تكوين التعبيرات العادية والتحقق منها في Cisco ESA و CES
خيارات التنزيل
-
ePub (408.2 KB)
العرض في تطبيقات مختلفة على iPhone أو iPad أو نظام تشغيل Android أو قارئ Sony أو نظام التشغيل Windows Phone
لغة خالية من التحيز
تسعى مجموعة الوثائق لهذا المنتج جاهدة لاستخدام لغة خالية من التحيز. لأغراض مجموعة الوثائق هذه، يتم تعريف "خالية من التحيز" على أنها لغة لا تعني التمييز على أساس العمر، والإعاقة، والجنس، والهوية العرقية، والهوية الإثنية، والتوجه الجنسي، والحالة الاجتماعية والاقتصادية، والتمييز متعدد الجوانب. قد تكون الاستثناءات موجودة في الوثائق بسبب اللغة التي يتم تشفيرها بشكل ثابت في واجهات المستخدم الخاصة ببرنامج المنتج، أو اللغة المستخدمة بناءً على وثائق RFP، أو اللغة التي يستخدمها منتج الجهة الخارجية المُشار إليه. تعرّف على المزيد حول كيفية استخدام Cisco للغة الشاملة.
حول هذه الترجمة
ترجمت Cisco هذا المستند باستخدام مجموعة من التقنيات الآلية والبشرية لتقديم محتوى دعم للمستخدمين في جميع أنحاء العالم بلغتهم الخاصة. يُرجى ملاحظة أن أفضل ترجمة آلية لن تكون دقيقة كما هو الحال مع الترجمة الاحترافية التي يقدمها مترجم محترف. تخلي Cisco Systems مسئوليتها عن دقة هذه الترجمات وتُوصي بالرجوع دائمًا إلى المستند الإنجليزي الأصلي (الرابط متوفر).
المحتويات
المقدمة
يوضح هذا المستند الكيفية التي تستخدم بها ESA و CES التعبيرات المنتظمة في عوامل التصفية واختلافات السلوك الأساسية والحاجة إلى الاختبار قبل الإنفاذ.
معلومات أساسية
يصف هذا المستند كيفية معالجة جهاز أمان البريد الإلكتروني من Cisco (ESA) وأمان البريد الإلكتروني للسحابة (CES) من Cisco للتعبيرات العادية عند إستخدامه ضمن عوامل تصفية الرسائل وعوامل تصفية المحتوى. وهو يركز بشكل خاص على فهم كيفية سلوك التعبيرات العادية في هذه المكونات وكيفية تفاعلها مع رؤوس البريد الإلكتروني ومحتوى المتن والمرفقات.
من المهم التوضيح من البداية أن محرك التعبير العادي المستخدم في وحدة DLP يتصرف بشكل مختلف. لذلك، فإن كل شيء موصوف في هذا المستند يطبق بشكل حصري على عوامل تصفية الرسائل وعوامل تصفية المحتوى ولا يطبق على سياسات DLP.
عند العمل باستخدام التعبيرات العادية في ESA، يجب على المسؤولين فهم عدم تقييم محتوى البريد الإلكتروني بنفس الطريقة التي يتم بها عرضه بشكل مرئي في عميل البريد. تحتوي رسائل البريد الإلكتروني على معلومات حول المظروف، رؤوس مهيكلة، أجزاء MIME، ومحتوى محتمل مرمز. ونتيجة لذلك، يمكن أن تؤدي المقارنات التي أجرتها عوامل التصفية إلى نتائج غير متوقعة إذا لم يتم فهم بنية الرسالة وسلوكيات regex بشكل كامل.
ولهذا السبب، يمكن دائما تمكين أي عامل تصفية جديد يستخدم تعبيرات عادية في "وضع المراقبة" قبل الإنفاذ. وهذا يسمح بالتحقق ضد حركة المرور الحقيقية ويمنع منع منع الحجب غير المقصود أو تأثير الأداء.
القواميس ومصطلحات البحث
عند إنشاء عامل تصفية رسائل أو عامل تصفية محتوى، يتم تفسير المصطلح الذي تم إدخاله في العديد من الشروط على أنه تعبير عادي. وهذا مفهوم بالغ الأهمية: وحتى عندما يعتزم المسؤول مطابقة النص الحرفي، يمكن ل ESA معالجة الإدخال باستخدام منطق regex.
لا ينطبق هذا بشكل موحد على جميع أنواع الشروط. على سبيل المثال، عند البحث عن عنوان IP محدد في ظروف مهيكلة معينة، لا يتم تفسير القيمة على أنها تعبير عادي. على أي حال، عند البحث ضمن رأس الموضوع، متن الرسالة، حقل رأس معين، أو اسم ملف مرفق، يتم التعامل مع القيمة عادة كنموذج regex.
والمثال الشائع يوضح ذلك بوضوح. افترض أن الهدف هو حجب رسائل البريد الإلكتروني المتعلقة بالموضوع:
Receipt number (123456)بما أن الأقواس هي حروف خاصة في التعبيرات العادية (تستخدم للتجميع)، يجب الهروب منها.
التعبير الصحيح سيكون:
Receipt number \(123456\)إذا لم يتم تخطي الأقواس، يقوم مشغل regex بتفسيرهم كمعاملات تجميع بدلا من الحروف الحرفية. حسب النمط، قد يؤدي ذلك إلى تطابقات غير مقصودة أو سلوك مختلف عن المتوقع.
لهذا السبب، من الضروري أن نفهم أي الحروف لها معنى خاص في regex ونضمن أنها هربت بشكل صحيح عندما يكون التطابق الحرفي مطلوبا.
