Cisco Prime Network Gateway High Availability Guide, 5.2
Bias-Free Language
The documentation set for this product strives to use bias-free language. For the purposes of this documentation set, bias-free is defined as language that does not imply discrimination based on age, disability, gender, racial identity, ethnic identity, sexual orientation, socioeconomic status, and intersectionality. Exceptions may be present in the documentation due to language that is hardcoded in the user interfaces of the product software, language used based on RFP documentation, or language that is used by a referenced third-party product. Learn more about how Cisco is using Inclusive Language.
- Updated:
- July 18, 2017
Chapter: Installing and Maintaining Gateway Local Redundancy
- Steps for Installing the Gateway Local Redundancy Solution
- Installation Requirements for Local Redundancy
- Preparing to Install the Local Redundancy Solution
- Configuring Hardware and External Storage for Red Hat Cluster Site
- Installing RHEL and Verifying the Version
- Installing RPMs Required on Red Hat for Prime Network
- Configuring Disk Group and Volumes
- Verify That All Servers Are Ready for Installation
- Creating the Mount Points for Installation
- Configure the Resources for Automatic Start After Reboot
- Stopping the RHCS Services
- Installing the Prime Network Gateway Local Redundancy Software
Installing and Maintaining Gateway Local Redundancy
The following topics provide procedures for setting up, installing, and maintaining the gateway local redundancy solution. Local redundancy is configured and monitored using the Red Hat Cluster Server (RHCS) for local redundancy. This chapter also explains how to install Prime Network Operations Reports and the Prime Network Integration Layer (PN-IL) with gateway local redundancy.

Note![]() Gateway high availability is supported only when the gateway software, Oracle database, and Infobright database (applicable for Operations Reports) are installed on the same server.
Gateway high availability is supported only when the gateway software, Oracle database, and Infobright database (applicable for Operations Reports) are installed on the same server.
Operations Reports are only available to customers with Operations Reports license prior to May 2018. For re-installation of Operations Reports contact a Cisco customer support representative.
- Steps for Installing the Gateway Local Redundancy Solution
- Installation Requirements for Local Redundancy
- Preparing to Install the Local Redundancy Solution
- Installing the Prime Network Gateway Local Redundancy Software
- Verifying the Local Redundancy Setup
- Post-Installation Tasks for Local Redundancy
- Maintaining Local Redundancy
- Uninstalling Local Redundancy
- Installing and Configuring PN-IL with Local Redundancy
Before proceeding with this chapter, make sure you have read Local Redundancy Functional Overview.
Steps for Installing the Gateway Local Redundancy Solution
Table 3-1 lists the steps you must follow to prepare for an installation, perform an installation, and verify an installation of the Prime Network gateway local redundancy solution. The table includes steps for working in a deployment that also has local redundancy. For local redundancy, the steps assume the primary database is on cluster node P1. An x means you must perform the step on that server.
Note![]() If you also have local redundancy installed, this procedure assumes the primary database is on the primary cluster server (P1).
If you also have local redundancy installed, this procedure assumes the primary database is on the primary cluster server (P1).
|
|
|
|
|
|
|---|---|---|---|---|
Collect server details, so that you have all information handy prior to installation. |
||||
Verify that the Prime Network servers meets the prerequisites. |
||||
Configure the dual-node cluster server hardware including configuring the external storage. |
Configuring Hardware and External Storage for Red Hat Cluster Site |
|||
Install RHEL and all recommended patches on both servers in the cluster. |
||||
Install the RPMs required for Red Hat and Oracle. If you are installing Operations Reports, be sure to check this section. |
||||
Configure disk groups, volumes, and partitions. If you are installing Operations Reports, be sure to check the required volume sizes. |
||||
Verify that all nodes are ready for installation by checking disk access, Linux versions, and NTP synchronization. |
||||
Mount the external shared storage, Oracle and Prime Network mount points on the relevant directories. |
||||
Make sure the /etc/hosts file lists the hostname before the fully qualified domain name (FQDN). Also make sure the hostname is not mapped to the loopback address (localhost / 127.0.0.1).
Note |
||||
Back up the /etc/host and root cron jobs files (the installation software will modify them). |
||||
For cluster node makes sure the specified services are configured to start automatically each time the machine is rebooted. |
||||
Stop the RHCS services in the order specified in Stopping the RHCS Services. |
||||
Install the gateway and Oracle database using install_prime_HA.pl. |
Installing the Prime Network Gateway Local Redundancy Software |
|||
Configure the embedded database (using the add_emdb_storage.pl -ha script). |
||||
If desired, install any new device packages so that you have the latest device support. |
||||
Installing Prime Network Operations Report with Gateway High Availability |
||||
(Optional) Setup RHCS Web GUI if it is not configured during installation. |
|
1.P1 is the primary cluster node and has the primary database. |
Installation Requirements for Local Redundancy
These topics list the prerequisites for installing gateway geographical redundancy:
Hardware and Software Requirements for Local Redundancy
Table 3-2 shows the core system requirements for local redundancy. Local redundancy requires a Prime Network embedded database and does not support IPv6 gateways or databases. If your high availability deployment differs from these requirements, please contact your Cisco account representative for assistance with the planning and installation of high availability.
