Solucionar problemas do cluster Firepower Threat Defense (FTD)
Opções de download
Linguagem imparcial
O conjunto de documentação deste produto faz o possível para usar uma linguagem imparcial. Para os fins deste conjunto de documentação, a imparcialidade é definida como uma linguagem que não implica em discriminação baseada em idade, deficiência, gênero, identidade racial, identidade étnica, orientação sexual, status socioeconômico e interseccionalidade. Pode haver exceções na documentação devido à linguagem codificada nas interfaces de usuário do software do produto, linguagem usada com base na documentação de RFP ou linguagem usada por um produto de terceiros referenciado. Saiba mais sobre como a Cisco está usando a linguagem inclusiva.
Sobre esta tradução
A Cisco traduziu este documento com a ajuda de tecnologias de tradução automática e humana para oferecer conteúdo de suporte aos seus usuários no seu próprio idioma, independentemente da localização. Observe que mesmo a melhor tradução automática não será tão precisa quanto as realizadas por um tradutor profissional. A Cisco Systems, Inc. não se responsabiliza pela precisão destas traduções e recomenda que o documento original em inglês (link fornecido) seja sempre consultado.
Contents
Introdução
Este documento descreve a solução de problemas de uma configuração de cluster no firewall de próxima geração Firepower (NGFW).
Pré-requisitos
Requisitos
A Cisco recomenda que você tenha conhecimento destes tópicos (consulte a seção Informações Relacionadas para obter links):
- Arquitetura da plataforma Firepower
- Configuração e operação do cluster Firepower
- Familiaridade com a CLI FTD e Firepower eXtensible Operating System (FXOS)
- NGFW/registros de plano de dados
- NGFW/rastreador de pacotes de plano de dados
- Capturas de plano de dados/FXOS
Componentes Utilizados
- HW Firepower 4125
- SW: 6.7.0 (Compilação 65) - plano de dados 9.15(1)
As informações neste documento foram criadas a partir de dispositivos em um ambiente de laboratório específico. Todos os dispositivos utilizados neste documento foram iniciados com uma configuração (padrão) inicial. Se a rede estiver ativa, certifique-se de que você entenda o impacto potencial de qualquer comando.
Informações de Apoio
A maioria dos itens abordados neste documento também se aplica totalmente à solução de problemas de cluster do Adaptive Security Appliance (ASA).
Configurar
A parte de configuração de uma implantação de cluster é abordada nos guias de configuração FMC e FXOS:
- Organização por clusters para o Firepower Threat Defense
- Implantação de um cluster do Firepower Threat Defense para escalabilidade e alta disponibilidade
Noções Básicas do Cluster
Arquitetura NGFW
É importante entender como um Firepower 41xx ou 93xx Series lida com pacotes de trânsito:
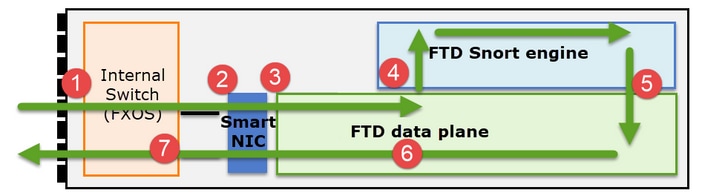
- Um pacote entra na interface de entrada e é tratado pelo switch interno do chassi.
- O pacote passa pela placa de rede inteligente. Se o fluxo for descarregado (aceleração de HW), o pacote será tratado exclusivamente pela placa de rede inteligente e enviado de volta à rede.
- Se o pacote não for descarregado, ele entra no plano de dados do FTD que faz principalmente verificações de L3/L4.
- Se a política exigir, o pacote será inspecionado pelo mecanismo Snort (principalmente inspeção L7).
- O mecanismo Snort retorna um veredito (por exemplo, permitir ou bloquear) para o pacote.
- O plano de dados descarta ou encaminha o pacote com base no veredito do Snort.
- O pacote sai do chassi através do switch interno do chassi.
Capturas de cluster
Os dispositivos Firepower oferecem vários pontos de captura que oferecem visibilidade aos fluxos de trânsito. Ao solucionar problemas e ativar capturas de cluster, os principais desafios são:
- O número de capturas aumenta à medida que o número de unidades no cluster aumenta.
- Você precisa estar ciente de como o cluster trata um fluxo específico para poder rastrear o pacote pelo cluster.
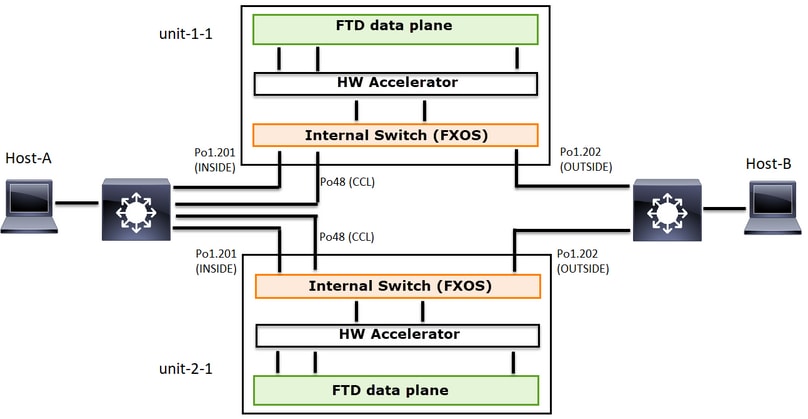
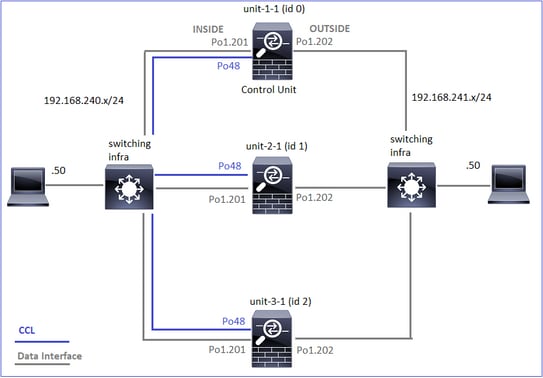
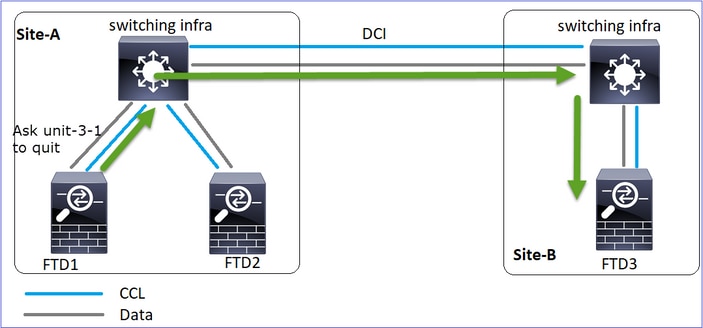
Este diagrama mostra um cluster de 2 unidades (por exemplo, FP941xx/FP9300):
No caso do estabelecimento de uma conexão TCP assimétrica, uma troca TCP SYN, SYN/ACK é semelhante a esta:
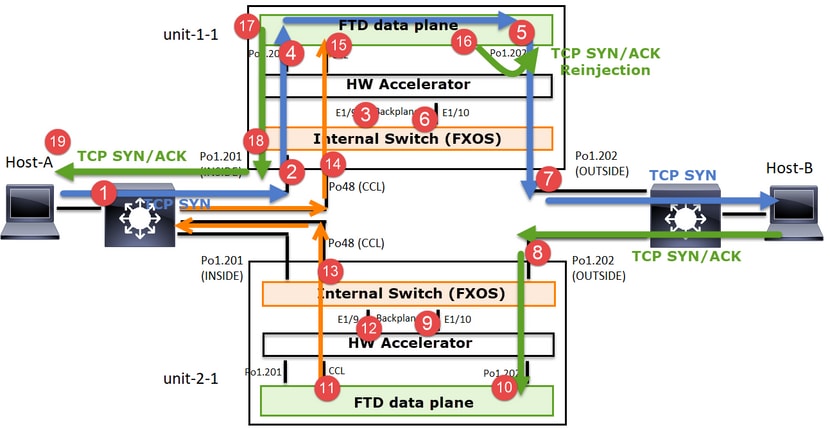
Encaminhar tráfego:
- O TCP SYN é enviado do Host-A para o Host-B.
- O TCP SYN chega ao chassi (um dos membros do Po1).
- O TCP SYN é enviado através de uma das interfaces de backplane do chassi (por exemplo, E1/9, E1/10, etc.) para o plano de dados.
- O TCP SYN chega à interface de ingresso do plano de dados (Po1.201/INSIDE). Neste exemplo, a unidade 1-1 assume a propriedade do fluxo, faz a seleção aleatória do Initial Sequence Number (ISN) e codifica as informações de propriedade (cookie) no número Seq.
- O TCP SYN é enviado de Po1.202/OUTSIDE (interface de saída do plano de dados).
- O TCP SYN chega a uma das interfaces de backplane do chassi (por exemplo, E1/9, E1/10, etc.).
- O TCP SYN é enviado para fora da interface física do chassi (um dos membros de Po1) em direção ao Host-B.
Tráfego de retorno:
- O TCP SYN/ACK é enviado do Host-B e chega à unidade 2-1 (um dos membros da Po1).
- O TCP SYN/ACK é enviado através de uma das interfaces de backplane do chassi (por exemplo, E1/9, E1/10, etc.) para o plano de dados.
- O TCP SYN/ACK chega à interface de ingresso do plano de dados (Po1.202/OUTSIDE).
- O TCP SYN/ACK é enviado do Cluster Control Link (CCL) em direção à unidade 1-1. Por padrão, o ISN está habilitado. Assim, o encaminhador encontra as informações do proprietário para TCP SYN+ACKs sem o envolvimento do direcionador. Para outros pacotes ou quando o ISN é desativado, o direcionador é consultado.
- O TCP SYN/ACK chega a uma das interfaces de backplane do chassi (por exemplo, E1/9, E1/10 e assim por diante).
- O TCP SYN/ACK é enviado para fora da interface física do chassi (um dos membros do Po48) em direção à unidade 1-1.
- O TCP SYN/ACK chega à unidade 1-1 (um dos membros da Po48).
- O TCP SYN/ACK é encaminhado através de uma das interfaces de painel traseiro do chassi para a interface de canal de porta CCL do plano de dados (nome do cluster).
- O plano de dados injeta novamente o pacote TCP SYN/ACK na interface de plano de dados Po1.202/OUTSIDE.
- O TCP SYN/ACK é enviado de Po1.201/INSIDE (interface de saída do plano de dados) para o HOST-A.
- O TCP SYN/ACK atravessa uma das interfaces do painel traseiro do chassi (por exemplo, E1/9, E1/10, etc.) e sai de um dos membros de Po1.
- O TCP SYN/ACK chega ao Host-A.
Para obter mais detalhes sobre esse cenário, leia a seção relacionada nos Estudos de Caso de Estabelecimento de Conexão de Cluster.
Com base nessa troca de pacotes, todos os possíveis pontos de captura de cluster são:
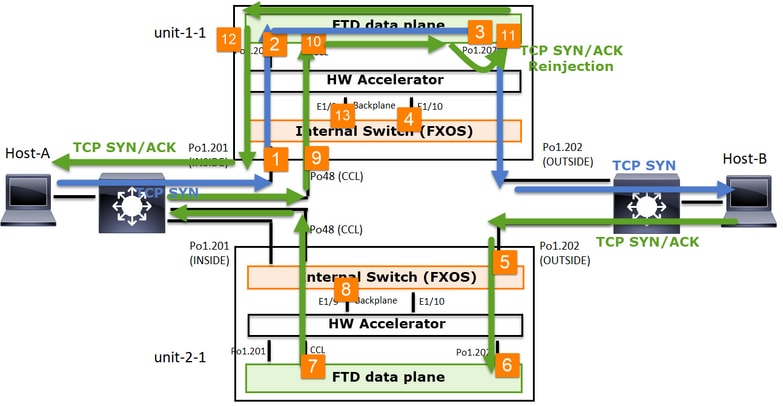
Para a captura de tráfego de encaminhamento (por exemplo, TCP SYN) em:
- A interface física do chassi (por exemplo, membros Po1). Essa captura é configurada na interface do usuário do Gerenciador de chassi (CM) ou na CLI do CM.
