各種Ultra-M元件的備份與還原程式- CPS
下載選項
無偏見用語
本產品的文件集力求使用無偏見用語。針對本文件集的目的,無偏見係定義為未根據年齡、身心障礙、性別、種族身分、民族身分、性別傾向、社會經濟地位及交織性表示歧視的用語。由於本產品軟體使用者介面中硬式編碼的語言、根據 RFP 文件使用的語言,或引用第三方產品的語言,因此本文件中可能會出現例外狀況。深入瞭解思科如何使用包容性用語。
關於此翻譯
思科已使用電腦和人工技術翻譯本文件,讓全世界的使用者能夠以自己的語言理解支援內容。請注意,即使是最佳機器翻譯,也不如專業譯者翻譯的內容準確。Cisco Systems, Inc. 對這些翻譯的準確度概不負責,並建議一律查看原始英文文件(提供連結)。
簡介
本文檔介紹在託管Calls CPS Virtual Network Functions的Ultra-M設定中備份和還原虛擬機器所需的步驟。
背景資訊
Ultra-M是經過預先封裝和驗證的虛擬化移動資料包核心解決方案,旨在簡化虛擬網路功能(VNF)的部署。Ultra-M解決方案包括以下型別的虛擬機器(VM):
- 彈性服務控制器(ESC)
- 思科原則套件(CPS)
Ultra-M的高階架構及相關的元件如下圖所示。
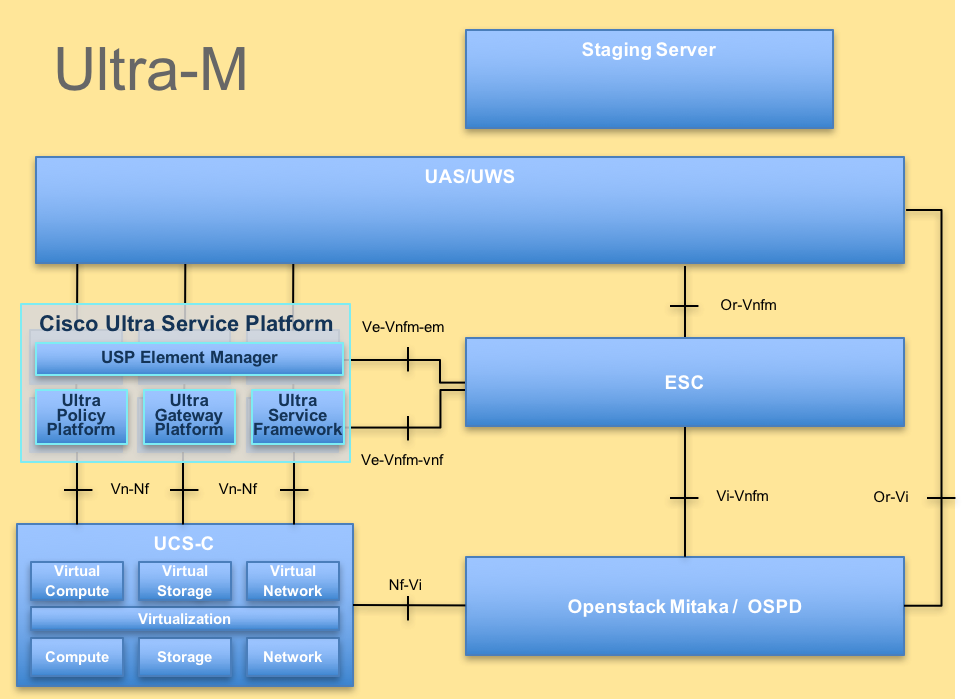

注意:為了定義本文檔中的過程,將考慮Ultra M 5.1.x版本。 本文檔適用於熟悉Cisco Ultra-M平台的思科人員。
縮寫
| VNF | 虛擬網路功能 |
| ESC | 彈性服務控制器 |
| MOP | 程式方法 |
| OSD | 物件儲存磁碟 |
| 硬碟 | 硬碟 |
| SSD | 固態硬碟 |
| VIM | 虛擬基礎架構管理員 |
| VM | 虛擬機器器 |
| UUID | 通用唯一辨識碼 |
備份程式
OSPD備份
1. 檢查OpenStack堆疊的狀態和節點清單。
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack stack list --nested
[stack@director ~]$ ironic node-list
[stack@director ~]$ nova list
2. 從OSP-D節點檢查是否所有底層雲服務均處於已載入、活動和執行狀態。
[stack@director ~]$ systemctl list-units "openstack*" "neutron*" "openvswitch*"
UNIT LOAD ACTIVE SUB DESCRIPTION
neutron-dhcp-agent.service loaded active running OpenStack Neutron DHCP Agent
neutron-openvswitch-agent.service loaded active running OpenStack Neutron Open vSwitch Agent
neutron-ovs-cleanup.service loaded active exited OpenStack Neutron Open vSwitch Cleanup Utility
neutron-server.service loaded active running OpenStack Neutron Server
openstack-aodh-evaluator.service loaded active running OpenStack Alarm evaluator service
openstack-aodh-listener.service loaded active running OpenStack Alarm listener service
openstack-aodh-notifier.service loaded active running OpenStack Alarm notifier service
openstack-ceilometer-central.service loaded active running OpenStack ceilometer central agent
openstack-ceilometer-collector.service loaded active running OpenStack ceilometer collection service
openstack-ceilometer-notification.service loaded active running OpenStack ceilometer notification agent
openstack-glance-api.service loaded active running OpenStack Image Service (code-named Glance) API server
openstack-glance-registry.service loaded active running OpenStack Image Service (code-named Glance) Registry server
openstack-heat-api-cfn.service loaded active running Openstack Heat CFN-compatible API Service
openstack-heat-api.service loaded active running OpenStack Heat API Service
openstack-heat-engine.service loaded active running Openstack Heat Engine Service
openstack-ironic-api.service loaded active running OpenStack Ironic API service
openstack-ironic-conductor.service loaded active running OpenStack Ironic Conductor service
openstack-ironic-inspector-dnsmasq.service loaded active running PXE boot dnsmasq service for Ironic Inspector