|
|
|
|---|---|
Red Hat 6.7, Red Hat 6.8, Red Hat 6.9, Red Hat 6.10, Red Hat 7.4, or Red Hat 7.5, 64-bit Server Edition (English language). Red Hat can run in a virtual environment and supports VMware ESXi version 5.5, 6.0, or 6.7, and also on the Openstack kernel-based virtual machine (KVM) hypervisor version 2.6. Note Both nodes in the cluster must have identical RHCS versions and packages. Required Red Hat services and components: • /usr/bin/expect—Tool to automate interactive applications • /usr/bin/scp—Secure copy tool • /usr/bin/ssh-keygen—Tool to generate, manage, and convert authentication keys. For more information on installing operating system and RPMs required on Red Hat, see Installing RHEL and Verifying the Version and Installing RPMs Required on Red Hat for Prime Network. |
|
| Note Oracle 12.2.0.1 is included in the Prime Network embedded database installation. |
|
RHEL 6.7, RHEL 6.8, RHEL 6.9, RHEL 6.10, RHEL 7.4, and RHEL 7.5 certified platform with fencing capabilities. Note RHEL supports the fence_vmware_soap fencing method on RHEL 6.5 or higher (with the High Availability and Resilient Storage Add Ons). For more information, see the Red Hat site. It is recommended for virtual machines, the RHCS must run with fence_vmware_soap fencing method. Note Hardware installation with no single point of failure is recommended. See Configuring Hardware and External Storage for Red Hat Cluster Site. While using fencing, ensure the following: – – – – Fencing options are listed in Fencing Options. For the recommended hardware for small, medium, and large networks, see the Cisco Prime Network 5.2 Installation Guide. |
|
|
– – – – – – –
|
|
RHCS requires a shared storage accessible from all cluster nodes. When using external storage, ensure the following: – – – –
Note If you are using Operations Reports, 1-4 additional partitions should be created for the Infobright database data, cache, backup, and DLP storage. |
|
|
2.Virtual machine and bare metal requirements for hard disk, memory, and processor are same. Refer to the Cisco Prime Network 5.2 Installation Guide for memory and processor requirements. |
Port Usage for Local Redundancy
In addition to the ports listed in the Cisco Prime Network 5.2 Installation Guide, the following ports must be free.
You can check the status of the listed ports by executing the following command:
To free any ports, contact your system administrator.
|
|
|
|---|---|
Preparing to Install the Local Redundancy Solution
These topics describe the setup tasks you may need to perform before installing the local redundancy software:
- Configuring Hardware and External Storage for Red Hat Cluster Site
- Installing RHEL and Verifying the Version
- Installing RPMs Required on Red Hat for Prime Network
- Configuring Disk Group and Volumes
- Verify That All Servers Are Ready for Installation
- Creating the Mount Points for Installation
- Stopping the RHCS Services
- Updating the Database Host in the Registry (Only for NAT)
- Configuring the RHCS Web Interface (Optional)
Configuring Hardware and External Storage for Red Hat Cluster Site
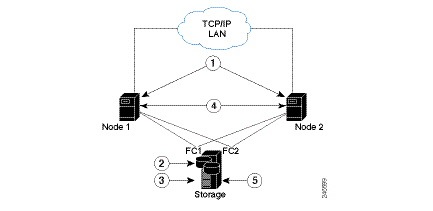
Figure 3-1 shows the recommended hardware design to avoid a single point of failure, which includes:
- Disk mirroring at the storage location.
- Redundant RAID controllers.
- Redundant storage and gateway power supplies.
- Dual NICs on both gateways.
- Separate NIC connections to switches.
- NIC bonding in active/backup mode.
Figure 3-1 Local Redundancy Hardware Installation to Avoid Single Points of Failure
|
|
|
||
|
|
|
||
|
|
|
Configure the external storage so all disks and logical unit numbers (LUNs) are accessible from both servers in the cluster. The disk and LUN configuration depends on the storage type:
- If you are using JBOD disks, provide enough physical disks to create the volumes shown in Table 3-4 to satisfy the Oracle performance requirements.
- If you are using storage that supports hardware RAID, divide the physical disks into LUNs so that the volumes listed in Table 3-4 can be created and configured to satisfy the Oracle performance requirements and protected with RAID5, RAID1, or RAID10. The Oracle volumes can be created on a single LUN.
- The number of HDD, HDD types, HDD capacity, and RAID level, should be based on recommendations provided by the Prime Network Capacity Planning Guide. Obtain the Capacity Planning Guide from your Cisco account representative.
Installing RHEL and Verifying the Version
Install the RHEL with the Red Hat Cluster Suite using the procedures in the Red Hat user documentation.
To verify that you have the required Linux version, use the following command:
RHEL installation version should be identical on all the servers.
Note![]() RHCS is included in the Red Hat Advanced Platform option. If Red Hat Clustering Service was not installed as part of RHEL, install the Red Hat Clustering Service using the procedures in the Red Hat user documentation.
RHCS is included in the Red Hat Advanced Platform option. If Red Hat Clustering Service was not installed as part of RHEL, install the Red Hat Clustering Service using the procedures in the Red Hat user documentation.
Installing RPMs Required on Red Hat for Prime Network
These sections list the additional RPMs required for Red Hat and Oracle:
Required RPMs for Red Hat 6.5
The following RPMs must be downloaded from the Red Hat website and installed on the gateway and unit servers.
- compat-libstdc++-33-3.2.3-69.el6.i686
- glibc-2.12-1.132.el6.i686
- libgcc-4.4.7-4.el6.i686
- libstdc++-devel-4.4.7-4.el6.i686
- libaio-devel-0.3.107-10.el6.i686
- libXtst-1.2.1-2.el6.i686(Required for GUI installation)
- libgcj-4.4.7-4.1.el6_5.i686(Required for GUI installation)
- libXext.i686
Minimum Required 64-bit packages
- binutils-2.20.51.0.2-5.36.el6.x86_64
- libXtst-1.2.1-2.el6.x86_64 (Required for GUI installation)
- libgcj-4.4.7-4.1.el6_5.x86_64(Required for GUI installation)
- compat-libcap1-1.10-1.x86_64
- compat-libstdc++-33-3.2.3-69.el6.x86_64
- openssl098e-0.9.8e-17.el6_2.2.x86_64 (Required for installing Operations Reports)
- gcc-c++-4.4.7-4.el6.x86_64
- glibc-devel-2.12-1.132.el6_5.4.x86_64
- numactl-2.0.7-8.el6.x86_64
- ksh-20120801-10.el6.x86_64
- libgcc-4.4.7-4.el6.x86_64
- libstdc++-devel-4.4.7-4.el6.x86_64
- libaio-devel-0.3.107-10.el6.x86_64
- make-3.81-20.el6.x86_64
- sysstat-9.0.4-22.el6.x86_64
- expect-5.44.1.15-5.el6_4.x86_64
- openssh-server-5.3p1-94.el6.x86_64
- openssh-5.3p1-94.el6.x86_64
- telnet-0.17-47.el6_3.1.x86_64
- dos2unix-3.1-37.el6.x86_64
Required RPMs for Oracle Database 12c
The following packages, or later versions of them, are required for the Oracle 12c database on Red Hat.
