Cisco 12000 Series Internet Router Parity Error Fault Tree
Available Languages
Contents
Introduction
This document explains the steps to troubleshoot and isolate a failing part or component of the Cisco 12000 Series Internet Router after you encounter a variety of parity error messages.
Note: This document does not cover the cause of parity errors. If you are interested in a more concise definition of parity errors (also known as Single Event Upsets - SEUs) and their possible cause, we recommend that you read the documents linked from Increasing Network Availability.
Before You Begin
Conventions
For more information on document conventions, see the Cisco Technical Tips Conventions.
Prerequisites
Before proceeding with this document, we recommend that you read the following documents:
Components Used
The information in this document is based on the software and hardware versions below.
-
Cisco 12000 Series Internet Router
-
All versions of Cisco IOS® software
The information presented in this document was created from devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. If you are working in a live network, ensure that you understand the potential impact of any command before using it.
Overview
Most of the Cisco 12000 Series Internet Router route processors and line cards include Error Code Correction (ECC) functionality. There are, however, some existing line cards in the field that do not have the ECC capability. ECC functionality only covers the RAM or Synchronous Dynamic RAM (SDRAM) memory on the cards. The rest is not protected by ECC.
Here is a comparison of ECC functionality for line cards used with the Cisco 12000:
-
All Engine 2 and later cards have ECC functionality.
-
Engine 1 cards changed to ECC after FCS.
-
Engine 0 cards do not have ECC functionality.
-
Some cards can be upgraded to similar products that integrate the ECC functionality.
The table below lists the products that have the ECC functionality:
| Non-ECC Products | ECC Products |
|---|---|
| GRP(=) | GRP-B(=) |
| GE-SX/LH-SC(=) | GE-GBIC-SC-B(=) |
| GE-GBIC-SC-A(=) | GE-GBIC-SC-B(=) |
| 8FE-FX-SC(=) | 8FE-FX-SC-B(=) |
| 8FE-TX-RF45(=) | 8FE-TX-RJ45-B(=) |
| 6DS3-SMB(=) | 6DS3-SMB-B(=) |
| 12DS3-SBM(=) | 12DS3-SMB-B(=) |
| OC12/SRP-IR-SC(=) | OC12/SRP-IR-SC-B(=) |
| OC12/SRP-MM-SC(=) | OC12/SRP-mm-SC-B(=) |
| OC12/SRP-LR-SC(=) | OC12/SRP-LR-SC-B(=) |
Note: -B and ECC are independent. -B means the product is a second major orderable revision of the board. In some cases, this was the revision for ECC.
Cisco offers a Technology Migration Plan (TMP) which allows you to upgrade a non-ECC board to a new ECC board. A credit will be applied to the purchase of the new ECC board in exchange for the non-ECC board.
Gigabit Route Processor (GRP) Parity Error Fault Tree Analysis
The flowchart below helps you determine which component of the Cisco 12000 Series Internet Router is responsible for parity/Error Code Correction (ECC) error messages on the Gigabit Route Processor (GRP).
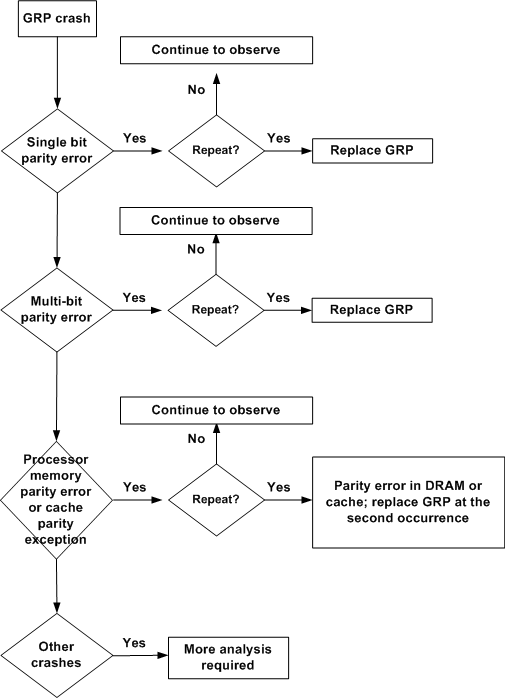
Note: Capture and record the show tech-support output and console logs, and collect all crashinfo files during parity/ECC error events.
Line Card Parity Error Fault Tree Analysis
The flowchart below helps you determine which component of a Cisco 12000 Series Internet Router line card is responsible for parity/Error Code Correction (ECC) error messages:
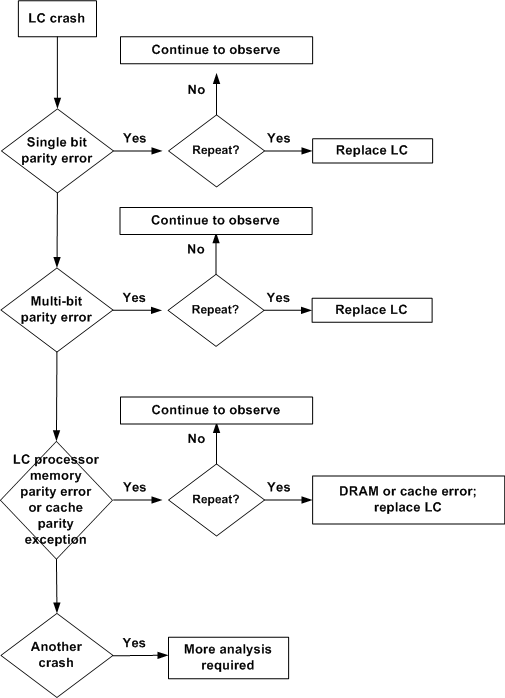
Note: Whenever a line card experiences a parity/ECC error event, collect as much information as possible (see Troubleshooting Line Card Crashes on the Cisco 12000 Series Internet Router for details).