أمثلة على الأحرف الخاصة وصياغتها التي تم تجاوزها
يظهر العمود الأول نموذجا لنص يحتوي على أحرف خاصة، ويظهر العمود الثاني كيفية كتابة صياغة التعبير العادي الصحيح لمطابقة النص الحرفي في Cisco ESA (regex نمط Python).
|
النص الحرفي المطلوب مطابقته |
تصحيح صياغة التعبير النمطي |
|---|---|
| رقم الاستلام (123456) | رقم الإيصال \(123456\) |
| user@example.com | user@example\.com |
| www.test.abc | www\.test\.abc |
| file_name.txt | file_name\.txt |
| السعر هو 10.50 | السعر هو 10\.50 |
| C:\Users\Admin | C:\\Users\\Admin |
| [سري] | \[سري\] |
| {الفاتورة} | \{الفاتورة\} |
| +34 600 123 456 | \+34 600 123 456 |
| السؤال? | سؤال\؟ |
| ضمان بنسبة 100٪ | مضمون بنسبة 100٪ (٪ لا يتطلب الهروب) |
| نجمة * رمز | علامة نجمية \* |
| أ|ب | أ\|ب |
| علامة الإقحام ^البدء | علامة الإقحام \^start |
| 100 دولار | دولار \$100 |
الحد من إستخدام التعبيرات المنتظمة
يجب إستعمال التعابير القانونية باعتناء وفقط عند الضرورة. وعلى الرغم من أنها توفر إمكانات تطابق قوية، إلا أن التعبيرات المفرطة أو غير المصممة بشكل جيد يمكن أن تزيد من وقت معالجة الرسائل وتنتج تطابقات غير مقصودة.
إحدى التركيبات المعينة التي تتطلب الحذر هي .* ، والتي تمثل "أي حرف، صفر أو أكثر من الوقت." عند وضعها في بداية أو نهاية تعبير، فإنها يمكن أن تسبب تراجعات زائدة ومعالجة غير ضرورية.
تشير وثائق Cisco إلى أن الإدخالات التي تستخدم .* في البداية أو النهاية قد تتسبب في قفل النظام تحت شروط معينة عند مطابقة أجزاء MIME معينة. ولهذا السبب، توصي Cisco بتجنب إستخدام المسافة بين السطور أو المسافة بين الحروف .* كلما أمكن.
في العديد من السيناريوهات، يستخدم المسؤولون أنماطا مثل .*الفاتورة.* عندما يمكنهم تبسيط عملية كتابة الفاتورة وإنتاج نفس النتيجة العملية في ESA. نظرا لأن محرك المسح الضوئي يقوم بالفعل بالبحث في مناطق المحتوى ذات الصلة، فإن إحاطة كلمة ب .* غالبا ما تكون مكررة وغير فعالة من الناحية الحسابية.

تحذير: والتوصية العامة هي إبقاء التعابير المنتظمة بسيطة ودقيقة قدر الإمكان.
عوامل تصفية الرسائل وعوامل تصفية المحتوى والقواميس
توفر Cisco ESA آليات متعددة لتقييم الرسائل وتطبيق الإجراءات. تعمل عوامل تصفية الرسائل في بداية مسار العمل وتستخدم بناء جملة نمط البرمجة النصية. فهي مرنة للغاية وتسمح بالمنطق المتقدم الذي يتضمن بيانات المغلفات والرؤوس وخصائص المرفقات. ومع ذلك، فنظرا لأنها تنفذ في وقت مبكر من سلسلة المعالجة، فإن عوامل تصفية الرسائل غير الفعالة يمكن أن تؤثر سلبا على الأداء.
يتم تكوين عوامل تصفية المحتوى من خلال الواجهة الرسومية ويتم تشغيلها بعد قبول الرسالة. بالنسبة لمعظم حالات إستخدام فحص المحتوى، تكون عوامل تصفية المحتوى أكثر سهولة في الإدارة وأكثر أمانا من وجهة نظر الأداء.
ضمن كل من عوامل تصفية الرسائل وعوامل تصفية المحتوى، يمكن تقديم التعبيرات العادية إما بشكل مباشر في حالة ما أو بشكل غير مباشر من خلال إستخدام القواميس.
تسمح القواميس للمسؤولين بتركيز مصطلحات البحث القابلة لإعادة الاستخدام. كل مدخل يكتب على سطر مستقل ويمكن أن يكون نص عادي أو تعبير عادي. تدعم القواميس أيضا الحروف غير ASCII، مما يجعلها مناسبة للبيئات متعددة اللغات.
في بعض الحالات، بعض تراكيب التعبيرات العادية المعقدة لا يمكن أن تتصرف بشكل متماثل داخل القواميس. عندما يقع هذا، التعبير العادي ينبغي أن يكون وضعت مباشرة في المرشح شرط بدلا من داخل القاموس.
يسمح Cisco ESA بإنشاء ما يصل إلى 150 قواميس محتوى. بشكل افتراضي، يمكن تكوين 100 قواميس ما لم يتم تعديل الحد عبر CLI باستخدام الأمر dictionaryconfig.
يمكن للقواميس أيضا تنفيذ ترجيح المصطلح. ويمكن تعيين وزن رقمي لكل مصطلح، وعندما تقوم الإيسا بمسح رسالة ما، فإنها تضاعف عدد مرات ظهور ذلك المصطلح بوزن ذلك المصطلح. تتم مقارنة النتيجة الناتجة مقابل الحد المحدد في عامل التصفية. يتيح نموذج تسجيل النقاط هذا إمكانية تنفيذ السياسات بشكل أكثر مرونة وتدرجا.
