Arborescence des erreurs de parité du Cisco 7200
Contenu
Introduction
Ce document explique les étapes pour dépanner et isoler la pièce ou la composante défectueuse du Cisco 7200 lorsque divers messages d'erreur de parité sont repérés. Nous vous recommandons de lire le document Dépannage des pannes de routeur et des erreurs de parité de la mémoire du processeur (PMPE) avant de lire ce document.
Remarque : les informations de ce document sont basées sur les routeurs de la gamme Cisco 7200.
Conditions préalables
Conditions requises
Aucune condition préalable spécifique n'est requise pour ce document.
Components Used
Ce document n'est pas limité à des versions de matériel et de logiciel spécifiques.
Les informations présentées dans ce document ont été créées à partir de périphériques dans un environnement de laboratoire spécifique. All of the devices used in this document started with a cleared (default) configuration. Si vous travaillez dans un réseau opérationnel, assurez-vous de bien comprendre l'impact potentiel de toute commande avant de l'utiliser.
Conventions
For more information on document conventions, refer to the Cisco Technical Tips Conventions.
Analyse de l'arbre des erreurs de parité du moteur de traitement réseau (NPE)
Ce schéma décrit les étapes à suivre pour déterminer quelle partie ou quel composant d'un Cisco 7200 échoue lorsque vous identifiez divers messages d'erreur de parité.
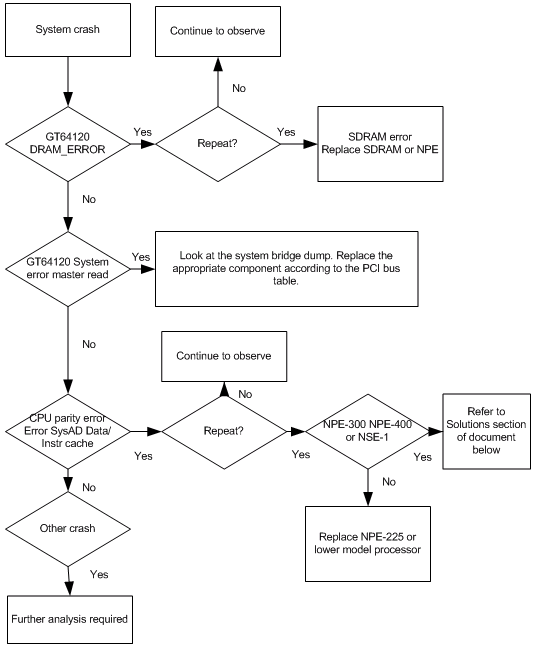
Remarque : Capturez et enregistrez la sortie et les journaux de console show tech-support, et collectez tous les fichiers crashinfo lors d'événements d'erreur de parité.
Détection des erreurs et messages de parité NPE
Cette section contient les diagrammes de bloc du NPE et où ces systèmes détectent les erreurs de parité. Vous trouverez une description de chaque type de message d'erreur ci-dessous.
Erreurs de parité dans le NPE-300
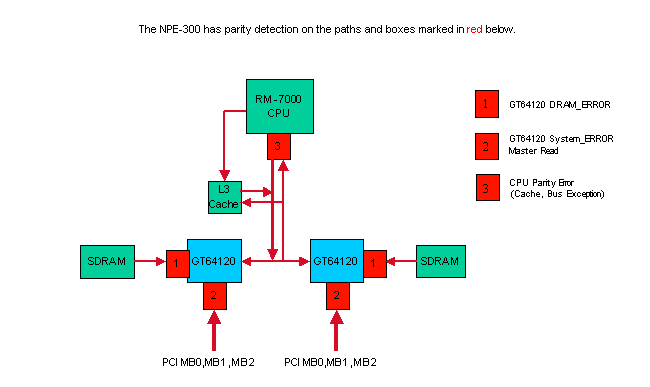
Le NPE-300 utilise le contrôle de parité dans la mémoire partagée (SDRAM), le bus PCI et l'interface externe du processeur pour protéger le système contre les erreurs de bits. Le contrôle de parité est capable de détecter une erreur de bit unique en utilisant une méthode simple ; ajout d’un bit de contrôle par huit bits de données. S'il détecte une erreur de bit lors de la transmission des données entre les composants matériels, le système rejette les données erronées. Les erreurs de bit unique à n’importe quel emplacement du schéma ci-dessus provoquent la réinitialisation du routeur.
