簡介
本文檔介紹即時消息和線上狀態(IM&P)高可用性如何在企業IM&P環境中工作以及如何對其進行故障排除。
必要條件
需求
思科建議您瞭解以下主題:
- Cisco整合IM&P
- Cisco Jabber使用者端
採用元件
- Cisco Unified IM&P 10.0及更高版本
- Cisco Jabber使用者端9.6及更新版本
本文中的資訊是根據特定實驗室環境內的元件所建立。文中使用到的所有元件皆從已清除(預設)的組態來啟動。如果您的網路運作中,請確保您瞭解任何指令可能造成的影響。
IM和狀態高可用性(HA)
IM and Presence Service Server在CUCM配置中以邏輯伺服器組的形式提供高可用性或冗餘。此配置將傳遞到IM and Presence,然後用於在IM and Presence服務或伺服器出現故障時允許冗餘。 發生HA事件時,終端使用者的會話將從故障伺服器移動到備份。 當伺服器已恢復正常狀態時,管理員會自動或手動將使用者會話移回。
冗餘組配置
冗餘組是允許將伺服器分配給IM and Presence子群集以及配置HA的邏輯伺服器對。若要訪問配置的此部分,請在CUCM伺服器網頁上找到它。
System > Presence Redundancy Group
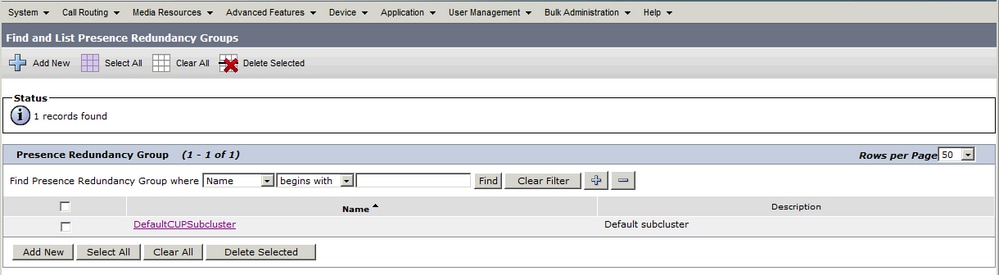
當管理員將IM&P Publisher新增到CUCM上的System > Server配置中,並儲存IM&P伺服器時,將建立DefaultCUPSubCluster冗餘組,同時為其分配了Publisher。
建立冗餘組時,該冗餘組如下所示:
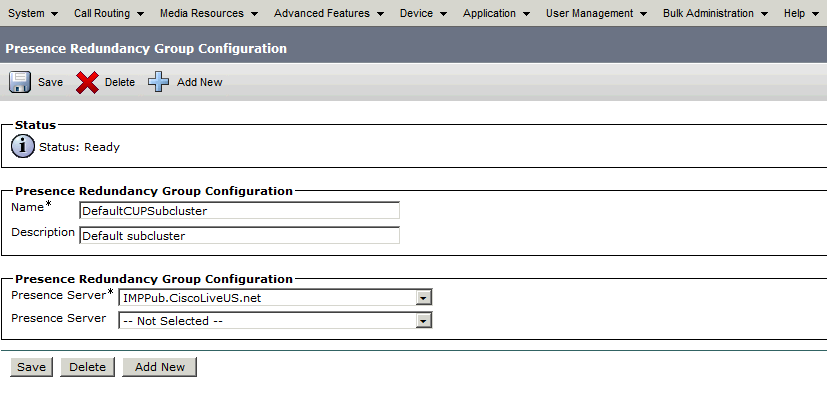
此冗餘組轉換為IM和狀態子集群。在CUCM中冗餘組配置的當前狀態下,這將是IM and Presence Cluster Topology網頁中的狀態:
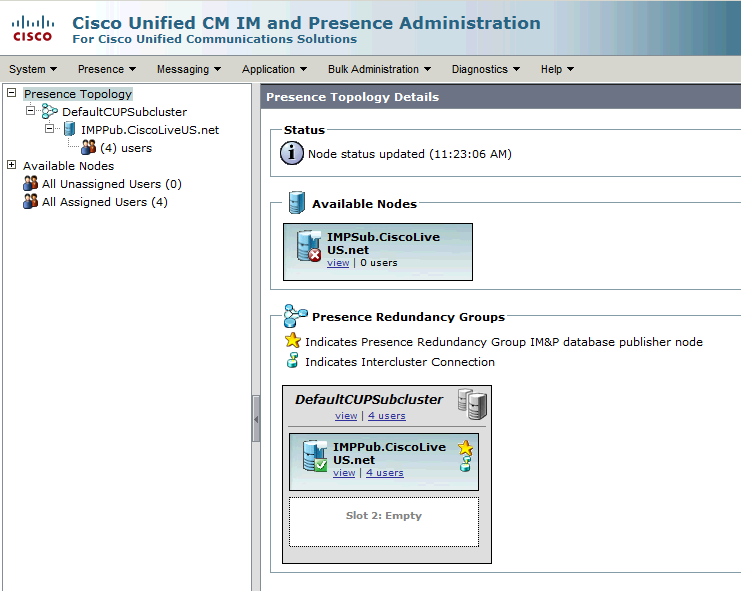
您會看到IM&P發佈伺服器已分配給DefaultCUPSubcluster,而訂閱伺服器未分配。 這是因為IM&P使用者伺服器未分配給CUCM配置中的冗餘組。
將訂閱伺服器分配給冗餘組。
要將訂戶伺服器分配給冗餘組,只需從下拉選單中選擇訂戶伺服器,然後Save配置更改。
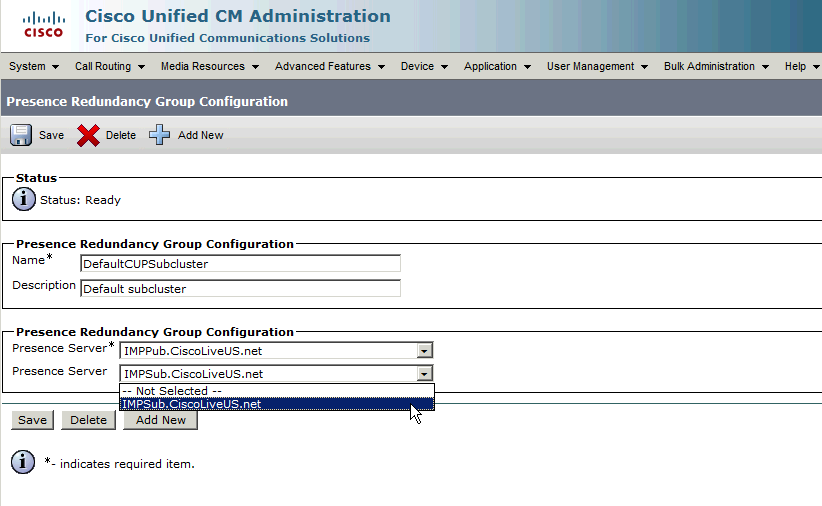
將IM&P使用者新增到冗餘組之後:
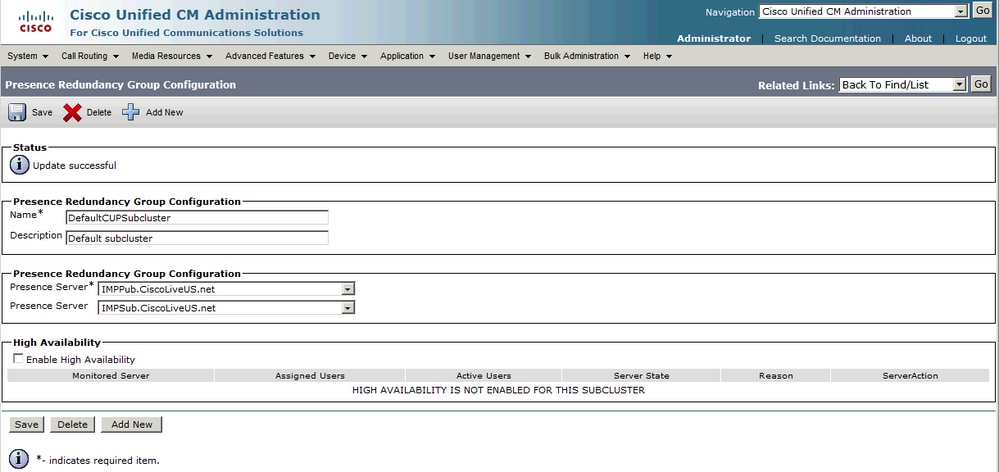
新增輔助節點(訂戶)後,您會看到可以選擇高可用性選項。要啟用高可用性,您只需選中啟用高可用性覈取方塊並儲存配置更改。
啟用高可用性後:
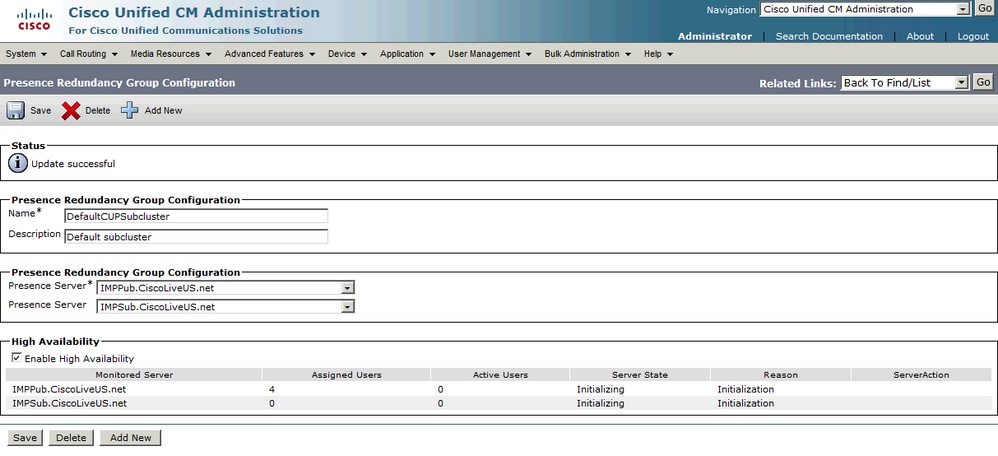
然後,該頁面自動刷新伺服器狀態和原因。 當伺服器處於初始化狀態時,這意味著兩個伺服器能夠通訊。 然後,伺服器會在狀態轉換為「正常」狀態之前驗證服務狀態。 如果兩個伺服器可以彼此連線,且兩個伺服器上所有受監控的服務都啟動,則您會取得正常正常狀態。這意味著所有受監控的服務都在IM&P伺服器上處於活動狀態。
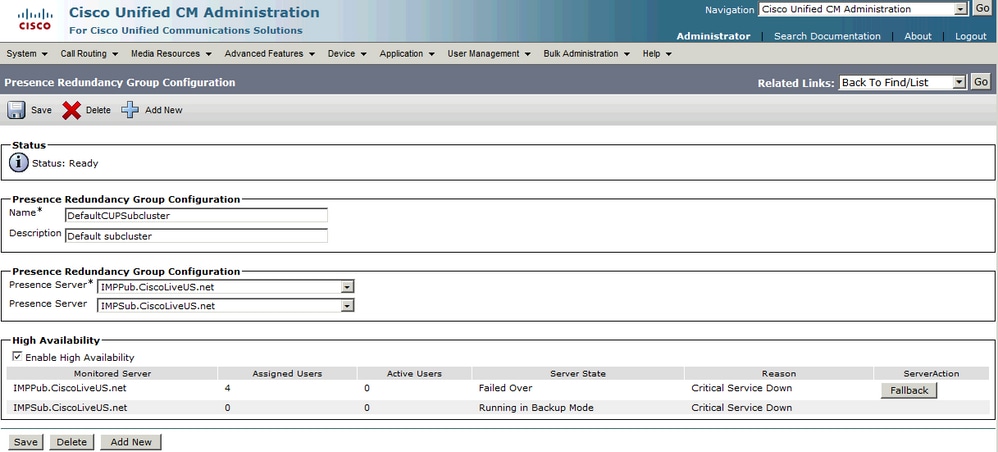
正常 — 正常冗餘組狀態:
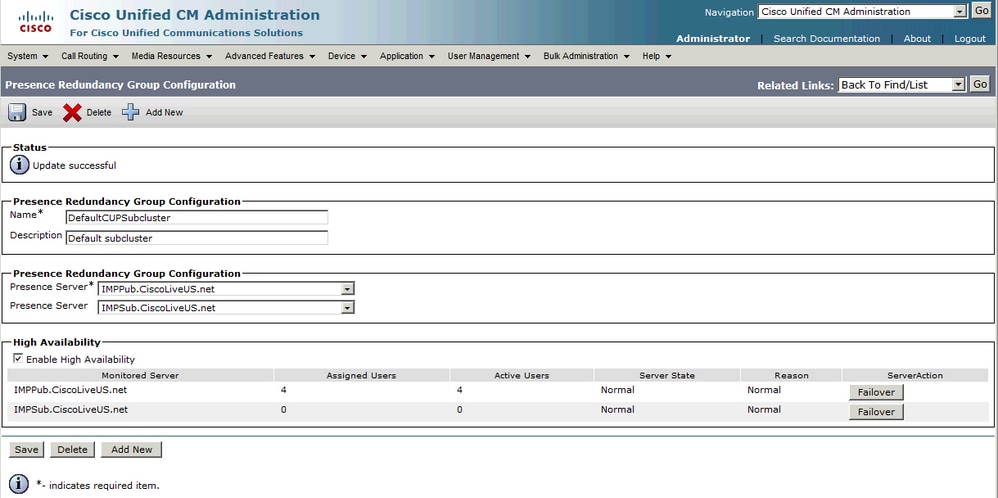
IM&P拓撲頁中的正常 — 正常高可用性狀態:
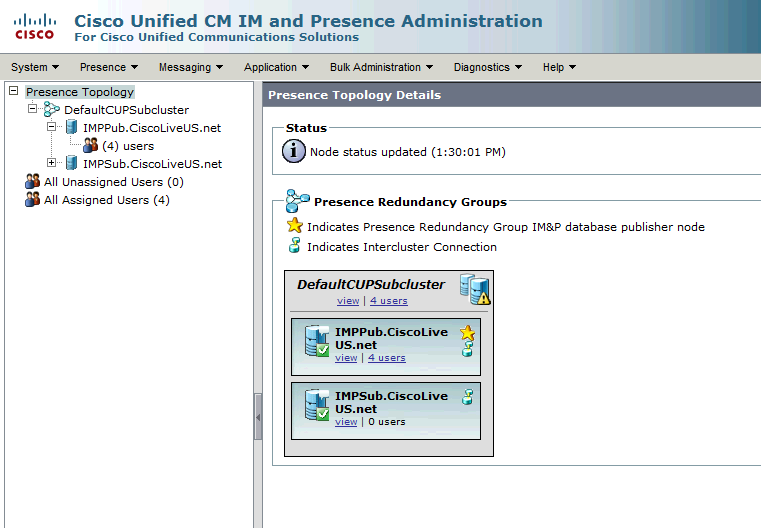
受監控的IM和狀態服務
由於您可以擁有各種部署模式:僅IM、帶SIP/XMPP聯合的IM、帶合規性的IM、帶持續聊天的IM、僅遠端呼叫控制等,因此要監控的這些進程的實際清單是動態的。預設情況下,啟用HA時,一律會監控這些專案:
- IDS資料庫
- Presence Engine(如果已啟用)
- XCP路由器
伺服器恢復管理器檢查以確定是否已配置和啟用符合性(消息歸檔程式)、持續聊天(文本會議管理器)、SIP聯合(SIP聯合連線管理器)和XMPP聯合(XMPP聯合連線管理器)。
如果同時配置並啟用了這些服務,伺服器恢復管理器(SRM)也會監視這些服務。
注意:在繼續重新啟動一個或多個受監控的服務之前,需要從CUCM伺服器上的線上狀態冗餘組禁用高可用性。當執行一個或多個IM&P節點的重新啟動時,也同樣適用。
使用者故障切換過程
當發生故障切換(自動或手動)時,需要記住的主要一點是,使用者帳戶不會從一個伺服器移動到另一個伺服器,而是僅會移動線上狀態引擎中的使用者會話。在IM and Presence的10個前版本中,使用者分配從一個伺服器移動到另一個伺服器。 此使用者移動對於伺服器資源而言非常昂貴,並且會增加伺服器上的負載。 在10.X及更高版本中,使用者將駐留在分配給他們的伺服器上,並且線上狀態引擎中的後端使用者會話將從故障節點移動到功能節點。 當伺服器恢復管理器(SRM)發生更改時,使用者不必退出Jabber並重新登入。
Jabber使用者端重新登入計時器
為了使使用者會話在故障轉移事件後在輔助IM&P節點上完全處於活動狀態,使用者必須嘗試通過SOAP(客戶端配置檔案代理)登入到該伺服器。從IMDB資料庫傳遞的一次性口令會自動發生這種情況。由於登入對IM and Presence伺服器上的資源來說非常昂貴,因此當發生故障切換事件時,必須有一種方法限制登入。 此限制或緩衝區允許所有使用者登入到輔助節點,而不中斷輔助節點上使用者的服務。 用於限制使用者登入的機制是客戶端重新登入下限和客戶端重新登入上限伺服器恢復管理器(SRM)服務引數。