بالإضافة إلى ذلك، يمكن أن تتضمن القواميس معرفات ذكية، والتي هي كاشفات خوارزمية للأنماط الرقمية المنظمة مثل أرقام الضمان الاجتماعي أو معرفات البنوك.
محرك التعبير العادي
تستخدم Cisco ESA تعبيرات منتظمة استنادا إلى نمط وحدة Python re. وعلى الرغم من أن هذا يوفر التوافق مع صياغة إعادة توجيه Python الشائعة، إلا أنه لا يتم بالضرورة دعم كل الميزات المتقدمة المدعومة في بيئات Python الكاملة في ESA.
لمطابقة السلسلة بدقة، يجب أن تكون التعبيرات مرتبطة باستخدام ^ في البداية و $ في النهاية. بدون هذه الارتباطات، يمكن لمحرك regex مطابقة السلاسل الفرعية بدلا من القيم الكاملة.
على سبيل المثال، التعبير:
sun.comمطابقة السلاسل مثل:
thegodsunocommandoومع ذلك، فإن التعبير:
^sun\.com$مطابقة السلسلة نفسها فقط sun.com.
عند مطابقة سلسلة فارغة، من المهم عدم إستخدام ""، نظرا لأن هذا يطابق جميع السلاسل بشكل فعال. بدلا من ذلك، التعبير الصحيح هو:
^$ونظرا لأن Cisco ESA تستخدم تعبيرات منتظمة على غرار Python، فهناك طريقتان لإجراء مقارنة لا حساسة لحالة الأحرف.
وبشكل افتراضي، كما ذكر، تكون التعابير المنتظمة حساسة لحالة الأحرف. وهذا يعني البحث عن:
fooماتش بس فووو لا فووو فووو اووو.
إن يريد أنت أن ينجز حالة غير متطابق، أنت يستطيع استعملت ال inline علم (؟i) في بداية التعبير عادي. هذا يقول محرك Regex لتجاهل حالة بقية النمط.
على سبيل المثال:
(?i)fooتطابق هذا التعبير:
- تبا
- فوو
- فو
- fO
إذا كنت تريد مطابقة السلسلة بأكملها تماما، مع تجاهل الحالة، يمكنك دمج العلامة التي لا تتأثر بالحالة مع الارتباطات:
(?i)^foo$وهذا يضمن أن القيمة الكاملة هي تماما "Foo"، بغض النظر عن الرسملة.
هناك بديل آخر (أقل عملية) يتمثل في تعريف كل التركيبات الممكنة بشكل صريح باستخدام فئات الأحرف، على سبيل المثال:
[Ff][Oo][Oo]ومع ذلك، يصبح من الصعب الحفاظ على هذا النهج ولا يوصى باستخدامه بدلا من ذلك عند إستخدام علامة (؟i).
وفي معظم سيناريوهات وكالة الفضاء الأوروبية، فإن الطريقة المفضلة والأكثر نظافة لمطابقة الحالات غير الحساسة هي إستخدام ما يلي:
(?i)في بداية التعبير العادي.
الحروف غير ASCII وحدود الكلمة
في اللغات التي تستخدم مجموعات حروف ثنائية البايت، مفاهيم حدود الكلمات أو الحالة لا يمكن أن تتصرف كما هو متوقع. قد تؤدي التعبيرات المعقدة التي تعتمد على التكوينات مثل \w إلى نتائج غير متناسقة عندما يكون الترميز أو الإعدادات المحلية غير معروفة.
في مثل هذه الحالات، من المستحسن أن تقوم بتعطيل فرض حدود الكلمة في تكوين القاموس أو تبسيط التعبير لتجنب الاعتماد على فئات الحروف الغامضة.
عند العمل باستخدام قواميس غير ASCII، فإن CLI Display لا يمكنه تجسيد الحروف بشكل صحيح طبقا للتشفير الطرفي. في تلك الحالات، تصدير القاموس إلى ملف نصي، تحريره خارجيا، وإعادة إدراجه هو المنهج الموصى به.
عوامل تصفية فعالة للكتابة
تعتبر الكفاءة أمرا حيويا عند كتابة المرشحات، خاصة في بيئات كبيرة الحجم. الخطأ الشائع هو كتابة سلاسل طويلة من أو شروط لمباريات مشابهة.
على سبيل المثال، فإن التحقق من العشرات من ملحقات المرفقات يفرض على محرك regex بشكل فردي التهيئة بشكل متكرر. وهذا يزيد من إستخدام وحدة المعالجة المركزية (CPU) ويقلل من إمكانية الصيانة.
فبدلا من كتابة العديد من المقارنات المنفصلة، فإن تجميعها باستخدام التناوب ضمن تعبير واحد عادي يقلل كثيرا من تكاليف المعالجة. يقلل ذلك عدد مرات إستدعاء محرك regex ويجعل المرشح أسهل في الصيانة.
لا يتعلق تصميم المرشح الفعال بقابلية القراءة فقط، بل يؤثر بشكل مباشر على أداء النظام.
PDFs والتعابير العادية
مطابقة المحتوى داخل ملفات PDF يمكن أن ينتج نتائج غير متوقعة طبقا على كيفية توليد PDF. لا تحتوي بعض ملفات PDF على مسافات منطقية أو فواصل أسطر في تمثيلها الداخلي. يحاول محرك المسح الضوئي إعادة بناء مسافات منطقية بناء على تحديد موضع الكلمة.