- Interface de ingresso do plano de dados (por exemplo, Po1.201 INSIDE).
- Interface de saída do plano de dados (por exemplo, Po1.202 OUTSIDE).
- Interfaces do chassi do backplane. No FP4100, há duas interfaces de backplane. No FP9300 há um total de 6 (2 por módulo). Como você não sabe em que interface o pacote chega, deve ativar a captura em todas as interfaces.
Para a captura de tráfego de retorno (por exemplo, TCP SYN/ACK) em:
- A interface física do chassi (por exemplo, membros Po1). Essa captura é configurada na interface do usuário do Gerenciador de chassi (CM) ou na CLI do CM.
- Interface de ingresso do plano de dados (por exemplo, Po1.202 OUTSIDE).
- Como o pacote é redirecionado, o próximo ponto de captura é o plano de dados CCL.
- Interfaces do chassi do backplane. Novamente, você deve habilitar a captura em ambas as interfaces.
- Interfaces de membro CCL de chassi de unidade 1-1.
- Interface CCL de plano de dados (nome do cluster).
- Interface de entrada (Po1.202 OUTSIDE). Este é o pacote injetado novamente da CCL para o plano de dados.
- Interface de saída do plano de dados (por exemplo, Po1.201 INSIDE).
- Interfaces do chassi do backplane.
Como ativar as capturas de cluster
Capturas FXOS
O processo é descrito no Guia de configuração de FXOS: Captura do pacote
Note: As capturas de FXOS só podem ser feitas na direção de entrada do ponto de vista do switch interno.
Capturas de plano de dados
A maneira recomendada de habilitar a captura em todos os membros do cluster é com o comando cluster exec.
Considere um cluster de 3 unidades:
Para verificar se há capturas ativas em todas as unidades de cluster, use este comando:
firepower# cluster exec show capture
unit-1-1(LOCAL):******************************************************
unit-2-1:*************************************************************
unit-3-1:*************************************************************
firepower#
Para ativar uma captura de plano de dados em todas as unidades em Po1.201 (INTERIOR):
firepower# cluster exec capture CAPI interface INSIDE
É altamente recomendável especificar um filtro de captura e, caso você espere muito tráfego, aumentar o buffer de captura:
firepower# cluster exec capture CAPI buffer 33554432 interface INSIDE match tcp host 192.168.240.50 host 192.168.241.50 eq 80
Verificação:
firepower# cluster exec show capture
unit-1-1(LOCAL):******************************************************
capture CAPI type raw-data buffer 33554432 interface INSIDE [Capturing - 5140 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
unit-2-1:*************************************************************
capture CAPI type raw-data buffer 33554432 interface INSIDE [Capturing - 260 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
unit-3-1:*************************************************************
capture CAPI type raw-data buffer 33554432 interface INSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
Para ver o conteúdo de todas as capturas (essa saída pode ser muito longa):
firepower# terminal pager 24
firepower# cluster exec show capture CAPI
unit-1-1(LOCAL):******************************************************
21 packets captured
1: 11:33:09.879226 802.1Q vlan#201 P0 192.168.240.50.45456 > 192.168.241.50.80: S 2225395909:2225395909(0) win 29200 <mss 1460,sackOK,timestamp 1110209649 0,nop,wscale 7>
2: 11:33:09.880401 802.1Q vlan#201 P0 192.168.241.50.80 > 192.168.240.50.45456: S 719653963:719653963(0) ack 2225395910 win 28960 <mss 1380,sackOK,timestamp 1120565119 1110209649,nop,wscale 7>
3: 11:33:09.880691 802.1Q vlan#201 P0 192.168.240.50.45456 > 192.168.241.50.80: . ack 719653964 win 229 <nop,nop,timestamp 1110209650 1120565119>
4: 11:33:09.880783 802.1Q vlan#201 P0 192.168.240.50.45456 > 192.168.241.50.80: P 2225395910:2225396054(144) ack 719653964 win 229 <nop,nop,timestamp 1110209650 1120565119>
unit-2-1:*************************************************************
0 packet captured
0 packet shown
unit-3-1:*************************************************************
0 packet captured
0 packet shown
Capturar Rastreamentos
Se quiser ver como os pacotes de entrada são tratados pelo plano de dados em cada unidade, use a palavra-chave trace. Isso rastreia os primeiros 50 pacotes de entrada. Você pode rastrear até 1000 pacotes de entrada.

Note: Caso haja várias capturas aplicadas em uma interface, você poderá rastrear um único pacote apenas uma vez.
Para rastrear os primeiros 1000 pacotes de entrada na interface OUTSIDE em todas as unidades de cluster:
firepower# cluster exec cap CAPO int OUTSIDE buff 33554432 trace trace-count 1000 match tcp host 192.168.240.50 host 192.168.241.50 eq www
Depois de capturar o fluxo de interesse, é necessário garantir que você rastreie os pacotes de interesse em cada unidade. O importante a ser lembrado é que um pacote específico pode ser #1 na unidade 1-1, mas #2 em outra unidade e assim por diante.
Neste exemplo, você pode ver que SYN/ACK é o pacote #2 na unidade 2-1, mas o pacote #1 na unidade 3-1:
firepower# cluster exec show capture CAPO | include S.*ack
unit-1-1(LOCAL):******************************************************
1: 12:58:31.117700 802.1Q vlan#202 P0 192.168.240.50.45468 > 192.168.241.50.80: S 441626016:441626016(0) win 29200 <mss 1380,sackOK,timestamp 1115330849 0,nop,wscale 7>
2: 12:58:31.118341 802.1Q vlan#202 P0 192.168.241.50.80 > 192.168.240.50.45468: S 301658077:301658077(0) ack 441626017 win 28960 <mss 1460,sackOK,timestamp 1125686319 1115330849,nop,wscale 7>
unit-2-1:*************************************************************
unit-3-1:*************************************************************
1: 12:58:31.111429 802.1Q vlan#202 P0 192.168.241.50.80 > 192.168.240.50.45468: S 301658077:301658077(0) ack 441626017 win 28960 <mss 1460,sackOK,timestamp 1125686319 1115330849,nop,wscale 7>
Para rastrear o #2 de pacotes (SYN/ACK) na unidade local:
firepower# cluster exec show cap CAPO packet-number 2 trace
unit-1-1(LOCAL):******************************************************
2: 12:58:31.118341 802.1Q vlan#202 P0 192.168.241.50.80 > 192.168.240.50.45468: S 301658077:301658077(0) ack 441626017 win 28960 <mss 1460,sackOK,timestamp 1125686319 1115330849,nop,wscale 7>
Phase: 1
Type: CAPTURE
Subtype:
Result: ALLOW
Config:
Additional Information:
MAC Access list
...
Para rastrear o mesmo pacote (SYN/ACK) na unidade remota:
firepower# cluster exec unit unit-3-1 show cap CAPO packet-number 1 trace
1: 12:58:31.111429 802.1Q vlan#202 P0 192.168.241.50.80 > 192.168.240.50.45468: S 301658077:301658077(0) ack 441626017 win 28960 <mss 1460,sackOK,timestamp 1125686319 1115330849,nop,wscale 7>
Phase: 1
Type: CAPTURE
Subtype:
Result: ALLOW
Config:
Additional Information:
MAC Access list
...
Captura CCL
Para ativar a captura no link CCL (em todas as unidades):
firepower# cluster exec capture CCL interface cluster
unit-1-1(LOCAL):******************************************************
unit-2-1:*************************************************************
unit-3-1:*************************************************************
Rejeitar Ocultar
Por padrão, uma captura habilitada em uma interface de dados de plano de dados mostra todos os pacotes:
- Aqueles que chegam da rede física
- Os que são reinjetados da CCL
Se você não quiser ver os pacotes injetados novamente, use a opção reinject-hide. Isso pode ser útil se você quiser verificar se um fluxo é assimétrico:
firepower# cluster exec capture CAPI_RH reinject-hide interface INSIDE match tcp host 192.168.240.50 host 192.168.241.50 eq 80
Essa captura mostra apenas o que a unidade local realmente recebe na interface específica diretamente da rede física, e não das outras unidades de cluster.
Quedas de ASP
Se quiser verificar se há descartes de software para um fluxo específico, você pode ativar a captura asp-drop. Se você não souber em qual motivo soltar focar, use a palavra-chave all. Além disso, se você não estiver interessado no payload do pacote, poderá especificar a palavra-chave headers-only. Isso permite capturar de 20 a 30 vezes mais pacotes:
firepower# cluster exec cap ASP type asp-drop all buffer 33554432 headers-only
unit-1-1(LOCAL):******************************************************
unit-2-1:*************************************************************
unit-3-1:*************************************************************
Além disso, você pode especificar os IPs de interesse na captura ASP:
firepower# cluster exec cap ASP type asp-drop all buffer 33554432 headers-only match ip host 192.0.2.100 any
Limpar uma captura
Para limpar o buffer de qualquer captura executada em todas as unidades de cluster. Isso não interrompe as capturas, mas apenas limpa os buffers:
firepower# cluster exec clear capture /all
unit-1-1(LOCAL):******************************************************
unit-2-1:*************************************************************
unit-3-1:*************************************************************
Parar uma captura
Há duas maneiras de interromper uma captura ativa em todas as unidades de cluster. Mais tarde, você pode retomar.
Caminho 1:
firepower# cluster exec cap CAPI stop
unit-1-1(LOCAL):******************************************************
unit-2-1:*************************************************************
unit-3-1:*************************************************************
Para retomar:
firepower# cluster exec no capture CAPI stop
unit-1-1(LOCAL):******************************************************
unit-2-1:*************************************************************
unit-3-1:*************************************************************
Caminho 2:
firepower# cluster exec no capture CAPI interface INSIDE
unit-1-1(LOCAL):******************************************************
unit-2-1:*************************************************************
unit-3-1:*************************************************************
Para retomar:
firepower# cluster exec capture CAPI interface INSIDE
unit-1-1(LOCAL):******************************************************
unit-2-1:*************************************************************
unit-3-1:*************************************************************
Coletar uma Captura
Há várias maneiras de exportar uma captura.
Caminho 1 - Para um servidor remoto:
Isso permite que você carregue uma captura do plano de dados para um servidor remoto (por exemplo, TFTP). Os nomes de captura são alterados automaticamente para refletir a unidade de origem:
firepower# cluster exec copy /pcap capture:CAPI tftp://192.168.240.55/CAPI.pcap
unit-1-1(LOCAL):******************************************************
Source capture name [CAPI]?
Address or name of remote host [192.168.240.55]?
Destination filename [CAPI.pcap]?
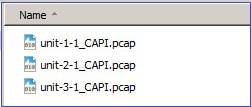
INFO: Destination filename is changed to unit-1-1_CAPI.pcap !!!!!!!
81 packets copied in 0.40 secs
unit-2-1:*************************************************************
INFO: Destination filename is changed to unit-2-1_CAPI.pcap !
unit-3-1:*************************************************************
INFO: Destination filename is changed to unit-3-1_CAPI.pcap !
