|
Cisco Nonstop Forwarding(NSF;ノンストップ フォワーディング)/Stateful Switchover(SSO;ステートフル スイッチオーバー)は、ハードウェアまたはソフトウェア障害による意図しないダウンタイムからシステムを保護し、ネットワーク サービスの継続的な提供を可能にします。NSF/SSOをネットワークの重要な部分に展開すれば、システムとサービスの可用性が向上するとともに、将来、In Service Software Upgrade(ISSU)で提供されるダウンタイムの計画化を目的とした機能を活用できるようになります。
重要なビジネス システムへのネットワーク アクセスを実現しようとしている企業においても、卓越したネットワーク サービスと接続性を顧客に提供することを追求しているネットワーク プロバイダーにおいても、コンポーネントの障害によって発生するダウンタイムを短縮することが業務には必須であると認識しています。シスコのお客様は、ビジネス要件と予算を考慮しながら、サービスが停止することのない冗長ネットワークの設計と運用の実現に向けて努力しています。
Cisco NSF/SSOは、ある種のネットワーク機能停止による影響を抑制するために開発された拡張機能から発展しました。Cisco NSF/SSOは、Route Processor Redundancy(RPR)およびRPR Plus(RPR+)として知られる初期のテクノロジーを基盤としています。シャーシ内でハードウェアを冗長化(冗長Route Processor [RP;ルート プロセッサ])し、コントロール プレーンをデータ プレーンから分離することによって、たとえハードウェアまたはソフトウェアに障害が発生してそれがRPに支障を与えたとしても、パケット損失することなく継続的にパケットを転送できるようにします(独自のテスト結果[英語]はhttp://www.cisco.com/warp/public/732/Tech/grip/tech.shtmlを参照してください)。
この文書は、Cisco NSF/SSOを展開することでネットワークサービスの可用性を高めようとしている設計スタッフと運用スタッフのための手引き書です。最初の項では、ネットワーク内でNSF/SSOを展開すべきポイントについて説明します。2項と3項では、SSOとNSFの運用について検討します。4項では、確実に展開を成功させるための実装手順について説明します。
注: この文書では、特に断りのないかぎり、「RP(ルート プロセッサ)」という用語は、ハードウェアの名称に関係なく、すべてのネットワーキング デバイス上のルート プロセッサ エンジンを指します。たとえば、Cisco 10000シリーズ インターネット ルータでは、RPはPerformance Routing Engine(PRE;パフォーマンス ルーティング エンジン)を指し、Cisco 12000シリーズ ルータでは、RPはGigabit Route Processor(GRP;ギガビット ルート プロセッサ)またはPerformance Route Processor(PRP;パフォーマンス ルート プロセッサ)を指します。また、Cisco Catalyst® 6500シリーズ スイッチとCisco 7600シリーズ ルータではスーパーバイザという用語が使用され、Cisco 7500シリーズ ルータのRPはRoute Switch Processor(RSP;ルート スイッチ プロセッサ)を指します。
Cisco NSF/SSOという言葉からは、すべてのネットワーク ノードに復元力の向上というメリットを提供するように思えます。しかし、実際には、この機能から最大の効果を得られるのはエッジ デバイスです。シングルポイント オブ フェイラーは、ネットワーク エッジの境界に存在する傾向があります。さらにサービス プロバイダーのような通信事業の場合、スケールメリットを基盤にしているので、そのエッジにはシングルポイント オブ フェイラーがより多く存在します。通常は、上位層とバックボーンのノード間のパスを冗長化することにより、単一ノードでの障害がサービスに影響を与えないようにします。したがって、上位層とバックボーンのノードには、シャーシ内でRPを冗長化させたり、ネットワーク復元力を装備したりはしません。代わりにそれらのノードは、代替パスへの高速なルーティング コンバージェンスによって可用性を向上させています。つまり、リンクまたはノードの障害をただちに検出し、トラフィックをすみやかに代替パスにルーティングします。Multiprotocol Label Switching(MPLS;マルチプロトコル ラベル スイッチング)Virtual Private Network(VPN;仮想私設網)ネットワークは、トラフィック処理などの機能を組み込んでおり、コアでのリンクとノードの保護によって、迅速にルートを変更してパスの復元力を実現します。ルーティング プロトコルのコンバージェンスは、ネットワーク サービスの可用性に直接影響を与えますが、複雑な問題なので、この文書では詳しく述べません。ルーティング プロトコル タイマーの操作とNSF/SSOに関する情報については、下記のURLにある高可用性に関する文書『Cisco NSF and Timer Manipulation for Fast Convergence』(英語)を参照してください。http://www.cisco.com/en/US/tech/tk869/tk769/technologies_white_paper09186a00801dce40.shtml
図1 Cisco NSF/SSOの主な展開ポイント
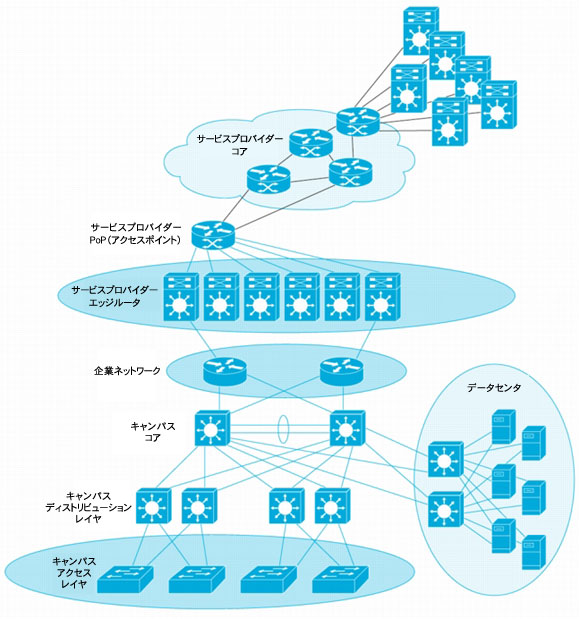
図1は、Cisco NSF/SSOを展開すべきポイントを示しています。色の付いた楕円で示しているように、NSF/SSOはサービス プロバイダー ネットワークのエッジに展開すると最も効果的です。NSFはサービス プロバイダーのエッジ ルータで、メンテナンスや何らかの障害などの理由によりRPがオフラインになっても、お客様がその影響を受けないことを保証します。特に、お客様またはネットワークが、単一のエッジ ルータのみでサービス プロバイダーと相互接続している場合に、最大の効果を発揮します。こうしたケースでは、サービス プロバイダーのエッジ ルータがシングルポイント オブ フェイラーとなるので、この機能がないと、ノードに何らかの障害が発生した場合、そのパスを使用しているすべてのトラフィック フローが停止します。NSFを設定すると、シャーシ内の冗長RPへスイッチオーバーする間もトラフィック フローは継続するため、サービスの向上と、ネットワーク寸断やルーティング プロトコル変動の抑制につながります。
多くのネットワークでは、トポロジー内の他の場所に設定しても効果が得られます。たとえば企業では、NSF/SSOをサービス プロバイダーとのエッジ境界に展開すると効果的です。これらのデバイスは、通常重要なネットワーク サービスを提供しており、再コンバージェンスによるパフォーマンス低下やパケットの損失は大きな問題となるからです。NSF/SSOはCisco Catalyst 6500シリーズ スイッチで装備できるので、シングルポイント オブ フェイラーとなる接続が存在するデータ センタの重要なディストリビューション レイヤ デバイスや、キャンパス アクセス レイヤに展開できます。詳細については、「キャンパス ネットワークのNSF/SSO」を参照してください。
Cisco NSF機能では、隣接ノードが1つの役割を果たします(図2を参照)。RPのスイッチオーバー中でもパケット転送を継続できる場合、そのノードはNSF対応ノードです。NSF/SSOの展開から最大の効果を得るには、隣接またはルーティング プロトコル ピア ノードがNSFを認識できる必要があります。実装には必ず必要というわけではありませんが、再起動するノードでパケット転送を継続できることをルーティング ピアが認識し、またスイッチオーバー後にルーティング テーブルの整合性の復元と確認を支援しなければ、限られた効果しか得られません。これについては、ルーティング プロトコルごとにNSF運用の詳細を説明する際に取り上げます。
シスコのNSFとSSOは、組み合わせて展開するように設計されています。NSFはSSOに基づいて、リンクとインターフェイスがスイッチオーバー中でも動作し、また下位レイヤのプロトコルの状態が維持されるようにします。ただしNSFを別個に設定したり、またSSOをNSFなしで有効にしたりすることは可能です。
図2 NSF認識デバイスとNSF対応デバイスの連携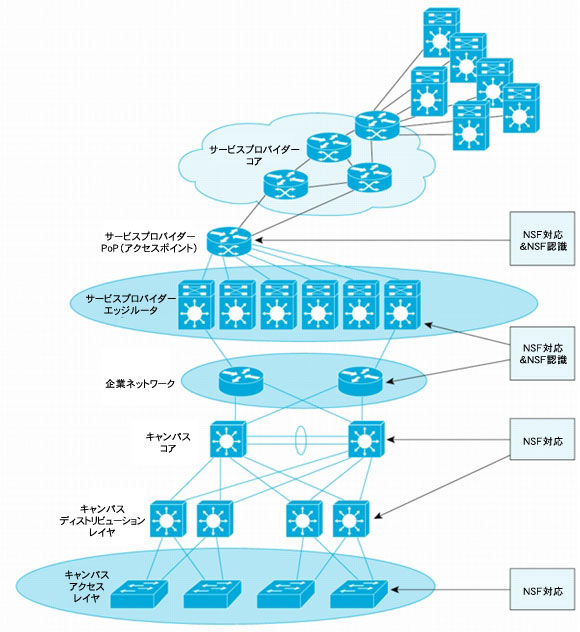
キャンパス ネットワークは通常、高度な冗長性と広域な帯域幅を備えた設計となっています。キャンパス内では、どのリンクまたはコンポーネントで障害が発生しても、二重の等コスト パスと高速コンバージェンスによってトラフィックは代替パスをとることが可能です。ただし、接続の維持、パケット損失の低減、および特定のネットワーク サービスを提供するノードを経由するパス フローの一貫性を確保するうえで、NSF/SSOが効果を発揮する場所があります。
図3 NSF認識デバイスとNSF対応デバイスの連携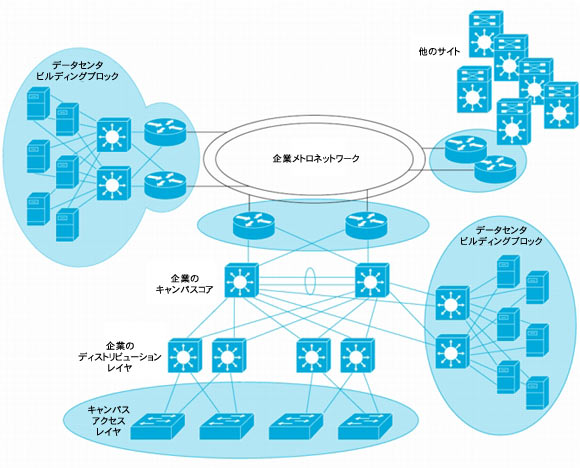
図3では、色付きの円で囲まれた部分が、NSF/SSOが最大の効果を発揮すると予想される場所です。
検討すべき最初の場所は、アクセス レイヤです。大規模企業では多くの場合、共通の機器とモジュールを使用することによって設計を簡略化し、運用の一貫性を確保することで、必要な予備品を最小限に抑えながら可用性を向上させます。Cisco Catalyst 6500シリーズまたは4500シリーズ スイッチでは、エンド ステーションとIPテレフォニーにワイヤリング クローゼット接続が提供されるので、SSOはスーパーバイザによる障害、またはソフトウェア問題によるサービスの停止からの保護を実現します。アクセス レイヤは通常、レイヤ2サービスを提供し、冗長スイッチでディストリビューション レイヤが構成されます。レイヤ2アクセス レイヤでは、NSFなしで展開したSSOで効果が得られます。一部の企業は、アクセス レイヤでレイヤ3ルーティングを展開しています。その場合は、NSF/SSOを使用できます。
検討すべきもう1つの場所は、キャンパス メトロポリタン ネットワーク エッジです。多くの企業ではキャンパスは拡張され、そこでは複数の建物が相互接続されています。Metropolitan-Area Network(MAN;メトロポリタン エリア ネットワーク)は、2台のルータまたはスイッチで各建物またはサイトを相互接続して構成される場合があります。メトロポリタン エリア サービスはサービス プロバイダーによって提供され、ダーク ファイバ経由で相互接続されるか、企業所有のファイバ パスで構成されます。いずれの場合も、各サイトがメトロポリタン ネットワークに接続するキャンパス エッジの重要性は非常に高まるので、NSF/SSOが効果的です。