إذا تم إنشاء كلمة باستخدام خطوط متعددة أو أحجام خطوط، فإن التمثيل الداخلي يمكن أن يجزئ النص. على سبيل المثال، كلمة "وسيلة شرح" يمكن أن تفسر داخليا على أنها "إستدعاء" أو "إيقاف."
في تلك الحالات، قد تفشل محاولة مطابقة تعبير "وسيلة الشرح" لأن التمثيل الداخلي لا يحتوي على تلك السلسلة المتجاورة بدقة. يجب أن يكون المسؤولون على دراية بهذا التحديد عند تصميم السياسات المبنية على المحتوى التي تستهدف مرفقات PDF.
إختبار التعابير القانونية
إن إختبار التعابير المنتظمة قبل نشرها في عملية الإنتاج هو مطلب عملياتي حاسم. قد يتصرف التعبير العادي الذي يبدو صحيحا بشكل متزامن بشكل مختلف تماما عند تقييمه مقابل حركة مرور البريد الإلكتروني الحقيقية. من دون إجراء إختبارات مناسبة، يمكن أن يؤدي عامل التصفية إلى ظهور نتائج إيجابية خاطئة أو فشل في اكتشاف الأنماط المقصودة أو زيادة الأداء أو تعطيل تدفق البريد المشروع بشكل غير مقصود.
يجب التعامل مع الاختبار كعملية منظمة على مرحلتين من أجل تقليل المخاطر إلى الحد الأدنى قبل تمكين عامل تصفية في الإنتاج.
المرحلة 1 - تصميم التعبير العادي والتحقق منه
تركز المرحلة الأولى على تصميم التعبير العادي نفسه والتحقق من صحته قبل دمجه في Cisco ESA.
1. إستخدام regex101 أو الأدوات المماثلة
منصات الإنترنت مثل http://regex101.com (أو أدوات مكافئة) مفيدة للغاية أثناء مرحلة التصميم. عند إستخدام هذه الأدوات، يجب تحديد نكهة بايثون لتقريبية محرك البحث ل ESA.
تتيح هذه الأنظمة الأساسية للمسؤولين ما يلي:
-
التحقق من صحة بناء الجملة
-
تأكد من أن الأحرف الخاصة قد تم تجاوزها بشكل صحيح
-
قم باختبار كل من الحالات المطابقة وغير المطابقة
-
عرض سلوك التجميع والقياس
-
تعرف على التركيبات الجشعة المحتملة مثل .*
ومع ذلك، تحاكي هذه الأدوات السلوك النمطي القياسي للبيثون ويمكن أن تدعم الميزات التي لم يتم تنفيذها بالكامل في Cisco ESA. ولذلك يجب اعتبارها أدوات تحقق أولية بدلا من إختبارات التوافق النهائية.
2. إستخدام نماذج AI (ChatGPT، Copilot، ...)
ويستطيع المساعدون الذين يعملون في مجال الذكاء الاصطناعي أن يسرعوا من إنشاء نظام إعادة المسح، وخاصة فيما يتصل بسيناريوهات المطابقة المعقدة. ومن خلال وصف السلوك المرغوب بلغة طبيعية، يستطيع المسؤولون الحصول على مقترح تغيير مبدئي يمكن تنقيحه بعد ذلك.
أدوات الذكاء الاصطناعي مفيدة بشكل خاص من أجل:
-
توليد تعبيرات مجمعة معقدة
-
تحويل متطلبات الأعمال إلى إعادة صياغة
-
تبسيط الشروط الطويلة أو القائمة على بدائل مجمعة
ومع ذلك، يجب دائما مراجعة التعابير التي ينشئها الذكاء الاصطناعي مراجعة نقدية. فهي قادرة على تقديم أوجه القصور، أو التراكيب غير المدعومة، أو المنطق المفرط التعقيد. ويجب أن تعامل المساعدة التي تقدمها منظمة العفو الدولية على أنها مساعدة في الصياغة، لا كمصادقة نهائية. لا يزال يتعين إختبار كل تعبير صادر عن AI باستخدام أساليب التحقق المنظمة.
المرحلة 2 - التحقق من سلوك التصفية في Cisco ESA
وبمجرد التحقق من صحة التعبير نفسه، تركز المرحلة الثانية على تأكيد كيفية سلوكه داخل Cisco ESA عند تطبيقه على معالجة الرسائل الحقيقية.
1. إستخدام ميزة التتبع في وحدة تحكم CES
تتيح ميزة "التتبع" في وحدة تحكم أمان البريد الإلكتروني (CES) من Cisco للمسؤولين إمكانية محاكاة كيفية معالجة رسالة معينة وتحليلها. هذه واحدة من أكثر الطرق موثوقية للتحقق من سلوك المرشح قبل التطبيق.
يوفر التتبع إمكانية رؤية في:
-
كيفية توزيع الرسالة
-
عوامل التصفية التي يتم تقييمها
-
ما إذا تم تشغيل الشرط أم لا
-
ترتيب تنفيذ القاعده
نظرا لأن ESA تقوم بإجراء تحليل MIME وتطبيع الرأس وفك تشفير المحتوى، فإن السلوك داخل الجهاز يمكن أن يختلف عن أدوات إختبار تغيير الكائن الخارجية. للحصول على تعليمات تفصيلية، يجب على المسؤولين مراجعة وثائق Cisco الرسمية:
يضمن إستخدام التتبع أن يتصرف عامل التصفية كما هو متوقع داخل محرك المعالجة الحقيقي.
2. إنشاء عامل التصفية باستخدام إجراء تسجيل
هناك أسلوب آخر آمن وموصى به وهو نشر عامل التصفية باستخدام إجراء غير معطل، مثل التسجيل، بدلا من تطبيق إجراء عدواني مثل إسقاط الرسائل أو إرتفاعها أو فرض حجر صحي عليها.