Os arquivos pcap carregados:
Caminho 2 - Buscar as capturas no FMC:
Essa forma só é aplicável ao FTD. Primeiro, você copia a captura para o disco FTD:
firepower# cluster exec copy /pcap capture:CAPI disk0:CAPI.pcap
unit-1-1(LOCAL):******************************************************
Source capture name [CAPI]?
Destination filename [CAPI.pcap]?
!!!!!
62 packets copied in 0.0 secs
No modo especialista, copie o arquivo do diretório /mnt/disk0/ para o diretório /ngfw/var/common/:
> expert
admin@firepower:~$ cd /mnt/disk0
admin@firepower:/mnt/disk0$ sudo cp CAPI.pcap /ngfw/var/common
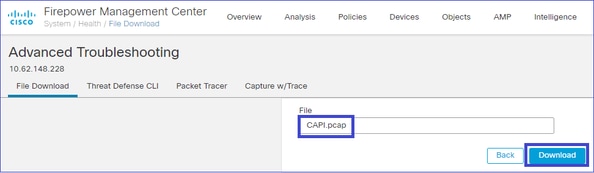
Por fim, no FMC, navegue para a seção System > Health > Monitor. Escolha View System & Troubleshoot Details > Advanced Troubleshooting e busque o arquivo de captura:
Deletar uma Captura
Para remover uma captura de todas as unidades de cluster, use este comando:
firepower# cluster exec no capture CAPI
unit-1-1(LOCAL):******************************************************
unit-2-1:*************************************************************
unit-3-1:*************************************************************
Fluxos descarregados
Em FP41xx/FP9300, os fluxos podem ser descarregados no HW Accelerator estaticamente (por exemplo, regras Fastpath) ou dinamicamente. Para obter mais detalhes sobre o descarregamento de fluxo, consulte este documento: Clarificar Ações de Regra de Política de Controle de Acesso de FTD.
Se um fluxo for descarregado, apenas alguns pacotes passarão pelo plano de dados do FTD. O restante é controlado pelo acelerador de hardware (Smart NIC).
Do ponto de vista da captura, isso significa que se você habilitar apenas as capturas de plano de dados FTD, não verá todos os pacotes que passam pelo dispositivo. Nesse caso, você também precisa ativar as capturas no nível do chassi FXOS.
Mensagens de Link de Controle de Cluster (CCL)
Se você fizer uma captura no CCL, perceberá que as unidades de cluster trocam diferentes tipos de mensagens. Os que interessam são:
|
Protocolo |
Descrição |
|
49495 UDP |
Pulsações de cluster (keepalives) · Difusão de L3 (255.255.255.255) · Esses pacotes são enviados por cada unidade de cluster a 1/3 do valor do tempo de espera da verificação de integridade. · Observe que nem todos os pacotes de 49495 UDP vistos na captura são pulsações · Os batimentos cardíacos contêm um número de sequência. |
|
UDP 4193 |
Mensagens de Caminho de Dados do Protocolo de Controle de Cluster ·Unicast · Esses pacotes contêm informações (metadados) sobre o proprietário do fluxo, o diretor, o proprietário do backup, etc. Exemplos são: · Uma mensagem "cluster add" é enviada do proprietário para o direcionador quando um novo fluxo é criado · Uma mensagem de "exclusão de cluster" é enviada do proprietário para o direcionador quando um fluxo é encerrado |
|
Pacotes de dados |
Pacotes de dados que pertencem aos vários fluxos de tráfego que atravessam o cluster |
Pulsação do cluster:
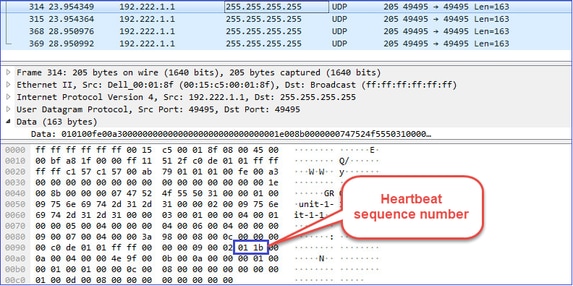
Mensagens do Ponto de Controle de Cluster (CCP)
Além das mensagens de pulsação, há várias mensagens de controle de cluster que são trocadas por meio do CCL em cenários específicos. Algumas delas são mensagens unicast, enquanto outras são broadcasts.
CLUSTER_QUIT_REASON_PRIMARY_UNIT_HC
Sempre que uma unidade perde 3 mensagens de heartbeat consecutivas do nó de controle, ela gera uma mensagem CLUSTER_QUIT_REASON_PRIMARY_UNIT_HC por meio do CCL. Esta mensagem:
- É um unicast.
- Ele é enviado para cada uma das unidades com um intervalo de 1 segundo.
- Quando uma unidade recebe esta mensagem, sai do cluster (DISABLED) e junta-se novamente.
P. Qual é a finalidade do CLUSTER_QUIT_REASON_PRIMARY_UNIT_HC?
A. Do ponto de vista da unidade-3-1 (Site-B), ela perde a conexão com a unidade-1-1 e a unidade-2-1 do site A, portanto precisa removê-las de sua lista de membros o mais rápido possível; caso contrário, pode ter um pacote perdido se a unidade-2-1 ainda estiver em sua lista de membros e a unidade-2-1 for um direcionador de uma conexão, e a consulta de fluxo para a unidade-2-1 falhar.
CLUSTER_QUIT_REASON_UNIT_HC
Sempre que o nó de controle perde 3 mensagens de pulsação consecutivas de um nó de dados, ele envia a mensagem CLUSTER_QUIT_REASON_UNIT_HC pelo CCL. Esta mensagem é unicast.
CLUSTER_QUIT_REASON_STRAY_MEMBER
Quando uma partição dividida se reconecta a uma partição de mesmo nível, o novo nó de dados é tratado como um membro perdido pela unidade de controle dominante e recebe uma mensagem de encerramento do CCP com a razão de CLUSTER_QUIT_REASON_STRAY_MEMBER.
CLUSTER_QUIT_MEMBER_DROPOUT
Uma mensagem de broadcast que é gerada por um nó de dados e é enviada como um broadcast. Quando uma unidade receber essa mensagem, passará para o status DISABLED. Além disso, a rejunção automática não inicia:
firepower# show cluster info trace | include DROPOUT
Nov 04 00:22:54.699 [DBUG]Receive CCP message: CCP_MSG_QUIT from unit-3-1 to unit-1-1 for reason CLUSTER_QUIT_MEMBER_DROPOUT
Nov 04 00:22:53.699 [DBUG]Receive CCP message: CCP_MSG_QUIT from unit-3-1 to unit-2-1 for reason CLUSTER_QUIT_MEMBER_DROPOUT
O histórico do cluster mostra:
PRIMARY DISABLED Received control message DISABLE (member dropout announcement)
Mecanismo de verificação de integridade (HC) do cluster
Pontos principais:
- Cada unidade de cluster envia um heartbeat a cada 1/3 do valor do tempo de espera de verificação de integridade para todas as outras unidades (broadcast 255.255.255.255) e usa o UDP port 49495 como transporte pelo CCL.
- Cada unidade de cluster rastreia de forma independente todas as outras unidades com um temporizador de Votação e um valor de Contagem de Votação.
- Se uma unidade de cluster não receber nenhum pacote (pulsação ou pacote de dados) de uma unidade de peer de cluster dentro de um intervalo de pulsação, ela aumentará o valor da Contagem de poll.
- Quando o valor de contagem de Poll para uma unidade de peer de cluster se torna 3, o peer é considerado inativo.
- Sempre que um heartbeat é recebido, seu número de sequência é verificado e, no caso de a diferença com o heartbeat recebido anteriormente ser diferente de 1, o contador de queda de heartbeat aumenta de acordo.
- Se o contador de Contagem de sondagem para um peer de cluster for diferente de 0 e um pacote for recebido pelo peer, o contador será redefinido para um valor 0.
Use este comando para verificar os contadores de integridade do cluster:
firepower# show cluster info health details
----------------------------------------------------------------------------------
| Unit (ID)| Heartbeat| Heartbeat| Average| Maximum| Poll|
| | count| drops| gap (ms)| slip (ms)| count|
----------------------------------------------------------------------------------
| unit-2-1 ( 1)| 650| 0| 4999| 1| 0|
| unit-3-1 ( 2)| 650| 0| 4999| 1| 0|
----------------------------------------------------------------------------------
Descrição das colunas principais:
|
Coluna |
Descrição |
|
Unidade (ID) |
A ID do par de cluster remoto. |
|
Contagem de pulsações |
O número de pulsações recebidas do par remoto por meio do CCL. |
|
Quedas de pulsação |
O número de pulsações perdidas. Este contador é calculado com base no número de sequência de pulsação recebido. |
|
Intervalo médio |
O intervalo de tempo médio das pulsações recebidas. |
|
Contagem de sondagens |
Quando esse contador se torna 3, a unidade é removida do cluster. O intervalo de consulta de sondagem é o mesmo que o intervalo de pulsação, mas é executado independentemente. |
Para redefinir os contadores, use este comando:
firepower# clear cluster info health details
P. Como verificar a frequência dos batimentos cardíacos?
A. Verifique o valor médio do intervalo:
firepower# show cluster info health details
----------------------------------------------------------------------------------
| Unit (ID)| Heartbeat| Heartbeat| Average| Maximum| Poll|
| | count| drops| gap (ms)| slip (ms)| count|
----------------------------------------------------------------------------------
| unit-2-1 ( 1)| 3036| 0| 999| 1| 0|
----------------------------------------------------------------------------------
P. Como você pode alterar o tempo de espera do cluster no FTD?
A. Use o FlexConfig.
P. Quem se torna o nó de controle após uma divisão cerebral?
A. A unidade com a prioridade mais alta (número mais baixo):
firepower# show run cluster | include priority
priority 9
Verifique o cenário de falha HC 1 para obter mais detalhes.
A visualização do mecanismo HC do cluster
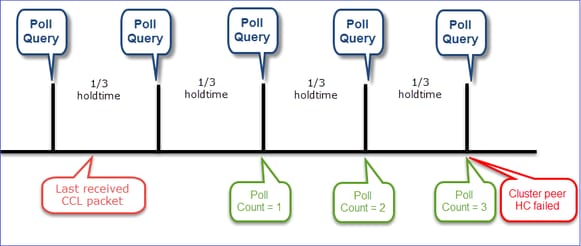
Temporizadores indicativos: Os valores mínimo e máximo dependem da última chegada do pacote CCL recebido.
|
Tempo de espera |
Verificação de consulta de sondagem (frequência) |
Tempo mínimo de detecção |
Tempo máximo de detecção |
|
3 seg (padrão) |
Aproximadamente 1 s |
~3,01 seg |
~3,99 seg |
|
4 s |
~1,33 seg |
~4,01 s |
~5,32 seg |
|
5 s |
~1,66 s |
~5,01 s |
~6,65 seg |
|
6 s |
Aprox. 2 s |
~6,01 seg |
~7,99 seg |
|
7 s |
~2,33 seg |
~7,01 seg |
~9,32 seg |
|
8 s |
~2,66 seg |
~8,01 seg |
~10,65 s |
Cenários de falha de HC de cluster
Os objetivos desta seção são demonstrar:
- Diferentes cenários de falha de HC de cluster.
- Como os diferentes logs e saídas de comando podem ser correlacionados.
