O que é o cluster Expressway e como ele funciona
Opções de download
Linguagem imparcial
O conjunto de documentação deste produto faz o possível para usar uma linguagem imparcial. Para os fins deste conjunto de documentação, a imparcialidade é definida como uma linguagem que não implica em discriminação baseada em idade, deficiência, gênero, identidade racial, identidade étnica, orientação sexual, status socioeconômico e interseccionalidade. Pode haver exceções na documentação devido à linguagem codificada nas interfaces de usuário do software do produto, linguagem usada com base na documentação de RFP ou linguagem usada por um produto de terceiros referenciado. Saiba mais sobre como a Cisco está usando a linguagem inclusiva.
Sobre esta tradução
A Cisco traduziu este documento com a ajuda de tecnologias de tradução automática e humana para oferecer conteúdo de suporte aos seus usuários no seu próprio idioma, independentemente da localização. Observe que mesmo a melhor tradução automática não será tão precisa quanto as realizadas por um tradutor profissional. A Cisco Systems, Inc. não se responsabiliza pela precisão destas traduções e recomenda que o documento original em inglês (link fornecido) seja sempre consultado.
Contents
Introdução
Este documento descreve como os clusters do Expressway são projetados para estender a resiliência e a capacidade de uma instalação do Expressway.
Informações de Apoio
Capacidade. O cluster do Expressway pode aumentar a capacidade de uma implantação do Expressway em um fator máximo de quatro, em comparação com um único Expressway. Os pares do Expressway em um cluster compartilham o uso de largura de banda, bem como roteamento, zona, FindMe e outras configurações.
Resiliência. O cluster do Expressway pode fornecer redundância enquanto um Expressway está no modo de manutenção ou quando ele se torna inacessível devido a uma rede ou queda de energia, ou outro motivo. Os pontos de extremidade podem se registrar em qualquer um dos pares em um cluster. Se os endpoints perderem a conexão com seu peer inicial, eles poderão se registrar novamente em outro no cluster.
Especificações
Um Expressway pode fazer parte de um cluster de até seis Expressways. Ao criar um cluster, você nomeia um peer como o principal, a partir do qual sua configuração é replicada para os outros peers. Cada peer do Expressway no cluster deve ter os mesmos recursos de roteamento. Se qualquer Expressway puder rotear uma chamada para um destino, presume-se que todos os peers do Expressway nesse cluster possam rotear uma chamada para esse destino.
Capacidade
Não há ganho de capacidade após quatro peers. Assim, em um cluster de seis pares, por exemplo, o quinto e o sexto Expressways não adicionam capacidade de chamada extra ao cluster. A resiliência é melhorada com os peers extras, mas não com a capacidade.
- Para pequenas máquinas virtuais (VMs), o cluster é apenas para redundância e não para escala, e não há ganho de capacidade do cluster.
- A capacidade baseada na configuração de cluster de 4 pontos é mostrada na próxima imagem:
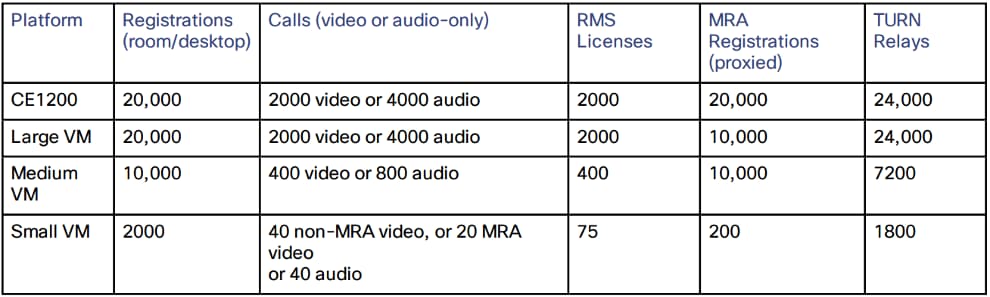
Elementos importantes da página

Requisitos
- Conhecimento básico do Secure Shell (SSH)
- Um cluster deve conter apenas o nó Expressway-C ou apenas nós Expressway-E.
- Todos os pares devem usar a mesma versão de software.
- Todos os pares usam plataforma de hardware, dispositivo ou máquina virtual (VM), com recursos equivalentes.
- O Expressway suporta um atraso de ida e volta de até 80 ms.
- O modo H323 é ativado em cada peer.
- Todos os peers têm o mesmo conjunto de teclas de opção instalado, com as próximas exceções:
- Para o Video Control Server (VCS): Licenças de chamadas transversais e não transversais
- Para Expressway: Sessões Rich Media
- Para Expressway: Licenças de registro de sistema de sala e de desktop
Todas as outras chaves de licença devem ser idênticas em cada par.
- Não deve haver conversão de endereço de rede (NAT) entre os pares de cluster.
Note: Se o Expressway-E usar um único Network Interface Controller (NIC), ele terá que usar IP público. Se o Expressway-E usar NIC duplo, a interface interna deverá ser usada para criar o cluster.
- O endereço IP, o Serviço de Nome de Domínio (DNS) e o Protocolo de Horário de Rede (NTP) devem ser configurados.
