Introdução
Este documento descreve como a Alta Disponibilidade de Mensagens Instantâneas e Presença (IM&P) funciona em um ambiente corporativo de IM&P e como solucionar problemas relacionados a ele.
Pré-requisitos
Requisitos
A Cisco recomenda que você tenha conhecimento destes tópicos:
- Cisco Unified IM&P
- Clientes Cisco Jabber
Componentes Utilizados
- Cisco Unified IM&P 10.0 e posterior
- Clientes Cisco Jabber 9.6 e posterior
As informações neste documento foram criadas a partir dos componentes em um ambiente de laboratório específico. Todos os componentes usados neste documento começaram com uma configuração limpa (padrão). Se a rede estiver ativa, certifique-se de que você entenda o impacto potencial de qualquer comando.
Alta disponibilidade (HA) de mensagens instantâneas e presença
O Servidor de Serviço de IM e Presença oferece alta disponibilidade ou redundância na forma de grupos de servidores lógicos na configuração do CUCM. Essa configuração é passada para IM e Presence e, em seguida, utilizada para permitir redundância no caso de um Serviço IM e Presence ou falha do servidor. Quando ocorre um evento de alta disponibilidade, as sessões do usuário final são movidas do servidor com falha para o backup. Quando o servidor tiver sido restaurado para um estado normal, as sessões do usuário serão retornadas automaticamente ou manualmente pelo administrador.
Configuração do grupo de redundância
O grupo de redundância é o par de servidores lógicos que permite a atribuição de um servidor ao subcluster de IM e Presença, bem como a configuração para HA. Para acessar essa parte da configuração, localize-a na página da Web do servidor CUCM.
Sistema > Grupos de Redundância de Presença
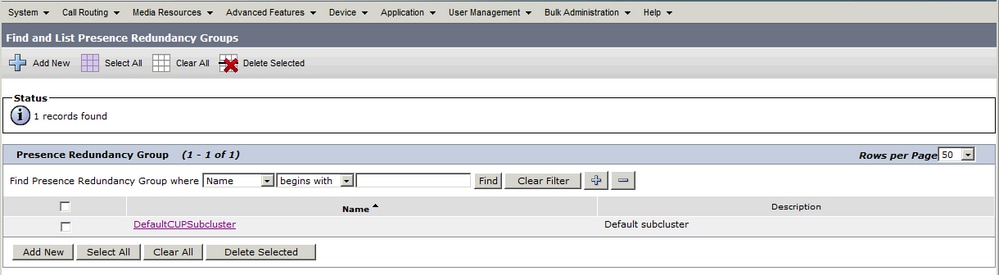
Quando o administrador adiciona o Editor de IM&P à configuração System > Server no CUCM e o servidor IM&P é salvo, o grupo de redundância DefaultCUPSubCluster é criado com o Editor atribuído a ele.
