إستبدال اللوحة الأم في خادم Ultra-M UCS 240M4 - vEPC
خيارات التنزيل
-
ePub (337.2 KB)
العرض في تطبيقات مختلفة على iPhone أو iPad أو نظام تشغيل Android أو قارئ Sony أو نظام التشغيل Windows Phone
لغة خالية من التحيز
تسعى مجموعة الوثائق لهذا المنتج جاهدة لاستخدام لغة خالية من التحيز. لأغراض مجموعة الوثائق هذه، يتم تعريف "خالية من التحيز" على أنها لغة لا تعني التمييز على أساس العمر، والإعاقة، والجنس، والهوية العرقية، والهوية الإثنية، والتوجه الجنسي، والحالة الاجتماعية والاقتصادية، والتمييز متعدد الجوانب. قد تكون الاستثناءات موجودة في الوثائق بسبب اللغة التي يتم تشفيرها بشكل ثابت في واجهات المستخدم الخاصة ببرنامج المنتج، أو اللغة المستخدمة بناءً على وثائق RFP، أو اللغة التي يستخدمها منتج الجهة الخارجية المُشار إليه. تعرّف على المزيد حول كيفية استخدام Cisco للغة الشاملة.
حول هذه الترجمة
ترجمت Cisco هذا المستند باستخدام مجموعة من التقنيات الآلية والبشرية لتقديم محتوى دعم للمستخدمين في جميع أنحاء العالم بلغتهم الخاصة. يُرجى ملاحظة أن أفضل ترجمة آلية لن تكون دقيقة كما هو الحال مع الترجمة الاحترافية التي يقدمها مترجم محترف. تخلي Cisco Systems مسئوليتها عن دقة هذه الترجمات وتُوصي بالرجوع دائمًا إلى المستند الإنجليزي الأصلي (الرابط متوفر).
المحتويات
المقدمة
يصف هذا المستند الخطوات المطلوبة لاستبدال اللوحة الأم المعيبة لأحد الخوادم في إعداد Ultra-M يستضيف وظائف الشبكة الظاهرية (VNF) لنظام التشغيل StarOS.
معلومات أساسية
Ultra-M هو حل أساسي لحزم الأجهزة المحمولة تم تجميعه في حزم مسبقا والتحقق من صحته افتراضيا تم تصميمه من أجل تبسيط نشر شبكات VNF. OpenStack هو مدير البنية الأساسية الظاهرية (VIM) ل Ultra-M ويتكون من أنواع العقد التالية:
- حوسبة
- قرص تخزين الكائنات - الحوسبة (OSD - الحوسبة)
- ضابط
- النظام الأساسي OpenStack - المدير (OSPD)
تم توضيح البنية المعمارية عالية المستوى لتقنية Ultra-M والمكونات المعنية في هذه الصورة:
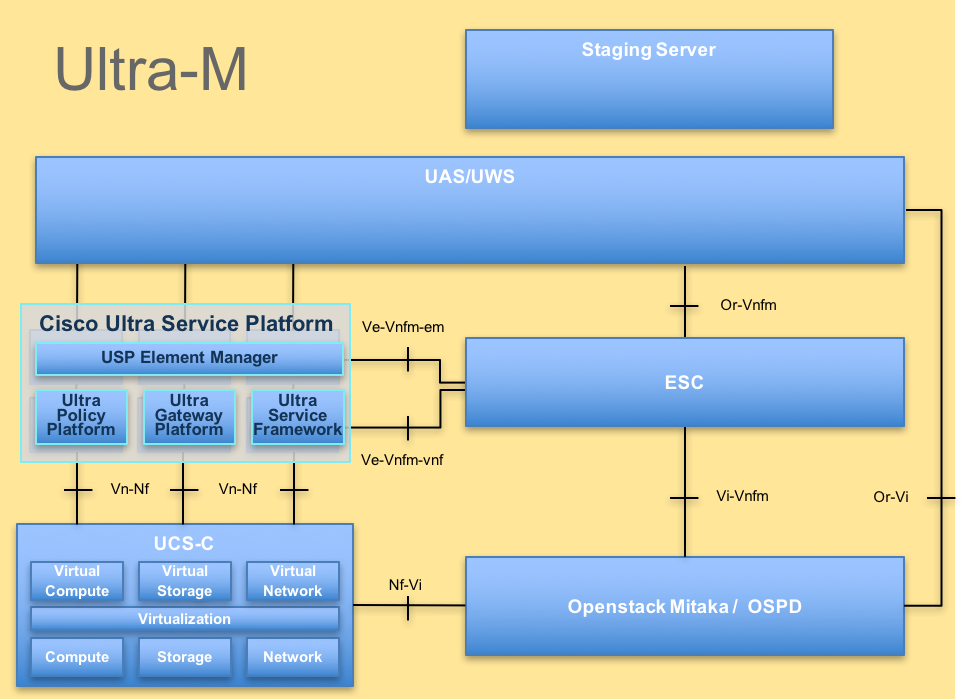 بنية UltraM
بنية UltraM
هذا المستند مخصص لأفراد Cisco المطلعين على نظام Cisco Ultra-M الأساسي وهو يفصل الخطوات المطلوبة ليتم تنفيذها على مستوى OpenStack و StarOS VNF في وقت إستبدال اللوحة الأم في الخادم.
ملاحظة: يتم النظر في الإصدار Ultra M 5.1.x لتحديد الإجراءات الواردة في هذا المستند.