- binutils-2.20.51.0.2-5.11.el6 (x86_64)
- glibc-2.12-1.7.el6 (x86_64)
- libgcc-4.4.4-13.el6 (x86_64)
- libstdc++-4.4.4-13.el6 (x86_64)
- libaio-0.3.107-10.el6 (x86_64)
- libXext-1.1 (x86_64)
- libXtst-1.0.99.2 (x86_64)
- libX11-1.3 (x86_64)
- libXau-1.0.5 (x86_64)
- libxcb-1.5 (x86_64)
- libXi-1.3 (x86_64)
- make-3.81-19.el6
- sysstat-9.0.4-11.el6 (x86_64)
- compat-libcap1-1.10-1 (x86_64)
- compat-libstdc++-33-3.2.3-69.el6 (x86_64)
- gcc-4.4.4-13.el6 (x86_64)
- gcc-c++-4.4.4-13.el6 (x86_64)
- glibc-devel-2.12-1.7.el6 (x86_64)
- ksh (any version of ksh)
- libstdc++-devel-4.4.4-13.el6 (x86_64)
- libaio-devel-0.3.107-10.el6 (x86_64)
Note![]() If any of the preceding packages are missing, the installation fails.
If any of the preceding packages are missing, the installation fails.
To verify all required RPMs are installed, execute the following command as root:
Configuring Disk Group and Volumes
Table 3-4 and Table 3-5 show the disk partitions required for the dual-node cluster at the primary site.
When you set up the RHCS disk groups and volumes, keep the following in mind:
- All of the shared storage should have an ext3 file system installed.
- Shared storage must be accessible from all cluster nodes. For recommendations on the number of HDD, HDD types, HDD capacity, and RAID level contact your Cisco representative.
- Placing the individual directories in separate partitions is recommended, though not required.
Note![]() Prime Network installation normally requires 1024 MB additional free space on the root partition. For HA, a temporary copy of Prime Network is installed under the root partition. Therefore, an additional 5120 MB free space is required, for a total of 6144 MB required free space. The HA files are installed under /usr/local/bin, /var, /etc., which requires a minimum of 1224 MB. You can add this amount to the root partition instead of creating a separate partition for each.
Prime Network installation normally requires 1024 MB additional free space on the root partition. For HA, a temporary copy of Prime Network is installed under the root partition. Therefore, an additional 5120 MB free space is required, for a total of 6144 MB required free space. The HA files are installed under /usr/local/bin, /var, /etc., which requires a minimum of 1224 MB. You can add this amount to the root partition instead of creating a separate partition for each.
Verify That All Servers Are Ready for Installation
Verify the following on all servers: disk access, Linux versions, and NTP sync on all servers:
- Access to all external disks is available.
- The same version of Linux is deployed on all servers. To check the version:
- Verify that the time is synchronized on both servers using NTP. For information on configuring NTP, see the Cisco Prime Network 5.2 Installation Guide.
Creating the Mount Points for Installation
Use this procedure to create mount points before setting up high availability.
Note![]() All servers in the local redundancy setup should have same mount points.
All servers in the local redundancy setup should have same mount points.
Step 1![]() Log in as root user, and create the following directories:
Log in as root user, and create the following directories:
Step 2![]() Mount the external shared storage on the relevant directories of the node from where you will run the installation. Mount it manually and do not add it to the fstab file. Comment out any corresponding entry to the shared storage in /etc/fstab for both cluster nodes.
Mount the external shared storage on the relevant directories of the node from where you will run the installation. Mount it manually and do not add it to the fstab file. Comment out any corresponding entry to the shared storage in /etc/fstab for both cluster nodes.
Step 3![]() If the embedded database mount points contained in networkdata/archive logs and control files are set outside the local disks, for example, on a SAN, make corresponding entries in /etc/fstab so the mount points are available during a reboot.
If the embedded database mount points contained in networkdata/archive logs and control files are set outside the local disks, for example, on a SAN, make corresponding entries in /etc/fstab so the mount points are available during a reboot.
Step 4![]() Mount all of the Oracle, Prime Network, Operations Reports mount points on the server where you will run the installation.
Mount all of the Oracle, Prime Network, Operations Reports mount points on the server where you will run the installation.
In this example, PRIMENETWORK and ORACLE are the sample label names :
Configure the Resources for Automatic Start After Reboot
For every cluster node, make sure the following resources are configured to start automatically each time the server is rebooted.
For automatically starting these services, run the following command:
Check that status of these services using the following command:
ricci 0:off 1:off 2:off 3:off 4:off 5:off 6:off
The above output indicate the ricci service is disabled
The above output indicate the ricci service is enabled
Stopping the RHCS Services
Make sure that the Red Hat Cluster Suite rgmanager and cman services are turned off before installing Prime Network high availability on the gateway.
To turn off the RHCS services:
Step 1![]() On P1, stop the rgmanager service using the following command:
On P1, stop the rgmanager service using the following command:
Step 2![]() On P2, stop the rgmanager service using the following command:
On P2, stop the rgmanager service using the following command:
Step 3![]() On P1, stop the cman service using the following command:
On P1, stop the cman service using the following command:
Step 4![]() On P2, stop the cman service using the following command:
On P2, stop the cman service using the following command:
Step 5![]() Enter the following command on all cluster nodes to verify the service status:
Enter the following command on all cluster nodes to verify the service status:
Step 6![]() The services are stopped.
The services are stopped.
For rgmanager stopped services the output is displayed as clurgmgrd is stopped and for cman as ccsd is stopped.
Installing the Prime Network Gateway Local Redundancy Software
The local redundancy solution for dual-node cluster is installed using install_prime_HA.pl script that is available in RH_ha.zip file in the installation DVD as described in Installation DVDs.
You can run the installation in interactive or in non-interactive mode. Interactive mode installation prompts you to enter the gateway HA data values one at a time. The Prime Network installer then updates the auto_install_RH.ini file template, which populates the install_Prime_HA.pl script.