Détection de parité/ECC NPE-400
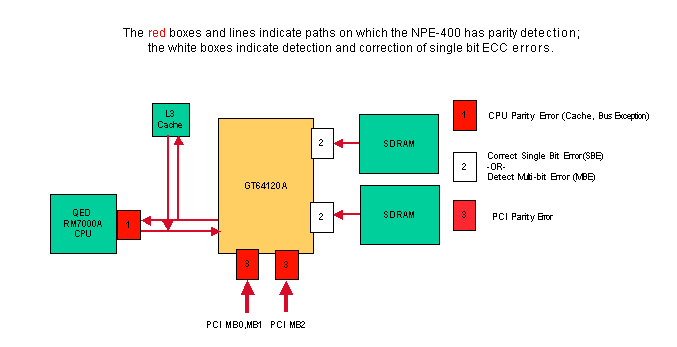
Le NPE-400 utilise la correction d'erreur à un bit et la détection d'erreur ECC (correction de code d'erreur) multibits pour la mémoire partagée (SDRAM). Pour augmenter la disponibilité du système dans le NPE-400, ECC corrige les erreurs de bit unique dans la SDRAM, afin de permettre au système de fonctionner normalement sans réinitialisation et sans temps d'arrêt. Pour plus d'informations sur la façon dont ECC améliore la disponibilité du système, reportez-vous à la page Augmenter la disponibilité du réseau.
Une erreur multibit dans SDRAM entraîne la réinitialisation du routeur avec une exception d'erreur de cache ou une erreur de bus. Le reste de la mémoire et des bus du système utilisent la détection de parité de bit unique. Les erreurs de bit unique à 1 et 3 dans le schéma ci-dessus provoquent la réinitialisation du routeur.
Erreurs de parité dans le routeur C7200
Plusieurs périphériques de contrôle de parité du routeur C7200/NPE peuvent signaler des données présentant une parité incorrecte pour toute opération de lecture ou d'écriture. Voici une description des différents messages d'erreur signalés sur un système C7200/NPE :
Erreur DRAM GT64010/GT64120
Cette erreur est signalée lorsqu'un contrôleur système GT64120 détecte une erreur de parité lors de la lecture de SDRAM :
%ERR-1GT64120 (PCI0):Fatal error, Memory parity error (external) GT=0xB4000000, cause=0x0100E283, mask=0x0ED01F00, real_cause=0x00000200 Bus_err_high=0x00000000, bus_err_low=0x00000000, addr_decode_err=0x1C000000
Remplacer la mémoire SDRAM après une deuxième défaillance. Si la défaillance persiste, remplacez le NPE.
Remarque : pour les NPE plus anciens (NPE-100/150/200) qui utilisent les contrôleurs GT64010, l'erreur ressemble à ceci :
%ERR-1-GT64010: Fatal error, Memory parity error (external) cause=0x0300E283, mask=0x0CD01F00, real_cause=0x00000200 bus_err_high=0x00000000, bus_err_low=0x00000000, addr_decode_err=0x00000000
Le contrôleur GT64010 utilise la mémoire DRAM (Dynamic RAM) et non la mémoire SDRAM. Dans ce cas, remplacez la DRAM après une deuxième défaillance. Si la défaillance persiste, remplacez le NPE.
Lecture du maître d'erreur de parité système GT64010/GT64120
Une erreur de parité dans la lecture principale est une erreur de parité déclenchée par l'accès à un pont PCI (Peripheral Component Interconnect). Voici un exemple de sortie d'erreur de parité :
%ERR-1-GT64120 (PCI0):Fatal error, Parity error on master read GT=B4000000, cause=0x0110E083, mask=0x0ED01F00, real_cause=0x00100000 Bus_err_high=0x00000000, bus_err_low=0x00000000, addr_decode_err=0x00000470 %ERR-1-SERR: PCI bus system/parity error %ERR-1-FATAL: Fatal error interrupt, No reloading Err_stat=0x81, err_enable=0xFF, mgmt_event=0x40
Remplacer le composant approprié après une deuxième défaillance. Le vidage du pont système indique le composant à remplacer.
