Austausch der Hauptplatine im Ultra-M UCS 240M4 Server - CPAR
Download-Optionen
-
ePub (3.7 MB)
In verschiedenen Apps auf iPhone, iPad, Android, Sony Reader oder Windows Phone anzeigen
Inklusive Sprache
In dem Dokumentationssatz für dieses Produkt wird die Verwendung inklusiver Sprache angestrebt. Für die Zwecke dieses Dokumentationssatzes wird Sprache als „inklusiv“ verstanden, wenn sie keine Diskriminierung aufgrund von Alter, körperlicher und/oder geistiger Behinderung, Geschlechtszugehörigkeit und -identität, ethnischer Identität, sexueller Orientierung, sozioökonomischem Status und Intersektionalität impliziert. Dennoch können in der Dokumentation stilistische Abweichungen von diesem Bemühen auftreten, wenn Text verwendet wird, der in Benutzeroberflächen der Produktsoftware fest codiert ist, auf RFP-Dokumentation basiert oder von einem genannten Drittanbieterprodukt verwendet wird. Hier erfahren Sie mehr darüber, wie Cisco inklusive Sprache verwendet.
Informationen zu dieser Übersetzung
Cisco hat dieses Dokument maschinell übersetzen und von einem menschlichen Übersetzer editieren und korrigieren lassen, um unseren Benutzern auf der ganzen Welt Support-Inhalte in ihrer eigenen Sprache zu bieten. Bitte beachten Sie, dass selbst die beste maschinelle Übersetzung nicht so genau ist wie eine von einem professionellen Übersetzer angefertigte. Cisco Systems, Inc. übernimmt keine Haftung für die Richtigkeit dieser Übersetzungen und empfiehlt, immer das englische Originaldokument (siehe bereitgestellter Link) heranzuziehen.
Inhalt
Einleitung
In diesem Dokument werden die Schritte beschrieben, die erforderlich sind, um ein fehlerhaftes Motherboard eines Servers in einer Ultra-M-Konfiguration zu ersetzen.
Dieses Verfahren gilt für eine OpenStack-Umgebung mit der NEWTON-Version, in der ESC CPAR nicht verwaltet und CPAR direkt auf dem auf OpenStack bereitgestellten virtuellen System installiert ist.
Hintergrundinformationen
Ultra-M ist eine vorkonfigurierte und validierte virtualisierte Mobile Packet Core-Lösung, die die Bereitstellung von VNFs vereinfacht. OpenStack ist der Virtualized Infrastructure Manager (VIM) für Ultra-M und besteht aus den folgenden Knotentypen:
- Computing
- Objektspeicherplatte - Computing (OSD - Computing)
- Controller
- OpenStack-Plattform - Director (OSPD)
Die High-Level-Architektur von Ultra-M und die beteiligten Komponenten sind in diesem Bild dargestellt:
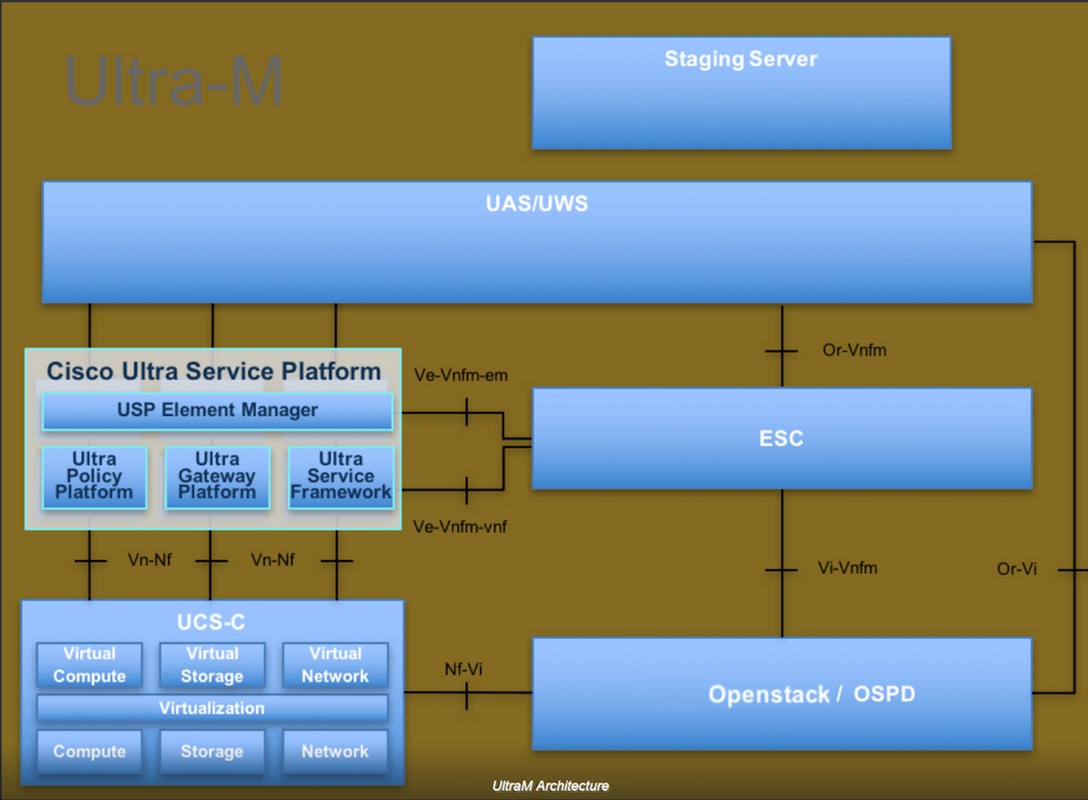
Dieses Dokument richtet sich an Cisco Mitarbeiter, die mit der Cisco Ultra-M-Plattform vertraut sind. Es beschreibt die erforderlichen Schritte für OpenStack und Redhat OS.
Anmerkung: Die Ultra M 5.1.x-Version wird bei der Definition der in diesem Dokument beschriebenen Verfahren berücksichtigt.
Abkürzungen
| MOPP | Verfahrensweise |
| OSD | Objektspeicherplatten |
| OSPD | OpenStack Platform Director |
| Festplatte | Festplattenlaufwerk |
| SSD | Solid-State-Laufwerk |
| VIM | Manager für virtuelle Infrastruktur |
| VM | Virtuelles System |
| EM | Element-Manager |
| USA | Ultra-Automatisierungsservices |
| UUID | Universeller eindeutiger IDentifier |
Workflow des MoP
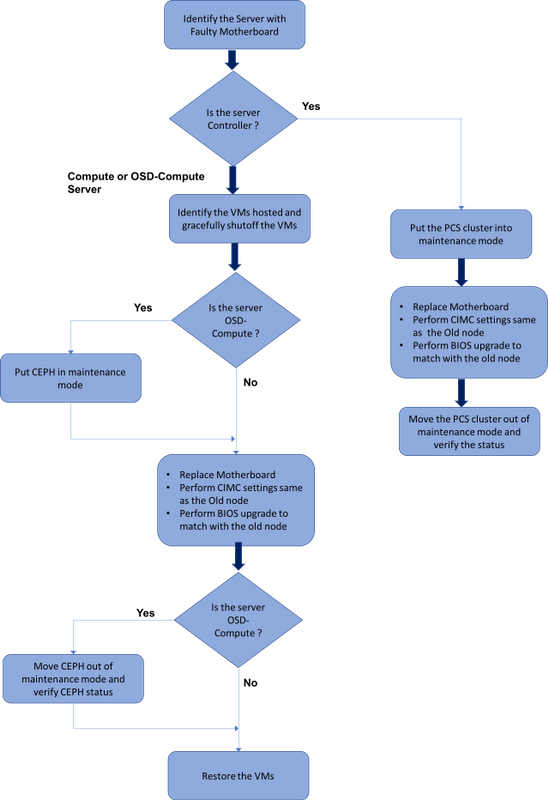
Austausch der Hauptplatine im Ultra-M-Setup
In einer Ultra-M-Konfiguration kann es Szenarien geben, in denen ein Austausch der Hauptplatine bei den folgenden Servertypen erforderlich ist: Computing, OSD-Computing und Controller.
Anmerkung: Die Boot-Laufwerke mit dem OpenStack-Einbau werden nach dem Austausch des Motherboards ausgetauscht. Daher besteht keine Notwendigkeit, den Knoten wieder in die Overcloud einzubinden. Sobald der Server nach der Ersetzungsaktivität eingeschaltet wird, registriert er sich selbst wieder beim Overcloud-Stack.
Voraussetzungen
Bevor Sie einen Compute-Knoten ersetzen, ist es wichtig, den aktuellen Status Ihrer Red Hat OpenStack Platform-Umgebung zu überprüfen. Es wird empfohlen, den aktuellen Status zu überprüfen, um Komplikationen zu vermeiden, wenn der Compute-Ersetzungsvorgang aktiviert ist. Dies kann durch diesen Austausch erreicht werden.
Im Falle einer Wiederherstellung empfiehlt Cisco, eine Sicherung der OSPD-Datenbank mit folgenden Schritten durchzuführen:
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql [root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql /etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack tar: Removing leading `/' from member names
Dieser Prozess stellt sicher, dass ein Knoten ersetzt werden kann, ohne die Verfügbarkeit von Instanzen zu beeinträchtigen.
Anmerkung: Stellen Sie sicher, dass Sie über den Snapshot der Instanz verfügen, damit Sie die VM bei Bedarf wiederherstellen können. Befolgen Sie dieses Verfahren, um einen Snapshot des virtuellen Systems zu erstellen.
Austausch der Hauptplatine im Rechenknoten
Vor der Aktivität werden die im Rechenknoten gehosteten VMs ordnungsgemäß deaktiviert. Sobald die Hauptplatine ausgetauscht wurde, werden die virtuellen Systeme wiederhergestellt.
Identifizieren der im Rechenknoten gehosteten VMs
[stack@al03-pod2-ospd ~]$ nova list --field name,host +--------------------------------------+---------------------------+----------------------------------+ | ID | Name | Host | +--------------------------------------+---------------------------+----------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | pod2-stack-compute-4.localdomain | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | pod2-stack-compute-3.localdomain | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | pod2-stack-compute-3.localdomain | +--------------------------------------+---------------------------+----------------------------------+
Anmerkung: In der hier gezeigten Ausgabe entspricht die erste Spalte dem Universally Unique IDentifier (UUID), die zweite Spalte ist der VM-Name und die dritte Spalte ist der Hostname, in dem die VM vorhanden ist. Die Parameter aus dieser Ausgabe werden in nachfolgenden Abschnitten verwendet.
Sicherung: Snapshot-Prozess
Schritt 1: Herunterfahren der CPAR-Anwendung.
Schritt 1:Öffnen Sie einen beliebigen SSH-Client, der mit dem Netzwerk verbunden ist, und stellen Sie eine Verbindung zur CPAR-Instanz her.
Es ist wichtig, dass nicht alle vier AAA-Instanzen an einem Standort gleichzeitig heruntergefahren werden, sondern nur eine nach der anderen.
Schritt 2:Herunterfahren der CPAR-Anwendung mit diesem Befehl:
/opt/CSCOar/bin/arserver stop A Message stating “Cisco Prime Access Registrar Server Agent shutdown complete.” Should show up
Wenn ein Benutzer eine CLI-Sitzung geöffnet hat, funktioniert der Befehl arserver stop nicht, und die folgende Meldung wird angezeigt:
ERROR: You can not shut down Cisco Prime Access Registrar while the CLI is being used. Current list of running CLI with process id is: 2903 /opt/CSCOar/bin/aregcmd –s
In diesem Beispiel muss die hervorgehobene Prozess-ID 2903 beendet werden, bevor CPAR beendet werden kann. Wenn dies der Fall ist, beenden Sie den Vorgang mit folgendem Befehl:
kill -9 *process_id*
Wiederholen Sie dann Schritt 1.
Schritt 3:Überprüfen Sie mit dem folgenden Befehl, ob die CPAR-Anwendung tatsächlich heruntergefahren wurde:
/opt/CSCOar/bin/arstatus
Diese Meldung sollte angezeigt werden:
Cisco Prime Access Registrar Server Agent not running Cisco Prime Access Registrar GUI not running
VM-Snapshot-Aufgabe
Schritt 1:Geben Sie die Website der grafischen Benutzeroberfläche von Horizon ein, die der Website (Stadt) entspricht, an der derzeit gearbeitet wird.
Beim Zugriff auf Horizon wird dieser Bildschirm angezeigt:
Schritt 2:Navigieren Sie zu Projekt > Instanzen, wie im Bild dargestellt.
War der verwendete Benutzer CPAR, werden in diesem Menü nur die 4 AAA-Instanzen angezeigt.
Schritt 3:Fahren Sie jeweils nur eine Instanz herunter. Wiederholen Sie den gesamten Vorgang in diesem Dokument.