The Cisco 12000 Series Internet Router recovers from parity errors in other line card memories (SDRAM and SRAM) without crashing.
Parity/ECC Errors in the Cisco 12000 Series Gigabit Route Processor
Data with bad parity can be reported by several of the parity-checking devices for any read or write operation on the Cisco 12000 Series Internet Router.
The GRP-B and the PRP use Single Bit Error Correction and Multi-bit Error Detection ECC to shared memory (SDRAM). A single bit error in SDRAM is corrected automatically, and the system continues to operate as normal.
Single-Bit Errors (SBEs)
PRP and GRP-B have the enhanced Dynamic RAM (DRAM) controller which supports ECC. Therefore, they can correct single-bit errors and report multi-bit errors. Correction of a single-bit error looks like this:
%Tiger-3-SBE: Single bit error detected and corrected at <address>
SBEs are corrected by the Error Correction Circuit and do not affect the functionality of the GRP-B or the PRP. No action is required for single-bit errors, unless they happen frequently. In that case, it is advisable to replace the processor board.
Multi-Bit Errors (MBEs)
The detection of a multi-bit error is reported through a Bus Error Exception or a CPU Cache Parity Error Exception.
Processor Memory Parity Errors (PMPE)
A Processor Memory Parity Error message is reported if the CPU detects a parity error when accessing the processor's external cache (L3 on the GRP) through the SysAD bus, or either of the CPU internal cache memories (L1 or L2). Table 1 lists examples of the messages that would be printed out for each type of cache parity error:
Table 1: Cache Parity Error Location
| Location of Parity Error | Error Message |
|---|---|
| L1 Instruction Cache | Error: Primary, instr cache, fields: data |
| L1 Data Cache | Error: Primary, data cache, fields: data |
| L2 Instruction Cache | Error: SysAD, instr cache, fields: data |
| L2 Data Cache | Error: SysAD, data cache, fields: data |
| L3 Instruction Cache | Error: SysAD, instr cache, fields: 1st dword |
| L3 Data Cache | Error: SysAD, data cache, fields: 1st dword |
Example:
The first line of the error message indicates the location of the parity error, and can be any location listed in Table 1. In this example, the location is L3 Instruction Cache.
Error: SysAD, instr cache, fields: data, 1st dword
Physical addr(21:3) 0x000000,
virtual addr 0x6040BF60, vAddr(14:12) 0x3000
virtual address corresponds to main:text, cache word 0
Low Data High Data Par Low Data High Data Par
L1 Data: 0:0xAE620068 0x8C830000 0x00 1:0x50400001 0xAC600004 0x01
2:0xAC800000 0x00000000 0x02 3:0x1600000B 0x00000000 0x01
Low Data High Data Par Low Data High Data Par
DRAM Data: 0:0xAE620068 0x8C830000 0x00 1:0x50400001 0xAC600004 0x01
2:0xAC800000 0x00000000 0x02 3:0x1600000B 0x00000000 0x01
The output of the show version should be similar to this:
...System was restarted by processor memory parity error at PC 0x602310D0, address 0x0 at 03:18:21 GMT Sun Oct 27 2002 ...
From the show context output, you can see that the system was restarted by a Cache Parity Exception:
Router#show context slot 11 CRASH INFO: Slot 11, Index 1, Crash at 19:08:07 CST Thu Nov 14 2002 VERSION: GS Software (GSR-P-M), Version 12.0(22)S1, EARLY DEPLOYMENT RELEASE SOFTWARE (fc1) TAC Support: http://www.cisco.com/tac Compiled Mon 16-Sep-02 17:36 by nmasa Card Type: Route Processor, S/N LC uptime was 0 minutes. System exception: sig=20, code=0xE42F3E4B, context=0x52CF3D44 System restarted by a Cache Parity Exception STACK TRACE: -Traceback= 5020453C 500E5E24 5010E6DC 5015F89C 501E9F6C 501E9F58 ...
Replace the GRP or the PRP after a second failure.
%GRP-3-PARITYERR Error Message
The following message may appear in the console output:
SEC 7: %GRP-3-PARITYERR: Parity error detected in the fabric buffers. Data (8)
This message means that a parity error has been detected by the fabric interface hardware on the GRP. The hex number indicates the error interrupt vector. This usually indicates a hardware problem on the GRP that reports the error (in this case, slot 7). The faulty GRP should be replaced on the second occurrence of a similar issue.
%PRP-3-SBE_DATA: Bad Data [hex] [hex] ECC rec [hex] calc [hex]
This error message displays when the router receives data with a bad parity.