Topologia
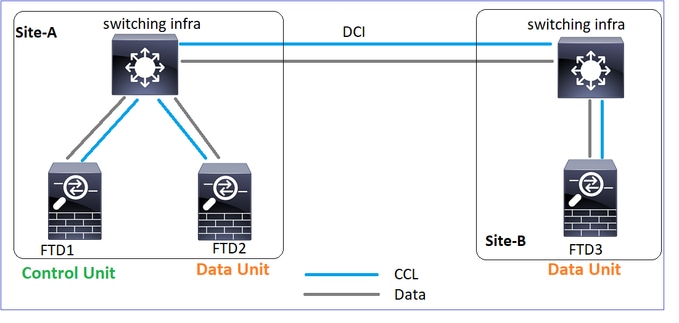
Configuração de cluster:
|
Unit-1-1 |
Unit-2-1 |
Unit-3-1 |
cluster group GROUP1 |
cluster group GROUP1 |
cluster group GROUP1 |
Status do cluster:
|
Unit-1-1 |
Unit-2-1 |
Unit-3-1 |
firepower# show cluster info |
firepower# show cluster info |
firepower# show cluster info |
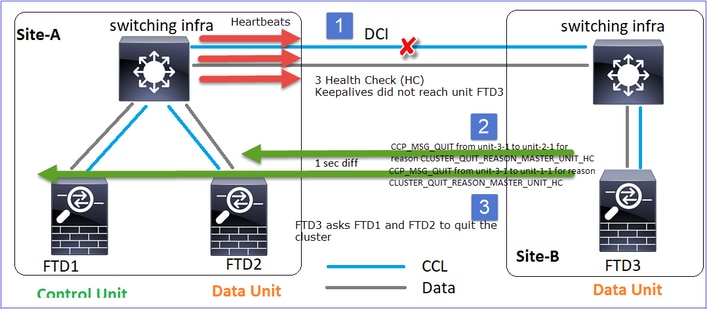
Cenário 1 - Perda de comunicação CCL por aprox. 4+ segundos em ambas as direções
Antes da falha:
|
FTD1 |
FTD2 |
FTD3 |
|
Local-A |
Local-A |
Local-B |
|
Nó de controle |
Nó de dados |
Nó de dados |
Após a recuperação (sem alterações nas funções de unidade):
|
FTD1 |
FTD2 |
FTD3 |
|
Local-A |
Local-A |
Local-B |
|
Nó de controle |
Nó de dados |
Nó de dados |
Análise
A falha (a comunicação da CCL foi perdida).

A mensagem do console do plano de dados na unidade 3-1:
firepower#
WARNING: dynamic routing is not supported on management interface when cluster interface-mode is 'spanned'.
If dynamic routing is configured on any management interface, please remove it.
Cluster unit unit-3-1 transitioned from SECONDARY to PRIMARY
Cluster disable is performing cleanup..done.
All data interfaces have been shutdown due to clustering being disabled.
To recover either enable clustering or remove cluster group configuration.
Logs de rastreamento de cluster de Unidade 1-1:
firepower# show cluster info trace | include unit-3-1
Nov 02 09:38:14.239 [INFO]Notify chassis de-bundle port for blade unit-3-1, stack 0x000055a8918307fb 0x000055a8917fc6e8 0x000055a8917f79b5
Nov 02 09:38:14.239 [INFO]FTD - CD proxy received state notification (DISABLED) from unit unit-3-1
Nov 02 09:38:14.239 [DBUG]Send CCP message to all: CCP_MSG_QUIT from unit-1-1 to unit-3-1 for reason CLUSTER_QUIT_MEMBER_DROPOUT
Nov 02 09:38:14.239 [INFO]Notify chassis de-bundle port for blade unit-3-1, stack 0x000055a8917eb596 0x000055a8917f4838 0x000055a891abef9d
Nov 02 09:38:14.239 [DBUG]Send CCP message to id 1: CCP_MSG_QUIT from unit-1-1 to unit-3-1 for reason CLUSTER_QUIT_REASON_UNIT_HC
Nov 02 09:38:14.239 [CRIT]Received heartbeat event 'SECONDARY heartbeat failure' for member unit-3-1 (ID: 1).
Split-brain:
|
Unit-1-1 |
Unit-2-1 |
Unit-3-1 |
firepower# show cluster info |
firepower# show cluster info |
firepower# show cluster info |
Histórico do cluster:
|
Unit-1-1 |
Unit-2-1 |
Unit-3-1 |
|
Nenhum evento |
Nenhum evento |
09:38:16 UTC Nov 2 2020 |
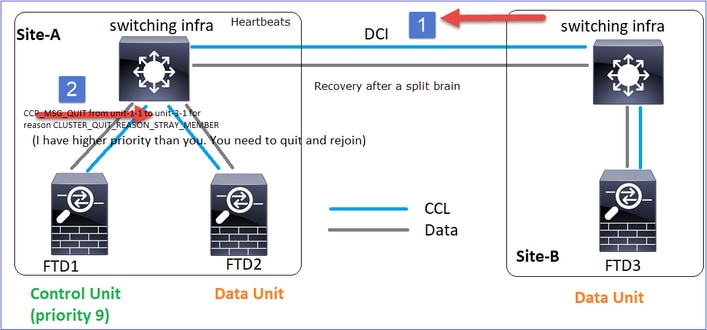
Restauração de Comunicação CCL
A Unidade-1-1 detecta o nó de controle atual e, como a unidade-1-1 tem prioridade mais alta, envia à unidade-3-1 uma mensagem CLUSTER_QUIT_REASON_STRAY_MEMBER para disparar um novo processo de eleição. No final, a unidade 3-1 se une novamente como um nó de dados.
Quando uma partição dividida se reconecta a uma partição de mesmo nível, o nó de dados é tratado como um membro perdido pelo nó de controle dominante e recebe uma mensagem de saída CCP com um motivo de CLUSTER_QUIT_REASON_STRAY_MEMBER.
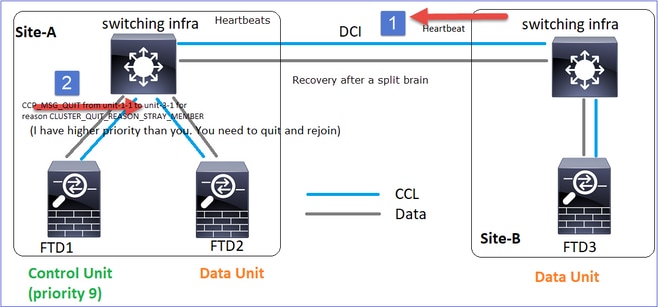
Unit-3-1 console logs show:
Cluster unit unit-3-1 transitioned from PRIMARY to DISABLED
The 3DES/AES algorithms require a Encryption-3DES-AES activation key.
Detected Cluster Primart.
Beginning configuration replication from Primary.
WARNING: Local user database is empty and there are still 'aaa' commands for 'LOCAL'.
..
Cryptochecksum (changed): a9ed686f 8e2e689c 2553a104 7a2bd33a
End configuration replication from Primary.
Cluster unit unit-3-1 transitioned from DISABLED to SECONDARY
As duas unidades (unidade 1-1 e unidade 3-1) são mostradas em seus logs de cluster:
firepower# show cluster info trace | include retain
Nov 03 21:20:23.019 [CRIT]Found a split cluster with both unit-1-1 and unit-3-1 as primary units. Primary role retained by unit-1-1, unit-3-1 will leave then join as a secondary
Nov 03 21:20:23.019 [CRIT]Found a split cluster with both unit-1-1 and unit-3-1 as primary units. Primary role retained by unit-1-1, unit-3-1 will leave then join as a secondary
Há também mensagens de syslog geradas para o split-brain:
firepower# show log | include 747016
Nov 03 2020 21:20:23: %FTD-4-747016: Clustering: Found a split cluster with both unit-1-1 and unit-3-1 as primary units. Primary role retained by unit-1-1, unit-3-1 will leave then join as a secondary
Nov 03 2020 21:20:23: %FTD-4-747016: Clustering: Found a split cluster with both unit-1-1 and unit-3-1 as primary units. Primary role retained by unit-1-1, unit-3-1 will leave then join as a secondary
Histórico do cluster:
|
Unit-1-1 |
Unit-2-1 |
Unit-3-1 |
|
Nenhum evento |
Nenhum evento |
09:47:33 UTC Nov 2 2020 |
Cenário 2 - Perda de comunicação CCL por aprox. 3-4 segundos em ambas as direções
Antes da falha:
|
FTD1 |
FTD2 |
FTD3 |
|
Local-A |
Local-A |
Local-B |
|
Nó de controle |
Nó de dados |
Nó de dados |
Após a recuperação (sem alterações nas funções de unidade):
|
FTD1 |
FTD2 |
FTD3 |
|
Local-A |
Local-A |
Local-B |
|
Nó de controle |
Nó de dados |
Nó de dados |
Análise
Evento 1: O nó de controle perde 3 CHs da unidade 3-1 e envia uma mensagem para a unidade 3-1 para deixar o cluster.
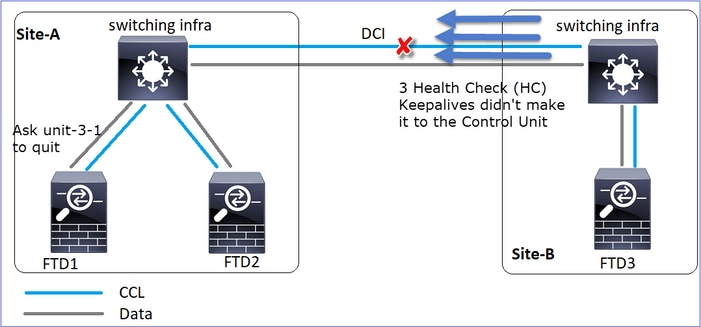
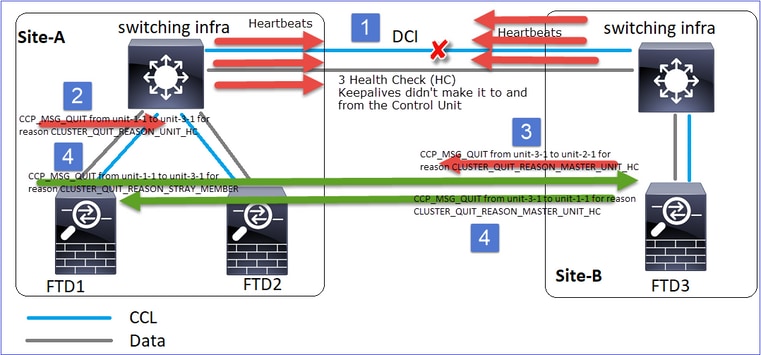
Evento 2: O CCL recuperou-se muito rapidamente e a mensagem CLUSTER_QUIT_REASON_STRAY_MEMBER do nó de controle chegou ao lado remoto. A unidade 3-1 vai diretamente para o modo DISABLED e não há split brain
Na unidade 1-1 (controle) você vê:
firepower#
Asking SECONDARY unit unit-3-1 to quit because it failed unit health-check.
Forcing stray member unit-3-1 to leave the cluster
Na unidade 3-1 (nó de dados) você vê:
firepower#
Cluster disable is performing cleanup..done.
All data interfaces have been shutdown due to clustering being disabled. To recover either enable clustering or remove cluster group configuration.
