Hadoop as a Service (HaaS) with Cisco UCS Common Platform Architecture (CPA v2) for Big Data and OpenStack
Available Languages
Table of Contents
About Cisco Validated Design (CVD) Program Hortonworks Data Platform (HDP 2.0)
Hortonworks: Key Features and Benefits
Canonical Ubuntu 12.04 LTS Release
Canonical Ubuntu OpenStack Architecture benefits
Hadoop as a Service (HaaS) Architecture Overview
Server Configuration and Cabling
Software Distributions and Versions
Hortonworks Data Platform (HDP 2.0)
Canonical Ubuntu 12.04 LTS Release
Performing Initial Setup of Cisco UCS 6296 Fabric Interconnects
Upgrading UCS Manager Software to Version 2.2(1b)
Adding Block of IP Addresses for KVM Access
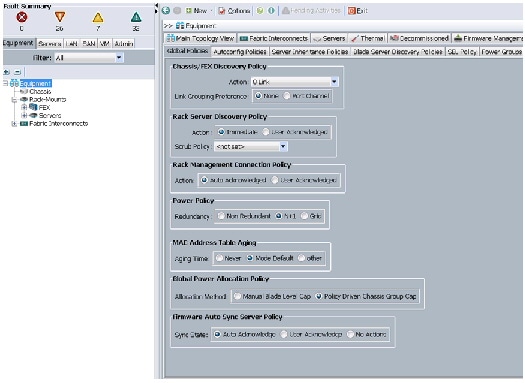
Editing Chassis/FEX Discovery Policy
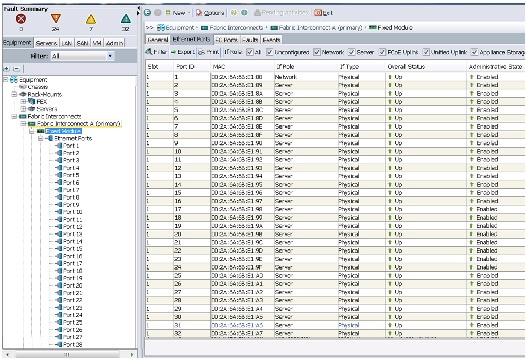
Enabling Server Ports and Uplink Ports
Creating Pools for Service Profile Templates
Creating Policies for Service Profile Templates
Creating Host Firmware Package Policy
Creating Local Disk Configuration Policy
Creating Service Profile Template
Configuring Network Settings for the Template
Configuring Storage Policy for the Template
Configuring vNIC/vHBA Placement for the Template
Configuring Server Boot Order for the Template
Configuring Server Assignment for the Template
Configuring Operational Policies for the Template
Creating Service Profiles from Templates
Configuring Nytro Flash on all node for installing OS
Configuring Disk Drives on all nodes
Installing Ubuntu Server 12.04.4 LTS with KVM
Install MySQL Server on the Controller Node
Install MySql Client on all the Other Nodes
OpenStack Repository - Ubuntu Cloud Archive for Havana
Install Apache on the Controller Node
Canonical Ubuntu OpenStack Havana Software Components
Installing Havana OpenStack Services
Define Users, Tenants, and Roles
Define services and API endpoints
Verify the Identity Service installation
Verify the Image Service installation
Install Compute controller services
Enable Networking (nova-networking)
Allocated floating-ips to the VMs
Pre-config of VM cluster for HDP Installation
Setting Up XFS Filesystem Master Nodes
Setting Up Password-less Login within VMs
HDP 2.0 Repo for Ubuntu on all VMs
Fully Qualified domain name (FQDN)
Install MySQL (resourcemanager VM)
Role Assignment – Masters/Slaves
Create the NameNode Directories
Create the SecondaryNameNode Directories
Create DataNode and YARN NodeManager Local Directories
Create the Log and PID Directories
Determine YARN and MapReduce Memory Configuration Settings
Set Default File and Directory Permissions
Validating the Core Hadoop Installation
Start MapReduce JobHistory Server
Installing HBase and Zookeeper
Create the Hbase Log and PID Directories
Create the Zookeeper Data and Pid Directories
Set Up the Configuration Files for Zookeeper and Hbase
Installing Apache Hive/HCatalog
About Cisco Validated Design (CVD) Program
The CVD program consists of systems and solutions designed, tested, and documented to facilitate faster, more reliable, and more predictable customer deployments. For more information visit: http://www.cisco.com/go/designzone .
ALL DESIGNS, SPECIFICATIONS, STATEMENTS, INFORMATION, AND RECOMMENDATIONS (COLLECTIVELY, "DESIGNS") IN THIS MANUAL ARE PRESENTED "AS IS," WITH ALL FAULTS. CISCO AND ITS SUPPLIERS DISCLAIM ALL WARRANTIES, INCLUDING, WITHOUT LIMITATION, THE WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT OR ARISING FROM A COURSE OF DEALING, USAGE, OR TRADE PRACTICE. IN NO EVENT SHALL CISCO OR ITS SUPPLIERS BE LIABLE FOR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, OR INCIDENTAL DAMAGES, INCLUDING, WITHOUT LIMITATION, LOST PROFITS OR LOSS OR DAMAGE TO DATA ARISING OUT OF THE USE OR INABILITY TO USE THE DESIGNS, EVEN IF CISCO OR ITS SUPPLIERS HAVE BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
THE DESIGNS ARE SUBJECT TO CHANGE WITHOUT NOTICE. USERS ARE SOLELY RESPONSIBLE FOR THEIR APPLICATION OF THE DESIGNS. THE DESIGNS DO NOT CONSTITUTE THE TECHNICAL OR OTHER PROFESSIONAL ADVICE OF CISCO, ITS SUPPLIERS OR PARTNERS. USERS SHOULD CONSULT THEIR OWN TECHNICAL ADVISORS BEFORE IMPLEMENTING THE DESIGNS. RESULTS MAY VARY DEPENDING ON FACTORS NOT TESTED BY CISCO.
The Cisco implementation of TCP header compression is an adaptation of a program developed by the University of California, Berkeley (UCB) as part of UCB’s public domain version of the UNIX operating system. All rights reserved. Copyright © 1981, Regents of the University of California.
Cisco and the Cisco logo are trademarks or registered trademarks of Cisco and/or its affiliates in the U.S. and other countries. To view a list of Cisco trademarks, go to this URL: http://www.cisco.com/go/trademarks . Third-party trademarks mentioned are the property of their respective owners. The use of the word partner does not imply a partnership relationship between Cisco and any other company. (1110R).
Any Internet Protocol (IP) addresses and phone numbers used in this document are not intended to be actual addresses and phone numbers. Any examples, command display output, network topology diagrams, and other figures included in the document are shown for illustrative purposes only. Any use of actual IP addresses or phone numbers in illustrative content is unintentional and coincidental.
© 2014 Cisco Systems, Inc. All rights reserved.
Acknowledgment
The authors acknowledge Ashwin Manjunatha, Ajay Singh, Mehul Bhatt, Samantha Jian-Pielak, Marc Solanas Tarre, Debo Dutta and Sindhu Sudhir for their contributions in developing this document.
Hadoop as a Service (HaaS) with Cisco UCS Common Platform Architecture (CPA v2) for Big Data and OpenStack
Introduction
Hadoop has become a strategic data platform embraced by mainstream enterprises as it offers a path for businesses to unlock value in big data while maximizing existing investments. The Hortonworks Data Platform 2.0 (HDP 2.0) is a 100% open source distribution of Apache Hadoop that is built, tested and hardened with enterprise rigor. The combination of HDP and Cisco UCS provides an industry-leading platform for Hadoop based application deployments. Hadoop as a Service is new to the industry but is gaining traction in many Service Providers and IT Organizations. This CVD focuses on setting up OpenStack on Ubuntu to deploy and manage Hadoop as a Service on Cisco UCS Common Platform Architecture version 2 (CPA v2).
Audience
This document describes the architecture and deployment procedures of Hadoop as a Service (HaaS) with OpenStack and Hortonworks Data Platform 2.0 (HDP 2.0) for Hadoop on a 64-node cluster based on CPA v2 for Big Data. The intended audience of this document include, but is not limited to, sales engineers, field consultants, professional services, IT managers, partner engineering and customers who want to deploy Hadoop as a Service with HDP 2.0 on Cisco UCS CPA v2 for Big Data.
Big Data
The Cisco UCS solution for HDP 2.0 is based on CPA v2 for Big Data, is a highly scalable architecture designed to meet a variety of scale-out application demands with seamless data integration and management integration capabilities built using the following components:
- Cisco UCS 6200 Series Fabric Interconnects —provide high-bandwidth, low-latency connectivity for servers, with integrated, unified management provided for all connected devices by Cisco UCS Manager. Deployed in redundant pairs, Cisco fabric interconnects offer the full active-active redundancy, performance, and exceptional scalability needed to support the large number of nodes that are typical in clusters serving big data applications. Cisco UCS Manger enables rapid and consistent server configuration using service profiles, automating ongoing system maintenance activities such as firmware updates across the entire cluster as a single operation. Cisco UCS Manager also offers advanced monitoring with options to raise alarms and send notifications about the health of the entire cluster.
- Cisco UCS 2200 Series Fabric Extenders —extend the network into each rack, acting as remote line cards for fabric interconnects and providing highly scalable and extremely cost-effective connectivity for a large number of nodes.
- Cisco UCS C-Series Rack Mount Servers —are 2-socket servers based on Intel Xeon E-2600 v2 series processors and supporting up to 768GB of main memory. 24 Small Form Factor (SFF) disk drives are supported in performance optimized option and 12 Large Form Factor (LFF) disk drives are supported in capacity option, along with 4 Gigabit Ethernet LAN-on-motherboard (LOM) ports.
- Cisco UCS Virtual Interface Cards (VICs) —unique to Cisco, Cisco UCS Virtual Interface Cards incorporate next-generation converged network adapter (CNA) technology from Cisco, and offer dual 10Gbps ports designed for use with Cisco UCS C-Series Rack-Mount Servers. Optimized for virtualized networking, these cards deliver high performance and bandwidth utilization and support up to 256 virtual devices.
- Cisco UCS Manager —resides within the Cisco UCS 6200 Series Fabric Interconnects. It makes the system self-aware and self-integrating, managing all of the system components as a single logical entity. Cisco UCS Manager can be accessed through an intuitive graphical user interface (GUI), a command-line interface (CLI), or an XML application-programming interface (API). Cisco UCS Manager uses service profiles to define the personality, configuration, and connectivity of all resources within Cisco UCS, radically simplifying provisioning of resources so that the process takes minutes instead of days. This simplification allows IT departments to shift their focus from constant maintenance to strategic business initiatives.
Hortonworks Data Platform (HDP 2.0)
Apache Hadoop is an open-source software framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. The Hortonworks Data Platform2.0 (HDP 2.0) is an enterprise-grade, Apache Hadoop distribution that enables storing, processing, and managing large data sets. The HDP 2.0 combines Apache Hadoop and it’s related projects into a single tested and certified package.
Hortonworks: Key Features and Benefits
With HDP 2.0, enterprises can retain and process large amounts of data, join new and existing data sets, and lower the cost of data analysis compared to traditional solutions. Hortonworks enables enterprises to implement the following data management principles:
- Retain as much data as possible. Traditional data warehouses age, and over time will eventually store only summary data. Analyzing detailed records is often critical to uncovering useful business insights.
- Join new and existing data sets. Enterprises can build large-scale environments for transactional data with analytic databases, but these solutions are not always well suited to processing nontraditional data sets such as text, images, machine data, and online data. Hortonworks enables enterprises to incorporate both structured and unstructured data in one comprehensive data management system.
- Archive data at low cost. It is not always clear what portion of stored data will be of value for future analysis. Therefore, it can be difficult to justify expensive processes to capture, cleanse, and store that data. Hadoop scales easily, so you can store years of data without much incremental cost, and find deeper patterns that your competitors may miss.
- Access all data efficiently. Data needs to be readily accessible. Apache Hadoop clusters can provide a low-cost solution for storing massive data sets while still making the information readily available. Hadoop is designed to efficiently scan all of the data, which is complimentary to databases that are efficient at finding subsets of data.
- Apply data cleansing and data cataloging. Categorize and label all data in Hadoop with enough descriptive information (metadata) to make sense of it later, and to enable integration with transactional databases and analytic tools. This greatly reduces the time and effort of integrating with other data sets, and avoids a scenario in which valuable data is eventually rendered useless.
- Integrate with existing platforms and applications. There are many business intelligence (BI) and analytic tools available, but they may not be compatible with your particular data warehouse or DBMS. Hortonworks connects seamlessly with many leading analytic, data integration, and database management tools.
The HDP 2.0 is the foundation for the next-generation enterprise data architecture – one that addresses both the volume and complexity of today’s data.
Canonical Ubuntu 12.04 LTS Release
Also known by its code name “Precise Pangolin”, Ubuntu 12.04 is a Long Term Support (LTS) release from Canonical. The support for Ubuntu 12.04 is expected to continue till April 2017, hence providing a long term robust support framework for customers. For open source projects, support is a crucial component, and Canonical provides enterprise level scale, stability and support for underlying Operating System as well as OpenStack components for cloud deployment on Ubuntu.
Canonical Ubuntu OpenStack Architecture benefits
Canonical OpenStack Platform on Canonical Ubuntu 12.04 provides the foundation to build a private or public Infrastructure as a Service (IaaS) for cloud-enabled workloads. It allows organizations to leverage OpenStack, the largest and fastest growing open source cloud infrastructure project, while maintaining the security, stability, and enterprise readiness of a platform built on Canonical Ubuntu 12.04.
Canonical Ubuntu OpenStack Platform gives organizations a open framework for hosting cloud workloads. In conjunction with other Ubuntu technologies, Canonical Ubuntu OpenStack Platform allows organizations to move from traditional workloads to cloud-enabled workloads on their own terms and timelines, as their applications require.
Canonical Ubuntu OpenStack Platform provides a certified ecosystem of hardware, software, and services, an enterprise lifecycle that extends the community OpenStack release cycle, and Canonical support on both the OpenStack modules and their underlying Linux dependencies.
Hadoop as a Service (HaaS) Architecture Overview
The Architecture for Hadoop as a Service is outlined in this section.
Canonical Ubuntu 12.04 LTS is both the host OS and guest OS on top of OpenStack. the tested configuration is based on Cisco UCS CPA v2 for Big Data optimized for Capacity with Flash Memory. http://www.cisco.com/c/dam/en/us/solutions/collateral/borderless-networks/advanced-services/common_platform_architecture.pdf . OpenStack release used for this solution is Havana. OpenStack components used are Keystone for Identity Service, Glance for VM Image service, Nova for compute (nova-compute uses KVM as the hypervisor), Storage is ephemeral (storage that is local to the VM and is deleted when the VM is terminated), networking is nova-network, which is a FlatNetwork and Horizon is used for OpenStack dashboard. Hortonworks 2.0 is installed manually on the guest VMs.