Um die VM herunterzufahren, navigieren Sie zu Aktionen > Instanz herunterfahren und bestätigen Sie Ihre Auswahl.

Schritt 4:Überprüfen Sie Status = Shutoff (Status = Herunterfahren) und Power State = Shut Down (Status = Herunterfahren), um sicherzustellen, dass die Instanz tatsächlich heruntergefahren wurde.
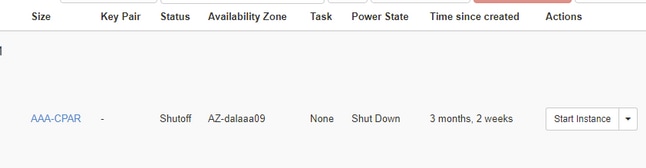
Dieser Schritt beendet das Herunterfahren der CPAR-Software.
VM-Snapshot
Wenn die virtuellen CPAR-Systeme ausgefallen sind, können die Snapshots parallel erstellt werden, da sie zu unabhängigen Computern gehören.
Die vier QCOW2-Dateien werden parallel erstellt.
Erstellen eines Snapshots für jede AAA-Instanz (25 Minuten -1 Stunde) (25 Minuten für Instanzen, die ein QoCow-Image als Quelle verwendet haben, und 1 Stunde für Instanzen, die ein Raw-Image als Quelle verwenden)
Schritt 1: Melden Sie sich bei OpenStack's Horizon am POD an.GUI.
Schritt 2: Fahren Sie nach der Anmeldung mit dem Abschnitt Projekt > Berechnen > Instanzen im oberen Menü fort, und suchen Sie nach den AAA-Instanzen.
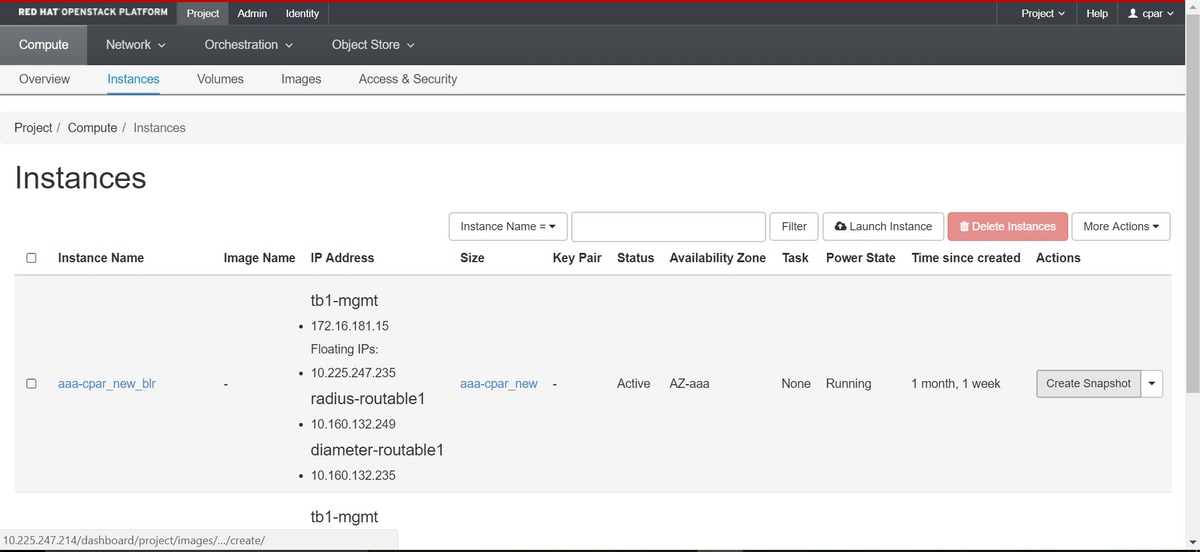
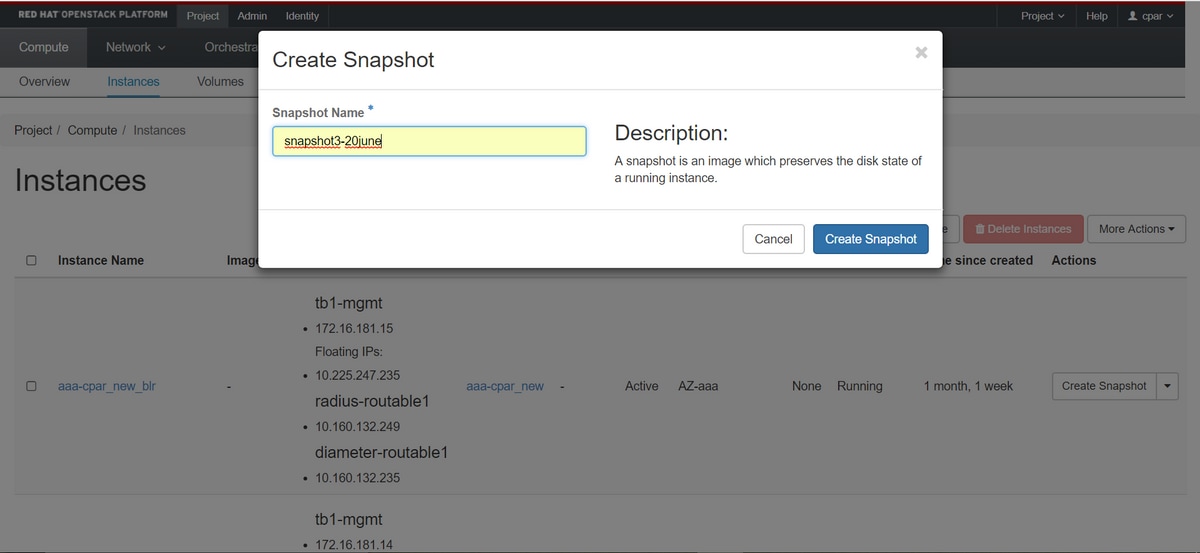
Schritt 3: Klicken Sie auf die Schaltfläche Snapshot erstellen, um mit der Snapshot-Erstellung fortzufahren (diese muss für die entsprechende AAA-Instanz ausgeführt werden).
Schritt 4: Nachdem der Snapshot ausgeführt wurde, navigieren Sie zum Menü IMAGES und überprüfen Sie, ob alle Vorgänge abgeschlossen sind und keine Probleme gemeldet werden.
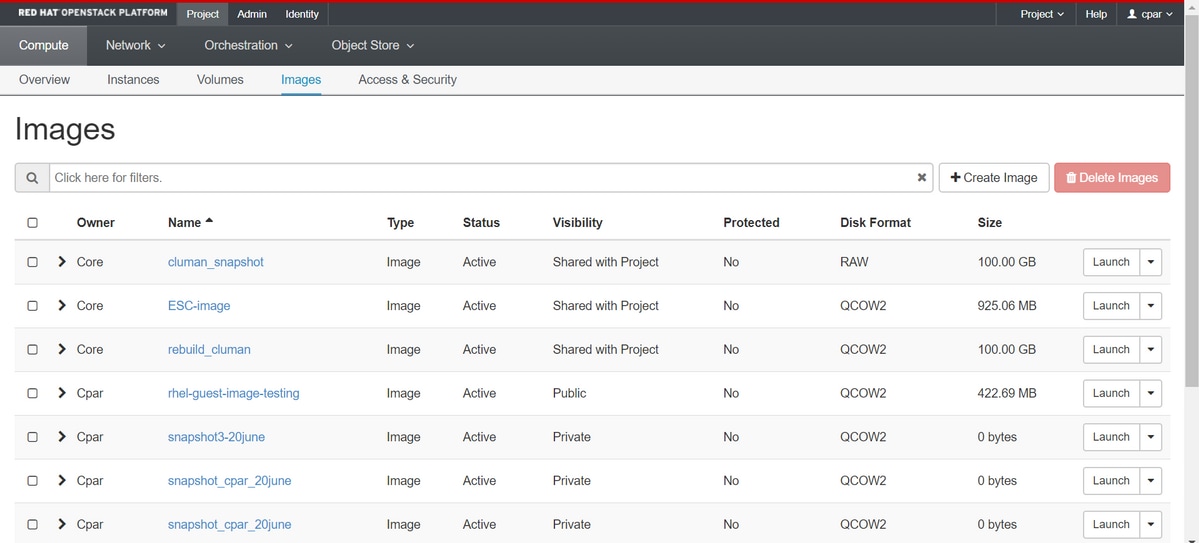
Schritt 5: Der nächste Schritt besteht darin, den Snapshot im QCOW2-Format herunterzuladen und auf eine entfernte Entität zu übertragen, falls die OSPD während dieses Vorgangs verloren geht. Um dies zu erreichen, identifizieren Sie den Snapshot mit diesem Befehl glance image-list auf OSPD-Ebene.
[root@elospd01 stack]# glance image-list +--------------------------------------+---------------------------+ | ID | Name | +--------------------------------------+---------------------------+ | 80f083cb-66f9-4fcf-8b8a-7d8965e47b1d | AAA-Temporary | | 22f8536b-3f3c-4bcc-ae1a-8f2ab0d8b950 | ELP1 cluman 10_09_2017 | | 70ef5911-208e-4cac-93e2-6fe9033db560 | ELP2 cluman 10_09_2017 | | e0b57fc9-e5c3-4b51-8b94-56cbccdf5401 | ESC-image | | 92dfe18c-df35-4aa9-8c52-9c663d3f839b | lgnaaa01-sept102017 | | 1461226b-4362-428b-bc90-0a98cbf33500 | tmobile-pcrf-13.1.1.iso | | 98275e15-37cf-4681-9bcc-d6ba18947d7b | tmobile-pcrf-13.1.1.qcow2 | +--------------------------------------+---------------------------+
Schritt 6. Nachdem Sie den herunterzuladenden Snapshot identifiziert haben (in diesem Fall wird der oben in Grün markierte Snapshot sein), laden Sie ihn im QCOW2-Format mit dem Befehl glance image-download herunter, wie hier dargestellt.
[root@elospd01 stack]# glance image-download 92dfe18c-df35-4aa9-8c52-9c663d3f839b --file /tmp/AAA-CPAR-LGNoct192017.qcow2 &
- Das "&" sendet den Prozess in den Hintergrund. Es wird einige Zeit dauern, bis diese Aktion abgeschlossen ist. Sobald dies geschehen ist, kann sich das Abbild im Verzeichnis /tmp befinden.
- Wenn beim Senden des Prozesses in den Hintergrund die Verbindung unterbrochen wird, wird der Prozess ebenfalls beendet.
- Führen Sie den Befehl "dissown -h" aus, damit der Prozess im Falle des Verlusts der SSH-Verbindung weiterhin auf der OSPD ausgeführt und beendet wird.
Schritt 7: Nachdem der Download-Prozess abgeschlossen ist, muss ein Komprimierungsprozess ausgeführt werden, da dieser Snapshot aufgrund von Prozessen, Aufgaben und temporären Dateien, die vom Betriebssystem verarbeitet werden, möglicherweise mit NULL gefüllt wird. Der für die Dateikomprimierung zu verwendende Befehl lautet virt-sparsify.
[root@elospd01 stack]# virt-sparsify AAA-CPAR-LGNoct192017.qcow2 AAA-CPAR-LGNoct192017_compressed.qcow2
Dieser Vorgang dauert einige Zeit (etwa 10-15 Minuten). Nach Fertigstellung ist die resultierende Datei diejenige, die wie im nächsten Schritt angegeben auf eine externe Entität übertragen werden muss.
Um dies zu erreichen, muss die Integrität der Datei überprüft werden. Führen Sie den nächsten Befehl aus, und suchen Sie nach dem Attribut "corrupt" am Ende der Ausgabe.
[root@wsospd01 tmp]# qemu-img info AAA-CPAR-LGNoct192017_compressed.qcow2 image: AAA-CPAR-LGNoct192017_compressed.qcow2 file format: qcow2 virtual size: 150G (161061273600 bytes) disk size: 18G cluster_size: 65536 Format specific information: compat: 1.1 lazy refcounts: false refcount bits: 16 corrupt: false
Um ein Problem zu vermeiden, bei dem das OSPD verloren geht, muss der kürzlich erstellte Snapshot im QCOW2-Format auf eine externe Einheit übertragen werden. Bevor Sie mit der Dateiübertragung beginnen, müssen wir prüfen, ob das Ziel über genügend freien Speicherplatz verfügt. Verwenden Sie den Befehl "df -kh", um den Speicherplatz zu überprüfen. Es wird empfohlen, die Datei mithilfe von SFTP "sftproot@x.x.x.x", wobei x.x.x.x die IP-Adresse einer Remote-OSPD ist, vorübergehend in die OSPD eines anderen Standorts zu übertragen. Um die Übertragung zu beschleunigen, kann das Ziel an mehrere OSPDs gesendet werden. Auf die gleiche Weise können wir den folgenden Befehl scp *name_of_the_file*.qcow2 root@ x.x.x.x:/tmp verwenden (wobei x.x.x.x die IP-Adresse eines Remote-OSPD ist), um die Datei in ein anderes OSPD zu übertragen.