المختصرات
| VNF | وظيفة الشبكة الظاهرية |
| سي إف | دالة التحكم |
| SF | وظيفة الخدمة |
| ESC | وحدة التحكم المرنة في الخدمة |
| ممسحة | طريقة إجرائية |
| OSD | أقراص تخزين الكائنات |
| محرك الأقراص الثابتة | محرك الأقراص الثابتة |
| محرك أقراص مزود بذاكرة مصنوعة من مكونات صلبة | محرك أقراص في الحالة الصلبة |
| فيم | مدير البنية الأساسية الظاهرية |
| VM | جهاز ظاهري |
| إم | مدير العناصر |
| UAS | خدمات أتمتة Ultra |
| uID | المعرف الفريد العالمي |
سير عمل مذكرة التفاهم
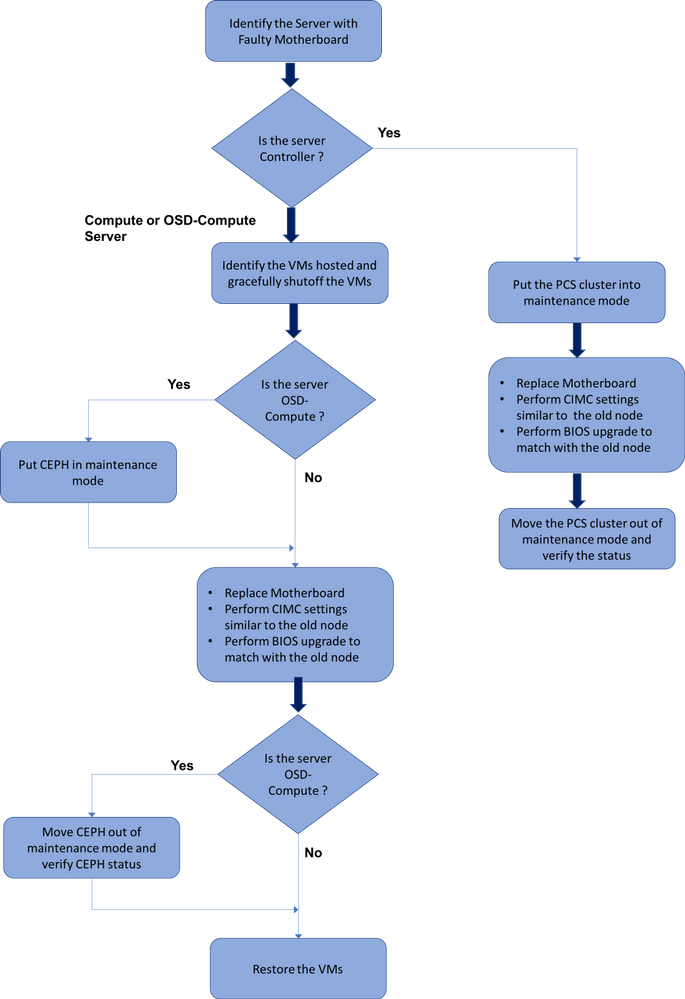 سير العمل ذو المستوى العالي لإجراء الاستبدال
سير العمل ذو المستوى العالي لإجراء الاستبدال
إستبدال اللوحات الأم في إعداد Ultra-M
في الإعداد الفائق لتقنية Ultra-M، قد تكون هناك سيناريوهات يلزم فيها إستبدال اللوحة الأم في أنواع الخوادم هذه: أجهزة الكمبيوتر ومحركات الأقراص التي تعمل بنظام التشغيل OSD - الحوسبة ووحدة التحكم.
ملاحظة: يتم إستبدال أقراص التمهيد مع تركيب OpenStack بعد إستبدال اللوحة الأم. وبالتالي، لا يوجد متطلبات لإضافة العقدة مرة أخرى إلى السحابة. بمجرد تشغيل الخادم بعد نشاط الاستبدال، فإنه سيقوم بتسجيل نفسه مرة أخرى في مكدس السحابة الزائدة.
إستبدال اللوحات الرئيسية في عقدة الحوسبة
قبل النشاط، يتم إيقاف تشغيل الأجهزة الافتراضية (VM) المستضافة في عقدة "الحوسبة" بشكل جميل. وبمجرد إستبدال اللوحة الأم، تتم إستعادة الأجهزة الافتراضية.
تحديد الأجهزة الافتراضية المستضافة في عقدة الحوسبة
التعرف على الأجهزة الافتراضية (VM) المستضافة على خادم الحوسبة. وقد يكون هناك إحتمالان:
يحتوي خادم الكمبيوتر على SF VM فقط:
[stack@director ~]$ nova list --field name,host | grep compute-10
| 49ac5f22-469e-4b84-badc-031083db0533 | VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d |
pod1-compute-10.localdomain |
يحتوي خادم الكمبيوتر على مجموعة CF/ESC/EM/UAS من VMs:
[stack@director ~]$ nova list --field name,host | grep compute-8
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-compute-8.localdomain |
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229 | pod1-compute-8.localdomain |
| 75528898-ef4b-4d68-b05d-882014708694 | VNF2-ESC-ESC-0 | pod1-compute-8.localdomain |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-compute-8.localdomain |
ملاحظة: في الإخراج المعروض هنا، يتوافق العمود الأول مع UUID، بينما يمثل العمود الثاني اسم VM، أما العمود الثالث فهو اسم المضيف حيث يوجد VM. سيتم إستخدام المعلمات من هذا الإخراج في الأقسام التالية.
إيقاف تشغيل الطاقة الرشيقة
القضية 1. Compute Node Host SF VM فقط
سجل الدخول إلى StarOS VNF وحدد البطاقة التي تطابق SF VM. أستخدم المعرف الفريد (UID) الخاص بمعرف فئة المورد (VM) المحدد من القسم التعرف على الأجهزة الافتراضية (VM) المستضافة في عقدة الحوسبة، والتعرف على البطاقة المطابقة لمعرف المستخدم الموحد:
[local]VNF2# show card hardware
Tuesday might 08 16:49:42 UTC 2018
<snip>
Card 8:
Card Type : 4-Port Service Function Virtual Card
CPU Packages : 26 [#0, #1, #2, #3, #4, #5, #6, #7, #8, #9, #10, #11, #12, #13, #14, #15, #16, #17, #18, #19, #20, #21, #22, #23, #24, #25]
CPU Nodes : 2
CPU Cores/Threads : 26
Memory : 98304M (qvpc-di-large)
UUID/Serial Number : 49AC5F22-469E-4B84-BADC-031083DB0533
<snip>
تحقق من حالة البطاقة:
[local]VNF2# show card table
Tuesday might 08 16:52:53 UTC 2018
Slot Card Type Oper State SPOF Attach
----------- -------------------------------------- ------------- ---- ------
1: CFC Control Function Virtual Card Active No
2: CFC Control Function Virtual Card Standby -
3: FC 4-Port Service Function Virtual Card Active No
4: FC 4-Port Service Function Virtual Card Active No
5: FC 4-Port Service Function Virtual Card Active No
6: FC 4-Port Service Function Virtual Card Active No
7: FC 4-Port Service Function Virtual Card Active No
8: FC 4-Port Service Function Virtual Card Active No
9: FC 4-Port Service Function Virtual Card Active No
10: FC 4-Port Service Function Virtual Card Standby -
إذا كانت البطاقة في الحالة النشطة، فقم بنقل البطاقة إلى حالة الاستعداد:
[local]VNF2# card migrate from 8 to 10
سجل الدخول إلى عقدة ESC التي تتوافق مع VNF وفحص حالة SF VM:
[admin@VNF2-esc-esc-0 ~]$ cd /opt/cisco/esc/esc-confd/esc-cli
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229</vm_name>
<state>VM_ALIVE_STATE</state>
<vm_name> VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d</vm_name>
<state>VM_ALIVE_STATE</state>
<snip>
إيقاف SF VM باستخدام اسم VM الخاص به. (اسم الجهاز الظاهري الذي تمت ملاحظته من القسم التعرف على الأجهزة الافتراضية المستضافة في عقدة الحوسبة😞
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli vm-action STOP VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d
وبمجرد إيقافه، يجب أن يدخل VM حالة إيقاف التشغيل:
[admin@VNF2-esc-esc-0 ~]$ cd /opt/cisco/esc/esc-confd/esc-cli
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229</vm_name>
<state>VM_ALIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c3_0_3e0db133-c13b-4e3d-ac14-
<state>VM_ALIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d</vm_name>
<state>VM_SHUTOFF_STATE</state>
<snip>
القضية 2. تستضيف عقدة الحوسبة CF/ESC/EM/UAS
سجل الدخول إلى StarOS VNF وحدد البطاقة التي تطابق CF VM. أستخدم UUID الخاص ب CF VM المحدد من القسم التعرف على VMs المستضافة في عقدة الكمبيوتر، والعثور على البطاقة المطابقة لمعرف المستخدم الموحد:
[local]VNF2# show card hardware
Tuesday might 08 16:49:42 UTC 2018
<snip>
Card 2:
Card Type : Control Function Virtual Card
CPU Packages : 8 [#0, #1, #2, #3, #4, #5, #6, #7]