Note
This CVD goes with Ephemeral storage for data storage. One of the reasons to go with Ephemeral as storage was to have compute local to storage as this is fundamental to Hadoop, else this would cause unwanted network traffic slowing the performance. Data redundancy is managed inherently by HDFS (Hadoop Filesystem). There are other solutions on top of OpenStack, which can provide storage to be local to compute or provide an alternate to HDFS with hooks to Hadoop MapReduce which are beyond the scope of this CVD. This CVD goes with Ephemeral storage for data storage. One of the reasons to go with Ephemeral as storage was to have compute local to storage as this is fundamental to Hadoop, else this would cause unwanted network traffic slowing the performance. Data redundancy is managed inherently by HDFS (Hadoop Filesystem). There are other solutions on top of OpenStack, which can provide storage to be local to compute or provide an alternate to HDFS with hooks to Hadoop MapReduce which are beyond the scope of this CVD.
OpenStack and Hadoop Layout
Of the 64 nodes (physical servers), one of the node is going to be Controller node for OpenStack (A controller node basically runs all services necessary to manage compute nodes which host VMs. Compute nodes run only minimal services and refer to Controller node for all querying and managing VM lifecycle within the individual servers. Typically a controller node does not host VMs. In other words, controller node does not run nova-compute; however, in this architecture Hadoop Namenode is run as a Single VM on the controller node. Hence, to run this single VM we need to run nova-compute services on controller node as well.
In order to host Hadoop Master services (namely Namenode and Resource Manager), two nodes run single VM to host Hadoop Namenode and Hadoop Resource Manager/Secondary Namenode (and other Master services discussed later). All other compute nodes host multiple VMs which will be used for data and tasks.
Note
Solution Overview
The current version of the Cisco UCS CPA v2 for Big Data offers the following configuration depending on the compute and storage requirements:
Note
The Capacity Optimized with Flash memory cluster configuration consists of the following:
Rack and PDU Configuration
Each rack consists of two vertical PDUs. The master rack consists of two Cisco UCS 6296UP Fabric Interconnects, two Cisco Nexus 2232PP Fabric Extenders and sixteen Cisco UCS C240M3 Servers, connected to each of the vertical PDUs for redundancy; thereby, ensuring availability during power source failure. The expansion racks consists of two Cisco Nexus 2232PP Fabric Extenders and sixteen Cisco UCS C240M3 Servers are connected to each of the vertical PDUs for redundancy; thereby, ensuring availability during power source failure, similar to the master rack.
Note
Table 2 and Table 3 describe the rack configurations of rack 1 (master rack) and racks 2-4 (expansion racks).
Server Configuration and Cabling
This CVD focuses on the architecture for Canonical Ubuntu OpenStack on UCS platform using Cisco UCS C-Series Servers for both compute and storage. Cisco UCS C240 M3 servers are used as compute, storage and controller nodes (from OpenStack perspective). UCS C-Series Servers are managed by UCS Manager, which provides ease of infrastructure management, and built-in network high availability.
The C240 M3 rack server is equipped with Intel Xeon E5-2660 v2 processors, 256GB of memory, Cisco UCS Virtual Interface Card 1225, Cisco LSI Nytro MegaRAID 8110-4i with 200GB Flash storage controller and 12 x 4TB 7.2K SATA disk drives.
Figure 1 illustrates the ports on the Cisco Nexus 2232PP Fabric Extender connecting to the Cisco UCS C240 M3 Servers. Sixteen Cisco UCS C240 M3 servers are used in Master rack configurations.
Figure 1 Topology Diagram of Cisco UCS C240 M3 Server
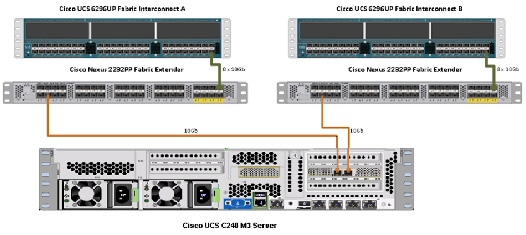
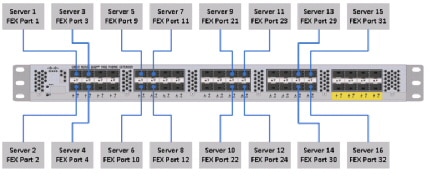
Figure 2 illustrates the port connectivity between the Cisco Nexus 2232PP fabric extender and Cisco UCS C240M3 server.
Figure 2 Connectivity Diagram of Cisco Nexus 2232PP FEX and Cisco UCS C240 M3 Servers
For more information on physical connectivity and single-wire management see:
http://www.cisco.com/en/US/docs/unified_computing/ucs/c-series_integration/ucsm2.1/b_UCSM2-1_C-Integration_chapter_010.html
For more information on physical connectivity illustrations and cluster setup, see:
http://www.cisco.com/en/US/docs/unified_computing/ucs/c-series_integration/ucsm2.1/b_UCSM2-1_C-Integration_chapter_010.html#reference_FE5B914256CB4C47B30287D2F9CE3597
Figure 3 depicts a 64 node cluster. Each link in the figure represents 8 x 10 Gigabit links.
Figure 3 64 Node Cluster Configuration

Software Distributions and Versions
The software distributions required versions are listed below.
Hortonworks Data Platform (HDP 2.0)
The Hortonworks Data Platform supported is HDP 2.0. For more information visit http://www.hortonworks.com
Canonical Ubuntu 12.04 LTS Release
The operating system supported is Ubuntu 12.04.4 Server. For more information visit http://www.ubuntu.com
Software Versions
The software versions tested and validated in this document are listed in Table 4 .
Note
Fabric Configuration
This section provides details for configuring a fully redundant, highly available Cisco UCS 6296 fabric configuration.
1.
Initial setup of the Fabric Interconnect A and B.
2.
4.
5.
6.
7.
Note
Performing Initial Setup of Cisco UCS 6296 Fabric Interconnects
This section describes the steps to perform initial setup of the Cisco UCS 6296 Fabric Interconnects A and B.
Configure Fabric Interconnect A
Follow these steps to configure Fabric Interconnect A:
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
Configure Fabric Interconnect B
Follow these steps to configure Fabric Interconnect B:
1.
2.
3.
4.
5.
6.
7.
For more information on configuring Cisco UCS 6200 Series Fabric Interconnect, see:
http://www.cisco.com/en/US/docs/unified_computing/ucs/sw/gui/config/guide/2.0/b_UCSM_GUI_Configuration_Guide_2_0_chapter_0100.html
Logging Into Cisco UCS Manager
Follow these steps to login to Cisco UCS Manager.
Open a Web browser and navigate to the Cisco UCS 6296 Fabric Interconnect cluster address.
Click the Launch link to download the Cisco UCS Manager software.
If prompted to accept security certificates, accept as necessary.
When prompted, enter admin for the username and enter the administrative password.
Upgrading UCS Manager Software to Version 2.2(1b)
This document assumes the use of UCS 2.2(1b). Make sure you have upgraded the Cisco UCS Manager software and Cisco UCS 6296UP Fabric Interconnect to version 2.2(1b)
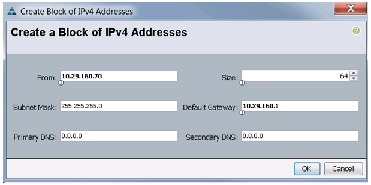
Adding Block of IP Addresses for KVM Access
The procedure discussed here provides you the details for creating a block of KVM IP addresses for server access in the Cisco UCS environment.
Follow these steps to create a block of IP addresses:
1.
2.
3.
4.
Figure 4 Adding a Block of IPv4 Addresses for KVM Access - Part 1
5.
Figure 5 Adding Block of IPv4 Addresses for KVM Access - Part 2
6.
7.
Figure 6 Adding Block of IPv4 Addresses for KVM Access - Part 3
Editing Chassis/FEX Discovery Policy
The procedure discussed here provides you the details for modifying the chassis discovery policy. Setting the discovery policy now will simplify server for the future B-Series UCS Chassis and additional Cisco UCS Fabric Extenders for further C-Series connectivity.
Follow these steps to edit the Chassis Discovery Policy:
1.
2.
3.
4.
Figure 7 Chassis/FEX Discovery Policy
Enabling Server Ports and Uplink Ports
The procedure discussed here provides you the details for enabling server and uplinks ports.
Follow these steps to enable server ports and uplink ports:
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
Figure 8 Enabling Server Ports

Figure 9 Showing Servers and Uplink Ports
Creating Pools for Service Profile Templates
The procedure discussed in this section provides you the details for creating Organizations, pools, and VLAN configuration for Service profile Templates.
Creating an Organization
Organizations are used as a means to arrange and restrict access to various groups within the IT organization, thereby enabling multi-tenancy of the compute resources. This document does not assume the use of Organizations; however, the necessary steps are provided for future reference.
Follow these steps to configure an organization within the Cisco UCS Manager:
1.
2.
3.
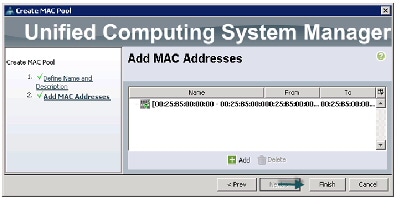
Creating MAC Address Pools
Follow these steps to create MAC address pools:
1.
3.
4.
5.
8.
9.
Figure 10 Specifying first MAC Address and Size
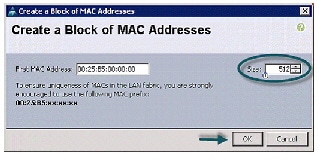
Figure 11 Adding MAC Addresses
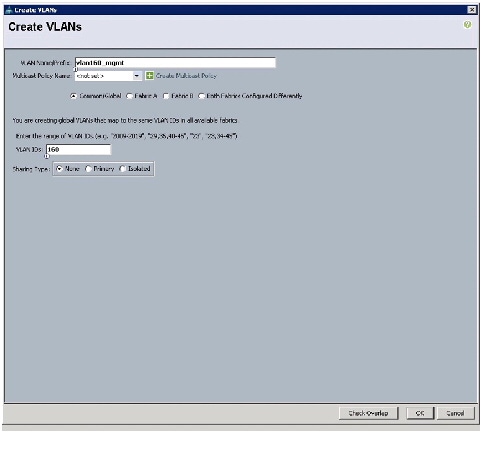
Configuring VLANs
VLANs are configured as in shown in Table 5 .
All of the VLANs created need to be trunked to the upstream distribution switch connecting the fabric interconnects. For this deployment vlan160_mgmt is configured for management access and user connectivity, vlan12_HDFS is configured for Hadoop interconnect traffic.
Follow these steps to configure VLANs in the Cisco UCS Manager:
1.
3.
4.