Sicheres Ausschalten
Knoten zum Ausschalten
- So schalten Sie die Instanz aus: nova stop <INSTANCE_NAME>
- Jetzt sehen Sie den Instanznamen mit dem Status shutoff.
[stack@director ~]$ nova stop aaa2-21 Request to stop server aaa2-21 has been accepted. [stack@director ~]$ nova list +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | ID | Name | Status | Task State | Power State | Networks | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | ACTIVE | - | Running | tb1-mgmt=172.16.181.14, 10.225.247.233; radius-routable1=10.160.132.245; diameter-routable1=10.160.132.231 | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | SHUTOFF | - | Shutdown | diameter-routable1=10.160.132.230; radius-routable1=10.160.132.248; tb1-mgmt=172.16.181.7, 10.225.247.234 | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | ACTIVE | - | Running | diameter-routable1=10.160.132.233; radius-routable1=10.160.132.244; tb1-mgmt=172.16.181.10 | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+
Hauptplatine austauschen
Die Schritte zum Austauschen der Hauptplatine in einem UCS C240 M4 Server können dem Cisco UCS C240 M4 Server-Installations- und Serviceleitfaden entnommen werden.
- Melden Sie sich mit der CIMC-IP beim Server an.
- Führen Sie ein BIOS-Upgrade durch, wenn die Firmware nicht der zuvor verwendeten empfohlenen Version entspricht. Die Schritte für das BIOS-Upgrade sind hier aufgeführt: Cisco UCS Rackmount-Server der C-Serie - BIOS-Upgrade-Leitfaden
Stellen Sie die VMs wieder her
Wiederherstellen einer Instanz durch Snapshot
Wiederherstellungsprozess
Es ist möglich, die vorherige Instanz mit dem Snapshot, der in den vorherigen Schritten erstellt wurde, erneut bereitzustellen.
Schritt 1 [OPTIONAL].Wenn kein vorheriger VMshot verfügbar ist, stellen Sie eine Verbindung mit dem OSPD-Knoten her, an den die Sicherung gesendet wurde, und setzen Sie die Sicherung auf den ursprünglichen OSPD-Knoten zurück. Verwenden Sie "sftproot@x.x.x.x", wobei x.x.x.x die IP-Adresse des ursprünglichen OSPD ist. Speichern Sie die Snapshot-Datei im Verzeichnis /tmp.
Schritt 2:Stellen Sie eine Verbindung mit dem OSPD-Knoten her, in dem die Instanz erneut bereitgestellt wird.
 Sourcen Sie die Umgebungsvariablen mit dem folgenden Befehl:
Sourcen Sie die Umgebungsvariablen mit dem folgenden Befehl:
# source /home/stack/pod1-stackrc-Core-CPAR
Schritt 3:Um den Snapshot als Image zu nutzen, muss er als solches in den Horizont hochgeladen werden. Verwenden Sie dazu den nächsten Befehl.
#glance image-create -- AAA-CPAR-Date-snapshot.qcow2 --container-format bare --disk-format qcow2 --name AAA-CPAR-Date-snapshot
Der Prozess zeichnet sich am Horizont ab.

Schritt 4:Navigieren Sie in Horizon zu Project > Instances, und klicken Sie auf Launch Instance.

Schritt 5:Geben Sie den Instanznamen ein, und wählen Sie die Verfügbarkeitszone aus.
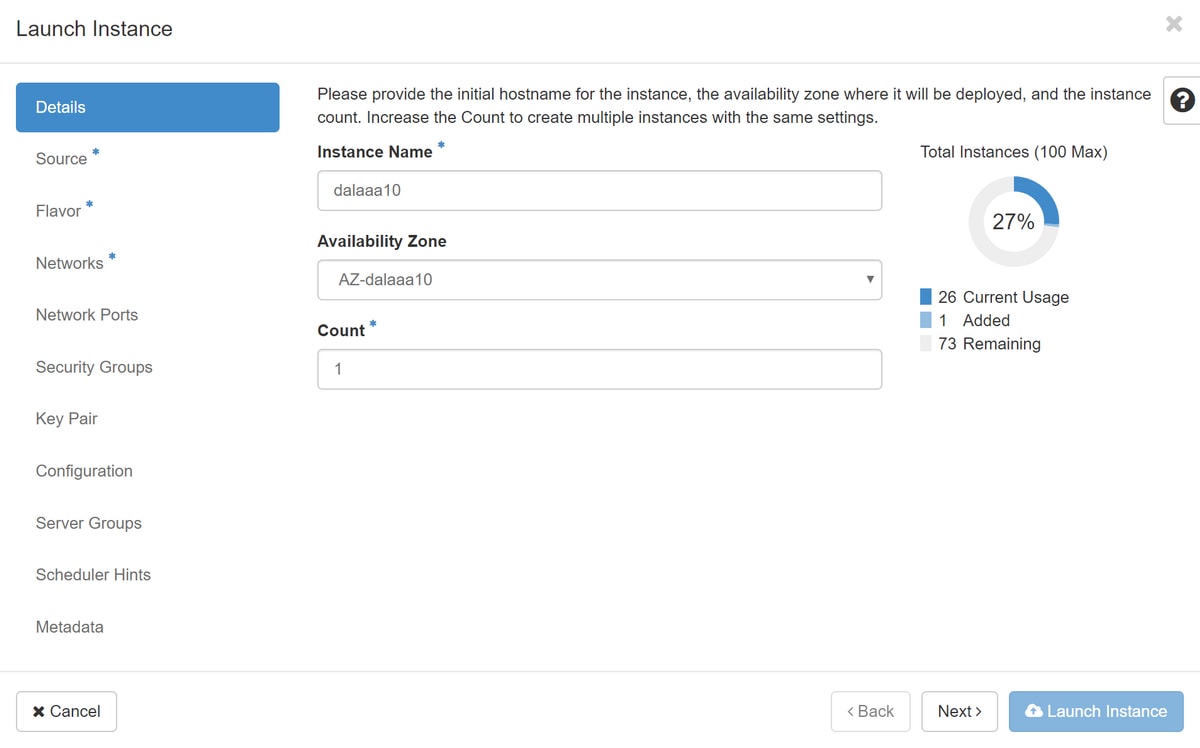
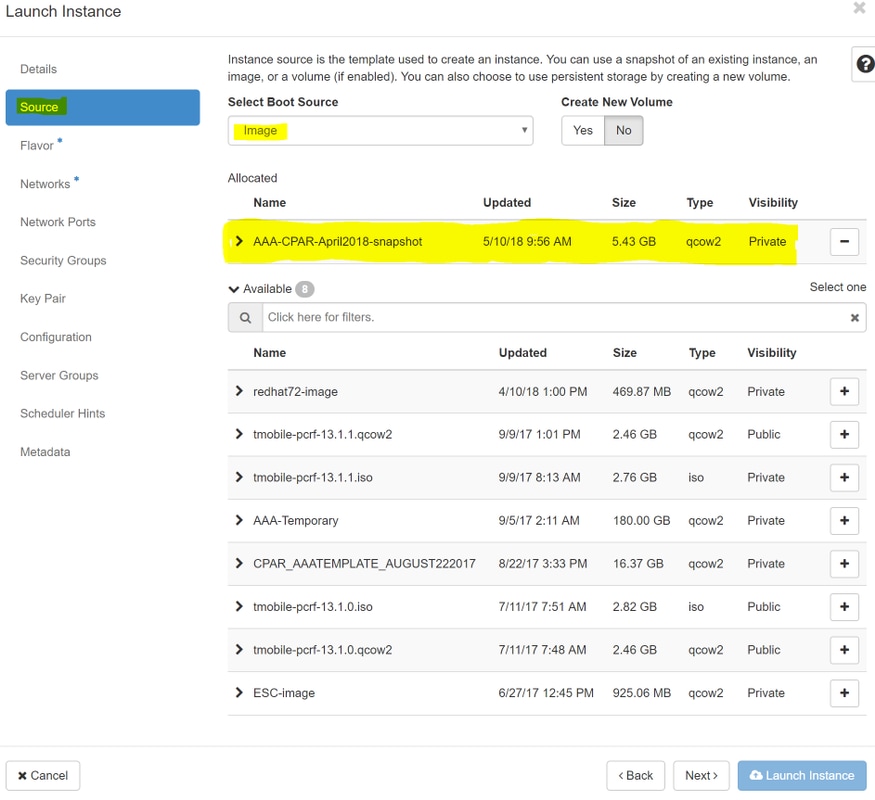
Schritt 6:Wählen Sie auf der Registerkarte Quelle das Bild aus, das die Instanz erstellen soll. Im Menü Select Boot Source wählen Sie Image, eine Liste von Images wird hier angezeigt, wählen Sie das, das zuvor hochgeladen wurde, als Sie auf + Zeichen klicken.
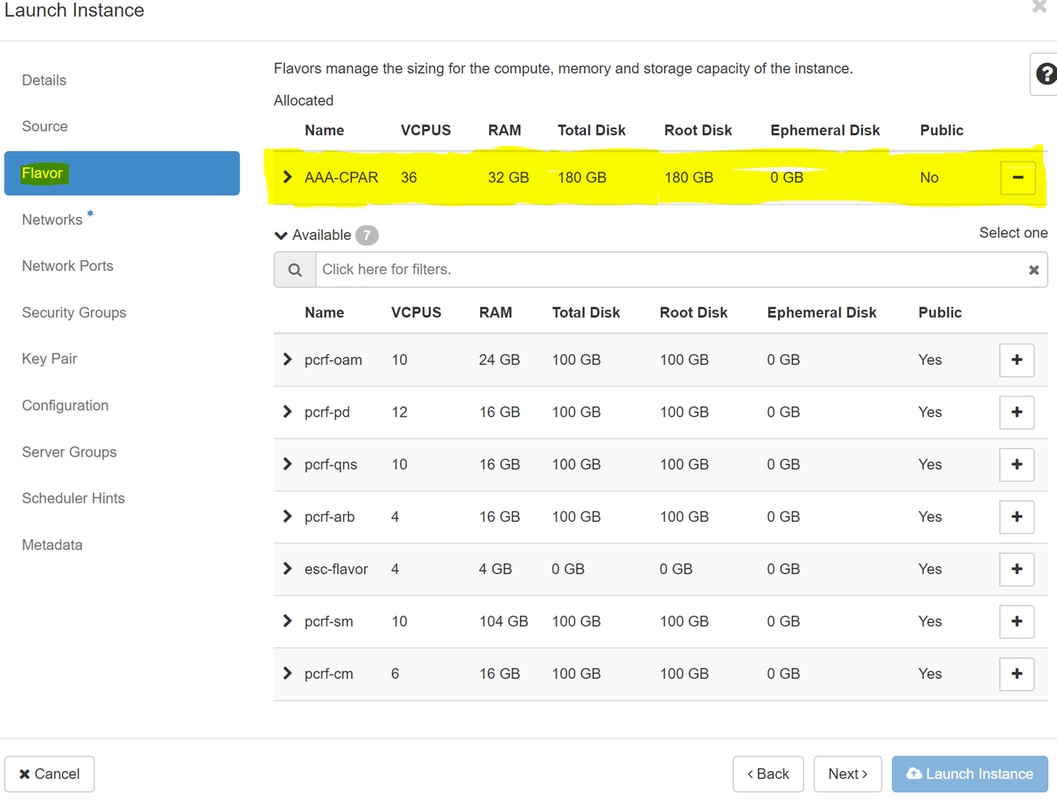
Schritt 7.Wählen Sie auf der Registerkarte "Flavor" die AAA-Variante aus, wenn Sie auf das Zeichen + klicken.