Quando criado, o Grupo de Redundância terá a seguinte aparência:
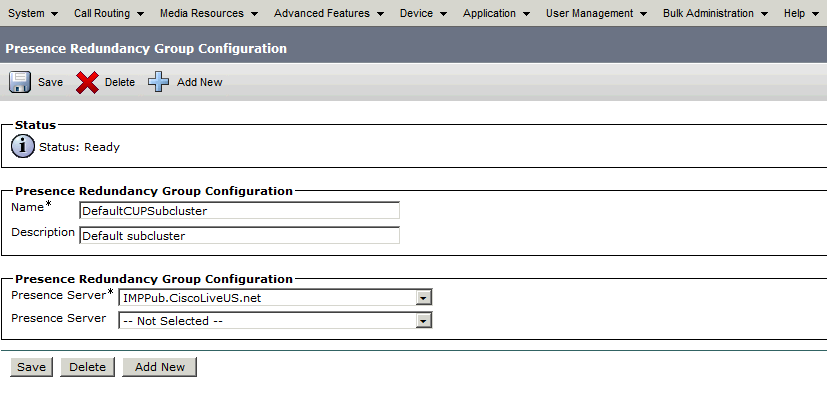
Este Grupo de Redundância converte para o subcluster de IM e Presença. No estado atual da configuração do grupo de redundância no CUCM, seria assim na página da Web Topologia do cluster de IM e presença:
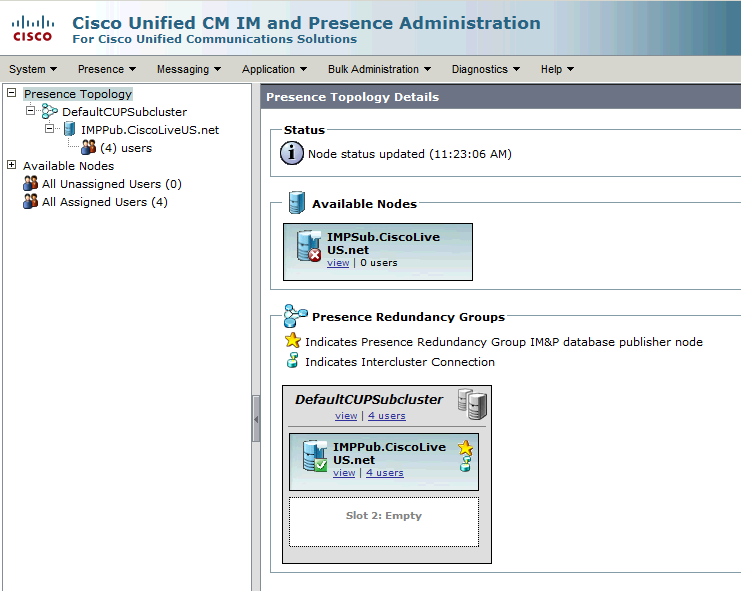
Você vê que o Editor do IM&P está atribuído ao DefaultCUPSubcluster e o servidor do assinante não. Isso ocorre porque o servidor do assinante IM&P não está atribuído ao grupo de redundância na configuração do CUCM.
Atribua o Assinante ao Grupo de Redundância.
Para atribuir o servidor do assinante ao grupo de redundância, basta escolher o servidor do assinante no menu suspenso e, em seguida, Salvar a alteração de configuração.
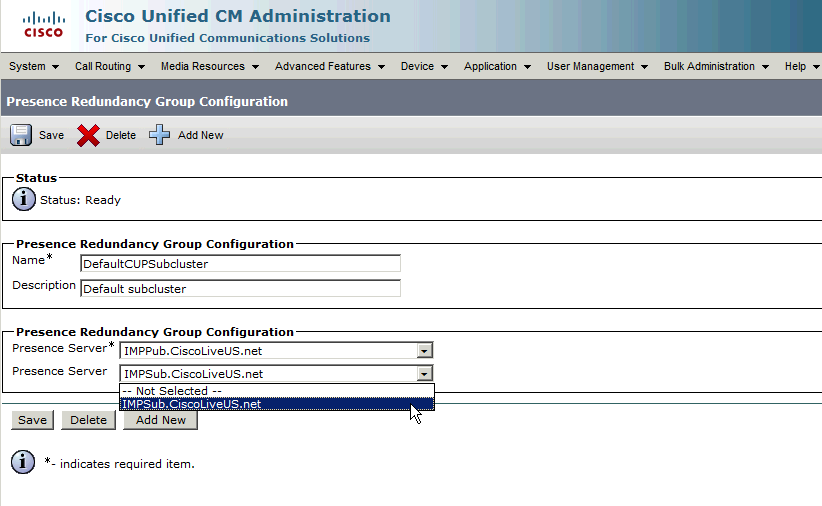
Depois que o Assinante IM&P for adicionado ao Grupo de redundância:
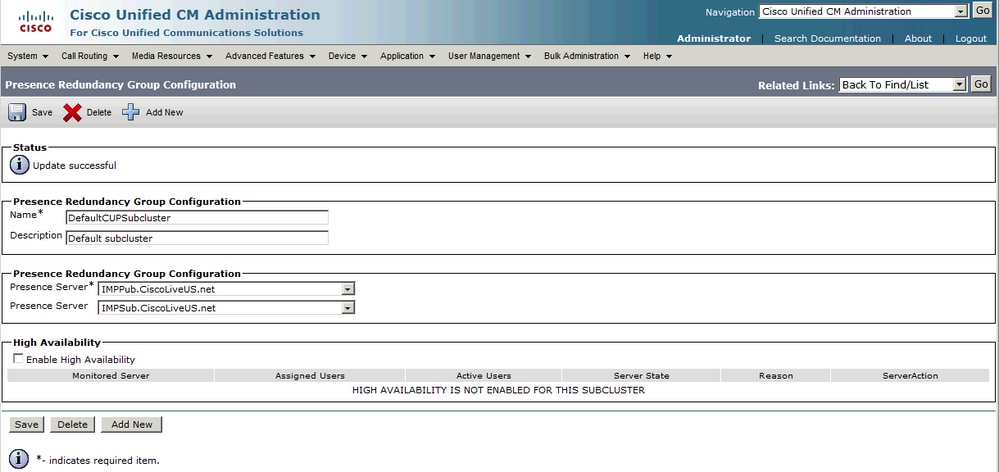
Após a adição do nó secundário (o assinante), você verá que a opção Alta disponibilidade pode ser selecionada. Para habilitar a Alta Disponibilidade, basta escolher a caixa de seleção Habilitar Alta Disponibilidade e Salvar a alteração de configuração.
Depois que a Alta Disponibilidade for habilitada:
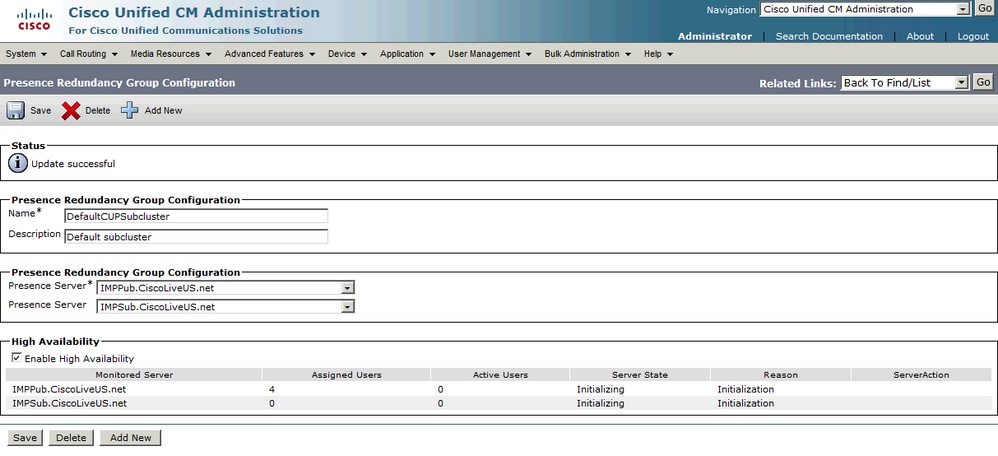
Em seguida, a página atualiza automaticamente o estado e o motivo do servidor. Quando o servidor está em um estado de inicialização, isso significa que os dois servidores podem se comunicar. Os servidores verificariam o status do serviço antes que o estado mudasse para Normal. Se os dois servidores puderem se conectar entre si e todos os serviços monitorados estiverem ativos em ambos, você obterá um estado Normal-Normal. Isso significa que todos os serviços monitorados estão ativos nos servidores IM&P.