CPU Nodes : 1
CPU Cores/Threads : 8
Memory : 16384M (qvpc-di-large)
UUID/Serial Number : F9C0763A-4A4F-4BBD-AF51-BC7545774BE2
<snip>
تحقق من حالة البطاقة:
[local]VNF2# show card table
Tuesday might 08 16:52:53 UTC 2018
Slot Card Type Oper State SPOF Attach
----------- -------------------------------------- ------------- ---- ------
1: CFC Control Function Virtual Card Standby -
2: CFC Control Function Virtual Card Active No
3: FC 4-Port Service Function Virtual Card Active No
4: FC 4-Port Service Function Virtual Card Active No
5: FC 4-Port Service Function Virtual Card Active No
6: FC 4-Port Service Function Virtual Card Active No
7: FC 4-Port Service Function Virtual Card Active No
8: FC 4-Port Service Function Virtual Card Active No
9: FC 4-Port Service Function Virtual Card Active No
10: FC 4-Port Service Function Virtual Card Standby -
إذا كانت البطاقة في الحالة النشطة، فقم بنقل البطاقة إلى حالة الاستعداد:
[local]VNF2# card migrate from 2 to 1
قم بتسجيل الدخول إلى عقدة ESC التي تتوافق مع VNF وتحقق من حالة الأجهزة الافتراضية (VMs):
[admin@VNF2-esc-esc-0 ~]$ cd /opt/cisco/esc/esc-confd/esc-cli
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229</vm_name>
<state>VM_ALIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c3_0_3e0db133-c13b-4e3d-ac14-
<state>VM_ALIVE_STATE</state>
<deployment_name>VNF2-DEPLOYMENT-em</deployment_name>
<vm_id>507d67c2-1d00-4321-b9d1-da879af524f8</vm_id>
<vm_id>dc168a6a-4aeb-4e81-abd9-91d7568b5f7c</vm_id>
<vm_id>9ffec58b-4b9d-4072-b944-5413bf7fcf07</vm_id>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea</vm_name>
<state>VM_ALIVE_STATE</state>
<snip>
إيقاف تشغيل CF و EM VM واحدا تلو الآخر باستخدام اسم الأجهزة الافتراضية الخاص به. (اسم الجهاز الظاهري الذي تمت ملاحظته من القسم التعرف على الأجهزة الافتراضية المستضافة في عقدة الحوسبة😞
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli vm-action STOP VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli vm-action STOP VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea
بعد توقفها، يجب أن يدخل VMs حالة إيقاف التشغيل:
[admin@VNF2-esc-esc-0 ~]$ cd /opt/cisco/esc/esc-confd/esc-cli
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229</vm_name>
<state>VM_SHUTOFF_STATE</state>
<vm_name>VNF2-DEPLOYM_c3_0_3e0db133-c13b-4e3d-ac14-
<state>VM_ALIVE_STATE</state>
<deployment_name>VNF2-DEPLOYMENT-em</deployment_name>
<vm_id>507d67c2-1d00-4321-b9d1-da879af524f8</vm_id>
<vm_id>dc168a6a-4aeb-4e81-abd9-91d7568b5f7c</vm_id>
<vm_id>9ffec58b-4b9d-4072-b944-5413bf7fcf07</vm_id>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea</vm_name>
VM_SHUTOFF_STATE
<snip>
قم بتسجيل الدخول إلى ESC المستضاف في عقدة الحوسبة وتحقق مما إذا كان في الحالة الرئيسية. إذا كانت الإجابة بنعم، فقم بتبديل ESC إلى وضع الاستعداد:
[admin@VNF2-esc-esc-0 esc-cli]$ escadm status
0 ESC status=0 ESC Master Healthy
[admin@VNF2-esc-esc-0 ~]$ sudo service keepalived stop
Stopping keepalived: [ OK ]
[admin@VNF2-esc-esc-0 ~]$ escadm status
1 ESC status=0 In SWITCHING_TO_STOP state. Please check status after a while.
[admin@VNF2-esc-esc-0 ~]$ sudo reboot
Broadcast message from admin@vnf1-esc-esc-0.novalocal
(/dev/pts/0) at 13:32 ...
The system is going down for reboot NOW!
استبدل اللوحة الأم
يمكن الرجوع إلى الخطوات المتعلقة باستبدال اللوحة الأم في خادم UCS C240 M4: دليل خدمة وتثبيت خادم Cisco UCS C240 M4
قم بتسجيل الدخول إلى الخادم باستخدام CIMC IP.
قم بإجراء ترقية BIOS إذا لم تكن البرامج الثابتة متوافقة مع الإصدار الموصى به المستخدم سابقا. تم توضيح خطوات ترقية BIOS هنا: دليل ترقية BIOS للخادم المركب على حامل Cisco UCS C-Series
إستعادة الأجهزة الافتراضية
القضية 1. Compute Node Host SF VM فقط
SF VM يكون في حالة خطأ في قائمة نوفا:
[stack@director ~]$ nova list |grep VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d
| 49ac5f22-469e-4b84-badc-031083db0533 | VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d | ERROR | - | NOSTATE |
إستردت ال SF VM من ال esc:
[admin@VNF2-esc-esc-0 ~]$ sudo /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli recovery-vm-action DO VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d
[sudo] password for admin:
Recovery VM Action
/opt/cisco/esc/confd/bin/netconf-console --port=830 --host=127.0.0.1 --user=admin --privKeyFile=/root/.ssh/confd_id_dsa --privKeyType=dsa --rpc=/tmp/esc_nc_cli.ZpRCGiieuW
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="1">
<ok/>
</rpc-reply>
راقبت الموقع winesc.log:
admin@VNF2-esc-esc-0 ~]$ tail -f /var/log/esc/yangesc.log
…
14:59:50,112 07-Nov-2017 WARN Type: VM_RECOVERY_COMPLETE
14:59:50,112 07-Nov-2017 WARN Status: SUCCESS
14:59:50,112 07-Nov-2017 WARN Status Code: 200
14:59:50,112 07-Nov-2017 WARN Status Msg: Recovery: Successfully recovered VM [VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d].
ضمنت أن يظهر ال SF بطاقة SF كإستعداد SF في ال VNF.
القضية 2. تستضيف Compute Node وحدات UAS و ESC و EM و CF
إستعادة نظام التشغيل UAS VM
تحقق من حالة UAS VM في قائمة نوفا وقم بحذفها:
[stack@director ~]$ nova list | grep VNF2-UAS-uas-0
| 307a704c-a17c-4cdc-8e7a-3d6e7e4332fa | VNF2-UAS-uas-0 | ACTIVE | - | Running | VNF2-UAS-uas-orchestration=172.168.11.10; VNF2-UAS-uas-management=172.168.10.3
[stack@tb5-ospd ~]$ nova delete VNF2-UAS-uas-0
Request to delete server VNF2-UAS-uas-0 has been accepted.