openstack-ironic-inspector.service loaded active running Hardware introspection service for OpenStack Ironic
openstack-mistral-api.service loaded active running Mistral API Server
openstack-mistral-engine.service loaded active running Mistral Engine Server
openstack-mistral-executor.service loaded active running Mistral Executor Server
openstack-nova-api.service loaded active running OpenStack Nova API Server
openstack-nova-cert.service loaded active running OpenStack Nova Cert Server
openstack-nova-compute.service loaded active running OpenStack Nova Compute Server
openstack-nova-conductor.service loaded active running OpenStack Nova Conductor Server
openstack-nova-scheduler.service loaded active running OpenStack Nova Scheduler Server
openstack-swift-account-reaper.service loaded active running OpenStack Object Storage (swift) - Account Reaper
openstack-swift-account.service loaded active running OpenStack Object Storage (swift) - Account Server
openstack-swift-container-updater.service loaded active running OpenStack Object Storage (swift) - Container Updater
openstack-swift-container.service loaded active running OpenStack Object Storage (swift) - Container Server
openstack-swift-object-updater.service loaded active running OpenStack Object Storage (swift) - Object Updater
openstack-swift-object.service loaded active running OpenStack Object Storage (swift) - Object Server
openstack-swift-proxy.service loaded active running OpenStack Object Storage (swift) - Proxy Server
openstack-zaqar.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server
openstack-zaqar@1.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server Instance 1
openvswitch.service loaded active exited Open vSwitch
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, for example, generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
37 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
3. 執行備份程式之前,請先確認您有足夠的可用磁碟空間。此星形箭號至少應為3.5 GB。
[stack@director ~]$df -h
4. 以root使用者身份執行這些命令,將資料從底層雲節點備份到名為undercloud-backup-[timestamp].tar.gz的檔案中,然後將其傳輸到備份伺服器。
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql
[root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql
/etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack
tar: Removing leading `/' from member names
ESC備份
1. 反過來,ESC透過與VIM互動來啟動虛擬網路功能(VNF)。
2. ESC在Ultra-M解決方案中具有1:1冗餘。部署了2個ESC VM,並且支援Ultra-M中的單個故障。例如,如果系統中存在單個故障,請恢復系統。
註:如果出現多個故障,則不受支援,可能需要重新部署系統。
ESC備份詳細資訊:
- 執行組態
- ConfD CDB DB
- ESC日誌
- 系統日誌配置
3. ESC DB備份的頻率非常棘手,在ESC監控和維護所部署的各種VNF VM的各種狀態機時需要謹慎處理。建議這些備份是在給定的VNF/POD/站點中的這些活動之後執行的。
4. 使用health.sh指令碼驗證ESC的運行狀況是否良好。
[root@auto-test-vnfm1-esc-0 admin]# escadm status
0 ESC status=0 ESC Primary Healthy
[root@auto-test-vnfm1-esc-0 admin]# health.sh
esc ui is disabled -- skipping status check
esc_monitor start/running, process 836
esc_mona is up and running ...