5.
6.
7.
8.
9.
Figure 13 Creating Management VLAN
10.
12.
13.
14.
15.
16.
17.
Figure 14 Creating VLAN for Hadoop Data

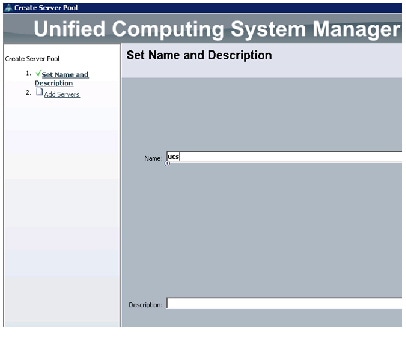
Creating Server Pool
A server pool contains a set of servers. These servers typically share the same characteristics in terms of location in the chassis, server type, amount of memory, local storage, type of CPU, or local drive configuration. You can manually assign a server to a server pool, or use server pool policies and server pool policy qualifications to automate the assignment.
Follow these steps to configure the server pool within the Cisco UCS Manager:
1.
3.
5.
6.
7.
Figure 15 Setting Name and Description of the Server Pool
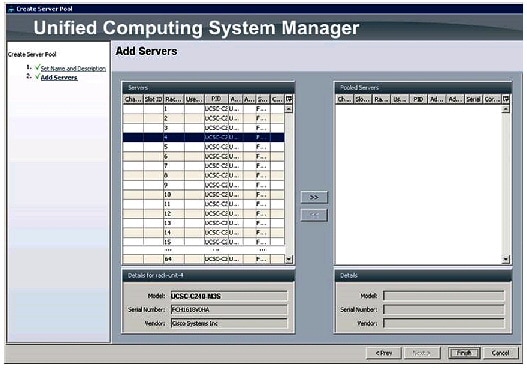
8.
10.
Figure 16 Adding Servers to the Server Pool
Creating Policies for Service Profile Templates
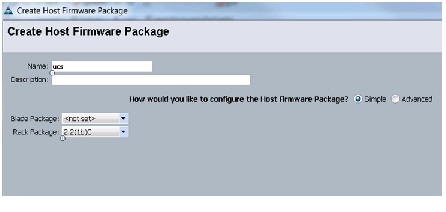
Creating Host Firmware Package Policy
Firmware management policies allow the administrator to select the corresponding packages for a given server configuration. These include adapters, BIOS, board controllers, FC adapters, HBA options, ROM and storage controller properties as applicable.
Follow these steps to create a firmware management policy for a given server configuration using the Cisco UCS Manager:
1.
3.
4.
5.
6.
7.
8.
Figure 17 Creating Host Firmware Package
Creating QoS Policies
Follow these steps to create the QoS policy for a given server configuration using the Cisco
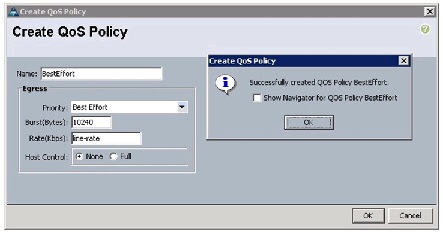
Best Effort Policy
Follow these steps for setting the best effort policy:
1.
3.
5.
6.
7.
8.
9.
10.
Figure 19 Creating BestEffort QoS Policy
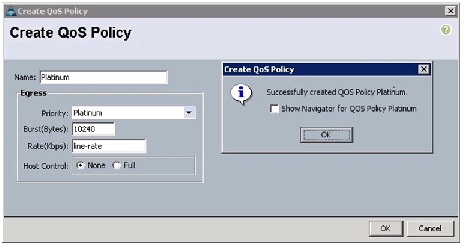
Platinum Policy
Follow these steps for setting platinum policy:
1.
3.
5.
6.
7.
8.
9.
10.
Figure 20 Creating Platinum QoS Policy
Setting Jumbo Frames
Follow these steps for setting Jumbo frames and enabling QoS:
1.
2.
3.
4.
5.
6.
7.
Figure 21 Setting Jumbo Frames

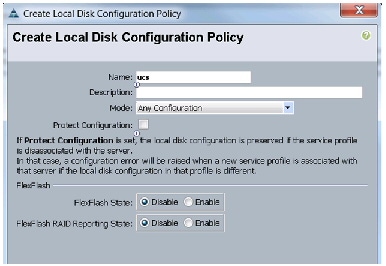
Creating Local Disk Configuration Policy
Follow these steps to create local disk configuration in the Cisco UCS Manager:
1.
3.
4.
5.
6.
7.
8.
9.
Figure 22 Configuring Local Disk Policy
Creating Server BIOS Policy
The BIOS policy feature in Cisco UCS automates the BIOS configuration process. The traditional method of setting the BIOS is done manually and is often error-prone. By creating a BIOS policy and assigning the policy to a server or group of servers, you can enable transparency within the BIOS settings configuration.
BIOS settings can have a significant performance impact, depending on the workload and the applications. The BIOS settings listed in this section is for configurations optimized for best performance which can be adjusted based on the application, performance and energy efficiency requirements.
Follow these steps to create a server BIOS policy using the Cisco UCS Manager:
1.
3.
5.
6.
Figure 23 Creating Server BIOS Policy
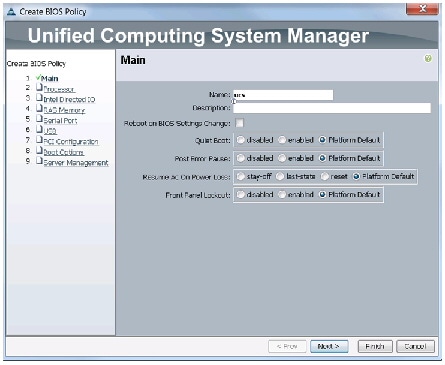
Figure 24 Creating Server BIOS Policy for Processor
Figure 25 Creating Server BIOS Policy for Intel Directed IO
Click Finish to complete creating the BIOS policy.
Figure 26 Creating Server BIOS Policy for Memory
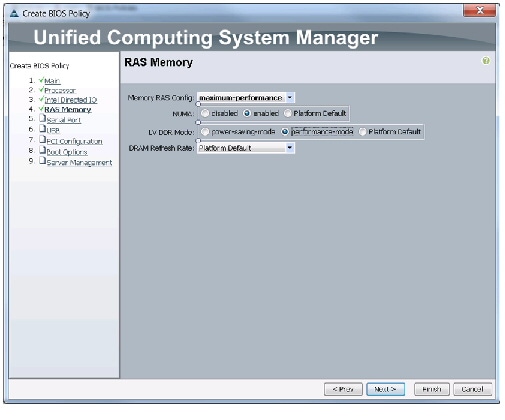
Creating Boot Policy
Follow these steps to create boot policies within the Cisco UCS Manager:
1.
3.
Figure 27 Creating Boot Policy - Part 1
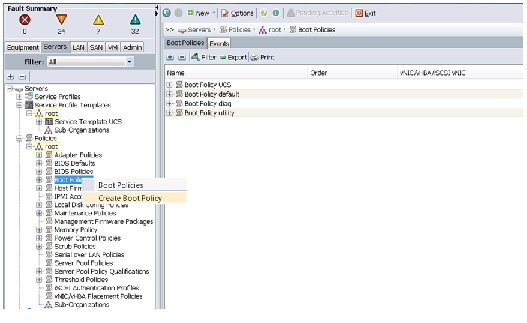
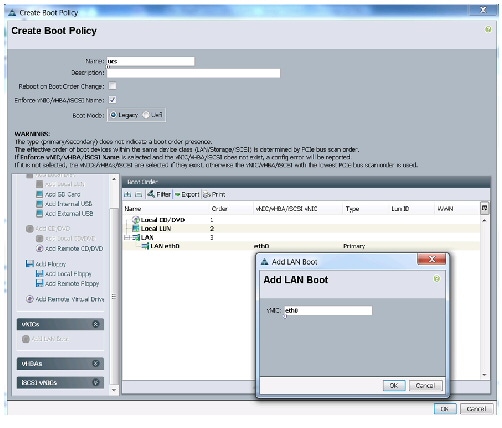
5.
6.
7.
8.
9.
10.
11.
12.
13.
Figure 28 Creating Boot Policy - Part 2
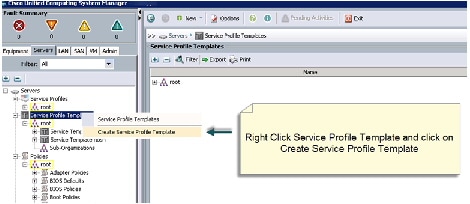
Creating Service Profile Template
To create a service profile template, follow these steps:
1.
2.
3.
Figure 29 Creating Service Profile Template
4.
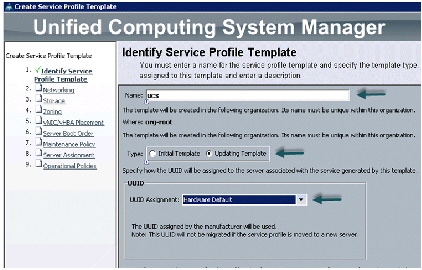
The following steps provide a detailed configuration procedure to identify the service profile template:
a.
b.
c.
Figure 30 Creating Service Profile Template - Identify
Configuring Network Settings for the Template
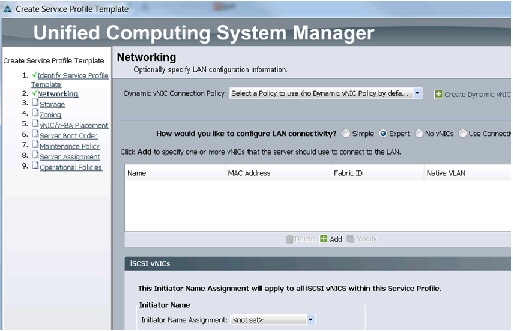
For network setting, follow these steps:
1.
2.
3.
Figure 31 Creating Service Profile Template - Networking
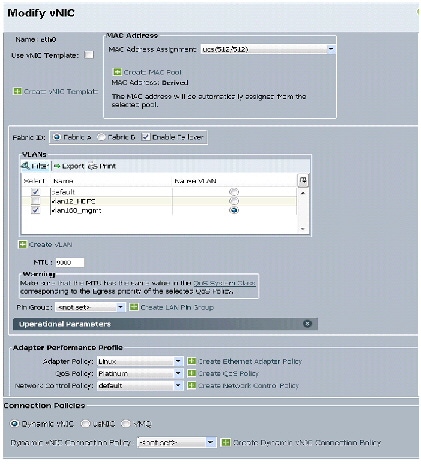
4.
5.
6.
7.
9.
10.
11.
12.
13.
Figure 32 Configuring vNIC eth0
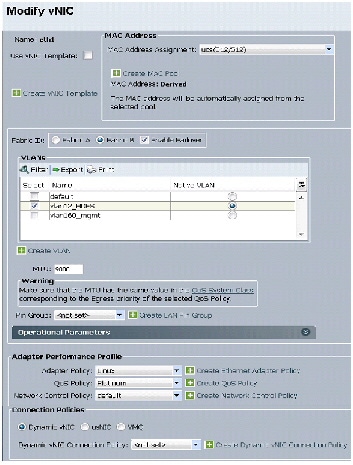
15.
16.
17.
18.
20.
21.
22.
23.
24.
Figure 33 Configuring vNIC eth1
Configuring Storage Policy for the Template
For configuring storage policy, follow these steps:
1.
2.
3.
Figure 34 Creating Service Profile Template - Storage
4.
Figure 35 Creating Service Profile Template - Zoning
C onfiguring vNIC/vHBA Placement for the Template
For configuring vNIC/vHBA placement policy, follow these steps:
1.
2.
3.
4.
Figure 36 Creating Service Profile Template - vNIC/vHBA Placement
Configuring Server Boot Order for the Template
For setting the server boot order, follow these steps:
1.
2.
3.
4.
6.
Figure 37 Creating Service Profile Template - Server Boot Order
For applying the maintenance policy, follow these steps:
1.
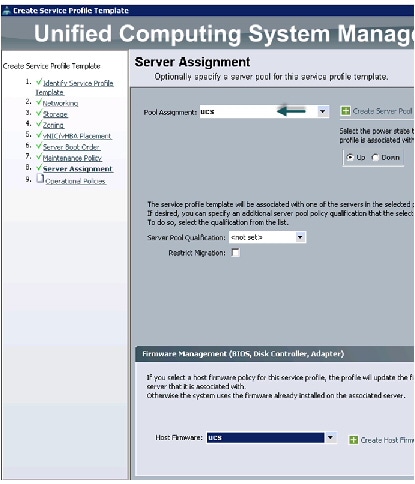
Configuring Server Assignment for the Template
For assigning servers to the pool, follow these steps:
1.
2.
3.
Figure 38 Creating Service Profile Template - Server Assignment
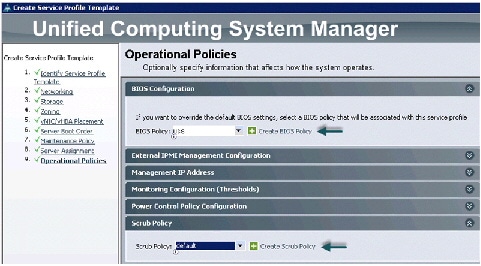
Configuring Operational Policies for the Template
For configuring operational Policies, follow these steps:
1.
2.
3.
4.
Figure 39 Creating Service Profile Template - BIOS Configuration for Operational Policies
Creating Service Profiles from Templates
1.
2.
3.
4.
Figure 40 Creating Service Profiles from Template
5.
Figure 41 Creating Service Profiles
6.
Figure 42 UCS Manager Showing all the Discovered Servers
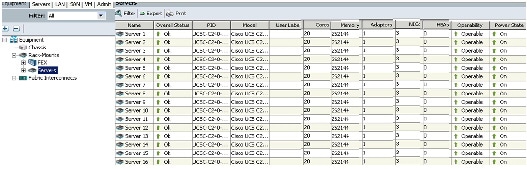
Configuring Nytro Flash on all node for installing OS
This section details the RAID configuration of Nytro Flash on all the nodes for installing the operating system. The Nytro Flash on RAID controller is configured as boot volume with 40 GB size with RAID1 configuration for redundancy.
Note
There are several ways to configure RAID: using LSI WebBIOS Configuration Utility embedded in the MegaRAID BIOS, booting DOS and running MegaCLI commands, using Linux based MegaCLI commands, or using third party tools that have MegaCLI integrated. For this deployment, the Nytro Flash and the disk drives are configured using LSI WebBIOS Configuration Utility.
Follow these steps to create RAID1 on the Nytro Flash to install the operating system:
1.
a.
2.
Figure 43 Adapter Selection for RAID Configuration
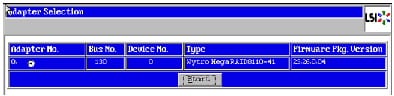
3.
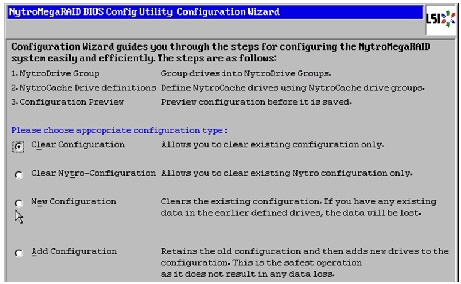
4.
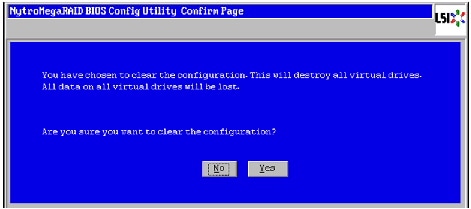
Figure 44 Clearing Current Configuration on the Controller
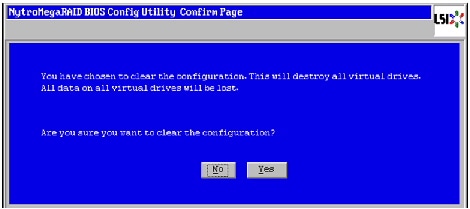
5.
Figure 45 Confirming Clearance of the Previous Configuration on the Controller
6.
7.
8.
Figure 46 Creating a New Configuration
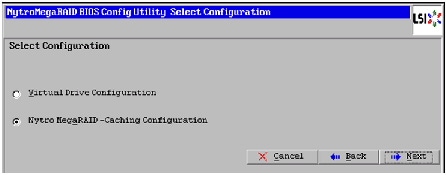
9.
10.
Figure 47 Selecting Nytro MegaRAID-Caching Configuration
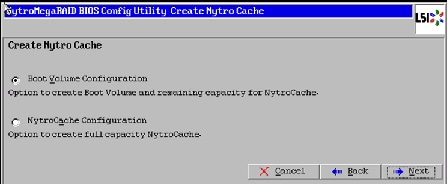
11.
Figure 48 Selecting Boot Volume Configuration
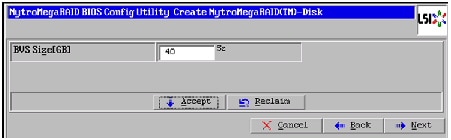
12.
Figure 49 Creating Boot Volume of 40GB
13.
Figure 50 Accept the Configuration
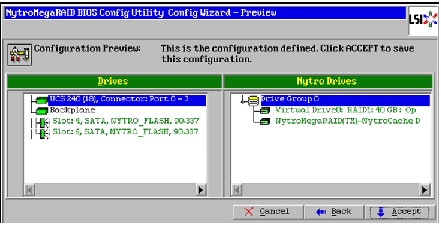
14.
15.
Figure 51 Confirm Saving Configuration

