Introdução
Este documento descreve como solucionar problemas de utilização de espaço em disco elevado para o sistema de arquivos /dev/vda3 no RCM.
Pré-requisitos
Requisitos
A Cisco recomenda que você tenha conhecimento de:
- Administração e arquitetura do sistema StarOS Control and User Plane Separation (CUPS).
- Comandos Linux/Unix básicos para monitoração do sistema de arquivos e da utilização do disco.
Componentes Utilizados
Este documento não se restringe a versões de software e hardware específicas.
As informações neste documento foram criadas a partir de dispositivos em um ambiente de laboratório específico. Todos os dispositivos utilizados neste documento foram iniciados com uma configuração (padrão) inicial. Se a rede estiver ativa, certifique-se de que você entenda o impacto potencial de qualquer comando.
Overview
Em implantações do Cisco Ultra Packet Core com Control e User Plane Separation (CUPS), o Redundancy Control Manager (RCM) desempenha um papel crítico nas operações e no gerenciamento do plano de controle. A utilização estável do sistema de arquivos em nós RCM é importante para garantir o bom funcionamento do registro, monitoramento e gerenciamento da sessão do assinante.
A alta utilização de espaço em disco no sistema de arquivos raiz (/dev/vda3) pode causar instabilidade no sistema, falhas nas gravações de log ou até mesmo reinicializações de serviço se não for marcada. Este artigo descreve a análise, as etapas de solução de problemas e as medidas preventivas para lidar com a alta utilização do disco em nós RCM.
Análise e observação
Durante o monitoramento, descobriu-se que o nó RCM atingiu 72% de utilização em seu sistema de arquivos raiz.
Instantâneo de Utilização de Disco
df -kh
Filesystem Size Used Avail Use% Mounted on
tmpfs 6.3G 9.7M 6.3G 1% /run
/dev/vda3 39G 27G 11G 72% /
tmpfs 32G 4.0K 32G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/vda2 488M 48K 452M 1% /var/tmp
/dev/vda1 488M 76K 452M 1% /tmp
Em uma investigação mais aprofundada, observou-se que os logs de diário em /var/log/journal/ tinham crescido significativamente. Os logs gerados somente em julho representaram aproximadamente 3 GB de espaço.
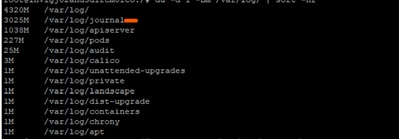
Processo de solução de problemas
Para controlar a utilização do disco, foram aplicadas as etapas necessárias de implementação da alteração:
Passo 1: Limpe registros antigos usando o vácuo do journalctl
Reter apenas as últimas duas semanas de logs:
sudo journalctl --vacuum-time=2weeks
Ou limite o tamanho do diário (por exemplo, mantenha apenas 600 MB):
sudo journalctl --vacuum-size=600M
Etapa 2: Configurar Retenção de Diário para Prevenção Futura
Editar configuração do diário:
vi /etc/systemd/journald.conf
Adicionar/modificar parâmetro:
MaxRetentionSec=2week
Aplicar configuração:
sudo systemctl restart systemd-journald
Etapa 3 opcional: Resolver erro de reinicialização
Ao reiniciar o serviço systemd-journald na Etapa 2, você pode obter um erro preocupado:
Error : Failed to allocate directory watch: Too many open files
-
systemd-journald usa inotify para observar alterações nos diretórios de log.
-
Cada relógio ou monitor ele configura as contagens para certos limites do kernel.
Os limites atuais definidos no RCM problemático são:
cat /proc/sys/fs/inotify/max_user_watches
501120
cat /proc/sys/fs/inotify/max_user_instances
128
ulimit -n
1024
A partir da saída coletada:
- Max identifique relógios: 501120
- Máximo de instâncias inotify: 128
Limite do descritor de arquivo aberto para o diário: 1024
Um (ou todos) os valores de saída podem ter atingido o limite levando ao erro. Portanto, coletamos o valor usado atual e os comparamos com o limite de saída coletado:
sudo lsof -p $(pidof systemd-journald) | wc -l
65
echo "Root inotify instances: $(sudo find /proc/*/fd -user root -type l -lname 'anon_inode:inotify' 2>/dev/null | wc -l) / $(cat /proc/sys/fs/inotify/max_user_instances)"
Root inotify instances: 126 / 128
Parece que a raiz já está usando 126 das 128 instâncias de inotify permitidas. Isso deixa journald quase sem espaço para criar uma nova instância de inotify quando a reiniciamos.
Para resolver o erro: podemos aumentar o valor de max_user_instances e reiniciar o serviço:
# Temporarily increase the limit (until next reboot)
echo 256 > /proc/sys/fs/inotify/max_user_instances
sudo systemctl restart systemd-journald
# Temporarily increase the limit (until next reboot)
echo 256 > /proc/sys/fs/inotify/max_user_instances
sudo systemctl restart systemd-journald
Verificação pós-alteração
Depois de aplicar as alterações, a utilização do disco caiu para 61%, restaurando o nó para o estado operacional normal.
df -kh
Filesystem Size Used Avail Use% Mounted on
tmpfs 6.3G 9.7M 6.3G 1% /run
/dev/vda3 39G 23G 15G 61% /
tmpfs 32G 4.0K 32G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/vda2 488M 48K 452M 1% /var/tmp
/dev/vda1 488M 76K 452M 1% /tmp
Recomendação
-
Implemente a mesma configuração em todos os nós RCM na implantação para manter a utilização do disco dentro dos limites de segurança.
-
Sempre coloque o RCM de destino no modo de espera antes de executar as alterações para evitar impacto no tráfego em tempo real.
-
Monitore periodicamente a utilização de /dev/vda3 e o crescimento do registro do diário como parte das verificações de integridade proativas do sistema.
 Feedback
Feedback