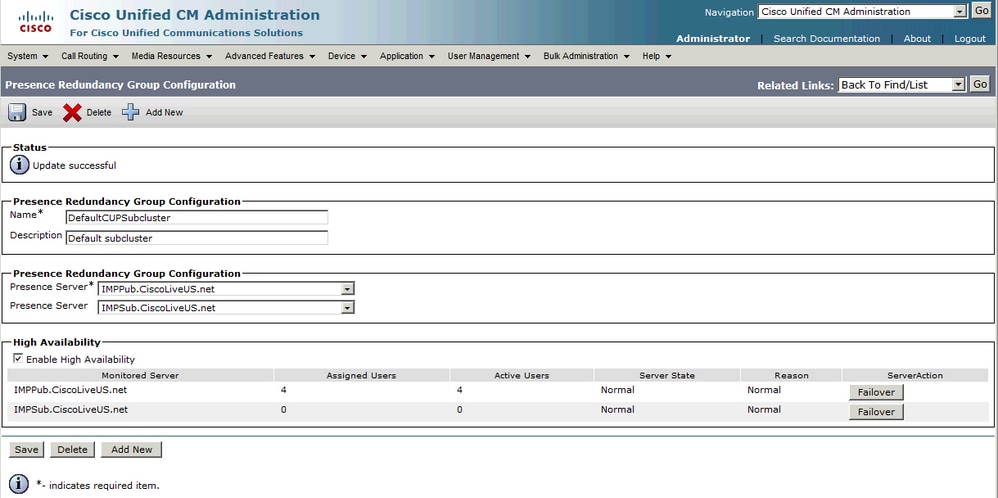
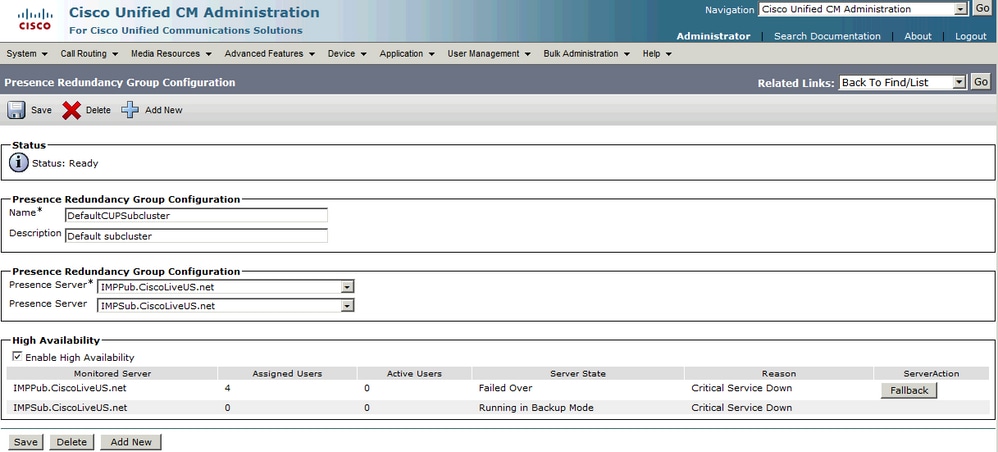
Estado do Grupo de Redundância Normal-Normal:
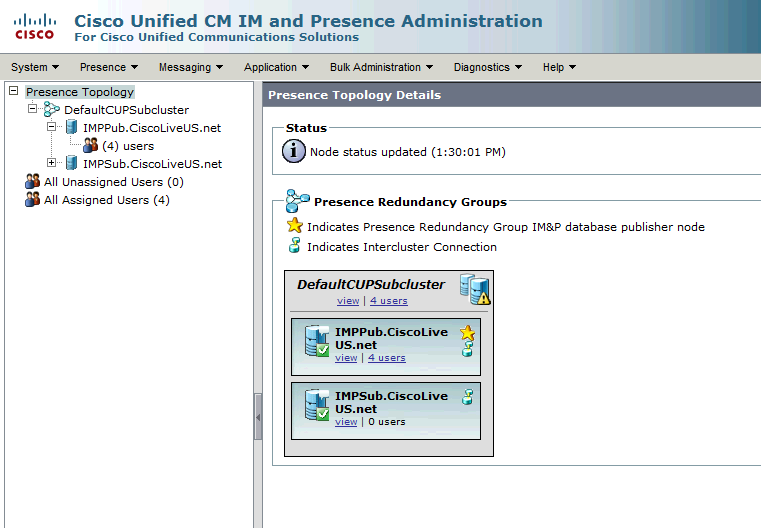
Estado de Alta Disponibilidade Normal-Normal na Página Topologia de IM&P:
Serviços monitorados de mensagens instantâneas e presença
Como você pode ter vários modelos de implantação: Somente IM, IM com Federação SIP/XMPP, IM com Conformidade, IM com bate-papo persistente, Somente Controle de Chamada Remota e assim por diante, a lista real de quais desses processos monitorar é dinâmica. Por padrão, esses itens são sempre monitorados quando o HA está habilitado:
- Banco de dados IDS
- Presence Engine (se ativado)
- Roteador XCP
O Gerenciador de Recuperação de Servidor verifica se a conformidade (Arquivador de Mensagens), o bate-papo persistente (Gerenciador de Conferência de Texto), a federação SIP (Gerenciador de Conexões da Federação SIP) e a federação XMPP (Gerenciador de Conexões da Federação XMPP) estão configuradas e ativadas.
Se estiverem configurados e ativados, o Server Recovery Manager (SRM) também monitorará esses serviços.
Cuidado: antes de continuar com a reinicialização de um ou mais dos serviços monitorados, você deve desabilitar a Alta disponibilidade dos Grupos de redundância de presença no servidor CUCM. O mesmo se aplica quando uma reinicialização de um ou mais nós IM&P é executada.
Processo de failover do usuário
Quando ocorre um failover (automático ou manual), o ponto principal a ser lembrado é que a conta de usuário não é movida de um servidor para o outro, mas apenas a sessão de usuário no Presence Engine é movida. Em versões anteriores a 10 do IM e Presence, a atribuição de usuário foi