Solucionar problemas quando o Element Manager é executado em um modo autônomo
Opções de download
Linguagem imparcial
O conjunto de documentação deste produto faz o possível para usar uma linguagem imparcial. Para os fins deste conjunto de documentação, a imparcialidade é definida como uma linguagem que não implica em discriminação baseada em idade, deficiência, gênero, identidade racial, identidade étnica, orientação sexual, status socioeconômico e interseccionalidade. Pode haver exceções na documentação devido à linguagem codificada nas interfaces de usuário do software do produto, linguagem usada com base na documentação de RFP ou linguagem usada por um produto de terceiros referenciado. Saiba mais sobre como a Cisco está usando a linguagem inclusiva.
Sobre esta tradução
A Cisco traduziu este documento com a ajuda de tecnologias de tradução automática e humana para oferecer conteúdo de suporte aos seus usuários no seu próprio idioma, independentemente da localização. Observe que mesmo a melhor tradução automática não será tão precisa quanto as realizadas por um tradutor profissional. A Cisco Systems, Inc. não se responsabiliza pela precisão destas traduções e recomenda que o documento original em inglês (link fornecido) seja sempre consultado.
Contents
Introduction
Este documento fornece um resumo de como solucionar problemas quando o Element Manager é executado em um modo autônomo.
Prerequisites
Requirements
A Cisco recomenda que você tenha conhecimento destes tópicos:
- StarOs
- Arquitetura básica Ultra-M
Componentes Utilizados
As informações neste documento são baseadas na versão Ultra 5.1.x.
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. Se a rede estiver ativa, certifique-se de que você entenda o impacto potencial de qualquer comando.
Informações de Apoio
O Ultra-M é uma solução de núcleo de pacotes móveis virtualizados, pré-embalada e validada, projetada para simplificar a implantação de VNFs. O OpenStack é o Virtualized Infrastructure Manager (VIM) para Ultra-M e consiste nos seguintes tipos de nó:
- Computação
- Disco de Armazenamento de Objeto - Computação (OSD - Compute)
- Controlador
- Plataforma OpenStack - Diretor (OSPD)
A arquitetura de alto nível da Ultra-M e os componentes envolvidos estão descritos nesta imagem:
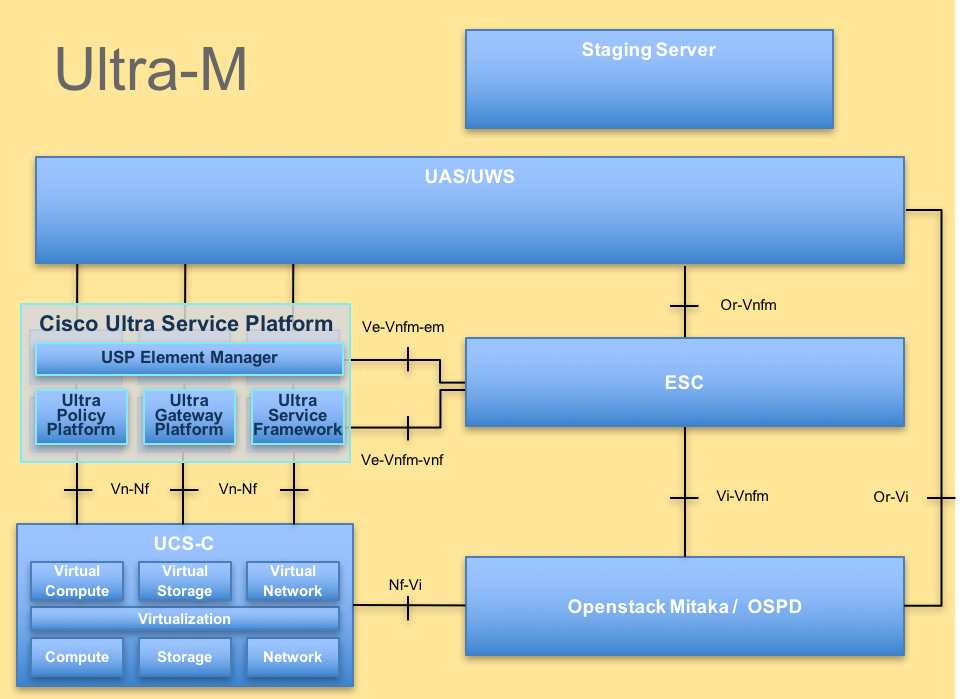 Arquitetura UltraM
Arquitetura UltraM
Este documento destina-se ao pessoal da Cisco familiarizado com a plataforma Cisco Ultra-M e detalha as etapas necessárias para serem executadas no nível de VNF do OpenStack e do StarOS no momento da substituição do servidor controlador.