Data with bad parity is reported by several of the parity-checking devices for any read or write operation performed on the Cisco 12000 Series Internet Router.
The PRP uses Single Bit Error Correction and Multi-bit Error Detection ECC to share memory (SDRAM). A single bit error in SDRAM is corrected automatically, and the system continues to operate as normal.
Single-Bit Errors (SBE) are corrected by the Error Correction Circuit (ECC) and do not affect the functionality of the PRP. No action is required for single-bit errors unless they happen frequently.
If the error happens frequently, it is advisable to replace the processor board.
Parity/ECC Errors in the Cisco 12000 Series Line Cards
SDRAM ECC Errors
-
SDRAM Single Bit Error-Correcting Code (ECC) Errors
A single-bit error is a single bit of data that is incorrect in a word read from memory. For SBEs, the error can be corrected without disruption to operations.
Single-bit errors are detected and the corrected data is presented. For instance, single-bit errors are reported as follows on Engine 4/4+:
SLOT 6:Jul 19 07:37:34: %TX192-3-SDRAM_SBE: Error=0x2 - DIMM1 Syndrome=0x7600 Addr=0xBEA09 Data bit80-Traceback= 401C8C9C 401C9508 401CDE08 401CDE40 4007F674 4009ED0C 4009ECF8
SBEs are corrected by the Error Correction Circuit and do not affect functionality of the line card. No action is required for single-bit errors, unless they occur frequently. In this case, it is advisable to replace the line card.
-
SDRAM Multi-bit ECC Errors
A multi-bit error is when more than one bit is incorrect in the same word. For MBEs, the error is detected and the line card crashes. The occurrence of SBEs and MBEs is very rare.
Here is an example of the message printed to the console in response to a multi-bit ECC error in SDRAM:
SLOT 5:Jul 25 16:58:51: %MCC192-3-SDRAM_SBE: Error=0x808 - DIMM0 Syndrome=0x31000000 Addr=0x81034 Data bit120 -Traceback= 401C8C9C 401C9508 40450018 400BF7D4 SLOT 5:Jul 25 16:58:51: %MCC192-3-SDRAM_MBE: Error=0x808 - DIMM0 Syndrome=0x18000000 Addr=0x80834 -Traceback= 401C8D88 401C9508 40450018 400BF7D4
MBEs cannot be corrected by ECC, and cause the line card to crash. The line card will then be reloaded and brought back into normal operation by the route processor.
Field diagnostics can be used to check line card memory for MBEs. MBEs are detected by field diagnostics as memory errors. Below is an example of a board that has experienced a multi-bit error on the TX SDRAM that failed field diagnostics:
FDIAG_STAT_IN_PROGRESS(5): test #12 TX SDRAM Marching Pattern FD 5> RIM: FD 5> TX Registers FD 5> INT_CAUSE_REG = 0x00000680 FD 5> Unexpected L3FE Interrupt occured. FD 5> ERROR: TX BMA Asic Interrupt Occured FD 5> *** 0-INT: External Interrupt *** FDIAG_STAT_DONE_FAIL(5) test_num 12, error_code 1 Field Diagnostic: ****TEST FAILURE**** slot 5: last test run 12, TX SDRAM Marching Pattern, error 1 Field Diag eeprom values: run 5 fail mode 1 (TEST FAILURE) slot 5 last test failed was 12, error code 1
If you have a QOC48 or a OC192 line card, refer to this Field Notice: QOC48/OC192 SBEs/MBEs. Otherwise, you should replace the line card after a second failure.
Cache Parity Exceptions
Check the value of the sig= field in the show context slot [slot#] output:
Router#show context slot 4
CRASH INFO: Slot 4, Index 1, Crash at 04:28:56 EDT Tue Apr 20 1999
VERSION:
GS Software (GLC1-LC-M), Version 11.2(15)GS1a, EARLY DEPLOYMENT RELEASE
SOFTWARE (fc1)
Compiled Mon 28-Dec-98 14:53 by tamb
Card Type: 1 Port Packet Over SONET OC-12c/STM-4c, S/N CAB020500AL
System exception: SIG=20, code=0xA414EF5A,
context=0x40337424
System restarted by a Cache Parity Exception
Some cards based on the Engine 1 forwarding engine are susceptible to internal cache corruption issues when operating at very specific voltage and temperature conditions.
Cache Error Recovery Feature (CERF) is a software feature in Engine1 line cards that detects and corrects cache parity errors by flushing errors from the external CPU cache, and refreshing the cache line from DRAM. This feature provides intelligence in the CPU cache management algorithm that enables the CPU to recover from a cache memory parity error, preventing a line card crash without incurring a performance hit.
Note: CERF is on by default. The activity of this software Error Correction Code (ECC) can be monitored by the show controller cerf command. To turn the feature off, use the global configuration command no service cerf.
See Field Notice: Cache Parity Error on GSR 1GE Card for additional information.
To determine on which forwarding engine the line card is based, see How can I determine what engine card is running in the box? from the Cisco 12000 Series Internet Router: Frequently Asked Questions document.