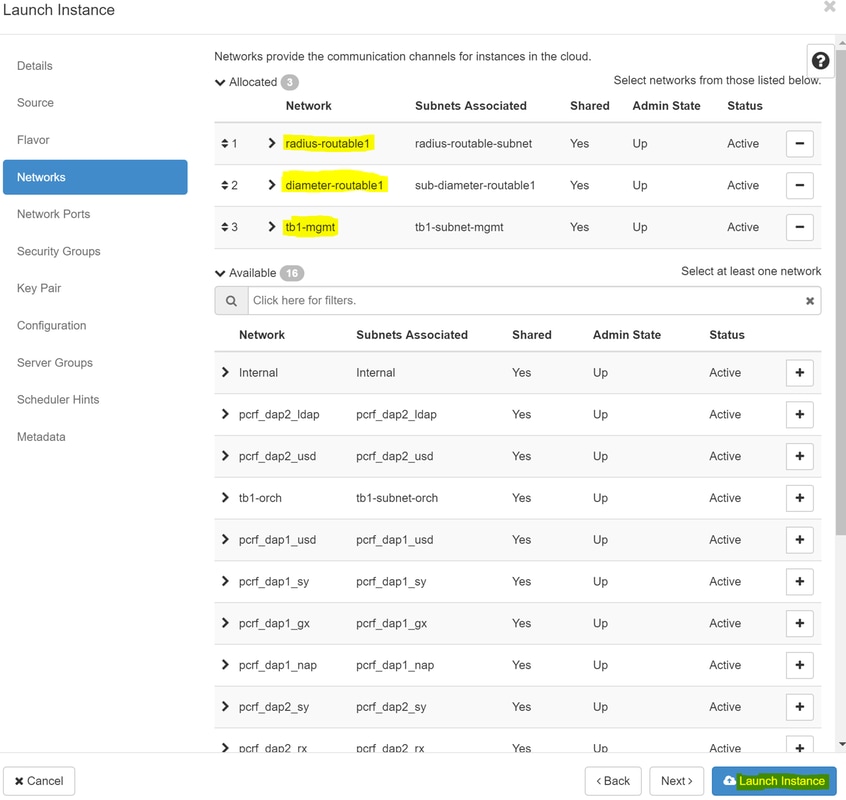
Schritt 8.Schließlich navigieren Sie zur Registerkarte Netzwerk und wählen Sie die Netzwerke, die die Instanz benötigt, wie Sie auf klicken + Zeichen. Wählen Sie in diesem Fall durchmesser-soutable1, radius-routable1 und tb1-mgmt.
Schritt 9. Klicken Sie abschließend auf Instanz starten, um sie zu erstellen. Die Fortschritte können in "Horizont" beobachtet werden:
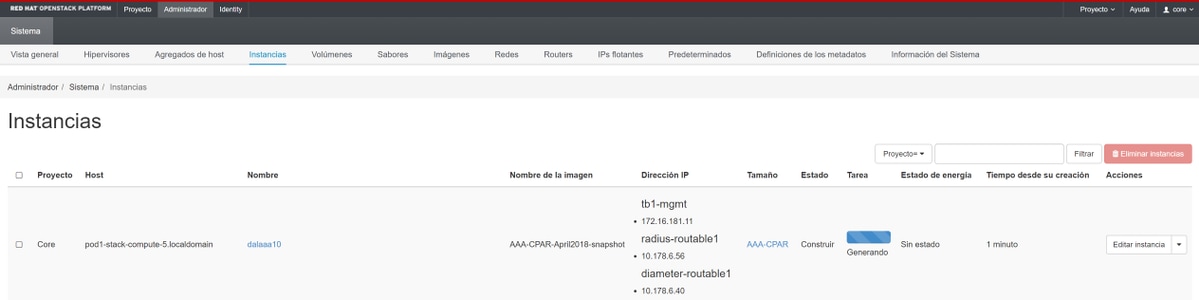
Nach wenigen Minuten ist die Instanz vollständig bereitgestellt und einsatzbereit.

Erstellen und Zuweisen einer Floating-IP-Adresse
Eine Floating-IP-Adresse ist eine routbare Adresse, d. h. sie ist von außerhalb der Ultra M/OpenStack-Architektur erreichbar und kann mit anderen Knoten im Netzwerk kommunizieren.
Schritt 1.Navigieren Sie im oberen Menü von Horizon zu Admin > Floating IPs.
Schritt 2. Klicken Sie auf die SchaltflächeAllocateIP to Project.
Schritt 3: Wählen Sie im Fenster Unverankerte IP-Adresse zuweisen den Pool aus, von dem die neue unverankerte IP-Adresse stammt, das Projekt, dem sie zugewiesen wird, und die neue unverankerte IP-Adresse selbst.
Beispiele:
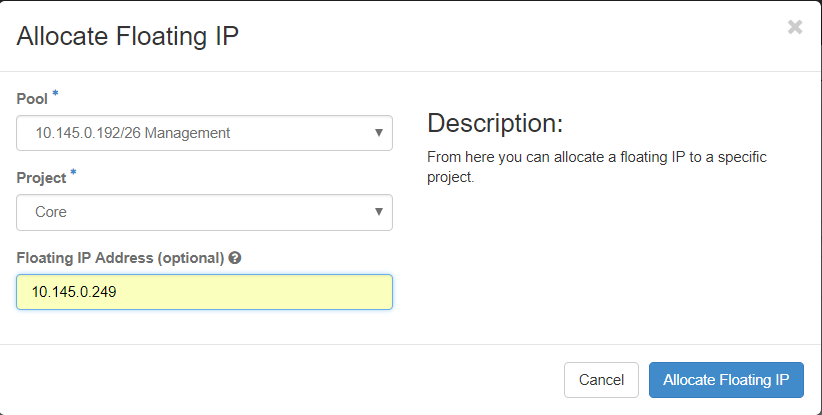
Schritt 4:Klicken Sie auf AllocateFloating-IP.
Schritt 5: Navigieren Sie im oberen Menü von Horizon zu Project > Instances.
Schritt 6:Klicken Sie in der Spalte Aktion auf den Pfeil, der in derSchaltfläche Snapshot erstellen nach unten zeigt, ein Menü sollte angezeigt werden. Wählen Sie die Option Unverankertes IP zuordnen aus.
Schritt 7: Wählen Sie die entsprechende Floating-IP-Adresse, die im IP-Adressfeld verwendet werden soll, und wählen Sie die entsprechende Verwaltungsschnittstelle (eth0) aus der neuen Instanz, der diese Floating-IP im zuzuordnenden Port zugewiesen wird. Als Beispiel für diese Vorgehensweise sehen Sie bitte das nächste Bild.
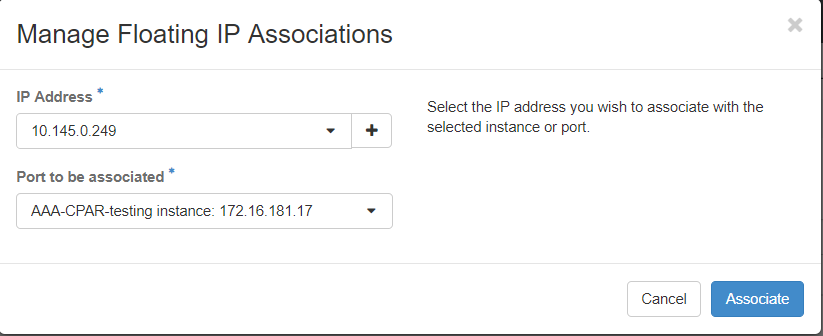
Schritt 8.Schließlich klicken Sie aufZuordnen.
Aktivieren von SSH
Schritt 1:Navigieren Sie im oberen Menü von Horizon zu Project > Instances.
Schritt 2:Klicken Sie auf den Namen der Instanz/VM, die im AbschnittNeue Instanz starten erstellt wurde.
Schritt 3: Klicken Sie aufKonsoleRegisterkarte. Dadurch wird die Befehlszeilenschnittstelle des virtuellen Systems angezeigt.
Schritt 4:Geben Sie nach der Anzeige der CLI die entsprechenden Anmeldeinformationen ein:
Benutzername:root
Kennwort: cisco123
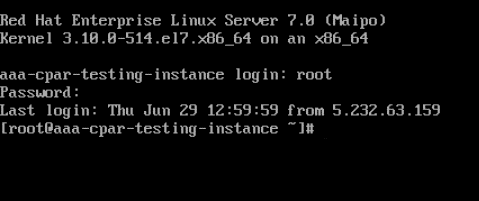
Schritt 5:Geben Sie in der CLI den Befehl vi /etc/ssh/sshd_configein, um die ssh-Konfiguration zu bearbeiten.
Schritt 6: Wenn die SSH-Konfigurationsdatei geöffnet ist, drücken Sie Ito, um die Datei zu bearbeiten. Dann suchen Sie nach dem Abschnitt unten gezeigt und ändern Sie die erste Zeile vonPasswordAuthentication nichtPasswordAuthentication ja.

Schritt 7.Drücken Sie ESC und geben Sie:wq! ein, um die Änderungen der Datei sshd_config zu speichern.
Schritt 8: Führen Sie den Befehl service sshd restart aus.
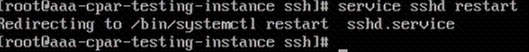
Schritt 9.Um zu testen, ob die SSH-Konfigurationsänderungen korrekt angewendet wurden, öffnen Sie einen beliebigen SSH-Client, und versuchen Sie, eine sichere Remote-Verbindung herzustellen, indem Sie die der Instanz zugewiesene Floating-IP (d. h. 10.145.0.249) und den Benutzerstamm verwenden.
Einrichten einer SSH-Sitzung
Öffnen Sie eine SSH-Sitzung mit der IP-Adresse des entsprechenden virtuellen Systems/Servers, auf dem die Anwendung installiert ist.

Start der CPAR-Instanz
Führen Sie die folgenden Schritte aus, wenn die Aktivität abgeschlossen wurde und die CPAR-Services auf der Website, die heruntergefahren wurde, wiederhergestellt werden können.
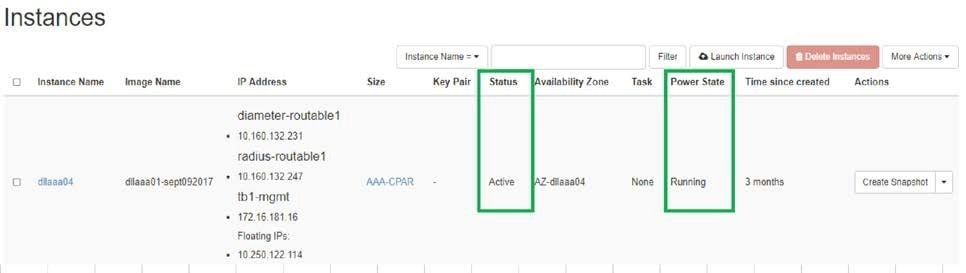
- Um sich wieder bei Horizon anzumelden, navigieren Sie zu Project > Instance > Start Instance.
- Überprüfen Sie, ob der Status der Instanz aktiv ist und der Netzstatus aktiv ist:
Integritätsprüfung nach einer Aktivität
Schritt 1:Führen Sie den Befehl /opt/CSCOar/bin/arstatus auf Betriebssystemebene aus.
[root@aaa04 ~]# /opt/CSCOar/bin/arstatus Cisco Prime AR RADIUS server running (pid: 24834) Cisco Prime AR Server Agent running (pid: 24821) Cisco Prime AR MCD lock manager running (pid: 24824) Cisco Prime AR MCD server running (pid: 24833) Cisco Prime AR GUI running (pid: 24836) SNMP Master Agent running (pid: 24835) [root@wscaaa04 ~]#
Schritt 2:Führen Sie den Befehl /opt/CSCOar/bin/aregcmd auf Betriebssystemebene aus, und geben Sie die Admin-Anmeldeinformationen ein. Vergewissern Sie sich, dass CPAR Health 10 von 10 ist, und verlassen Sie CPAR CLI.
[root@aaa02 logs]# /opt/CSCOar/bin/aregcmd Cisco Prime Access Registrar 7.3.0.1 Configuration Utility Copyright (C) 1995-2017 by Cisco Systems, Inc. All rights reserved. Cluster: User: admin Passphrase: Logging in to localhost [ //localhost ] LicenseInfo = PAR-NG-TPS 7.2(100TPS:) PAR-ADD-TPS 7.2(2000TPS:) PAR-RDDR-TRX 7.2() PAR-HSS 7.2() Radius/ Administrators/ Server 'Radius' is Running, its health is 10 out of 10 --> exit
Schritt 3:Führen Sie den Befehl netstat aus. | Grep-Durchmesser und überprüfen Sie, ob alle DRA-Verbindungen hergestellt sind.
Die unten genannte Ausgabe ist für eine Umgebung, in der Durchmesserverbindungen erwartet werden. Wenn weniger Links angezeigt werden, stellt dies eine Trennung von der DRA dar, die analysiert werden muss.
[root@aa02 logs]# netstat | grep diameter tcp 0 0 aaa02.aaa.epc.:77 mp1.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:36 tsa6.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:47 mp2.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:07 tsa5.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:08 np2.dra01.d:diameter ESTABLISHED
Schritt 4:Überprüfen Sie, ob im TPS-Protokoll Anfragen aufgeführt sind, die von CPAR verarbeitet werden. Die hervorgehobenen Werte stellen den TPS dar, und dies sind die Werte, denen wir Aufmerksamkeit schenken müssen.
Der Wert von TPS sollte 1500 nicht überschreiten.