لاسترداد AutoVNF-UAS VM، قم بتشغيل البرنامج النصي لفحص UAS للتحقق من الحالة. يجب الإبلاغ عن خطأ. ثم قم بالتشغيل مرة أخرى باستخدام — خيار الإصلاح من أجل إعادة إنشاء جهاز UAS VM المفقود:
[stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts/
[stack@director scripts]$ ./uas-check.py auto-vnf VNF2-UAS
2017-12-08 12:38:05,446 - INFO: Check of AutoVNF cluster started
2017-12-08 12:38:07,925 - INFO: Instance 'vnf1-UAS-uas-0' status is 'ERROR'
2017-12-08 12:38:07,925 - INFO: Check completed, AutoVNF cluster has recoverable errors
[stack@director scripts]$ ./uas-check.py auto-vnf VNF2-UAS --fix
2017-11-22 14:01:07,215 - INFO: Check of AutoVNF cluster started
2017-11-22 14:01:09,575 - INFO: Instance VNF2-UAS-uas-0' status is 'ERROR'
2017-11-22 14:01:09,575 - INFO: Check completed, AutoVNF cluster has recoverable errors
2017-11-22 14:01:09,778 - INFO: Removing instance VNF2-UAS-uas-0'
2017-11-22 14:01:13,568 - INFO: Removed instance VNF2-UAS-uas-0'
2017-11-22 14:01:13,568 - INFO: Creating instance VNF2-UAS-uas-0' and attaching volume ‘VNF2-UAS-uas-vol-0'
2017-11-22 14:01:49,525 - INFO: Created instance ‘VNF2-UAS-uas-0'
سجل الدخول إلى AutoVNF-UAS. استني كم دقيقة وبعدين بتشوف انو الطيران بدون طيار بيرجع حالو:
VNF2-autovnf-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.17.181.101
INSTANCE IP STATE ROLE
-----------------------------------
172.17.180.6 alive CONFD-SLAVE
172.17.180.7 alive CONFD-MASTER
172.17.180.9 alive NA
إسترداد ESC VM
تحقق من حالة ESC VM من قائمة نوفا وقم بحذفها:
stack@director scripts]$ nova list |grep ESC-1
| c566efbf-1274-4588-a2d8-0682e17b0d41 | VNF2-ESC-ESC-1 | ACTIVE | - | Running | VNF2-UAS-uas-orchestration=172.168.11.14; VNF2-UAS-uas-management=172.168.10.4 |
[stack@director scripts]$ nova delete VNF2-ESC-ESC-1
Request to delete server VNF2-ESC-ESC-1 has been accepted.
من AutoVNF-UAS، ابحث عن حركة نشر ESC وفي سجل الحركة، ابحث عن سطر الأوامر boot_vm.py لإنشاء مثيل ESC:
ubuntu@VNF2-uas-uas-0:~$ sudo -i
root@VNF2-uas-uas-0:~# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on VNF2-uas-uas-0
VNF2-uas-uas-0#show transaction
TX ID TX TYPE DEPLOYMENT ID TIMESTAMP STATUS
-----------------------------------------------------------------------------------------------------------------------------
35eefc4a-d4a9-11e7-bb72-fa163ef8df2b vnf-deployment VNF2-DEPLOYMENT 2017-11-29T02:01:27.750692-00:00 deployment-success
73d9c540-d4a8-11e7-bb72-fa163ef8df2b vnfm-deployment VNF2-ESC 2017-11-29T01:56:02.133663-00:00 deployment-success
VNF2-uas-uas-0#show logs 73d9c540-d4a8-11e7-bb72-fa163ef8df2b | display xml
<config xmlns="http://tail-f.com/ns/config/1.0">
<logs xmlns="http://www.cisco.com/usp/nfv/usp-autovnf-oper">
<tx-id>73d9c540-d4a8-11e7-bb72-fa163ef8df2b</tx-id>
<log>2017-11-29 01:56:02,142 - VNFM Deployment RPC triggered for deployment: VNF2-ESC, deactivate: 0
2017-11-29 01:56:02,179 - Notify deployment
..
2017-11-29 01:57:30,385 - Creating VNFM 'VNF2-ESC-ESC-1' with [python //opt/cisco/vnf-staging/bootvm.py VNF2-ESC-ESC-1 --flavor VNF2-ESC-ESC-flavor --image 3fe6b197-961b-4651-af22-dfd910436689 --net VNF2-UAS-uas-management --gateway_ip 172.168.10.1 --net VNF2-UAS-uas-orchestration --os_auth_url http://10.1.2.5:5000/v2.0 --os_tenant_name core --os_username ****** --os_password ****** --bs_os_auth_url http://10.1.2.5:5000/v2.0 --bs_os_tenant_name core --bs_os_username ****** --bs_os_password ****** --esc_ui_startup false --esc_params_file /tmp/esc_params.cfg --encrypt_key ****** --user_pass ****** --user_confd_pass ****** --kad_vif eth0 --kad_vip 172.168.10.7 --ipaddr 172.168.10.6 dhcp --ha_node_list 172.168.10.3 172.168.10.6 --file root:0755:/opt/cisco/esc/esc-scripts/esc_volume_em_staging.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_volume_em_staging.sh --file root:0755:/opt/cisco/esc/esc-scripts/esc_vpc_chassis_id.py:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_vpc_chassis_id.py --file root:0755:/opt/cisco/esc/esc-scripts/esc-vpc-di-internal-keys.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc-vpc-di-internal-keys.sh
احفظ خط boot_vm.py في ملف نصي Shell (esc.sh) وقم بتحديث جميع أسطر اسم المستخدم **** وكلمة المرور ***** مع المعلومات الصحيحة (بشكل خاص core/<password>). تحتاج إلى إزالة خيار —encrypt_key أيضا. بالنسبة user_pass وuser_confd_pass، تحتاج إلى إستخدام التنسيق - username: كلمة المرور (مثال - admin:<password>).
ابحث عن عنوان URL إلى bootvm.py من running-config واحصل على ملف bootvm.py إلى VM autoVNF. في هذه الحالة، 10.1.2.3 هو عنوان IP الخاص ب AutoIT VM:
root@VNF2-uas-uas-0:~# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on VNF2-uas-uas-0
VNF2-uas-uas-0#show running-config autovnf-vnfm:vnfm
…
configs bootvm
value http:// 10.1.2.3:80/bundles/5.1.7-2007/vnfm-bundle/bootvm-2_3_2_155.py
!
