Procedimento de recuperação para falha de cluster Ultra-M AutoVNF - vEPC
Opções de download
Linguagem imparcial
O conjunto de documentação deste produto faz o possível para usar uma linguagem imparcial. Para os fins deste conjunto de documentação, a imparcialidade é definida como uma linguagem que não implica em discriminação baseada em idade, deficiência, gênero, identidade racial, identidade étnica, orientação sexual, status socioeconômico e interseccionalidade. Pode haver exceções na documentação devido à linguagem codificada nas interfaces de usuário do software do produto, linguagem usada com base na documentação de RFP ou linguagem usada por um produto de terceiros referenciado. Saiba mais sobre como a Cisco está usando a linguagem inclusiva.
Sobre esta tradução
A Cisco traduziu este documento com a ajuda de tecnologias de tradução automática e humana para oferecer conteúdo de suporte aos seus usuários no seu próprio idioma, independentemente da localização. Observe que mesmo a melhor tradução automática não será tão precisa quanto as realizadas por um tradutor profissional. A Cisco Systems, Inc. não se responsabiliza pela precisão destas traduções e recomenda que o documento original em inglês (link fornecido) seja sempre consultado.
Contents
Introdução
Este documento descreve as etapas necessárias para recuperar o Ultra Automation Services (UAS) ou a falha do AutoVNF Cluster em uma configuração Ultra-M que hospeda o StarOS Virtual Network Functions (VNFs).
Informações de Apoio
A Ultra-M é uma solução de núcleo de pacotes móveis virtualizados, validada e predefinida, projetada para simplificar a implantação de VNFs.
A solução Ultra-M consiste nos tipos de máquina virtual (VM) mencionados:
- TI automática
- Implantação automática
- UAS ou AutoVNF
- Gerenciador de Elementos (EM)
- Controlador de serviços elástico (ESC)
- Função de controle (CF)
- Função de sessão (SF)
A arquitetura avançada do Ultra-M e os componentes envolvidos são descritos nesta imagem:
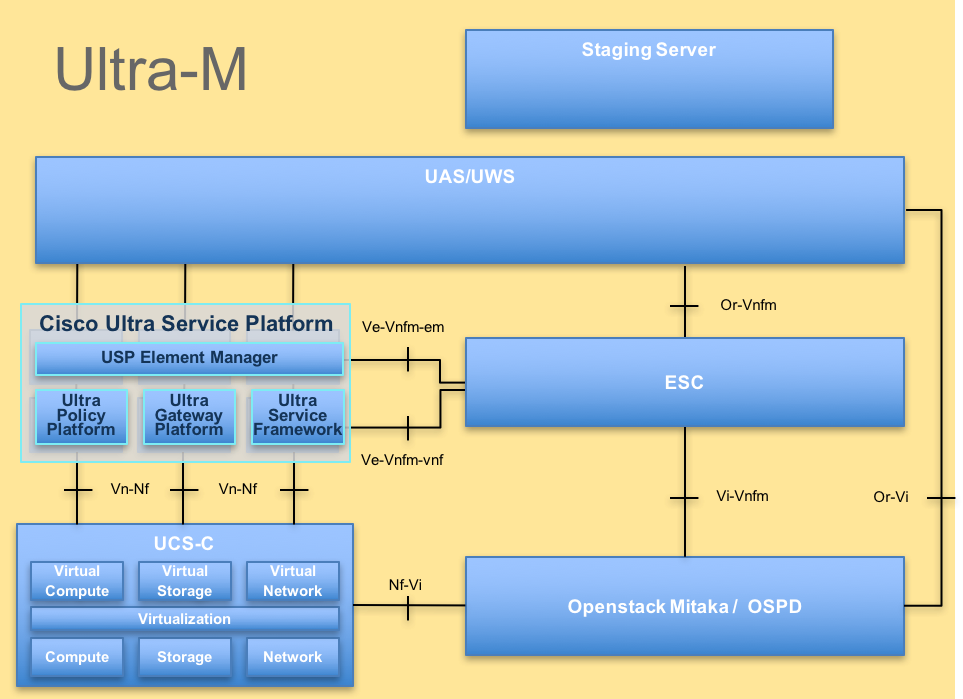 Arquitetura UltraM
Arquitetura UltraM
Este documento destina-se ao pessoal da Cisco que está familiarizado com a plataforma Cisco Ultra-M.
Note: A versão Ultra M 5.1.x é considerada para definir os procedimentos neste documento.