Alternatively, you can enter all the installation values in the auto_install_RH.ini template, located in the RH_ha directory, then run the installation in non-interactive mode. The installation mode is determined by the presence or absence of the -autoconf flag.
Note![]() It is recommended you run the installation in interactive mode first to populate the auto_install_RH.ini template with the user input. This gives you the ability to verify the input and run the installation again in non-interactive mode, if needed.
It is recommended you run the installation in interactive mode first to populate the auto_install_RH.ini template with the user input. This gives you the ability to verify the input and run the installation again in non-interactive mode, if needed.
This procedure installs gateway high availability for local redundancy with RHEL 6.5, 6.7, or 6.8.
Step 1![]() Change to the root user, then unzip the RH_ha.zip located on the installation DVD. Unzipping RH_ha.zip creates the /tmp/RH_ha directory.
Change to the root user, then unzip the RH_ha.zip located on the installation DVD. Unzipping RH_ha.zip creates the /tmp/RH_ha directory.
Note![]() If you are running the Korn shell (/bin/ksh) and the prompt is the hash tag (#), the installation will fail. Run the installation script using bash.
If you are running the Korn shell (/bin/ksh) and the prompt is the hash tag (#), the installation will fail. Run the installation script using bash.
Step 2![]() From the /tmp/RH_ha directory run the install_Prime_HA.pl in interactive or non-interactive mode. For information on the install_Prime_HA.pl script, see Installation DVDs.
From the /tmp/RH_ha directory run the install_Prime_HA.pl in interactive or non-interactive mode. For information on the install_Prime_HA.pl script, see Installation DVDs.
Step 3![]() For local redundancy alone, enter local HA= yes, DR= no, when prompted. See Table 3-6 for the prompts that appears while installing local redundancy configuration.
For local redundancy alone, enter local HA= yes, DR= no, when prompted. See Table 3-6 for the prompts that appears while installing local redundancy configuration.
Step 4![]() Execute the install_Prime_HA.pl script in interactive or non-interactive method.
Execute the install_Prime_HA.pl script in interactive or non-interactive method.
For interactive installation, execute the following commands:
See Table 3-6 for descriptions of other parameters you will be asked to enter at various stages of the interactive installation.
a.![]() Edit the auto_install_RH.ini file template found under the RH_ha directory with all of the installation details.
Edit the auto_install_RH.ini file template found under the RH_ha directory with all of the installation details.
Note![]() To prevent any security violation, it is highly recommended to remove the password in auto_install_RH.ini file after the successful installation.
To prevent any security violation, it is highly recommended to remove the password in auto_install_RH.ini file after the successful installation.
After the install_Prime_HA.pl script is completed:
Table 3-6 describes the prompts that you need to enter during the local redundancy installation.
Note![]() If you experience problems, see Troubleshooting the Local Redundancy Installation.
If you experience problems, see Troubleshooting the Local Redundancy Installation.
|
|
|
|
|---|---|---|
Enter no ; this procedure is for local redundancy alone. To install local + geographical redundancy, see Installing the Prime Network Gateway Geographical Redundancy Software. |
||
yes or no depending on whether NTP should be configured on two gateways. If not configured, first configure NTP and then continue with the installation. For more details on procedures, see configuring NTP in the Cisco Prime Network 5.2 Installation Guide. |
||
User-defined Prime Network OS user ( pnuser). Username must start with a letter and contain only the following characters: [A-Z a-z 0-9]. |
||
Location of the mount point given for the oracle-home / oracle-user. Default is /opt/ora/oracle. |
||
Directory should be located under Prime Network file system mount point but not the mount point itself. |
||
Mount point of the Prime Network installation. Should be the same for all relevant nodes. Example: For install.pl the path will be /dvd/Server. |
||
Location of Oracle mount points, separated by ",". First is the mount point for the Oracle home directory, for example, /opt/ora,/opt/dbf. Note For interactive installations: Installer asks you for a mount, then asks if you want to add another one. For non-interactive installations, enter all Oracle mount data in the input file. |
||
yes or no value indicating whether you want to use the default Oracle mount point or not |
||
Directory containing embedded Oracle zip files. Can be a temporary location where the files were copied from the installation DVDs; or directly specify the location on DVD. |
||
Hostname for node running the installation. For local redundancy dual-node clusters, node must be one of the cluster nodes. This is the value returned by the system call hostname. |
||
hostname for the second cluster node for local redundancy dual-node clusters. This is the value returned by the system call hostname. |
||
Password for Prime Network root, bosenable, bosconfig, bosusermngr, and web monitoring users (users for various system components). Passwords must contain: |
||
E-mail address to which embedded database will send error messages. When a local HA Oracle database is switched to run on a different gateway either manually or automatically, the oracle started in machine_name notification will be emailed to the recipient with email address configured in oracle.sh. If you want a different recipient to receive the email notification, you need to manually update the oracle.sh file. |
||
Location of the database archive files. Should be located under one of the Oracle mounts but not directly on the mount, and should be compliant with the storage requirements. |
||
Location of database redologs. Should be located under one of the Oracle mounts but not directly on the mount, and should be compliant with the storage requirements. |
||
Location of database backup files. Should be located under one of the Oracle mounts but not directly on the mount, and should be compliant with the storage requirements. |
||
Location of database data files. Should be located under one of the Oracle mounts but not directly on the mount, and should be compliant with the storage requirements. |
||
An available multicast address accessible and configured for both cluster nodes. |
||
User-defined cluster name. The cluster name cannot be more than 15 non-NUL (ASCII 0) characters. For local HA, the cluster name must be unique within the LAN. |
||
Type of fencing device configured for node running the installation. (For information about supported fencing devices and information you may need to provide to the installation script, see supported fencing methods in Fencing Options.) |
||
Hostname of fencing device configured for the node running the installation (for some fencing devices, can be an IP address). |
||
Login name for fencing device configured for node running the installation. |
||
Password for fencing device configured for node running the installation. |
||
Type of fencing device configured for second cluster node. (For information about supported fencing devices and information you may need to provide to the installation script, see supported fencing methods in Fencing Options.) |
||
Hostname of fencing device configured for second cluster node (for some fencing devices, can be an IP address). |
||
Login name for fencing device configured for second cluster node. |
||
Password for fencing device configured for second cluster node. |
||
| ort and the password for cluster web interface. LUCI_PORT must be available and should not be in Prime Network debug range: or in Prime Network AVM port range: |
||
Step 5![]() Configure the embedded database by running the add_emdb_storage.pl utility. In the following, NETWORKHOME is the Prime Network installation directory (/export/home/ pnuser by default).