Client Re-Login Lower Limit — 用於定義Jabber客戶端在發生HA事件時嘗試登入到輔助伺服器之前等待的最小時間量(以秒為單位)的引數。
Client Re-Login Upper Limit — 用於定義Jabber客戶端在發生HA事件時嘗試登入到輔助伺服器之前等待的最大時間量(以秒為單位)的引數。
Jabber客戶端在登入到伺服器時接收這些引數,並快取這些值以供將來使用。 當您從IM&P伺服器收到HA事件時,客戶端選擇上限與下限之間的隨機秒數,並等待Jabber客戶端嘗試登入到輔助伺服器之前的時間量。 計時器到期後,客戶端會嘗試通過SOAP登入到輔助節點。
IM和狀態回退型別
如果存在使用者故障切換,則在有問題的伺服器上恢復服務時,必須存在使用者回退。 有兩種型別的伺服器回退:
手動回退
在服務已還原且冗餘組允許「回退」按鈕時,發生手動回退(伺服器恢復管理器的預設配置)。選擇該按鈕後,移動到輔助節點的使用者會話將移回其宿主節點。 然後,Jabber客戶端應用回退的上限和下限重新登入。
自動回退
自動回退發生在伺服器監視服務和伺服器恢復管理器(SRM)服務自動將使用者回退到其宿主節點上。此配置中的關鍵是,伺服器恢復管理器(SRM)服務會等待30分鐘,以便故障服務/伺服器在啟動自動回退之前保持活動狀態。 一旦建立了這30分鐘的正常運行時間,使用者會話將移回其宿主節點。然後,Jabber客戶端應用回退的上限和下限重新登入。

註:自動回退不是預設配置,但可以啟用。 要啟用自動回退,請將Server Recovery Manager Service Parameters中的Enable Automatic Fallback引數更改為值True。
疑難排解
本節提供的資訊可用於對組態進行疑難排解。
排除IM&P服務伺服器上的高可用性故障時,您必須考慮兩個重要的計時器。