If the line card is based on Engine 1, the workaround is to upgrade the Cisco IOS software to a release which contains the Cache Error Recovery Feature (CERF). This feature was first available in Cisco IOS Software Release 12.0(21)S3. If it is still crashing by Cache Parity Exception, then the line card needs to be replaced.
If the line card is based on another Engine type, you should replace the line card on the second occurrence of a similar crash.
Engine 0-based Line Card Error Messages
You may see the following message in the console logs:
SLOT 2:Oct 23 17:07:45.531 EST: %LC-3-L3FEERRS: L3FE DRAM error 12 address 41E9B9A0 SLOT 2:Oct 23 17:07:45.531 EST: %LC-3-L3FEERR: L3FE error: rxbma 0 addr 0 txbma 0 addr 0 dram 12 addr 41E9B9A0 io 0 addr 0 SLOT 2:Oct 23 17:07:45.531 EST: %GSR-3-INTPROC: Process Traceback= 40080BAC -Traceback= 40357084 40495D30 40496EE0 400CCF98
This message reports a CPU DRAM write parity error. L3FE stands for Layer 3 forwarding engine. The line card should be replaced at the second occurrence of a similar problem.
Engine 1-based Line Card Error Messages
Here are some error messages that you may encounter:
-
In the logs for a one-port Gigabit line card:
SLOT 5: %LCGE-3-INTR: TX GigaTranslator external interface parity error
For newer boards, one fix has been to replace the TX GigaTranslator ASIC with a field-programmable gate array (FPGA). At the second occurrence of a similar issue, the board should be replaced.
-
In the console output:
SLOT 6: %LC-3-ECC: Salsa ECC: About to handle ECC single bit error, ECC status = 2 DRAM error status = = 21 SLOT 6: %LC-3-L3FEERR: L3FE error: rxbma 0 addr 0 txbma 0 addr 0 dram 21 addr 200020 io 0 addr 0 SLOT 6: %LC-3-ECC: Salsa ECC: Addresses: Salsa returned =429BFDE8 correcting on = 429BFDE8 SLOT 6: %MEM_ECC-3-SBE: Single bit error detected and corrected at 0x429BFDE8 SLOT 6: %MEM_ECC-3-SYNDROME_SBE: 8-bit Syndrome for the detected Single-bit error: 0x8A SLOT 4: %MEM_ECC-3-SBE_HARD: Single bit *hard* error detected at 0x6299FB60 SLOT 1:Jun 10 05:29:47.690 EDT: %LC-3-ECC: Salsa ECC: About to handle ECC single bit error,ECC status = 0 DRAM error status =12 SLOT 6:Sep 26 15:18:01: %LC-3-SWECC: L2 event cleared: EPC = 0x40631CCC, CERR = 0xE40BB933, SysAD Addr = 1, total = 1 SLOT 0:Dec 7 13:48:11.480: %LC-3-SWECC_DATA: L2 event cleared: EPC = 0x400A8040, CERR = 0xA01DCE58, l1v = 0x41E3C20441E3C1C5, dv =0x41E3C1C441E3C204, SysAD Addr = 0, total = 1
These messages can be split into the following parts:
-
%LC-3-ECC: Salsa ECC - There is an error in the line card's L3FE ASIC.
-
%LC-3-L3FEERR - There is an error in the line card's L3FE ASIC reg. information.
-
%MEM_ECC-3-SBE - A single-bit correctable error was detected on a read from DRAM. The show memory ecc command can be used to dump single-bit errors logged thus far. This is the same as the %MEM_ECC-3-SBE_LIMIT error message.
-
%MEM_ECC-3-SYNDROME_SBE - The 8-bit syndrome for detected single-bit error. This value does not indicate the exact positions of the bits in error, but can be used to approximate their positions. This is the same as the %MEM_ECC-3-SYNDROME_SBE_LIMIT error message.
Basically, the line card reported a single-bit error and corrected it automatically. No action is required from your part, unless this occurs frequently. In this case, it is advisable to replace the line card.
-
%LC-3-SWECC_DATA - Indicates that a cache event has been corrected at LC in SLOT 0 by the Software Error Correction Code (SWECC).
-
-
Another message that you might encounter is:
SLOT 4: %MEM_ECC-3-SBE_HARD: Single bit *hard* error detected at 0x6299FB60
This message means that a single-bit uncorrectable error [hard error] was detected on a CPU read from DRAM. The show memory ecc command dumps the single-bit errors logged thus far and indicates detected hard error address locations.
Monitor the system using the show memory ecc command and replace the DRAM if there are too many occurrences of these errors.
Engine 2-based Line Card Error Messages
You may see the following error in the console output:
SLOT 6: %LC-6-PSAECC: An TLU SDRAM ECC correctable error occurred address 19C49FD SLOT 2:035610: Feb 26 13:09:13.628 UTC: %LC-6-PSAECC: An PLU SDRAM ECC correctable error occurred address 1956059
This means that the Packet Switching ASIC (PSA) ECC protected SDRAM has identified a correctable one-bit error. No action is required from your part, unless these messages occur frequently. In this case, it is advisable to replace the line card.
