إستخدام تصنيف المستند المستند المستند إلى ML لإدارة سياسة DLP بشكل فعال
المحتويات
المقدمة
يوضح هذا المستند كيفية إستخدام تصنيف المستند المستند المستند إلى ML (الذي تم إنشاؤه باستخدام Meta Llama 3) لتبسيط إدارة سياسة منع فقدان البيانات (DLP) وتحسينها.
نظرة عامة
يحسن تصنيف مستند ML مطابقة المحتوى ويجعل إدارة سياسة DLP أسهل. يمكنك الاختيار من بين أنواع المستندات التي تم تعريفها مسبقا والتي تم تدريبها مسبقا، مما يقلل من الحاجة إلى إنشاء تصنيفات بيانات معقدة من البداية بناء على البنود والأنماط.
كيفية إستخدام تصنيف المستند المستند المستند إلى ML
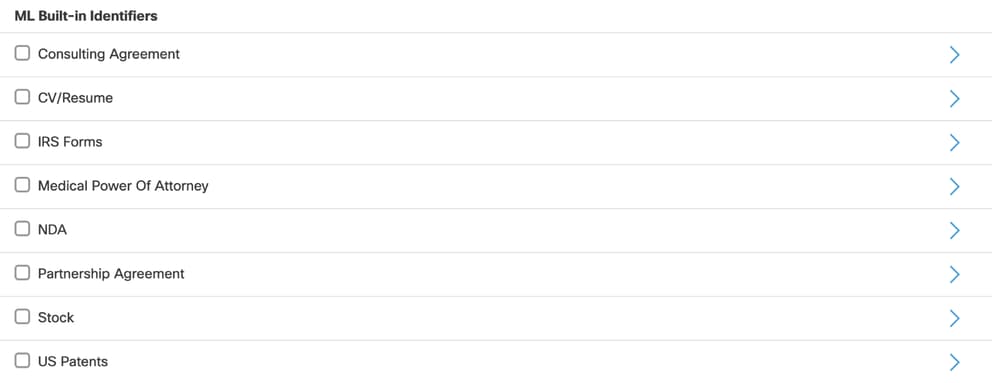
- يتوفر تصنيف المستند المستند المستند المستند إلى ML كمعرف مدمج عند إنشاء تصنيف بيانات.
- تظهر جميع المعرفات المدعومة المستندة إلى ML في قسم المعرفات المدمجة ل ML أثناء إعداد تصنيف البيانات.
 26221783199892
26221783199892
أنواع المستندات المدعومة
يمكنك إستخدام التصنيف المستند إلى ML لأنواع المستندات التالية:
- إتفاقيات التشاور
- CVs واستئنافها
- نماذج IRS
- الوكاله الطبيه
- إتفاقيات عدم الإفصاح (NDA)
- إتفاقيات الشراكة
- ستوك وبراءات الاختراع الأمريكية
اللغات والمناطق المدعومة
حيث تدعم النسخة الأولية مستندات اللغة الإنجليزية فقط. ومن المقرر تقديم الدعم للغات والمناطق الإضافية من أجل عمليات التحديث في المستقبل.
دعم DLP متعدد الأوضاع
يعمل تصنيف المستند المستند المستند المستند المستند إلى ML مع DLP في الوقت الفعلي و SAAs API DLP. إنه متوافق مع جميع أنواع الملفات المدعومة ب DLP.
الموارد ذات الصلة
ارجع إلى وثائق Secure Access و Umbrella للحصول على إرشادات حول إستخدام معرفات البيانات المستندة إلى ML في تصنيفات البيانات وقواعد DLP:
- الوصول الآمن: معرفات البيانات المضمنة
- Umbrella: معرفات البيانات المضمنة
محفوظات المراجعة
| المراجعة | تاريخ النشر | التعليقات |
|---|---|---|
2.0 |
20-Jul-2026
|
الإصدار الأولي |
1.0 |
21-Oct-2025
|
الإصدار الأولي |
 التعليقات
التعليقات