Abreviaturas
Essas abreviações são usadas neste artigo:
| VNF | Função de rede virtual |
| EM | Gestor de Elementos |
| VIP | Endereço IP virtual: |
| CLI | Linha de comando |
Problema: A EM pode acabar nesse estado, como parece do Ultra M Health Manager
EM: 1 is not part of HA-CLUSTER,EM is running in standalone mode
Depende da versão, pode haver 2 ou 3 EM em execução no sistema.
No caso em que você tem 3 EM implantado, dois deles seriam funcionais e o terceiro apenas para poder ter o cluster Zookeeper. No entanto, não é usado.
Se um dos 2 EMs funcionais não funcionasse ou não estivesse acessível, o EM em funcionamento estaria no modo autônomo.
Caso você tenha implantado o 2 EM, caso um deles não esteja funcionando ou acessível, o EM restante poderá estar no modo autônomo.
Este documento explica o que procurar se isso acontecer e como se recuperar.
Etapas de solução de problemas e recuperação
Etapa 1. Verifique o estado dos EMs.
Conecte-se ao VIP EM e verifique se o nó está nesse estado:
root@em-0:~# ncs_cli -u admin -C
admin connected from 127.0.0.1 using console on em-0
admin@scm# show ems
EM VNFM ID SLA SCM PROXY
3 up down up
admin@scm#
Portanto, a partir daqui, você pode ver que há apenas uma entrada no SCM - e essa é a entrada para nosso nó.
Se você conseguir se conectar ao outro EM, poderá ver algo como:
root@em-1# ncs_cli -u admin -C admin connected from 127.0.0.1 using
admin connected from 127.0.0.1 using console on em-1
admin@scm# show ems
% No entries found.
Dependendo do problema no EM, o NCS CLI não pode ser acessível ou o nó pode ser reinicializado.
Etapa 2. Verifique os registros em /var/log/em no nó que não se junta ao cluster.
Verifique os logs no nó no estado do problema. Assim, para a amostra mencionada, você navegaria em-1 /var/log/em/zookeeper logs:
...
2018-02-01 09:52:33,591 [myid:4] - INFO [main:QuorumPeerMain@127] - Starting quorum peer
2018-02-01 09:52:33,619 [myid:4] - INFO [main:NIOServerCnxnFactory@89] - binding to port 0.0.0.0/0.0.0.0:2181
2018-02-01 09:52:33,627 [myid:4] - INFO [main:QuorumPeer@1019] - tickTime set to 3000
2018-02-01 09:52:33,628 [myid:4] - INFO [main:QuorumPeer@1039] - minSessionTimeout set to -1
2018-02-01 09:52:33,628 [myid:4] - INFO [main:QuorumPeer@1050] - maxSessionTimeout set to -1
2018-02-01 09:52:33,628 [myid:4] - INFO [main:QuorumPeer@1065] - initLimit set to 5
2018-02-01 09:52:33,641 [myid:4] - INFO [main:FileSnap@83] - Reading snapshot /var/lib/zookeeper/data/version-2/snapshot.5000000b3
2018-02-01 09:52:33,665 [myid:4] - ERROR [main:QuorumPeer@557] - Unable to load database on disk
java.io.IOException: The current epoch, 5, is older than the last zxid, 25769803777
at org.apache.zookeeper.server.quorum.QuorumPeer.loadDataBase(QuorumPeer.java:539)
at org.apache.zookeeper.server.quorum.QuorumPeer.start(QuorumPeer.java:500)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.runFromConfig(QuorumPeerMain.java:153)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.initializeAndRun(QuorumPeerMain.java:111)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.main(QuorumPeerMain.java:78)
2018-02-01 09:52:33,671 [myid:4] - ERROR [main:QuorumPeerMain@89] - Unexpected exception, exiting abnormally
java.lang.RuntimeException: Unable to run quorum server
at org.apache.zookeeper.server.quorum.QuorumPeer.loadDataBase(QuorumPeer.java:558)
at org.apache.zookeeper.server.quorum.QuorumPeer.start(QuorumPeer.java:500)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.runFromConfig(QuorumPeerMain.java:153)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.initializeAndRun(QuorumPeerMain.java:111)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.main(QuorumPeerMain.java:78)
Caused by: java.io.IOException: The current epoch, 5, is older than the last zxid, 25769803777
at org.apache.zookeeper.server.quorum.QuorumPeer.loadDataBase(QuorumPeer.java:539)
Etapa 3. Verifique se existe um instantâneo em questão.