System bridge dump:
Bridge 1, for PA bay 1, 3 and 5. Handle=1
DEC21150 bridge chip, config=0x0
(0x1C):sec status, io base =0x83A09141
Detected Parity Error on secondary bus
Data Parity Detected on secondary bus
(0x20):mem base & limit =0x4AF04880
Ces tableaux vous indiquent quel composant présente un problème possible à partir de la sortie du message d'erreur.
NPE-100/150/2000 :
| Numéro de pont | À quoi sert le pont ? | Erreur de parité sur le bus principal | Erreur de parité sur le bus secondaire |
|---|---|---|---|
| Pont 0 | Mo0 en aval vers MB1 0 | Remplacer le NPE | Remplacer NPE ; s'il est toujours présent, remplacez le châssis |
| Pont 1 | Mo1 en amont vers Mo0 | Remplacer NPE ; s'il est toujours présent, remplacez le châssis | Remplacer le NPE |
| Pont 2 | Mo0 en aval vers Mo2 | Remplacer le NPE | Remplacer NPE ; s'il est toujours présent, remplacez le châssis |
| Pont 3 | Mo2 en amont vers Mo0 | Remplacer NPE ; s'il est toujours présent, remplacez le châssis | Remplacer le NPE |
NPE-175/225/300/400/NSE-1 :
| Numéro de pont | À quoi sert le pont ? | Erreur de parité sur le bus principal | Erreur de parité sur le bus secondaire |
|---|---|---|---|
| Pont 0 | Pour la baie PA 0 (carte d'E/S, PCMCIA, interfaces | Remplacer le NPE | Remplacer NPE ; si elle est toujours présente, remplacez la carte d'E/S. S'il est toujours présent, remplacez le châssis |
| Pont 1 | Pour les baies PA 1, 3 et 5 | Remplacer le NPE | Remplacer le NPE ; s'il est toujours présent, remplacez le châssis |
| Pont 2 | Pour les baies PA 2, 4 et 6 | Remplacer le NPE | Remplacer NPE ; s'il est toujours présent, remplacez le châssis |
Tous les C7200 :
| Numéro de pont | À quoi sert le pont ? | Erreur de parité sur le bus principal | Erreur de parité sur le bus secondaire |
|---|---|---|---|
| Pont 4 | Carte de ports 1 | Remplacer NPE ; s'il est toujours présent, remplacez le châssis | Remplacer PA 1 ; s'il est toujours présent, remplacez le châssis |
| Pont 5 | Carte de ports 2 | Remplacer NPE ; s'il est toujours présent, remplacez le châssis | Remplacer PA 2 ; s'il est toujours présent, remplacez le châssis |
| Pont 6 | Carte de ports 3 | Remplacer NPE ; s'il est toujours présent, remplacez le châssis | Remplacer PA 3 ; s'il est toujours présent, remplacez le châssis |
| Pont 7 | Carte de ports 4 | Remplacer NPE ; s'il est toujours présent, remplacez le châssis | Remplacer PA 4 ; s'il est toujours présent, remplacez le châssis |
| Pont 8 | Carte de ports 5 | Remplacer NPE ; s'il est toujours présent, remplacez le châssis | Remplacer PA 5 ; s'il est toujours présent, remplacez le châssis |
| Pont 9 | Carte de ports 6 | Remplacer NPE ; s'il est toujours présent, remplacez le châssis | Remplacer PA 6 ; s'il est toujours présent, remplacez le châssis |
Erreur de parité du processeur
Comme pour tous les ordinateurs et les périphériques réseau, le NPE est susceptible d'être confronté à de rares erreurs de parité dans la mémoire du processeur. Les erreurs de parité peuvent entraîner la réinitialisation du système et peuvent être un événement unique temporaire (erreur SEU ou soft) ou se produire plusieurs fois (souvent appelé erreurs matérielles) en raison d'un matériel endommagé. Pour plus d'informations sur les SEU, reportez-vous à la page Augmenter la disponibilité du réseau. Une erreur de parité du processeur est signalée si le processeur détecte une erreur de parité lors de l'accès à l'un des caches du processeur (L1, L2 ou, s'il y en a, L3).