16.
Figure 52 Setting Virtual Drive as Boot Drive
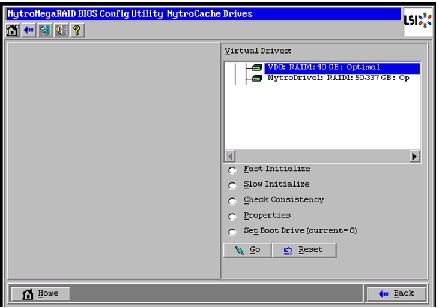
Configuring Disk Drives on all nodes
This section details the configuration of disk drives on all nodes. The disk drives are configured as single RAID5 with 1MB stripe size, read ahead cache and write cache is enabled while battery is in use.
There are several ways in which you can configure RAID:
- Using LSI WebBIOS Configuration Utility embedded in the MegaRAID BIOS
- Booting DOS and running MegaCLI commands
- Using Linux based MegaCLI commands
- Using third party tools that have MegaCLI integrated
For this deployment, the disk drives are configured using LSI WebBIOS Configuration Utility.
Follow these steps to create RAID5 on all the 12 disk drive:
1.
a.
2.
3.
Figure 53 Adapter Selection for RAID Configuration
4.
Figure 54 Setting Virtual Drive as Boot Drive
5.
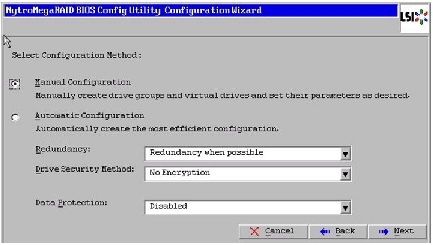
Figure 55 Choosing Manual Configuration Method
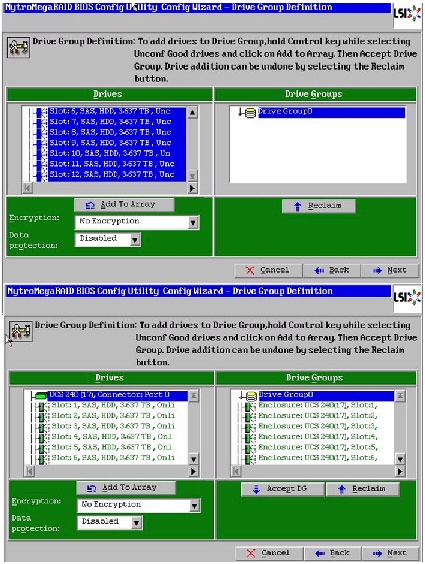
7.
8.
Figure 56 Selecting all Drives and Adding to Drive Group
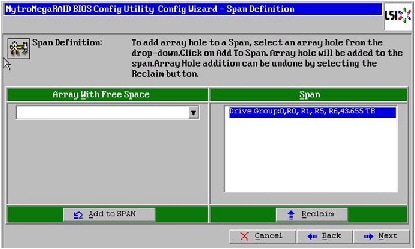
9.
Figure 57 Span Definition Window - Adding to Span
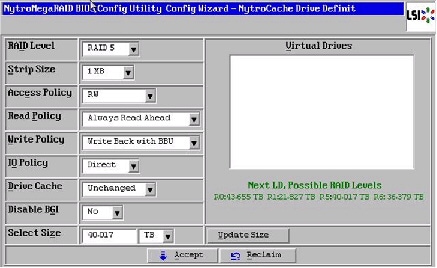
10.
b.
c.
d.
e.
f.
Note Clicking the Update Size might change some of the settings in the window. Make sure all the settings are correct before accepting.
Figure 58 Virtual Drive Definition Window
11.
12.
13.
14.
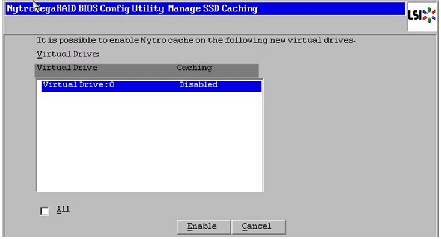
15.
Figure 60 Initializing Virtual Drive Window
Installing Ubuntu Server 12.04.4 LTS with KVM
The following section provides detailed procedures for installing Ubuntu Server 12.04.4 LTS.
There are multiple methods to install Ubuntu Server OS. The installation procedure described in this deployment guide uses KVM console and virtual media from Cisco UCS Manager.
1.
3.
4.
Figure 61 Opening KVM Console of the Server
5.
6.
in the Virtual Media selection window.
7.
Note The Ubuntu Server 12.04.4 LTS ISO can be downloaded from: http://www.ubuntu.com/download/server/thank-you?country=US&version=12.04.4&architecture=amd64.
8.
Figure 63 Browse to Ubuntu Server 12.04.4 LTS ISO Image
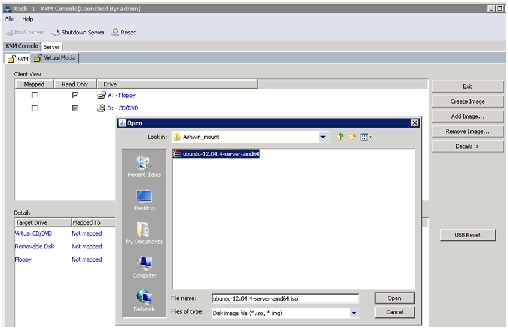
9.
10.
11.
.
13.
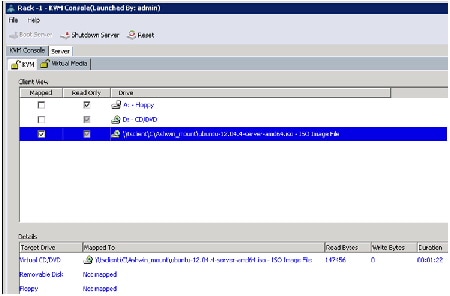
14.
15.
Figure 66 Selecting Install Ubuntu Server Option

16.
Figure 67 Selecting Language for Installation and Default Language for the Server
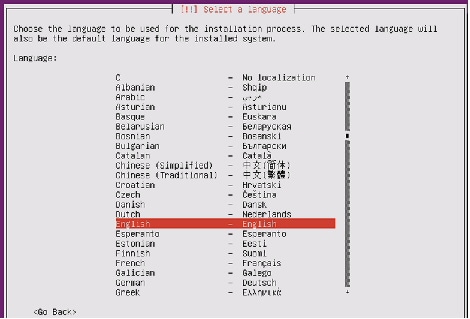
17.
18.
19.
20.
Figure 69 Configuring Network for eth0
21.
Figure 70 Selecting Network Configuration Method
22.
23.
24.
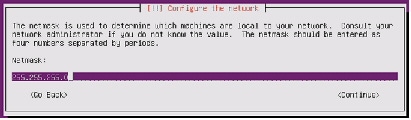
25.
26.
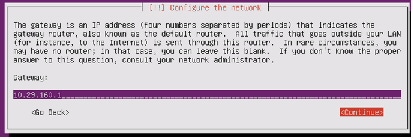
Figure 74 Entering Name Server Address
27.
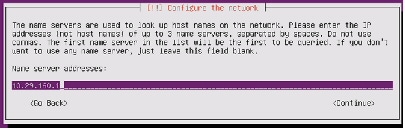
Figure 75 Entering Hostname for the Server
28.
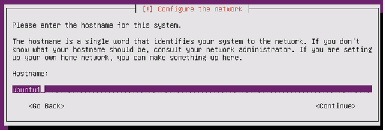
Figure 76 Entering Domain Name for the Server
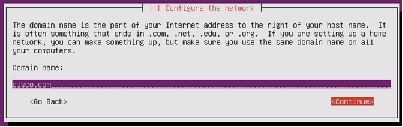
29.
Figure 77 Setting up User for the Server
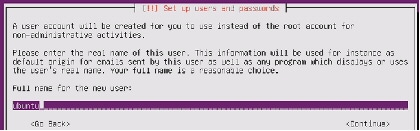
Figure 78 Setting up Username and Password

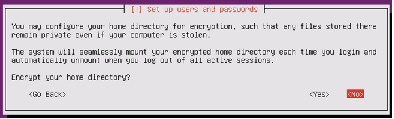
30.
Figure 79 Configuring Encryption for Home Directory
32.
Figure 81 Choosing Partitioning Method
33.
Figure 82 Partitioning Nytro Flash VD for Installing Operating System
34.
Figure 83 Confirm Write Changes
35.
Figure 84 Configuring http Proxy
Figure 85 Selecting Updating Options
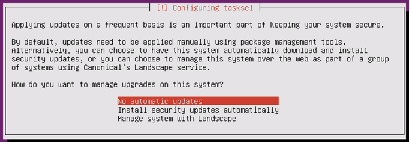
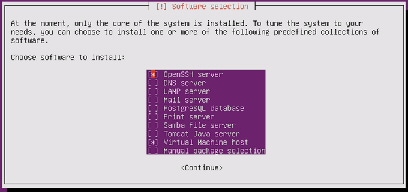
37.
Figure 86 Selecting Software for Installation
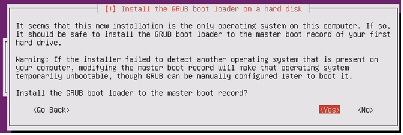
38.
Figure 87 Installing GRUB Boot Loader
39.
Figure 88 Finishing the Installation

Repeat the above steps (Steps 1 to 39) on all the servers to install Ubuntu Server 12.04.4 LTS. The OS installation and configuration of the nodes that is mentioned above can be automated through PXE boot or third party tools.
Note
Post OS Install Configuration
Choose one of the nodes of the cluster or a separate node as Admin Node for management of all the other nodes, node ubuntu20 for the purpose of this CVD.
Note • All Nodes in the system are assumed to have access to Internet.
- Most commands in this CVD are run as “sudo”. To avoid this, one could change profile as “sudo su” and run the commands without “sudo” as this is with full root privileges.
Most of the following configurations are done from the admin node.
Update Proxy for apt
On the admin node add the proxy to apt
Run the following command after updating the file as above
Note
Password-less login
On the admin node run command ssh-keygen:
Run the following command from the admin node to copy the public key id_rsa.pub to all the nodes
of the cluster. ssh-copy-id appends the keys to the remote-host's .ssh/authorized_key.
Setup Parallel Shell - clush
Install clustershell as follows
Update clustershell config to identify all nodes in the cluster

Note
Provide “all” in the above file relates to all nodes to be included in “-a” option for clush Provide “all” in the above file relates to all nodes to be included in “-a” option for clush
For all cluster nodes add the following lines in the end of /etc/sudoers to prevent Ubuntu asking for
N ameserver
On Admin node move the link - /etc/resolv.conf to static file for backing up:
Ping www.ubuntu.com to confirm
Configuring /etc/hosts
Follow these steps to create the host file across all the nodes in the cluster:
1.
2.
NTP Configuration
The Network Time Protocol (NTP) is used to keep all the cluster nodes time-synchronized. The Network Time Protocol daemon (ntpd) sets and maintains the system time in sync with the timeserver located in the admin node (ubuntu20). Configuring NTP is critical for any Hadoop cluster because if the server clocks in the cluster go out of sync, serious problems will occur with HBase and other services.
Note
Create /home/ubuntu/ntp.conf on the admin node and copy it to all nodes except admin node (Don’t overwrite ntp.conf on admin node).
Install ntp on all the nodes by running the following commands:
Copy ntp.conf file from the admin node to /etc of all the nodes by executing the following command in the admin node (ubuntu20).
Restart NTP on all the nodes including the admin node:
Configuring the Filesystem
In order to format the data partition which will be used by OpenStack for instances and data, ensure OS is on /dev/sda on all nodes and the data partition is on /dev/sdb by running the following commands
On the Admin node, create a file containing the following script driveconf.sh
1.
echo /sbin/mkfs.xfs -f -q -l size=65536b,lazy-count=1,su=256k -d sunit=1024,swidth=6144 -r extsize=256k -L ${Y} ${X}1/sbin/mkfs.xfs -f -q -l size=65536b,lazy-count=1,su=256k -d sunit=1024,swidth=6144 -r extsize=256k -L ${Y} ${X}1
Note This script formats /dev/sdb which is considered as the data partition (single volume of all 12 4TB drives which is RAID5). If OS is on /dev/sdb, that will be wiped out.
2.
3.
O penStack Pre-requisites
The following section provides information on setting up OpenStack.
Controller Node
In this CVD, the node ubuntu20 is used as the controller node. The controller node in OpenStack runs all OpenStack API services and OpenStack schedulers.
Networking
For an OpenStack production deployment, most of the nodes must have these network interface cards:
- One network interface card for external network traffic
- Another card to communicate with other OpenStack nodes.
In this CVD, eth0 is 10.29.160.x - public interface (with access to internet). eth1 is 192.168.10.x - private/internal interface for communication between VMs. We can add additional eth1 ip as follows:
Update /etc/network/interface on each host.
Run command “service networking restart” on all nodes as follows
Passwords
The various OpenStack services and the required software like the database and the Messaging server have to be password protected. These passwords are needed when configuring a service and then again to access the service. For more information, see:
http://docs.openstack.org/havana/install-guide/install/apt/content/basics-passwords.html
For simplicity, we use “ubuntu” as the password for all services in this CVD.
This guide uses the conventions, SERVICE_PASS as the password to access the service with SERVICE as the database name and SERVICE_DBPASS as the database password.
Table provides the list of passwords used in this CVD.
Installing MySQL
OpenStack services require a database to store information. This CVD uses MySQL for database which will be installed on the controller node and all the other nodes need MySQL client software to be installed for accessing MySQL.
Install MySQL Server on the Controller Node
During the install, you will be prompted for the mysql root password. Enter a password of your choice and verify it.
Edit /etc/mysql/my.cnf and set the bind-address to the internal IP address of the controller, to enable access from outside the controller node.

