Solucione problemas de falha de replicação entre racks com o código de erro "424-Geo-replication Checksum Mismatch"
Opções de download
Linguagem imparcial
O conjunto de documentação deste produto faz o possível para usar uma linguagem imparcial. Para os fins deste conjunto de documentação, a imparcialidade é definida como uma linguagem que não implica em discriminação baseada em idade, deficiência, gênero, identidade racial, identidade étnica, orientação sexual, status socioeconômico e interseccionalidade. Pode haver exceções na documentação devido à linguagem codificada nas interfaces de usuário do software do produto, linguagem usada com base na documentação de RFP ou linguagem usada por um produto de terceiros referenciado. Saiba mais sobre como a Cisco está usando a linguagem inclusiva.
Sobre esta tradução
A Cisco traduziu este documento com a ajuda de tecnologias de tradução automática e humana para oferecer conteúdo de suporte aos seus usuários no seu próprio idioma, independentemente da localização. Observe que mesmo a melhor tradução automática não será tão precisa quanto as realizadas por um tradutor profissional. A Cisco Systems, Inc. não se responsabiliza pela precisão destas traduções e recomenda que o documento original em inglês (link fornecido) seja sempre consultado.
Contents
Introdução
Este documento descreve vários métodos de investigação para solucionar problemas de Incompatibilidade de Soma de Verificação de Replicação Geográfica entre os racks Local e Remoto.
Pré-requisitos
Requisitos
A Cisco recomenda que você tenha conhecimento destes tópicos:
- Redundância geográfica em função de gerenciamento de sessão (SMF)
- SMF
- Encerramento de Conexão do Protocolo de Controle de Transmissão (TCP)
Componentes Utilizados
Este documento não se restringe a versões de software e hardware específicas.
As informações neste documento foram criadas a partir de dispositivos em um ambiente de laboratório específico. Todos os dispositivos utilizados neste documento foram iniciados com uma configuração (padrão) inicial. Se a rede estiver ativa, certifique-se de que você entenda o impacto potencial de qualquer comando.
Informações de Apoio
O que é redundância geográfica no SMF?
-
O SMF oferece suporte a GR (Geographical - Geographical Redundancy - Redundância geográfica) no modo ativo-ativo.
-
A configuração do GR também é responsável pela replicação dos
etcd/cachedados para o rack em standby. -
O SMF suporta redundância primária/standby na qual os dados são replicados da instância primária para a instância standby.
-
Se a instância principal falhar, a instância stand-by se tornará a principal e assumirá a operação.
-
Para atingir o GR, dois pares principal/standby podem ser configurados onde cada site processa ativamente o tráfego e o standby atua como um backup para o site remoto.
Pod de replicação geográfica
-
O Pod de replicação geográfica é apresentado para comunicação entre racks/locais e para monitorar POD/BFD dentro do rack
-
Duas instâncias de GR-POD são executadas em cada rack/local
-
Dois GR PODs funcionam no modo Ative-Standby
-
GR PODs são gerados no nó Proto/VM
-
O GR POD usa dois Endereços IP Virtuais (VIPs)
-
VIP interno para comunicação entre PODs (dentro do rack)
-
VIP externo para comunicação POD GR entre racks/locais
-
VIPs configurados para POD GR podem estar ativos em um dos nós/VM Proto
-
Quando o POD GR ativo é reiniciado, o VIP é comutado para outro nó/VM Proto e o POD GR em standby executado no outro nó/VM Proto pode se tornar Ativo
Configuração de referência do GR Pod:
smf# show running-config instance instance-id 1 endpoint geo
Thu Oct 20 06:25:25.319 UTC+00:00
instance instance-id 1
endpoint geo
replicas 1
nodes 2
interface geo-internal
vip-ip a.b.c.d vip-port 7001
exit
interface geo-external
vip-ip Y.Y.Y.Y vip-port 7002
exit
exit
exit
Identificar o Geo Pod ativo e o Geo Pod em standby
Para identificar o pod geográfico ativo, você precisa verificar se há erros ou eventos nos logs do pod geográfico.