[root@wscaaa04 ~]# tail -f /opt/CSCOar/logs/tps-11-21-2017.csv 11-21-2017,23:57:35,263,0 11-21-2017,23:57:50,237,0 11-21-2017,23:58:05,237,0 11-21-2017,23:58:20,257,0 11-21-2017,23:58:35,254,0 11-21-2017,23:58:50,248,0 11-21-2017,23:59:05,272,0 11-21-2017,23:59:20,243,0 11-21-2017,23:59:35,244,0 11-21-2017,23:59:50,233,0
Schritt 5:Suchen Sie nach "error"- oder "alarm"-Meldungen in name_radius_1_log.
[root@aaa02 logs]# grep -E "error|alarm" name_radius_1_log
Schritt 6:Überprüfen Sie mit dem folgenden Befehl, wie viel Speicher der CPAR-Prozess belegt:
oberste | Grep Radius
[root@sfraaa02 ~]# top | grep radius 27008 root 20 0 20.228g 2.413g 11408 S 128.3 7.7 1165:41 radius
Der hervorgehobene Wert sollte kleiner sein als: 7 GB, d. h. die maximal zulässige Größe auf Anwendungsebene.
Austausch der Hauptplatine im OSD-Rechenknoten
Vor der Aktivität werden die im Rechenknoten gehosteten VMs ordnungsgemäß heruntergefahren und der CEPH in den Wartungsmodus versetzt. Nach dem Austausch der Hauptplatine werden die virtuellen Systeme wiederhergestellt, und der CEPH-Modus wird aus dem Wartungsmodus verschoben.
Identifizieren der im OSD-Rechenknoten gehosteten VMs
Identifizieren Sie die VMs, die auf dem OSD-Computing-Server gehostet werden.
[stack@director ~]$ nova list --field name,host | grep osd-compute-0 | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | pod2-stack-compute-4.localdomain |
Sicherung: Snapshot-Prozess
Herunterfahren der CPAR-Anwendung
Schritt 1:Öffnen Sie einen beliebigen SSH-Client, der mit dem Netzwerk verbunden ist, und stellen Sie eine Verbindung zur CPAR-Instanz her.
Es ist wichtig, dass nicht alle vier AAA-Instanzen an einem Standort gleichzeitig heruntergefahren werden, sondern nur eine nach der anderen.
Schritt 2:Herunterfahren der CPAR-Anwendung mit diesem Befehl:
/opt/CSCOar/bin/arserver stop A Message stating “Cisco Prime Access Registrar Server Agent shutdown complete.” Should show up
Anmerkung: Wenn ein Benutzer eine CLI-Sitzung geöffnet hat, funktioniert der Befehl arserver stop nicht, und die folgende Meldung wird angezeigt:
ERROR: You can not shut down Cisco Prime Access Registrar while the CLI is being used. Current list of running CLI with process id is: 2903 /opt/CSCOar/bin/aregcmd –s
In diesem Beispiel muss die hervorgehobene Prozess-ID 2903 beendet werden, bevor CPAR beendet werden kann. Wenn dies der Fall ist, beenden Sie den Vorgang mit folgendem Befehl:
kill -9 *process_id*
Wiederholen Sie dann Schritt 1.
Schritt 3:Vergewissern Sie sich mit diesem Befehl, dass die CPAR-Anwendung tatsächlich heruntergefahren wurde:
/opt/CSCOar/bin/arstatus
Folgende Meldungen werden angezeigt:
Cisco Prime Access Registrar Server Agent not running Cisco Prime Access Registrar GUI not running
VM-Snapshot-Aufgabe
Schritt 1:Geben Sie die Website der grafischen Benutzeroberfläche von Horizon ein, die der Website (Stadt) entspricht, an der derzeit gearbeitet wird.
Beim Zugriff auf Horizon wird das abgebildete Bild beobachtet:
Schritt 2: Navigieren Sie zu Projekt > Instanzen, wie im Bild dargestellt.
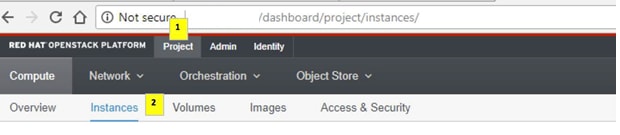
War der verwendete Benutzer CPAR, werden in diesem Menü nur die 4 AAA-Instanzen angezeigt.
Schritt 3:Fahren Sie jeweils nur eine Instanz herunter. Wiederholen Sie den gesamten Vorgang in diesem Dokument.
Um die VM herunterzufahren, navigieren Sie zu Aktionen > Instanz herunterfahren und bestätigen Sie Ihre Auswahl.

Schritt 4:Überprüfen Sie Status = Shutoff (Status = Herunterfahren) und Power State = Shut Down (Status = Herunterfahren), um sicherzustellen, dass die Instanz tatsächlich heruntergefahren wurde.
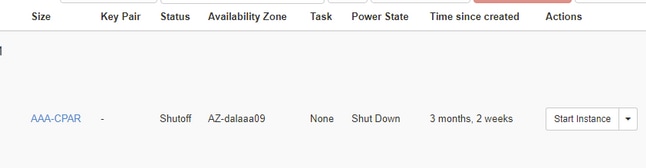
Dieser Schritt beendet das Herunterfahren der CPAR-Software.
VM-Snapshot
Wenn die virtuellen CPAR-Systeme ausgefallen sind, können die Snapshots parallel erstellt werden, da sie zu unabhängigen Computern gehören.
Die vier QCOW2-Dateien werden parallel erstellt.
Schnappschuss jeder AAA-Instanz (25 Minuten -1 Stunde) (25 Minuten für Instanzen, die ein QoCow-Image als Quelle verwendet haben, und 1 Stunde für Instanzen, die ein Raw-Image als Quelle verwenden)
Schritt 1: Melden Sie sich bei der OpenStack-HorizonGUI des POD an.
Schritt 2: Fahren Sie nach der Anmeldung mit dem Abschnitt Projekt > Berechnen > Instanzen im oberen Menü fort, und suchen Sie nach den AAA-Instanzen.
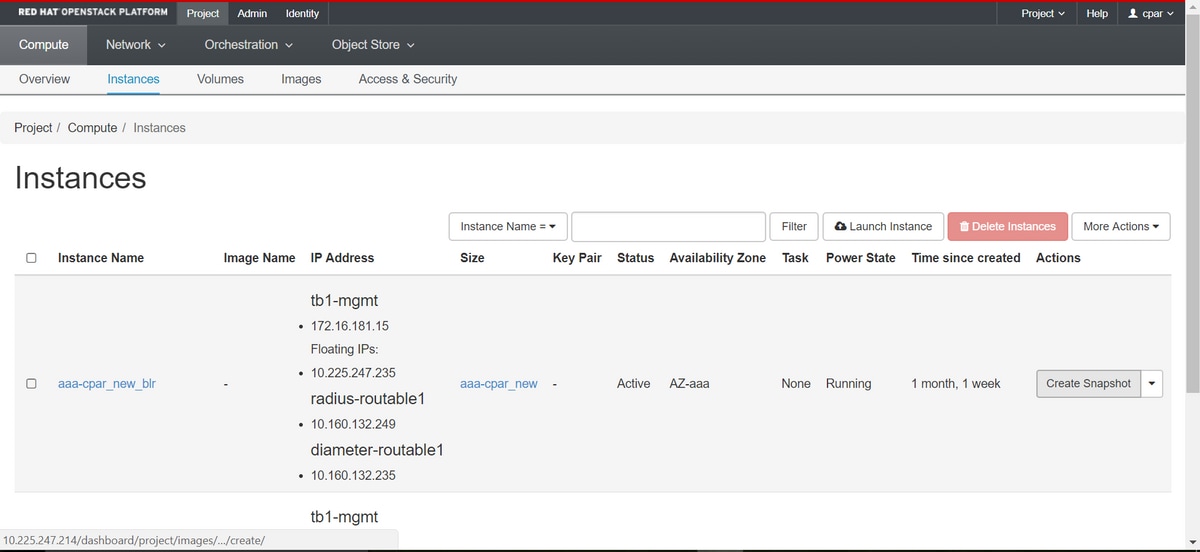
Schritt 3: Klicken Sie auf die Schaltfläche Snapshot erstellen, um mit der Snapshot-Erstellung fortzufahren (diese muss für die entsprechende AAA-Instanz ausgeführt werden).
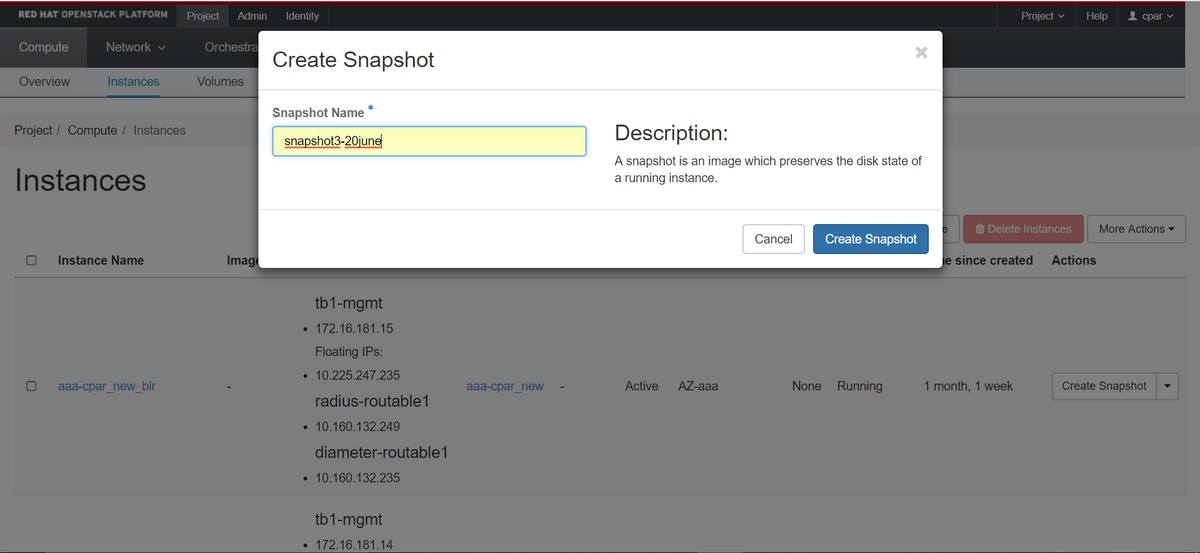
Schritt 4: Nachdem der Snapshot ausgeführt wurde, navigieren Sie zum Menü IMAGES und überprüfen Sie, ob alle Vorgänge abgeschlossen sind und keine Probleme gemeldet werden.
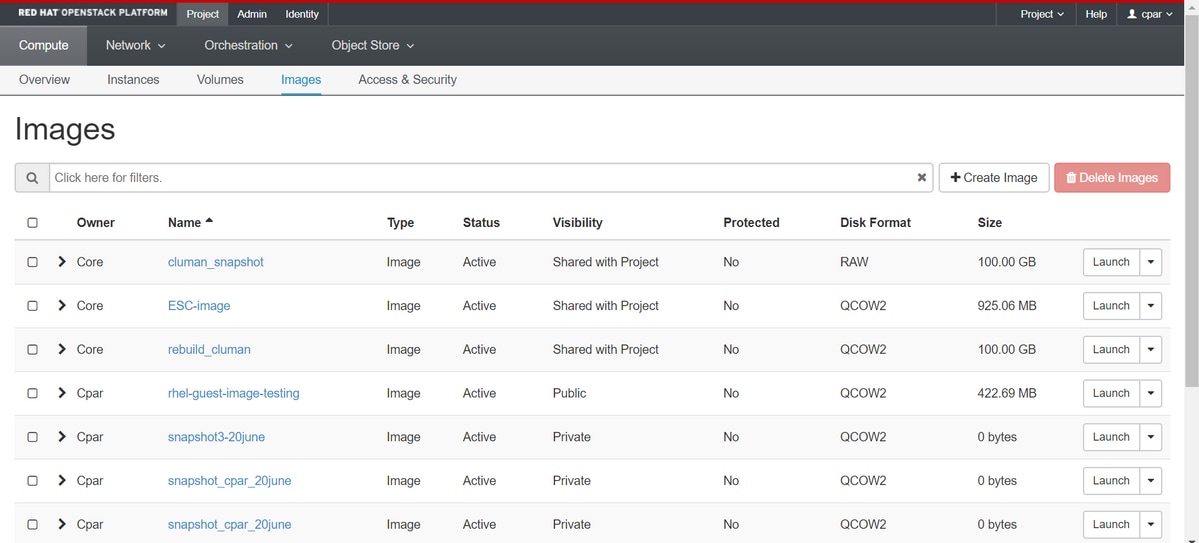
Schritt 5: Der nächste Schritt besteht darin, den Snapshot im QCOW2-Format herunterzuladen und auf eine entfernte Entität zu übertragen, falls die OSPD während dieses Vorgangs verloren geht. Um dies zu erreichen, identifizieren Sie den Snapshot mit diesem Befehl glance image-list auf OSPD-Ebene.