Restart the MySQL service to apply the changes:

Securing MySQL Server
All anonymous users that are created when the database is first started are to be deleted. Otherwise, database connection problems occur while following the CVD. To do this, use the mysql_secure_installation command.
This command presents a number of options to secure the database installation. Respond yes to all prompts unless there is a good reason to do otherwise.
Install MySql Client on all the Other Nodes
On all the nodes, install the MySQL client and the MySQL Python library on any of the systems that does not host a MySQL database:
OpenStack Repository - Ubuntu Cloud Archive for Havana
1.
2.
Messaging server (RabbitMQ)
Install the messaging queue server RabbitMQ on the controller node.
Note
OpenStack Services
OpenStack provides an Infrastructure as a Service (IaaS) solution through a set of interrelated services. Each service offers an Application Programming Interface (API) that facilitates this integration. Depending on the needs, some or all services can be installed.
Note
The following table describes the OpenStack services that make up the OpenStack architecture:
Canonical Ubuntu OpenStack Havana Software Components
This CVD focuses on Canonical OpenStack software components based on the upstream “Havana” OpenStack release. Ubuntu is the popular Linux flavor to deploy OpenStack among Service Providers and Enterprise customers. Following few subsections cover key software components involved in OpenStack. For more information, see:
https://wiki.openstack.org/wiki/UnderstandingFlatNetworking#Multiple_nodes.2C_multiple_adapters
Identity Service (“Keystone”)
This is a central authentication and authorization mechanism for all OpenStack users and services. It supports multiple forms of authentication including standard username and password credentials and it can also integrate with existing directory services such as LDAP.
Endpoints, Tenants, Tokens and Roles
The Identity service catalog lists all of the services deployed in an OpenStack cloud and manages authentication for them through endpoints. An endpoint is a network address where a service listens for requests. The Identity service provides each OpenStack service – such as Image, Compute, or Block Storage -- with one or more endpoints.
The Identity service uses tenants to group or isolate resources. By default users in one tenant can’t access resources in another even if they reside within the same OpenStack cloud deployment or physical host. The Identity service issues tokens to authenticated users. The endpoints validate the token before allowing user access. User accounts are associated with roles that define their access credentials. Multiple users can share the same role within a tenant.
Image Service (“Glance”)
This service discovers, registers, and delivers virtual machine images. They can be copied via snapshot and immediately stored as the basis for new instance deployments. Stored images allow OpenStack users and administrators to provision multiple servers quickly and consistently.
By default the Image Service stores images in the /var/lib/glance/images directory of the local server’s filesystem where Glance is installed.
Compute Service (“Nova”)
OpenStack Compute provisions and manages large networks of virtual machines. It is the backbone of OpenStack’s IaaS functionality. OpenStack Compute scales horizontally on standard hardware enabling the favorable economics of cloud computing. Users and administrators interact with the compute fabric via a web interface and command line tools.
OpenStack Compute provides distributed and asynchronous architecture, allowing scale out fault tolerance for virtual machine instance management.
OpenStack Compute is composed of many services that work together to provide the full functionality. The openstack-nova-cert and openstack-nova-consoleauth services handle authorization. The openstack-nova-api responds to service requests and the openstack-nova-scheduler dispatches the requests to the message queue. The openstack-nova-conductor service updates the state database, which limits direct access to the state database by compute nodes for increased security. The openstacknova-compute service creates and terminates virtual machine instances on the compute nodes. Finally, openstack-nova-novncproxy provides a VNC proxy for console access to virtual machines via a standard web browser.
Ephemeral Storage
Deploying only the OpenStack Compute Service (nova), users do not have access to any form of persistent storage by default. The disks associated with VMs are "Ephemeral", meaning that (from the user's point of view) they effectively disappear when a virtual machine is terminated (when VM is deleted).
Networking (nova-network)
Networking for the VMs in this CVD employs nova-network (Legacy OpenStack Network), which is a FlatNetwork. FlatNetworking primarily involves compute nodes. It uses Ethernet adapters configured as bridges to allow network traffic to transit between all the various nodes. This setup can be done with a single adapter on the physical host, or multiple.
For more information, see: https://wiki.openstack.org/wiki/UnderstandingFlatNetworking#Multiple_nodes.2C_multiple_adapters
Dashboard (“Horizon”)
The OpenStack Dashboard is an extensible web-based application that allows cloud administrators and users to control and provision compute, storage, and networking resources. Administrators can use the Dashboard to view the state of the cloud, create users, assign them to tenants, and set resource limits.
The OpenStack Dashboard runs as an Apache HTTP server via the httpd service.
Note
Installation of OpenStack
OpenStack basically has three roles for the nodes underneath.
- Controller node – It is the main management for OpenStack which controls compute and storage node. This runs all OpenStack API Services and OpenStack schedulers.
- Compute node – These nodes are hosts to the VMs spawned.
- Storage node – These nodes hosts the storage for VMs.
Note
Following OpenStack services are run on different components.
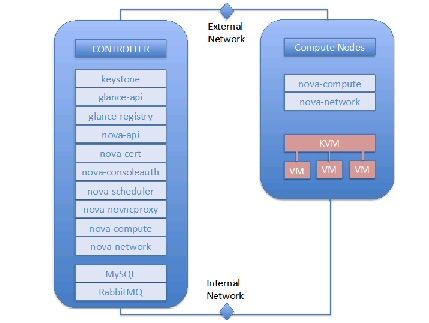
- Controller node - Identity Service (keystone), Image Service (Glance), Dashboard (Horizon), and management portion of Compute, with the associated API services, MySQL databases, and messaging system. In this CVD, we have Nova compute and Nova network also running on the controller node.
- Compute node - Tenant virtual machines on a hypervisor. By default, Nova compute uses KVM as the hypervisor. Compute also provisions and operates tenant networks and implements security groups.
Figure 89 Controller and Compute Nodes
Installing Havana OpenStack Services
This section details the installation of Havana OpenStack components on the cluster.
Identity Service (Keystone)
The Identity Service is used for the following functions:
- User management: To manage User Credentials.
- Service catalog: Provides available services along with their API endpoints.
- User - Digital representation of a person, system, or service who uses OpenStack cloud services. Users have a login and may be assigned tokens to access resources. Users can be directly assigned to a particular tenant and behave as if they are contained in that tenant.
- Token - An arbitrary bit of text that is used to access resources. Each token has a scope which describes which resources are accessible with it. A token may be revoked at any time and is valid for a finite duration.
- Tenant - A container used to group or isolate resources and/or identity objects. Depending on the service operator, a tenant may map to a customer, account, organization, or project.
- Service - An OpenStack service such as Compute (Nova), or Image Service (Glance). Provides one or more endpoints through which users can access resources and perform operations.
- Endpoint - A network-accessible address, usually described by a URL, from where you access a service.
- Role - A role includes a set of rights and privileges. A user assuming that role inherits those rights and privileges. In the Identity Service, a token that is issued to a user includes the list of roles that user has. Services that are being called by that user determine how they interpret the set of roles a user has and to which operations or resources each role grants access.
Note
1.
2.

3.
4.
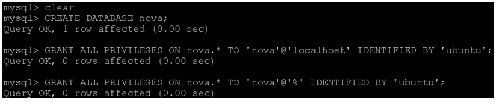
mysql> GRANT ALL PRIVILEGES ON keystone.* TO \ 'keystone'@'localhost' IDENTIFIED BY 'KEYSTONE_DBPASS';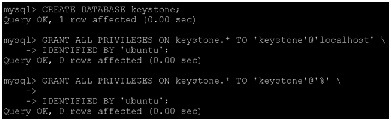
5.
6.
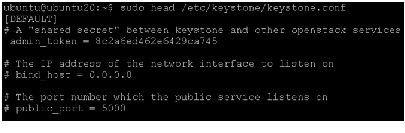
 Edit /etc/keystone/keystone.conf and change the [DEFAULT] section, replacing ADMIN_TOKEN with the results of the command.
Edit /etc/keystone/keystone.conf and change the [DEFAULT] section, replacing ADMIN_TOKEN with the results of the command.
Note Make sure there are no trailing spaces before admin_token.
Define Users, Tenants, and Roles
After you install the Identity Service, set up users, tenants, and roles to authenticate against. These are used to allow access to services and endpoints.
At this point, we have not created any users, so we have to use the authorization token created in an earlier step. We have set OS_SERVICE_TOKEN, as well as OS_SERVICE_ENDPOINT to specify where the Identity Service is running. Replace ADMIN_TOKEN with your authorization token above.

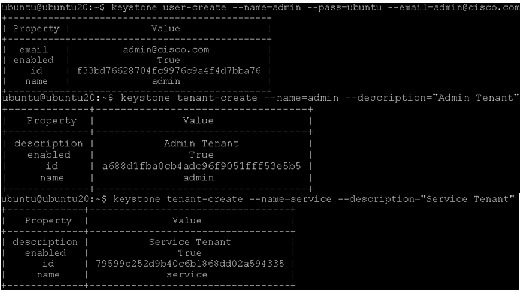
First, create a tenant for an administrative user and a tenant for other OpenStack services to use.

Note
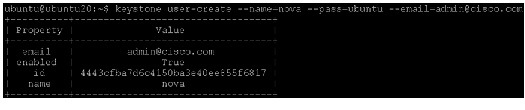
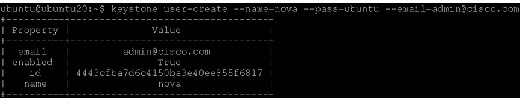
Next, create an administrative user called admin. Choose a password for the admin user and specify an email address for the account.
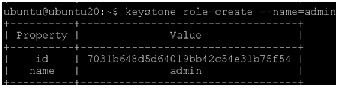
Create a role for administrative tasks called admin. Any roles you create should map to roles specified in the policy.json files of the various OpenStack services. The default policy files use the admin role to allow access to most services.
Finally, add roles to users. Users always log in with a tenant, and roles are assigned to users within tenants. Add the admin role to the admin user when logging in with the admin tenant.
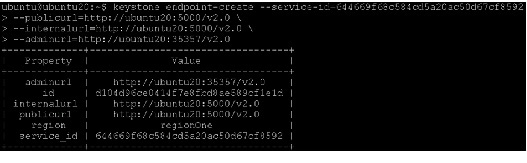
Define services and API endpoints
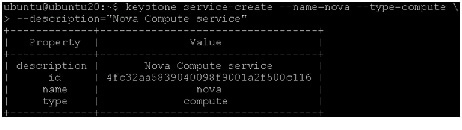
For Identity Service to track which OpenStack services are installed and where they are located on the network, services must be registered in the OpenStack installation. To register a service, run these commands:
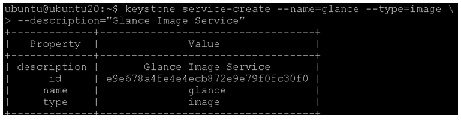
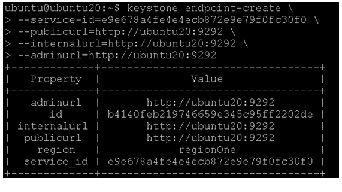
- keystone service-create - Describes the service.
- keystone endpoint-create - Associates API endpoints with the service.
Identity Service itself must be registered. Use the OS_SERVICE_TOKEN environment variable, as set previously, for authentication.
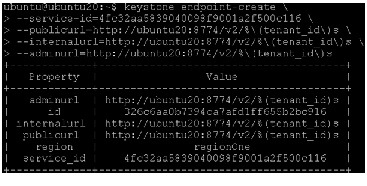
1.
The service ID is randomly generated and is different from the one shown below.