Configure the embedded database by running the add_emdb_storage.pl utility. In the following, NETWORKHOME is the Prime Network installation directory (/export/home/ pnuser by default).
b.![]() Change directories to NETWORKHOME /Main/scripts/embedded_db and enter the following command:
Change directories to NETWORKHOME /Main/scripts/embedded_db and enter the following command:
Enter the number corresponding to the estimated database profile that meets your requirement. For more information, contact your Cisco representative and obtain the Prime Network Capacity Planning Guide.
c.![]() Insert the event and workflow archiving size in days. If you are not sure what to choose, take the default.
Insert the event and workflow archiving size in days. If you are not sure what to choose, take the default.
When you are done, validate the installation by following the steps in Verifying the Local Redundancy Setup.
Troubleshooting the Local Redundancy Installation
1. Problem : Installation fails.
Solution : Please review the following:
- Make sure all the necessary ports for installation are free, otherwise installation prerequisite verification returns an error that a needed port is blocked.
- For a virtual machine, if the installation prerequisite verification returns an error that swap space is insufficient, you can override the message and continue the installation by adding the following entry into the auto_install_RH.ini file.
Note![]() Changing the Override Swap value to True is not recommended because a Prime Network service might not function correctly without the required swap space.
Changing the Override Swap value to True is not recommended because a Prime Network service might not function correctly without the required swap space.
- If the failure occurs because a parameter needs to change, save the auto_install_RH.ini file to a temporary directory, then remove the old RH_ha directory and files. After you remove the old directory and files, redeploy the RH_ha.zip file. You must do this because installation changes the template files. However, after correcting the incorrect parameters, you can use the old auto_install_RH.ini file so you do not have to enter the correct input parameters again.
- If a local service (network/oracle_db services) in a local redundancy configuration fails, RHCS will try to stop, unmount, mount, then start the service locally. If this does not succeed, RHCS will automatically try to relocate the service to the standby node.
- If the local redundancy cluster nodes lose connection to each other, they try to fence each other. The node that succeeds starts the cluster services.
- If a local redundancy service enters a stopped state and does not start automatically on either node, you can start the service using the RHCS web or CLI interface. Before you do this, review the cluster log located in the /var/log/messages.
- When you run the install_Prime_HA.pl script log files are created. These are located in tmp/RH_ha.
- If the Prime Network file replication (not the Oracle database) in a geographical redundant configuration fails, verify the root cron jobs on both the primary and remote sites. The cron list and scripts run by the crons are located in the /var/adm/cisco/prime-network/scripts/ha/rsync directory.
Note![]() If you need to reinstall an embedded database in a directory that previously contained an embedded database, you must manually remove the database. If you do not do this, the installation will fail.
If you need to reinstall an embedded database in a directory that previously contained an embedded database, you must manually remove the database. If you do not do this, the installation will fail.
2. Problem : PN service relocation fails.
Description : This occurs when the unmount operation fails.
Solution : Cisco Advanced Malware Protection (AMP) service has to be disabled to resolve this issue. Follow the below mentioned steps:
1.![]() Check the status of Cisco AMP service. Execute the following command:
Check the status of Cisco AMP service. Execute the following command:
2.![]() If Cisco AMP is enabled, execute the following commands to disable it:
If Cisco AMP is enabled, execute the following commands to disable it:
3.![]() Perform service relocation.
Perform service relocation.
4.![]() Re-enable Cisco AMP service after relocating the services. Execute the following commands:
Re-enable Cisco AMP service after relocating the services. Execute the following commands:
Verifying the Local Redundancy Setup
To verify the installation, perform the verification steps in Table 3-7 . After you have verified the setup, proceed to Post-Installation Tasks for Local Redundancy.
Post-Installation Tasks for Local Redundancy
After you have validated the installation, perform these post-installation tasks:
- Updating the Database Host in the Registry (Only for NAT)
- Configuring the RHCS Web Interface (Optional)
Updating the Database Host in the Registry (Only for NAT)
If you are using network address translation (NAT) with the Cisco Prime Network Vision client, update the database host in the Prime Network registry to contain the hostname instead of the IP address.
Complete the following mandatory steps after the Cisco Prime Network 5.2 gateway installation or upgrade is complete and the system is up and running.
Note![]() If you already use a hostname instead of an IP address, you do not have to repeat this procedure.
If you already use a hostname instead of an IP address, you do not have to repeat this procedure.
In the following procedure, NETWORKHOME is the Prime Network installation directory (/export/home/ pnuser by default).
Step 1![]() Before changing the hostname, verify that the Windows client workstations have the correct Domain Name System (DNS) mapping.
Before changing the hostname, verify that the Windows client workstations have the correct Domain Name System (DNS) mapping.
Step 2![]() From NETWORKHOME /Main, enter the following commands:
From NETWORKHOME /Main, enter the following commands:
During switchover, you should unset the entries in the site.xml file and then reset using the following commands:
You can also change the FQDN in all nodes of persistency.xml.
Step 3![]() Enter the following command to restart the Prime Network system:
Enter the following command to restart the Prime Network system:
Configuring the RHCS Web Interface (Optional)
The RHCS web interface is configured during the install process. Use the information provided in this section only if you decide to change the configuration of the web interface at a later stage or if the web interface was not configured during the installation process.
The RHCS “luci” web interface allows you to configure and manage storage and cluster behavior on remote systems. You will use it to manage the Prime Network gateway HA. Before you begin this procedure, you should have the Red Hat Conga User Manual. It can be obtained at:
http://sources.redhat.com/cluster/conga/doc/user_manual.html
If your fencing device is supported by RHCS but not listed in Fencing Options, that is, you chose the Manual fencing option during the installation, manually configure the device using the Red Hat fencing configuration documentation. This can be obtained at:
http://docs.redhat.com/docs/en-US/Red_Hat_Enterprise_Linux/5/pdf/Configuration_Example_-_Fence_Devices/Red_Hat_Enterprise_Linux-5-Configuration_Example_-_Fence_Devices-en-US.pdf
Note![]() The following procedure provides the general steps to configure the luci interface. See the Red Hat Conga User Manual for details on performing steps in this procedure.