[root@elospd01 stack]# glance image-list +--------------------------------------+---------------------------+ | ID | Name | +--------------------------------------+---------------------------+ | 80f083cb-66f9-4fcf-8b8a-7d8965e47b1d | AAA-Temporary | | 22f8536b-3f3c-4bcc-ae1a-8f2ab0d8b950 | ELP1 cluman 10_09_2017 | | 70ef5911-208e-4cac-93e2-6fe9033db560 | ELP2 cluman 10_09_2017 | | e0b57fc9-e5c3-4b51-8b94-56cbccdf5401 | ESC-image | | 92dfe18c-df35-4aa9-8c52-9c663d3f839b | lgnaaa01-sept102017 | | 1461226b-4362-428b-bc90-0a98cbf33500 | tmobile-pcrf-13.1.1.iso | | 98275e15-37cf-4681-9bcc-d6ba18947d7b | tmobile-pcrf-13.1.1.qcow2 | +--------------------------------------+---------------------------+
Schritt 6. Nachdem Sie festgestellt haben, dass der Snapshot heruntergeladen werden soll (in diesem Fall wird der oben in Grün markierte Snapshot sein), laden Sie ihn jetzt im QCOW2-Format mit diesem Befehl glance image-download herunter, wie hier gezeigt.
[root@elospd01 stack]# glance image-download 92dfe18c-df35-4aa9-8c52-9c663d3f839b --file /tmp/AAA-CPAR-LGNoct192017.qcow2 &
- Das "&" sendet den Prozess in den Hintergrund. Es wird einige Zeit dauern, bis diese Aktion abgeschlossen ist. Sobald dies geschehen ist, kann sich das Abbild im Verzeichnis /tmp befinden.
- Wenn beim Senden des Prozesses in den Hintergrund die Verbindung unterbrochen wird, wird der Prozess ebenfalls beendet.
- Führen Sie den Befehl "dissown -h" aus, damit der Prozess im Falle des Verlusts der SSH-Verbindung weiterhin auf der OSPD ausgeführt und beendet wird.
7. Nachdem der Download-Prozess abgeschlossen ist, muss ein Komprimierungsprozess ausgeführt werden, da dieser Snapshot aufgrund von Prozessen, Aufgaben und temporären Dateien, die vom Betriebssystem verarbeitet werden, möglicherweise mit NULL gefüllt wird. Der für die Dateikomprimierung zu verwendende Befehl lautet virt-sparsify.
[root@elospd01 stack]# virt-sparsify AAA-CPAR-LGNoct192017.qcow2 AAA-CPAR-LGNoct192017_compressed.qcow2
Dieser Vorgang dauert einige Zeit (etwa 10-15 Minuten). Nach Fertigstellung ist die resultierende Datei diejenige, die wie im nächsten Schritt angegeben auf eine externe Entität übertragen werden muss.
Um dies zu erreichen, muss die Integrität der Datei überprüft werden. Führen Sie den nächsten Befehl aus, und suchen Sie am Ende der Ausgabe nach dem Attribut "corrupt".
[root@wsospd01 tmp]# qemu-img info AAA-CPAR-LGNoct192017_compressed.qcow2 image: AAA-CPAR-LGNoct192017_compressed.qcow2 file format: qcow2 virtual size: 150G (161061273600 bytes) disk size: 18G cluster_size: 65536 Format specific information: compat: 1.1 lazy refcounts: false refcount bits: 16 corrupt: false
Um ein Problem zu vermeiden, bei dem das OSPD verloren geht, muss der kürzlich erstellte Snapshot im QCOW2-Format auf eine externe Einheit übertragen werden. Bevor Sie mit der Dateiübertragung beginnen, müssen wir prüfen, ob das Ziel über genügend freien Speicherplatz verfügt. Verwenden Sie den Befehl "df -kh", um den Speicherplatz zu überprüfen. Es wird empfohlen, die Datei mithilfe von SFTP "sftproot@x.x.x.x", wobei x.x.x.x die IP-Adresse einer Remote-OSPD ist, vorübergehend in die OSPD eines anderen Standorts zu übertragen. Um die Übertragung zu beschleunigen, kann das Ziel an mehrere OSPDs gesendet werden. Auf die gleiche Weise können wir den folgenden Befehl scp *name_of_the_file*.qcow2 root@ x.x.x.x:/tmp verwenden (wobei x.x.x.x die IP-Adresse eines Remote-OSPD ist), um die Datei in ein anderes OSPD zu übertragen.
CEPH in Wartungsmodus versetzen
Schritt 1: Überprüfen Sie, ob der Status von ceph osd auf dem Server aktiv ist.
[heat-admin@pod2-stack-osd-compute-0 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod2-stack-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-3 4.35999 host pod2-stack-osd-compute-1
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
-4 4.35999 host pod2-stack-osd-compute-2
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
Schritt 2: Melden Sie sich beim OSD-Rechenknoten an, und setzen Sie CEPH in den Wartungsmodus.
[root@pod2-stack-osd-compute-0 ~]# sudo ceph osd set norebalance
[root@pod2-stack-osd-compute-0 ~]# sudo ceph osd set noout
[root@pod2-stack-osd-compute-0 ~]# sudo ceph status
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_WARN
noout,norebalance,sortbitwise,require_jewel_osds flag(s) set
monmap e1: 3 mons at {pod2-stack-controller-0=11.118.0.10:6789/0,pod2-stack-controller-1=11.118.0.11:6789/0,pod2-stack-controller-2=11.118.0.12:6789/0}
election epoch 10, quorum 0,1,2 pod2-stack-controller-0,pod2-stack-controller-1,pod2-stack-controller-2
osdmap e79: 12 osds: 12 up, 12 in
flags noout,norebalance,sortbitwise,require_jewel_osds
pgmap v22844323: 704 pgs, 6 pools, 804 GB data, 423 kobjects
2404 GB used, 10989 GB / 13393 GB avail
704 active+clean
client io 3858 kB/s wr, 0 op/s rd, 546 op/s wr
Anmerkung: Wenn CEPH entfernt wird, wechselt das VNF HD RAID in den Status "Heruntergestuft", aber der Zugriff auf die Festplatte muss weiterhin möglich sein.
Sicheres Ausschalten
Knoten zum Ausschalten
- So schalten Sie die Instanz aus: nova stop <INSTANCE_NAME>
- Sie sehen den Instanznamen mit dem Status shutoff.
[stack@director ~]$ nova stop aaa2-21 Request to stop server aaa2-21 has been accepted. [stack@director ~]$ nova list +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | ID | Name | Status | Task State | Power State | Networks | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | ACTIVE | - | Running | tb1-mgmt=172.16.181.14, 10.225.247.233; radius-routable1=10.160.132.245; diameter-routable1=10.160.132.231 | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | SHUTOFF | - | Shutdown | diameter-routable1=10.160.132.230; radius-routable1=10.160.132.248; tb1-mgmt=172.16.181.7, 10.225.247.234 | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | ACTIVE | - | Running | diameter-routable1=10.160.132.233; radius-routable1=10.160.132.244; tb1-mgmt=172.16.181.10 | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+
Hauptplatine austauschen
Die Schritte zum Austauschen der Hauptplatine in einem UCS C240 M4 Server können dem Cisco UCS C240 M4 Server-Installations- und Serviceleitfaden entnommen werden.
- Melden Sie sich mit der CIMC-IP beim Server an.
- Führen Sie ein BIOS-Upgrade durch, wenn die Firmware nicht der zuvor verwendeten empfohlenen Version entspricht. Die Schritte für das BIOS-Upgrade sind hier aufgeführt: Cisco UCS Rackmount-Server der C-Serie - BIOS-Upgrade-Leitfaden
CEPH aus Wartungsmodus entfernen
Melden Sie sich beim OSD-Rechenknoten an, und versetzen Sie CEPH aus dem Wartungsmodus.
[root@pod2-stack-osd-compute-0 ~]# sudo ceph osd unset norebalance
[root@pod2-stack-osd-compute-0 ~]# sudo ceph osd unset noout
[root@pod2-stack-osd-compute-0 ~]# sudo ceph status
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
monmap e1: 3 mons at {pod2-stack-controller-0=11.118.0.10:6789/0,pod2-stack-controller-1=11.118.0.11:6789/0,pod2-stack-controller-2=11.118.0.12:6789/0}
election epoch 10, quorum 0,1,2 pod2-stack-controller-0,pod2-stack-controller-1,pod2-stack-controller-2
osdmap e81: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v22844355: 704 pgs, 6 pools, 804 GB data, 423 kobjects
2404 GB used, 10989 GB / 13393 GB avail
704 active+clean
client io 3658 kB/s wr, 0 op/s rd, 502 op/s wr
Stellen Sie die VMs wieder her
Wiederherstellen einer Instanz durch Snapshot
Wiederherstellungsprozess:
Es ist möglich, die vorherige Instanz mit dem Snapshot, der in den vorherigen Schritten erstellt wurde, erneut bereitzustellen.
Schritt 1 [OPTIONAL].Wenn kein vorheriger VMshot verfügbar ist, stellen Sie eine Verbindung mit dem OSPD-Knoten her, an den die Sicherung gesendet wurde, und setzen Sie die Sicherung auf den ursprünglichen OSPD-Knoten zurück. Verwenden Sie "sftproot@x.x.x.x", wobei x.x.x.x die IP-Adresse des ursprünglichen OSPD ist. Speichern Sie die Snapshot-Datei im Verzeichnis /tmp.
Schritt 2:Stellen Sie eine Verbindung mit dem OSPD-Knoten her, in dem die Instanz erneut bereitgestellt wird.

Sourcen Sie die Umgebungsvariablen mit dem folgenden Befehl:
# source /home/stack/pod1-stackrc-Core-CPAR
Schritt 3:Um den Snapshot als Image zu nutzen, muss er als solches in den Horizont hochgeladen werden. Verwenden Sie dazu den nächsten Befehl.
#glance image-create -- AAA-CPAR-Date-snapshot.qcow2 --container-format bare --disk-format qcow2 --name AAA-CPAR-Date-snapshot
Der Prozess zeichnet sich am Horizont ab.

Schritt 4:Navigieren Sie in Horizon zu Project > Instances, und klicken Sie auf Launch Instance.

Schritt 5:Geben Sie den Instanznamen ein, und wählen Sie die Verfügbarkeitszone aus.