Engine 3-based Line Card Error Messages
You can see these errors in the console output:
SLOT 6:00:03:53: %PM622-3-SAR_SRAM_PARITY_ERR: (6/0): Parity error in Reassembly SAR SRAM address: 80000000.Resetting the port SLOT 3:00:00:53: %PM622-3- SAR_MULTIBIT_ECC_ERR: (3/0): Multi-bit ECC Uncorrectable error in SAR SDRAM address: 80000000. Resseting the port. SLOT 4:00:00:53: %PM622-3 SAR_SINGLE_BIT_ECC_ERR: (3/0): ECC corrected an error in SAR SDRAM address: 800000. SLOT 0:Jun 25 20:45:53 KST: %EE48-6-ALPHAECC: RX ALPHA: An PLU SDRAM ECC correctable error occured address 1000C254 SLOT 0:Jun 25 20:45:53 KST: %EE48-6-ALPHAECC2: RX ALPHA: An PLU SDRAM ECC multibit error occured at address 1000E254 SLOT 5:Nov 17 09:46:30.171: %EE48-6-ALPHA_PARITY: TX ALPHA: Transient SRAM64 parity corrected error 3E Data 0 100000 Parity bits 0 SLOT 10:Feb 21 16:55:36: %EE48-3-ALPHA_SRAM64_ERR: TX ALPHA: ALPHA_PST_RANGE_ERR error 11003F Data 0 0 Parity bits 0 SLOT 4:Jan 15 06:30:00.942 UTC: %EE48-2-GULF_TX_SRAM_ERROR: ASIC GULF: TX SRAM uncorrectable error detected. Details=0x0000 SLOT 0:Mar 16 19:50:22.464 cst: %EE48-4-QM_ZBT_PARITY: ToFab Address 0xB95E Data 0x1 SLOT 5:May 17 06:17:35.507: %EE48-4-QM_NON_ZBT_PARITY: ToFab Error 0x10000028 SLOT 5:May 17 06:17:53.883: %EE48-4-QM_ZBT_PARITY_TRANSIENT: FrFab Address 0x0 Data 0x7E SLOT 5:May 17 06:17:53.883: %EE48-4- GULF_RX_TB_PARITY_ERROR: ASIC GULF: RX telecom bus parity error on port 0 SLOT 1:Dec 13 00:27:42: %EE48-3-SRAM_PARITY: SRAM parity: Unable to find shadow 281B9EB4 SLOT 0:Aug 4 08:55:37: %EE48-3-QM_PARITY: FrFab Address 0x1859E Data 0x10 SLOT 0:Aug 4 08:55:37: %EE48-3-QM_ERROR: FrFab error register 0x80000.
Engine 4/4+-based Line Card Error Messages
-
You may encounter the following messages on Engine 4/4+-based line cards:
SLOT 4: %RX192-3-HINTR: status = 0x4000000, mask = 0x3FFFFFFF - Parity error on rx_pbc_mem. -Traceback= 401C37C0 403D8814 400BE1EC SLOT 4: %LC-3-ERR_INTR: Error interrupt occurred -Traceback= 400CE028 400C8DF0 40010A24
or
SLOT 3: %RX192-3-HINTR: status = 0x4000000, mask = 0x3FFFFFFF - Parity error on rx_pbc_mem. -Traceback= 406012E0 406972A0 400C555C %FIB-3-FIBDISABLE: Fatal error, slot 3: IPC failure
or
SLOT 13:Dec 5 07:30:15.272 cst: %HERA-6-PAM_ACL_SBE: PKT CNT MEM Syndrome=0x8 Addr=0x523C SLOT 2:00:03:41: %MCC192-6-RED_PARAM1_SBE: Parameter 1 - Single Bit Error detected and corrected Syndrome = 0x7, Address = 0x43, samebit No, diffbit No SLOT 2:00:03:41: %MCC192-6-RED_PARAM2_SBE: Parameter 1 - Single Bit Error detected and corrected Syndrome = 0x7, Address = 0x43, samebit No, diffbit No SLOT 5:Apr 26 11:56:08.160: %MCC192-3-SDRAM_MBE: Error=0x200 - DIMM1 Syndrome=0x3000 Addr=0x811C3 SLOT 10:Mar 6 05:05:26.965: %RX192-3-ADJ_MEM_MBE: phy addr 0x7905E648, offset 0xBCC9, old ecc 0x0, new ecc 0x0, bit -1, value 0x0 - MBE on Adjacency Memory.. SLOT 13:Dec 5 07:30:15.272 cst: %HERA-6-PAM_ACL_MBE: PKT CNT MEM Syndrome=0x8 Addr=0x523C SLOT 2:00:03:41: %MCC192-6-RED_PARAM1_MBE: Parameter 1 - Single Bit Error detected and corrected Syndrome = 0x7, Address = 0x43, samebit No, diffbit No SLOT 2:00:03:41: %MCC192-3-RED: Error=0x80000 - RED PARAM 1 ECC SBE Error. -Traceback= 405AF5E0 405B1CEC 406DFF7C 406E057C 400FC7E SLOT 2:00:03:41: %MCC192-6-RED_PARAM2_MBE: Parameter 1 - Single Bit Error detected and corrected Syndrome = 0x7, Address = 0x43, samebit No, diffbit No Sep 8 14:32:09 jst: %MEM_ECC-3-SYNDROME_SBE_LIMIT: 8-bit Syndrome for the detected Single-bit error: 0xD5
The symptoms for this issue include:
-
Cisco Express Forwarding on this line card gets disabled
-
The associated ports stay up/up
-
The line card might be automatically reset
If the line card does not reset, the workaround is to execute the microcode reload <slot> command:
This message does not always indicate a hardware issue with the RX192 module. Some Cisco IOS software bugs might produce this error message as a side-effect. If this message shows up only once, keep monitoring the board. The device will be reset. If the problem persists, the card will be automatically reset. Contact your Cisco Technical Support representative for assistance if this message persists.