最後に、フロントエンドのデータ センタ、サーバ、コンピューティング クラスタ、およびメインフレームに使用される機器についても、NSF/SSOは効果的です。ここで特に有利なことは、ハードウェアおよびソフトウェア ベースのIPサービス機器またはブレード(ファイアウォール、コンテンツ管理システム、ロードバランシング システムなど)を通過するトラフィック パスが保全されることです。
図4 データ センタのNSF/SSO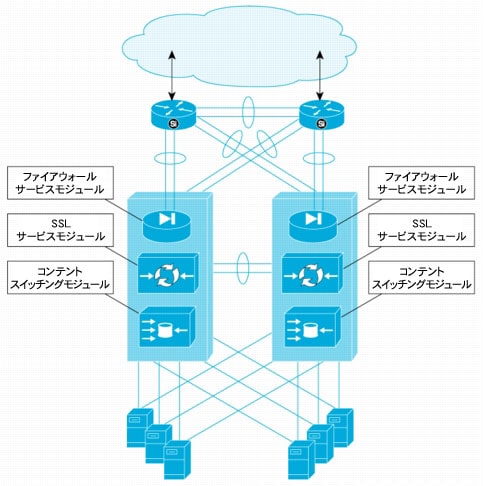
図4は、データ センタの設計を示しています。この図は、2台のCisco Catalyst 6500シリーズ スイッチに統合型サービス モジュールを展開する例になっています。具体的には、ファイアウォール サービス モジュール、SSLサービス モジュール、およびコンテント スイッチング サービス モジュールを使用して、接続先サーバのアプリケーションに向かうトラフィックに重要なサービスを提供しています。
この環境では、片方のCisco Catalyst 6500シリーズ スイッチのスーパーバイザに障害が発生しても、トラフィックが同じパスで伝送され続けます。NSF/SSOのサポートによって、障害とネットワークの再コンバージェンスの影響は最小限に抑えられ、トラフィックの損失量が抑制されるとともに、Mean Time To Repair(MTTR;平均復旧時間)も短縮します。サービス モジュール、シャーシ電源、またはシャーシ全体の障害に影響する重大な障害からの保護は、並列で動作する冗長スイッチで引き続き提供されます。
シスコのSSOは、他の2つのCisco IOS®ソフトウェア インフラストラクチャ サブシステム、Redundancy FacilityとCheckpoint Facilityに依存しています。PPP、High-Level Data Link Control(HDLC;ハイレベル データリンク制御)、フレーム リレーといった個々のプロトコルを制御するソフトウェアは、Checkpoint FacilityとRedundancy Facilityを使用して、リンクの状態とレイヤ2プロトコルの詳細がスタンバイRPに複製されるようにします。これによって、RPのスイッチオーバー中にリンクの動作が維持されます。
以前の冗長モード(RPRなど)では、こうした品質を提示できませんでした。RPRモードでは、スタンバイRPは電源投入時にCisco IOSソフトウェア イメージをロードし、スタンバイ モードで初期化されます。スタートアップ コンフィギュレーションはスタンバイRPに同期化されますが、その後の変更は同期化されません。スイッチオーバーが発生すると、スタンバイRPはアクティブRPとして再初期化され、すべてのライン カードをリロードしてシステムを再起動します。ライン カードがすべてリロードされるため、隣接ルータではほとんどのタイプのポイントツーポイント接続で物理リンクの障害が検出されます。RPR+モードでは、スタンバイRPは完全に初期化され、設定されます。これによって、RPR+ではアクティブRPに障害が発生したり、手動でスイッチオーバーを実行したりした場合のスイッチオーバー時間を大幅に短縮できます。スタートアップ コンフィギュレーションとランニング コンフィギュレーションは、つねに両方ともアクティブRPとスタンバイRPで同期され、ライン カードがスイッチオーバー中にリセットされることはありません。インターフェイスは移行中も動作しているため、近接ルータで物理リンクのフラップ(リンクの一時的なダウンとアップ)が検出されることもありません。ただし、ライン カード、プロトコル、およびアプリケーションの状態情報は同期化されないため、一部のレイヤ2プロトコルでは障害が発生します。冗長性モードをSSOに設定すると、ライン カード、プロトコル、およびアプリケーションの状態情報が同期化されて冗長RPは「ホット」スタンバイとなり、いつでもただちに移行できるようになります。
現在、SSOを使用して同期化を実行するには、両方のRPで同じレベルのソフトウェア リリースが動作している必要があります。開発中のIn Service Software Upgrade(ISSU)が利用できるようになると、この制約はなくなり、NSF/SSOを活用することによって、サービスに影響を与えずにソフトウェア アップグレードを実行できるようになります。
SSOの運用上の主な効果と利点は、RPがプライマリRPからホット スタンバイRPに切り替わるときに、隣接デバイスでリンク障害が検出されないことです。これは、RPのスイッチオーバーにのみ当てはまります。シャーシ全体が電源を失ったり障害を起こしたりした場合、またはライン カードに障害が発生した場合、リンクは障害を起こし、ピアでそのイベントが検出されます。もちろん、これはリンク障害を検出できるポイントツーポイントのギガビット イーサネット インターフェイスやPacket over SONET(POS)インターフェイスなどの場合です。NSFが有効になっていても、物理リンクの障害はピアによって検出可能で、NSF認識は無効になります。
SSOのプロトコルサポートSSOを認識できないプロトコルとアプリケーションでダイナミックに生成された状態は、スイッチオーバーが発生すると消失するので、再初期化と再起動が必要です。これらのプロトコルとアプリケーションでは、状態情報が確立または再構築されるまでにある程度のパケット損失が発生する場合があります。
2004年10月の時点で、SSOはPPP、Multilink PPP(MLPPP;マルチリンク ポイントツーポイント プロトコル)、HDLC、フレーム リレー、ATM、およびイーサネットをサポートしています。スイッチング製品には、表1に記載されている機能およびプロトコルのサポートも含まれます。
|
製品ではコンフィギュレーションと状態情報も維持され、レイヤ4でのトランスペアレントなフェールオーバーが可能です。これには、Quality of Service(QoS;サービス品質)、セキュリティ機能、およびAccess Control List(ACL;アクセス制御リスト)の維持が含まれます。
特定のプロトコルごとの状態の同期化、制限事項、およびコンフィギュレーションの詳細については、該当するシスコのマニュアルを参照してください。
Cisco NSFはレイヤ3のルーティング冗長性機能と考えることができます。NSFでは、フォワーディング プレーンからのコントロール プレーンの分離を活用します。コントロール プレーンはルーティング プロトコルのインテリジェンスであり、フォワーディング プレーンは利用可能な場合、ハードウェア アクセラレーションを使用してパケット交換を行います。NSFはCisco Express Forwarding(CEF)と緊密に連携しています。Cisco 12000およびCisco 7600シリーズ ルータやCisco Catalyst 6500シリーズ スイッチなどの分散ルーティング ハードウェアは、CEFの情報をForwarding Information Base(FIB;フォワーディング情報ベース)の形式でライン カードにダウンロードします。こうしてRPのスイッチオーバー中でも、ライン カードは保持しているルーティング情報を使用してトラフィックの転送を継続できます。
また、NSFはCheckpoint FacilityとRedundancy Facilityを使用して、CEFの状態情報をスタンバイRPに複製します。ホット スタンバイRPに切り替わって「アクティブ」になると、NSF対応およびNSF設定済みルーティング プロトコルによってネイバーとの隣接関係が再設定され、ルーティング情報が交換されます。ルーティング情報の交換後、Routing Information Base(RIB;ルーティング情報ベース)はFIBによって検証され、さらに必要に応じてアップデートされて、ルーティング情報の正確さとピアとの同期化が保証されます。
ルーティング プロトコルの隣接関係はプライマリRPがダウンすると失われ、スタンバイRPがアクティブになったあとで再確立されることに注意してください。さらにその後、ルーティング プロトコル情報はピアと交換されます。これを実行し、ピアまたは隣接ルータから、スイッチオーバー中のルータへのトラフィック転送を確実に継続させるために、ルーティング プロトコルの拡張機能が使用されます。
運用および展開の点からみると、上記の実現には隣接ルータでルーティング プロトコルの拡張機能がサポートされていることが必要です。ルーティング プロトコルの拡張機能によって、ネイバーはピアがパケット転送を継続できることをあらかじめ認識できます。一方、隣接関係が短時間途絶するために、ルーティング プロトコル情報の送信を要求する場合があることも、あらかじめ認識できます。スイッチオーバー中でも転送を継続できるルータは、NSF対応ルータです。ルーティング プロトコルの拡張機能で、再起動するルータへのトラフィック転送を継続する機能をサポートするデバイスは、NSF認識デバイスです。シスコ デバイスでNSF対応のものは、NSF認識デバイスでもあります。一部のソフトウェア バージョンとシスコ製品には、NSF認識はサポートしていてもNSF対応ではないものがあります。
NSFのプロトコル サポートCisco NSFでは、Border Gateway Protocol(BGP)、Intermediate System-to-Intermediate System(IS-IS)、Open Shortest Path First(OSPF)、およびEIGRPの各ルーティング プロトコルがサポートされています。Cisco NSFは、MPLS関連のプロトコルもサポートしています(製品とリリースの入手方法については、該当する文書を参照してください)。スイッチオーバー中、各プロトコルではCEFによってパケット転送が継続され、一方ルーティング プロトコルによってRIBが再構築されます。
Cisco NSFの現在の実装は、次の要件を想定して設計されています。シスコはネットワーク コミュニティおよびIETFと連携し、広く使用されているルーティング プロトコルに対する複数の機能拡張を推進することで、効果的なソリューションを生み出しています。プロトコルの拡張機能の基礎となる規格とドラフトについては、「関連する規格とドラフト」にまとめてあります。
次の項では、プロトコルの拡張機能と、サポートされている各ルーティング プロトコルの実装について説明します。