vimmanager start/running, process 2741
vimmanager start/running, process 2741
esc_confd is started
tomcat6 (pid 2907) is running... [ OK ]
postgresql-9.4 (pid 2660) is running...
ESC service is running...
Active VIM = OPENSTACK
ESC Operation Mode=OPERATION
/opt/cisco/esc/esc_database is a mountpoint
============== ESC HA (Primary) with DRBD =================
DRBD_ROLE_CHECK=0
MNT_ESC_DATABSE_CHECK=0
VIMMANAGER_RET=0
ESC_CHECK=0
STORAGE_CHECK=0
ESC_SERVICE_RET=0
MONA_RET=0
ESC_MONITOR_RET=0
=======================================
ESC HEALTH PASSED
5. 備份「執行中」組態並將檔案傳輸至備份伺服器。
[root@auto-test-vnfm1-esc-0 admin]# /opt/cisco/esc/confd/bin/confd_cli -u admin -C
admin connected from 127.0.0.1 using console on auto-test-vnfm1-esc-0.novalocal
auto-test-vnfm1-esc-0# show running-config | save /tmp/running-esc-12202017.cfg
auto-test-vnfm1-esc-0#exit
[root@auto-test-vnfm1-esc-0 admin]# ll /tmp/running-esc-12202017.cfg
-rw-------. 1 tomcat tomcat 25569 Dec 20 21:37 /tmp/running-esc-12202017.cfg
備份ESC資料庫
1. 登入到ESC VM並在進行備份之前執行此命令。
[admin@esc ~]# sudo bash
[root@esc ~]# cp /opt/cisco/esc/esc-scripts/esc_dbtool.py /opt/cisco/esc/esc-scripts/esc_dbtool.py.bkup
[root@esc esc-scripts]# sudo sed -i "s,'pg_dump,'/usr/pgsql-9.4/bin/pg_dump," /opt/cisco/esc/esc-scripts/esc_dbtool.py
#Set ESC to mainenance mode
[root@esc esc-scripts]# escadm op_mode set --mode=maintenance
2. 檢查ESC模式並確保其處於維護模式。
[root@esc esc-scripts]# escadm op_mode show
3. 使用ESC中提供的資料庫備份還原工具備份資料庫。
[root@esc scripts]# sudo /opt/cisco/esc/esc-scripts/esc_dbtool.py backup --file scp://<username>:<password>@<backup_vm_ip>:<filename>
4. 將ESC設回「操作模式」並確認模式。
[root@esc scripts]# escadm op_mode set --mode=operation
[root@esc scripts]# escadm op_mode show
5. 切換作業選項至「命令檔」目錄,並收集日誌。
[root@esc scripts]# /opt/cisco/esc/esc-scripts
sudo ./collect_esc_log.sh
6. 若要建立ESC的快照,請先關閉ESC。
shutdown -r now
7. 從OSPD建立影像快照。
nova image-create --poll esc1 esc_snapshot_27aug2018
8. 驗證是否已建立快照。
openstack image list | grep esc_snapshot_27aug2018
9. 從OSPD啟動ESC。
nova start esc1
10. 在備用ESC VM上重複相同的過程,並將日誌傳輸到備份伺服器。
11. 收集ESC VMS上的系統日誌配置備份,並將它們傳輸到備份伺服器。
[admin@auto-test-vnfm2-esc-1 ~]$ cd /etc/rsyslog.d
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/00-escmanager.conf
00-escmanager.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/01-messages.conf
01-messages.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/02-mona.conf