Voici quatre exemples de ce type d'erreur :
Exemple 1 :
Error: SysAD, data cache, fields: data, 1st dword
Physical addr(21:3) 0x195BE88,
Virtual address is imprecise.
Imprecise Data Parity Error
Imprecise Data Parity Error
Le NPE dispose d'un processeur R7K avec cache non bloquant. Cache non bloquant signifie que lorsqu'il exécute une instruction de chargement de données dans un registre et que ces données ne se trouvent pas dans le cache L1, le processeur charge les données à partir d'un cache de moindre ordre ou de données SDRAM. Le processeur ne bloque pas l'exécution d'autres instructions, sauf si une autre instruction cache est manquée ou si une autre instruction dépend des données chargées. Cela peut accélérer considérablement le processeur et améliorer les performances, mais peut également conduire à des erreurs de parité imprécises. Une erreur de parité imprécise se produit lorsque le processeur lit des informations sans blocage, puis détermine qu'il y a eu une erreur de parité dans la ligne de cache associée. Le processeur R7K ne peut pas nous dire précisément quelle instruction était exécutée lors du chargement de la ligne de cache, et c'est la raison pour laquelle nous l'appelons une erreur de parité imprécise.
Même si les systèmes utilisent la correction de code d'erreur (ECC), il est toujours possible de voir une erreur de parité occasionnelle lorsque plus d'une erreur unique s'est produite dans les 64 bits de données en raison d'une erreur grave dans le cache.
Une erreur de parité se produit lorsqu'une valeur de bit de signal est modifiée de sa valeur d'origine (0 ou 1) à la valeur opposée. Cette erreur peut se produire en raison d'une erreur de parité logicielle ou matérielle.
Des erreurs de parité logicielle se produisent en raison d'une influence externe sur la mémoire du périphérique, qui modifie la valeur du bit au niveau actuel. Ce type de problème est temporaire et ne se reproduit pas. Des erreurs de parité matérielle se produisent lorsque la valeur de bit est modifiée par la mémoire elle-même en raison d'un endommagement de la mémoire. Dans ce cas, le problème se produit chaque fois que cette zone de mémoire est utilisée, ce qui signifie que le problème peut se répéter plusieurs fois en quelques jours à une semaine.
Exemple 2 :
Error: SysAD, instr cache, fields: data, 1st dword
Physical addr(21:3) 0x000000,
virtual addr 0x6040BF60, vAddr(14:12) 0x3000
virtual address corresponds to main:text, cache word 0
Low Data High Data Par Low Data High Data Par
L1 Data: 0:0xAE620068 0x8C830000 0x00 1:0x50400001 0xAC600004 0x01
2:0xAC800000 0x00000000 0x02 3:0x1600000B 0x00000000 0x01
Low Data High Data Par Low Data High Data Par
DRAM Data: 0:0xAE620068 0x8C830000 0x00 1:0x50400001 0xAC600004 0x01
2:0xAC800000 0x00000000 0x02 3:0x1600000B 0x00000000 0x01
Exemple 3 :
Cache Err Reg = 0xE4588D10 Data reference, Secondary/Sys intf cache, Data field error Error on 1st doubleword on System interface No errors in addition to instr error Data phy addr that caused last parity or bus error: 0x1E84040C
Exemple 4 (NPE-300 et NPE-400 uniquement) :
%CERF-3-RECOVER: PC=0x604F136C, Origin=L3 Data ,PhysAddr=0x013CEFD0
ou
%SYS-2-CERF_ABORT: Reason=0xEE23, PC=0x604629C8, Origin=L3 Data, Phys Addr=0x0287A4E8
Les deux messages ci-dessus sont accompagnés d'un rapport CERF (Cache Error Recovery Function) comme suit :