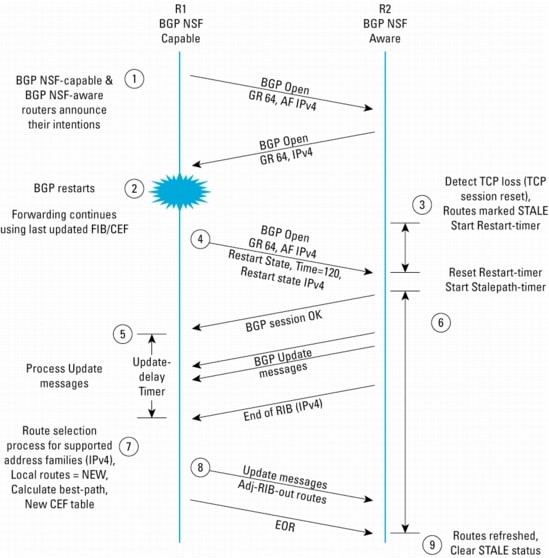
BGP NSF最初のBGP接続が確立されると、プロトコルの調整が始まります。NSF対応ルータとそのピアは、セッションを確立する最初のBGP OPEN中に、新しいBGP Capability(#64)を交換することによって、BGPグレースフル リスタート メカニズムに対応していることを示します。
ルータは、NSF対応であるかどうかに関係なく、Capability 64を送信することに注意してください。Capability 64だけでは、再起動可能かどうかはわかりません。この信号が示すのは、当該ルータがIETFのドラフトで規定されているBGPの拡張機能を実装しているということです。そのため、BGPグレースフル リスタート対応で設定されているCisco 7200シリーズ ルータは、デュアルRPをサポートしていないために、BGPを再起動できない場合でも、Capability 64をピアにアドバタイズします。
さらに、NSF対応ルータは、一連のAddress Family Identifier(AFI)とSubsequent Address Family Identifier(SAFI)を提供し、それらについてBGPリスタートの前後でフォワーディング ステートを維持する機能を備えています。AFIとSAFIは、BGPで情報を伝送できる各種のプロトコルを示します。これには、IPv4、IPv6、MPLS、およびユニキャスト/マルチキャスト ルーティングなどのプロトコル サポートが含まれます。
BGPグレースフル リスタート プロトコル拡張機能の手順AS間の例
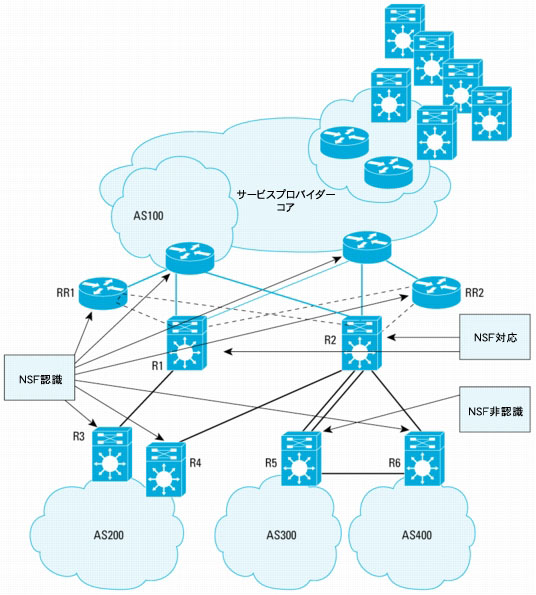
図6は、複数の異なるASにピアが配置されているeBGPの展開を示しています。この図には、可能な設計がいくつか示されています。ルータR1とルータR2はAS100に属します。ピアリング ポイントには、RR1とRR2の2台のルート リフレクタが配置されています。可能な設計の1つは、接続先のAS(AS200)にある2つの異なるルータに対して、2つのリンクと2つのeBGPセッションを使用するものです。別の設計ではeBGPマルチホップを使用して、単一のルータに対し2つのリンクを使用します(図のAS300との接続を参照)。さらにもう1つの可能性は、AS400との接続のような単一の接続です。AS400は、AS300を経由する別のパスを備えていることに注意してください。
図からは、AS100にピアリングしている一部のルータが、NSF認識ではない場合があるということもわかります。前述のように、NSF/SSOが最大の効果を発揮するのは、ピア ルータがNSF認識ルータである場合です。ただし理解を深めるために、ピアがNSFを認識しない場合のトラフィック フローの動作についても説明します。
注:NSF対応ルータはNSF認識ルータでもあります。
検討のために、R2がスイッチオーバーを実行するケースを取り上げます。
まず、AS100とAS400の間の動作を検討します。AS400はAS100と単一のルータ(R6)経由で接続されていますが、このルータはBGP NSF認識ルータなので、スイッチオーバー中でもR2へのトラフィック転送を継続します。さらにR6は、R2との接続損失をどのピアにも通知しません。またR2の上流のルータも、R2を経由してAS400に向かうパケットの転送を継続します。NSF/SSOは完全に意図したとおり機能します。RPのスイッチオーバー中も転送は継続し、ルーティング プロトコルの混乱もまったく起こりません。
同じことは、AS100とAS200の間のトラフィック フローにも当てはまります。ここでは2つの異なるルータに対して、2つの接続が管理ドメイン間で使用されています。R3とR4は、両方ともBGP NSF認識ルータです。BGPで使用されているTCPセッションがR2上のRPのスイッチオーバーで消失しても、同様に問題なく処理されます。スイッチオーバー中のトラフィックは、BGPが選択した最適パスで継続的に転送されます。
次に、AS300に出入りするトラフィックを検討します。R5はBGP NSF認識ルータではありません。おそらくR5では、BGP NSF認識のサポートを提供した最初のバージョン(Cisco IOSソフトウェア リリース12.0(22)S)よりも前のソフトウェアが実行されています。R2でスイッチオーバーが実行されると、TCP/BGPセッションの障害がR5で検出されます。次にR5は、トラフィックをルーティングして障害を迂回させようとします。その結果AS100宛てのトラフィックは、AS400のR6を経由するルートをとりますが、R2はNSF/SSO対応で設定されているため、R5に対してAS300に向かうトラフィックの転送を継続します。これは、NSF認識ピアとNSF非認識ピアが混在するときに発生する可能性のある、非対称ルーティングの例です。非対称ルーティングは望ましくない状態であり、ある程度のパケット損失が発生することもありますが、それでもR2の再初期化に伴うネットワークの混乱よりは望ましい状態です。
R5がR6に接続されていない場合を考えます。R2は以前にR5から学習したルートをクリアしません。R2は、最後にアップデートされたCEFテーブルを使用して、R5へのIPパケットの転送を継続する必要があります。R5はNSF非認識ルータなので、R2とのBGPセッションを喪失し、BGPセッションを最初から初期化します。R2はAS300宛てのパケット転送をR5経由で継続しますが、そのトラフィックにはリターン パスがありません。R5がR2との間で再コンバージェンスを完了するまでに、パケット損失が発生します。
このルールには例外があります。R5がネクスト ホップとしてR2を指定するデフォルトのスタティック ルートを持ち、またBGPのみを使用していたとすると、そのルートはR5によってアドバタイズされ、R2のBGPテーブルにエントリされます。この場合、R5のそのルートはR2で維持され、またR5に必要なのはデフォルトのルートだけなので、パケット損失は発生しません。
BGPとIGPの関係
このシナリオでは、展開上重要な考慮事項があります。このトポロジーでは、AS100からネクスト ホップに到達できるようにするために、Interior Gateway Protocol(IGP;内部ゲートウェイ プロトコル)(OSPFまたはIS-IS)を運用するのが非常に一般的です。BGPと選択されたIGPプロトコルは相互に依存します。最適パスを計算する際、BGPは特定の宛先プレフィクスをアドバタイズするルータのIPアドレスを認識しています。ただし、そのアドバタイズしているルータに到達するネクスト ホップを決定するには、IGPからの情報が必要です。
BGPグレースフル リスタートではBGPのコンバージェンスのタイミングを変更できるので、BGPで最適パスの選択が実行されるときに、IGPのコンバージェンスが未完了という状態になる可能性があります。したがって、アドバタイズしているルータへのパスがIGPによって計算されていないため、宛先プレフィクスがBGPにいくらか存在しても、CEFテーブルには追加できません。これによりパケット損失が発生することもあるので、BGPグレースフル リスタートに加えて、IS-ISまたはOSPF用のNSFを設定することを強く推奨します。
ルート リフレクタとの相互作用ルート リフレクタが実際にNSF対応で、BGPプロセスを再開する別のバリエーションを検討します。ルート リフレクタがBGPを再開すると、すべてのクライアントはルート リフレクタによって反映されたルーティング情報を維持します。バックアップ ルート リフレクタに切り替えるクライアントはありません。
NSF対応ルート リフレクタを使用するときは、特別に考慮すべき点がいくつかあります。まず考慮することは、ルート リフレクタが持つBGPピアの数とBGPデータの総量が、おそらくAS内の他のルータよりも多くなるということです。このため、スイッチオーバー中の最適パス選択の完了にかかる時間が長くなる場合があります。第2に、ネットワーク設計者は、ネットワークでパケット転送の連続性とルーティングの安定性を確保するという要件と、コンバージェンスの完了までにルーティングが大幅に変化する可能性との間で、折り合いをつける必要があります。RPのスイッチオーバー中、Cisco NSFはBGPのルーティング情報ではなく、CEFテーブルを使用してパケットを転送することに注意してください。
Cisco NSFをルート リフレクタで使用する場合、もう1つ設定の調整が必要になることがあります。再コンバージェンスのプロセスが全体で360秒を超えると予想される場合は、bgp graceful-restart stalepath-time 360コマンドのデフォルト値をルート リフレクタのすべてのピアで調整する必要があります。ステイルパス タイムの値は、コンバージェンス時間の予想値(秒)に30~60秒のバッファ ゾーンを加算した値に等しくなるように調整します。これにより、コンバージェンス時間がネットワークの状態変化に基づいて変動しても対応できます。
BGPグレースフル リスタートをルート リフレクタで使用すべきかどうかの決定は複雑であり、ネットワークの運用に大きく左右されます。ネットワーク設計者は、この決定にあたって重要なファクタを比較検討する必要があります。次の疑問に答えることが必要です。これらの疑問は、ルート リフレクタでCisco NSF/SSOを使用するかどうかを決定する際に問題となりますが、Cisco NSF/SSOを展開する場所と方法を決定する際に役立つ一般的な疑問でもあります。
特定のネットワーク展開で、別のケースとトポロジーが可能な場合もあります。したがって、NSF/SSOを導入するときは、実際にネットワークでアクティブ化する前に、すべてのケースについてその効果を分析することが重要です。
BGP NSFの設定
設計と展開オプションが決まれば、設定は非常に簡単です。
BGP NSF(グレースフル リスタート)は、ルータのbgpグローバル コンフィギュレーション コマンドを使用して設定します。
Router(config-route)# [no] bgp graceful-restart
Router(config-route)# [no] bgp graceful-restart restart-time n
Router(config-route)# [no] bgp update-delay n
Router(config-route)# [no] bgp graceful-restart stalepath-time n