Cluster unit unit-3-1 transitioned from SECONDARY to DISABLED
A unidade de cluster 3-1 fez a transição para um estado DISABLED e, uma vez restaurada a comunicação CCL, ela ingressa novamente como um nó de dados:
firepower# show cluster history
20:58:40 UTC Nov 1 2020
SECONDARY DISABLED Received control message DISABLE (stray member)
20:58:45 UTC Nov 1 2020
DISABLED ELECTION Enabled from CLI
20:58:45 UTC Nov 1 2020
ELECTION SECONDARY_COLD Received cluster control message
20:58:45 UTC Nov 1 2020
SECONDARY_COLD SECONDARY_APP_SYNC Client progression done
20:59:33 UTC Nov 1 2020
SECONDARY_APP_SYNC SECONDARY_CONFIG SECONDARY application configuration sync done
20:59:44 UTC Nov 1 2020
SECONDARY_CONFIG SECONDARY_FILESYS Configuration replication finished
20:59:45 UTC Nov 1 2020
SECONDARY_FILESYS SECONDARY_BULK_SYNC Client progression done
21:00:09 UTC Nov 1 2020
SECONDARY_BULK_SYNC SECONDARY Client progression done
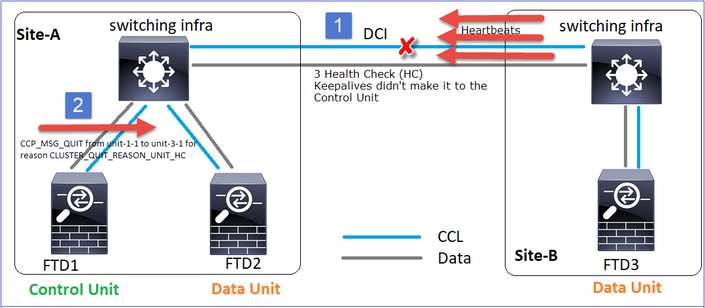
Cenário 3 - Perda de comunicação CCL por aprox. 3-4 segundos em ambas as direções
Antes da falha:
|
FTD1 |
FTD2 |
FTD3 |
|
Local-A |
Local-A |
Local-B |
|
Nó de controle |
Nó de dados |
Nó de dados |
Após a recuperação (o nó de controle foi alterado):
|
FTD1 |
FTD2 |
FTD3 |
|
Local-A |
Local-A |
Local-B |
|
Nó de dados |
Nó de controle |
Nó de dados |
Análise
- A ACL fica inativa.
- A unidade 1-1 não recebe 3 mensagens HC da unidade 3-1 e envia uma mensagem QUIT para a unidade 3-1. Essa mensagem nunca chega à unidade 3-1.
- A Unidade-3-1 envia uma mensagem QUIT para a unidade-2-1. Essa mensagem nunca chega à unidade-2-1.
A CCL se recupera.
- A Unidade-1-1 vê que a unidade-3-1 anunciou a si mesma como um nó de controle e envia a mensagem QUIT_REASON_STRAY_MEMBER para a unidade-3-1. Quando a unidade-3-1 obtém essa mensagem, ela entra em um estado DISABLED. Ao mesmo tempo, a unidade 3-1 envia uma mensagem QUIT_REASON_PRIMARY_UNIT_HC à unidade 1-1 e solicita que ela seja encerrada. Quando a unidade 1-1 recebe essa mensagem, ela entra em um estado DISABLED.
Histórico do cluster:
|
Unit-1-1 |
Unit-2-1 |
Unit-3-1 |
19:53:09 UTC Nov 2 2020 |
19:53:06 UTC Nov 2 2020 |
19:53:06 UTC Nov 2 2020 |
Cenário 4 - Perda de comunicação CCL por aprox. 3-4 segundos
Antes da falha:
|
FTD1 |
FTD2 |
FTD3 |
|
Local-A |
Local-A |
Local-B |
|
Nó de controle |
Nó de dados |
Nó de dados |
Após a recuperação (o nó de controle alterou os sites):
|
FTD1 |
FTD2 |
FTD3 |
|
Local-A |
Local-A |
Local-B |
|
Nó de dados |
Nó de dados |
Nó de controle |
Análise
A falha

Um sabor diferente da mesma falha. Neste caso, a unidade-1-1 também não recebeu 3 mensagens HC da unidade-3-1, e uma vez que obteve um novo keepalive, tentou expulsar a unidade-3-1 com o uso de uma mensagem STRAY, mas a mensagem nunca chegou à unidade-3-1:

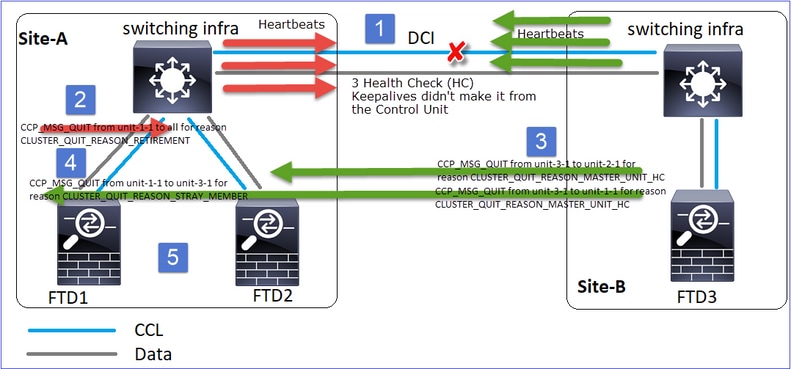
- A CCL se torna unidirecional por alguns segundos. A unidade 3-1 não recebe 3 mensagens HC da unidade 1-1 e torna-se um nó de controle.
- A Unidade 2-1 envia uma mensagem CLUSTER_QUIT_REASON_RETIREMENT (broadcast).
- A Unidade-3-1 envia uma mensagem QUIT_REASON_PRIMARY_UNIT_HC para a unidade-2-1. A Unidade-2-1 a recebe e sai do cluster.
- A Unidade-3-1 envia uma mensagem QUIT_REASON_PRIMARY_UNIT_HC para a unidade-1-1. A Unidade-1-1 a recebe e sai do cluster. A CCL se recupera.
- As Unidades 1-1 e 2-1 reingressam no cluster como nós de dados.
Note: Se na etapa 5 o CCL não se recuperar, então no site-A o FTD1 se tornará o novo nó de controle e, após a recuperação do CCL, ele ganhará a nova eleição.
Mensagens de syslog na unidade 1-1:
firepower# show log | include 747
Nov 03 2020 23:13:08: %FTD-7-747005: Clustering: State machine notify event CLUSTER_EVENT_MEMBER_STATE (unit-3-1,DISABLED,0x0000000000000000)
Nov 03 2020 23:13:09: %FTD-4-747015: Clustering: Forcing stray member unit-3-1 to leave the cluster
Nov 03 2020 23:13:09: %FTD-7-747005: Clustering: State machine notify event CLUSTER_EVENT_MEMBER_STATE (unit-2-1,DISABLED,0x0000000000000000)
Nov 03 2020 23:13:10: %FTD-4-747015: Clustering: Forcing stray member unit-3-1 to leave the cluster
Nov 03 2020 23:13:10: %FTD-6-747004: Clustering: State machine changed from state PRIMARY to DISABLED
Nov 03 2020 23:13:12: %FTD-7-747006: Clustering: State machine is at state DISABLED
Nov 03 2020 23:13:12: %FTD-7-747005: Clustering: State machine notify event CLUSTER_EVENT_MY_STATE (state DISABLED,0x0000000000000000,0x0000000000000000)
Nov 03 2020 23:13:18: %FTD-6-747004: Clustering: State machine changed from state ELECTION to ONCALL
Logs de rastreamento de cluster na unidade 1-1:
firepower# show cluster info trace | include QUIT
Nov 03 23:13:10.789 [DBUG]Send CCP message to all: CCP_MSG_QUIT from unit-1-1 for reason CLUSTER_QUIT_REASON_RETIREMENT
Nov 03 23:13:10.769 [DBUG]Receive CCP message: CCP_MSG_QUIT from unit-3-1 to unit-1-1 for reason CLUSTER_QUIT_REASON_PRIMARY_UNIT_HC
Nov 03 23:13:10.769 [DBUG]Send CCP message to id 1: CCP_MSG_QUIT from unit-1-1 to unit-3-1 for reason CLUSTER_QUIT_REASON_STRAY_MEMBER
Nov 03 23:13:09.789 [DBUG]Receive CCP message: CCP_MSG_QUIT from unit-2-1 for reason CLUSTER_QUIT_REASON_RETIREMENT
Nov 03 23:13:09.769 [DBUG]Send CCP message to id 1: CCP_MSG_QUIT from unit-1-1 to unit-3-1 for reason CLUSTER_QUIT_REASON_STRAY_MEMBER
Nov 03 23:13:08.559 [DBUG]Send CCP message to all: CCP_MSG_QUIT from unit-1-1 to unit-3-1 for reason CLUSTER_QUIT_MEMBER_DROPOUT
Nov 03 23:13:08.559 [DBUG]Send CCP message to id 1: CCP_MSG_QUIT from unit-1-1 to unit-3-1 for reason CLUSTER_QUIT_REASON_UNIT_HC
Mensagens de syslog na unidade 3-1:
firepower# show log | include 747
Nov 03 2020 23:13:09: %FTD-7-747005: Clustering: State machine notify event CLUSTER_EVENT_MEMBER_STATE (unit-2-1,DISABLED,0x0000000000000000)
Nov 03 2020 23:13:10: %FTD-7-747005: Clustering: State machine notify event CLUSTER_EVENT_MEMBER_STATE (unit-1-1,DISABLED,0x0000000000000000)
Nov 03 2020 23:13:10: %FTD-6-747004: Clustering: State machine changed from state SECONDARY to PRIMARY
Nov 03 2020 23:13:10: %FTD-6-747004: Clustering: State machine changed from state PRIMARY_FAST to PRIMARY_DRAIN
Nov 03 2020 23:13:10: %FTD-6-747004: Clustering: State machine changed from state PRIMARY_DRAIN to PRIMARY_CONFIG
Nov 03 2020 23:13:10: %FTD-6-747004: Clustering: State machine changed from state PRIMARY_CONFIG to PRIMARY_POST_CONFIG
Nov 03 2020 23:13:10: %FTD-7-747006: Clustering: State machine is at state PRIMARY_POST_CONFIG
Nov 03 2020 23:13:10: %FTD-6-747004: Clustering: State machine changed from state PRIMARY_POST_CONFIG to PRIMARY
Nov 03 2020 23:13:10: %FTD-7-747006: Clustering: State machine is at state PRIMARY
Histórico do cluster
|
Unit-1-1 |
Unit-2-1 |
Unit-3-1 |
23:13:13 UTC Nov 3 2020 |
23:13:12 UTC Nov 3 2020 |
23:13:10 UTC Nov 3 2020 |
Cenário 5
Antes da falha:
|
FTD1 |
FTD2 |
FTD3 |
|
Local-A |
Local-A |
Local-B |
|
Nó de controle |
Nó de dados |
Nó de dados |
Após a recuperação (sem alterações):
|
FTD1 |
FTD2 |
FTD3 |
|
Local-A |
Local-A |
Local-B |
|
Nó de controle |
Nó de dados |
Nó de dados |
A falha:
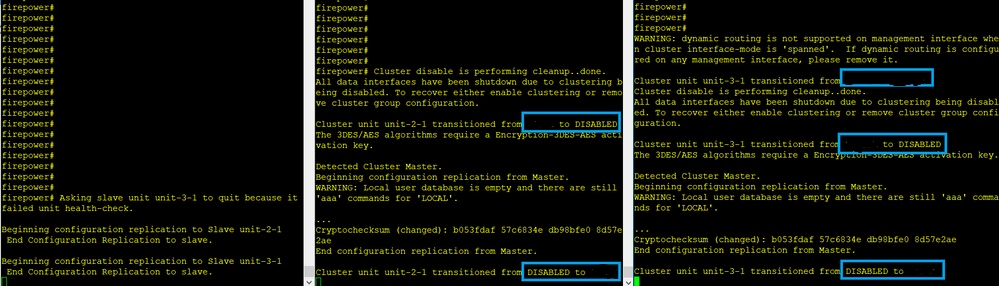
A Unidade 3-1 enviou mensagens QUIT para a unidade 1-1 e para a unidade 2-1, mas devido a problemas de conectividade, somente a unidade 2-1 recebeu a mensagem QUIT.