Conexões e portas de cluster
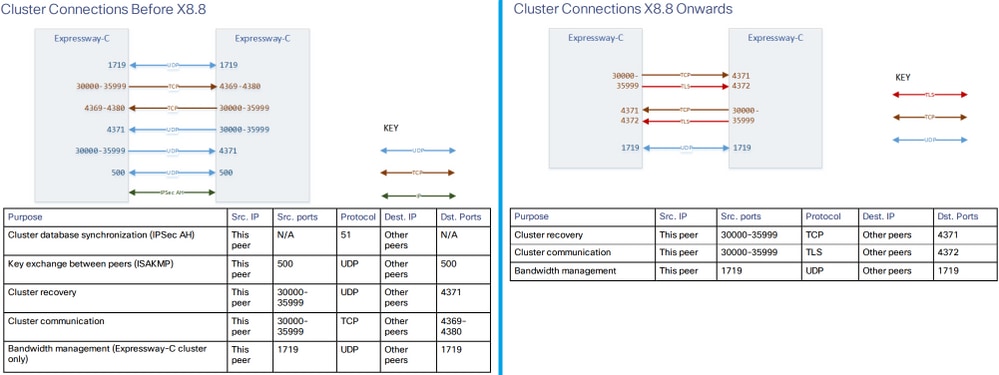
Configurações
Criar um Novo Cluster
- Abra a interface da Web do Expressway.
- Navegue até System > Clustering.
- Insira os próximos valores:
Note: Você deve criar um cluster de um peer (primário) primeiro e reiniciar o primário antes de adicionar outros peers. Você pode adicionar mais peers depois de estabelecer um cluster de um.
Configuração primária: 1
Versão IP do cluster: Escolha IPv4 ou IPv6 para corresponder ao esquema de endereços de rede.
Opções do modo de verificação TLS: Permissivo (padrão) ou Impor.
Permissivo significa que os pares não validam os certificados uns dos outros quando as conexões TLS (Transport Layer Security) dentro do cluster são estabelecidas.
Aplicar é mais seguro, mas exige que cada par tenha um certificado válido e que a Autoridade de Certificação (CA) seja confiável para todos os outros pares.
Endereço do peer 1: Insira o endereço deste Expressway (o par primário). Se o modo de verificação TLS estiver definido como Impor, você deverá inserir um FQDN (Fully Qualified Domain Name, Nome de domínio totalmente qualificado) que corresponda ao CN (Common Name, Nome comum) do assunto ou a um SAN (Subject Alternative Name, Nome alternativo do assunto) no certificado desse par.
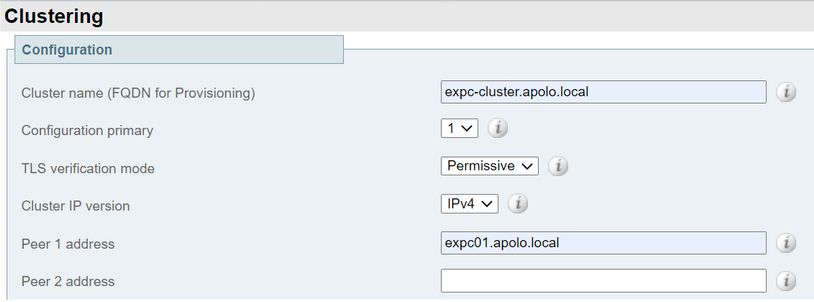
- Selecione Save.
- Reiniciar o servidor.
- Navegue até Manutenção > Opções de reinicialização, selecione Reiniciar e confirme OK.
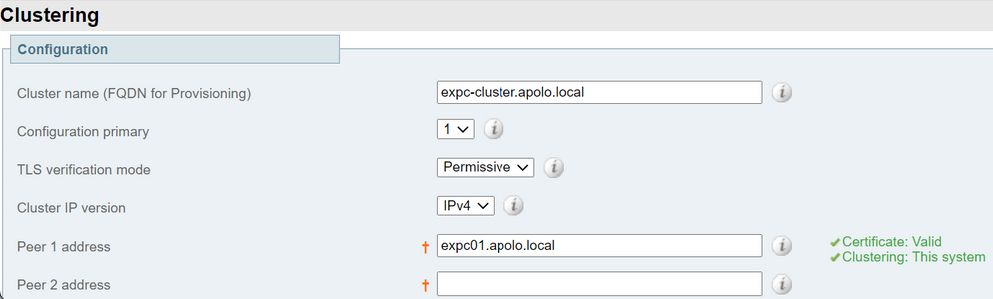
- Valide se o certificado é válido, como mostrado na próxima imagem:
Adicionar Outros Pares ao cluster
Para adicionar um peer adicional, siga as próximas etapas:
- Navegue até System > Clustering no Expressway principal.
- No primeiro campo vazio, insira o endereço do novo peer do Expressway.
- Selecione Save.
- O peer 1 deve indicar This system. O novo par deve indicar Desconhecido e, em seguida, com uma atualização, deve indicar Falha, pois ainda não ingressou totalmente no cluster.
- Navegue até System > Clustering em um dos peers subordinados que já estão no cluster e edite os próximos campos:

- Repita a etapa anterior para cada um dos pares subordinados que já estão no cluster.
- Selecione Save.
- O Expressway aciona um alarme de falha de comunicação de cluster. O alarme é cancelado após a reinicialização necessária.
- Reinicie o Expressway.
- Após a reinicialização, aguarde aproximadamente 2 minutos - essa é a frequência com que a configuração é copiada do principal.