bgp graceful-restartコマンドは、Cisco NSF対応ルータ、およびグレースフル リスタートに係わるすべてのNSF認識ピアで実行する必要があります。グレースフル リスタートはデフォルトでは無効なので、NSF対応ルータとすべてのピア ルータで正しく設定することが必要です。
bgp graceful-restart restart-time nコマンドは、再起動ルータの障害が検出されたあと、ピアがTCPセッションの再接続と、新しいBGP OPENメッセージを待ち受ける最大時間を指定します。TCPおよびBGPセッションが再確立されないうちにこのタイマーが切れた場合、BGPセッションは障害を起こしたとみなされ、通常のBGP復旧手順が有効になります。再起動時間のデフォルト値は120秒です。
bgp update-delay nコマンドは、Cisco NSF対応ルータで実行できます。このコマンドは、最初のピアが再接続されたあとのタイム インターバルを指定します。再起動ルータはこのインターバル中に、すべてのBGPアップデートとEND OF RECORD(EOR)マーカーを、設定されているすべてのピアから受け取ります。nのデフォルト値は120秒で、常に秒単位で指定します。再起動ルータが多数のピアを持ち、それぞれが多数のアップデートを送信するときは、この値をデフォルト値よりも大きくすることが必要な場合もあります。
bgp graceful-restart stalepath-time nコマンドは、再起動ルータのNSF認識ピアで実行できます。このタイマーは、再起動ルータとのBGPセッションを再確立したあと、ピアが転送にstaleルートを使用できる最大時間を設定します。デフォルト値は360秒です。これはコンバージェンスを完了するには十分な時間ですが、大規模なネットワークでは、この値を大きくすることが必要な場合もあります。
OSPF NSFOSPFはリンク ステート ルーティング プロトコルの1つで、同一ルーティング エリア内のすべてのルータが、一貫したルーティング トポロジーのビューを保持するようになります。たとえば、ルーティング トポロジーに変更があった場合は、Link-State Advertisement(LSA;リンク ステート アドバタイズ)がOSPFエリア全体にフラッディングされます。これにより、エリア内のすべてのルータでShortest Path First(SPF)計算が実行され、ルーティング テーブルが更新され、FIBテーブルの再読み込みが行われます。
再コンバージェンス中はネットワークが不安定になり、悪影響が生じることがあります。RPのスイッチオーバーは復旧処理であり、ルーティング トポロジーの変更ではありません。ルーティング トポロジーは以前の状態に復帰させる必要があるからです。再起動ルータがLSAフラッディングとネイバー隣接関係のフラップを引き起こさずにルーティング情報を再学習できれば、ルーティングの不安定化を回避できます。
OSPFルーティング プロトコルでこの目標を達成するには、主に次の2つの課題に対処する必要があります。ネイバー隣接関係の維持
OSPFがデュアルRPを備えたNSFルータで有効になっている場合、ルーティング プロセスはアクティブRPでのみ実行されます。スタンバイRPには、OSPF関連のルーティング情報、LSDB、およびネイバー データ構造は保持されていません。スイッチオーバーが発生すると、ネイバー関係は再確立する必要があります。
OSPF Helloプロトコルを使用することで、ネイバー関係の確立と維持、およびネイバー間の双方向通信の確認ができます。ルータが受信するネイバーのHelloパケット内にそのルータがリストされていれば、双方向通信が成立していることがわかります。
スイッチオーバーが発生すると、再起動ルータはHelloパケットを送信することによって、ネイバー隣接関係の再確立を試みます。新たにアクティブになったRPにはネイバーの状態情報が存在しないため、このHelloパケットのネイバー リストには、ネイバー情報がまったく含まれません。そのあとプロトコルに変更がなければ、このHelloパケットを受信するネイバーは双方向チェックに失敗し、再起動ルータとの既存のネイバー隣接関係をリセットします。近接ルータは同時に、隣接関係の変更を反映するためにアップデートLSAをフラッディングするので、ルーティングの混乱が引き起こされます。
シスコは、プロトコル機能拡張をOSPFに導入することによって、この問題を解決しました。シスコの実装は、IETFの3つのドラフトで提案されている方式に準拠しています(「関連する規格とドラフト」を参照)。ネイバー隣接関係のフラップを防止するため、シスコのOSPF NSFの実装では、Helloプロトコルに新しいビットとしてRestart Signalを導入しています。HelloパケットにRestart Signalビットが設定されることにより、そのルータでRPのスイッチオーバーが実行されていることがわかります。ネイバーはこのHelloパケットを受信すると、OSPF NSF手順に従って、双方向接続チェックを無視します。
Restart Signalビットは、HelloパケットのLink Local Signaling(LLS)データ ブロックにあるExtended Options Type Length Value(EO-TLV)に格納されています。LLSデータ ブロックがHelloパケットに存在することは、IETFのドラフトで導入されたLビットによって示されます。LビットはOSPFのOptionsフィールドに設定されます。ビットの値は0x10です。
NSFの実行中、Restart Signalビットが設定されたHelloパケットは2秒間隔で送信されます。これは、スイッチオーバー後のコンバージェンス時間を短縮するためです。このRestart Signalビットが設定された2秒間隔のHelloパケットは、「Fast Hello」と呼ばれています。Restart Signalビットは、ネイバー隣接関係が復旧するとクリアされます。
LSDBの再同期化
OSPF NSFではOSPFの状態情報がスタンバイRPに保持されないため、新たにアクティブになったRPは、LSDBをネイバーと同期化する必要があります。
これらの方法は、RPのスイッチオーバーの場合はいずれも実行不可能です。第1の方法が不可能なのは、LSAフラッディング回避のためには、RPのスイッチオーバー中もネイバー隣接関係を維持する必要があるからです。第2の同期方法は、変更のみが再同期化される差分式のため不十分です。この差分式のLSDB同期化では、FIB内のルートをすべて検証することができません。スイッチオーバー後はすべてのルートを検証し、トポロジー全体の完全性を維持することが不可欠です。
Cisco OSPF NSFでは、Out of Band(OOB) LSDB再同期化を使用することによって、この問題に対処しています。OOB再同期化メカニズムはIETFのドラフトで定義されており、ネイバー隣接関係が確立されたあとにLSDBを完全に再同期化できます。
このOOB再同期化機能を通知するため、新しいビットであるLSDB Resynchronization(LR)ビットが定義されています。LRビットはLLSデータ ブロック内のEO-TLVに設定されます。このデータ ブロックは、すべてのHelloパケットとDatabase Description(DBD)パケットに含まれています。
LRビットに加えて、DBDパケットには新たにRビットも導入されています。Rビットは、OOB再同期化手順がアクティブになっていることを示すために使用されます。このRビットは、DBDパケットのOptionsフィールドのフラグに設定されます。
LRビットを導入すると、OSPF NSFルータは、OSPFネイバーがNSF手順をサポートできるかどうかを識別できます。OSPFの動作中にLRビットの設定されたHelloパケットをネイバーから受信すると、そのネイバーがNSF認識で、NSF手順を実行できることがわかります。Rビットを導入すると、ルータは通常のLSDB同期化またはOOB再同期化のどちらが実行されているかを識別できます。
OOB再同期化メカニズムを使用したLSDB同期化プロセスは、すべての隣接ネイバー間で実行されるわけではありません。それはRFC 2328で定義されている従来のLSDB同期化と同じ方法により、ルータ間で実行されます。たとえばブロードキャスト ネットワークでは、再起動ルータがDesignated Router(DR;指定ルータ)またはBackup DR(BDR;バックアップ指定ルータ)でない場合は、指定ルータとの間でのみOOB再同期化が行われます。再起動ルータがNSF認識ネイバーとポイントツーポイントで接続されている場合は、そのネイバーとOOB再同期化が行われます。
注:NSF非認識ルータが検出されると、OSPF NSF対応ルータはセグメントでのNSF処理を無効にします。デフォルトでは、他のセグメントでNSF処理が継続されます。(OSPF)nsf [enforce global] CLI(コマンドライン インターフェイス)オプションが設定された場合、NSF処理はすべてのセグメントで終了します。また、共通セグメント上の2台のルータが同時にNSFの実行を試みた場合、NSF処理は両方のルータで終了します。
OSPF NSFプロトコル拡張機能の手順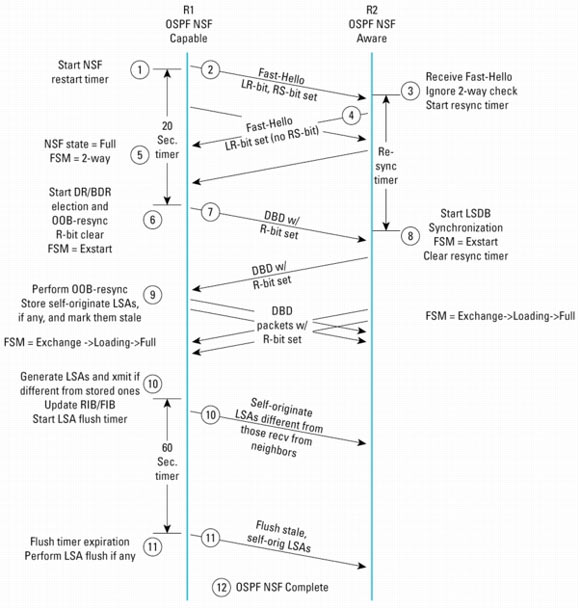
NSF非認識ネイバーが存在してもNSFの利点を活用することはある程度可能なので、NSFは漸次的に展開できます。再起動ルータは、セグメント内のネイバーがNSFを認識できないことを検出すると、デフォルトでは、そのセグメントのNSF手順を終了させるだけです。ほかのセグメントのNSF手順は継続されます。
混在環境では、RPのスイッチオーバー中、およびNSF手順が完了するまでに、非対称ルーティングが発生することがあります。ルーティングはNSF手順が完了すると対称になります。
以下は、NSFが動作しているときのトラフィック フローについての説明です。トラフィック フローを次の3つの段階で図示します。理解しやすいように、OSPF NSF再起動ルータとして1台のエッジ ルータに焦点を合わせ、そのネイバー ルータの1つがNSF非認識ルータであるとします。
OSPF NSF非認識ネイバーが存在するときのトラフィック フロー
図8では、R8がNSF再起動ルータです。そのネイバーのうち4台(R1、R4、R5、R7)はNSF認識ルータです。R2はNSF非認識ルータです。この設計は、NSF非認識ルータが存在するときのトラフィック フローの結果を示すという目的に合わせ、意図的に構成したものです。またリンクはすべて等コストで、「enforce global」コンフィギュレーションオプションは無効になっているものとします。「enforce global」オプションが設定されていると、NSF非認識ネイバーが検出された場合に、ネットワークの全セグメントですべてのOSPF NSF手順が強制的に終了されます。