من خلال تكوين عامل التصفية لتسجيل إدخال عند مطابقته، يمكن للمسؤولين:
-
لاحظ تواتر المطابقة
-
الكشف عن المشغلات غير المتوقعة
-
التحقق من تأثير الأداء
-
تحليل سلوك حركة المرور الحقيقي
ويضع هذا النهج التصفية بفعالية في مرحلة مراقبة خاضعة للرقابة داخل حركة مرور الإنتاج. وبمجرد اكتمال التحقق من الصحة بشكل كاف والتأكد من صحة السلوك، يمكن تغيير الإجراء بأمان إلى وضع الإنفاذ.
تقديم التعبير في مرشح المحتوى وفي القاموس
بمجرد تصميم التعبير العادي والتحقق من صحته بشكل صحيح، فإن الخطوة التالية هي فهم كيفية إدخاله داخل Cisco ESA. يمكن أن تظهر الصياغة مختلفة قليلا بناء على ما إذا كان التعبير قد تم تكوينه مباشرة في حالة "عامل تصفية المحتوى" أو داخل القاموس. وغالبا ما يسبب هذا الاختلاف الارتباك.
تقديم التعبير في عامل تصفية المحتوى
عند تكوين حالة عامل تصفية محتوى (على سبيل المثال، مطابقة رأس الموضوع)، يجب إدخال التعبير العادي في حقل الشرط. إذا كنا نريد مطابقة النص الحرفي:
Receipt number (123456)يجب أن نتهرب من الأقواس لأنها حروف خاصة في التعبيرات العادية.
ولذلك يجب كتابة الريجة نفسها كما يلي:
Receipt number \(123456\)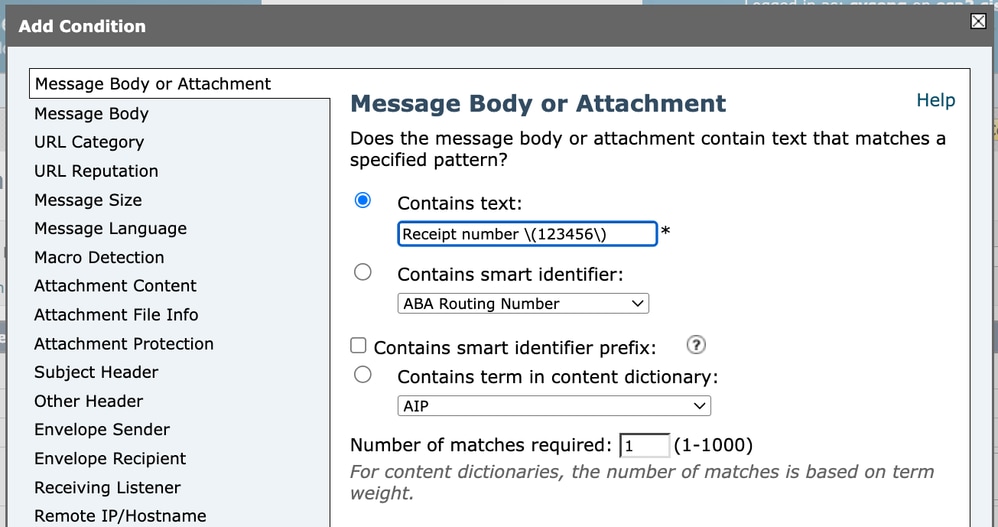 مرشح المحتوى 1
مرشح المحتوى 1
ومع ذلك، عند عرض حالة التصفية الكاملة في واجهة المستخدم الرسومية (GUI) أو خرج التكوين المتقدم، يمكن أن تظهر على النحو التالي:
subject == "Receipt number \\(123456\\)" عامل تصفية المحتوى 2
عامل تصفية المحتوى 2
قد يكون هذا مربكا للوهلة الأولى. السبب وراء شرطة مائلة عكسية مزدوجة (\) هو أن شرطة مائلة للخلف نفسها هي أيضا حرف خاص داخل سلاسل مقتبسة. في هذا السياق، يتم إستخدام شرطة مائلة عكسية واحدة للهروب من الأقواس الخاصة بمحرك regex، ويتم إستخدام شرطة مائلة عكسية ثانية للهروب من شرطة مائلة خلفية داخل السلسلة المقتبسة.
من الناحية العملية:
\(123456\) هو التعبير النمطي الحقيقي.
\\( هي الطريقة التي يمثل بها النظام \( داخل سلسلة تكوين مقتبسة.
على الرغم من أنه يظهر مختلفا عند عرضه، فإن التعبير العادي المنطقي الذي يتم تقييمه يبقى:
رقم الإيصال \(123456\)
هذه ببساطة مسألة هروب سلسلة في إخراج التكوين.