- Validar o status do banco de dados do Cluster.

- Certifique-se de que a configuração seja replicada em um peer subordinado.

Aplicar verificação TLS
Caution: Antes de continuar, verifique se as SANs de certificado contêm os FQDNs que estão nos campos de endereço Peer N. Você deve ver mensagens de status verdes para clustering e certificado ao lado de cada campo de endereço antes de continuar.


- No peer primário, defina o modo de verificação TLS como Enforce.
Caution: Um aviso será exibido se algum certificado for inválido e impedirá que o cluster funcione corretamente no modo de verificação TLS imposto.
- O novo modo de verificação TLS é replicado em todo o cluster.
- Verifique se o modo de verificação TLS está agora Enforce no outro peer.
- Selecione Save e reinicie o peer principal.
- Depois que o peer principal estiver novamente on-line, reinicie cada peer um por um.
- Aguarde a estabilização do cluster e confirme se o status Clustering e Certificate está verde para todos os pares.

Alterar o Par Principal
Note: Você pode fazer esse processo mesmo se o peer primário atual não estiver acessível.
- No novo Expressway primário, navegue para Sistema > Clustering.
- No menu suspenso Configuration primary, selecione o número de ID da entrada de peer que diz This system.
- Selecione Save.
Note: Enquanto esse processo é executado, ignore todos os alarmes no Expressway que relatam incompatibilidade primária de cluster ou erro de replicação de cluster.
- Em todos os outros peers do Expressway, comece com o peer antigo primário (se ainda estiver acessível).
- Navegue até Sistema > Clustering.
- No menu suspenso Configuration primary, selecione o número de ID do novo Expressway principal.
- Selecione Save.
- Confirme se a alteração na Configuração primária foi aceita, navegue para Sistema > Clustering e atualize a página.
- Se algum Expressway não tiver aceitado a alteração, repita o mesmo procedimento.
- Valide se o status do banco de dados do cluster está relatado como Ativo.
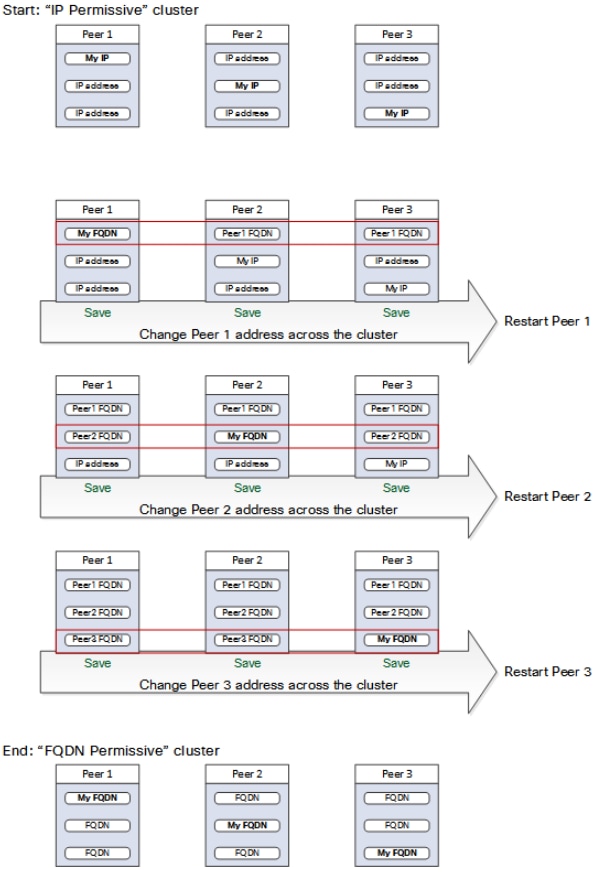
Alterar Cluster para usar FQDNs
Note: Enquanto esse procedimento é executado, as comunicações entre os peers são afetadas temporariamente, isso significa que espera-se que os alarmes persistam até que as alterações sejam concluídas e o cluster concorde com os novos endereços.
- Entre em todos os correspondentes de cluster e navegue até System > Clustering.
- Escolha o endereço de mesmo nível que será alterado. é recomendável começar com o endereço do peer 1.
- Em cada peer no cluster, siga o próximo procedimento:
- Altere o campo de endereço de mesmo nível escolhido do endereço IP para seu FQDN.
- Selecione Save.
- Alterne para o peer identificado pelo endereço de peer alterado e reinicie o servidor.
- Aguarde até que todos os alarmes de cluster transientes sejam resolvidos.
- Escolha o próximo endereço de peer a ser alterado e repita as etapas de 3 a 7.
- Repita este procedimento até que você tenha alterado todos os endereços de todos os pares e reiniciado todos os pares.