図8 NSF非認識ネイバーが存在する場合のOSPF NSFの例
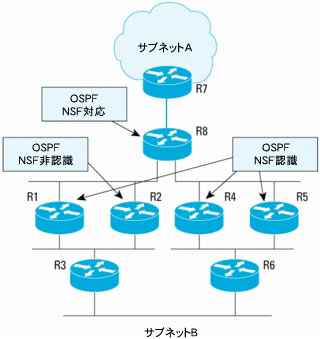
図9 スイッチオーバー前のサブネットAからサブネットBへのトラフィック フロー
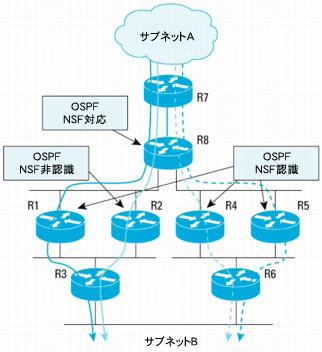
図10 スイッチオーバー前のサブネットBからサブネットAへのトラフィック フロー
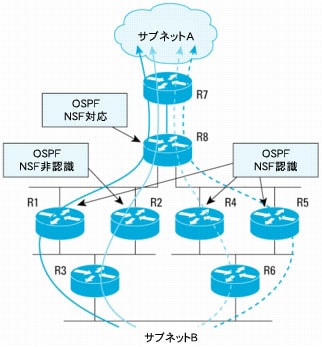
図11 R2がNSFを認識しないためにR1とR2を迂回するトラフィック
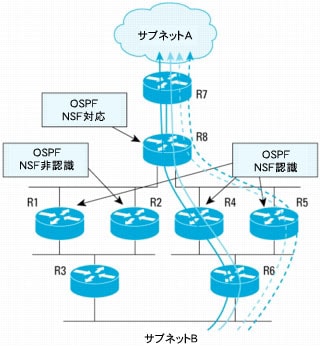
図12は、R8でスイッチオーバーが発生したために、NSF手順が進行しているときのトラフィック フローを示しています。
図12 スイッチオーバー前とスイッチオーバー中のトラフィック フロー
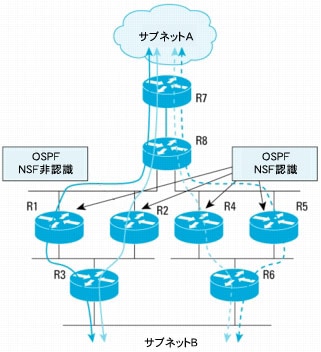
ここではR6のリンクが障害を起こしたために、トポロジー変更が発生するものとします。この場合はR6でLSAが作成され、OSPFエリアにフラッディングされます。
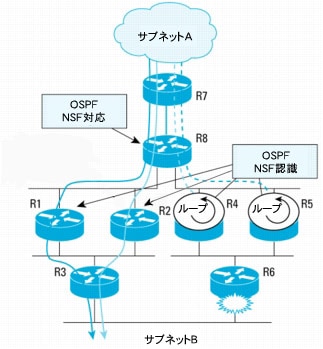
LSAを受信したR4とR5は、R6を経由するサブネットBへのパスが存在しなくなったことを認識します。R4とR5はパスを再計算し、サブネットBにはR8経由で到達できると判断します。そのため、R8がサブネットBに到達するためのネクスト ホップとして選定されます。これによって、一時的にルーティング ループが発生します(図13)。
このルーティング ループの発生は短時間です。NSF手順はまだ進行中であり、OOB再同期化手順がR8とR4、またはR5の間で完了すると、R8はR6を経由するサブネットBへのパスが利用できなくなったことを認識するので、ルーティング ループは解消します。
注: ルーティング ループは、NSFプロセス中にトポロジー変更があると必ず発生するわけではありません。ネットワーク トポロジー、変更のタイプ(スタブ ネットワークのフラップではルーティング ループは発生しません)、および変更のタイミングに左右されます。
NSF手順が有効なときにトポロジー変更が発生した場合のもう1つの例は、NSFを終了させることです。NSFプロセスをトポロジー変更中に終了させると、Cisco NSFのメリットは完全になくなります。NSFがトポロジー変更中に終了された場合、4つのフローはいずれもサブネットBに到達しません。トラフィックの消失です。NSF/SSOが実装されていなくても、ネットワークの再コンバージェンスが完了するまでは、RPのスイッチオーバーによってトラフィック損失が発生するのが一般的です。あらゆる面を考えると、こうした結果を招くよりもNSF/SSOがもたらすメリットの方が大きくなります。
図13 NSF手順中にルーティング変更によって生じる一時的なループ
OSPF NSFの設定
OSPFでNSFの動作を設定するには、ルータのOSPFコンフィギュレーション モードでnsfコマンドを使用します。
router(config)# router ospf 100
router(config-router)# nsf
注: ルータをNSF認識ルータに設定する必要はありません。ルータで、NSF手順をサポートできるCisco IOSソフトウェア リリースが実行されていれば、設定なしでNSFを認識します。
OSPF NSF非認識ルータが検出された場合に、オプションでルータ全体のOSPF NSFプロセスを終了させるには、「enforce global」キーワードを設定します。
router(config)# router ospf 1
router(config-router)# nsf enforce global
IS-ISはOSPFと同様、リンク ステート ルーティング プロトコルの1つです。したがって、同じルーティング エリア内のルータは、すべて一貫したルーティング トポロジーのビューを保持する必要があります。たとえば、ルーティング トポロジーに変更があった場合は、Link State Protocol(LSP)データ ユニットがIS-ISエリア全体にフラッディングします。その結果、エリア内のすべてのルータでSPFアルゴリズムが実行され、RIBが更新され、FIBの再読み込みが行われます。
ネットワークが再コンバージェンス中に不安定になり、パケットの配信に悪影響を与えることもあります。RPのスイッチオーバーは復旧処理と捉えることはできますが、ルーティング トポロジーの変更とは捉えられません。ルーティング トポロジーはスイッチオーバー後、以前の状態に復帰します。再起動ルータが、LSPフラッディングとネイバー隣接関係のフラップを引き起こさずにルーティング情報を再学習または維持できれば、ルーティングの不安定化は回避できます。
OSPFの場合と同様、IS-ISルーティング プロトコルでこの目標を達成するには、主に次の2つの課題に対処する必要があります。この問題に対処するには、2つのソリューションがあります。1つはシスコ固有のステートフル ルーティング ソリューションで、もう1つはOSPFとBGPで使用される前述の方法によく似ています。Cisco IOSソフトウェア固有のソリューションでは、チェックポイント機能を使用して、スタンバイRPのIS-IS隣接関係とデータベースの状態をバックアップします。2つめのソリューションはIETFの成果に基づき、IS-IS Hello PDU内の新しいTLVを使用します。したがって2つめの方法では、支援ネイバーが機能する必要があります。
シスコのステートフル ソリューションこのシスコ固有のソリューションは、前述の2つの問題(隣接関係の再取得とLSDBの再同期化)に革新的かつ独特な方法で対処します。
隣接関係の維持シスコのソリューションは、適切な状態情報をチェックポイント化し、再起動後にそれを使用することでこれらの課題を克服し、ネイバーで隣接関係が廃棄されることを防止します。メカニズムは、ポイントツーポイントとLANの両方の隣接関係に対応して設計されています。
LSPデータベースの同期化
データベースの同期化は、再初期化プロセスのもう1つの部分です。IS-ISプロトコルでは、LSDBを近接ルータと同期化するメカニズムを利用できます。通常の状況ではリブートによって、隣接関係の再初期化とそれに続くLSPデータベースの同期化が引き起こされます。隣接関係の再初期化はシスコのIS-ISステートフル ソリューションによって抑制されるので、トポロジー変更を起こさずにルータのLSPデータベースを同期化するために、特定のメカニズムが使用されます。
この場合もメカニズムは、ポイントツーポイントとLANの両方のインターフェイスに対応するように開発されています。
IETFソリューション
IETFソリューションが定義するメカニズムでは、ルータが再起動してネイバーでダウン ステートを繰り返さずに隣接関係を再確立できることを、再起動ルータからネイバーに通知します。一方、データベース同期化が正しく開始されることも通知します。前述のシスコのステートフルIS-ISルーティング ソリューションと異なり、IETFソリューションはステートレスです。このソリューションでは、LSPデータベースの内容と隣接関係の情報はチェックポイント化されません。
IETFソリューションでは、再起動ルータの再起動を隠蔽しません。再起動ルータは再起動したことを明示し、LSPデータベースの内容をネイバーから取得できるようにします。ネイバーはこれを認識し、再起動ルータと連携します。
隣接関係の再取得
隣接関係の再取得は、再初期化の最初のステップです。再起動ルータは、隣接関係が再取得されるので、ネイバーでは隣接関係再初期化の必要がないことをネイバーに対して明示的に通知します。これは、新しい「再起動」オプション(TLV)をHello PDUに含めることで実現されます。このTLVの存在によって送信者が新しい再起動機能をサポートしていることがわかります。またこのTLVには、再起動中の情報伝達に使用するフラグが付いています。この機能をサポートしているルータから送信されるHelloメッセージには、このTLVが含まれます。このTLVには、2つのフラグが含まれています。「Restart Request」を示すRRと「Restart Acknowledgement」を伝達するRA、そして「Remaining Time」で、これは許容できる復旧時間を再起動ルータに通知します。
再起動ルータの近接ルータは、「再起動」TLVにRRビットが設定されたHelloメッセージを受信すると、再起動ルータとの隣接関係を「Up」ステートのまま維持し、この再起動への確認応答としてRAビットを設定したHelloメッセージを送信します。
複数のレベルLSPデータベースの同期化
ルータは再起動すると、ネイバーごとに保持されているLSP状態を反映したCSNPをそれぞれのインターフェイスで受信できます。CSNPが正しく受信されるまでは、RRビットの設定された「再起動」Helloが再送信されて、CSNPの着信を保証します。このLSPがすべて受信されると、同期化が完了します。
LSPの作成とフラッディング
隣接関係がすべて再初期化されると、ルータでは利用可能な隣接関係情報がすべて再取得されたものとみなされ、IS-ISで独自のLSPを作成できるようになります。ローカライズされた再起動を実現するためには、再起動前のルータの状態を反映する十分な情報が取得されるまで、このルータのLSPを作成および伝達しないことが重要です。また、このローカルLSPの再作成フェーズより前に、ローカル ルータのLSPの古くなったコピーが受信されることもあります。
通常の場合、作成を終えているルータから受信されたLSPのコピーは削除する必要があります。ただし再起動ルータの場合は、作成される必要のない新しいLSPが受信されることもあります(レベル1のSPFが実行されて、レベル2に伝達の必要のあるプレフィクスが検出された場合)。「余計な」LSPを削除すると、他のすべてのルータに影響が及び、そのFIBは混乱します。NSF認識ルータでは、プロトコルとIS-ISレベル間の再分配がすべて実行されるまで、この「余計な」LSPは無視されます。「余計な」LSPは、同期化ポイントに達してから削除されます。
同様に、レベル間情報の再分配は、このルータのLSPが他のノードにフラッディングする前に再開されます。レベル1またはレベル2のLSPの送信は、他のレベルのSPFが実行され、伝播する必要のあるレベル間情報がこのLSPに含まれていることが確認できるまで延期されます。