root@VNF2-uas-uas-0:~# wget http://10.1.2.3:80/bundles/5.1.7-2007/vnfm-bundle/bootvm-2_3_2_155.py
--2017-12-01 20:25:52-- http://10.1.2.3 /bundles/5.1.7-2007/vnfm-bundle/bootvm-2_3_2_155.py
Connecting to 10.1.2.3:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 127771 (125K) [text/x-python]
Saving to: ‘bootvm-2_3_2_155.py’
100%[=====================================================================================>] 127,771 --.-K/s in 0.001s
2017-12-01 20:25:52 (173 MB/s) - ‘bootvm-2_3_2_155.py’ saved [127771/127771]
إنشاء ملف /tmp/esc_params.cfg:
root@VNF2-uas-uas-0:~# echo "openstack.endpoint=publicURL" > /tmp/esc_params.cfg
تنفيذ برنامج نصي من Shell لنشر ESC من عقدة UAS:
root@VNF2-uas-uas-0:~# /bin/sh esc.sh
+ python ./bootvm.py VNF2-ESC-ESC-1 --flavor VNF2-ESC-ESC-flavor --image 3fe6b197-961b-4651-af22-dfd910436689
--net VNF2-UAS-uas-management --gateway_ip 172.168.10.1 --net VNF2-UAS-uas-orchestration --os_auth_url
http://10.1.2.5:5000/v2.0 --os_tenant_name core --os_username core --os_password <PASSWORD> --bs_os_auth_url
http://10.1.2.5:5000/v2.0 --bs_os_tenant_name core --bs_os_username core --bs_os_password <PASSWORD>
--esc_ui_startup false --esc_params_file /tmp/esc_params.cfg --user_pass admin:<PASSWORD> --user_confd_pass
admin:<PASSWORD> --kad_vif eth0 --kad_vip 172.168.10.7 --ipaddr 172.168.10.6 dhcp --ha_node_list 172.168.10.3
172.168.10.6 --file root:0755:/opt/cisco/esc/esc-scripts/esc_volume_em_staging.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_volume_em_staging.sh
--file root:0755:/opt/cisco/esc/esc-scripts/esc_vpc_chassis_id.py:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_vpc_chassis_id.py
--file root:0755:/opt/cisco/esc/esc-scripts/esc-vpc-di-internal-keys.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc-vpc-di-internal-keys.sh
سجل الدخول إلى ESC جديد وتحقق من حالة النسخ الاحتياطي:
ubuntu@VNF2-uas-uas-0:~$ ssh admin@172.168.11.14
…
####################################################################
# ESC on VNF2-esc-esc-1.novalocal is in BACKUP state.
####################################################################
[admin@VNF2-esc-esc-1 ~]$ escadm status
0 ESC status=0 ESC Backup Healthy
[admin@VNF2-esc-esc-1 ~]$ health.sh
============== ESC HA (BACKUP) ===================================================
ESC HEALTH PASSED
إسترداد الأجهزة الافتراضية باستخدام تقنية CF و EM من تقنية ESC
تحقق من حالة CF و EM VMs من قائمة نوفا. يجب أن تكون في حالة الخطأ:
[stack@director ~]$ source corerc
[stack@director ~]$ nova list --field name,host,status |grep -i err
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | None | ERROR|
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229 |None | ERROR
سجل الدخول إلى مدير ESC، وقم بتشغيل recovery-vm-action لكل EM و CF VM متأثر. كن صبورا. يقوم ESC بجدولة إجراء الاسترداد وقد لا يحدث ذلك لدقائق قليلة. راقبت الموقع winesc.log:
sudo /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli recovery-vm-action DO
[admin@VNF2-esc-esc-0 ~]$ sudo /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli recovery-vm-action DO VNF2-DEPLOYMENT-_VNF2-D_0_a6843886-77b4-4f38-b941-74eb527113a8
[sudo] password for admin:
Recovery VM Action
/opt/cisco/esc/confd/bin/netconf-console --port=830 --host=127.0.0.1 --user=admin --privKeyFile=/root/.ssh/confd_id_dsa --privKeyType=dsa --rpc=/tmp/esc_nc_cli.ZpRCGiieuW
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="1">
<ok/>
</rpc-reply>
[admin@VNF2-esc-esc-0 ~]$ tail -f /var/log/esc/yangesc.log
…
14:59:50,112 07-Nov-2017 WARN Type: VM_RECOVERY_COMPLETE
14:59:50,112 07-Nov-2017 WARN Status: SUCCESS
14:59:50,112 07-Nov-2017 WARN Status Code: 200
14:59:50,112 07-Nov-2017 WARN Status Msg: Recovery: Successfully recovered VM [VNF2-DEPLOYMENT-_VNF2-D_0_a6843886-77b4-4f38-b941-74eb527113a8]
قم بتسجيل الدخول إلى em جديدة وتحقق من أن حالة em موجودة:
ubuntu@VNF2vnfddeploymentem-1:~$ /opt/cisco/ncs/current/bin/ncs_cli -u admin -C
admin connected from 172.17.180.6 using ssh on VNF2vnfddeploymentem-1
admin@scm# show ems
EM VNFM
ID SLA SCM PROXY
---------------------
2 up up up
3 up up up
سجل الدخول إلى StarOS VNF وتحقق من أن بطاقة CF في حالة الاستعداد.
معالجة فشل إسترداد ESC
في الحالات التي يفشل فيها ESC في بدء تشغيل VM بسبب حالة غير متوقعة، يوصى بإجراء تبديل ESC من خلال إعادة تشغيل ESC الرئيسي. تستغرق عملية تحويل مركز الأنظمة الإلكترونية (ESC) حوالي دقيقة. قم بتشغيل البرنامج النصي health.sh على ESC الأساسي الجديد للتحقق من الحالة قيد التشغيل. مدير ESC لبدء تشغيل VM وإصلاح حالة VM. تستغرق مهمة الاسترداد هذه ما يصل إلى 5 دقائق لإكمالها.
يمكنك مراقبة /var/log/esc/yangesc.log و/var/log/esc/escmanager.log. إذا لم يظهر لك الجهاز الظاهري الذي تم إسترداده بعد 5 إلى 7 دقائق، فسيحتاج المستخدم إلى الذهاب وإجراء عملية الاسترداد اليدوي للأجهزة الافتراضية (الأجهزة الافتراضية) المتأثرة.
إستبدال اللوحات الأم في عقدة حوسبة OSD
قبل النشاط، يتم إيقاف تشغيل الأجهزة الافتراضية (VM) المستضافة في عقدة "الحوسبة" بشكل جيد ويتم وضع CEPH في وضع الصيانة. وبمجرد إستبدال اللوحة الأم، تتم إستعادة الأجهزة الافتراضية (VM) ويتم نقل CEPH خارج وضع الصيانة.
وضع CEPH في وضع الصيانة
تحقق من وجود حالة الشجرة CEPH في الخادم.
[heat-admin@pod1-osd-compute-1 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod1-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-3 4.35999 host pod1-osd-compute-2
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
-4 4.35999 host pod1-osd-compute-1
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
قم بتسجيل الدخول إلى عقدة حوسبة OSD ووضع CEPH في وضع الصيانة.
[root@pod1-osd-compute-1 ~]# sudo ceph osd set norebalance
[root@pod1-osd-compute-1 ~]# sudo ceph osd set noout
[root@pod1-osd-compute-1 ~]# sudo ceph status
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_WARN
noout,norebalance,sortbitwise,require_jewel_osds flag(s) set
monmap e1: 3 mons at {pod1-controller-0=11.118.0.40:6789/0,pod1-controller-1=11.118.0.41:6789/0,pod1-controller-2=11.118.0.42:6789/0}
election epoch 58, quorum 0,1,2 pod1-controller-0,pod1-controller-1,pod1-controller-2
osdmap e194: 12 osds: 12 up, 12 in
flags noout,norebalance,sortbitwise,require_jewel_osds
pgmap v584865: 704 pgs, 6 pools, 531 GB data, 344 kobjects
1585 GB used, 11808 GB / 13393 GB avail
704 active+clean
client io 463 kB/s rd, 14903 kB/s wr, 263 op/s rd, 542 op/s wr
ملاحظة: عند إزالة CEPH، يمر RAID VNF HD بالحالة المخفضة ولكن يجب الوصول إلى محرك الأقراص الثابتة.