2.
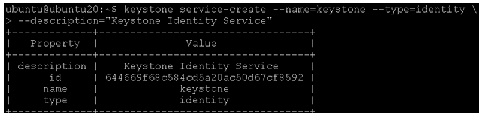
3.
Verify the Identity Service installation
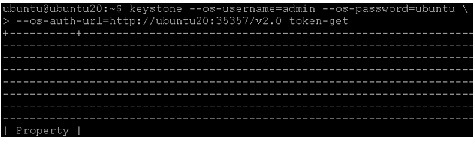
To verify the Identity Service is installed and configured correctly, first unset the OS_SERVICE_TOKEN and OS_SERVICE_ENDPOINT environment variables. These were only used to bootstrap the administrative user and register the Identity Service.
Now use the regular username-based authentication. Request an authentication token using the admin user and the password you chose during the earlier administrative user-creation step.
You should receive a token in response, paired with your user ID. This verifies that keystone is running on the expected endpoint, and that the user account is established with the expected credentials.
Next, verify that authorization is behaving as expected by requesting authorization on a tenant.
You should receive a new token in response, this time including the ID of the tenant you specified. This verifies that your user account has an explicitly defined role on the specified tenant, and that the tenant exists as expected.
You can also set your --os-* variables in your environment to simplify command-line usage. Set up an openrc.sh file with the admin credentials and admin endpoint.
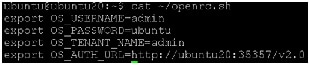
Source this file to read in the environment variables.
Verify that openrc.sh file is configured correctly by performing the same command as above, but without the --os-* arguments.
The command returns a token and the ID of the specified tenant. This verifies that you have configured your environment variables correctly.
Finally, verify that your admin account has authorization to perform administrative commands.
+----------------------------------+---------+--------------------+--------+ | id | enabled | email | name | +----------------------------------+---------+--------------------+--------+This verifies that the user account has the admin role, which matches the role used in the Identity Service policy.json file.
Image Service (Glance)
The OpenStack Image Service enables users to discover, register, and retrieve virtual machine images. Users can add new images or take a snapshot of an image from an existing server for immediate storage. Use snapshots for back up and as templates to launch new servers. Virtual machine images made available through the Image Service can be stored in a variety of locations from simple file systems to object-storage systems like OpenStack Object Storage.
Note
The Image Service includes the following components:
- glance-api - Accepts Image API calls for image discovery, retrieval, and storage.
- glance-registry - Stores, processes, and retrieves metadata about images. Metadata includes size, type, and so on.
- Database - Stores image metadata. Database used can be changed depending on the preference. Most deployments use MySQL or SQlite.
- Storage repository for image files - The Image Service supports normal file systems, RADOS block devices, Amazon S3, and HTTP.
A number of periodic processes run on the Image Service to support caching. The Image Service is central to the overall IaaS picture. It accepts API requests for images or image metadata from end users or Compute components.
Install the Image Service
This section details installing Glance, the image service in OpenStack Havana, on the controller node.
1.
2.
Configure the location of the database. The Image Service provides the glance-api and glance-registry services, each with its own configuration file. Both the services configuration files would be updated throughout this section. Replace GLANCE_DBPASS with your Image Service database password.
Edit /etc/glance/glance-api.conf and /etc/glance/glance-registry.conf and change the [DEFAULT] section.
#See:http://www.sqlalchemy.org/docs/05/reference/sqlalchemy/connections.html#sqlalchemy.create_engine
3.
4.
5.
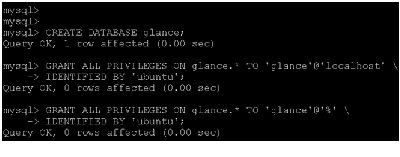
Note Make sure the command is run with sudo here, else tables in database glance will not be created.
6.
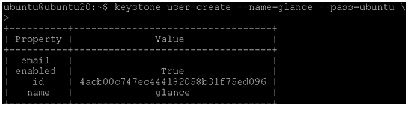
7.
Edit the /etc/glance/glance-api.conf and /etc/glance/glance-registry.conf files. Replace GLANCE_PASS with the password you chose for the glance user in the Identity Service.
a.
b.
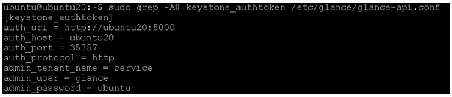
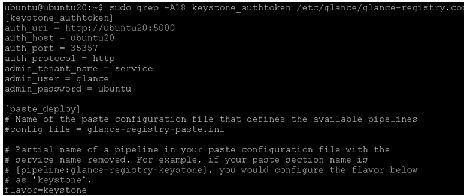
8.
Edit each file to set the following options in the [filter:authtoken] section and leave any other existing option as it is.
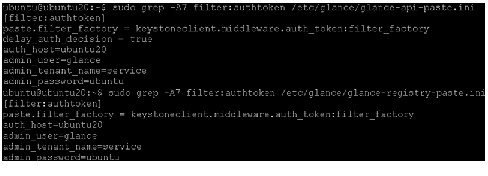
9.
10.
11.
Verify the Image Service installation
To test the Image Service installation, download at least one virtual machine image that is known to work with OpenStack. For example, CirrOS is a small test image that is often used for testing OpenStack deployments (CirrOS downloads). This walk through uses the 64-bit CirrOS QCOW2 image.
CirrOS is a minimal Linux distribution that was designed for use as a test image on clouds such as OpenStack Compute.
For KVM deployment, images are recommended to be in qcow2 format. The most recent 64-bit qcow2 image as of this writing is cirros-0.3.2-x86_64-disk.img
Note
Canonical maintains an official set of Ubuntu-based images .
Images are arranged by Ubuntu release, and by image release date, with "current" being the most recent. For example, the page that contains the most recently built image for Ubuntu 12.04 "Precise Pangolin" is http://cloud-images.ubuntu.com/precise/current/ . At the bottom of the page are links to images that can be downloaded directly.
For KVM deployment, images are recommended to be in qcow2 format. The most recent version of the 64-bit QCOW2 image for Ubuntu 12.04 is precise-server-cloudimg-amd64-disk1.img .
Note • In a ubuntu image, the login account is ubuntu.
- See http://docs.openstack.org/image-guide/content/ch_obtaining_images.html for links to obtain Virtual machine images of different Operating Systems
In this section we will set up the Ubuntu virtual machine image precise-server-cloudimg-amd64-disk1.img for Glance.
For more information about how to download and build images, see OpenStack Virtual Machine Image Guide . For information about how to manage images, see the OpenStack User Guide .
1.

2.
imageLabel is the arbitrary label, by which users refer to the image.
fileFormat specifies the format of the image file. Valid formats include qcow2, raw, vhd, vmdk, vdi, iso, aki, ari, and ami.
You can verify the format using the file command:

containerFormat specifies the container format. Valid formats include: bare, ovf, aki, ari and ami.
Specify bare to indicate that the image file is not in a file format that contains metadata about the virtual machine. Although this field is currently required, it is not actually used by any of the OpenStack services and has no effect on system behavior. Because the value is not used anywhere, it safe to always specify bare as the container format.
accessValue specifies image access:
–
–
imageFile specifies the name of your downloaded image file.
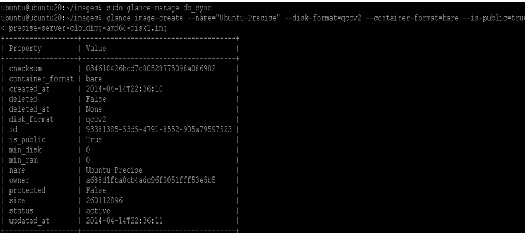
3.

Compute service (Nova)
The Compute service is a cloud computing fabric controller, which is the main part of an IaaS system. It is a collection of services that enable you to launch virtual machine instances and use it to host and manage cloud-computing systems.
Compute interacts with the Identity Service for authentication, Image Service for images, and the Dashboard for the user and administrative interface. Access to images is limited by project and by user; quotas are limited per project (for example, the number of instances). The Compute service scales horizontally on standard hardware, and downloads images to launch instances as required.
The Compute Service is made up of the following functional areas and their underlying components:
- nova-api service - Accepts and responds to end user compute API calls. Supports the OpenStack Compute API, the Amazon EC2 API, and a special Admin API for privileged users to perform administrative actions. Also, initiates most orchestration activities, such as running an instance, and enforces some policies.
- nova-api-metadata service - Accepts metadata requests from instances. The nova-api-metadata service is generally used only when run in a multi-host mode with nova-network installations.
- nova-compute process - A worker daemon that creates and terminates virtual machine instances through hypervisor APIs. For example, XenAPI for XenServer/XCP, libvirt for KVM or QEMU, VMwareAPI for VMware, and others.
- nova-scheduler process - Takes a virtual machine instance request from the queue and determines on which compute server host it should run.
- nova-conductor module - Mediates interactions between nova-compute and the database. Aims to eliminate direct accesses to the cloud database made by nova-compute. The nova-conductor module scales horizontally.
- nova-network worker daemon - Similar to nova-compute, it accepts networking tasks from the queue and performs tasks to manipulate the network, such as setting up bridging interfaces or changing iptables rules.
- nova-dhcpbridge script - Tracks IP address leases and record them in the database by using the dnsmasq dhcp-script facility.
- nova-consoleauth daemon - Authorizes tokens for users that console proxies provide.
- nova-novncproxy daemon - Provides a proxy for accessing running instances through a VNC connection. Supports browser-based novnc clients.
- nova-xvpnvncproxy daemon - A proxy for accessing running instances through a VNC connection.
- nova-cert daemon - Manages x509 certificates.
- The queue - A central hub for passing messages between daemons. Usually implemented with RabbitMQ, but could be any AMPQ message queue, such as Apache Qpid.
- SQL database - Stores most buildtime and runtime states for a cloud infrastructure. Includes available instance types, instances, networks, and projects. The databases widely used are MySQL (as in this CVD), and PostgreSQL.
The Compute Service interacts with other OpenStack services: Identity Service for authentication, Image Service for images, and the OpenStack dashboard for a web interface.
Install Compute controller services
These services can be configured to run on separate nodes or the same node. In this CVD, most services run on the controller node and the service that launches virtual machines runs on a dedicated compute node. This section shows how to install and configure these services on the controller node. Controller also runs nova-compute in order to run a single VM that runs Hadoop Master services such as Namenode. This section details on the services to be installed on the controller node.
1.
2.
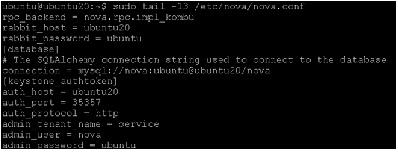
Edit /etc/nova/nova.conf file and add these lines to the [database] and [keystone_authtoken] sections:
3.
4.
5.
6.
Note Make sure the command typed is “db sync” and not “db_sync”. Also, this has to be run as sudo.
7.
Edit the /etc/nova/nova.conf file and add these lines to the [DEFAULT] section:
8.
9.
10.
11.
12.
Edit the [DEFAULT] section in the /etc/nova/nova.conf file to add this key:
13.
Note Make sure that the api_paste_config=/etc/nova/api-paste.ini option is set in the /etc/nova/nova.conf file.
14.
15.
17.
Configure a Compute node
After you configure the compute service on the controller node, the systems need to be configured as a compute node. The compute node receives requests from the controller node and hosts virtual machine instances.
The compute service relies on a hypervisor to run virtual machine instances. OpenStack can use various hypervisors, but this guide uses KVM, which is default for nova-compute.
For this architecture of Hadoop as a Service on OpenStack, all nodes are compute nodes including the controller node. The controller node runs Master hadoop services like Namenode and another node runs Resource manager on their VMs and these don’t run either Hadoop tasks or Hadoop datanode/ nodeserver for storing data.
This section also provides details on where the instances should be placed, i.e., in the mounted partition /DATA/ instead of the default in the OS drive.
Note
Following steps are performed on all nodes running nova-compute (including controller node):
1.
- Ensure eth1 is configured for dhcp.
- Ensure /etc/hosts are set on all nodes.
- Ensure all nodes are NTP synchronized.
- Install the MySQL client libraries. You do not need to install the MySQL database server or start the MySQL service.
2.
Run this command on the controller node (ubuntu20):
When prompted to create a supermin appliance, respond yes .
Note This can not be run as a clush command on all nodes as this requires the supermin to choose the option yes, you can run clush command to check if the installation is successful.
3.
To also enable this override for all future kernel updates, create the file /etc/kernel/postinst.d/statoverride containing:
Make sure the file is executable:
4.
5.
6.
Edit /etc/nova/nova.conf and add the following keys under the [DEFAULT] section:
Note Before changing individual /etc/nova/nova.conf, ensure to add this specific nova-networking config into /etc/nova/nova.conf in [default] to all nodes to avoid updating the individual files again. This CVD will go into details of nova-network in detail in the next section.
Note eth1 in internal-ip interface for openstack VMs to communicate. eth0 is public-ip interface.
7.
8.
Note This step is important to ensure all VM instances are in /DATA partition which has huge storage compared to the OS drive which would be default
9.
10.
11.
Changes to many nodes can be done by making changes on one node and copying the file to all the other compute nodes while ensuring not to overwriting the controller node as in following example:
12.
scheduler_default_filters=RetryFilter,AvailabilityZoneFilter,RamFilter,ComputeFilter,ComputeCapabilitiesFilter,ImagePropertiesFilter,SameHostFilter,DifferentHostFilter
Note If troubleshooting, the option “debug=true” can be set in the controller node /etc/nova/nova.conf file. However, this should be removed when in production to prevent performance slowdown. All debug logs will be available in /var/log/nova/nova-*.log.
13.
14.
15.
Note
Enable Networking (nova-networking)
This section discusses configuring FlatNetworking in OpenStack compute, that takes care of DHCP.
This set up uses multi-host functionality. Networking is configured to be highly available by distributing networking functionality across multiple hosts. As a result, no single network controller acts as a single point of failure. This process configures each compute node for networking.
1.
So that the nova-network service can forward metadata requests on each compute node, each compute node must install the nova-api-metadata service, as follows:
2.
Note This was already done in the above section. To avoid updating the individual files, edit nova.conf.
Note This must be done on the controller node as well.
3.
4.
Note Change the fixed-range-v4 based on your network environment
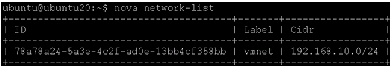
# sudo nova-manage network create vmnet --fixed_range_v4=192.168.10.0/24 --bridge=br100 --multi_host=T
Note Troubleshooting Note: Due to a bug, the "nova-api service" is automatically removed after you trying to install "nova-compute". This causes an error while running the above command such as “HTTPConnectionPool(host='10.0.0.0', port=8774): Max retries exceeded with url”
Reinstall nova-api as follows on the controller:
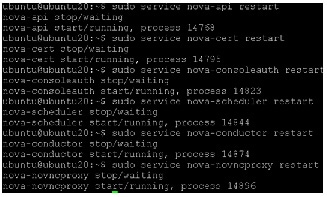
Restart all the nova services as:
5.
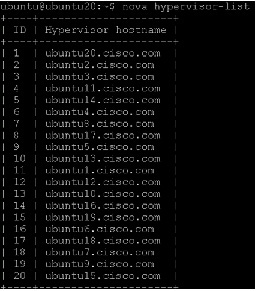
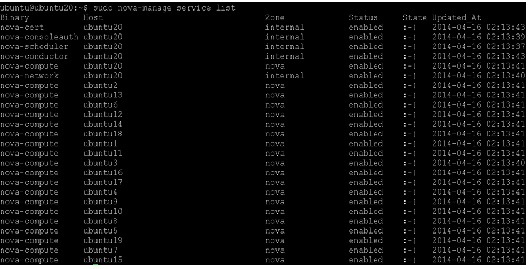
Launch an instance
After configuring the compute services, instances can be launched. An instance is a virtual machine that OpenStack provisions on compute servers.
1.
The id_rsa private key is saved locally in ~/.ssh, which can be used to connect to an instance launched by using mykey as the keypair. To view available keypairs:
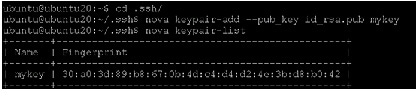
2.
–
–
–
–
–
–
–
–
–
To create a hadoop slave (data-node and task-tracker) flavor for a VM where 8 VMs would be hosted on C240M3 server with 20 Physical cores and 256GB RAM, run the following command to create a VM flavor with 2vCPUs, 50GB OS disk space, 28250 MB Memory and 2TB local ephemeral disk space for each of the VM.
To Create a hadoop Master (Namenode and Job-tracker/Resource Manager) flavor for a VM where 1 VM would be hosted on C240M3 server with 20 Physical cores and 256GB RAM, run the following command to create a VM flavor with 16vCPUs, 50GB OS disk space, 226000 MB Memory and 20TB local ephemeral disk space for each of the VM.