注:SPF計算の「最初の反復」中に情報がRIBに追加されなくても、FIBにエントリが保持されているため、これらの宛先へのトラフィックは廃棄されません。IS-IS以外のルーティング プロトコル情報の再分配は、最後のNSF IS-IS LSPの作成前に、RIBでアップデートされる適切なルーティング情報に依存することがあります。
SPF計算
LSPデータベースが再同期化されると、リンク ステート データベースは最新になります。SPF計算が実行され、再初期化されたすべての情報がRIBとFIBに伝播されます。このプロセスでリフレッシュされなかったルートはすべて古くなっているので、ブラック ホールとルーティング ループを抑制するためのホールド タイム経過後に削除されます。
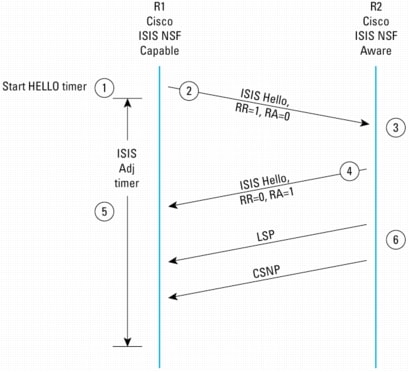
IS-IS NSFプロトコル拡張機能の手順
この項では、IETFの実装に対応したIS-IS NSFについて説明します。
注:NSF非認識ルータが検出されると、IETF IS-IS NSF対応ルータは、他のすべてのセグメントでNSF処理を無効にします。
図15 IS-IS NSF非認識ピアとのIETF IS-IS NSF手順
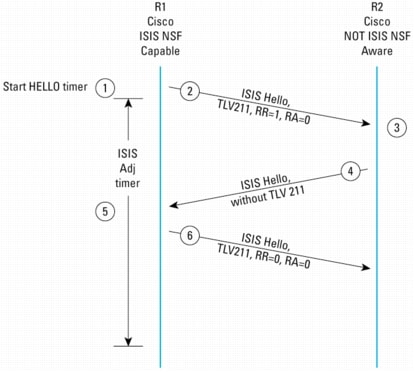
Cisco IS-IS NSFは、近接ルータのNSF機能にかかわらず、同レベルの効果で機能する利点を備えています。IETFバージョンを展開する場合は、IS-IS NSF手順に再起動ルータとそのネイバーの両方が関与するため、IS-IS NSF対応ルータのネイバーはNSF認識ルータである必要があります。
タイマー調整に関する考慮事項
隣接関係を廃棄する標準的なタイムアウト時間は、ポイントツーポイント リンクでは30秒、LANでは10秒です。この時間内にHelloの伝送が再開できれば、ネイバーはその隣接関係を廃棄しません。したがって、Helloのホールド タイムは、隣接関係が時間切れになる前にプロセスを再開できるだけの十分な長さに設定する必要があります。
「スムーズに」再起動するという目標は、リンク(およびその後のトポロジー)の変更にすばやく反応するという目標と矛盾することになりますが、ホールド タイムの設定値を長くするだけでは、スムーズな再起動は保証できません。Helloタイマーが変動すると、Helloとホールド タイムの時間切れはホールド インターバル全体に均一に分散します。これはどの瞬間にも、多数の隣接関係が時間切れ寸前になっていることを意味します。時間切れ寸前の隣接関係がすべて失われないようにするには、Helloの乗数を1より大きくするのが唯一妥当な方法です。これは一般的に行われていることですが、NSFでは絶対要件です。Helloの乗数を2または3にすると、(少なくともHelloが失われていない隣接関係では、)再起動プロセスで復旧のためのHelloインターバルは最大になります。インターフェイスの数が多いときは、NSFルータのIS-IS再起動時間を決定する必要があります。
IS-IS NSFの設定
IS-ISでNSF動作を設定するには、ルータのIS-ISコンフィギュレーション モードでnsfコマンドを使用します。デフォルトではNSF再起動はオフですが、ルータにはデフォルトでIETF TLVが含まれています。動作モード(シスコまたはIETF)はこの段階で選択されます。
router(config)# router isis
router(config-router)# nsf [cisco/ietf]
次のコマンドは、2つの再起動間のインターバルを(0~1440分の範囲で)指定します。ルータのアクティブおよびスタンバイRPがこの時間より長く稼働していないと、IS-IS NSFはキャンセルされます。デフォルト値は5分です。
router(config)# router isis
router(config-router)# nsf interval 600
次のコマンドは、IS-IS隣接関係を持つインターフェイスが再起動完了前にすべて動作状態になるように、NSF再起動の待ち時間を(1~60秒の範囲で)設定します。デフォルト値は10秒です。
router(config)# router isis
router(config-router)# nsf interface wait 20
次のIETFモード専用コマンドは、overloadビットの設定された独自のLSPが作成されてフラッディングされる前に、LSPデータベースが同期化されるのをNSFが待つ時間を(秒単位で)設定します。
router(config)# router isis
router(config-router)# nsf t3 manual 60
「adjacency」キーワードを使用すると、この上記のt3時間は、スイッチオーバー前にネイバーにアドバタイズされる隣接関係のホールド タイムから決定されます。
router(config)# router isis
router(config-router)# nsf t3 adjacency
EIGRP NSF
Enhanced Interior Gateway Routing Protocol(EIGRP)は、さまざまなトポロジーとメディアに適したIGPです。EIGRPは拡張ディスタンス ベクタ ルーティング プロトコルで、Diffused Update Algorithm(DUAL)に基づいて、ネットワーク内の宛先への最短パスを計算します。設計の優れたネットワークでは、EIGRPのスケーラビリティが発揮されるので、きわめて高速のコンバージェンスが実現され、またオーバーヘッド トラフィックは最小限に抑えられます。これまでに説明した各種のルーティング プロトコルと同じく、EIGRPルーティング プロトコルとNSFが相互作用する目的は、RPのスイッチオーバーが発生したときに、ルーティングへの影響が最小限に抑えられ、パケット転送が混乱しないような形で、グレースフル リスタートを実行することです。
ネイバー隣接関係の維持
他のプロトコルと同様、NSFを実現するには、スイッチオーバー中に再起動ルータのピアが再起動ルータへのパケット転送を継続する必要があります。したがって、ピアでネイバー隣接関係がリセットされないようにすることが必要です。
ネイバーによる隣接関係のリセットを防止するため、再起動ルータは新しいRestart(RS)ビットをEIGRPパケットのヘッダーに設定し、再起動を示すことで、スイッチオーバー中でもサービス提供ができることをピアに通知します。EIGRP NSFを設定すると、HelloパケットとNSF再起動期間中に送信される最初のINITアップデート パケットに、RSビットが設定されます。RSビットをHelloパケットに設定することによって、再起動ルータはスイッチオーバーを迅速にネイバーに通知できます。またこれによってNSF認識ピアは、通常の隣接関係検出と起動の方法を使用するのではなく、NSF拡張機能に従う必要があることを認識します。
NSF非認識ネイバーは新しいRSビットを無視します。このネイバーはINITアップデート パケットを受信するか、またはホールド タイマーが切れると、隣接関係をリセットします。
HelloパケットまたはINITパケットによって再起動の通知を受信すると、ネイバーは再起動ピアをピア リストに書き込み、再起動ルータとの隣接関係を維持します。近接ルータは、再起動ルータに関する状態変更を自身のネイバーにはまったく伝達しません。代わりに、再起動ルータを経由するルートをstaleとマーキングし、再起動ルータへのパケット転送を継続します。これによって、ルータの障害に伴うネットワーク パフォーマンスへの悪影響を回避できます。
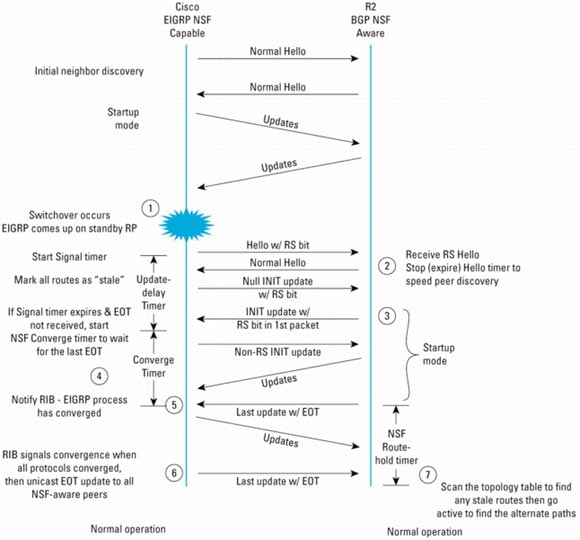
EIGRP NSFプロトコル拡張機能の手順
図16は、NSF対応ルータでスイッチオーバーが実行されているときの、NSF対応EIGRPルータとNSF認識EIGRPピア間のプロトコル交換を示しています。
再起動ルータがまだピアを再検出していない場合、NSF認識ルータがINITパケットの前にHelloパケットを受信することがあります。再起動ルータのピア再検出プロセスを早めるため、NSF認識ルータはただちにより短いHelloタイム インターバルでHelloパケットを返信します。
注: ルータはNSFを認識できても再起動手順は実行しません。この状態は、再起動ネイバーがリロードされ、コールド スタートから稼働状態になるときに発生します。
End of Tableマーカー方式に加えて、EIGRPではタイマー(NSFコンバージ タイマー)が使用され、すべてのEnd of Tableマーカーを受信するまでの最大待ち時間が設定されます。
この時点でNSF拡張機能はすべて完了し、通常のEIGRP処理が継続します。
EIGRP NSFの展開
再起動ルータがNSFを正しく実行するには、ピア ルータでEIGRP NSF機能を備えたCisco IOSソフトウェア バージョンが動作していることも必要です。ピア ルータでEIGRP NSF機能を持たないCisco IOSソフトウェア バージョンが動作している場合、スイッチオーバーの結果は隣接関係がリセットされるのと変わりません。これは非NSF EIGRPルータが、再起動ルータからINITアップデート パケットを受信すると隣接関係をリセットするためです。
このEIGRP NSFの設計では、2つの近接ルータでスイッチオーバーまたはNSF再起動が同時に実行されるケースはサポートしていません。両方のルータが同時に再起動した場合は、HelloパケットまたはINITアップデート パケット内のRSビットによって、一方に他方の再起動が通知されます。両方のルータでNSF以外の通常の再起動が実行され、それらのピア関係はNSF以外の方法で再確立されます。
EIGRP NSFでは、次のことを認識する3つの新しいタイマーが追加されています。
EIGRP NSFの設定
EIGRP NSFはデフォルトでは無効です。NSFは、次のコマンドで有効または無効にします。
router eigrp <AS-number>
[no] nsf
タイマーは、次のコマンドで指定できます。
router eigrp <AS-number>
[no] timers nsf signal <seconds>
[no] timers nsf converge <seconds>
[no] timers nsf route-hold <seconds>
MPLSネットワークの高可用性
Cisco IOSソフトウェア リリース12.2(25)Sでは、MPLS環境に対応したHAが導入されています。MPLS High Availability(MPLS-HA)のサポートの主な対象は、MPLSネットワークへのアクセスを提供するService Provider Edge(PE;プロバイダー エッジ)デバイスです。これらのデバイスは、MPLSコアに基づかない純粋なIPネットワークのエッジ ルータと同様に、MPLS VPNサービスのお客様にとってシングルポイント オブ フェイラーとなることがよくあります。