- 伺服器每60秒交換4個keepalive。如果60秒後沒有響應,思科服務恢復管理器(SRM)會認為無響應節點已離線,並觸發「故障轉移」命令。如下一段代碼片斷所示,最後一個心跳發生在62秒前。
2021-05-13 02:48:48,244 INFO[HS]rsrm.RsrmHeartBeatHandler - RsrmHeartBeatHandler: peer down, time since last heartbeat[s]= 62
2021-05-13 02:48:48,244 INFO [HS] rsrm.RsrmAutomaticFallback - RsrmAutomaticFallback: peer states vector changed to [Normal,Running in Backup Mode]
提示:對於此情況,如果您在網路中發現一些延遲,建議將心跳超時計時器從60秒增加到90秒。
導航到CUCM管理網頁>系統>服務引數配置>選擇IM&P伺服器>選擇Cisco Recovery ManagerSettings。在Keep Alive(Heartbeat)超時時,將數增加到90秒。
- IM&P訂戶伺服器等待90秒。如果它檢測到一個或多個受監控的服務發生故障,訂閱伺服器將接管該服務。
要收集以進行故障排除的日誌
- Server Recover Manager(SRM)在故障切換事件之前和之後記錄日誌(如有可能,請執行調試級別)。
- 通過IM&P命令列介面從企業子集群運行sql select *命令輸出。
- 通過IM&P命令列介面從企業版運行sql select *命令輸出。
- enterprisenode表顯示節點的節點資訊和子群集分配。
- 如果故障切換是由被停止的服務生成的,請收集:
- 事件檢視器系統日誌
- 事件檢視器應用程式日誌
- 來自已停止服務的日誌。
 意見
意見