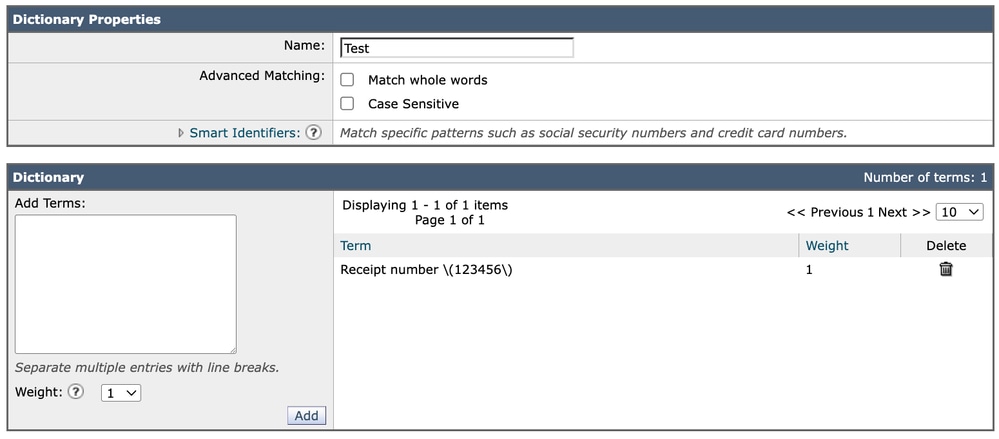
تقديم التعبير في قاموس
عند إضافة نفس التعبير إلى القاموس، يتم تقديم المدخل مباشرة على هيئة:
Receipt number \(123456\)وفي هذه الحالة، يستمر عرضها كما هي مكتوبة تماما. ليس مثل تمثيل واجهة المستخدم الرسومية لمرشح المحتوى، فإن القواميس لا تتطلب طبقات هروب إضافية في تنسيق التكوين المرئي الخاص بها.
 قاموس
قاموس
يتم تقييم كل مدخل قاموس على هيئة نص عادي أو تعبير نمطي بناء على بنيته. إذا تم تضمين حروف خاصة (مثل الأقواس في هذه الحالة)، فيجب أن يكون التعبير قد هرب بالفعل بشكل صحيح عند إدخاله.
عن "مطابقة كل الكلمات"
عند تهيئة قاموس، هناك خيار يسمى "مطابقة كل الكلمات." وفي حالات كثيرة، يوصى بعدم الاعتماد على هذا الإعداد عند العمل بالتعبيرات المنتظمة.
والسبب هو أن السلوك اللغوي يمكن التحكم به بدقة أكثر باستخدام نقاط ربط regex.
على سبيل المثال:
^ يضمن أن المطابقة تبدأ من البداية.
يضمن $ انتهاء المطابقة في النهاية.
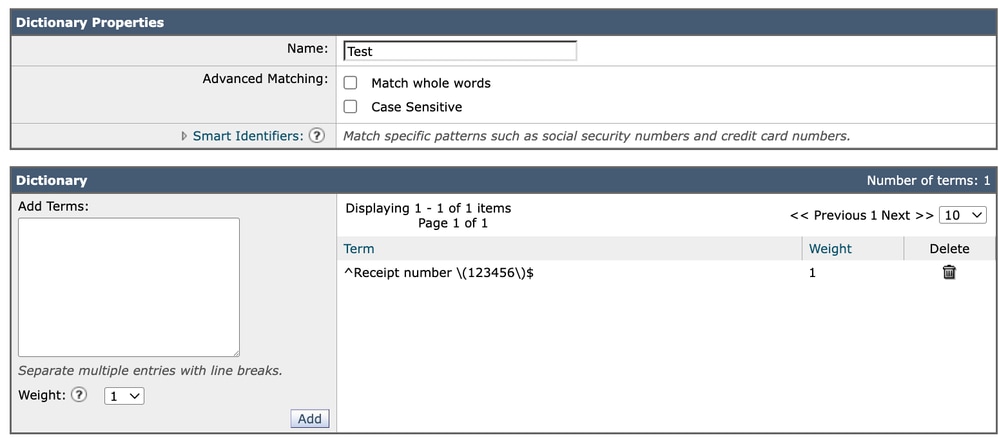
إستخدام الارتباطات مثل:
^Receipt number \(123456\)$توفير تحكم واضح ويمكن التنبؤ به في السلوك المتطابق الدقيق. ويتجنب هذا النهج أي غموض محتمل يتعلق بكيفية تفسير حدود الكلمات، ولا سيما في البيئات المتعددة اللغات أو غير المترابطة.
 قاموس 2
قاموس 2
ولهذا السبب، من المفضل عموما إدارة مطابقة الدقة مباشرة ضمن التعبير العادي بدلا من الاعتماد على خيار "مطابقة كل الكلمات".
إن فهم هذه الفروق الدقيقة بين مرشحات المحتوى والقواميس يضمن أن تتصرف التعبيرات بشكل متناسق ويقلل من مخاطر أخطاء التكوين أثناء التطبيق.
إعادة ترتيب التكلفة في Cisco ESA
عند العمل باستخدام تعبيرات منتظمة في Cisco ESA، يعتمد تأثير الأداء بشكل كبير على كم النص الذي يجب أن يقوم المحرك بمسحه ومدى التراجع الذي يجب أن يقوم به. ونظرا لأنه يجب على ESA تقييم هياكل الرسائل بالكامل وأجزاء MIME وحتى المرفقات التي تم فك ترميزها، يمكن للأنماط غير الفعالة زيادة إستخدام وحدة المعالجة المركزية (CPU) بشكل كبير.
وهو ترتيب عملي من أعلى تكلفة حوسبة إلى الأدنى.
الأكثر تكلفة — أنماط عالية الخطورة
يمكن أن تؤثر هذه التعابير بشكل كبير على الأداء، لا سيما على الرسائل الكبيرة.
وحدات كمية متداخلة (في أسوأ الحالات)
الأمثلة:
(.*)+
(.+)+
(\S+)+هذه خطيرة للغاية لأنها تخلق سيناريوهات تراجعية أسية.
ويفرض القياس الكمي داخل مقياس كمي آخر على محرك regex تجربة العديد من التركيبات قبل الفشل.