この文書の作成時点では、MPLS-HA機能のサポートはCisco 7500シリーズ ルータでのみリリースされています。他の製品についても順次サポートされる予定です。Cisco 7500シリーズ製品のMPLS-HAでは、MPLSレイヤ3 VPN用のNSF/SSO、およびLabel Distribution Protocol(LDP)NSF(グレースフル リスタート)のサポートが可能となっています。これまでに説明した他のプロトコルと同様、LDPの実装では、隣接ピア ルータでのLDPグレースフル リスタート(NSF認識)が必要になります。LDP GR認識は、Cisco IOSソフトウェア リリース12.0(29)S以上が稼働するCisco 12000シリーズ製品で利用できます。
MPLSの完全サポートを提供していないCisco IOSソフトウェアが稼働しているネットワークでは、RPのスイッチオーバー中にMPLSトラフィックのパケット損失が発生します。ただしこの場合でも、SSOに維持されるリンク レイヤの状態によってすばやく回復できるため、NSF/SSOを有効にすることには、ある程度の利点があります。試験の測定結果によると、多くのリンク タイプでは、MPLSインターフェイスを備えたルータでスイッチオーバーが発生した場合のトラフィック損失は、そのルータでRPR+のスイッチオーバーが実行された場合とほぼ同じです。ただし一部のリンク タイプでは、トラフィックの損失は減少します。転送を継続するにはLDPプロセスでラベルの完全な再起動と学習が必要ですが、再起動の速度はNSF/SSOを有効にすることで向上します。
MPLS-HAがCisco 12000シリーズやその他の製品で利用可能になると、MPLSレイヤ3 VPN、さらにMPLSレイヤ2 VPNで同じようにパケット損失をゼロにすることが可能になります。
MPLS-HA機能詳細については、この文書の最後にある「参考文献」を参照してください。
MPLS-HAの前提条件MPLS-HAの動作
BGPは、プレフィクスにローカル ラベルを割り当てると、そのローカル ラベル バインディングをバックアップRPでチェックポイント化します。チェックポイント機能は、状態情報をアクティブRPからバックアップRPにコピーします。これによって、バックアップRPは最新情報とまったく同じコピーを保持するようになります。アクティブRPに障害が発生しても、サービスを中断することなくバックアップRPに切り替えることができます。チェックポイント化は、アクティブRPがすべてのローカル ラベル バインディングを、バックアップRPにコピーするバルク同期化を行うときに開始されます。その後アクティブRPは、ラベルの割り当てまたは解放のときに、個々のプレフィクス ラベル バインディングをダイナミックにチェックポイント化します。これによって、BGPの再コンバージェンス前でもラベル付きパケットの転送を続けることができます。
VPN NSF用に設定されていないルータが、VPN NSFを備えたルータとのBGPセッションの確立を試みた場合、2台のルータは通常のBGPセッションを確立しますが、VPN NSFは実行できません。
LDPグレースフル リスタート(NSF)
LDP NSF(LDPグレースフル リスタート[GR])は、RPのスイッチオーバーが片方のLSRで発生するなどして2台のLSR間のLDP通信がいったん失われ、その後復旧する場合に、それらのLSRでLDPとフォワーディング ステートを保護するために使用できるメカニズムです。LDP GRによって、中断されたLDP通信が障害から復旧するまでの間も、以前に学習したラベルを使用するトラフィックでノンストップのMPLS転送が可能になります。
この実装によって、LDPコンポーネント(コントロール プレーン)の再起動やネイバーとのLDP通信の一時的な中断から保護されます。LDPコンポーネントの再起動(LDP再起動)が発生すると、すべてのLDPネイバーとのLDP通信が中断し、それらのネイバーから学習したLDP状態が失われます。LDPコンポーネントは再起動せず、ネイバーとの通信が失われただけ(LDPセッション リセット)の場合は、そのネイバーから学習したLDP状態は、関連するフォワーディング ステートも含めて維持されます。
LDP GRは、この文書で説明している他のNSFプロトコルと同様に動作します。LDP GRでは、LDP通信の障害から回復するために、LSRが次のように動作することが必要です。図17は、2台のLSR間のLDP GRメッセージ フローを示しています。
LDPでは、Helloメッセージが交換され、LDPメッセージを伝送するためにTCPセッションが確立されると規定しています。
1 & 2. LSRは、LDP初期化メッセージの中にオプション パラメータとしてFault Tolerant(FT) Session TLVを含めることによって、LDPグレースフル リスタートのサポートが可能であることを示します。L(Learn from Network)フラグは、LDP GR手順が使用されることを示します。オプションのFT Session TLVは、下位互換性を確保できるように定義されています。TLVの「Uビット」が設定されると、受信側はLDP GRをサポートしていない場合にTLVを自動的に削除します。その場合、LDPセッションは確立しますが、GRは実行されません。
LDP GR関連で、FT Session TLVに存在するタイマー フィールドは次の2つです。図17 LDPグレースフル リスタート拡張機能
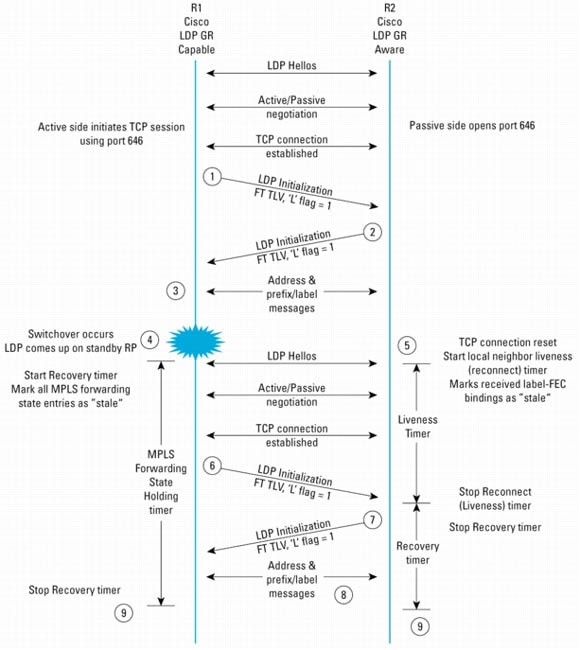
この時間を0にすると、再起動の前後にMPLSフォワーディング ステートは維持されていないことが示されます。
この時間内にLSRがネイバーとのLDPセッションを確立しなければ、staleバインディングはすべて削除されます。
LDP GR認識ルータはLDPセッション リセット モードになります。LDP GR認識ルータは、再起動ルータとのLDPセッションを再確立する時間を設定するためにタイマーを開始します。ルータがLDPセッションの再確立を待ち受ける時間は、ピアからFT TLVで受信される再接続時間、またはneighbor-livenessタイマーの値よりも短くなります。タイマーが切れる前にLDPセッションが確立された場合、ルータはそのネイバーと関連するstaleラベル バインディングを削除します。neighbor-livenessタイマーのデフォルト値は120秒です。
再起動手順中は既存のラベル バインディングが使用されます。送信ラベル バインディングは、LDPセッションの再確立後、再起動ルータによってアドバタイズされます。LDPがアドバタイズされたプレフィクスのバインディングを保持している場合は、新しいバインディングが既存のLDP手順を使用して学習されます。ラベル バインディングが保持されている場合、LDPは新しいバインディングが学習されたときに、保持されているバインディングの「stale」マークを消去します。同じラベルがアドバタイズされた場合は、動作は必要ありません。新しいラベルがアドバタイズされると、LDPはそのイベントを処理するために既存の手順を使用して、ラベル バインディングをアップデートする必要があります。
MPLS-HAの設定
MPLS-HAのサポートを有効にするには、まずルータをSSOモードにする必要があります。次に、LDPグレースフル リスタートを有効にすることが必要です。NSFで最大の効果が得られるように、IGPプロトコルとPE-CEプロトコルも有効にする必要があります。次に、LDPの具体的な設定について説明します。
LDPグレースフル リスタートの設定
LDP GRは、次のグローバル コマンドによって有効化します。
Router(config)# mpls ldp graceful-restart
LDP GRタイマーの値は、関連する次のコマンドで指定します。
LDPグレースフル リスタートの状態は、次のコマンドを使用して決定できます。
Router# show mpls ldp graceful-restart
LDP Graceful Restart is enabled
Neighbor Liveness Timer: 5 seconds
Max Recovery Time: 200 seconds
Down Neighbor Database (0 records):
Graceful Restart-enabled Sessions:
VRF default:
Peer LDP Ident: 18.18.18.18:0, State: estab
Peer LDP Ident: 17.17.17.17:0, State: estab
Cisco NSF/SSOのサポートは、Cisco IOSソフトウェア12.0(22)Sで初めて登場しました。その後、他のリリースにも拡張され、Cisco 7500シリーズ ルータ用のCisco IOSソフトウェア リリース12.2(25)SではMPLS-HAのサポートが導入されました。 NSF/SSOは現在、幅広いシスコ製品、RP、およびライン カード ハードウェアで利用できます。またNSF認識も、さまざまなシスコ製品ファミリーの複数のリリースで一般的な機能となっています。
ハードウェアの制限さまざまなライン カードでCisco NSF/SSOがサポートされています。パフォーマンスを最適化するには、ルータ シャーシ内のすべてのカードでCisco SSOがサポートされている必要があります。各プラットフォームで現在サポートされているライン カードの一覧については、シスコの最新マニュアルで確認してください。Cisco SSOでサポートされていない特定のライン カードの場合、そのライン カードはRPR+モードで動作します。RPのスイッチオーバー時には、カード上の分散転送情報が消去されます。これにより、スイッチオーバーが発生した場合、そのカードを経由して到達できる宛先へのトラフィックに損失が発生します。他のライン カードは、スイッチオーバー中も転送を継続します。
各種ライン カードまたはモジュール組み合わせのサポートに関する詳細は、CCO上の該当するマニュアルを参照するか、シスコの担当者にお問い合わせください。
この項では、NSF/SSOの展開時に踏むべき実際の実装手順について概説します。
ピアの組み合わせの検討
実装前の最初のステップはネットワークを再検討し、手持ちのさまざまなピアの組み合わせを分析することです。シスコ製品だけで構成されたネットワークを利用しているお客様は、展開が最も簡単です。マルチベンダー環境を利用しているお客様は、グレースフル リスタート規格とプロトコル拡張機能のサポート レベルを確認する必要があります。いずれの場合も、HA認識のサポートでは、さまざまな組み合わせを利用できます。