The following procedure provides the general steps to configure the luci interface. See the Red Hat Conga User Manual for details on performing steps in this procedure.
Note![]() The RHCS web interface must be configured for both servers in the local redundant dual-node cluster.
The RHCS web interface must be configured for both servers in the local redundant dual-node cluster.
Step 1![]() As root user, run the following command and enter the needed details:
As root user, run the following command and enter the needed details:
Step 2![]() Edit /etc/sysconfig/luci to change the default port to an available port. (The default 8084 port is used by Prime Network.) For example:
Edit /etc/sysconfig/luci to change the default port to an available port. (The default 8084 port is used by Prime Network.) For example:
Note![]() The ports must be available and should not be in Prime Network debug range (60000 <= X < 61000) or in Prime Network avm port range (2000 <= X < 3000 or 8000 <= X < 9000)
The ports must be available and should not be in Prime Network debug range (60000 <= X < 61000) or in Prime Network avm port range (2000 <= X < 3000 or 8000 <= X < 9000)
Step 3![]() As the root user, enter:
As the root user, enter:
Step 4![]() Enter the web interface using the following link:
Enter the web interface using the following link:
From the RHCS web interface you can stop, start, and relocate the Prime Network and oracle_db services managed by the cluster.
Step 5![]() In the luci web interface, add the cluster that was configured by the Prime Network installation. See the Red Hat Conga User Manual for details on performing the following:
In the luci web interface, add the cluster that was configured by the Prime Network installation. See the Red Hat Conga User Manual for details on performing the following:
Step 6![]() If your fencing device is supported by RHCS but not listed in Fencing Options, use the Red Hat fencing configuration guide to configure the device.
If your fencing device is supported by RHCS but not listed in Fencing Options, use the Red Hat fencing configuration guide to configure the device.
Note![]() If you provision a new fencing device, set it as the primary fencing method. The manual fencing agent should be kept as the backup fencing method.
If you provision a new fencing device, set it as the primary fencing method. The manual fencing agent should be kept as the backup fencing method.
Maintaining Local Redundancy
After the local redundancy cluster is deployed, failovers are automatic. In case of a single service failure, the cluster will attempt to restart the service. If the retries fail, the service will be relocated to the second node and started on that node. This does not impact the other service in the cluster.
Note![]() For complete redundancy, a configuration with no single point of failure is recommended. See the RHCS documentation for recommended configurations.
For complete redundancy, a configuration with no single point of failure is recommended. See the RHCS documentation for recommended configurations.
- Monitoring Log Messages
- Monitoring Cluster Status Using the CLI
- Monitoring Cluster Status Using the GUI
- Managing the Local Redundancy Cluster
- Manually Fencing
Monitoring Log Messages
The RHCS log messages provide information about cluster-related issues, such as service failure.
Every 30 seconds, RHCS issues status commands to check the Prime Network, Oracle, and Oracle listener processes. These messages are logged to /var/log/messages and can be viewed by the root user (or from the RHCS web GUI). The following are some example messages.
Monitoring Cluster Status Using the CLI
You can use the clustat command checks a cluster’s members and overall status.
As the root user, enter the following command to verify the cluster and services are running:
In the following example, the cluster name is ana_cluster and hostname.cisco.com is the node from which the command was run.
Monitoring Cluster Status Using the GUI
The RHCS web interface is automatically configured by the Prime Network installation script. If the interface was not configured during the installation process, use the procedure in Configuring the RHCS Web Interface (Optional) section to configure RHCS Web GUI. For details on how to use the web GUI, see the appropriate RHCS documentation.
- Check the cluster status, including the status of each service and the node each service is running on.
- Initiate a switchover of a service to the other node (relocate the service from the Services area of the GUI).
You can connect to the RHCS web interface by entering the following in the address field of your browser: https:// cluster-node-hostname : port /luci.
Managing the Local Redundancy Cluster
You can use clusvcadm command to check the version of the RHCS used on the cluster, stop, restart the cluster services and so on. To manage the cluster from the CLI, enter:
[root@hostname RH_ha] clusvcadm
Table 3-8 shows the RHCS clusvcadm command options to manage the cluster.
|
|
|
|---|---|
To restart Prime Network, Oracle, or (if installed) Operations Reports application processes, use the following procedure.
Step 1![]() Place the Prime Network and database RHCS services in maintenance mode (also called freezing) using the following command, where service is ana, oracle_db, or ifb.
Place the Prime Network and database RHCS services in maintenance mode (also called freezing) using the following command, where service is ana, oracle_db, or ifb.
Step 2![]() Confirm that the services are in maintenance mode. Run clustat and verify that the output shows the service followed by a [Z], which indicates the service is in maintenance mode (frozen). When the services are frozen, the cluster does not monitor them.
Confirm that the services are in maintenance mode. Run clustat and verify that the output shows the service followed by a [Z], which indicates the service is in maintenance mode (frozen). When the services are frozen, the cluster does not monitor them.
Note![]() If you attempt to restart either the Prime Network, Oracle, or Infobright applications without freezing the RHCS process, the cluster may detect that the services are down and attempt to restart them.
If you attempt to restart either the Prime Network, Oracle, or Infobright applications without freezing the RHCS process, the cluster may detect that the services are down and attempt to restart them.
Step 3![]() After confirming that the ana, oracle_db, and ifb cluster configured services are frozen, use the normal application commands to stop Prime Network and Oracle.
After confirming that the ana, oracle_db, and ifb cluster configured services are frozen, use the normal application commands to stop Prime Network and Oracle.