Logs de rastreamento de cluster de Unidade 1-1:
firepower# show cluster info trace | include QUIT
Nov 04 00:52:10.429 [DBUG]Receive CCP message: CCP_MSG_QUIT from unit-3-1 for reason CLUSTER_QUIT_REASON_RETIREMENT
Nov 04 00:51:47.059 [DBUG]Receive CCP message: CCP_MSG_QUIT from unit-2-1 for reason CLUSTER_QUIT_REASON_RETIREMENT
Nov 04 00:51:45.429 [DBUG]Send CCP message to all: CCP_MSG_QUIT from unit-1-1 to unit-3-1 for reason CLUSTER_QUIT_MEMBER_DROPOUT
Nov 04 00:51:45.429 [DBUG]Send CCP message to unit-3-1(1): CCP_MSG_QUIT from unit-1-1 to unit-3-1 for reason CLUSTER_QUIT_REASON_UNIT_HC
Logs de rastreamento do cluster da Unidade 2-1:
firepower# show cluster info trace | include QUIT
Nov 04 00:52:10.389 [DBUG]Receive CCP message: CCP_MSG_QUIT from unit-3-1 for reason CLUSTER_QUIT_REASON_RETIREMENT
Nov 04 00:51:47.019 [DBUG]Send CCP message to all: CCP_MSG_QUIT from unit-2-1 for reason CLUSTER_QUIT_REASON_RETIREMENT
Nov 04 00:51:46.999 [DBUG]Receive CCP message: CCP_MSG_QUIT from unit-3-1 to unit-2-1 for reason CLUSTER_QUIT_REASON_PRIMARY_UNIT_HC
Nov 04 00:51:45.389 [DBUG]Receive CCP message: CCP_MSG_QUIT from unit-1-1 to unit-3-1 for reason CLUSTER_QUIT_MEMBER_DROPOUT
Histórico do cluster:
|
Unit-1-1 |
Unit-2-1 |
Unit-3-1 |
|
Nenhum evento |
00:51:50 UTC Nov 4 2020 |
00:51:47 UTC Nov 4 2020 |
Estabelecimento de Conexão de Plano de Dados de Cluster
Pontos de captura do NGFW
O NGFW oferece recursos de captura nestes pontos:
- Switch interno do chassi (FXOS)
- Mecanismo de plano de dados FTD
- Mecanismo Snort de FTD
Quando você soluciona problemas de caminho de dados em um cluster, os pontos de captura usados na maioria dos casos são as capturas de mecanismo de plano de dados FXOS e FTD.
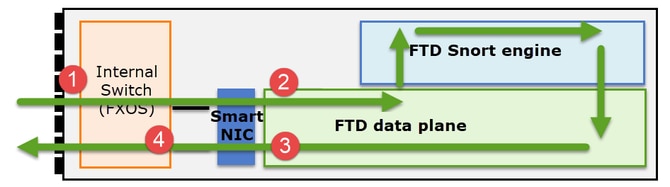
- Captura de ingresso FXOS na interface física
- Captura de ingresso de FTD em mecanismo de plano de dados
- Captura de saída FTD no mecanismo de plano de dados
- Captura de entrada FXOS na interface do painel traseiro
Para obter mais detalhes sobre as capturas de NGFW, consulte este documento:
Conceitos Básicos das Funções de Fluxo de Unidade de Cluster
As conexões podem ser estabelecidas por meio de um cluster de várias maneiras, dependendo de fatores como:
- Tipo de tráfego (TCP, UDP, etc.)
- Algoritmo de balanceamento de carga configurado no switch adjacente
- Recursos configurados no firewall
- Condições de rede (por exemplo, fragmentação de IP, atrasos de rede e assim por diante)
|
Função de fluxo |
Descrição |
Pavilhão(ões) |
|
PROPRIETÁRIO |
Geralmente, a unidade que recebe inicialmente a conexão |
UIO |
|
Director |
A unidade que trata solicitações de pesquisa de proprietário de encaminhadores. |
Y |
|
Proprietário do backup |
Desde que o direcionador não seja a mesma unidade que o proprietário, o direcionador também será o proprietário do backup. Se o proprietário escolher a si mesmo como o direcionador, então um proprietário de backup separado será escolhido. |
S (se o direcionador também for o proprietário do backup) y (se o direcionador não for o proprietário do backup) |
|
Encaminhador |
Uma unidade que encaminha pacotes ao proprietário |
z |
|
Proprietário do fragmento |
A unidade que lida com o tráfego fragmentado |
- |
|
Backup do chassi |
Em um cluster entre chassis, quando os fluxos de diretor/backup e proprietário são de propriedade das unidades do mesmo chassi, uma unidade em um dos outros chassis torna-se um backup/diretor secundário. Essa função é específica para clusters entre chassis do Firepower 9300 Series com mais de um blade. |
w |
- Para obter mais detalhes, verifique a seção relacionada no Guia de configuração (consulte os links em Informações relacionadas)
- Em cenários específicos (consulte a seção estudos de caso) algumas sinalizações nem sempre são mostradas.
Estudos de Caso de Estabelecimento de Conexão de Cluster
A próxima seção aborda vários estudos de caso que demonstram algumas das maneiras pelas quais uma conexão pode ser estabelecida através de um cluster. Os objetivos são:
- Familiarize-se com as diferentes funções de unidade.
- Demonstre como as várias saídas de comando podem ser correlacionadas.
Topologia

Unidades e IDs de cluster:
|
Unit-1-1 |
Unit-2-1 |
Unit-3-1 |
Cluster GROUP1: On |
Unit "unit-2-1" in state SECONDARY |
Unit "unit-3-1" in state SECONDARY |
Capturas de cluster habilitadas:
cluster exec cap CAPI int INSIDE buffer 33554432 match tcp host 192.168.240.50 host 192.168.241.50 eq 80
cluster exec cap CAPO int OUTSIDE buffer 33554432 match tcp host 192.168.240.50 host 192.168.241.50 eq 80
cluster exec cap CAPI_RH reinject-hide int INSIDE buffer 33554432 match tcp host 192.168.240.50 host 192.168.241.50 eq 80
cluster exec cap CAPO_RH reinject-hide int OUTSIDE buffer 33554432 match tcp host 192.168.240.50 host 192.168.241.50 eq 80
cluster exec cap CCL int cluster buffer 33554432
Note: Esses testes foram executados em um ambiente de laboratório com tráfego mínimo através do cluster. Na produção, tente usar os filtros de captura mais específicos possível (por exemplo, a porta de destino e, sempre que possível, a porta de origem) para minimizar o ‘ruído’ nas capturas.
Estudo de caso 1. Tráfego simétrico (o proprietário também é o diretor)
Observação 1. As capturas de reinserção/ocultação mostram pacotes somente na unidade 1-1. Isso significa que o fluxo em ambas as direções passou pela unidade 1-1 (tráfego simétrico):
firepower# cluster exec show cap
unit-1-1(LOCAL):******************************************************
capture CCL type raw-data interface cluster [Capturing - 33513 bytes]
capture CAPI type raw-data buffer 33554432 trace interface INSIDE [Buffer Full - 33553914 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq 80
capture CAPO type raw-data buffer 33554432 trace interface OUTSIDE [Buffer Full - 33553914 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq 80
capture CAPI_RH type raw-data reinject-hide buffer 33554432 interface INSIDE [Buffer Full - 33553914 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq 80
capture CAPO_RH type raw-data reinject-hide buffer 33554432 interface OUTSIDE [Buffer Full - 33553914 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq 80
unit-2-1:*************************************************************
capture CCL type raw-data interface cluster [Capturing - 23245 bytes]
capture CAPI type raw-data buffer 33554432 trace interface INSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq 80
capture CAPO type raw-data buffer 33554432 trace interface OUTSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq 80
capture CAPI_RH type raw-data reinject-hide buffer 33554432 interface INSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq 80
capture CAPO_RH type raw-data reinject-hide buffer 33554432 interface OUTSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq 80
unit-3-1:*************************************************************
capture CCL type raw-data interface cluster [Capturing - 24815 bytes]
capture CAPI type raw-data buffer 33554432 trace interface INSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq 80
capture CAPO type raw-data buffer 33554432 trace interface OUTSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq 80
capture CAPI_RH type raw-data reinject-hide buffer 33554432 interface INSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq 80
capture CAPO_RH type raw-data reinject-hide buffer 33554432 interface OUTSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq 80
Observação 2. Análise de flag de conexão para fluxo com porta origem 45954:
firepower# cluster exec show conn
unit-1-1(LOCAL):******************************************************
22 in use, 25 most used
Cluster:
fwd connections: 0 in use, 1 most used
dir connections: 0 in use, 122 most used
centralized connections: 0 in use, 0 most used
VPN redirect connections: 0 in use, 0 most used
Inspect Snort:
preserve-connection: 1 enabled, 0 in effect, 2 most enabled, 1 most in effect
TCP OUTSIDE 192.168.241.50:80 INSIDE 192.168.240.50:45954, idle 0:00:00, bytes 487413076, flags UIO N1
unit-2-1:*************************************************************
22 in use, 271 most used
Cluster:
fwd connections: 0 in use, 2 most used
dir connections: 0 in use, 2 most used
centralized connections: 0 in use, 0 most used
VPN redirect connections: 0 in use, 0 most used
Inspect Snort:
preserve-connection: 1 enabled, 0 in effect, 249 most enabled, 0 most in effect
unit-3-1:*************************************************************
17 in use, 20 most used
Cluster:
fwd connections: 1 in use, 2 most used
dir connections: 1 in use, 127 most used
centralized connections: 0 in use, 0 most used
VPN redirect connections: 0 in use, 0 most used
Inspect Snort:
preserve-connection: 0 enabled, 0 in effect, 1 most enabled, 0 most in effect
TCP OUTSIDE 192.168.241.50:443 NP Identity Ifc 192.168.240.50:39698, idle 0:00:23, bytes 0, flags z
TCP OUTSIDE 192.168.241.50:80 INSIDE 192.168.240.50:45954, idle 0:00:06, bytes 0, flags y
|
Unidade |
Sinalizador |
Nota |
|
Unit-1-1 |
UIO |
· Proprietário do fluxo - A unidade controla o fluxo · Diretor - Como a unidade 3-1 tem "y" e não "Y", isso implica que a unidade 1-1 foi escolhida como o diretor para esse fluxo. Assim, como também é o proprietário, outra unidade (unidade 3-1 neste caso) foi eleita como o proprietário de backup |
|
Unit-2-1 |
- |
- |
|
Unit-3-1 |
y |
A unidade é um proprietário de Backup |
Isso pode ser visualizado da seguinte maneira:
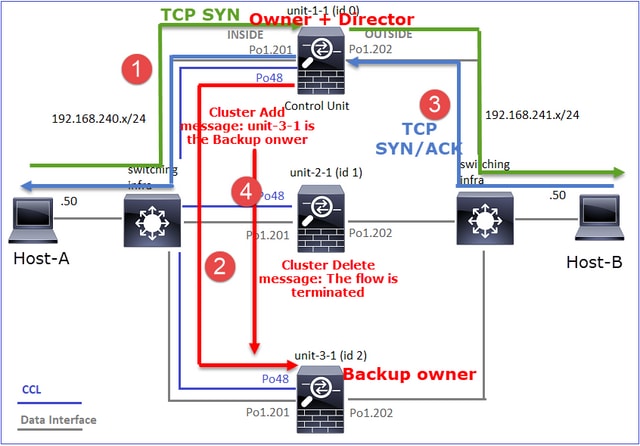
- O pacote TCP SYN chega do Host-A para a unidade 1-1. A unidade 1-1 torna-se o proprietário do fluxo.