Abreviaturas
| VNF | Função de rede virtual |
| CF | Função de controle |
| SF | Função de serviço |
| ESC | Controlador de serviço elástico |
| MOP | Método de Procedimento |
| OSD | Discos de Armazenamento de Objetos |
| HDD | Unidade de disco rígido |
| SSD | Unidade de estado sólido |
| VIM | Gerente de infraestrutura virtual |
| VM | Máquina virtual |
| EM | Gerenciador de Elementos |
| UAS | Ultra Automation Services |
| UUID | Identificador Exclusivo Universal |
Fluxo de trabalho do MoP
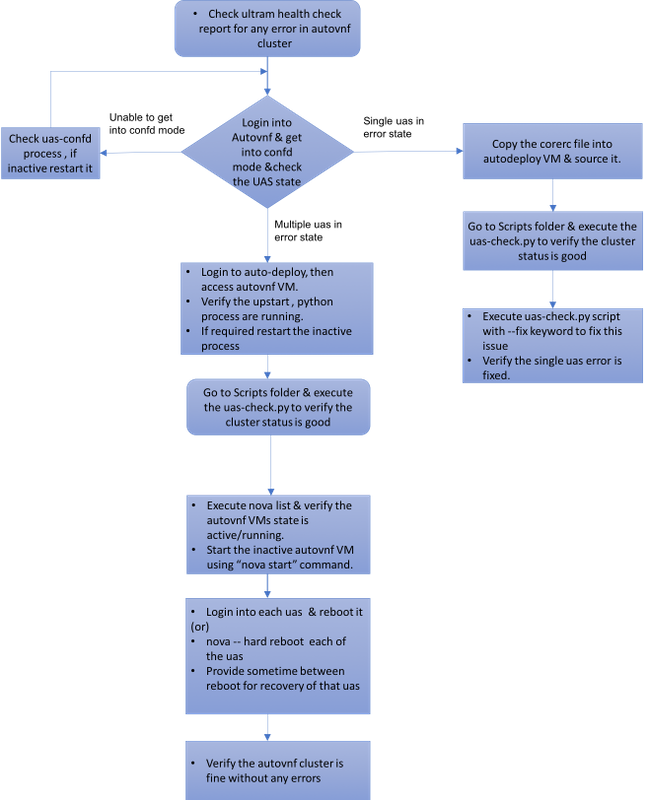
Caso 1. Recuperação da Falha Única do Cluster de UAS
Verificação de status
1. O Ultra-M Manager executa a verificação de integridade do nó Ultra-M. Navegue até o diretório reports /var/log/cisco/ultram-health/ e grep para o relatório UAS.
-
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | XXX | AutoVNF Cluster FAILED : Node: 172.16.180.12, Status: error, Role: NA
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
2. O status esperado do cluster de UAS será conforme descrito, onde todos os três UAS estão vivos.
[stack@pod1-ospd ~]# ssh ubuntu@10.1.1.1
password:
ubuntu@autovnf1-uas:~$ ncs_cli -u admin -C
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.12 alive NA
Falha ao Conectar-se ao Servidor Confiável ao Tentar Conectar-se ao UAS
1. Em alguns casos, você não poderá se conectar ao servidor confd.
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ confd_cli -u admin -C
Failed to connect to server
2. Verifique o status do processo uas-confd.
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ sudo initctl status uas-confd
uas-confd stop/waiting
3. Se o servidor confd não for executado, reinicie o serviço.
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ sudo initctl start uas-confd
uas-confd start/running, process 7970
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 172.16.180.9 using ssh on autovnf1-uas-0
Recuperar UAS do Estado de Erro
1. Em caso de falha de um AutoVNF entre o cluster, o cluster de UAS mostra um dos UAS no estado Erro .
[stack@pod1-ospd ~]# ssh ubuntu@10.1.1.1
password:
ubuntu@autovnf1-uas:~$ ncs_cli -u admin -C
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.12 alive error
2. Copie o arquivo corerc (rc do seu VNF) de /home/stack no servidor OSPD para AutoDeploy e o origine.
3. Verifique o status do seu UAS/AutoVNF com o uso do script uas-check.py . autovnf1 é o nome AutoVNF.
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts/uas-check.py auto-vnf autovnf1
2017-11-17 14:52:20,186 - INFO: Check of AutoVNF cluster started
2017-11-17 14:52:22,172 - INFO: Found 2 AutoVNF instance(s), 3 expected
2017-11-17 14:52:22,172 - INFO: Instance 'autovnf1-uas-2' is missing
2017-11-17 14:52:22,172 - INFO: Check completed, AutoVNF cluster has recoverable errors
4. Recupere o UAS com o uso do script uas-check.py e adicione a palavra-chave —fix.
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts/uas-check.py auto-vnf autovnf1 --fix
2017-11-17 14:52:27,493 - INFO: Check of AutoVNF cluster started
2017-11-17 14:52:29,215 - INFO: Found 2 AutoVNF instance(s), 3 expected
2017-11-17 14:52:29,215 - INFO: Instance 'autovnf1-uas-2' is missing
2017-11-17 14:52:29,215 - INFO: Check completed, AutoVNF cluster has recoverable errors
2017-11-17 14:52:29,386 - INFO: Creating instance 'autovnf1-uas-2' and attaching volume 'autovnf1-uas-vol-2'
2017-11-17 14:52:47,600 - INFO: Created instance 'autovnf1-uas-2'
5. Você verá que o UAS recém-criado está ativo e faz parte do cluster.
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.13 alive NA
Caso 2. Os Três UAS (AutoVNF) estão em Estado de Erro
1. O Ultra-M Manager executa a verificação de integridade do nó Ultra-M.
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | XXX | AutoVNF Cluster FAILED : Node: 172.16.180.12, Status: error, Role: NA,Node: 172.16.180.9, Status: error, Role: NA,Node: 172.16.180.10, Status: error, Role: NA
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
2. Como observado na saída, o gerenciador Ultra-M relata que há uma falha para AutoVNF e mostra que todos os três UAS do cluster estão no estado Erro.