Step 4![]() After restarting the Prime Network, Oracle, and Infobright applications, move the RHCS services out of freeze mode and reinitiate the cluster’s monitoring of the ana and oracle services:
After restarting the Prime Network, Oracle, and Infobright applications, move the RHCS services out of freeze mode and reinitiate the cluster’s monitoring of the ana and oracle services:
Manually Fencing
During the installation of the RHCS solution, you are prompted to select one of three fencing options. You can reconfigure the fencing choice at any time using the RHCS web interface or other RHCS tools. If you choose manual fencing, you must disconnect the node and storage when a problem occurs (either by disconnecting the node and storage by hand or by using another fencing agent).
Note![]() We recommend that manual fencing only be used on a temporary basis. If you use manual fencing, it is your responsibility to make sure that when an error occurs, the node and the storage are disconnected during the cluster workflow. We recommend that manual fencing only be used on a temporary basis and as a backup for your chosen fencing agent.
We recommend that manual fencing only be used on a temporary basis. If you use manual fencing, it is your responsibility to make sure that when an error occurs, the node and the storage are disconnected during the cluster workflow. We recommend that manual fencing only be used on a temporary basis and as a backup for your chosen fencing agent.
If you are using manual fencing and an error occurs that requires fencing intervention, a message is printed to /var/log/messages advising you to run the fence_ack_manual command on the gateway server.
- Before disconnecting the faulty node, remove the cman and rgmanager services from the automatic startup sequence. This is to avoid the failure when the restored node joins the cluster. You can remove these services by using the commands,
Use the procedure below to disconnect the faulty node.
Step 1![]() Log into the gateway server as root and enter the command using the following syntax.
Log into the gateway server as root and enter the command using the following syntax.
where n nodename indicates the node that has been disconnected from storage.
Note![]() For Red Hat 6.x, use only fence_ack_manual nodename.
For Red Hat 6.x, use only fence_ack_manual nodename.
Step 2![]() Continue with the confirmation message to disconnect the faulty node from the storage.
Continue with the confirmation message to disconnect the faulty node from the storage.
Uninstalling Local Redundancy
To uninstall local redundancy setup, follow the procedure provided below. The procedure also removes the operations reports if installed.
Step 1![]() Determine the active and standby cluster nodes using the following command:
Determine the active and standby cluster nodes using the following command:
Step 2![]() Stop cluster services on the standby nodes using the following command:
Stop cluster services on the standby nodes using the following command:
Step 3![]() Uninstall the Prime Network on the standby nodes by choosing Yes to all the prompts. The process uninstalls the Prime Network even if the disks are not mounted on the secondary nodes.
Uninstall the Prime Network on the standby nodes by choosing Yes to all the prompts. The process uninstalls the Prime Network even if the disks are not mounted on the secondary nodes.
/var/adm/cisco/prime-network/reg/current/uninstall.pl
Step 4![]() Verify if the configuration file (cluster.conf) located at /etc/cluster/cluster.conf is either deleted or rolled back to the state before the Prime Network is installed.
Verify if the configuration file (cluster.conf) located at /etc/cluster/cluster.conf is either deleted or rolled back to the state before the Prime Network is installed.
Step 5![]() Stop the cluster services on the active node using the following commands:
Stop the cluster services on the active node using the following commands:
Note![]() Verify if ana/oracle disks are not mounted by using the command df -h
Verify if ana/oracle disks are not mounted by using the command df -h
Step 6![]() Manually remount the filesystems used by the cluster on the correct mounting points. This is because shutting down the cluster results in dismounting of all filesystems related to the cluster services.
Manually remount the filesystems used by the cluster on the correct mounting points. This is because shutting down the cluster results in dismounting of all filesystems related to the cluster services.
Step 7![]() Uninstall Prime Network on the active node using the following command.
Uninstall Prime Network on the active node using the following command.
/var/adm/cisco/prime-network/reg/current/uninstall.pl
Step 8![]() Verify if the configuration file (cluster.conf) located at /etc/cluster/cluster.conf is either deleted or rolled back to the state before the Prime Network is installed.
Verify if the configuration file (cluster.conf) located at /etc/cluster/cluster.conf is either deleted or rolled back to the state before the Prime Network is installed.
Installing and Configuring PN-IL with Local Redundancy
This section explains how to install and configure the Prime Network Integration Layer (PN-IL) 1.2 with a Prime Network gateway local redundancy deployment. It also explains how to integrate the deployment with Cisco Prime Central. For information on the Prime Central releases with which you can install PN-IL 1.2, see the Cisco Prime Network 5.2 Release Notes.
These topics provide the information you will need to install and configure PN-IL local redundancy:
- Installation DVD
- Steps for Installing PN-IL with Local Redundancy
- Installing PN-IL on a Prime Network Server (Local Redundancy)
- Configuring PN-IL on a Prime Network Gateway (Local Redundancy)
- Disabling the PN-IL Health Monitor
If you want to migrate an existing standalone installation of PN-IL (with local redundancy) to suite mode, you can use the procedure in Configuring PN-IL with Prime Central (Suite Mode with Local Redundancy).
Installation DVD
The PN-IL high availability files are provided on the Prime Network installation DVD named Disk 1: New Install DVD. Disk 2 contains the tar file sil-esb-2.2.0.tar.gz, which contains the PN-IL installation files and scripts, including:
Steps for Installing PN-IL with Local Redundancy
Table 3-9 provides the basic steps you must follow to set up local redundancy for PN-IL.
Note![]() Install PN-IL only on the primary server.
Install PN-IL only on the primary server.
If you want to migrate an existing standalone installations of PN-IL (with local redundancy) to suite mode, see the procedure in Configuring PN-IL with Prime Central (Suite Mode with Local Redundancy).
|
|
|
|
|
|
|---|---|---|---|---|
Collect server details, so that you have all information handy prior to installation. |
|
|||
Installing PN-IL on a Prime Network Server (Local Redundancy) |
||||
Configure PN-IL (in standalone or suite mode) and unfreeze RHCS. |
Configuring PN-IL on a Prime Network Gateway (Local Redundancy) |
|||
Installing PN-IL on a Prime Network Server (Local Redundancy)
Make sure Prime Network is installed and running on the cluster.
In the following procedure, $ANAHOME is the pnuser environment variable for the Prime Network installation directory (/export/home/ pnuser by default). To install PN-IL on a server running Prime Network local redundancy software:
Step 1![]() On the primary cluster node (P1), log in as root and freeze the ana service.