movida de um servidor para o outro. Essa mudança de usuário era muito cara para os recursos do servidor e adicionada à carga que estava no servidor. No 10.X e posterior, o usuário permanece hospedado no servidor ao qual está atribuído, e a sessão de usuário de backend no Presence Engine é movida do nó com falha para o nó funcional. O usuário não precisa sair do Jabber e fazer login novamente quando a alteração acontece com o Server Recovery Manager (SRM).
Temporizador de novo login do cliente Jabber
Para que a sessão do usuário se torne totalmente ativa no nó secundário de IM&P após um evento de failover, o usuário deve tentar fazer logon nesse servidor via SOAP (Client Profile Agent). Isso acontece automaticamente com a senha ocasional que é passada do banco de dados do IMDB. Como os logons são extremamente caros para os recursos do servidor IM e Presence, deve haver uma maneira de acelerar os logons quando ocorrer um evento de failover. Esse acelerador ou buffer permite que todos os usuários façam logon no nó secundário sem interrupção do serviço para usuários no nó secundário. Os mecanismos usados para acelerar os logons de usuários são os parâmetros de serviço Client Re-Login Lower Limit e Client Re-Login Upper Limit Server Recovery Manager (SRM).
Limite inferior de novo login do cliente - o parâmetro que define a quantidade mínima de tempo (em segundos) que o cliente Jabber espera antes de tentar fazer login no servidor secundário no caso de um evento de HA.
Limite superior de novo login do cliente - o parâmetro que define a quantidade máxima de tempo (em segundos) que o cliente Jabber espera antes de tentar fazer login no servidor secundário no caso de um evento de HA.