Verifique a integridade do UAS com o script uas-check.py
1. Inicie a sessão no AutoDeploy e verifique se você pode acessar o AutoVNF UAS e obter o status.
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts$ ./uas-check.py auto-vnf autovnf1 --os-tenant-name core
2017-12-05 11:41:09,834 - INFO: Check of AutoVNF cluster started
2017-12-05 11:41:11,342 - INFO: Found 3 ACTIVE AutoVNF instances
2017-12-05 11:41:11,343 - INFO: Check completed, AutoVNF cluster is fine
2. A partir da Implantação Automática, Secure Shell (SSH) para o nó AutoVNF e entre no modo confd. Verifique o status com show uas.
ubuntu@auto-deploy-iso-590-uas-0:~$ ssh ubuntu@172.16.180.9
password:
autovnf1-uas-1#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
----------------------------
172.16.180.9 error NA
172.16.180.10 error NA
172.16.180.12 error NA
3. É recomendável verificar o status nos três nós de UAS.
Verifique o estado das VMs no nível do OpenStack
Verifique o status das VMs AutoVNF na lista de novas. Se necessário, execute início de nova para iniciar a VM de desligamento.
[stack@pod1-ospd ultram-health]$ nova list | grep autovnf
| 83870eed-b4e9-47b3-976d-cc3eddecf866 | autovnf1-uas-0 | ACTIVE | - | Running | orchestr=172.16.180.12; mgmt=172.16.181.6
| 201d9ce5-538c-42f7-a46c-fc8cdef1eabf | autovnf1-uas-1 | ACTIVE | - | Running | orchestr=172.16.180.10; mgmt=172.16.181.5
| 6c6d25cd-21b6-42b9-87ff-286220faa2ff | autovnf1-uas-2 | ACTIVE | - | Running | orchestr=172.16.180.9; mgmt=172.16.181.13
Verificar a Visão do Zookeeper
1. Verifique o estado do zookeeper para verificar o modo como líder.
ubuntu@autovnf1-uas-0:/var/log/upstart$ /opt/cisco/usp/packages/zookeeper/current/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/cisco/usp/packages/zookeeper/current/bin/../conf/zoo.cfg
Mode: leader
2. O Zookeeper normalmente deve estar ativado.
Identificar e Solucionar Problemas do AutoVNF - Processos e Tarefas
1. Identifique o motivo do estado Erro dos nós. Para que o AutoVNF seja executado, há um conjunto de processos que devem estar ativos e em execução, como mostrado:
AutoVNF
uws-ae
uas-confd
cluster_manager
uas_manager
ubuntu@autovnf1-uas-0:~$ sudo initctl list | grep uas
uas-confd stop/waiting ====> this is not good, the uas-confd process is not running
uas_manager start/running, process 2143
root@autovnf1-uas-1:/home/ubuntu# sudo initctl list
....
uas-confd start/running, process 1780
....
autovnf start/running, process 1908
....
....
uws-ae start/running, process 1909
....
....
cluster_manager start/running, process 1827
....
.....
uas_manager start/running, process 1697
......
......
2. Verifique se estes processos python estão em execução:
uas_manager.py
cluster_manager.py
usp_autovnf.py
root@autovnf1-uas-1:/home/ubuntu# ps -aef | grep pyth
root 1819 1697 0 Jun13 ? 00:00:50 python /opt/cisco/usp/uas/manager/uas_manager.py
root 1858 1827 0 Jun13 ? 00:09:21 python /opt/cisco/usp/uas/manager/cluster_manager.py
root 1908 1 0 Jun13 ? 00:01:00 python /opt/cisco/usp/uas/autovnf/usp_autovnf.py
root 25662 24750 0 13:16 pts/7 00:00:00 grep --color=auto pyth
3. Se algum dos processos esperados não estiver no estado inicial/em execução, reinicie o processo e verifique o status. Se ele ainda aparecer no estado Erro, siga o procedimento mencionado na próxima seção para corrigir esse problema.
Correção para vários UAS em estado de erro
1. nova — reinicialização forçada <nome da VM> a partir do OSPD, dê algum tempo para a recuperação dessa VM antes de prosseguir para o próximo UAS. Faça isso em todas as VMs de UAS.
or
2.Faça login em cada um dos UAS e use sudo reboot. Aguarde a recuperação e prossiga para outras VMs de UAS.
Para logs de transação, verifique:
/var/log/upstart/autovnf.log
show logs xxx | display xml
Isso corrigirá o problema e recuperará o UAS do estado Erro.
1. Verifique o mesmo com o uso do relatório ultram_health_check.
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | :-) |
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
Colaborado por engenheiros da Cisco
- Partheeban RajagopalServiços avançados da Cisco
- Padmaraj RamanoudjamServiços avançados da Cisco
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)