- A Unidade-1-1 também é eleita diretora de fluxo. Assim, ele também escolhe a unidade 3-1 como o proprietário do backup (mensagem de adição de cluster).
- O pacote TCP SYN/ACK chega do Host-B para a unidade 3-1. O fluxo é simétrico.
- Quando a conexão é encerrada, o proprietário envia uma mensagem de exclusão de cluster para remover as informações de fluxo do proprietário do backup.
A observação 3. Capture with trace mostra que ambas as direções passam somente pela unidade 1-1:
Etapa 1. Identificar o fluxo e os pacotes de interesse em todas as unidades de cluster com base na porta de origem:
firepower# cluster exec show capture CAPI | i 45954
unit-1-1(LOCAL):******************************************************
1: 08:42:09.362697 802.1Q vlan#201 P0 192.168.240.50.45954 > 192.168.241.50.80: S 992089269:992089269(0) win 29200 <mss 1460,sackOK,timestamp 495153655 0,nop,wscale 7>
2: 08:42:09.363521 802.1Q vlan#201 P0 192.168.241.50.80 > 192.168.240.50.45954: S 4042762409:4042762409(0) ack 992089270 win 28960 <mss 1380,sackOK,timestamp 505509125 495153655,nop,wscale 7>
3: 08:42:09.363827 802.1Q vlan#201 P0 192.168.240.50.45954 > 192.168.241.50.80: . ack 4042762410 win 229 <nop,nop,timestamp 495153657 505509125>
…
unit-2-1:*************************************************************
unit-3-1:*************************************************************
firepower# cluster exec show capture CAPO | i 45954
unit-1-1(LOCAL):******************************************************
1: 08:42:09.362987 802.1Q vlan#202 P0 192.168.240.50.45954 > 192.168.241.50.80: S 2732339016:2732339016(0) win 29200 <mss 1380,sackOK,timestamp 495153655 0,nop,wscale 7>
2: 08:42:09.363415 802.1Q vlan#202 P0 192.168.241.50.80 > 192.168.240.50.45954: S 3603655982:3603655982(0) ack 2732339017 win 28960 <mss 1460,sackOK,timestamp 505509125 495153655,nop,wscale 7>
3: 08:42:09.363903 802.1Q vlan#202 P0 192.168.240.50.45954 > 192.168.241.50.80: . ack 3603655983 win 229 <nop,nop,timestamp 495153657 505509125>
…
unit-2-1:*************************************************************
unit-3-1:*************************************************************
Etapa 2. Como este é um rastreamento de fluxo TCP, os pacotes de handshake triplo. Como pode ser visto nesta saída, a unidade 1-1 é o proprietário. Por razões de simplicidade, são omitidas as fases de rastreio não relevantes:
firepower# show cap CAPI packet-number 1 trace
25985 packets captured
1: 08:42:09.362697 802.1Q vlan#201 P0 192.168.240.50.45954 > 192.168.241.50.80: S 992089269:992089269(0) win 29200 <mss 1460,sackOK,timestamp 495153655 0,nop,wscale 7>
...
Phase: 4
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'INSIDE'
Flow type: NO FLOW
I (0) got initial, attempting ownership.
Phase: 5
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'INSIDE'
Flow type: NO FLOW
I (0) am becoming owner
...
O tráfego de retorno (TCP SYN/ACK):
firepower# show capture CAPO packet-number 2 trace
25985 packets captured
2: 08:42:09.363415 802.1Q vlan#202 P0 192.168.241.50.80 > 192.168.240.50.45954: S 3603655982:3603655982(0) ack 2732339017 win 28960 <mss 1460,sackOK,timestamp 505509125 495153655,nop,wscale 7>
...
Phase: 3
Type: FLOW-LOOKUP
Subtype:
Result: ALLOW
Config:
Additional Information:
Found flow with id 9364, using existing flow
Observação 4. Os syslogs de plano de dados FTD mostram a criação e o término da conexão em todas as unidades:
firepower# cluster exec show log | include 45954
unit-1-1(LOCAL):******************************************************
Dec 01 2020 08:42:09: %FTD-6-302013: Built inbound TCP connection 9364 for INSIDE:192.168.240.50/45954 (192.168.240.50/45954) to OUTSIDE:192.168.241.50/80 (192.168.241.50/80)
Dec 01 2020 08:42:18: %FTD-6-302014: Teardown TCP connection 9364 for INSIDE:192.168.240.50/45954 to OUTSIDE:192.168.241.50/80 duration 0:00:08 bytes 1024000440 TCP FINs from INSIDE
unit-2-1:*************************************************************
unit-3-1:*************************************************************
Dec 01 2020 08:42:09: %FTD-6-302022: Built backup stub TCP connection for INSIDE:192.168.240.50/45954 (192.168.240.50/45954) to OUTSIDE:192.168.241.50/80 (192.168.241.50/80)
Dec 01 2020 08:42:18: %FTD-6-302023: Teardown backup TCP connection for INSIDE:192.168.240.50/45954 to OUTSIDE:192.168.241.50/80 duration 0:00:08 forwarded bytes 0 Cluster flow with CLU closed on owner
Estudo de caso 2. Tráfego simétrico (proprietário diferente do diretor)
- O mesmo que o estudo de caso #1, mas neste estudo de caso, um proprietário de fluxo é uma unidade diferente do diretor.
- Todas as saídas são semelhantes às #1 do estudo de caso. A principal diferença em comparação com a #1 do estudo de caso é o indicador "Y", que substitui o indicador "y" do cenário 1.
Observação 1. O proprietário é diferente do diretor.
Análise de sinalizador de conexão para fluxo com 46278 de porta de origem:
firepower# cluster exec show conn
unit-1-1(LOCAL):******************************************************
23 in use, 25 most used
Cluster:
fwd connections: 0 in use, 1 most used
dir connections: 0 in use, 122 most used
centralized connections: 0 in use, 0 most used
VPN redirect connections: 0 in use, 0 most used
Inspect Snort:
preserve-connection: 2 enabled, 0 in effect, 4 most enabled, 1 most in effect
TCP OUTSIDE 192.168.241.50:80 INSIDE 192.168.240.50:46278, idle 0:00:00, bytes 508848268, flags UIO N1
TCP OUTSIDE 192.168.241.50:80 INSIDE 192.168.240.50:46276, idle 0:00:03, bytes 0, flags aA N1
unit-2-1:*************************************************************
21 in use, 271 most used
Cluster:
fwd connections: 0 in use, 2 most used
dir connections: 0 in use, 2 most used
centralized connections: 0 in use, 0 most used
VPN redirect connections: 0 in use, 0 most used
Inspect Snort:
preserve-connection: 0 enabled, 0 in effect, 249 most enabled, 0 most in effect
unit-3-1:*************************************************************
17 in use, 20 most used
Cluster:
fwd connections: 1 in use, 5 most used
dir connections: 1 in use, 127 most used
centralized connections: 0 in use, 0 most used
VPN redirect connections: 0 in use, 0 most used
Inspect Snort:
preserve-connection: 0 enabled, 0 in effect, 1 most enabled, 0 most in effect
TCP OUTSIDE 192.168.241.50:80 NP Identity Ifc 192.168.240.50:46276, idle 0:00:02, bytes 0, flags z
TCP OUTSIDE 192.168.241.50:80 INSIDE 192.168.240.50:46278, idle 0:00:06, bytes 0, flags Y
|
Unidade |
Sinalizador |
Nota |
|
Unit-1-1 |
UIO |
· Proprietário do fluxo - A unidade controla o fluxo |
|
Unit-2-1 |
- |
- |
|
Unit-3-1 |
Y |
· Diretor e proprietário do backup - A unidade 3-1 tem a bandeira Y (Diretor). |
Isso pode ser visualizado da seguinte maneira:
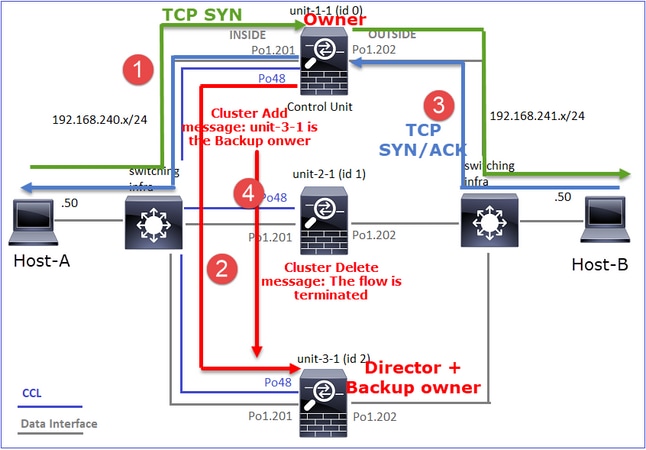
- O pacote TCP SYN chega do Host-A para a unidade 1-1. A unidade 1-1 torna-se o proprietário do fluxo.
- A Unidade 3-1 é eleita o diretor de fluxo. A Unidade-3-1 também é a proprietária do backup (mensagem "cluster add" no UDP 4193 sobre o CCL).
- O pacote TCP SYN/ACK chega do Host-B para a unidade 3-1. O fluxo é simétrico.
- Quando a conexão é encerrada, o proprietário envia pela CCL uma mensagem de "exclusão de cluster" no UDP 4193 para remover as informações de fluxo do proprietário do backup.
Observação 2. A captura com rastreamento mostra que ambas as direções passam somente pela unidade 1-1.
Etapa 1. Use a mesma abordagem do estudo de caso 1 para identificar o fluxo e os pacotes de interesse em todas as unidades de cluster com base na porta de origem:
firepower# cluster exec show cap CAPI | include 46278
unit-1-1(LOCAL):******************************************************
3: 11:01:44.841631 802.1Q vlan#201 P0 192.168.240.50.46278 > 192.168.241.50.80: S 1972783998:1972783998(0) win 29200 <mss 1460,sackOK,timestamp 503529072 0,nop,wscale 7>
4: 11:01:44.842317 802.1Q vlan#201 P0 192.168.241.50.80 > 192.168.240.50.46278: S 3524167695:3524167695(0) ack 1972783999 win 28960 <mss 1380,sackOK,timestamp 513884542 503529072,nop,wscale 7>
5: 11:01:44.842592 802.1Q vlan#201 P0 192.168.240.50.46278 > 192.168.241.50.80: . ack 3524167696 win 229 <nop,nop,timestamp 503529073 513884542>
…
unit-2-1:*************************************************************
unit-3-1:*************************************************************
firepower#
Capturar na interface EXTERNA:
firepower# cluster exec show cap CAPO | include 46278
unit-1-1(LOCAL):******************************************************
3: 11:01:44.841921 802.1Q vlan#202 P0 192.168.240.50.46278 > 192.168.241.50.80: S 2153055699:2153055699(0) win 29200 <mss 1380,sackOK,timestamp 503529072 0,nop,wscale 7>
4: 11:01:44.842226 802.1Q vlan#202 P0 192.168.241.50.80 > 192.168.240.50.46278: S 3382481337:3382481337(0) ack 2153055700 win 28960 <mss 1460,sackOK,timestamp 513884542 503529072,nop,wscale 7>
5: 11:01:44.842638 802.1Q vlan#202 P0 192.168.240.50.46278 > 192.168.241.50.80: . ack 3382481338 win 229 <nop,nop,timestamp 503529073 513884542>
unit-2-1:*************************************************************
unit-3-1:*************************************************************
firepower#
Etapa 2. Focalizar nos pacotes de entrada (TCP SYN e TCP SYN/ACK):
firepower# cluster exec show cap CAPI packet-number 3 trace
unit-1-1(LOCAL):******************************************************
824 packets captured
3: 11:01:44.841631 802.1Q vlan#201 P0 192.168.240.50.46278 > 192.168.241.50.80: S 1972783998:1972783998(0) win 29200 <mss 1460,sackOK,timestamp 503529072 0,nop,wscale 7>
…
Phase: 4
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'INSIDE'
Flow type: NO FLOW
I (0) got initial, attempting ownership.