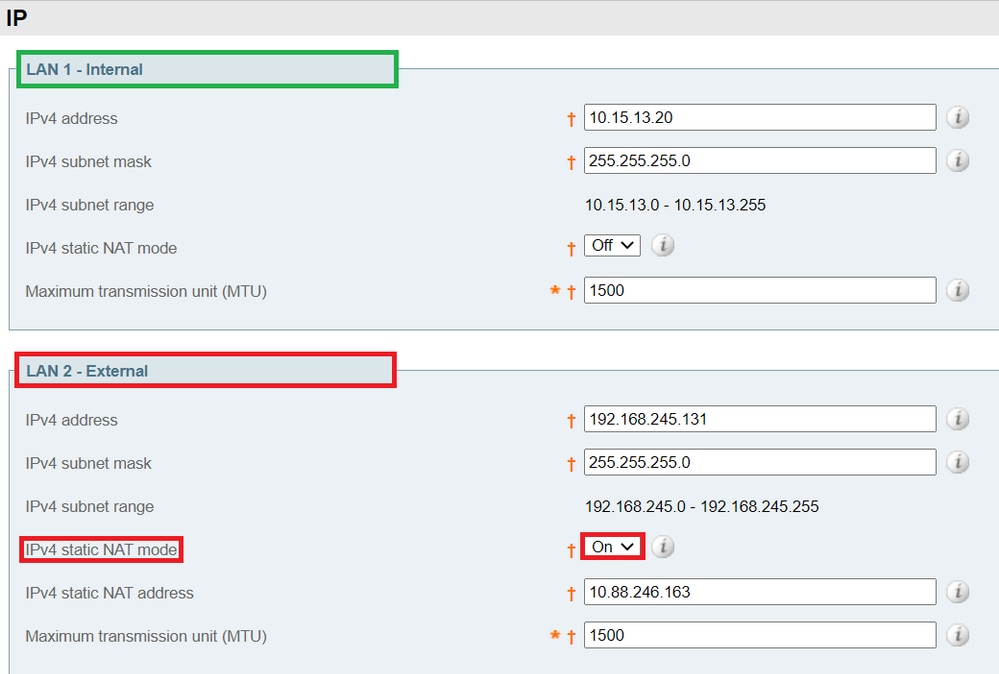
Mapeamento de endereço de cluster para Expressway-E
Para implantações seguras como acesso remoto e móvel (MRA), cada par do Expressway-E deve ter um certificado com uma SAN que contenha seu FQDN público. O FQDN é mapeado no DNS público para o endereço IP público do Expressway-E.
Note: Se você simplesmente quiser agrupar os correspondentes do Cisco Expressway-E e não precisar da verificação TLS entre eles, poderá formar o cluster com os endereços IP privados dos nós. Você não precisa do Mapeamento de Endereços de cluster.
Os Mapeamentos de Endereço de Cluster são pares FQDN:IP compartilhados ao redor do cluster, um par para cada par. Os peers consultam a tabela de mapeamento antes de consultar o DNS e, se encontrarem uma correspondência, não consultam o DNS.
Se você optar por aplicar o TLS, os correspondentes também deverão ler os nomes do campo SAN dos certificados uns dos outros e verificar cada nome em relação ao lado FQDN do mapeamento.
É altamente recomendável que você insira os mapeamentos no peer principal. Os mapeamentos de endereço são replicados dinamicamente por meio do cluster. Para configurar o Mapeamento de Endereços, siga o próximo procedimento:
- Faça Nabigate para System > Clustering no peer primário e altere o menu suspenso Cluster address mapping enabled para On (o padrão é Off). Os campos Mapeamento de endereço de cluster são exibidos.
- Edite os mapeamentos para que os FQDNs públicos dos peers do Expressway-E correspondam aos endereços IP de suas NICs internas.
- Selecione Salvar.

Caution: Não tente usar o DNS público para mapear os FQDNs públicos dos pares para seus endereços IP privados. Essa ação pode interromper a conectividade externa.
Cluster com NIC única
Se desejar que os pares do Expressway-E em um cluster verifiquem as identidades uns dos outros com certificados, você poderá permitir que eles usem DNS para resolver FQDNs de pares de cluster para seus endereços IP públicos. Essa é uma maneira perfeitamente aceitável de formar um cluster se os nós do Expressway-E tiverem:
- Somente uma placa de rede
- Nenhum NAT estático configurado
- Endereços IP roteáveis
Troubleshooting
O que aciona uma redefinição de fábrica?
Se você limpar todos os campos de endereço de peer da página de clustering e salvar a configuração, o Expressway, por padrão, executa uma Fatory Reset na próxima vez que você fizer uma reinicialização. Isso significa que toda a configuração é excluída, exceto a configuração básica de rede para a interface LAN1 (Local Area Network 1), que inclui toda a configuração executada depois que você limpa os campos e reinicia a próxima vez.
Tip: Se precisar evitar a redefinição de fábrica, restaure os campos de endereço do peer do cluster. Substitua os endereços de peer originais na mesma ordem e salve a configuração para limpar o banner.
A redefinição de fábrica é acionada automaticamente quando o peer é reiniciado, para remover dados confidenciais e a configuração do cluster. A redefinição limpa todas as configurações, exceto as informações básicas de rede a seguir:
Note: Se você usar a opção de placa de rede dupla, esteja ciente de que qualquer configuração de LAN2 será completamente removida pela redefinição.
- Endereços IP · Contas e senhas de administrador e raiz
- Chaves SSH
- Teclas de opção
- Acesso seguro ao protocolo HTTPS habilitado
- Acesso SSH habilitado
Note: A partir da versão X12.6, a redefinição de fábrica remove do par o certificado do servidor, a chave privada associada e as configurações de armazenamento confiável da autoridade de certificação. Em versões anteriores do software Expressway, essas configurações são preservadas.