وفي حالة الحركة المرورية الحقيقية، قد يؤدي ذلك إلى إرتفاعات كبيرة في وحدة المعالجة المركزية.
التوصية: تجنب إستخدام كميات مضمنة غير محدودة وغير محددة.
طماع .* يتبع نمط مطلوب
مثال:
.*text
.*\/\?textيستهلك هذا النقش الرسالة بأكملها أولا، ثم يتخلف عن كل حرف حتى يعثر على السلسلة الفرعية المطلوبة.
إذا لم يكن النموذج موجودا - أو ظهر بالقرب من النهاية - فإن المحرك يعمل على عكس الإتجاه ويختبر الرمز المميز المطلوب في العديد من المواقع، مما يزيد من تكلفة وحدة المعالجة المركزية (CPU).
وفي وكالة الفضاء الأوروبية، حيث يمكن للأجسام أن تكون كبيرة وأن تتضمن محتوى MIME، يصبح ذلك باهظ التكلفة بسرعة كبيرة.
التوصية: عدم الاستعداد .* لاكتشاف السلاسل الفرعية. يقوم ESA بالفعل بالبحث عن المحتوى الذي تم تقييمه، بينما تعمل أحرف البدل البادئة فقط على زيادة تتبع الارتباطات واستخدام وحدة المعالجة المركزية.
text$
\/\?text$بدائل كبيرة ذات بادئات مشتركة
مثال:
(a.*b|a.*c|a.*d)عندما تتشارك عدة بدائل البنية، يقيم المحرك كل فرع بشكل تسلسلي.
إذا كانت الفروع الباكرة متطابقة تقريبا ولكن تفشل في وقت متأخر، يعيد المحرك على نطاق واسع.
وهذا يزيد من وقت التقييم بشكل كبير.
تكلفة متوسطة - الاستخدام بحذر
هذه الأنماط ليست كارثية، لكنها لا تزال غير فعالة.
واسع .* الاستخدام
مثال:
https://.*\?textعلى الرغم من أنها ليست أسية، .* ما زالت تسمح بمطابقة غير محدودة. إذا لم تظهر السلسلة الفرعية المتوقعة بسرعة، يقوم المحرك بفحص أجزاء كبيرة من الرسالة.
في ESA، يكون هذا شائعا عند مسح كائنات البريد الإلكتروني بحثا عن عناوين URL للتصيد الاحتيالي.
كميه كسولة (+؟، *؟)
مثال:
\S+?
.*?إن المقاييس الكمية الكسولة تغير إستراتيجية المطابقة (الأقصر أولا). يمكنها تقليل التطابق الزائد في بعض الأنماط، لكن في أحمال عمل "البحث" الكبيرة يمكنها زيادة المحاولات عندما يكون الرمز المميز الإنهاء متأخرا أو مفقودا.
وفي كثير من الحالات التي تستخدم فيها الإيسا، فإنها لا توفر فائدة حقيقية ويمكن أن تدخل عمليات إعادة محاولة داخلية غير ضرورية.
فئات أحرف عامة جدا
الأمثلة:
\S+
.+هذه تسمح بنطاق متطابق واسع، بزيادة عدد المسارات المحتملة للتتبع العكسي.
يفضل دائما المزيد من فئات الحروف المحددة.
منخفضة التكلفة - أنماط آمنة وفعالة
يوصى باستخدام هذه العناصر لبيئات ESA للإنتاج.
حرفية ثابتة
الأمثلة:
text
iw\.adcالسلاسل الحرفية هي أكثر التطابقات الممكنة فعالية. يجري المحرك مقارنات مباشرة مع أدنى كلفة.
إستخدام الارتباطات للحد من نطاق البحث
عندما يتوقع التطابق في مكان معين، تذكر تثبيت النمط باستخدام ^ أو $. تقوم الارتباطات بتقييد التقييم على مواضع ثابتة وتمنع المحرك من مسح المحتوى بالكامل بشكل غير ضروري. يمكن أن يقلل ذلك من التتبع وتحسين الأداء، خاصة في أجسام الرسائل الكبيرة أو الرؤوس المنظمة.
^Invoice$فئات حروف معينة
[A-Za-z0-9.-]+
[^/\s]+يؤدي هذا إلى تقييد ما يمكن مطابقته، مما يقلل بشكل كبير من مساحة البحث ويحد من عدم تتبع الارتباطات.
الأنماط المهيكلة والمقيدة
مثال:
https?:\/\/[A-Za-z0-9.-]+(?:\/[^?\s]*)*\/\?text- المجال ثابت.
- لا تستخدم .*.
- لا يحتوي على أنماط متداخلة كارثية (مثال، (.*)+)
- لا يوجد مشغلات كسولة غير ضرورية.
- كل قسم مقيد.
ويعمل هذا على تقليل تأثير وحدة المعالجة المركزية (CPU) بشكل كبير مقارنة بمطابقة أحرف البدل الواسعة.
إرشادات عملية ل Cisco ESA
عند تصميم regex لمرشحات الرسالة أو المحتوى:
- كلما كان النمط أكثر تحديدا، كلما كان الأداء أفضل.
- تجنب .* ما لم يكن ذلك ضروريا حقا — ولا سيما تجنب وضع العلامات المميزة المطلوبة بعده.
- لا تستخدم مطلقا كميات متداخلة.
- يفضل فئات الحروف الصريحة على أحرف البدل.
- قم دائما باختبار التعبيرات الجديدة في "وضع الشاشة" قبل التطبيق.