CERFa[1 ] 05:25:36 MET Tue Jul 9 2002: result=0xEE23; instr_pos=-2; rpl_off=1 CERFb[1 ] PC =604629C8; ORGN=L3 Data; PRID=00002710; PHYA=0287A4E8 CERFc[1 ] SREG=3400E105; CAUS=00000400; DEA0=0287A4E8; ECC =00000000 CERFd[1 ] CERR=E447A4EA; EPC =606361F8; DEA1=02517058; INFO=00000000 CERFe[1 ] CACHE=28FF78B4 62B36D98 02020684 00000E17 00000030 00000001 61F2934C 3EDA025D CERFe[1 ] SDRAM=28FF78B4 62B36D98 02020684 00000E17 00000030 00000001 61F2934C 3EDA025D CERFg[1 ] CXT =00000000; XCXT=00000000; BVAD=00000008; PFCL=00000000 CERFh[1 ] ISeq: 0045182B; 1060000E; 2C4203E9; 92430028; 38420001; 30630005 CERFi[1 ] o0 $3 ....; beq....; sltiu $2 ....; lbu $3, 0x0028($18); xori $2....; andi $3 ....;* CERFj[1 ] ; ; ; 6287A4E8; ; ; CERFk[1 ] ResumptionCode= 0x92430028; 0x0000000F; 0x42000018 CERFl[1 ] Instr's checked=4; diags=0x00000158,0x00040000,3600,1,0 CERFm[1 ] BaseRegLost later/off: 0/0 times; StoredValueLost: 0 times CERFn[1 ] INFO=00000000; CNFG=5061F4BB; ICTL=00000000 Initial Register Values CERFs00[1 ] $0=00000000 AT=61A30000 v0=00000001 v1=00000002 CERFs04[1 ] a0=28FF8728 a1=00003A98 a2=00000000 a3=00000007 CERFs08[1 ] t0=00000000 t1=3400E101 t2=606381E0 t3=FFFF00FF CERFs12[1 ] t4=606381C8 t5=000005D4 t6=00000008 t7=61C50000 CERFs16[1 ] s0=6189C188 s1=00000000 s2=6287A4C0 s3=00003A98 CERFs20[1 ] s4=61BD57B0 s5=00000006 s6=00000000 s7=61BD6C60 CERFs24[1 ] t8=60634788 t9=00000000 k0=621A8374 k1=6063EA40 CERFs28[1 ] gp=61A33B20 sp=61E28678 s8=00000000 ra=60462CA4 1 Cache error exceptions already reported
Les journaux ci-dessus s'affichent si le CERF est activé sur un NPE-300 ou un NPE-400 et qu'une erreur de parité se produit. Pour plus d'informations sur le CERF, reportez-vous à la section Solutions ci-dessous.
Solutions
La procédure suivante est recommandée lorsque vous rencontrez de telles erreurs :
-
Surveillez le matériel affecté pour voir si le même problème se reproduit. Si ce n'est pas le cas, il s'agissait alors d'un événement SEU (Single Event Upset) transitoire et vous n'avez pas besoin d'agir.
-
Dans le cas peu probable où le problème se reproduirait, la commande de contournement/désactivation de la couche 3 du cache est une option qui peut aider à réduire l'impact du problème. Cette commande n'est disponible que sur les plates-formes suivantes :
-
7200 avec moteur processeur NPE-300, NPE-400 ou NSE-1
-
7400 avec moteur processeur NSE-1
Comme le NPE-300 ne prend pas en charge la mémoire ECC, cette fonctionnalité est particulièrement importante pour augmenter la disponibilité du système et gérer ces erreurs de parité sans interruption de service. Cela résout de nombreuses erreurs de parité logicielle. La mise en garde est qu'il y a un léger impact sur les performances du système lorsque le cache de couche 3 est désactivé. La dégradation des performances se situe entre 1 % et 10 % selon la configuration du système. La syntaxe de cette commande dépend de la version du logiciel Cisco IOS.
-
La commande cache L3 disable se trouve dans le logiciel Cisco IOS Versions 12.3(5a) et ultérieures. Il sera également disponible en version 12.1(22)E. Dans ces versions, le cache de couche 3 est désactivé par défaut. Aucune action n'est donc nécessaire pour tirer parti de cette fonctionnalité. Le cache L3 peut être réactivé avec la commande no cache L3 disable.