02-mona.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.conf
rsyslog.conf
CPS備份
步驟 1.建立CPS Cluster-Manager的備份。
使用此命令可檢視nova例項並記下群集管理器VM例項的名稱:
nova list
從ESC停止俱樂部成員。
/opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli vm-action STOP <vm-name>
步驟 2.驗證Cluster Manager是否處於SHUTOFF狀態。
admin@esc1 ~]$ /opt/cisco/esc/confd/bin/confd_cli admin@esc1> show esc_datamodel opdata tenants tenant Core deployments * state_machine
步驟 3.建立新星快照影像,如以下命令所示:
nova image-create --poll <cluman-vm-name> <snapshot-name>
注意:請確保您有足夠的磁碟空間來儲存快照。
.重要資訊-如果在建立快照後無法訪問VM,請使用nova list命令檢查VM的狀態。如果處於SHUTOFF狀態,則需要手動啟動VM。
步驟 4.使用以下命令檢視映像清單:nova image-list
圖1:輸出示例

步驟 5.建立快照時,快照影像會儲存在OpenStack概覽中。若要將快照儲存在遠端資料存放區,請下載快照並將檔案以OSPD傳輸至(/home/stack/CPS_BACKUP)。
若要下載影像,請在OpenStack中使用此指令:
glance image-download –-file For example: glance image-download –-file snapshot.raw 2bbfb51c-cd05-4b7c-ad77-8362d76578db
步驟 6.列出下載的影像,如以下命令所示:
ls —ltr *snapshot*
Example output: -rw-r--r--. 1 root root 10429595648 Aug 16 02:39 snapshot.raw
步驟 7.儲存叢集管理員VM的快照,以便在未來還原。
2. 備份配置和資料庫。
1. config_br.py -a export --all /var/tmp/backup/ATP1_backup_all_$(date +\%Y-\%m-\%d).tar.gz OR 2. config_br.py -a export --mongo-all /var/tmp/backup/ATP1_backup_mongoall$(date +\%Y-\%m-\%d).tar.gz 3. config_br.py -a export --svn --etc --grafanadb --auth-htpasswd --haproxy /var/tmp/backup/ATP1_backup_svn_etc_grafanadb_haproxy_$(date +\%Y-\%m-\%d).tar.gz 4. mongodump - /var/qps/bin/support/env/env_export.sh --mongo /var/tmp/env_export_$date.tgz 5. patches - cat /etc/broadhop/repositories, check which patches are installed and copy those patches to the backup directory /home/stack/CPS_BACKUP on OSPD 6. backup the cronjobs by taking backup of the cron directory: /var/spool/cron/ from the Pcrfclient01/Cluman. Then move the file to CPS_BACKUP on the OSPD.
從crontab-l驗證是否需要任何其他備份。
將所有備份傳輸到OSPD /home/stack/CPS_BACKUP。
3. 從ESC主要檔案備份yaml檔案。
/opt/cisco/esc/confd/bin/netconf-console --host 127.0.0.1 --port 830 -u <admin-user> -p <admin-password> --get-config > /home/admin/ESC_config.xml
以OSPD /home/stack/CPS_BACKUP傳輸檔案。
4. 備份crontab -l條目。
使用crontab -l建立一個txt檔案,並將其ftp到遠端位置(在OSPD /home/stack/CPS_BACKUP中)。
5. 從LB和PCRF客戶端備份路由檔案。
Collect and scp the configurations from both LBs and Pcrfclients route -n /etc/sysconfig/network-script/route-*
還原程式
OSPD復原
OSPD復原程式會根據這些假設來執行。
1. OSPD備份可從舊OSPD伺服器獲得。
2. 可以在新伺服器上執行OSPD恢復,該伺服器將替換系統中的舊OSPD伺服器。 .
