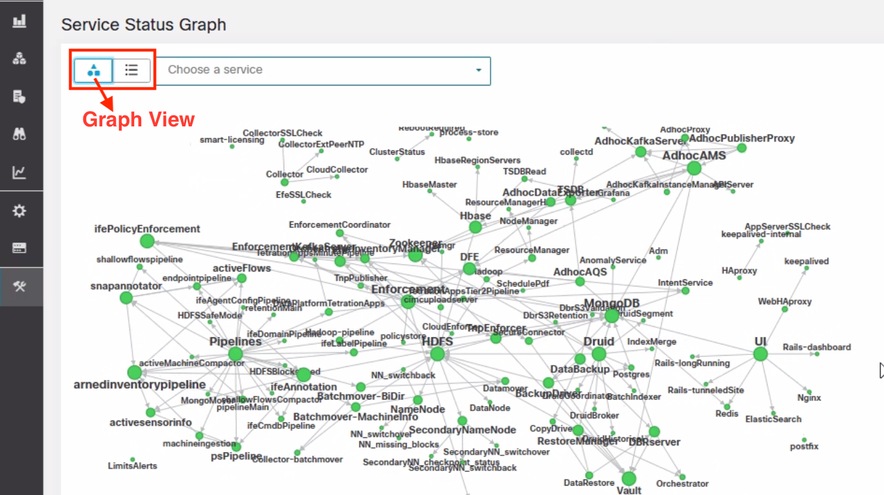
Servicestatus
Die Seite Service Status (Service-Status) befindet sich im linken Navigationsbereich unter
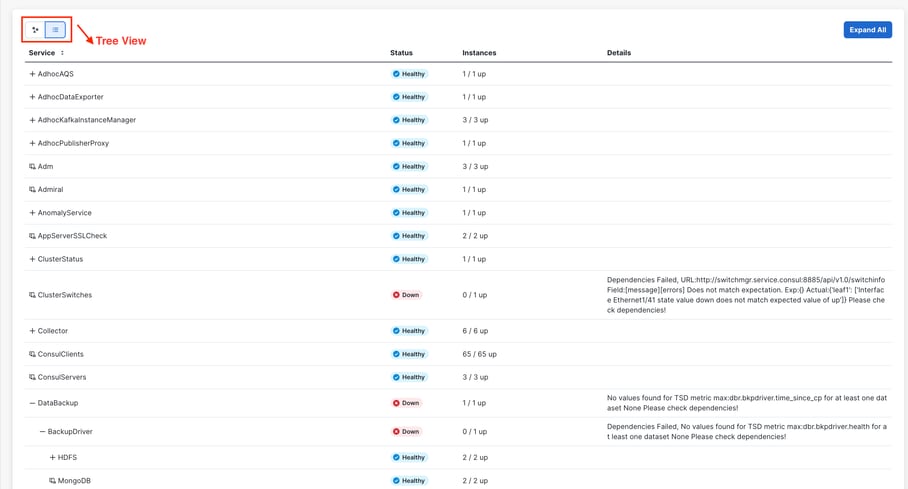
Seite "Service Status" (Service-Status) werden der Status aller Services angezeigt, die in Ihrem Cisco Secure Workload-Cluster verwendet werden, sowie deren Abhängigkeiten.
Die Diagrammansicht zeigt den Zustand des Diensts an, jeder Knoten im Diagramm zeigt den Zustand des Diensts an, und ein Edge stellt die Abhängigkeit von anderen Diensten dar. Dienste, die nicht ordnungsgemäß funktionieren, werden rot markiert, wenn der Dienst nicht verfügbar ist, und orange, wenn der Dienst heruntergestuft, aber verfügbar ist. Eine grüne Farbe oder eine himmelblaue Farbe weist darauf hin, dass der Service fehlerfrei ist. Weitere Debuginformationen zu diesen Knoten finden Sie in der Strukturansicht mit der SchaltflächeAlle erweitern, um alle untergeordneten Knoten im Abhängigkeitsbaum anzuzeigen. Down zeigt an, dass der Dienst nicht funktioniert, und Ungesund zeigt an, dass der Dienst nicht voll funktionsfähig ist.