-
-
The SBE events can be checked on the E4/E4+ with the show controllers mcc192 ecc command:
LC-Slot4#show controllers mcc192 ecc MCC192 SDRAM ECC Counters SBE = 0x0, MBE = 0x0 TX192 SDRAM ECC Counters SBE = 0x0, MBE = 0x0This reports on both RX and TX memory.
Engine 5/5+-based Line Card Error Messages
You can see these errors in the console output:
SLOT 1:Jun 26 20:45:53 KST: %EE192-6-WAHOOECC: RX WAHOO: An PLU SDRAM ECC correctable error occured address 20000254 SLOT 9:Sep 2 21:27:49.680 GMT+8: %MCC192-3-PKTMEM_SBE: Single bit error detected and corrected SLOT 14:Jul 18 07:19:24.637: RX_XBMA: 1-bit CPUIM_ECCERR1 error 0x2 SLOT 15:Jan 4 16:53:16.591: TX_XBMA: (1) QSRAM qinfo SBE detected. info: 0x82605455 SLOT 12:Dec 12 22:34:15: %EE192-4-BM_ERRSSS: FrFab BM BADDR ECC ERR info single bit error(s) corrected, error 8250F63E count: 2 SLOT 1:Nov 22 13:40:02 JST: %EE192-3-QM_ERROR: RX_XBMA OQLLM error error register 0x1 -Traceback= 40AE71AC 406078C4 405F5EC0 SLOT 7:001113: Oct 24 10:50:28.520 BST: %EE192-3-WAHOOERRS: RX WAHOO: WAHOO_CSRAM_CNTRL_INT PIPE0 error 8 SLOT 6:Oct 4 16:48:00.487: %EE192-3-WAHOOERRSSS: RX WAHOO: WAHOO_FFCRAM_CNTRL_INT PIPE0 error 4 addr 3FBFAB8 agent 94 SLOT 7:001114: Oct 24 10:50:28.520 BST: %EE192-3-WAHOOERRSSSS: RX WAHOO: WAHOO_PPC_INT PIPE1 error pl_ctl 4000226 pl_aa_avl F9F7B pl_aa_end 7FF9 pl_aa_fatal 4800000 SLOT 6:Oct 4 16:48:00.487: %EE192-3-WAHOOERRS: RX WAHOO WAHOO_NFC_SRAM_MULTI_ECC_ERR multi-bit CSSRAM error SLOT 6:Oct 4 16:48:00.487: %EE192-3-WAHOOERRS: WAHOO_CTCAM_CNTRL_INT multi-bit CSRAM error SLOT 6:Oct 4 16:48:00.487: %EE192-3-WAHOOERRS: WAHOO_FFCRAM_CNTRL_INT MBE SLOT 6:Oct 4 16:48:00.487: %EE192-3-WAHOOERRS: FSRAM not OK WAHOO_FSRAM_CNTRL_INT ECC_1_BIT_EE | ECC_UNCORR_EE SLOT 6:Oct 4 16:48:00.487: %EE192-3-WAHOOERRS: WAHOO_CTCAM_CNTRL_INT multi-bit CSRAM error SLOT 1:00:01:14: WEEKLY_THROTTLE_SOCKEYE_SBE: SOCKEYE SBE: addr: 0xC2A007C0, synd: 0xC4 SLOT 1:00:01:14: WEEKLY_THROTTLE_CBSRAM_SBE_TX+i: CBSRAM SBE TX: 1-bit CBSRAM error. SLOT 1:00:01:14: WEEKLY_THROTTLE_CBSRAM_SBE_RX+i: CBSRAM SBE RX: 1-bit CBSRAM error. SLOT 1:00:01:14: WEEKLY_THROTTLE_CSSRAM_SBE_TX+i: CSSRAM SBE TX: 1-bit CSSRAM error. SLOT 1:00:01:14: WEEKLY_THROTTLE_CSSRAM_SBE_RX+i: CSSRAM SBE RX: 1-bit CSSRAM error. SLOT 1:00:01:14: WEEKLY_THROTTLE_CSRAM_SBE_TX+i: CSRAM SBE TX: 1-bit CSRAM error. SLOT 1:00:01:14: WEEKLY_THROTTLE_CSRAM_SBE_RX+i: CSRAM SBE RX: 1-bit CSRAM error. SLOT 1:00:01:14: WEEKLY_THROTTLE_W_FW_TCAM_PRTY_TX+throttle_i: TX FTCAM PRTY error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_FW_TCAM_PRTY_RX+throttle_i: RX FTCAM PRTY error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_CL_TCAM_PRTY_TX+throttle_i: TX CLTCAM PRTY error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_CL_TCAM_PRTY_RX+throttle_i: RX CLTCAM PRTY error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_NF_TCAM_PRTY_TX+throttle_i: TX NFTCAM PRTY error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_NF_TCAM_PRTY_RX+throttle_i: RX NFTCAM PRTY error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_TCAM_PRTY_VMR: TCAM PRTY VMR error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_TCAM_PRTY_NO-VMR: TCAM PRTY NO-VMR error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_FCRAM_SBE_TX: FCRAM SBE TX error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_FCRAM_SBE_RX: FCRAM SBE TX error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_FCRAM_PER_CHIP_SBE_TX: FCRAM CHIP SBE error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_ FCRAM_PER_CHIP_SBE_RX: FCRAM CHIP SBE