O cliente Jabber recebe esses parâmetros no login no servidor e armazena em cache os valores para uso futuro. Quando você recebe um evento de alta disponibilidade do servidor IM&P, o cliente escolhe um número aleatório de segundos entre os limites superior e inferior e espera esse tempo antes que o cliente Jabber tente fazer login no secundário. Quando o temporizador expirar, o cliente tentará fazer login SOAP no nó secundário.
Tipos de fallback de mensagens instantâneas e presença
Se houver failover do usuário, deverá haver fallback do usuário quando o serviço for restaurado no servidor com problemas. Há dois tipos de fallback de servidor:
Fallback manual
O fallback manual (configuração padrão do Server Recovery Manager) ocorre quando o serviço é restaurado e o grupo de redundância permite o botão Fallback. Quando esse botão é selecionado, as sessões do usuário que foram movidas para o nó secundário são movidas de volta para o nó hospedado. Em seguida, o cliente Jabber aplica os limites superior e inferior de login novamente para o fallback.
Fallback automático
O fallback automático ocorre quando o servidor monitora os serviços e o serviço SRM (Server Recovery Manager) faz o fallback automático dos usuários para seus nós hospedados. A chave nessa configuração é que o serviço SRM (Server Recovery Manager) espera 30 minutos para que um serviço/servidor com falha permaneça ativo antes que um fallback automático seja iniciado. Quando esse tempo de atividade de 30 minutos é estabelecido, as sessões do usuário são movidas de volta para seus nós hospedados. Em seguida, o cliente Jabber aplica os limites superior e inferior de login novamente para o fallback.

Observação: o fallback automático não é a configuração padrão, mas pode ser habilitado. Para ativar o fallback automático, altere o parâmetro Ativar Fallback Automático nos Parâmetros de Serviço do Server Recovery Manager para o valor Verdadeiro.
Troubleshooting
Esta seção fornece as informações que você pode usar para solucionar problemas da sua configuração.
Ao solucionar problemas de alta disponibilidade no Servidor do Serviço IM&P, há dois temporizadores importantes que devem ser considerados.
- Os servidores trocam 4 keepalives a cada 60 segundos. Se não houver resposta após os 60 segundos, o Cisco Service Recovery Manager (SRM) considera que o nó que não responde ficou off-line e aciona um comando de failover. Como mostra o próximo snippet, a última pulsação ocorreu 62 segundos atrás.
2021-05-13 02:48:48,244 INFO[HS]rsrm.RsrmHeartBeatHandler - RsrmHeartBeatHandler: peer down, time since last heartbeat[s]= 62
2021-05-13 02:48:48,244 INFO [HS] rsrm.RsrmAutomaticFallback - RsrmAutomaticFallback: peer states vector changed to [Normal,Running in Backup Mode]
Dica: para este cenário, se você encontrou alguma latência em sua rede, é recomendável aumentar o temporizador de timeout de heartbeat de 60 para 90 segundos.
Navegue até a página da Web CUCM Administration > System > Service parameters configuration > Select the IM&P Server> Select Cisco Recovery ManagerSettings. No tempo limite de Keep Alive (Heartbeat), aumente o número para 90 segundos.
- O servidor do Assinante IM&P aguarda 90 segundos. Se detectar que um ou mais dos serviços monitorados está inoperante, o servidor do Assinante assumirá o controle.
Registros a serem coletados para solução de problemas
- Registros do Server Recover Manager (SRM) de antes e depois do evento de failover (nível de depuração, se possível).
- A saída do comando através da interface de linha de comando IM&P execute sql select * from enterprisesubcluster.
- A tabela de subcluster empresarial no IM&P hospeda a configuração do Grupo de Redundância.
- A saída do comando através da interface de linha de comando IM&P execute sql select * from enterprisenode.
- A tabela de nós da empresa exibe as informações do nó e a atribuição de subcluster do nó.
- Se o failover for produzido por um serviço que está sendo interrompido, colete:
- Logs do sistema do visualizador de eventos
- Logs de aplicativos do visualizador de eventos
- Logs do serviço interrompidos.
 Feedback
Feedback