-
La commande cache de contournement de couche 3 se trouve dans les versions 12.2(6)S, 12.2(6)B, 12.2(8)BC1b, 12.0(20)SP, 12.2(6)PB, 12.2(2)DD2, 12.0(20)ST3 12.0(21)S, 12.1(11)EC, 12.2(7)T, 12.1(13) et 12.2(7) ou ultérieur, et 12.1(11)E à 12.1(21)E. Cette commande est désactivée par défaut.
Pour activer le contournement du cache de couche 3, entrez ce qui suit en mode de configuration :
Router(config)#cache L3 bypass
Pour désactiver le contournement du cache de couche 3, passez en mode de configuration :
Router(config)#no cache L3 bypass
Le nouveau paramètre de cache ne prend effet que lorsque le routeur est rechargé.
Lorsque le routeur démarre, les informations système s'affichent, y compris les informations sur le cache L3. Ceci est dû au fait que le fichier startup-config n'a pas encore été traité par le système. Une fois le fichier startup-config traité, le cache L3 est ignoré si la commande cache L3 bypass figure dans la configuration.
Pour vérifier le paramètre du cache de couche 3, vous pouvez émettre la commande show version. Si le cache de couche 3 est ignoré, il n'y a aucune référence au cache de couche 3 dans la sortie show version.
-
-
Une autre fonctionnalité qui contribue à augmenter la disponibilité du système est la fonction de récupération des erreurs de cache (CERF). Lorsque cette fonctionnalité est activée (par défaut dans les dernières versions du logiciel Cisco IOS, mais à partir de février 2004, uniquement pour les NPE-300 et NPE-400), le logiciel Cisco IOS tente de résoudre l'erreur de parité et d'empêcher le processeur de s'écraser. Cette fonctionnalité résout environ 75 % de certains types d'erreurs de parité logicielle. En appelant cette commande, le système voit une dégradation des performances inférieure à 5 %.
Le CERF du NPE-300 se trouve dans les versions du logiciel Cisco IOS 12.1(15), 12.1(12)EC, 12.0(22)S, 12.2(10)S, 12.2(10)T, 12.2(10), 12.2(2)2 B4, 12.2(11)BC1b et 12.1(5)XM8 ou ultérieur.
Le CERF pour le NPE-400 se trouve dans les versions 12.3(3)B, 12.2(14)S3, 12.1(20)E, 12.1(19)E1, 12.3(1a), 12.2(13)T5, 12.2(18)S, 2.3(2)T, 12.2(18), 12.3(3) et 12.3(1)B1 ou ultérieur.
Le CERF pour le NPE-300 nécessite une révision matérielle 4.1 ou supérieure. Afin d'identifier la version matérielle de votre NPE-300, utilisez la commande show c7200.
Router>show c7200 ... C7206VXR CPU EEPROM: Hardware revision 4.1 Board revision A0 ...
Le CERF pour le NPE-400 nécessite le processeur R7K version 2.1 ou ultérieure. Afin d'identifier la révision du processeur de votre NPE-400, utilisez la commande show version.
Router>show version ... cisco 7206VXR (NPE400) processor with 491520K/32768K bytes of memory. R7000 CPU at 350Mhz, Implementation 39, Rev 3.2, 256KB L2, 4096KB L3 Cache 6 slot VXR midplane, Version 2.1 ...
Remarque : Il est important de collecter tous les fichiers crashinfo pertinents afin de déterminer la cause première de l'erreur, comme expliqué dans la section Récupération des informations du fichier Crashinfo.
Si les suggestions ci-dessus ne résolvent pas le problème, le remplacement du NPE peut être utile en cas d'occurrences répétées d'erreurs de parité, car les erreurs de parité matérielle sont dues à un matériel endommagé. Les remplacements matériels sont identiques au NPE d'origine. Le remplacement du NPE ne garantit pas qu'aucune autre erreur de parité ne se produira puisque les SEU (Single Event Upsets) sont inhérents à tout équipement informatique doté de mémoire.
Informations connexes
Historique de révision
| Révision | Date de publication | Commentaires |
|---|---|---|
1.0 |
13-Apr-2009 |
Première publication |
 Commentaires
CommentairesContacter Cisco
- Ouvrir un dossier d’assistance

- (Un contrat de service de Cisco est requis)