ESC復原
1. 如果VM處於錯誤或關閉狀態,請強制重新啟動以啟動受影響的VM,則ESC VM可恢復。執行這些步驟以恢復ESC。
2. 辨識處於「錯誤」或「關閉」狀態的VM,一旦辨識,請硬重新啟動ESC VM。在本示例中,您將重新啟動auto-test-vnfm1-ESC-0。
[root@tb1-baremetal scripts]# nova list | grep auto-test-vnfm1-ESC-
| f03e3cac-a78a-439f-952b-045aea5b0d2c | auto-test-vnfm1-ESC-0 | ACTIVE | - | running | auto-testautovnf1-uas-orchestration=172.31.12.11; auto-testautovnf1-uas-management=172.31.11.3 |
| 79498e0d-0569-4854-a902-012276740bce | auto-test-vnfm1-ESC-1 | ACTIVE | - | running | auto-testautovnf1-uas-orchestration=172.31.12.15; auto-testautovnf1-uas-management=172.31.11.15 |
[root@tb1-baremetal scripts]# [root@tb1-baremetal scripts]# nova reboot --hard f03e3cac-a78a-439f-952b-045aea5b0d2c\
Request to reboot server <Server: auto-test-vnfm1-ESC-0> has been accepted.
[root@tb1-baremetal scripts]#
3. 如果刪除ESC VM,需要再次啟動。請使用以下步驟順序。
[stack@pod1-ospd scripts]$ nova list |grep ESC-1
| c566efbf-1274-4588-a2d8-0682e17b0d41 | vnf1-ESC-ESC-1 | ACTIVE | - | running | vnf1-UAS-uas-orchestration=172.16.11.14; vnf1-UAS-uas-management=172.16.10.4 |
[stack@pod1-ospd scripts]$ nova delete vnf1-ESC-ESC-1
Request to delete server vnf1-ESC-ESC-1 has been accepted.
4. 如果ESC VM不可恢復並且需要還原資料庫,請從以前備份中還原資料庫。
5. 對於ESC資料庫恢復,必須確保esc服務在恢復資料庫之前停止;對於ESC HA,首先在輔助VM中執行,然後執行主VM。
# service keepalived stop
6. 檢查ESC服務狀態,確保在HA的主和輔助VM中均已停止。
# escadm status
7. 執行命令檔以還原資料庫。在將資料庫恢復到新建立的ESC例項時,該工具還可以將其中一個例項升級為主的ESC,將其資料庫資料夾裝載到drbd裝置,並且可以啟動PostgreSQL資料庫。
# /opt/cisco/esc/esc-scripts/esc_dbtool.py restore --file scp://<username>:<password>@<backup_vm_ip>:<filename>
8. 重新啟動ESC服務以完成資料庫還原。對於兩個VM中的HA,請重新啟動keepalive服務。
# service keepalived start
9. 成功還原並運行虛擬機器之後,請確保從上次成功的已知備份還原所有系統日誌特定配置。確保已在所有ESC虛擬機器中還原該配置。
[admin@auto-test-vnfm2-esc-1 ~]$
[admin@auto-test-vnfm2-esc-1 ~]$ cd /etc/rsyslog.d
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/00-escmanager.conf
00-escmanager.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/01-messages.conf
01-messages.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/02-mona.conf
02-mona.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.conf
rsyslog.conf
10. 如果需要從OSPD快照重建ESC,請使用此命令並在備份期間使用快照。
nova rebuild --poll --name esc_snapshot_27aug2018 esc1
11. 重建完成後,檢查ESC的狀態。
nova list --fileds name,host,status,networks | grep esc
12. 使用此命令檢查ESC運行狀況。
health.sh
Copy Datamodel to a backup file
/opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli get esc_datamodel/opdata > /tmp/esc_opdata_`date +%Y%m%d%H%M%S`.txt
當ESC無法啟動VM
- 在某些情況下,ESC可能會由於意外狀態而無法啟動VM。解決方法是透過重新啟動主要ESC來執行ESC切換。ESC切換可能需要一分鐘的時間。 在新的Primary ESC上執行health.sh以驗證它是否已啟動。當ESC變成主要時,ESC可以修復VM狀態並啟動VM。由於此操作已計畫,您必須等待5-7分鐘才能完成。