تحديد الأجهزة الافتراضية المستضافة في عقدة حوسبة OSD
التعرف على الأجهزة الافتراضية (VM) المستضافة على خادم حوسبة OSD. وقد يكون هناك إحتمالان:
يحتوي خادم OSD-Compute على مجموعة إدارة العناصر (EM)/UAS/النشر التلقائي/تقنية المعلومات التلقائية من VMs:
[stack@director ~]$ nova list --field name,host | grep osd-compute-0
| c6144778-9afd-4946-8453-78c817368f18 | AUTO-DEPLOY-VNF2-uas-0 | pod1-osd-compute-0.localdomain |
| 2d051522-bce2-4809-8d63-0c0e17f251dc | AUTO-IT-VNF2-uas-0 | pod1-osd-compute-0.localdomain |
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-osd-compute-0.localdomain |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-osd-compute-0.localdomain |
يحتوي خادم الحوسبة على مجموعة وظائف التحكم (CF)/وحدة التحكم المرنة في الخدمات (ESC)/مدير العناصر (EM)/ (UAS) من VMs:
[stack@director ~]$ nova list --field name,host | grep osd-compute-1
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-compute-8.localdomain |
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229 | pod1-compute-8.localdomain |
| 75528898-ef4b-4d68-b05d-882014708694 | VNF2-ESC-ESC-0 | pod1-compute-8.localdomain |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-compute-8.localdomain |
ملاحظة: في الإخراج المعروض هنا، يتوافق العمود الأول مع UUID، بينما يمثل العمود الثاني اسم VM، أما العمود الثالث فهو اسم المضيف حيث يوجد VM. سيتم إستخدام المعلمات من هذا الإخراج في الأقسام التالية.
إيقاف تشغيل الطاقة الرشيقة
القضية 1. تستضيف عقدة OSD-Compute CF/ESC/EM/UAS
إجراء تشغيل الأجهزة الافتراضية (VMs) التي تعمل بالترتيب وفقا لمعيار CF/ESC/EM/UAS هو نفسه بغض النظر عما إذا كان قد تم إستضافة الأجهزة الافتراضية (VM) في عقدة Compute أو OSD-Compute. اتبع الخطوات التي تتيحها عملية إستبدال اللوحات الأم في عقدة الحوسبة للتخلص من الأجهزة الافتراضية بسهولة تامة.
القضية 2. تستضيف عقدة OSD-Compute النشر التلقائي/Auto-it/em/UAS
نسخ CDB إحتياطيا للنشر التلقائي
قم بإجراء نسخ إحتياطي لبيانات CDB المميزة للنشر التلقائي بشكل دوري أو بعد كل عملية تنشيط/إلغاء تنشيط وحفظ الملف إلى خادم نسخ إحتياطي. لا يعد النشر التلقائي زائدا وفي حالة فقدان هذه البيانات، لن تتمكن من إلغاء تنشيط النشر بشكل رائع.
قم بتسجيل الدخول إلى دليل cdb المربوط الخاص بالنشر التلقائي والنسخ الاحتياطي.
ubuntu@auto-deploy-iso-2007-uas-0:~ $sudo -i
root@auto-deploy-iso-2007-uas-0:~#service uas-confd stop
uas-confd stop/waiting
root@auto-deploy-iso-2007-uas-0:~# cd /opt/cisco/usp/uas/confd-6.3.1/var/confd
root@auto-deploy-iso-2007-uas-0:/opt/cisco/usp/uas/confd-6.3.1/var/confd#tar cvf autodeploy_cdb_backup.tar cdb/
cdb/
cdb/O.cdb
cdb/C.cdb
cdb/aaa_init.xml
cdb/A.cdb
root@auto-deploy-iso-2007-uas-0:~# service uas-confd start
uas-confd start/running, process 13852
ملاحظة: opy autodeploy_cdb_backup.tar لإجراء نسخ إحتياطي للخادم.
النسخ الاحتياطي للنظام.cfg من Auto-it
إجراء عملية نسخ إحتياطي لملف system.cfg لإجراء نسخ إحتياطي للخادم:
Auto-it = 10.1.1.2
Backup server = 10.2.2.2
[stack@director ~]$ ssh ubuntu@10.1.1.2
ubuntu@10.1.1.2's password:
Welcome to Ubuntu 14.04.3 LTS (GNU/Linux 3.13.0-76-generic x86_64)
* Documentation: https://help.ubuntu.com/
System information as of Wed Jun 13 16:21:34 UTC 2018
System load: 0.02 Processes: 87
Usage of /: 15.1% of 78.71GB Users logged in: 0
Memory usage: 13% IP address for eth0: 172.16.182.4
Swap usage: 0%
Graph this data and manage this system at:
https://landscape.canonical.com/
Get cloud support with Ubuntu Advantage Cloud Guest:
http://www.ubuntu.com/business/services/cloud
Cisco Ultra Services Platform (USP)
Build Date: Wed Feb 14 12:58:22 EST 2018
Description: UAS build assemble-uas#1891
sha1: bf02ced
ubuntu@auto-it-vnf-uas-0:~$ scp -r /opt/cisco/usp/uploads/system.cfg root@10.2.2.2:/home/stack
root@10.2.2.2's password:
system.cfg 100% 565 0.6KB/s 00:00
ubuntu@auto-it-vnf-uas-0:~$
ملاحظة: يكون الإجراء الخاص بتشغيل أجهزة VM/UAS هو نفسه بغض النظر عما إذا كان قد تم إستضافة أجهزة VM في عقدة Compute أو OSD-Compute أم لا.
اتبع الخطوات التي تتطلبها عملية إستبدال اللوحات الأم في عقدة الحوسبة من أجل إيقاف تشغيل هذه الأجهزة الافتراضية بسهولة.
استبدل اللوحة الأم
يمكن الرجوع إلى الخطوات المتعلقة باستبدال اللوحة الأم في خادم UCS C240 M4: دليل خدمة وتثبيت خادم Cisco UCS C240 M4
قم بتسجيل الدخول إلى الخادم باستخدام CIMC IP.
قم بإجراء ترقية BIOS إذا لم تكن البرامج الثابتة متوافقة مع الإصدار الموصى به المستخدم سابقا. تم توضيح خطوات ترقية BIOS هنا: دليل ترقية BIOS للخادم المركب على حامل Cisco UCS C-Series
نقل CEPH خارج وضع الصيانة
قم بتسجيل الدخول إلى عقدة حوسبة OSD ونقل CEPH خارج وضع الصيانة.