Falha de redefinição de fábrica
A redefinição de fábrica pode falhar; isso pode acontecer se o Expressway for uma instalação nova do Open Virtualization Appliance (OVA) e não tiver sido atualizado.
Para corrigir isso, siga qualquer uma das opções a seguir:
- Atualize todos os nós para a mesma versão de software com o arquivo tar.gz. Ao final do processo de atualização, reinicie o servidor, que acionará a Redefinição de fábrica.
- Carregue o arquivo tar.gz diretamente na pasta de redefinição de fábrica com WinSCP (/mnt/harddisk/fatory-reset/). Em seguida, reinicie o computador para iniciar a redefinição de fábrica ou execute a redefinição de fábrica a partir da CLI.
Note: Certifique-se de fazer os backups apropriados antes de uma atualização, alteração de certificado ou quando houver um aviso de redefinição de fábrica.
Reiniciar sequência
Se for necessário reiniciar o cluster ou qualquer peer, siga as próximas etapas:
- Reinicie o peer primário e aguarde até que ele esteja acessível por meio da interface da Web.
- Valide o status da replicação de cluster no primário e o status de todos os pares. Aguarde alguns minutos, atualize as interfaces da Web do peer ocasionalmente.
- Reinicie outros peers, se necessário, um de cada vez. Cada vez, aguarde alguns minutos depois que estiver acessível e valide seu status de replicação.
Note: Pode ser necessário aguardar cerca de 5 minutos após fazer qualquer alteração de cluster antes que os pares do Expressway relatem o status bem-sucedido.
Alarmes e avisos
Os alarmes de erros de cluster são mostrados no formato: Erro de replicação de cluster: (detalhes) é necessária a sincronização manual da configuração, alguns exemplos são os seguintes:
- Erro de replicação de cluster: a sincronização manual da configuração é necessária.
- Erro de replicação de cluster: não é possível localizar o arquivo de configuração principal ou de par deste subordinado; é necessária a sincronização manual da configuração.
- Erro de replicação de cluster: a ID principal de configuração está inconsistente, a sincronização manual da configuração é necessária.
- Erro de replicação de cluster: a configuração deste peer conflita com a configuração do principal, sendo necessária a sincronização manual da configuração.
Se um Expressway subordinado relatar o alarme mencionado, siga o próximo procedimento:
- Faça login como administrador em uma interface SSH ou outra interface CLI.
- Execute o próximo comando: xcommand ForceConfigUpdate
Note: Certifique-se de fazer os backups apropriados antes de uma atualização, alteração de certificado ou quando houver um aviso de redefinição de fábrica.
- Esse comando exclui a configuração do Expressway subordinado e força-o a atualizar sua configuração do Expressway principal.
Se o problema persistir, ele pode estar relacionado à chave de criptografia por peer de cluster. Geralmente ocorre quando os peers são atualizados na ordem errada, os peers subordinados não são sincronizados com o principal. Se o comando xforceconfigupdate não funcionar, siga o próximo procedimento:
- Entre no par primário e confirme se ele está em um bom estado.
- Certifique-se de que a configuração do cluster mostre que esse item de mesmo nível é o principal.
- Atualize o primário novamente, use o mesmo pacote que você usou originalmente para atualizar.
O alarme de replicação é cancelado depois que o peer primário é atualizado e reinicializado. Isso normalmente acontece dentro de dez minutos após a reinicialização, mas pode ser até vinte minutos após a reinicialização.
Alarmes comuns
Configuração de clustering inválida: O modo H.323 deve estar ativado - o clustering usa comunicações H.323 entre os peers.
Para que esse alarme seja cancelado, certifique-se de que o modo H.323 esteja ativado, navegue para Configuration > Protocols > H.323.
Falha no banco de dados do Expressway: Entre em contato com seu representante de suporte da Cisco.
Para solucionar esse tipo de alarme, siga o próximo procedimento:
- Tire um instantâneo do sistema e forneça-o ao representante de suporte.
- Remova o Expressway do cluster.
- Restaure o banco de dados do Expressway de um backup feito anteriormente nesse Expressway.
- Adicione o Expressway de volta ao cluster.
Um segundo método será possível se o banco de dados não se recuperar:
- Tire um instantâneo do sistema e forneça-o ao Centro de Assistência Técnica (TAC).
- Remova o Expressway do cluster.
- Efetue login como root e execute o próximo comando clusterdb_destroy_and_purge_data.sh.
- Restaure o banco de dados do Expressway de um backup feito anteriormente nesse Expressway.
- Adicione o Expressway de volta ao cluster.
Note: Certifique-se de fazer os backups apropriados antes de uma atualização, alteração de certificado ou quando houver um aviso de redefinição de fábrica.
Caution: clusterdb_destroy_and_purge_data.sh é tão perigoso quanto parece — use esta opção como último recurso.
Problemas relacionados à chave do sistema
Note: As próximas informações aplicam-se à versão X14 em diante.
Falha ao atualizar os alarmes de arquivos-chave gerados no Expressways em um cenário de nó único.
Siga o próximo procedimento para solucionar este tipo de alarme:
- Faça login como administrador através da CLI (disponível por padrão através de SSH e através da porta serial nas versões de hardware).
- Execute o próximo comando: xCommand ForceSystemKeyUpdate.