Anmerkung: Ab Patch-Version 3.10.2.11 wird die Service-Statusseite in Himmelblau angezeigt. Eine grüne Farbe oder eine himmelblaue Farbe weist darauf hin, dass der Service fehlerfrei ist.
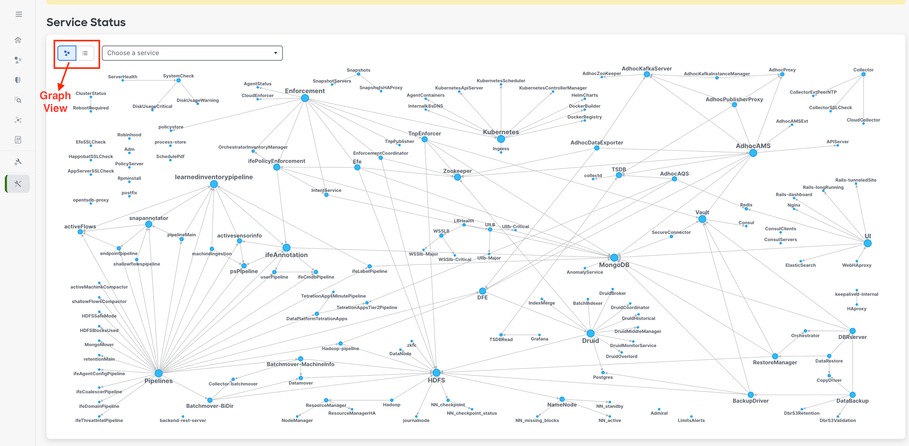
Standardmäßig werden auf der Seite Service Status (Dienststatus) die Clusterfunktionen und -abhängigkeiten in einer grafischen Ansicht angezeigt. Wenn alle Symbole grün oder himmelblau sind, wird kein Fehler erkannt.
Wenn ein Service in Rot oder Orange angezeigt wird, zeigt die Baumstruktur die Liste der Services an und ermöglicht Ihnen, die Abhängigkeiten des Service sowie weitere Details anzuzeigen, die von der Funktion "Service Status" erkannt wurden. Diese Informationen zu Abhängigkeitsfehlern sollten beim Öffnen eines Tickets beim TAC unbedingt notiert und erfasst werden.
Vorsicht: Wenn Sie feststellen, dass ein Servicefall defekt ist und eine rote Farbe aufweist, wenden Sie sich an das Technical Assistance Center (TAC), um Unterstützung bei der Behebung dieser Probleme zu erhalten. Schnelle Kontaktaufnahme mit dem TAC zur Wiederherstellung der vollen Funktionalität
Hawkeye (Diagramme)
Hawkeye-Dashboards bieten Einblick in den Status des sicheren Workload-Clusters sowie Metriken und Informationen zur Unterstützung der Fehlerbehebung
Die Seite Hawkeye (Diagramme) befindet sich im linken Navigationsbereich unter
Wenn Sie auf Hawkeye (Diagramme) klicken, wird automatisch eine neue Browserregisterkarte geöffnet, auf der das Hawkeye-Dashboard wie hier dargestellt angezeigt wird.
Klicken Sie im Hawkeye-Dashboard auf die Registerkarte Spark Pipeline Current (Spark Pipeline Aktuell), um den Status des sicheren Workload-Clusters zu überwachen.
Überprüfen Sie auf der Seite Spark Pipeline Current (Aktuelle Spark-Pipeline), ob die Werte für End-to-End-Verzögerung, Serving Layer-Verzögerung, Main Pipeline Latency (Hauptpipelinelatenz) und Active Flow Latency (Aktive Flow-Latenz) unter 10 Minuten liegen.