- 您可以監控/var/log/esc/yangesc.log和/var/log/esc/escmanager.log。如果您在5-7分鐘後沒有看到虛擬機器被恢復,則使用者將需要執行受影響虛擬機器的手動恢復。
- VM成功恢復並運行之後;請確保從以前成功的已知備份恢復所有系統日誌特定配置。確保已在所有ESC VM中還原它
root@abautotestvnfm1em-0:/etc/rsyslog.d# pwd
/etc/rsyslog.d
root@abautotestvnfm1em-0:/etc/rsyslog.d# ll
total 28
drwxr-xr-x 2 root root 4096 Jun 7 18:38 ./
drwxr-xr-x 86 root root 4096 Jun 6 20:33 ../]
-rw-r--r-- 1 root root 319 Jun 7 18:36 00-vnmf-proxy.conf
-rw-r--r-- 1 root root 317 Jun 7 18:38 01-ncs-java.conf
-rw-r--r-- 1 root root 311 Mar 17 2012 20-ufw.conf
-rw-r--r-- 1 root root 252 Nov 23 2015 21-cloudinit.conf
-rw-r--r-- 1 root root 1655 Apr 18 2013 50-default.conf
root@abautotestvnfm1em-0:/etc/rsyslog.d# ls /etc/rsyslog.conf
rsyslog.conf
CPS復原
恢復OpenStack中的群集管理器虛擬機器。
步驟 1.將叢集管理員VM快照複製到控制器刀鋒,如以下命令所示:
ls —ltr *snapshot*
Example output: -rw-r--r--. 1 root root 10429595648 Aug 16 02:39 snapshot.raw
步驟 2.將快照影像從Datastore上傳到OpenStack:
glance image-create --name --file --disk-format qcow2 --container-format bare
步驟 3.驗證是否使用Nova命令上載快照,如以下示例所示:
nova image-list
圖2:輸出示例

步驟 4.根據叢集管理員VM是否存在,您可以選擇建立叢集或重新建立叢集:
· 如果Cluster Manager VM例項不存在,請使用Heat或Nova命令建立Cluman VM,如以下示例所示:
使用ESC建立Cluman VM。
/opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli edit-config /opt/cisco/esc/cisco-cps/config/gr/tmo/gen/<original_xml_filename>
PCRF群集可以在前面的命令的幫助下生成,然後從使用config_br.py restore進行的備份中恢復群集管理器配置,從備份中進行的轉儲中恢復mongorestore。
delete - nova boot --config-drive true --image "" --flavor "" --nic net-id=",v4-fixed-ip=" --nic net-id="network_id,v4-fixed-ip=ip_address" --block-device-mapping "/dev/vdb=2edbac5e-55de-4d4c-a427-ab24ebe66181:::0" --availability-zone "az-2:megh-os2-compute2.cisco.com" --security-groups cps_secgrp "cluman"
· 如果Cluster Manager VM例項存在,則使用nova rebuild命令以上載的快照重建Cluman VM例項,如下所示:
nova rebuild <instance_name> <snapshot_image_name>
舉例來說:
nova rebuild cps-cluman-5f3tujqvbi67 cluman_snapshot
步驟 5.列出所有執行處理(如圖所示),並確認已建立並執行新的叢集管理員執行處理:
nova list
圖3.輸出範例

還原系統上的最新修補程式。
1. Copy the patch files to cluster manager which were backed up in OSPD /home/stack/CPS_BACKUP 2. Login to the Cluster Manager as a root user. 3. Untar the patch by executing this command: tar -xvzf [patch name].tar.gz 4. Edit /etc/broadhop/repositories and add this entry: file:///$path_to_the plugin/[component name] 5. Run build_all.sh script to create updated QPS packages: /var/qps/install/current/scripts/build_all.sh 6. Shutdown all software components on the target VMs: runonall.sh sudo monit stop all 7. Make sure all software components are shutdown on target VMs: statusall.sh
注意:所有軟體元件都必須顯示「未監督」作為目前狀態。