次に、実装の戦略を考えます。推奨する方法は、コアから実施することです。上位層のコア対面ルータを、必要なNSF認識をサポートするCisco IOSソフトウェアのレベルまでアップグレードします。さらにサイトごと、または特定のロケーションで作業を行い、NSF/SSOをエッジ デバイスに実装します。
ルート リフレクタを使用する場合は、このルータがBGP NSFを認識するようにします。これが完了すると、ネットワーク エッジ境界でNSF/SSOの有効化を開始できます。
OSPF NSF認識はデフォルトでオンですが、BGP NSF認識は設定の必要があります。またピアをリセットして、BGP NSFがその特定のピアについて有効になるようにする必要があります。OSPF NSFが有効で、BGP NSFが無効の状態は望ましくないので、実装の観点では避ける必要があります。
サービス プロバイダーでの展開例
設定の準備
サービス プロバイダーのPOPまたはサイト内でNSF/SSOを展開するための最初の準備ステップは、サイト内のすべてのルータの機能別一覧を作成することです。たとえば、カスタマー アクセス ルータ、アグリゲーション レイヤ ルータ、ルート リフレクタ、コア ルータなどです。
NSF/SSOの展開で予想される適切なレベルのソフトウェアが、すべてのルータで実行されていることを再確認します。
ピアリングの設定をルータごとに再確認し、実際の設定が実行されるときにすべてのOSPFまたはIS-ISおよびBGPピアが含まれるようにします。
特定のネットワークで実行されるステップを簡単にまとめると、次のようになります(この例では、IGPをOSPFとし、ルート リフレクタを使用すると仮定しています)。以下に、NSF/SSOを実装する詳細なコンフィギュレーション コマンドを例示します。
段階的な実装手順
この項では展開の例、およびNSF/SSOの実装に使用する一連のCLIコンフィギュレーション コマンドを示します。
Cisco 7500シリーズ ルータとCisco 12000シリーズ ルータについては、特記すべき運用上の注意事項がいくつかあります。
Cisco 7500シリーズ ルータ運用上の注意事項スレーブがオンラインになると、トラフィックはスレーブがバスに再接続するときにもう一度中断します。このトラフィックの中断は、スイッチオーバーが発生した際の最初のトラフィック損失以下になります。
Cisco 12000シリーズ ルータ運用上の注意事項スレーブがオンラインになるときにトラフィック損失は発生しません。
設定Router(config)#router bgp <as number>
Router(config-router)#bgp graceful-restart
次に、このサイトのアグリゲーション レイヤ ルータでOSPF NSFを有効にします(関連するCisco IOSソフトウェア ベースのデバイスが存在する場合)。
Router(config)#router ospf <process id>
Router(config-router)#nsf
同じコマンドを使用して、サイト内のすべてのカスタマー アクセス レイヤ ルータまたはエッジ ルータで、BGPおよびOSPFグレースフル リスタートを有効にします。
Router(config)#router ospf <process id>
Router(config-router)#nsf
Router(config)#router bgp <as number>
Router(config-router)#bgp graceful-restart
この時点で、ルータは「望ましくない」設定状態の1つになります。OSPF NSFは稼働していますが、BGPピアがリセットされていないため、BGP NSFは未稼働です。NSF/SSOの設定手順ではこうした状態は回避できないので、次のステップをすみやかに実行し、SSO/NSFを完全に稼働状態にします。
次に、BGPピアをリセットする必要があります。通常サービス プロバイダーのPOPの設計では、冗長アグリゲーション ルータが配置されます。この場合、clear ip bgp* を一方のアグリゲーション レイヤ ルータで実行してピアが再確立するのを待ち、次にもう一方のアグリゲーション レイヤ ルータでclear ip bgp* を実行するのが最も簡単です。これによって、設定した最初のサイトのBGP RRピアがすべてキャッチされます。そのあと他のサイトを設定していくときは、clear ip bgp* を使用してリセット済みサイトのBGP RRピアを再度リセットする必要はありません。BGPピアをそれぞれ任意にリセットすることは可能ですが、すべてのBGPピアがグレースフル リスタート機能を備えるようにすることが重要です。
次に、デュアル プロセッサを備えたアグリゲーション レイヤ ルータとアクセス レイヤ ルータを、すべてRedundancy Mode SSOで設定します。
Cisco 7500シリーズ ルータでは、ハードウェア モジュール コマンドを設定することが必要です。
router#conf t
router(config)#hardware-module slot 6 image disk0:<image-name>
router(config)#hardware-module slot 7 image disk0:<image-name>
注: スロットは、ルータがCisco 7507とCisco 7513のどちらであるかによって異なります。
両タイプのルータに、次のコマンドを使用してSSOを設定します。
router#conf t
router(config)#redundancy
router(config-red)#mode sso
SSOを設定すると、スレーブは自動的にリセットされます。Cisco 12000シリーズ ルータのリセット中、トラフィック損失は発生しません。Cisco 7500シリーズ ルータでは、スレーブをリセットすると、スレーブがオンラインに復帰するときに短時間だけトラフィック損失が発生します。
最後に、NSF/SSOの設定を各ルータで確認する必要があります。
OSPFでは、次のコマンドでNSFが有効になっていることを確認します。
router>sh ip ospf | inc Non-Stop
Non-Stop Forwarding enabled
BGPでは、各ピアを次の行で確認する必要があります。
Graceful Restart Capability: advertised and received
機能はアドバタイズされ、かつ受信される必要があります。受信されない場合は、ピアの相手側でBGPグレースフル リスタートが設定されていないか、またはそのピアがリセットされていないかのいずれかです。
最後にsh redundancyコマンドで、ルータがSSOモードで動作していることを確認します。
router>sh red
Redundant System Information:
------------------------------
Available system uptime = 12 minutes
Switchovers system experienced = 0
Standby failures = 0
Last switchover reason = none
Hardware Mode = Duplex
Configured Redundancy Mode = sso
Operating Redundancy Mode = sso
Maintenance Mode = Disabled
Communications = Up
ここ数年の間に、ネットワークの可用性は、サービス プロバイダーと企業の双方にとってますます重要な問題となってきました。シスコは、Cisco IOSソフトウェアのHAインフラストラクチャとCisco NSF/SSO、およびグレースフル リスタート用のさまざまなルーティング プロトコル拡張機能など、高可用性ネットワーキングに向けた包括的戦略を実践しています。ユーザとベンダーがこうした拡張機能による展開の経験を蓄積するにしたがって、プロトコルそのものとネットワークの展開方法に、さらに改良が加えられます。
シスコはSSOを、Cisco IOSソフトウェアのインフラストラクチャ機能として実装しています。Cisco SSOは、実際にはレイヤ2接続の維持以上の機能を提供しており、すべてのサポート プラットフォームとインフラストラクチャの状態の管理も行っています。レイヤ2接続の維持は、Cisco SSOの提供サービスの中で最も目につきやすいものであるにすぎません。
まとめとして、シスコはお客様のニーズに対応する革新的機能を提供し続けます。シスコのHA戦略は単純です。つまり、ダウンタイムの原因となるあらゆる可能性に対処し、MTBFを拡大してMTTRを短縮するための特徴、機能、ベスト プラクティス設計の推奨事項、および運用手順を提供することです。Cisco NSF/SSOは現在、既存のハードウェアに展開することが可能です。Cisco NSF/SSOは、ネットワーク ルーティング プロトコルの再コンバージェンス、およびそれに伴うトラフィック バーストとCPU負荷を最小限に抑えます。また、ネットワーク利用の計画性を強化し、信頼性に対するユーザの認知度も向上させます。
RPのスイッチオーバー発生時に転送を継続させるメカニズムは、完全には規格化されていません。関連する文書を以下に挙げます。
シスコのBGPの実装は、draft-ietf-idr-restart-nn.txtに記されている仕様に準拠しています。この文書の作成時点での最新バージョンはdraft-ietf-idr-restart-10で、これは規格案です。
シスコのOSPFの実装は、次のIETFのドラフトに記されている仕様に準拠しています。OSPF Hitless Restartの現在の標準は、RFC 3623 『Graceful OSPF Restart』です。現在(この文書の作成時)シスコの実装は、RFC 3623と相互運用できません。
IS-IS(IETFオプション)のCisco NSFの実装は、RFC 3847『Restart Signaling for Intermediate System to Intermediate System(IS-IS)』に記されている仕様に準拠しています。シスコ固有のステートフル実装もサポートされており、設定が可能です。
シスコのLDPの実装は、RFC 3478『Graceful Restart Mechanism for Label Distribution Protocol』に記されている仕様に準拠しています。
|