On the primary cluster node (P1), log in as root and freeze the ana service.
Note![]() The cluster server should be the active node where the ana service is running.
The cluster server should be the active node where the ana service is running.
Step 2![]() As pnuser (the operating system user for the Prime Network application), log into the active node where you froze the ana service.
As pnuser (the operating system user for the Prime Network application), log into the active node where you froze the ana service.
Step 3![]() Create an installation directory for PN-IL.
Create an installation directory for PN-IL.
For example, if the Prime Network installation directory was /export/home/pn41, you would run this command to create an installation directory called pnil:
Step 4![]() Copy the installation files from the installation DVD, extract them, and start the installation script. These examples use the PN-IL installation directory named pnil.
Copy the installation files from the installation DVD, extract them, and start the installation script. These examples use the PN-IL installation directory named pnil.
a.![]() Copy the PN-IL installation tar file from Disk 2 to the directory you created in Step 3.
Copy the PN-IL installation tar file from Disk 2 to the directory you created in Step 3.
b.![]() Change to the directory you created in Step 3 and extract the PN-IL installation tar:
Change to the directory you created in Step 3 and extract the PN-IL installation tar:
c.![]() Change to directory where the installation tar files were extracted and run the installation script:
Change to directory where the installation tar files were extracted and run the installation script:
Step 5![]() Reload the user profile using the following command:
Reload the user profile using the following command:
Next, perform the necessary configuration steps that are described in Configuring PN-IL on a Prime Network Gateway (Local Redundancy).
Configuring PN-IL on a Prime Network Gateway (Local Redundancy)
If you are using Prime Network in standalone mode—that is, without Prime Central—configure PN-IL using the instructions in Configuring PN-IL with Prime Network (Standalone Mode with Local Redundancy).
If you are using Prime Network with Prime Central, configure PN-IL as described in Configuring PN-IL with Prime Central (Suite Mode with Local Redundancy).
Configuring PN-IL with Prime Network (Standalone Mode with Local Redundancy)
In standalone mode, Prime Network is not integrated with Prime Central and can independently expose MTOSI and 3GPP web services to other OSS/applications. In the following procedure, $PRIMEHOME is the pnuser environment variable for the PN-IL installation directory you created in Installing PN-IL on a Prime Network Server (Local Redundancy).
Step 1![]() As pnuser, configure PN-IL in standalone mode using the following command:
As pnuser, configure PN-IL in standalone mode using the following command:
itgctl config 1 --anaPtpServer 192.0.2.22 --anaPtpUser root --anaPtpPw myrootpassword --authURL https://192.0.2.22:6081/ana/services/userman
Step 2![]() Start PN-IL by using the following command:
Start PN-IL by using the following command:
Step 3![]() Log out as pnuser and log back in as the operating system root user.
Log out as pnuser and log back in as the operating system root user.
Step 4![]() Unfreeze the ana service.
Unfreeze the ana service.
Next, disable the PN-IL health monitor as described in Disabling the PN-IL Health Monitor.
Configuring PN-IL with Prime Central (Suite Mode with Local Redundancy)
Note![]() Use this procedure only after installing the PN-IL as described in Installing and Configuring PN-IL with Local Redundancy.
Use this procedure only after installing the PN-IL as described in Installing and Configuring PN-IL with Local Redundancy.
When Prime Network is in suite mode, it is integrated with Prime Central. This procedure explains how to integrate PN-IL with a deployment of Prime Central that is using gateway local redundancy. You can use this procedure for:
- New installations of PN-IL with local redundancy.
- Existing standalone installations of PN-IL with local redundancy, that you want to move from standalone to suite mode.
Figure 3-2 illustrates the deployment of local redundancy in Suite Mode.
Figure 3-2 Local Redundancy Suite Mode
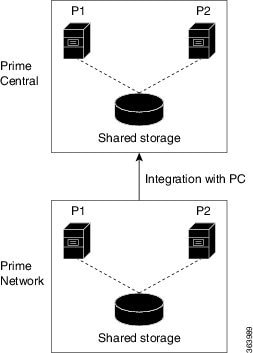
In the following procedure, $PRIMEHOME is the pnuser environment variable for the PN-IL installation directory you created in Installing PN-IL on a Prime Network Server (Local Redundancy).
Make sure Prime Network is in suite mode. For information on integrating Prime Network with Prime Central, refer to the Cisco Prime Central Quick Start Guide.
Step 1![]() Edit the necessary integration files and run the integration script:
Edit the necessary integration files and run the integration script:
a.![]() Log into the Prime Network primary gateway server as pnuser and change to the $PRIMEHOME/integration directory.
Log into the Prime Network primary gateway server as pnuser and change to the $PRIMEHOME/integration directory.
b.![]() Edit the ILIntegrator.prop file and change the value of the ‘HOSTNAME’ property to ana-cluster-ana, which is the fixed name for the Prime Network cluster server.
Edit the ILIntegrator.prop file and change the value of the ‘HOSTNAME’ property to ana-cluster-ana, which is the fixed name for the Prime Network cluster server.
c.![]() Execute the following integration script to integrate PN-IL into the deployment:
Execute the following integration script to integrate PN-IL into the deployment:
Note![]() When you run DMIntegrator.sh, you must exactly follow the format below or the script will fail.
When you run DMIntegrator.sh, you must exactly follow the format below or the script will fail.
DMIntegrators.sh uses these variables. You must enter them in this exact order.
Step 2![]() Reload the user profile:
Reload the user profile:
Step 4![]() Log out as pnuser and log back in as the operating system root user.
Log out as pnuser and log back in as the operating system root user.
Step 5![]() Unfreeze the ana service.
Unfreeze the ana service.
Next, disable the PN-IL health monitor as described in Disabling the PN-IL Health Monitor.
Disabling the PN-IL Health Monitor
When PN-IL is installed in a local redundancy deployment, the RHCS cluster service monitors PN-IL’s status. Therefore, you should disable the PN-IL health monitor.
To disable the PN-IL health monitor, log in as pnuser and execute the following command:
 Feedback
Feedback