Navegue até /var/lib/zookeeper/data/version-2 e verifique se o snapshot vermelho na etapa 2 está presente.
300000042 log.500000001 snapshot.300000041 snapshot.40000003b
ubuntu@em-1:/var/lib/zookeeper/data/version-2$ ls -la
total 424
drwxrwxr-x 2 zk zk 4096 Jan 30 12:12 .
drwxr-xr-x 3 zk zk 4096 Feb 1 10:33 ..
-rw-rw-r-- 1 zk zk 1 Jan 30 12:12 acceptedEpoch
-rw-rw-r-- 1 zk zk 1 Jan 30 12:09 currentEpoch
-rw-rw-r-- 1 zk zk 1 Jan 30 12:12 currentEpoch.tmp
-rw-rw-r-- 1 zk zk 67108880 Jan 9 20:11 log.300000042
-rw-rw-r-- 1 zk zk 67108880 Jan 30 10:45 log.400000024
-rw-rw-r-- 1 zk zk 67108880 Jan 30 12:09 log.500000001
-rw-rw-r-- 1 zk zk 67108880 Jan 30 12:11 log.5000000b4
-rw-rw-r-- 1 zk zk 69734 Jan 6 05:14 snapshot.300000041
-rw-rw-r-- 1 zk zk 73332 Jan 29 09:21 snapshot.400000023
-rw-rw-r-- 1 zk zk 73877 Jan 30 11:43 snapshot.40000003b
-rw-rw-r-- 1 zk zk 84116 Jan 30 12:09 snapshot.5000000b3 ---> HERE, you see it
ubuntu@em-1:/var/lib/zookeeper/data/version-2$
Etapa 4. Etapas de recuperação.
1. Ative o modo de depuração para que EM interrompa a reinicialização.
ubuntu@em-1:~$ sudo /opt/cisco/em-scripts/enable_debug_mode.sh
A reinicialização da VM pode ser necessária novamente (será automaticamente, você não precisa fazer nada)
2. Mova os dados do detentor da zootecnia.
No /var/lib/zookeeper/data há a pasta chamada version-2 que tem o instantâneo do DB. O erro acima indica a falha de carregamento para que você a remova.
ubuntu@em-1:/var/lib/zookeeper/data$ sudo mv version-2 old ubuntu@em-1:/var/lib/zookeeper/data$ ls -la total 20 .... -rw-r--r-- 1 zk zk 2 Feb 1 10:33 myid drwxrwxr-x 2 zk zk 4096 Jan 30 12:12 old --> so you see now old folder and you do not see version-2 -rw-rw-r-- 1 zk zk 4 Feb 1 10:33 zookeeper_server.pid ..
3. Reinicialize o nó.
sudo reboot
4. Desative novamente o modo de depuração.
ubuntu@em-1:~$ sudo /opt/cisco/em-scripts/disable_debug_mode.sh
Estas etapas devem trazer o serviço de volta ao problema EM.
Colaborado por engenheiros da Cisco
- Snezana MitrovicCisco TAC Engineer
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)