Pod ativo:
user@smf-ims-master-1:~$ kubectl logs georeplication-pod-0 -n smf-smfix1|tail -3
[ERROR] [grcacachepod.go:339] [gr_deferred_sync.application.app] Periodic Sync: Total time taken to sync IPAM cache pod data: 500.563723ms”
[ERROR] [GeoAdminStreamClient.go:276] [gr_pod.geo_admin_client.app] no one waiting for received response for txnID:CP0XXXOKCP0XXX-SMF-IMS-smfix1111163550 of host=geo-admin-pod2
Pod de espera:
user@cp0xxx-smf-ims-master-1:~$ kubectl logs georeplication-pod-1 -n smf-smfix1|tail -3
[ERROR] [gr_pod.geo_replication_client_stream] Counters => not an active geo pod
[ERROR] [gr_pod.geo_replication_client_stream] Counters => not an active geo pod
[ERROR] [gr_pod.geo_replication_client_stream] Counters => not an active geo pod
Funcionalidades do GR POD
Pods GR Replicam os dados do ETCD e do pod de cache em todo o local
Para visualizar detalhes de replicação para dados ETCD e cache-pod, use CLI:
[cp0xxx-smf-ims/smfix1] smf# show georeplication checksum instance-id 1
Thu Oct 20 07:11:52.409 UTC+00:00
checksum-details
-- ---- --------
ID Type Checksum
-- ---- -------
1 ETCD 1666249907
IPAM CACHE 1666249907
NRFMgmt CACHE 1666249907
Manter Funções de Instâncias Locais de Site no ETCD
[ERROR] [gr_pod.gradmin] updateEntryInEtcd: Updating etcd entries for keys : Instance.2, with role as PRIMARY
[ERROR] [gr_pod.gradmin] updateEntryInEtcd: Updating etcd entries for keys : Instance.1, with role as STANDBY
Monitorar o status do site local (status do POD/status do BFD)
[cp0xxx-smf-ims/smfix1] smf# show running-config geomonitor podmonitor pods smf-service
Thu Oct 20 07:36:41.280 UTC+00:00
geomonitor podmonitor pods smf-service
retryCount 2
retryInterval 900
retryFailOverInterval 500
failedReplicaPercent 60
Funções do Site
PRIMARY : O site está pronto e recebe tráfego ativamente para a instância determinada.
STANDBY: O site está em espera, pronto para receber tráfego, mas não recebe tráfego para uma determinada instância.
STANDBY_ERROR: O site está com problema, não está ativo e não está pronto para receber tráfego para uma determinada instância.
FAILOVER_INIT: O site iniciou o failover e não está na condição de receber tráfego, tempo de buffer de 2s para o aplicativo concluir sua atividade.
FAILOVER_COMPLETE: O site concluiu o failover e tentou informar o site de mesmo nível sobre o failover da instância especificada. tempo de buffer de 2s.
FAILBACK_STARTED: O failover manual é acionado com um atraso do site remoto para uma determinada instância.

Note: A replicação de cache/ETCD e a replicação de CDL aconteceriam mesmo em todas as funções. Se os links GR estiverem inativos/a pulsação periódica falhar, os gatilhos GR serão suspensos.
GR-Disparadores
CLI para verificar as funções da instância GR no rack
Show role instance id 1
Show role instance id 2
CLI para redefinir função de erro de standby para standby
Geo reset-role instance-id <1/2> role standby
Erro de CLI para função de switch do modo de espera para o modo de espera
Geo switch-role instance-id <1/2> role standby failback-interval 0
CLI para função de switch do modo de espera para o primário
Para iniciar essa função do Switch, você precisa acionar a CLI no Rack que tem uma das Instâncias como Primária.
Geo switch-role instance-id <1/2> role standby failback-interval 0
Note: Cenário de dia ensolarado: Rack1-Instância1-Primário, Instância2-Em Espera; Rack2-Instância1-EmEspera, Instância2-Primária.
Cenário de dia chuvoso: Rack1-Instância 1 e Instância 2-Primária; Rack2-Instância 1 e Instância 2-StandBy.
Encerramento da conexão TCP
O Protocolo TCP é um protocolo orientado a conexão, o que significa que uma conexão é estabelecida e mantida até que os programas de aplicação em cada extremidade tenham terminado a troca de mensagens. O TCP funciona com o Internet Protocol (IP).
O handshake TCP também é conhecido como handshake triplo. Quando uma conexão é iniciada da máquina cliente para a máquina servidor, o cliente e o servidor trocam pacotes SYN e ACK antes que os dados sejam transmitidos.