error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_FSRAM_SBE_TX: FSRAM SBE TX error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_FSRAM_SBE_RX: FSRAM SBE RX error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_ FSRAM_MBE_TX: FSRAM MBE RX error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_ FSRAM_MBE_RX: FSRAM MBE RX error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_BM_ISERR_TX: ISERR TX error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_BM_ISERR_RX: ISERR RX error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_BM_FCRAM_SBE_TX: FCRAM SBE TX error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_BM_FCRAM_SBE_RX: FCRAM SBE RX error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_QM_QSRAM_LINK_SBE_TX: QSRAM LINK SBE TX error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_QM_QSRAM_LINK_SBE_RX: QSRAM LINK SBE RX error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_QM_QSRAM_QEINFO_SBE_TX: QSRAM queue info sbe tx error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_QM_QSRAM_QEINFO_SBE_TX: QSRAM queue info sbe rx error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_QM_QSRAM_BADDR_SBE_TX: qsram bad addr sbe tx error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_ QM_QSRAM_BADDR_SBE_RX: qsram bad addr sbe rx error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_QM_OQLLM_SBE_TX: oqllm sbe tx error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_QM_OQLLM_SBE_RX: oqllm sbe rx error status = 0x3
Engine 6-based Line Card Error Messages
You can see these errors in the console output:
SLOT 0:Jan 14 08:53:44.581 GMT: %FIA-3-RAMECCERR: To Fabric ECC error was detected Single Bit Error RAM2 status = 0x8000 Syndrome = 0x0 addr = 0x0 SLOT 6:Apr 29 09:36:12: %E6LC-4-ECC_THRESHOLD: HERMES VID SBE exceeded threshold, possible memory failure SLOT 4:*Mar 13 23:38:19.295: %E6_RX192-3-MTRIE_SBE: Head1 Syndrome=0x94 Addr=0xFFF2B -Traceback= 40544830 40546A90 40688C94 400EDC18 SLOT 7:*Mar 4 1234:19.295: %E6_RX192-3-ADJ_SBE: Syndrome=0x59 Addr=0xFFF2B -Traceback= 40000830 40036A90 40555D44 400ddd23 SLOT 14:Dec 9 20:02:29: %E6_RX192-6-PBC_SBE: Single bit error detected and corrected RLDRAM Syndrome=0x61 Addr=0xF855 Dec 9 20:02:33: %GRP-4-RSTSLOT: Resetting the card in the slot: 14,Event: linecard error report SLOT 4:06:21:43: %E6_RX192-3-ACL_SBE: ACTION MEM Syndrome=0x7 Addr=0x0 -Traceback= 40549740 4054A7E0 4068D814 400EE018 SLOT 6:Mar 28 03:30:19: %RX192-3-HINTR: status = 0x1000000000000, mask = 0x7FFFFF0FA320F - L3X SBE error. -Traceback= 405816DC 406A1010 406A1650 400F70E8 SLOT 6:Mar 28 03:30:19: %E6_RX192-6-VID_SBE: Single bit error detected and corrected VID memory Syndrome=0x19 Addr=0xE51B SLOT 6:Nov 27 23:32:36: %HERA-3-PKTMEM_SBE: Single bit error detected and corrected Error=0x80 – Syndrome=0x5100000000000000 Addr=0x894620 Data bit116 SLOT 7:Oct 2 23:32:36: %HERA-6- MCD_SBE: Single bit error detected and corrected Error=0x50 – Syndrome=0x3100000000000000 Addr=0x331110 Data bit216 SLOT 1:Jun 22 03:32:36: %HERA-6- MRW_SBE: Single bit error detected and corrected Error=0x50 – Syndrome=0x3100000000000000 Addr=0x331110 Data bit216 SLOT 12:May 24 03:03:36: %HERA-6- UPF_SBE: Single bit error detected and corrected Error=0x60 – Syndrome=0x4100000000000000 Addr=0x451140 Data bit216 SLOT 13:Dec 5 07:30:15.272 cst: %HERA-6-PAM_ACL_SBE: PKT CNT MEM Syndrome=0x8 Addr=0x523C SLOT 9:May 5 18:52:14: %HERA-6-QM_FBF_SBE: Free Block FIFO - Single Bit Error detected and corrected Syndrom = 0x10, Addr = 0x778, samebit Yes, diffbit No SLOT 9:May 5 18:52:14: %HERA-3-QM: Error=0x40 - FBF RAM ECC SBE. -Traceback= 405AD4CC 405AF5D0 405F2E80 406DCDB8 406DD434 400FC500 SLOT 3:Aug 16 00:45:14: %MCC192-6-RED_AQD_SBE: Average Queue Depth - Single Bit Error detected and corrected Syndrome = 0x7, Address = 0x89, samebit No, diffbit No SLOT 2:Jan 23 06:29:56 KST: %MCC192-6-RED_STAT_SBE: Statistics - Single Bit Error detected and corrected Syndrome = 0x38, Address = 0xFF, samebit No, diffbit No SLOT 4:*Mar 13 23:38:19.295: %E6_RX192-3-MTRIE_MBE: Single bit error detected and corrected Head1 Syndrome=0x94 Addr=0xFFF2B SLOT 7:*Mar 4 1234:19.295: %E6_RX192-3-ADJ_MBE: Syndrome=0x59 Addr=0xFFF2B -Traceback= 40000830 40036A90 40555D44 400ddd23 00:00:18: %E6_RX192-3-PBC_MBE: ADJ OBANK LO Syndrome=0xE5 Addr=0x142 -Traceback= 405BF8B0 405C0F08 406E8D78 406E93B8 400FCCE0 SLOT 6:Mar 28 03:30:19: %E6_RX192-6-VID_MBE: Single bit error detected and corrected VID memory Syndrome=0x19 Addr=0xE51B SLOT 0:Apr 18 06:44:53.751 GMT: %HERA-3-PKTMEM_MBE: Error=0x1010 - Syndrome=0x9900000000 SLOT 7:Oct 2 23:32:36: %HERA-6- MCD_MBE: Single bit error detected and corrected Error=0x50 – Syndrome=0x3100000000000000 Addr=0x331110 Data bit216 SLOT 1:Jun 22 03:32:36: %HERA-6- MRW_MBE: Single bit error detected and corrected Error=0x50 - Syndrome=0x3100000000000000 Addr=0x331110 Data bit216 SLOT 13:Dec 5 07:30:15.272 cst: %HERA-6-PAM_ACL_MBE: PKT CNT MEM Syndrome=0x8 Addr=0x523C SLOT 9:May 5 18:52:14: %HERA-6-QM_FBF_MBE: Free Block FIFO - Single Bit Error detected and corrected Syndrome = 0x10, Addr = 0x778, samebit Yes, diffbit No SLOT 3:Aug 16 00:45:14: %MCC192-6-RED_AQD_MBE: Average Queue Depth - Single Bit Error detected and corrected Syndrome = 0x7, Address = 0x89, samebit No, diffbit No SLOT 2:Jan 23 06:29:56 KST: %MCC192-6-RED_STAT_MBE: Statistics - Single Bit Error detected and corrected Syndrome = 0x38, Address = 0xFF, samebit No, diffbit No
SPA Error Messages
You can see these errors in the console output:
SLOT 7:Jan 4 02:04:00.487: %SPA_CHOC_DSX-3-UNCOR_PARITY_ERR: SPA4/0: CHOC SPA parity error(s) encountered SLOT 7:Jan 4 02:04:00.487: %MCT1E1-3-UNCOR_PARITY_ERR: SPA5/0: T1E1 SPA parity error(s) encountered SLOT 3: 00:33:48: %MCT1E1-3-UNCOR_MEM_ERR: SPA3/0: 1 uncorrectable HDLC SRAM memory error(s) encountered. SLOT 1:Oct 3 14:42:45.727: %SPA_PLIM-4-SBE_ECC: SPA-4XT3/E3[1/2] reports 2 SBE occurrence at 1 addresses SLOT 1: Jul 22 05:26:29.613 UTC: %SPA_DATABUS-3-SPI4_SINGLE_DIP4_PARITY: SIP Sbslt 0 Ingress Sink - A single DIP4 parity error has occurred on the data bus. SLOT 4: Dec 2 22:44:05: %SPA_DATABUS-3-SPI4_SINGLE_DIP2_PARITY: SIP Sbslt 0 Egress Source - A single DIP 2 parity error on the FIFO status bus has occurred. SLOT 1:Oct 3 14:42:45.727: %SPA_PLIM-4-SBE_OVERFLOW: SPA-4XT3/E3[1/2] reports SBE table (2 elements) overflows SLOT 1:Oct 3 14:42:45.727: % SPA_PLUGIN-3-SPI4_SETCB: SPA-4XT3/E3[1/2] : IPC SPI4 set callback failed(status 2).
Parity Errors in the Cisco 12000 Series Switching Fabric Cards
All the parity error messages related to switching fabric cards are covered in detail in Hardware Troubleshooting for the Cisco 12000 Series Internet Router. These messages include (non-exhaustive list):
%FABRIC-3-PARITYERR: To Fabric parity error was detected. Grant parity error Data = 0x2. SLOT 1:%FABRIC-3-PARITYERR: To Fabric parity error was detected. Grant parity error Data = 0x1
Related Information
Revision History
| Revision | Publish Date | Comments |
|---|---|---|
1.0 |
06-Dec-2002 |
Initial Release |
 Feedback
FeedbackContact Cisco
- Open a Support Case

- (Requires a Cisco Service Contract)