Falha ao atualizar os alarmes de arquivos-chave gerados no Expressways em um cenário de cluster.
Siga o próximo procedimento para solucionar este tipo de alarme:
- Efetue login no nó como admin por meio da CLI (disponível por padrão no SSH e pela porta serial nas versões de hardware) onde esse alarme não é acionado.
- Execute o próximo comando: xCommand ForceSystemKeyUpdate.
Detalhes dos logs
Como qualquer outro log no Expressway, você pode habilitar logs de diagnóstico, com Despejos TCP.
Em um estado normal, a Sincronização de BD no nó mestre é mostrada nos logs como a próxima saída:
2020-07-21T15:16:50.321-05:00 expc01 replication: UTCTime="2020-07-21 20:16:50,321" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationsynchroniser(270)" Detail="Starting synchronisation"
2020-07-21T15:16:50.330-05:00 expc01 replication: UTCTime="2020-07-21 20:16:50,330" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationutils(750)" AlternateIPAddresses="[u'(10.15.13.15 expc01)', u'(10.15.13.16 expc02)']" ConfigurationMasterIndex="0" LocalPeerIndex="0"
2020-07-21T15:16:50.433-05:00 expc01 replication: UTCTime="2020-07-21 20:16:50,433" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationsynchroniser(257)" Detail="This peer is the cluster master, local configuration has already been replicated to the other peers"
2020-07-21T15:16:50.437-05:00 expc01 replication: UTCTime="2020-07-21 20:16:50,437" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationsynchroniser(336)" Detail="Synchronisation completed successfully"Da perspectiva do nó Peer, ele é mostrado como a próxima saída:
2020-07-21T15:16:46.900-05:00 expc02 replication: UTCTime="2020-07-21 20:16:46,899" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationsynchroniser(270)" Detail="Starting synchronisation"
2020-07-21T15:16:46.908-05:00 expc02 replication: UTCTime="2020-07-21 20:16:46,908" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationutils(750)" AlternateIPAddresses="[u'(10.15.13.15 expc01)', u'(10.15.13.16 expc02)']" ConfigurationMasterIndex="0" LocalPeerIndex="1"
2020-07-21T15:16:46.947-05:00 expc02 replication: UTCTime="2020-07-21 20:16:46,946" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationsynchroniser(254)" Detail="This peer is not the cluster master, local configuration is already up to date"
2020-07-21T15:16:46.950-05:00 expc02 replication: UTCTime="2020-07-21 20:16:46,950" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationsynchroniser(336)" Detail="Synchronisation completed successfully"Uma Desconexão de Peer é mostrada na próxima saída:
2020-08-12T14:57:43.353-05:00 expc01 UTCTime="2020-08-12 19:57:43,353" Module="developer.clusterdb.cdb" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.159.0>" Detail="Processed mnesia_down event from accessible node" Node="clusterdb@expc02.apolo.local"
2020-08-12T14:57:43.354-05:00 expc01 UTCTime="2020-08-12 19:57:43,353" Module="developer.clusterdb.cdb" Level="ERROR" Node="clusterdb@expc01.apolo.local" PID="<0.159.0>" Detail="Inconsistent Database" Context="from mnesia system - mnesia down" Node="clusterdb@expc02.apolo.local"
2020-08-12T14:57:43.354-05:00 expc01 UTCTime="2020-08-12 19:57:43,354" Module="developer.clusterdb.cdb" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.159.0>" Detail="Connecting database on mnesia running_partitioned_network event" Node="clusterdb@expc02.apolo.local"
2020-08-12T14:57:43.354-05:00 expc01 UTCTime="2020-08-12 19:57:43,354" Module="developer.clusterdb.cdb" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.14215.425>" Detail="Ready to perform node connection transaction" Node="clusterdb@expc02.apolo.local"
2020-08-12T14:57:43.354-05:00 expc01 UTCTime="2020-08-12 19:57:43,354" Module="developer.clusterdb.cdb" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.14215.425>" Detail="Running node connection transaction" Node="clusterdb@expc02.apolo.local"
2020-08-12T14:57:43.354-05:00 expc01 UTCTime="2020-08-12 19:57:43,354" Module="developer.clusterdb.synchronise" Level="WARN" Node="clusterdb@expc01.apolo.local" PID="<0.14215.425>" Detail="Failed connecting to node" Node="clusterdb@expc02.apolo.local" Reason="{ badrpc, { EXIT, { aborted, { noproc, { gen_server, call, [ kernel_safe_sup, { start_child, { dets_sup, { dets_sup, start_link, }, permanent, 1000, supervisor, [ dets_sup ] } }, infinity ] } } } } }"