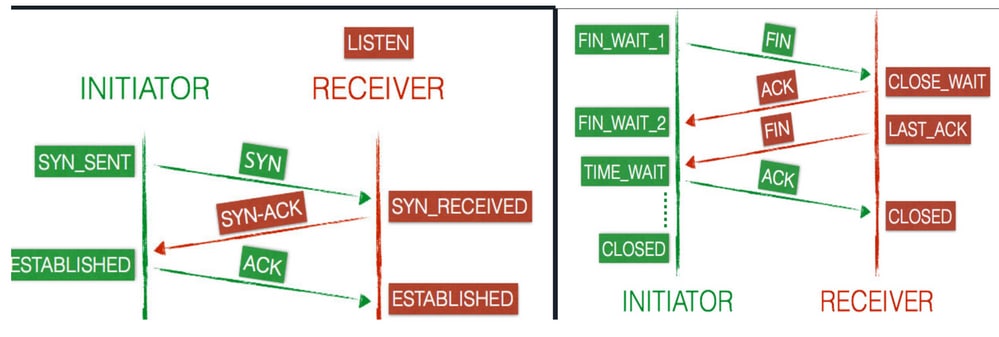 Protocolo de Controle de Transmissão :Estados de Conexão de Cliente e Servidor
Protocolo de Controle de Transmissão :Estados de Conexão de Cliente e Servidor
Uma conexão progride através de uma série de estados ao longo de sua vida útil. Os estados são: LISTEN, SYN-SENT, SYN-RECEIVED, ESTABLISHED, FIN-WAIT-1, FIN-WAIT-2,CLOSE-WAIT,CLOSING LAST-ACK TIME-WAITCLOSED, , e o estado ficcional exibido.
- Quando uma nova conexão TCP é aberta, o cliente (iniciador) envia um
SYNpacote ao servidor (receptor) e atualiza seu estado paraSYN-SENT. - Em seguida, o servidor envia uma
SYN-ACKresposta ao cliente que altera seu estado de conexão paraSYN-RECEIVED.
- O cliente responde com um
ACKe a conexão é marcada comoESTABLISHEDem ambos os pontos finais, agora o cliente e o servidor estão prontos para transferir dados.
- O cliente envia um
FINpacote ao servidor e atualiza seu estado paraFIN-WAIT-1. - O servidor recebe a solicitação de término do cliente e responde com um
ACK. Após a resposta, o servidor entra em umCLOSE-WAITestado. - Assim que o cliente recebe a resposta do servidor, ele vai para o
FIN-WAIT-2estado. - O servidor ainda está no estado
CLOSE-WAITe ele vai independentemente com um FIN, que atualiza o estado paraLAST-ACK. - Agora, o cliente recebe a solicitação de terminação e responde com um
ACK, o que resulta em umTIME-WAITestado. - O servidor está concluído e define a conexão para
CLOSEDimediatamente. - O cliente permanece no estado
TIME-WAITpor no máximo quatro minutos, antes que a conexão sejaCLOSEDinterrompida.
Problema
Cenário 1. A Soma de Verificação de Replicação Geográfica para a Id de Instância 1 tem Cache do IPAM e Incompatibilidade de Soma de Verificação de Cache NRFMgmt
falha no status de replicação geográfica smfix1/smfix2 (Falha na replicação entre racks para o site remoto).
ERRO: Falha do comando Admin [pod internal-gr-pod-1, URL http://X.X.0.0:15290/commands] com Código 424, Falha na mensagem: incompatibilidade de soma de verificação de replicação.
O problema foi observado em 23 de agosto às 00:36:19 como "Falha na replicação entre racks".
From CEE alerts:
Inter_Rack_Replication 9ca45362a049 critical 08-23T00:36:19 System
Inter rack replication to Remote Site failed
Nesta saída da CLI, você pode ver instance-id 1 has Checksum Mismatch for IP Address Management (IPAM) and NRF Cache.