8. Update the qns VMs with the new software using reinit.sh script: /var/qps/install/current/scripts/upgrade/reinit.sh 9. Restart all software components on the target VMs: runonall.sh sudo monit start all 10. Verify that the component is updated, run: about.sh
恢復克隆作業。
1. 將備份檔案從OSPD移動到Cluman/Pcrfclient01。
2. 運行命令以從備份啟用cronjob。
#crontab Cron-backup
3.檢查此命令是否已啟用cronjobs。
#crontab -l
恢復群集中的各個VM。
重新部署pcrfclient01 VM:
步驟 1.以root使用者身分登入Cluster Manager VM。
步驟 2.請記住使用以下命令的SVN儲存區域的UUID:
svn info http://pcrfclient02/repos | grep UUID
命令可以輸出儲存庫的UUID。
例如:儲存區域UUID:ea50bbd2-5726-46b8-b807-10f4a7424f0e
步驟 3.在叢集管理員上匯入備份原則建置器組態資料,如以下範例所示:
config_br.py -a import --etc-oam --svn --stats --grafanadb --auth-htpasswd --users /mnt/backup/oam_backup_27102016.tar.gz
注意:許多部署都運行定期備份配置資料的cron作業。如需詳細資訊,請參閱Subversion Repository Backup。
步驟 4. 要使用最新配置在群集管理器上生成VM存檔檔案,請執行以下命令:
/var/qps/install/current/scripts/build/build_svn.sh
步驟 5.要部署pcrfclient01 VM,請執行以下操作之一:
在OpenStack中,使用HEAT模板或Nova命令重新建立VM。如需詳細資訊,請參閱CPS Installation Guide for OpenStack。
步驟 6.透過執行以下一系列命令,重新建立pcrfclient01和pcrfclient02之間以pcrfclient01為主的SVN主/輔助同步。
如果SVN已經同步,請不要發出這些命令。
要檢查SVN是否同步,請從pcrfclient02運行此命令。
如果傳回值,則SVN已經同步:
/usr/bin/svn propget svn:sync-from-url --revprop -r0 http://pcrfclient01/repos
從pcrfclient01執行以下命令:
/bin/rm -fr /var/www/svn/repos /usr/bin/svnadmin create /var/www/svn/repos /usr/bin/svn propset --revprop -r0 svn:sync-last-merged-rev 0 http://pcrfclient02/repos-proxy-sync /usr/bin/svnadmin setuuid /var/www/svn/repos/ "Enter the UUID captured in step 2" /etc/init.d/vm-init-client / var/qps/bin/support/recover_svn_sync.sh
步驟 7.如果pcrfclient01也是仲裁者VM,請執行以下步驟:
a)根據系統配置建立mongodb啟動/停止指令碼。並非所有部署都配置了所有這些資料庫。
注意:請參閱/etc/broadhop/mongoConfig.cfg以決定需要設定哪些資料庫。
cd /var/qps/bin/support/mongo build_set.sh --session --create-scripts build_set.sh --admin --create-scripts build_set.sh --spr --create-scripts build_set.sh --balance --create-scripts build_set.sh --audit --create-scripts build_set.sh --report --create-scripts
b)啟動監控程式:
/usr/bin/systemctl start sessionmgr-XXXXX
c)等待仲裁程式啟動,然後運行diagnostics.sh —get_replica_status檢查副本集的運行狀況。
重新部署pcrfclient02 VM:
步驟 1.以root使用者身分登入Cluster Manager VM。
步驟 2.要使用最新配置在群集管理器上生成VM存檔檔案,請執行以下命令:
/var/qps/install/current/scripts/build/build_svn.sh
步驟 3.要部署pcrfclient02 VM,請執行以下操作之一:
在OpenStack中,使用HEAT模板或Nova命令重新建立VM。如需詳細資訊,請參閱CPS Installation Guide for OpenStack。
步驟 4.將Shell保護到pcrfclient01:
ssh pcrfclient01
步驟 5.運行此指令碼以從pcrfclient01恢復SVN回執:
/var/qps/bin/support/recover_svn_sync.sh
重新部署sessionmgr VM:
步驟 1.以root使用者身分登入Cluster Manager VM。
步驟 2.要部署sessionmgr VM並替換故障或損壞的VM,請執行以下操作之一:
在OpenStack中,使用HEAT模板或Nova命令重新建立VM。如需詳細資訊,請參閱CPS Installation Guide for OpenStack。