[root@pod1-osd-compute-1 ~]# sudo ceph osd unset norebalance
[root@pod1-osd-compute-1 ~]# sudo ceph osd unset noout
[root@pod1-osd-compute-1 ~]# sudo ceph status
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
monmap e1: 3 mons at {pod1-controller-0=11.118.0.40:6789/0,pod1-controller-1=11.118.0.41:6789/0,pod1-controller-2=11.118.0.42:6789/0}
election epoch 58, quorum 0,1,2 pod1-controller-0,pod1-controller-1,pod1-controller-2
osdmap e196: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v584954: 704 pgs, 6 pools, 531 GB data, 344 kobjects
1585 GB used, 11808 GB / 13393 GB avail
704 active+clean
client io 12888 kB/s wr, 0 op/s rd, 81 op/s wr
إستعادة الأجهزة الافتراضية
القضية 1. تستضيف عقدة OSD-Compute أنظمة CF و ESC و EM و UAS
إجراء إستعادة الأجهزة الافتراضية (VMs) التي تعمل بالتوافق مع معيار CF/ESC/EM/UAS هو نفسه بغض النظر عما إذا كان قد تم إستضافة الأجهزة الافتراضية (VMs) في عقدة Compute أو OSD-Compute. اتبع الخطوات من الحالة 2. تستضيف عقدة الحوسبة CF/ESC/EM/UAS لاستعادة الأجهزة الافتراضية (VMs).
القضية 2. تستضيف عقدة OSD-Compute تقنية المعلومات التلقائية والنشر التلقائي و EM و UAS
إسترداد VM الذي تم نشره تلقائيا
من OSPD، إذا تأثر النشر التلقائي ل VM ولكنه لا يزال يظهر Active/Running، ستحتاج إلى حذفه أولا. إذا لم يتأثر النشر التلقائي، فقم بالتخطي إلى إسترداد الأجهزة الافتراضية (VM) التلقائية:
[stack@director ~]$ nova list |grep auto-deploy
| 9b55270a-2dcd-4ac1-aba3-bf041733a0c9 | auto-deploy-ISO-2007-uas-0 | ACTIVE | - | Running | mgmt=172.16.181.12, 10.1.2.7 [stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts
[stack@director ~]$ ./auto-deploy-booting.sh --floating-ip 10.1.2.7 --delete
بمجرد حذف النشر التلقائي، قم بإنشائه مرة أخرى بنفس العنوان floatingip:
[stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts
[stack@director scripts]$ ./auto-deploy-booting.sh --floating-ip 10.1.2.7
2017-11-17 07:05:03,038 - INFO: Creating AutoDeploy deployment (1 instance(s)) on 'http://10.84.123.4:5000/v2.0' tenant 'core' user 'core', ISO 'default'
2017-11-17 07:05:03,039 - INFO: Loading image 'auto-deploy-ISO-5-1-7-2007-usp-uas-1.0.1-1504.qcow2' from '/opt/cisco/usp/uas-installer/images/usp-uas-1.0.1-1504.qcow2'
2017-11-17 07:05:14,603 - INFO: Loaded image 'auto-deploy-ISO-5-1-7-2007-usp-uas-1.0.1-1504.qcow2'
2017-11-17 07:05:15,787 - INFO: Assigned floating IP '10.1.2.7' to IP '172.16.181.7'
2017-11-17 07:05:15,788 - INFO: Creating instance 'auto-deploy-ISO-5-1-7-2007-uas-0'
2017-11-17 07:05:42,759 - INFO: Created instance 'auto-deploy-ISO-5-1-7-2007-uas-0'
2017-11-17 07:05:42,759 - INFO: Request completed, floating IP: 10.1.2.7
انسخ ملف AutoDeploy.cfg وISO وملف confd_backup tar من خادم النسخ الاحتياطي لديك إلى النشر التلقائي ل VM واستعادة ملفات cdb المضمنة من ملف النسخ الاحتياطي tar:
ubuntu@auto-deploy-iso-2007-uas-0:~# sudo -i
ubuntu@auto-deploy-iso-2007-uas-0:# service uas-confd stop
uas-confd stop/waiting
root@auto-deploy-iso-2007-uas-0:# cd /opt/cisco/usp/uas/confd-6.3.1/var/confd
root@auto-deploy-iso-2007-uas-0:/opt/cisco/usp/uas/confd-6.3.1/var/confd# tar xvf /home/ubuntu/ad_cdb_backup.tar
cdb/
cdb/O.cdb
cdb/C.cdb
cdb/aaa_init.xml
cdb/A.cdb
root@auto-deploy-iso-2007-uas-0~# service uas-confd start
uas-confd start/running, process 2036
تحقق من تحميل الإرساء بشكل صحيح عن طريق التحقق من الحركات السابقة. قم بتحديث autodeploy.cfg باسم كمبيوتر OSD جديد. راجع القسم- الخطوة النهائية: تحديث تكوين النشر التلقائي.
root@auto-deploy-iso-2007-uas-0:~# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on auto-deploy-iso-2007-uas-0
auto-deploy-iso-2007-uas-0#show transaction
SERVICE SITE
DEPLOYMENT SITE TX AUTOVNF VNF AUTOVNF
TX ID TX TYPE ID DATE AND TIME STATUS ID ID ID ID TX ID
-------------------------------------------------------------------------------------------------------------------------------------
1512571978613 service-deployment tb5bxb 2017-12-06T14:52:59.412+00:00 deployment-success
auto-deploy-iso-2007-uas-0# exit
إسترداد Auto-IT VM
من OSPD، إذا كان تطبيق Auto-it VM متأثرا ولكنه لا يزال يظهر ك Active/Running، فأنت بحاجة إلى حذفه. إذا لم يكن تلقائيا متأثرا، انتقل إلى التالي:
[stack@director ~]$ nova list |grep auto-it
| 580faf80-1d8c-463b-9354-781ea0c0b352 | auto-it-vnf-ISO-2007-uas-0 | ACTIVE | - | Running | mgmt=172.16.181.3, 10.1.2.8 [stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts
[stack@director ~]$ ./ auto-it-vnf-staging.sh --floating-ip 10.1.2.8 --delete
إعادة إنشاء تقنية Auto-IT من خلال تشغيل البرنامج النصي المرحلي ل Auto-IT-VNF:
[stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts
[stack@director scripts]$ ./auto-it-vnf-staging.sh --floating-ip 10.1.2.8
2017-11-16 12:54:31,381 - INFO: Creating StagingServer deployment (1 instance(s)) on 'http://10.84.123.4:5000/v2.0' tenant 'core' user 'core', ISO 'default'
2017-11-16 12:54:31,382 - INFO: Loading image 'auto-it-vnf-ISO-5-1-7-2007-usp-uas-1.0.1-1504.qcow2' from '/opt/cisco/usp/uas-installer/images/usp-uas-1.0.1-1504.qcow2'
2017-11-16 12:54:51,961 - INFO: Loaded image 'auto-it-vnf-ISO-5-1-7-2007-usp-uas-1.0.1-1504.qcow2'
2017-11-16 12:54:53,217 - INFO: Assigned floating IP '10.1.2.8' to IP '172.16.181.9'
2017-11-16 12:54:53,217 - INFO: Creating instance 'auto-it-vnf-ISO-5-1-7-2007-uas-0'
2017-11-16 12:55:20,929 - INFO: Created instance 'auto-it-vnf-ISO-5-1-7-2007-uas-0'
2017-11-16 12:55:20,930 - INFO: Request completed, floating IP: 10.1.2.8
أعد تحميل صورة ISO. في هذه الحالة، يكون عنوان IP ل Auto-IT 10.1.2.8. سيستغرق تحميل هذا الإجراء بضع دقائق:
[stack@director ~]$ cd images/5_1_7-2007/isos
[stack@director isos]$ curl -F file=@usp-5_1_7-2007.iso http://10.1.2.8:5001/isos
{
"iso-id": "5.1.7-2007"
}
to check the ISO image:
[stack@director isos]$ curl http://10.1.2.8:5001/isos
{
"isos": [
{
"iso-id": "5.1.7-2007"
}
]
}
نسخ ملفات VNF system.cfg من دليل OSPD Auto-Deployment إلى Auto-IT VM:
[stack@director autodeploy]$ scp system-vnf* ubuntu@10.1.2.8:.