[cp0xxx-smf-ims/smfix1] smf# show georeplication checksum instance-id 1
Mon Sep 5 08:38:27.762 UTC+00:00
checksum-details
-- --- --------
ID Type Checksum
-- ---- --------
1 ETCD 1662367102
IPAM CACHE 1662367102
NRFMgmtCACHE 1662367102
[cp0xxx-smf-ims/smfix2] smf# show georeplication checksum instance-id 1
Mon Sep 5 08:38:30.767 UTC+00:00
checksum-details
-- ---- --------
ID Type Checksum
-- ---- --------
1 ETCD 1662367102
IPAM CACHE 1661214831
NRFMgmtCACHE 1661214831
Cenário 2. A Soma de Verificação de Replicação Geográfica para a Id de Instância 2 tem Incompatibilidade de Soma de Verificação ETCD
[cp0xxx-smf-ims/smfix1] smf# show georeplication checksum instance-id 2
Mon Sep 5 08:38:37.852 UTC+00:00
checksum-details
-- ---- --------
ID Type Checksum
-- ---- --------
2 ETCD 1661214828
IPAM CACHE 1662367107
NRFMgmtCACHE 1662367107
[cp0xxx-smf-ims/smfix2] smf# show georeplication checksum instance-id 2
Mon Sep 5 08:38:39.118 UTC+00:00
checksum-details
-- ---- -------
ID Type Checksum
-- ---- --------
2 ETCD 1662367107
IPAM CACHE 1662367107
NRFMgmtCACHE 1662367107
Cenário 3. Falha no Estabelecimento da Conexão TCP com Site Remoto
Rack1-smfix1-logs:
A partir dos registros GR Pod, você pode observar que o ponto de verificação Atualizar pod do cache está parado, a replicação imediata falhou e nenhum host remoto está disponível.
2022/08/23 00:34:00.035 [ERROR] [grreplicationclient.go:201] [gr_pod.geo_replication_client_stream.app] HandleImmediateReplication failed: [RPCNoRemoteHostAvailable] No remote host available for this request
2022/08/23 00:34:02.086 [ERROR] [grreplicationclient.go:466] [gr_pod.geo_replication_client_stream.app] Stream disconnected, closing logQueueCounter=0xc0093b08b0
2022/08/23 00:34:04.124 [ERROR] [GeoAdminStreamClient.go:215] [gr_pod.geo_admin_client.app] ADMIN(geo-admin-pod2) : exit outgoing request loop stream closed
2022/08/23 00:34:43.623 [ERROR] [grreplicationclient.go:270] [gr_pod.geo_replication_client_stream.app] Update etcd checkpointing stopped for grinstance: 1
Rack2-smfix2-logs:
A partir dos registros GR Pod, você pode observar o erro de desconexão de fluxo e a diferença da soma de verificação de CACHE é maior do que o esperado.
2022/08/23 00:34:06.497 [ERROR] [grreplicationserver.go:62] [gr_pod.geo_replication_server_stream.app] Stream disconnected, closing logQueueCounter=0xc001b85d08
2022/08/23 00:34:06.497 [ERROR] [grreplicationserver.go:314] [gr_pod.geo_replication_server_stream.app] handleCachePodSyncRequests : Stream closed of connection=0xc002ee08f0
2022/08/23 00:34:56.751 [ERROR] [grpodcommands.go:455] [gr_pod.cli_command.app] compareChecksumData: CACHE checksum difference is more then expected, local checksum [1661214831] remote checksum [1661214892]
2022/08/23 00:34:56.678 [ERROR] [etcdAuditReplHandler.go:196] [gr_pod.application.app] SyncETCDData periodic sync : For ETCD [C.GR.1.] key, the remote site data size is: [10833]
2022/08/23 00:36:56.757 [ERROR] [grpodcommands.go:455] [gr_pod.cli_command.app] compareChecksumData: CACHE checksum difference is more then expected, local checksum [1661214831] remote checksum [1661215012]
Cenário 4. Erro de DIMM Observado no Servidor que Hospeda o Nó Mestre
O erro de ECC é visto no nó master-1 que hospeda geo-replication-pod-0 quase ao mesmo tempo que o erro de desconexão de fluxo.
CP0XXX-Server9-02# scope sel
CP0XXX-Server9-02 /sel # show entries
Time Severity Description
----------------------- ------------- ----------------------------------------
2022-08-23 00:33:59 UTC Informational "DDR4_P1_E1_ECC: Memory sensor, read 1 correctable ECC errors on CPU1 DIMM E1 was asserted"
2022-08-22 22:59:45 UTC Informational "DDR4_P1_E1_ECC: Memory sensor, read 1 correctable ECC errors on CPU1 DIMM E1 was asserted"
- A comunicação entre o pod de replicação geográfica em Rack1 e o pod de replicação geográfica em Rack2 foi interrompida.
-
Ocorre um erro de DIMM em um dos nós principais que fez com que a conexão de fluxo ficasse inativa entre Rack1 e Rack2.
-
A partir do Rack1, o pod de replicação geográfica não conseguiu replicar ou enviar qualquer solicitação ao Rack2, ele aparece com o erro Host remoto não disponível.
-
A partir da saída do comando netstat em Rack1 e Rack2 para a porta 7002, constatou-se que o soquete Rack1 está preso no estado FIN_WAIT1 e o soquete Rack2 está preso no estado SYN_RECV.