Stellen Sie außerdem sicher, dass die Laufzeitwerte weniger als 1 Minute betragen und in Sekunden angezeigt werden und der HDFS-Status "Good" (Gut) lautet, wie im nächsten Beispiel gezeigt.
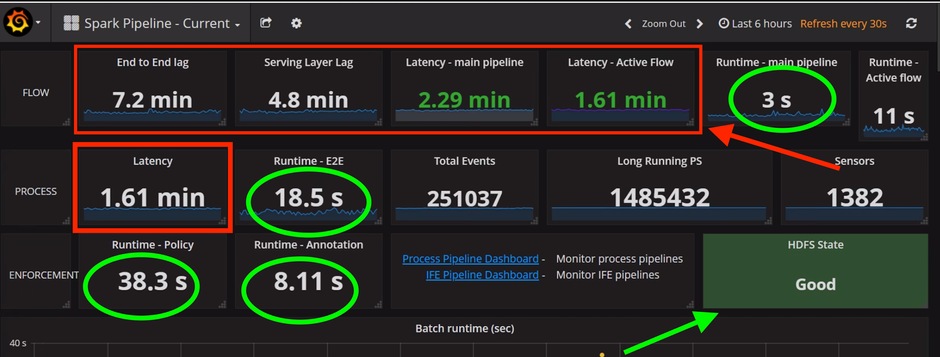
Vorsicht: Wenn Sie Latenzwerte (einschließlich End-to-End-Verzögerung oder Verzögerung auf dem Service-Layer) von mehr als 6 Stunden beobachten, ohne eine allmähliche Verringerung festzustellen, wenden Sie sich an das Technical Assistance Center (TAC).
Upgrade-Prechecks
Verwenden Sie vor und nach Wartungsaufgaben die Upgrade-Vorabprüfung, um Cluster-Zustandsprüfungen auszuführen. Dieser Prozess stellt sicher, dass Services, Konfigurationen und Hardwarekomponenten ordnungsgemäß funktionieren.
-
Navigieren Sie zuUpgrade Precheck.
Navigieren Sie zu TetrationUI, und befolgen Sie die folgenden Schritte:
-
Klicken Sie auf Plattform.
-
Wählen Sie Upgrade/Neustart/Herunterfahren aus.
-
Klicken Sie auf Upgrade PreCheck starten.
Warten Sie einige Minuten auf die Ausgabe der Upgrade-Vorprüfungen. Wenn alles wie in diesem Bild gezeigt erfolgreich ist, können Sie mit den nächsten Aktionen der Clusterwartungsaktivitäten fortfahren.
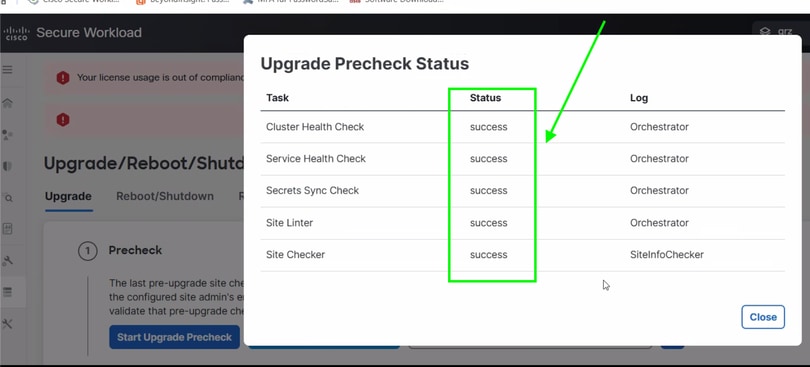
Vorsicht: Wenn die Upgrade-Vorabprüfung nicht erfolgreich war, wenden Sie sich an das Technical Assistance Center (TAC).
|
 Feedback
Feedback