2020-08-12T14:57:43.524-05:00 expc01 alarm: Level="WARN" Event="Alarm Raised" Id="20006" UUID="0f96695e-d954-4f6f-85c1-2ef1eae6f764" Severity="warning" Detail="Cluster database communication failure: The database is unable to replicate with one or more of the cluster peers" UTCTime="2020-08-12 19:57:43,524"
2020-08-12T14:57:43.771-05:00 expc01 alarm: Level="WARN" Event="Alarm Raised" Id="20004" UUID="3bca6888-f622-11df-93be-07cc953d7b99" Severity="warning" Detail="Cluster communication failure: The system is unable to communicate with one or more of the cluster peers" UTCTime="2020-08-12 19:57:43,771"
2020-08-12T14:57:53.872-05:00 expc01 tvcs: UTCTime="2020-08-12 19:57:53,871" Module="network.h323" Level="INFO": Action="Sent" Dst-ip="10.15.13.16" Dst-port="1719" Detail="Sending RAS SCI SeqNum=52319 Retransmit=True"
2020-08-12T14:57:54.872-05:00 expc01 tvcs: UTCTime="2020-08-12 19:57:54,871" Module="network.h323" Level="INFO": Action="Sent" Dst-ip="10.15.13.16" Dst-port="1719" Detail="Sending RAS LRQ SeqNum=52320 Retransmit=True"
2020-08-12T14:57:56.872-05:00 expc01 tvcs: UTCTime="2020-08-12 19:57:56,871" Module="network.h323" Level="INFO": Action="Sent" Dst-ip="10.15.13.16" Dst-port="1719" Detail="Sending RAS LRQ SeqNum=52320 Retransmit=True"
2020-08-12T14:57:57.871-05:00 expc01 tvcs: UTCTime="2020-08-12 19:57:57,871" Module="network.h323" Level="INFO": Action="Sent" Dst-ip="10.15.13.16" Dst-port="1719" Detail="Sending RAS SCI SeqNum=52319 Retransmit=True"
2020-08-12T14:57:58.871-05:00 expc01 tvcs: Event="External Server Communications Failure" Reason="gatekeeper timed out" Service="NeighbourGatekeeper" Detail="name:10.15.13.16:1719" Level="1" UTCTime="2020-08-12 19:57:58,871"
2020-08-12T14:57:58.871-05:00 expc01 tvcs: UTCTime="2020-08-12 19:57:58,871" Module="network.h323" Level="INFO": Action="Sent" Dst-ip="10.15.13.16" Dst-port="1719" Detail="Sending RAS LRQ SeqNum=52320 Timeout=True"
2020-08-12T14:57:59.601-05:00 expc01 UTCTime="2020-08-12 19:57:59,601" Module="developer.clusterdb.peernameresolver" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.145.0>" Detail="Triggering forced peer update of peers which failed DNS and queueing next run" Queue-Time-ms="300000"
2020-08-12T14:58:01.871-05:00 expc01 tvcs: UTCTime="2020-08-12 19:58:01,871" Module="network.h323" Level="INFO": Action="Sent" Dst-ip="10.15.13.16" Dst-port="1719" Detail="Sending RAS SCI SeqNum=52319 Timeout=True"
A alteração para a aplicação de TLS no nó mestre é mostrada na próxima saída:
2020-08-12T15:13:24.970-05:00 expc01 UTCTime="2020-08-12 20:13:24,969" Module="developer.cdbtable.cdb.clusterConfiguration" Level="DEBUG" Node="clusterdb@expc01.apolo.local" PID="<0.345.0>" Detail="Inserting into table" TableName="clusterConfiguration"
2020-08-12T15:13:24.976-05:00 expc01 UTCTime="2020-08-12 20:13:24,975" Event="System Configuration Changed" Node="clusterdb@expc01.apolo.local" PID="<0.345.0>" Detail="xconfiguration clusterConfiguration tls_verify - changed from: Permissive to: Enforcing"
2020-08-12T15:13:24.976-05:00 expc01 httpd[15060]: web: Event="System Configuration Changed" Detail="configuration/cluster/tls_verify - changed from: 'Permissive' to: 'Enforcing'" Src-ip="10.15.13.30" Src-port="53155" User="admin" Level="1" UTCTime="2020-08-12 20:13:24"
2020-08-12T15:13:24.979-05:00 expc01 management: UTCTime="2020-08-12 20:13:24,978" Module="developer.management.databasemanager" Level="INFO" CodeLocation="databasemanager(312)" Detail="Cluster configuration change detected"
2020-08-12T15:13:24.980-05:00 expc01 UTCTime="2020-08-12 20:13:24,980" Module="developer.cdbtable.cdb.clusterConfiguration" Level="DEBUG" Node="clusterdb@expc01.apolo.local" PID="<0.345.0>" Detail="Inserting into table" TableName="clusterConfiguration"
2020-08-12T15:13:24.986-05:00 expc01 management: UTCTime="2020-08-12 20:13:24,986" Module="developer.management.databasemanager" Level="INFO" CodeLocation="databasemanager(405)" Detail="TLS Verify change status" Startup="False" New="True"
2020-08-12T15:13:25.022-05:00 expc01 UTCTime="2020-08-12 20:13:25,022" Event="System Configuration Changed" Node="clusterdb@expc01.apolo.local" PID="<0.557.0>" Detail="xconfiguration alternatesConfiguration - Changed"
2020-08-12T15:13:25.022-05:00 expc01 UTCTime="2020-08-12 20:13:25,022" Module="developer.clusterdb.peernameresolver" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.145.0>" Detail="Notifying databasemanager (Management Framework)"
2020-08-12T15:13:25.022-05:00 expc01 UTCTime="2020-08-12 20:13:25,022" Module="developer.clusterdb.alternatesmanager" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.142.0>" Detail="alternate peer changed info recieved"