مقارنة أداء Regex (سياق Cisco ESA)
|
نمط |
مستحسن |
مخاطر تراجعية |
تأثير ESA |
بديل موصى به |
|
https؟:\/\/.*/\؟text.* |
لا |
عالي |
أعلى |
^https؟:\/\/[A-ZA-z0-9.-]+(؟:\/[^؟\s]*)*\/؟نص |
|
https؟:\/\/.*\؟نص |
⚠ بحذر |
متوسط-مرتفع |
متوسط-مرتفع |
^https؟:\/\/[^؟\s]+\؟text$ |
|
https؟:\/\/.* |
لا |
متوسط-مرتفع |
الوسيطة |
^https؟:\//[A-ZA-z0-9.-]+(؟:\/[^\s]*)* |
|
.*كلمة المرور |
لا |
عالي |
أعلى |
كلمة المرور$ |
|
.*نص.* |
لا |
عالي |
أعلى |
نص |
|
.*(فاتورة|دفع|تحويل) |
لا |
عالي |
أعلى |
(الفاتورة|الدفع|التحويل)$ |
|
(.+)+ |
أبدا |
عالي جدا (أسي) |
شديد |
إعادة الهيكلة بدون كميات متداخلة (مثال .+) |
|
.*@.* |
لا |
عالي |
أعلى |
[A-Za-z0-9._٪+-]+@[A-Za-Z0-9.-]+\.[A-Za-Z]{2،} |
|
\s+؟ |
غير مثالي |
الوسيطة |
الوسيطة |
\S+ أو فئة أكثر تحديدا مثل [A-Za-z0-9.-]+ |
|
.*\/admin |
لا |
عالي |
أعلى |
\/admin$ |
|
.*(تسجيل الدخول|التحقق).* |
لا |
عالي |
أعلى |
(تسجيل الدخول|التحقق) |
|
^*نص |
لا |
عالي |
أعلى |
text$ (أو ^text إذا كان الموضع مهما) |
القرار
تعد التعبيرات المنتظمة أداة قوية ومرنة داخل Cisco ESA، مما يتيح الفحص الدقيق للمحتوى وتنفيذ السياسات المتقدم في كل من عوامل تصفية الرسائل وعوامل تصفية المحتوى. ولكن مع هذه المرونة تأتي المسؤولية. قد تؤدي التعبيرات غير المصممة أو التي لم يتم إختبارها بشكل كاف إلى نتائج إيجابية خاطئة أو عمليات اكتشاف فائتة أو انخفاض الأداء أو العرقلة غير المقصودة لحركة البريد الإلكتروني الشرعية.
ولهذا السبب، يجب دائما أن يكون إستخدام التعبيرات المنتظمة في الإيسا نهجا منظما ومنضبطا. يجب أن تضمن مرحلة الإنشاء أن التعبير صحيح تركيبيا، تم فلاته بشكل صحيح، فعال، ومتوافق منطقيا مع الهدف المقصود. ومن الممكن أن تعمل الأدوات الخارجية وعمليات التوليد بمساعدة الذكاء الاصطناعي على التعجيل بهذه العملية إلى حد كبير، ولكن لا ينبغي لها أبدا أن تحل محل التحقق الدقيق من الصحة.
ولا يقل عن ذلك أهمية مرحلة التصديق داخل بيئة الإيسا ذاتها. ولأن وكالة الفضاء الأوروبية تتعامل مع الرسائل من خلال تحليل MIME، وتطبيع الرأس، وفك شفرة المحتوى، فإن سلوك العالم الحقيقي من الممكن أن يختلف عن التوقعات النظرية. يسمح إستخدام أدوات مثل تتبع عوامل التصفية ونشرها في البداية في وضع التسجيل أو المراقبة للمسؤولين بتأكيد السلوك الصحيح دون مخاطر تشغيلية.
وبإيجاز، يجب ابقاء التعابير القانونية بسيطة قدر الامكان، فحصها بدقة، ونشرها بحذر. ولا يقتصر عامل التصفية الذي تم تصميمه بشكل جيد والتحقق من صحته على فرض السياسة بشكل فعال، بل يعمل أيضا على حماية إستقرار النظام وضمان السلوك المتوقع في بيئات الإنتاج.
توثيق
للحصول على تفاصيل تقنية إضافية وإرشادات رسمية حول كيفية تنفيذ التعبيرات المنتظمة واستخدامها داخل Cisco ESA، يجب على المسؤولين الرجوع إلى وثائق منتجات Cisco
يوفر القسم "التعبيرات العادية في القواعد" نظرة عامة حول كيفية تقييم التعبيرات العادية داخل عوامل تصفية الرسائل وعوامل تصفية المحتوى، بما في ذلك اعتبارات الصياغة والاستخدام ضمن شروط القاعدة.
يقدم الجزء "إرشادات لاستعمال التعابير القانونية" توصيات عملية حول الصياغة الصحيحة، تثبيت التعابير، معالجة الحروف الخاصة، وتجنب الاخطاء الشائعة التي يمكن ان تؤثر في الاداء أو تطابق الدقة.
يوصى بشدة بمراجعة هذه الموارد الرسمية عند تصميم عوامل التصفية التي تعتمد على التعبيرات العادية أو أستكشاف أخطائها وإصلاحها، لأنها توفر إرشادات موثوق بها تتوافق مع إصدار AsyncOS المحدد المستخدم.
محفوظات المراجعة
| المراجعة | تاريخ النشر | التعليقات |
|---|---|---|
1.0 |
26-Feb-2026
|
الإصدار الأولي |
تمت المساهمة من قبل
- ألبرتو تورالبامهندس تسويق فني
 التعليقات
التعليقاتاتصل بنا
- فتح حالة دعم

- (تتطلب عقد خدمة Cisco)