步驟 3.根據系統配置建立mongodb啟動/停止指令碼。
並非所有部署都配置了所有這些資料庫。請參閱/etc/broadhop/mongoConfig.cfg以決定需要設定哪些資料庫。
cd /var/qps/bin/support/mongo build_set.sh --session --create-scripts build_set.sh --admin --create-scripts build_set.sh --spr --create-scripts build_set.sh --balance --create-scripts build_set.sh --audit --create-scripts build_set.sh --report --create-scripts
步驟 4.將Shell保護到sessionmgr VM並啟動監控進程:
ssh sessionmgrXX /usr/bin/systemctl start sessionmgr-XXXXX
步驟 5.等待成員啟動,並等待輔助成員同步,然後運行diagnostics.sh —get_replica_status檢查資料庫的運行狀況。
步驟 6.要恢復Session Manager資料庫,請根據備份是使用—mongo-all還是—mongo選項執行,使用以下示例命令之一:
• config_br.py -a import --mongo-all --users /mnt/backup/Name of backup or • config_br.py -a import --mongo --users /mnt/backup/Name of backup
要重新部署策略導向器(負載平衡器) VM:
步驟 1.以root使用者身分登入Cluster Manager VM。
步驟 2.若要在叢集管理員上匯入備份原則建置器組態資料,請執行以下命令:
config_br.py -a import --network --haproxy --users /mnt/backup/lb_backup_27102016.tar.gz
步驟 3.要使用最新配置在群集管理器上生成VM存檔檔案,請執行以下命令:
/var/qps/install/current/scripts/build/build_svn.sh
步驟 4.要部署lb01 VM,請執行以下操作之一:
在OpenStack中,使用HEAT模板或Nova命令重新建立VM。如需詳細資訊,請參閱CPS Installation Guide for OpenStack。
要重新部署策略伺服器(QNS) VM,請執行以下操作:
步驟 1.以root使用者身分登入Cluster Manager VM。
步驟 2.在叢集管理員上匯入備份原則建置器組態資料,如以下範例所示:
config_br.py -a import --users /mnt/backup/qns_backup_27102016.tar.gz
步驟 3.要使用最新配置在群集管理器上生成VM存檔檔案,請執行以下命令:
/var/qps/install/current/scripts/build/build_svn.sh
步驟 4.要部署qns VM,請執行以下操作之一:
在OpenStack中,使用HEAT模板或Nova命令重新建立VM。如需詳細資訊,請參閱CPS Installation Guide for OpenStack。
資料庫還原的一般程式。
步驟 1.執行此命令以還原資料庫:
config_br.py –a import --mongo-all /mnt/backup/backup_$date.tar.gz where $date is the timestamp when the export was made.
例如,
config_br.py –a import --mongo-all /mnt/backup/backup_27092016.tgz
步驟 2.登入資料庫,確認資料庫是否在執行中且可存取:
1. 登入會話管理器:
mongo --host sessionmgr01 --port $port
其中$port是要檢查的資料庫的埠號。例如,27718是預設的平衡連線埠。
2. 透過執行此命令顯示資料庫:
show dbs
3. 透過執行以下命令將mongo shell切換到資料庫:
use $db
其中$db是顯示在上一個命令中的資料庫名稱。
use命令將蒙戈shell切換到此資料庫。
例如,
use balance_mgmt
4.若要顯示收集,請執行以下命令:
show collections
5. 若要顯示收集中的記錄數目,請執行以下命令:
db.$collection.count() For example, db.account.count()
上一個範例可以顯示餘額資料庫(balance_mgmt)中收集帳戶的記錄數目。
Subversion儲存庫還原。
要從備份還原策略生成器配置資料,請執行以下命令:
config_br.py –a import --svn /mnt/backup/backup_$date.tgz where, $date is the date when the cron created the backup file.
還原Grafana儀表板。
您可以使用以下命令恢復Grafana控制台:
config_br.py -a import --grafanadb /mnt/backup/
正在驗證還原。
恢復資料後,透過執行以下命令驗證工作系統:
/var/qps/bin/diag/diagnostics.sh
修訂記錄
| 修訂 | 發佈日期 | 意見 |
|---|---|---|
2.0 |
20-Mar-2024
|
已更新標題、簡介、替代文字、機器翻譯、樣式要求和格式。 |
1.0 |
21-Sep-2018
|
初始版本 |
由思科工程師貢獻
- Aaditya DeodharCisco Advanced Services
 意見
意見