2020-08-12T15:13:25.031-05:00 expc01 UTCTime="2020-08-12 20:13:25,031" Event="System Configuration Changed" Node="clusterdb@expc01.apolo.local" PID="<0.557.0>" Detail="xconfiguration alternatesConfiguration - Changed"
2020-08-12T15:13:25.192-05:00 expc01 management: UTCTime="2020-08-12 20:13:25,192" Module="developer.diagnostics.alarmmanager" Level="INFO" CodeLocation="alarmmanager(173)" Detail="Raising alarm" UUID="e2b8e3d1-b731-4d7d-b606-4682a8f0c2e6" Parameters="null"
2020-08-12T15:13:25.195-05:00 expc01 management: Level="WARN" Event="Alarm Raised" Id="20007" UUID="e2b8e3d1-b731-4d7d-b606-4682a8f0c2e6" Severity="warning" Detail="Restart required: Cluster configuration has been changed, however a restart is required for this to take effect" UTCTime="2020-08-12 20:13:25,194"
Da perspectiva do nó Peer, ele é mostrado na próxima saída:
2020-08-12T15:13:24.976-05:00 expc02 UTCTime="2020-08-12 20:13:24,976" Event="System Configuration Changed" Node="clusterdb@expc02.apolo.local" PID="<0.390.0>" Detail="xconfiguration clusterConfiguration tls_verify - changed from: Permissive to: Enforcing"
2020-08-12T15:13:24.979-05:00 expc02 management: UTCTime="2020-08-12 20:13:24,978" Module="developer.management.databasemanager" Level="INFO" CodeLocation="databasemanager(312)" Detail="Cluster configuration change detected"
2020-08-12T15:13:24.982-05:00 expc02 management: UTCTime="2020-08-12 20:13:24,982" Module="developer.management.databasemanager" Level="INFO" CodeLocation="databasemanager(405)" Detail="TLS Verify change status" Startup="False" New="True"
2020-08-12T15:13:25.040-05:00 expc02 UTCTime="2020-08-12 20:13:25,040" Module="developer.clusterdb.peernameresolver" Level="INFO" Node="clusterdb@expc02.apolo.local" PID="<0.136.0>" Detail="Notifying databasemanager (Management Framework)"
2020-08-12T15:13:25.040-05:00 expc02 UTCTime="2020-08-12 20:13:25,040" Module="developer.clusterdb.alternatesmanager" Level="INFO" Node="clusterdb@expc02.apolo.local" PID="<0.143.0>" Detail="alternate peer changed info recieved"
2020-08-12T15:13:25.041-05:00 expc02 UTCTime="2020-08-12 20:13:25,041" Event="System Configuration Changed" Node="clusterdb@expc02.apolo.local" PID="<0.543.0>" Detail="xconfiguration alternatesConfiguration - Changed"
2020-08-12T15:13:25.042-05:00 expc02 UTCTime="2020-08-12 20:13:25,042" Event="System Configuration Changed" Node="clusterdb@expc02.apolo.local" PID="<0.543.0>" Detail="xconfiguration alternatesConfiguration - Changed"
2020-08-12T15:13:25.046-05:00 expc02 UTCTime="2020-08-12 20:13:25,046" Module="developer.clusterdb.alternatesmanager" Level="INFO" Node="clusterdb@expc02.apolo.local" PID="<0.143.0>" Detail="alternate peer changed info recieved"
2020-08-12T15:13:25.047-05:00 expc02 UTCTime="2020-08-12 20:13:25,046" Module="developer.clusterdb.peernameresolver" Level="INFO" Node="clusterdb@expc02.apolo.local" PID="<0.136.0>" Detail="Notifying databasemanager (Management Framework)"
2020-08-12T15:13:25.047-05:00 expc02 UTCTime="2020-08-12 20:13:25,047" Event="System Configuration Changed" Node="clusterdb@expc02.apolo.local" PID="<0.543.0>" Detail="xconfiguration alternatesConfiguration - Changed"
2020-08-12T15:13:25.049-05:00 expc02 UTCTime="2020-08-12 20:13:25,049" Event="System Configuration Changed" Node="clusterdb@expc02.apolo.local" PID="<0.543.0>" Detail="xconfiguration alternatesConfiguration - Changed"
2020-08-12T15:13:25.136-05:00 expc02 management: UTCTime="2020-08-12 20:13:25,136" Module="developer.diagnostics.alarmmanager" Level="INFO" CodeLocation="alarmmanager(173)" Detail="Raising alarm" UUID="e2b8e3d1-b731-4d7d-b606-4682a8f0c2e6" Parameters="null"
2020-08-12T15:13:25.139-05:00 expc02 management: Level="WARN" Event="Alarm Raised" Id="20007" UUID="e2b8e3d1-b731-4d7d-b606-4682a8f0c2e6" Severity="warning" Detail="Restart required: Cluster configuration has been changed, however a restart is required for this to take effect" UTCTime="2020-08-12 20:13:25,139"
Vídeos
Os próximos vídeos podem ser úteis:
Como criar e adicionar um peer a um cluster do Expressway
Remoção de um peer de um cluster do Expressway
Procedimento de reinicialização do cluster do Expressway
Como atualizar um cluster do Expressway Gerando CSR para MRA/Expressways em cluster
Histórico de revisões
| Revisão | Data de publicação | Comentários |
|---|---|---|
1.0 |
02-Jul-2021
|
Versão inicial |
Colaborado por engenheiros da Cisco
- Jefferson Madriz
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)