ubuntu@10.1.2.8's password:
system-vnf1.cfg 100% 1197 1.2KB/s 00:00
system-vnf2.cfg 100% 1197 1.2KB/s 00:00
ubuntu@auto-it-vnf-iso-2007-uas-0:~$ pwd
/home/ubuntu
ubuntu@auto-it-vnf-iso-2007-uas-0:~$ ls
system-vnf1.cfg system-vnf2.cfg
ملاحظة: إجراءات الاسترداد الخاصة ب EM و UAS VM هي نفسها بغض النظر عما إذا كان VM مستضافا في Compute أو OSD-Compute. اتبع الخطوات التالية من إستبدال اللوحة الأم في عقدة الحوسبة للتخلص من هذه الأجهزة الافتراضية بسهولة.
إستبدال اللوحة الأم في عقدة وحدة التحكم
التحقق من حالة وحدة التحكم ووضع نظام المجموعة في وضع الصيانة
من OSPD، يمكنك تسجيل الدخول إلى وحدة التحكم والتحقق من أن أجهزة الكمبيوتر في حالة جيدة - حيث تظهر وحدات التحكم الثلاث جميعها على الإنترنت في Galera وحدات التحكم الثلاث كرئيسية.
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod1-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Mon Dec 4 00:46:10 2017 Last change: Wed Nov 29 01:20:52 2017 by hacluster via crmd on pod1-controller-0
3 nodes and 22 resources configured
Online: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Full list of resources:
ip-11.118.0.42 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-11.119.0.47 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
ip-11.120.0.49 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-192.200.0.102 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: haproxy-clone [haproxy]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
ip-11.120.0.47 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: redis-master [redis]
Masters: [ pod1-controller-2 ]
Slaves: [ pod1-controller-0 pod1-controller-1 ]
ip-10.84.123.35 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
openstack-cinder-volume (systemd:openstack-cinder-volume): Started pod1-controller-2
my-ipmilan-for-controller-0 (stonith:fence_ipmilan): Started pod1-controller-0
my-ipmilan-for-controller-1 (stonith:fence_ipmilan): Started pod1-controller-0
my-ipmilan-for-controller-2 (stonith:fence_ipmilan): Started pod1-controller-0
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
ضع نظام المجموعة في وضع الصيانة:
[heat-admin@pod1-controller-0 ~]$ sudo pcs cluster standby
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod1-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Mon Dec 4 00:48:24 2017 Last change: Mon Dec 4 00:48:18 2017 by root via crm_attribute on pod1-controller-0
3 nodes and 22 resources configured
Node pod1-controller-0: standby
Online: [ pod1-controller-1 pod1-controller-2 ]
Full list of resources:
ip-11.118.0.42 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-11.119.0.47 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
ip-11.120.0.49 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-192.200.0.102 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: haproxy-clone [haproxy]
Started: [ pod1-controller-1 pod1-controller-2 ]
Stopped: [ pod1-controller-0 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod1-controller-1 pod1-controller-2 ]
Slaves: [ pod1-controller-0 ]
ip-11.120.0.47 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: redis-master [redis]
Masters: [ pod1-controller-2 ]
Slaves: [ pod1-controller-1 ]
Stopped: [ pod1-controller-0 ]
ip-10.84.123.35 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
openstack-cinder-volume (systemd:openstack-cinder-volume): Started pod1-controller-2
my-ipmilan-for-controller-0 (stonith:fence_ipmilan): Started pod1-controller-1
my-ipmilan-for-controller-1 (stonith:fence_ipmilan): Started pod1-controller-1
my-ipmilan-for-controller-2 (stonith:fence_ipmilan): Started pod1-controller-2
استبدل اللوحة الأم
يمكن الرجوع إلى الخطوات المتعلقة باستبدال اللوحة الأم في خادم UCS C240 M4: دليل خدمة وتثبيت خادم Cisco UCS C240 M4
قم بتسجيل الدخول إلى الخادم باستخدام CIMC IP.
قم بإجراء ترقية BIOS إذا لم تكن البرامج الثابتة متوافقة مع الإصدار الموصى به المستخدم سابقا. تم توضيح خطوات ترقية BIOS هنا: دليل ترقية BIOS للخادم المركب على حامل Cisco UCS C-Series
إستعادة حالة نظام المجموعة
قم بتسجيل الدخول إلى وحدة التحكم التي تأثرت، قم بإزالة وضع الاستعداد عن طريق إعداد عدم الاستعداد. تحقق مما إذا كانت وحدة التحكم متصلة بنظام المجموعة أم لا، بينما يقوم Galera بعرض وحدات التحكم الثلاث كوحدات تحكم رئيسية. قد يستغرق ذلك بضع دقائق.
[heat-admin@pod1-controller-0 ~]$ sudo pcs cluster unstandby
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod1-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Mon Dec 4 01:08:10 2017 Last change: Mon Dec 4 01:04:21 2017 by root via crm_attribute on pod1-controller-0
3 nodes and 22 resources configured
Online: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Full list of resources:
ip-11.118.0.42 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-11.119.0.47 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
ip-11.120.0.49 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-192.200.0.102 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: haproxy-clone [haproxy]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
ip-11.120.0.47 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: redis-master [redis]
Masters: [ pod1-controller-2 ]
Slaves: [ pod1-controller-0 pod1-controller-1 ]
ip-10.84.123.35 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
openstack-cinder-volume (systemd:openstack-cinder-volume): Started pod1-controller-2
my-ipmilan-for-controller-0 (stonith:fence_ipmilan): Started pod1-controller-1
my-ipmilan-for-controller-1 (stonith:fence_ipmilan): Started pod1-controller-1
my-ipmilan-for-controller-2 (stonith:fence_ipmilan): Started pod1-controller-2
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
محفوظات المراجعة
| المراجعة | تاريخ النشر | التعليقات |
|---|---|---|
1.0 |
22-Aug-2018
|
الإصدار الأولي |
تمت المساهمة بواسطة مهندسو Cisco
- Padmaraj Ramanoudjam andخدمات Cisco المتقدمة
- Partheeban Rajagopalخدمات Cisco المتقدمة
 التعليقات
التعليقاتاتصل بنا
- فتح حالة دعم

- (تتطلب عقد خدمة Cisco)