Note Flavors can be created from Dashboard Horizon as well.
3.
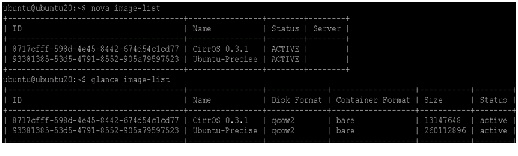
4.
5.
Since all these are run as admin (see openrc.sh file create earlier which was sourced), get the tenant-id of admin to update RAM for VM instances.
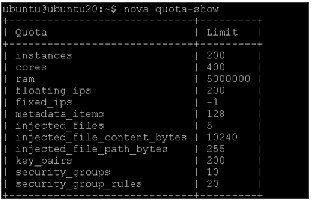
Update RAM to be 230000, this is slightly over to 8VMs each of 28500MB RAM, as in the hadoop.8vm.slave flavor created. As mentioned earlier, all nodes are 256GB RAM.
Note • All the quotas are for the project (identified by tenant-id and in this case for project admin) on the entire cluster on which openstack is deployed. So in-order to update instances, ram or cores, we need to consider how many per node and how many nodes and provide the total number for quota-update. In this config, each node has 20 physical core and 256 GB RAM, of which 16 cores are provided for Openstack and 230000MB for Openstack Memory and roughly 8 instances per node.
These can be updated from Horizon dashboard too.
6.
In order to achieve this, we need to launch the cirros instance on nodes giving a filter of Different_host so as to get the ids of cirros to pass it as option to launch Ubuntu VMs.
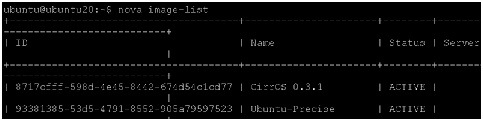
#nova boot --flavor 1 --key_name mykey --image 8717cfff-598d-4e45-8442-674d54c1cd77 --security_group default cirros
To list the VMs launched run the following command.
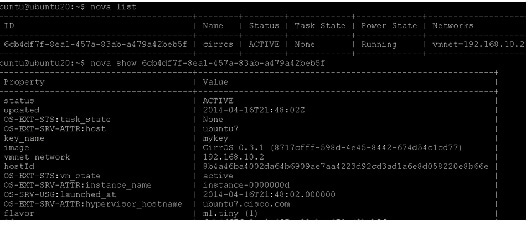
We now know that this VM was placed in node ubuntu7, so rename the VM in-order to use this information later.

Now create another cirros instance on a different node by passing a hint different_host option as:
#nova boot --flavor 1 --key_name mykey --image 8717cfff-598d-4e45-8442-674d54c1cd77 --security_group default --hint different_host=6cb4df7f-8ea1-457a-83ab-a479a42beb5f cirros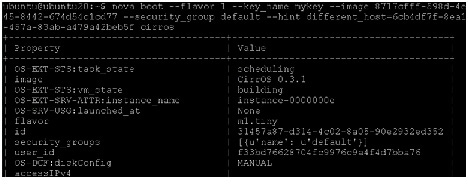
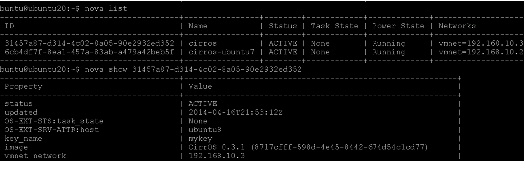
7.
8.
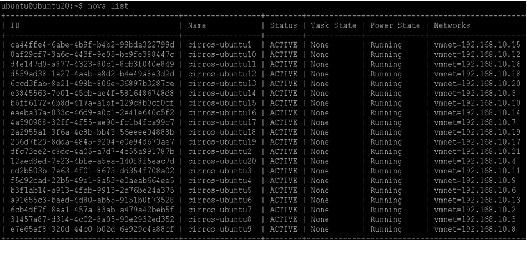
The Ubuntu VMs can be launched as follows by providing the hing “same_host” with the VM id of the cirros running on the same host as the one we need the VM to be placed in.
$ nova boot --flavor flavorType --key_name keypairName --image ID --hint same_host=<id_of_cirros_on_node_host> <instance-name>Create an instance by using flavor 8 for datanodes VMs. For example:
$ nova boot --flavor 8 --key_name mykey --image 93381385-53d5-4791-8552-905a79597523 --security_group default --hint same_host=<id_of_cirros_vm_on_ubuntu1> ubuntu1-vm1Create an instance by using flavor 9 for Namenode/ResourceManager VMs on nodes specially configured for that as done earlier. In this CVD, controller and Namenode are in same host.
 $ nova boot --flavor 9 --key_name mykey --image 93381385-53d5-4791-8552-905a79597523 --security_group default --hint same_host=<id_of_cirros_vm_on_ubuntu20> ubuntu20-namenode
$ nova boot --flavor 9 --key_name mykey --image 93381385-53d5-4791-8552-905a79597523 --security_group default --hint same_host=<id_of_cirros_vm_on_ubuntu20> ubuntu20-namenode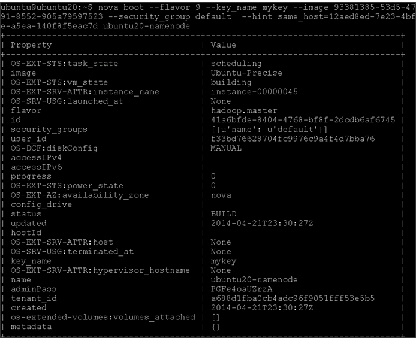
 $ nova boot --flavor 9 --key_name mykey --image 93381385-53d5-4791-8552-905a79597523 --security_group default --hint same_host=<id_of_cirros_vm_on_ubuntu19> ubuntu19-resourcemgr
$ nova boot --flavor 9 --key_name mykey --image 93381385-53d5-4791-8552-905a79597523 --security_group default --hint same_host=<id_of_cirros_vm_on_ubuntu19> ubuntu19-resourcemgr
Note ssh to Ubuntu VMs won’t work unless floating-ips are assigned which will be done in the next section.
9.
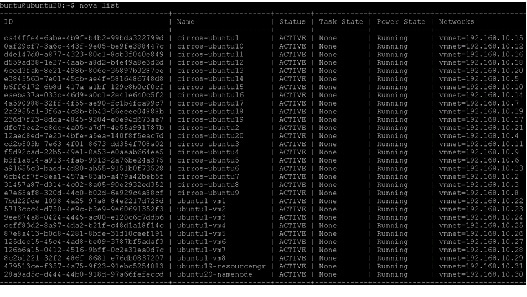
10.
Note If using a CirrOS image to spawn an instance you must log in as the cirros, and not the root, user.You can also log in to the cirros account without an ssh key by using the cubswin password: $ ssh cirros@10.0.0.3.
VMs on each node can be instantiated following a script similar to this:
nova boot --flavor 8 --key_name mykey --image 93381385-53d5-4791-8552-905a79597523 --security_group default --hint same_host=2a2955a1-3f6a-4c8b-bb43-56eeee04888b ubuntu18-vm1nova boot --flavor 8 --key_name mykey --image 93381385-53d5-4791-8552-905a79597523 --security_group default --hint same_host=2a2955a1-3f6a-4c8b-bb43-56eeee04888b ubuntu18-vm2nova boot --flavor 8 --key_name mykey --image 93381385-53d5-4791-8552-905a79597523 --security_group default --hint same_host=2a2955a1-3f6a-4c8b-bb43-56eeee04888b ubuntu18-vm3nova boot --flavor 8 --key_name mykey --image 93381385-53d5-4791-8552-905a79597523 --security_group default --hint same_host=2a2955a1-3f6a-4c8b-bb43-56eeee04888b ubuntu18-vm4nova boot --flavor 8 --key_name mykey --image 93381385-53d5-4791-8552-905a79597523 --security_group default --hint same_host=2a2955a1-3f6a-4c8b-bb43-56eeee04888b ubuntu18-vm5nova boot --flavor 8 --key_name mykey --image 93381385-53d5-4791-8552-905a79597523 --security_group default --hint same_host=2a2955a1-3f6a-4c8b-bb43-56eeee04888b ubuntu18-vm6Openstack Dashboard (Horizon)
The OpenStack dashboard, also known as Horizon, is a Web interface that enables cloud administrators and users to manage various OpenStack resources and services.
The dashboard enables web-based interactions with the OpenStack Compute cloud controller through the OpenStack APIs.
Install and configure the dashboard on a node that can contact the Identity Service.
Provide users with the following information so that they can access the dashboard through a web browser on their local machine:
- The public IP address from which they can access the dashboard.
- The user name and password with which they can access the dashboard.
Your web browser, and that of your users, must support HTML5 and have cookies and JavaScript enabled.
Note
Installing the Dashboard
Following section details installing Horizon dashboard on the controller node:
1.
2.
Note The address and port must match the ones set in /etc/memcached.conf. If you change the memcached settings, you must restart the Apache web server for the changes to take effect. You can use options other than memcached option for session storage. Set the session back-end through the SESSION_ENGINE option. To change the timezone, use the dashboard or edit the /etc/openstack-dashboard/local_settings.py file. Change the following parameter: TIME_ZONE = "UTC".
3.
Edit /etc/openstack-dashboard/local_settings.py:
4.
Edit /etc/openstack-dashboard/local_settings.py and change OPENSTACK_HOST to the hostname of your Identity Service:
5.
6.
Login with credentials for any user that you created with the OpenStack Identity Service, for example, “admin/admin”.
Figure 90 OpenStack Login Page
Dashboard can be further tuned with different backend storage and database. For more information, see: http://docs.openstack.org/havana/install-guide/install/apt/content/dashboard-sessions.html
Allocated floating-ips to the VMs
Allocate floating-ips to the VMs launched in the previous section in-order to be able to access the Ubuntu VMs.
On the controller node run the following command:

Go to the horizon page by accessing http://<controller-ip>/horizon
Access Project > Access & Security > Click the Floating IPs tab.
2.
3.
Figure 91 Managing and Associating IP Address to the Instance

Figure 92 Associated Instances and Their IP Addresses

4.
5.
6.
Note If a floating ip has to be assigned for all VM (if required in some use-cases), this can be assigned to every VM at the time the VM is being created/spawned by having the following entry in nova.conf to avoid manually assigning floating-ip. This floating ip makes the VM accessible externally (through the internet), hence doing so would require the floating-ip range being assigned to be available (not used). This however may not be preferred for all cases (consider spawning 1000 VMs, then 1000 publicly IP addresses should be available) and this might not be needed for the use-case and here assigning floating-ip manually as and when needed might be ideal.
Accessing the VM created
To access the VM, the mykey.pem file is needed. This was created in the controller node and so the connection to VM is from the controller node (Copy this file to any other node if access is needed from other nodes).
Run the following set of commands:
Add a password to be able to access directly from the dashboard horizon.
Setting Up XFS Filesystem Master Nodes
Note
Run the following to make sure the partition is visible in the VM:
Install xfsprogs to run mkfs.xfs