-
No lado do servidor, ou seja, no Rack2, o soquete está preso no estado SYNC_RECV, e a conexão recém-criada também entra no estado SYNC_RECV e não consegue se comunicar.
-
A conexão está no estado SYN_RECV porque o kernel recebeu um pacote SYN para uma porta, isto é, no modo LISTENING, mas a outra extremidade não respondeu com ACK.
O smfix2-Master-2 tem o VIP externo geográfico (Y.Y.Y:7002) instalado, mas o estado de conexão TCP do host remoto (SMFIX1) está preso no estado SYN_RECV em vez do estado ESTABLISHED. a.b.c.d e a.b.c.e são IPs Master-1 e 2 de smfix1 (Rack1).
user@cp0xxx-smf-ims-master-2:~$ netstat -anp | grep 7002
tcp 0 0 Y.Y.Y.Y:7002 0.0.0.0:* LISTEN -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:35542 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:47046 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:36248 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:42686 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:38248 SYN_RECV -
O status da conexão TCP do VIP Geográfico Externo no smfix1 (Rack1) para par Remoto está no estado FIN-WAIT1:
user@cp0xxx-smf-ims-master-1:~$ netstat -anp | grep 7002
tcp 0 0 a.b.c.d 0.0.0.0:* LISTEN -
tcp 0 1 a.b.c.d:60866 Y.Y.Y.Y:7002 FIN_WAIT1 -
tcp 0 1 a.b.c.d:52274 Y.Y.Y.Y:7002 FIN_WAIT1 -
tcp 0 1 a.b.c.d:59674 Y.Y.Y.Y:7002 FIN_WAIT1 -
tcp 0 1 a.b.c.d:47926 Y.Y.Y.Y:7002 FIN_WAIT1 -
Solução
Rack1:
-
Primeiro, exclua o pod Geo em espera, aguarde a recuperação do pod e, em seguida, exclua o pod Geo Ativo. Faça login no Master VIP e exclua o pod GR:
kubectl delete pod-n
Rack2:
- Primeiro, exclua o pod geográfico em espera, aguarde a recuperação do pod e, em seguida, exclua o pod geográfico ativo.
-
Verifique o status de replicação geográfica a partir do CLI, publique a exclusão dos GeoPods.
show georeplication-status
- Após a exclusão do pod Geo em Rack1 e Rack2, você pode ver o IP VIP Geo Externo: A porta TCP passa para o estado ESTABLISHED.
- Status de Replicação Geográfica "Aprovado".
- Nenhuma incompatibilidade de checksum é vista no status de replicação nos racks.
smfix2 (Rack2):
user@cp0xxx-smf-ims-master-1:~$ sudo netstat -anp | grep 7002 | grep -v aa
tcp 0 0 Y.Y.Y.Y:7002 0.0.0.0:* LISTEN 36854
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:46402 ESTABLISHED 36854/grpod
tcp 0 0 Y.Y.Y.Y:7002 1a.b.c.e:54708 ESTABLISHED 36854/grpod
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:55152 ESTABLISHED 36854/grpod
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:46530 ESTABLISHED 36854/grpod
tcp 0 0 10.59.0.0:7002 10.59.0.0:46532 ESTABLISHED 36854/grpod
smfix1 (Rack1):
user@cp0xxx-smf-ims-master-1:~$ sudo netstat -anp | grep 7002 | grep -v aa
tcp 0 0 a.b.c.d 0.0.0.0:* LISTEN 53932/grpod
tcp 0 0 a.b.c.d:46530 Y.Y.Y.Y:7002 ESTABLISHED 53932/grpod
tcp 0 0 a.b.c.d:46402 Y.Y.Y.Y:7002 ESTABLISHED 53932/grpod
tcp 0 17 a.b.c.d:46532 Y.Y.Y.Y:7002 ESTABLISHED 53932/grpod
2. Estado de replicação geográfica:
[okcp0xx-smf-ims/smfix1] smf# show georeplication-status
result "pass"
[okcp0xx-smf-ims/smfix2] smf# show georeplication-status
result "pass"
Histórico de revisões
| Revisão | Data de publicação | Comentários |
|---|---|---|
1.0 |
05-Dec-2022
|
Versão inicial |
Colaborado por engenheiros da Cisco
- Manasa G KambiEngenheiro do Cisco TAC
- Krishna KishoreLíder técnico da Cisco
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)