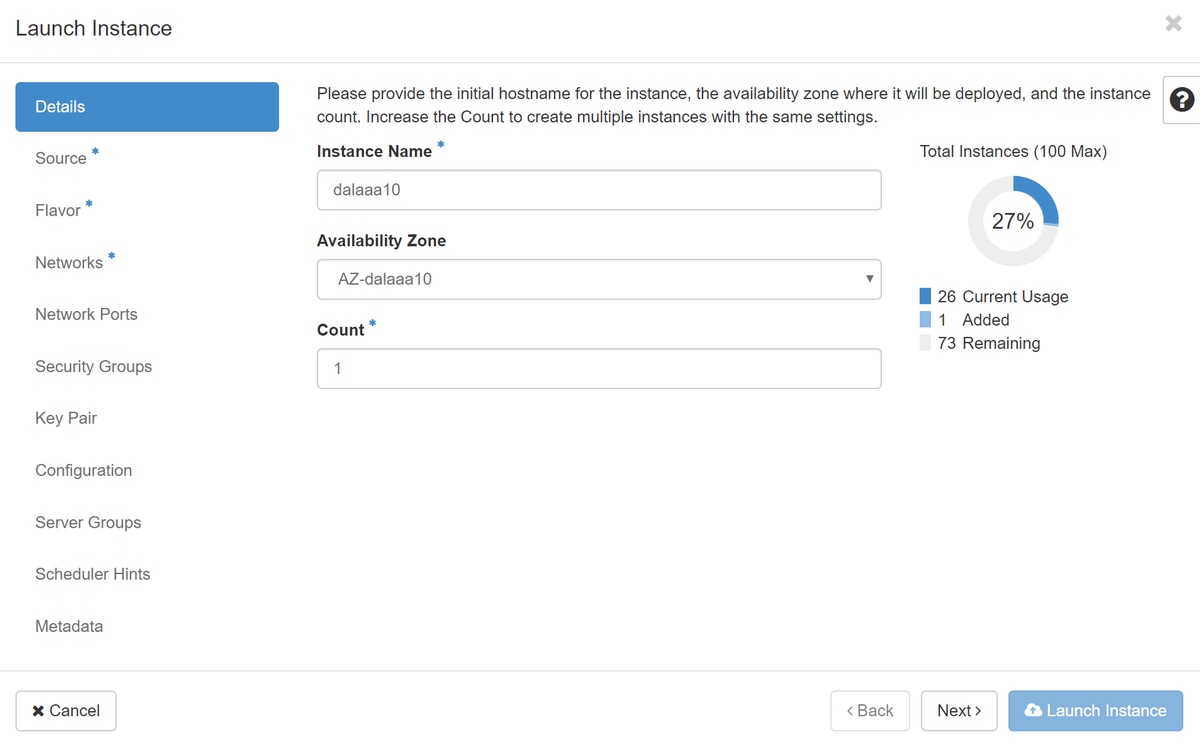
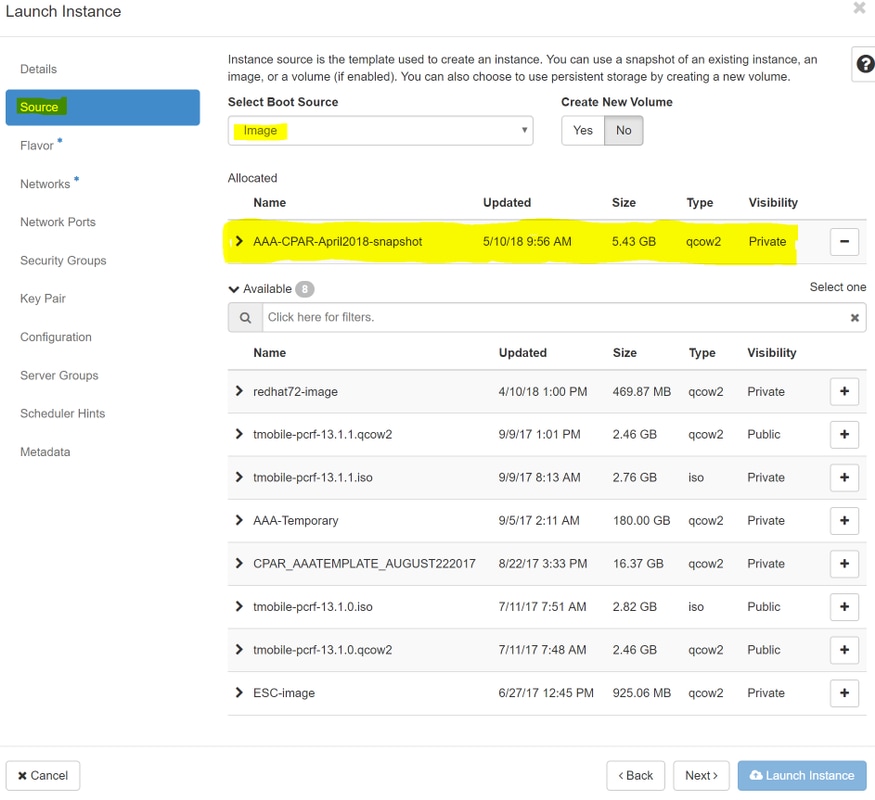
Schritt 6:Wählen Sie auf der Registerkarte Quelle das Bild aus, das die Instanz erstellen soll. Wählen Sie im Menü Select Boot Source (Boot-Quelle auswählen) image aus, hier wird eine Liste von Images angezeigt. Wählen Sie das Image aus, das zuvor hochgeladen wurde, wenn Sie auf das Zeichen + klicken.
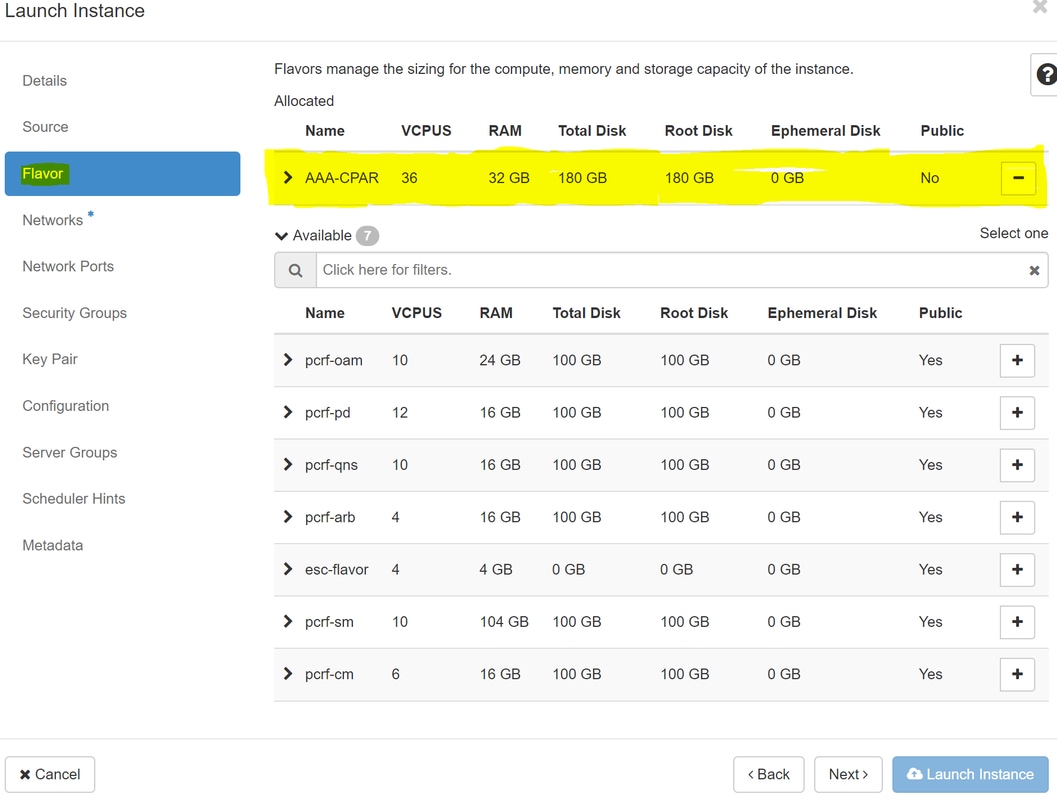
Schritt 7.Wählen Sie auf der Registerkarte "Flavor" die AAA-Variante aus, wenn Sie auf das Zeichen + klicken.
Schritt 8.Schließlich navigieren Sie zur Registerkarte Netzwerk und wählen Sie die Netzwerke, die die Instanz benötigt, wie Sie auf das + Zeichen klicken. Wählen Sie in diesem Fall durchmesser-soutable1, radius-routable1 und tb1-mgmt.
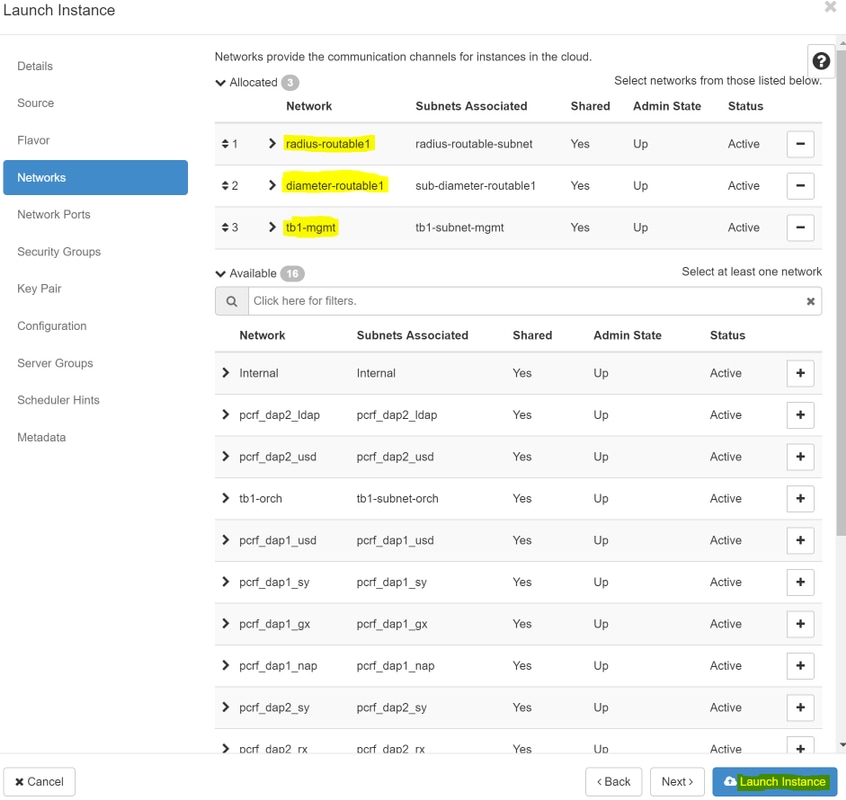
Schritt 9. Klicken Sie abschließend auf Instanz starten, um sie zu erstellen. Die Fortschritte können in "Horizont" beobachtet werden:
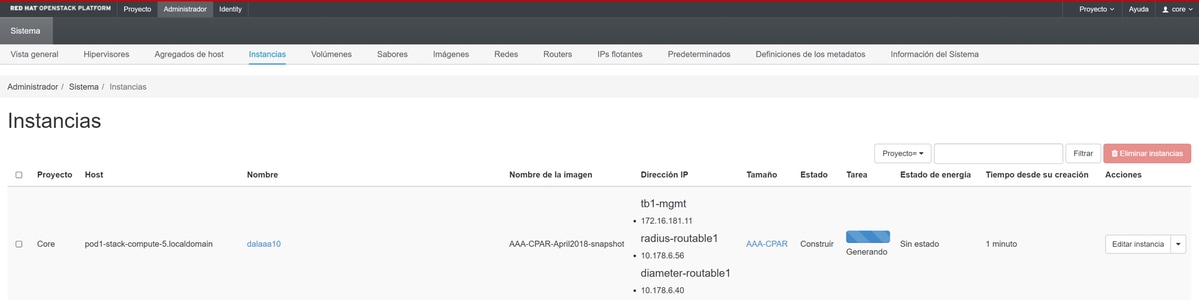
Nach wenigen Minuten ist die Instanz vollständig bereitgestellt und einsatzbereit.

Erstellen und Zuweisen einer Floating-IP-Adresse
Eine Floating-IP-Adresse ist eine routbare Adresse, d. h. sie ist von außerhalb der Ultra M/OpenStack-Architektur erreichbar und kann mit anderen Knoten im Netzwerk kommunizieren.
Schritt 1.Navigieren Sie im oberen Menü von Horizon zu Admin > Floating IPs.
Schritt 2:Klicken Sie auf die SchaltflächeAllocateIP to Project.
Schritt 3: Wählen Sie im Fenster Unverankerte IP-Adresse zuweisen den Pool aus, von dem die neue unverankerte IP-Adresse stammt, das Projekt, dem sie zugewiesen wird, und die neue unverankerte IP-Adresse selbst.
Beispiele:
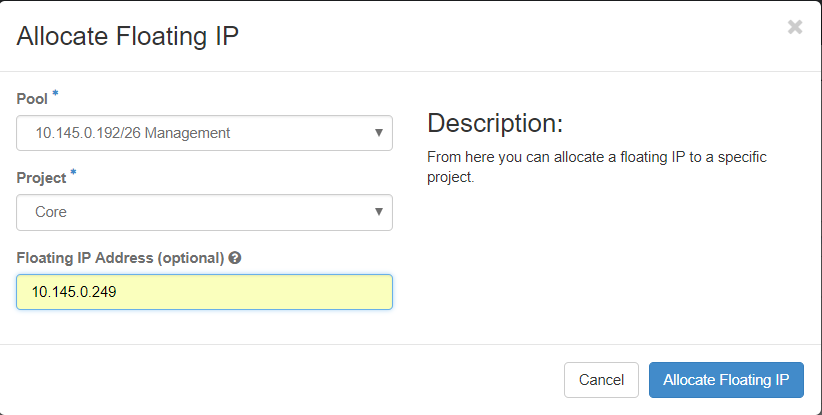
Schritt 4:Klicken Sie auf AllocateFloating-IP.
Schritt 5: Navigieren Sie im oberen Menü von Horizon zu Project > Instances.
Schritt 6. Klicken Sie in der Spalte Aktion auf den Pfeil, der nach unten zeigt, um ein Menü anzuzeigen. Wählen Sie die Option Unverankertes IP zuordnen aus.
Schritt 7: Wählen Sie die entsprechende Floating-IP-Adresse, die im IP-Adressfeld verwendet werden soll, und wählen Sie die entsprechende Verwaltungsschnittstelle (eth0) aus der neuen Instanz, der diese Floating-IP im zuzuordnenden Port zugewiesen wird. Als Beispiel für diese Vorgehensweise sehen Sie bitte das nächste Bild.