Note If provided Ephemeral storage is less than 4TB, the storage will be automatically mounted as ext3 Filesystem to /mnt when the VM is spawned. If the ephemeral storage is more than 4TB, this won’t be done and the above process has to be repeated for data/task VM as well to create the partition and mount it.
Setting Up Password-less Login within VMs
To access all the VMs instantiated from Namenode VM, we need to setup password-less login.
Login to the Namenode VM (running on controller node) as mentioned above and run the following commands:
1.
2.
3.
Note
Clush
Install clush on the Admin VM (VM on controller node) as follows:
Update clustershell config to identify all nodes in the cluster

Note
Ensure that clush is working fine by running the command clush -a -b pwd.
/etc/hosts
Update /etc/hosts file on all VMs. From OpenStack, get the VM and their ips as follows:
nova list | grep ubuntu | grep -v cirros | awk '{print $12," ",$4}' | sed 's/vmnet=//g' | sed ‘s/,//g’ > hosts-vmCopy these vms on hosts-vm to /etc/hosts and copy this to all nodes
Install NTP on all VMs
Install NTP on all VMs as follows:
The Network Time Protocol (NTP) is used to synchronize the time of all the nodes within the cluster. The Network Time Protocol daemon (ntpd) sets and maintains the system time of day in synchronism with the timeserver located in the admin node (rhel1). Configuring NTP is critical for any Hadoop Cluster. If server clocks in the cluster drift out of sync, serious problems will occur with HBase and other services.
Note
Install ntp on all the nodes by running the following command:
Copy ntp.conf file from the admin node to /etc of all the nodes by executing the following command in the admin node:
HDP 2.0 Repo for Ubuntu on all VMs
To install HDP 2.0 repo for Ubuntu on all the VMs, run these commands:
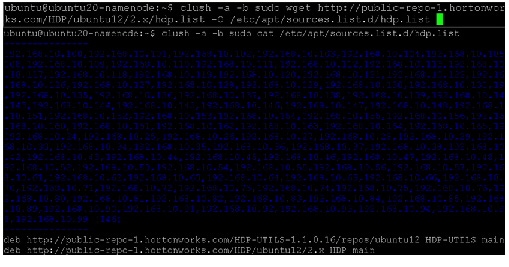
Add gpg keys for all VMs
For Each Ubuntu hosts, add the gpg keys as the root user (ensure the commands are run as “sudo su”).
Fully Qualified domain name (FQDN)
Make sure the fully qualified domain name (FQDN) for each VM host in set properly by running the following command:
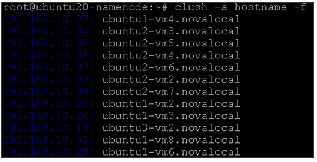
Domain Name Server (DNS)
Make sure the domain name server (DNS) is configured for both forward and reverse lookup.
A list of VM ip and their hostname can be generated by running the following command:
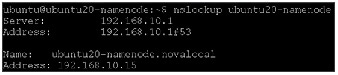
Install MySQL (resourcemanager VM)
MySQL database instance is needed to store metadata information for Hive and HCatalog services. You can either use an existing MySQL instance or install a new instance of MySQL manually. To install a new instance:
1.
2.

This prompts for mysql root password
4.
5.

6.
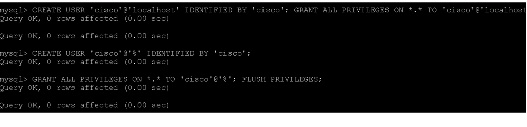
7.

8.

Installing HDP 2.0
HDP 2.0 is an enterprise grade, hardened Hadoop distribution. HDP combines Apache Hadoop and its related projects into a single tested and certified package. It offers the latest innovations from the open source community with the testing and quality you expect from enterprise quality software.
This section details installing Hadoop 2.0 manually on the VMs (which are currently running 8VM per node and two additional VM for Namenode and Resource Manager/Secondary namenode).
Note
Download Companion Files
To install hadoop manually download the companion files, which includes script files and configuration files, and use throughout this process. Download and extract the files on all VMs of Hadoop Cluster (all modifications to the hadoop config files will be done mostly in Namenode/Admin VM and copied to all other VMs from the Namenode VM).
clush –a –b wget http://public-repo-1.hortonworks.com/HDP/tools/2.0.6.0/hdp_manual_install_rpm_helper_files-2.0.6.101.tar.gzUnzip and untar the above downloaded file
This has scripts to setup and install hadoop.
In directory hdp_manual_install_rpm_helper_files-2.0.6.101/scripts/ under hdp_manual_install_rpm_helper_files-2.0.6.101, update the file directory.sh pointing to mounted filesystem as follows. Update this on the namenode and copy the same on all the VMs.
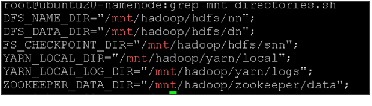
Copy the file directories.sh to all.
clush -b -w 192.168.10.[23-167] -c ./directories.sh --dest=/home/ubuntu/hdp_manual_install_rpm_helper_files-2.0.6.101/scripts/Add the two files in the bash_profile so the value is set for all the nodes. Add this in namenode and copy to all nodes. File directories.sh as mentioned above has location for the directories for the services and usersAndGroups.sh script defines all the users, which will be created later.
Note
This can be verified by running:
To create Hadoop Users on all the VMs, run the following script:
Create script hadoop_users.sh as follows in /home/ubuntu on Namenode VM to create the users need for HDP services.
Role Assignment – Masters/Slaves
This section defines assignment of master services and client services for various VMs that have been selected to appropriate hosts in the cluster. Master services (namenode/resourcemgr/etc) are all assigned to special VMs defined in flavors with more resources. The right column shows the current service assignments by VM.
Reconfigure the service assignment to match Table 9 :
Create Hadoop Directories
For manually installing HDP 2.0 on the VMs, directories need to be created for different services and appropriate permissions and ownership needs to be set.
Create the NameNode Directories
On the node that hosts the NameNode service, execute the following commands:
Create the SecondaryNameNode Directories
Create the directories of Secondary Namenode service on resource-mgr-vm by executing the following commands on Namenode.
Create DataNode and YARN NodeManager Local Directories
Create the directories of Datanodes by executing the following commands on Namenode.
Determine YARN and MapReduce Memory Configuration Settings
Memory configurations can be manually calculated by running the yarn-util script provided in companion files as follows:
Given the flavor of each Datanode/Tasktracker VM with 27GB Memory, 2 Cores and 2TB disk space.
Note
Set Default File and Directory Permissions
Set the default file and directory permissions to 0022 (022). This is the default setting typically for most Linux distributions.
Make sure umask 0022 is set in .bash_profile as mentioned in the above section. This ensures that the umask is set for all terminal sessions that you will use during the installation.
Install the Hadoop Packages
Install the following services on all the cluster VM nodes by running the command on the Namenode VM:
clush –a –B sudo apt-get –y install hadoop hadoop-hdfs libhdfs0 libhdfs0-dev hadoop-yarn hadoop-mapreduce hadoop-client openssl
Install Compression Libraries
Follow these steps to make the compression libraries available on all the cluster nodes:
H adoop Configuration
/home/ubuntu/hdp_manual_install_rpm_helper_files-2.0.6.101/configuration_files need to be edited and used in the configuration files for HDFS and MapReduce In directory /etc/hadoop/conf/core-hadoop.
Slaves
Create /etc/hadoop/conf/slaves file in namenode VM with the ip of all datanodes. A simple way to get all the ips is to run a gerp command on controller node and filter out all other VMs created such as cirros, namenode VM, resourcemanager VM as shown in the example.
nova list | grep ubuntu | grep -v ubuntu19- | grep -v ubuntu20- | grep -v cirros | awk '{print $4}' ' > slavesEnsure all the needed hostnames are present
Copy the contents of slaves to Namenode VM at /etc/hadoop/conf/slaves.
Note
In Namenode /etc/hadoop/conf/hadoop-env.sh, modify HADOOP_SLAVES with the value:
hdfs-site.xml
Update TODO fields as follows:
Note
Copy the configuration files
Delete the previous hadoop configuration directory if existing and recreate the directory.
Validating the Core Hadoop Installation
Follow these steps to install HDP:
Use the following instructions to start core Hadoop and perform the smoke tests:
Format and Start HDFS
1.
Make sure the namenode is up and running by typing the command:
2.
$sudo -u $HDFS_USER /usr/lib/hadoop/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR start secondarynamenode
Execute these commands on all datanodes:
$clush –b –w 192.168.10.[24-167] “sudo -u $HDFS_USER /usr/lib/hadoop/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR start datanode”
Smoke Test HDFS
1.

2.
3.

Start YARN
1.
Update /usr/lib/hadoop-yarn/sbin/yarn-daemon.sh in ResourceManager by setting the following:
Start MapReduce JobHistory Server
1.
2.
Ubuntu requires a passwd for all the users. Create a password for $HDFS_USER/hdfs and login as hdfs.
Run the following on Resource-manager VM as $HDFS_USER
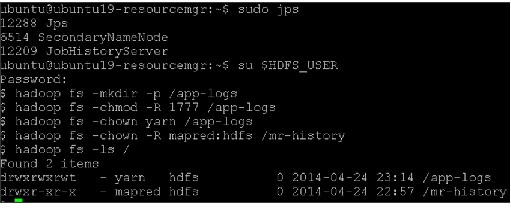
3.
Update the file /usr/lib/hadoop-mapreduce/sbin/mr-jobhistory-daemon.sh only on ResourceManager VM by adding the line HADOOP_LIBEXEC_DIR=/usr/lib/hadoop/libexec/ as follows:
Smoke Test MapReduce
1.
Installing HBase and Zookeeper
This section describes installing and testing Apache HBase, a distributed, column-oriented database that provides the ability to access and manipulate data randomly in the context of the large blocks that make up HDFS. It also describes installing and testing Apache ZooKeeper, a centralized tool for providing services to highly distributed systems.
Create the Hbase Log and PID Directories
To create the Hbase log and PID directories, run these commands:
Create the Zookeeper Data and Pid Directories
To create the Zookeeper data and PID directories, run these commands:
Initialize the zookeeper data directories with the 'myid' file. Create one file per Zookeeper server (namenode, resourcemanager and ubuntu1-vm1 servers), and put the number of that server in each file.
In the myid file on the namenode server, enter the corresponding number:
In the myid file on the resourcemanager server, enter the corresponding number:
In the myid file on the third server, enter the corresponding number:
Set Up the Configuration Files for Zookeeper and Hbase
There are several configuration files that need to be set up for HBase and ZooKeeper.
- Extract the HBase and ZooKeeper configuration files to separate temporary directories. The files are located in the configuration_files/hbase and configuration_files/zookeeper directories of the companion files.
- Modify the configuration files. In the respective temporary directories, locate the following files and modify the properties based on your environment. Search for TODO in the files for the properties to replace.
1.
Modify zoo.cfg in the namenode in the companion files and change TODO section as follows adding three servers
2.
3.
This increases the HeapSize to 4G for both Hbase Master and Region Server.
1.
2.
On all hosts create the config directory:
3.
For Zookeeper it is Namenode, Resourcemanager and one more VM and for Hbase, to HBase Master (at resource manager vm and all regionservers). cd to <companion files>/configuration_files/zookeeper on Namenode
cd to <companion files>/configuration_files/hbase on Namenode
4.
clush -b -w 192.168.10.[15,23,24] sudo chown -R $ZOOKEEPER_USER:$HADOOP_GROUP $ZOOKEEPER_CONF_DIR/../ ;Execute this command from the Namenode node:
clush -b -w 192.168.10.[15,23,24] sudo -u $ZOOKEEPER_USER /usr/lib/zookeeper/bin/zkServer.sh start $ZOOKEEPER_CONF_DIR/zoo.cfgThis above jps command should show process “QuorumPeerMain”
Execute this command from the HBase master node (same asResourceManager VM):
Installing Mahout
Install Mahout on all the VMs other than the namenode and the resourcemanager as follows:

Installing Apache Pig
This section describes installing and testing Apache Pig on all VMs other than namenode and resourcemanager. Apache Pig is a platform for creating higher level data flow programs that can be compiled into sequences of MapReduce programs, using Pig, the platform’s native language.
Installing Apache Hive/HCatalog
Install Apache Hive on all VM. Hive will be configured and run mostly from Resource Manager.
Install Hive and Hcatalog
Hive/HCatalog Configuration
We have created a sample user “cisco” for this CVD as mentioned in above pre-requisite section under MySQL, update the hive configuration file /etc/hive/hive-site.xml.
Create and Copy Hive Configuration files to all data/task VMs
Copy the above update hive configuration and all other Hive files in HDP companion files to all the data/task VMs.
Create Hive directories on Hadoop
This completes the Manual installation of HDP 2.0. For more information, see: http://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.0.9.1/bk_installing_manually_book/content/rpm-chap1.html
Conclusion
Hadoop has evolved into a leading data management platform across all verticals. The Cisco CPA v2 for Big Data for HDP 2.0 with OpenStack offers a dependable multi-tenant Hadoop deployment model for Hadoop as a Service.
The configuration detailed in the document can be extended to clusters of various sizes depending on what application demands. Up to 160 servers (10 racks) can be supported with no additional switching in a single UCS domain. Each additional rack requires two Cisco Nexus 2232PP 10GigE Fabric Extenders and 16 Cisco UCS C240 M3 Rack-Mount Servers. Scaling beyond 10 racks (160 servers) can be implemented by interconnecting multiple UCS domains using Nexus 6000/7000 Series switches, scalable to thousands of servers and to hundreds of petabytes storage, and managed from a single pane using UCS Central .
Bill of Material
This section gives the BOM for the 64 node Capacity Optimized with Flash memory Cluster. See Table 13 for BOM for the master rack, Table 14 for expansion racks (rack 2 to 4), Table 17 and 18 for software components.
Cisco RP208-30-U-2 Single Phase PDU 20x C13 4x C19 (Country Specific)
UC PLUS 24X7X4 Cisco RP208-30-U-X Single Phase PDU 2x (Country Specific)
 Feedback
Feedback