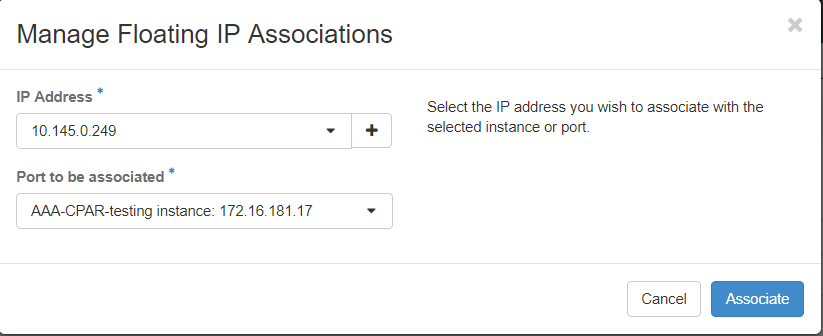
Schritt 8.Schließlich klicken Sie auf die Schaltfläche Zuordnen.
Aktivieren von SSH
Schritt 1:Navigieren Sie im oberen Menü von Horizon zu Project > Instances.
Schritt 2:Klicken Sie auf den Namen der Instanz/VM, die im AbschnittNeue Instanz starten erstellt wurde.
Schritt 3:Klicken Sie auf die Registerkarte Konsole. Es wird die CLI des virtuellen Systems angezeigt.
Schritt 4: Geben Sie nach der Anzeige der CLI die entsprechenden Anmeldeinformationen ein:
Benutzername:root
Kennwort: cisco123
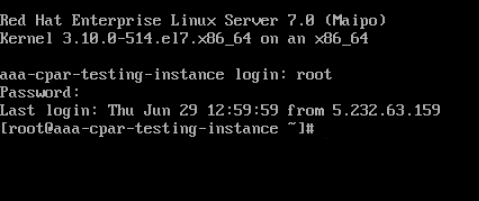
Schritt 5:Geben Sie in der CLI den Befehl vi /etc/ssh/sshd_configein, um die ssh-Konfiguration zu bearbeiten.
Schritt 6: Wenn die SSH-Konfigurationsdatei geöffnet ist, drücken Sie Ito, um die Datei zu bearbeiten. Suchen Sie dann nach dem hier abgebildeten Abschnitt, und ändern Sie die erste Zeile vonPasswordAuthentication notoPasswordAuthentication yes.

Schritt 7.Drücken Sie ESC und geben Sie:wq! ein, um die Änderungen der Datei sshd_config zu speichern.
Schritt 8. Führen Sie den Befehl service sshd restart aus.
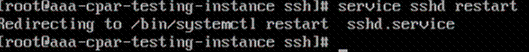
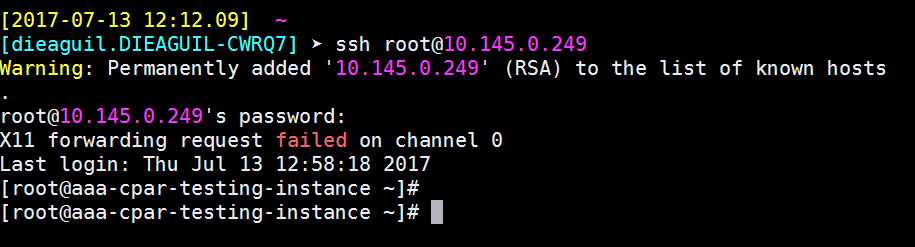
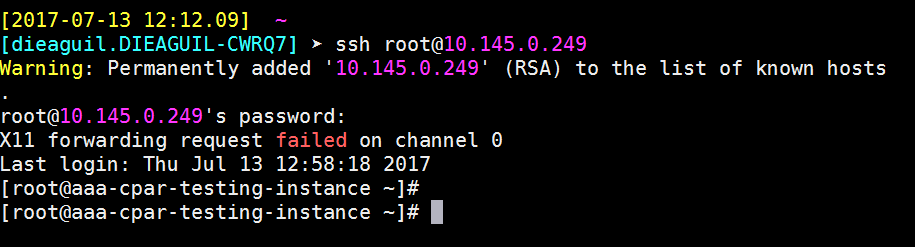
Schritt 9.Um zu testen, ob die SSH-Konfigurationsänderungen korrekt angewendet wurden, öffnen Sie einen beliebigen SSH-Client, und versuchen Sie, eine sichere Remote-Verbindung herzustellen, indem Sie die der Instanz zugewiesene Floating-IP (d. h. 10.145.0.249) und den Benutzerstamm verwenden.
Einrichten einer SSH-Sitzung
Öffnen Sie eine SSH-Sitzung mit der IP-Adresse des entsprechenden virtuellen Systems/Servers, auf dem die Anwendung installiert ist.

Start der CPAR-Instanz
Befolgen Sie diese Schritte, sobald die Aktivität abgeschlossen wurde und die CPAR-Services auf der Website, die heruntergefahren wurde, wiederhergestellt werden können.
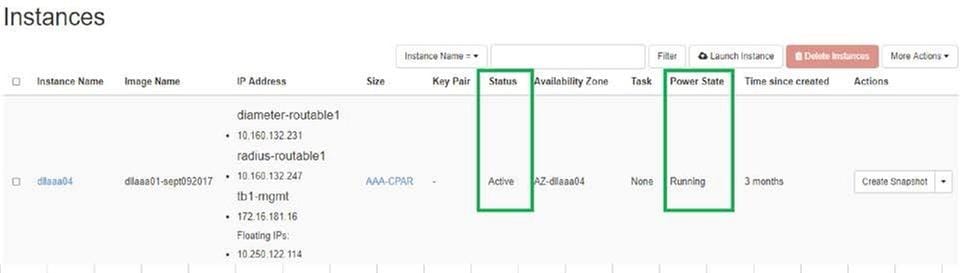
- Melden Sie sich wieder bei Horizon an, und navigieren Sie zu Project > Instance > Start Instance.
- Überprüfen Sie, ob der Status der Instanz aktiv ist und der Netzstatus aktiv ist:
Integritätsprüfung nach einer Aktivität
Schritt 1: Führen Sie den Befehl /opt/CSCOar/bin/arstatus auf Betriebssystemebene aus.
[root@aaa04 ~]# /opt/CSCOar/bin/arstatus Cisco Prime AR RADIUS server running (pid: 24834) Cisco Prime AR Server Agent running (pid: 24821) Cisco Prime AR MCD lock manager running (pid: 24824) Cisco Prime AR MCD server running (pid: 24833) Cisco Prime AR GUI running (pid: 24836) SNMP Master Agent running (pid: 24835) [root@wscaaa04 ~]#
Schritt 2: Führen Sie den Befehl /opt/CSCOar/bin/aregcmd auf Betriebssystemebene aus, und geben Sie die Admin-Anmeldeinformationen ein. Vergewissern Sie sich, dass CPAR Health 10 von 10 ist, und verlassen Sie CPAR CLI.
[root@aaa02 logs]# /opt/CSCOar/bin/aregcmd Cisco Prime Access Registrar 7.3.0.1 Configuration Utility Copyright (C) 1995-2017 by Cisco Systems, Inc. All rights reserved. Cluster: User: admin Passphrase: Logging in to localhost [ //localhost ] LicenseInfo = PAR-NG-TPS 7.2(100TPS:) PAR-ADD-TPS 7.2(2000TPS:) PAR-RDDR-TRX 7.2() PAR-HSS 7.2() Radius/ Administrators/ Server 'Radius' is Running, its health is 10 out of 10 --> exit
Schritt 3:Führen Sie den Befehl netstat aus. | Grep-Durchmesser und überprüfen Sie, ob alle DRA-Verbindungen hergestellt sind.
Die hier erwähnte Ausgabe bezieht sich auf eine Umgebung, in der Durchmesserverbindungen erwartet werden. Wenn weniger Links angezeigt werden, stellt dies eine Trennung von der DRA dar, die analysiert werden muss.
[root@aa02 logs]# netstat | grep diameter tcp 0 0 aaa02.aaa.epc.:77 mp1.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:36 tsa6.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:47 mp2.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:07 tsa5.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:08 np2.dra01.d:diameter ESTABLISHED
Schritt 4:Überprüfen Sie, ob im TPS-Protokoll Anfragen aufgeführt sind, die von CPAR verarbeitet werden. Die hervorgehobenen Werte stellen den TPS dar, und dies sind die Werte, denen wir Aufmerksamkeit schenken müssen.
Der Wert von TPS sollte 1500 nicht überschreiten.
[root@wscaaa04 ~]# tail -f /opt/CSCOar/logs/tps-11-21-2017.csv 11-21-2017,23:57:35,263,0 11-21-2017,23:57:50,237,0 11-21-2017,23:58:05,237,0 11-21-2017,23:58:20,257,0 11-21-2017,23:58:35,254,0 11-21-2017,23:58:50,248,0 11-21-2017,23:59:05,272,0 11-21-2017,23:59:20,243,0 11-21-2017,23:59:35,244,0 11-21-2017,23:59:50,233,0
Schritt 5:Suchen Sie nach "error"- oder "alarm"-Meldungen in name_radius_1_log.
[root@aaa02 logs]# grep -E "error|alarm" name_radius_1_log
Schritt 6:Überprüfen Sie mit diesem Befehl die Speicherkapazität, die der CPAR-Prozess verwendet:
oberste | Grep Radius
[root@sfraaa02 ~]# top | grep radius 27008 root 20 0 20.228g 2.413g 11408 S 128.3 7.7 1165:41 radius
Der hervorgehobene Wert sollte kleiner sein als: 7 GB, d. h. die maximal zulässige Größe auf Anwendungsebene.
Austausch der Hauptplatine im Controller-Knoten
Überprüfen des Controller-Status und Einstellen des Clusters in den Wartungsmodus
Von OSPD melden Sie sich beim Controller an, und überprüfen Sie, ob die PCs in gutem Zustand sind - alle drei Controller online und galera zeigen alle drei Controller als Master an.
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod2-stack-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Fri Jul 6 09:02:52 2018Last change: Mon Jul 2 12:49:52 2018 by root via crm_attribute on pod2-stack-controller-0
3 nodes and 19 resources configured
Online: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Full list of resources:
ip-11.120.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-192.200.0.110(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
ip-11.120.0.44(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
ip-11.118.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-10.225.247.214(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Master/Slave Set: redis-master [redis]
Masters: [ pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-0 pod2-stack-controller-1 ]
ip-11.119.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
openstack-cinder-volume(systemd:openstack-cinder-volume):Started pod2-stack-controller-1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Den Cluster in den Wartungsmodus versetzen
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs cluster standby
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod2-stack-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Fri Jul 6 09:03:10 2018Last change: Fri Jul 6 09:03:06 2018 by root via crm_attribute on pod2-stack-controller-0
3 nodes and 19 resources configured
Node pod2-stack-controller-0: standby
Online: [ pod2-stack-controller-1 pod2-stack-controller-2 ]
Full list of resources:
ip-11.120.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod2-stack-controller-1 pod2-stack-controller-2 ]
Stopped: [ pod2-stack-controller-0 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-192.200.0.110(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
ip-11.120.0.44(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
ip-11.118.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-10.225.247.214(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Master/Slave Set: redis-master [redis]
Masters: [ pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-1 ]
Stopped: [ pod2-stack-controller-0 ]
ip-11.119.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
openstack-cinder-volume(systemd:openstack-cinder-volume):Started pod2-stack-controller-1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Hauptplatine austauschen
Eine Vorgehensweise zum Austauschen der Hauptplatine in einem UCS C240 M4 Server finden Sie im Cisco UCS C240 M4 Server Installation and Service Guide.
- Melden Sie sich mit der CIMC-IP beim Server an.
- Führen Sie ein BIOS-Upgrade durch, wenn die Firmware nicht der zuvor verwendeten empfohlenen Version entspricht. Die Schritte für das BIOS-Upgrade sind hier aufgeführt:
BIOS-Upgrade-Leitfaden für Cisco UCS Rackmount-Server der C-Serie
Cluster-Status wiederherstellen
Melden Sie sich am betroffenen Controller an, und entfernen Sie den Standby-Modus, indem Sie unstandby festlegen. Überprüfen Sie, ob der Controller mit Cluster online ist, und galera zeigt alle drei Controller als Master an. Dieser Vorgang kann einige Minuten dauern.
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs cluster unstandby
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod2-stack-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Fri Jul 6 09:03:37 2018Last change: Fri Jul 6 09:03:35 2018 by root via crm_attribute on pod2-stack-controller-0
3 nodes and 19 resources configured
Online: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Full list of resources:
ip-11.120.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod2-stack-controller-1 pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-0 ]
ip-192.200.0.110(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
ip-11.120.0.44(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
ip-11.118.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod2-stack-controller-1 pod2-stack-controller-2 ]
Stopped: [ pod2-stack-controller-0 ]
ip-10.225.247.214(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Master/Slave Set: redis-master [redis]
Masters: [ pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-0 pod2-stack-controller-1 ]
ip-11.119.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
openstack-cinder-volume(systemd:openstack-cinder-volume):Started pod2-stack-controller-1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Beiträge von Cisco Ingenieuren
- Karthikeyan DachanamoorthyCisco Advance Services
- Harshita BhardwajCisco Advance Services
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)