Phase: 5
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'INSIDE'
Flow type: NO FLOW
I (0) am becoming owner
Rastreie o SYN/ACK na unidade 1-1:
firepower# cluster exec show cap CAPO packet-number 4 trace
unit-1-1(LOCAL):******************************************************
4: 11:01:44.842226 802.1Q vlan#202 P0 192.168.241.50.80 > 192.168.240.50.46278: S 3382481337:3382481337(0) ack 2153055700 win 28960 <mss 1460,sackOK,timestamp 513884542 503529072,nop,wscale 7>
Phase: 3
Type: FLOW-LOOKUP
Subtype:
Result: ALLOW
Config:
Additional Information:
Found flow with id 9583, using existing flow
Observação 3. Os syslogs de plano de dados FTD mostram a criação e o término da conexão no proprietário e no proprietário do backup:
firepower# cluster exec show log | include 46278
unit-1-1(LOCAL):******************************************************
Dec 01 2020 11:01:44: %FTD-6-302013: Built inbound TCP connection 9583 for INSIDE:192.168.240.50/46278 (192.168.240.50/46278) to OUTSIDE:192.168.241.50/80 (192.168.241.50/80)
Dec 01 2020 11:01:53: %FTD-6-302014: Teardown TCP connection 9583 for INSIDE:192.168.240.50/46278 to OUTSIDE:192.168.241.50/80 duration 0:00:08 bytes 1024001808 TCP FINs from INSIDE
unit-2-1:*************************************************************
unit-3-1:*************************************************************
Dec 01 2020 11:01:44: %FTD-6-302022: Built director stub TCP connection for INSIDE:192.168.240.50/46278 (192.168.240.50/46278) to OUTSIDE:192.168.241.50/80 (192.168.241.50/80)
Dec 01 2020 11:01:53: %FTD-6-302023: Teardown director TCP connection for INSIDE:192.168.240.50/46278 to OUTSIDE:192.168.241.50/80 duration 0:00:08 forwarded bytes 0 Cluster flow with CLU closed on owner
Estudo de caso 3. Tráfego assimétrico (o diretor encaminha o tráfego)
Observação 1. As capturas de reinserção/ocultação mostram pacotes nas unidades 1-1 e 2-1 (fluxo assimétrico):
firepower# cluster exec show cap
unit-1-1(LOCAL):******************************************************
capture CCL type raw-data buffer 33554432 interface cluster [Buffer Full - 33554320 bytes]
capture CAPI type raw-data buffer 100000 trace interface INSIDE [Buffer Full - 98552 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPO type raw-data buffer 100000 trace interface OUTSIDE [Buffer Full - 98552 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPI_RH type raw-data reinject-hide buffer 100000 interface INSIDE [Buffer Full - 98552 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPO_RH type raw-data reinject-hide buffer 100000 interface OUTSIDE [Buffer Full - 99932 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
unit-2-1:*************************************************************
capture CCL type raw-data buffer 33554432 interface cluster [Buffer Full - 33553268 bytes]
capture CAPI type raw-data buffer 100000 trace interface INSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPO type raw-data buffer 100000 trace interface OUTSIDE [Buffer Full - 99052 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPI_RH type raw-data reinject-hide buffer 100000 interface INSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPO_RH type raw-data reinject-hide buffer 100000 interface OUTSIDE [Buffer Full - 99052 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
unit-3-1:*************************************************************
capture CCL type raw-data buffer 33554432 interface cluster [Capturing - 53815 bytes]
capture CAPI type raw-data buffer 100000 trace interface INSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPO type raw-data buffer 100000 trace interface OUTSIDE [Capturing - 658 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPI_RH type raw-data reinject-hide buffer 100000 interface INSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPO_RH type raw-data reinject-hide buffer 100000 interface OUTSIDE [Capturing - 658 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
Observação 2. Análise de flag de conexão para fluxo com porta origem 46502.
firepower# cluster exec show conn
unit-1-1(LOCAL):******************************************************
23 in use, 25 most used
Cluster:
fwd connections: 0 in use, 1 most used
dir connections: 0 in use, 122 most used
centralized connections: 0 in use, 0 most used
VPN redirect connections: 0 in use, 0 most used
Inspect Snort:
preserve-connection: 2 enabled, 0 in effect, 4 most enabled, 1 most in effect
TCP OUTSIDE 192.168.241.50:80 INSIDE 192.168.240.50:46502, idle 0:00:00, bytes 448760236, flags UIO N1
TCP OUTSIDE 192.168.241.50:80 INSIDE 192.168.240.50:46500, idle 0:00:06, bytes 0, flags aA N1
unit-2-1:*************************************************************
21 in use, 271 most used
Cluster:
fwd connections: 0 in use, 2 most used
dir connections: 1 in use, 2 most used
centralized connections: 0 in use, 0 most used
VPN redirect connections: 0 in use, 0 most used
Inspect Snort:
preserve-connection: 0 enabled, 0 in effect, 249 most enabled, 0 most in effect
TCP OUTSIDE 192.168.241.50:80 INSIDE 192.168.240.50:46502, idle 0:00:00, bytes 0, flags Y
unit-3-1:*************************************************************
17 in use, 20 most used
Cluster:
fwd connections: 1 in use, 5 most used
dir connections: 0 in use, 127 most used
centralized connections: 0 in use, 0 most used
VPN redirect connections: 0 in use, 0 most used
Inspect Snort:
preserve-connection: 0 enabled, 0 in effect, 1 most enabled, 0 most in effect
|
Unidade |
Sinalizador |
Nota |
|
Unit-1-1 |
UIO |
· Proprietário do fluxo - A unidade controla o fluxo. |
|
Unit-2-1 |
Y |
· Diretor - Como a unidade 2-1 tem a flag ‘Y’, isso implica que a unidade 2-1 foi escolhida como o diretor para esse fluxo. · Proprietário do backup · Finalmente, embora não seja óbvio a partir dessa saída, a partir das saídas show capture e show log é evidente que a unidade 2-1 encaminha esse fluxo para o proprietário (embora tecnicamente não seja considerado um encaminhador nesse cenário). Note: Uma unidade não pode ser direcionadora (fluxo Y) e encaminhadora (fluxo z), essas duas funções são mutuamente exclusivas. Os diretors (fluxo Y) ainda podem encaminhar o tráfego. Consulte a saída do comando show log posteriormente neste estudo de caso. |
|
Unit-3-1 |
- |
- |
Isso pode ser visualizado da seguinte maneira:
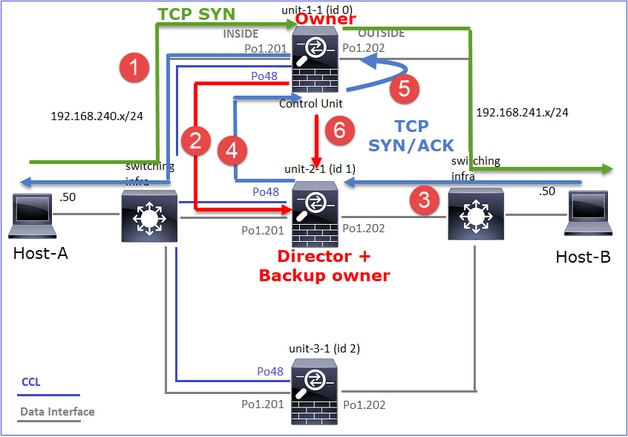
- O pacote TCP SYN chega do Host-A para a unidade 1-1. A unidade 1-1 torna-se o proprietário do fluxo.
- A unidade 2-1 é eleita o diretor de fluxo e o proprietário do backup. O proprietário do fluxo envia uma mensagem unicast "cluster add" no UDP 4193 para informar o proprietário do backup sobre o fluxo.
- O pacote TCP SYN/ACK chega do Host-B para a unidade 2-1. O fluxo é assimétrico.
- A Unidade 2-1 encaminha o pacote por meio do CCL para o proprietário (devido ao Cookie TCP SYN).
- O proprietário injeta novamente o pacote na interface OUTSIDE e depois encaminha o pacote para o Host-A.
- Quando a conexão é encerrada, o proprietário envia uma mensagem de exclusão de cluster para remover as informações de fluxo do proprietário do backup.
Observação 3. Capture with trace mostra o tráfego assimétrico e o redirecionamento da unidade 2-1 para a unidade 1-1.
Etapa 1. Identificar os pacotes que pertencem ao fluxo de interesse (porta 46502):
firepower# cluster exec show capture CAPI | include 46502
unit-1-1(LOCAL):******************************************************
3: 12:58:33.356121 802.1Q vlan#201 P0 192.168.240.50.46502 > 192.168.241.50.80: S 4124514680:4124514680(0) win 29200 <mss 1460,sackOK,timestamp 510537534 0,nop,wscale 7>
4: 12:58:33.357037 802.1Q vlan#201 P0 192.168.241.50.80 > 192.168.240.50.46502: S 883000451:883000451(0) ack 4124514681 win 28960 <mss 1380,sackOK,timestamp 520893004 510537534,nop,wscale 7>
5: 12:58:33.357357 802.1Q vlan#201 P0 192.168.240.50.46502 > 192.168.241.50.80: . ack 883000452 win 229 <nop,nop,timestamp 510537536 520893004>
unit-2-1:*************************************************************
unit-3-1:*************************************************************
A direção de retorno:
firepower# cluster exec show capture CAPO | include 46502
unit-1-1(LOCAL):******************************************************
3: 12:58:33.356426 802.1Q vlan#202 P0 192.168.240.50.46502 > 192.168.241.50.80: S 1434968587:1434968587(0) win 29200 <mss 1380,sackOK,timestamp 510537534 0,nop,wscale 7>
4: 12:58:33.356915 802.1Q vlan#202 P0 192.168.241.50.80 > 192.168.240.50.46502: S 4257314722:4257314722(0) ack 1434968588 win 28960 <mss 1460,sackOK,timestamp 520893004 510537534,nop,wscale 7>
5: 12:58:33.357403 802.1Q vlan#202 P0 192.168.240.50.46502 > 192.168.241.50.80: . ack 4257314723 win 229 <nop,nop,timestamp 510537536 520893004>
unit-2-1:*************************************************************
1: 12:58:33.359249 802.1Q vlan#202 P0 192.168.241.50.80 > 192.168.240.50.46502: S 4257314722:4257314722(0) ack 1434968588 win 28960 <mss 1460,sackOK,timestamp 520893004 510537534,nop,wscale 7>
2: 12:58:33.360302 802.1Q vlan#202 P0 192.168.241.50.80 > 192.168.240.50.46502: . ack 1434968736 win 235 <nop,nop,timestamp 520893005 510537536>
3: 12:58:33.361004 802.1Q vlan#202 P0 192.168.241.50.80 > 192.168.240.50.46502: . 4257314723:4257316091(1368) ack 1434968736 win 235 <nop,nop,timestamp 520893006 510537536>
…
unit-3-1:*************************************************************
Etapa 2. Rastrear os pacotes. Por padrão, somente os primeiros 50 pacotes de entrada são rastreados. Para simplificar, as fases de rastreamento não relevantes são omitidas.
Unidade 1-1 (Proprietário)
firepower# cluster exec show capture CAPI packet-number 3 trace
unit-1-1(LOCAL):******************************************************
3: 12:58:33.356121 802.1Q vlan#201 P0 192.168.240.50.46502 > 192.168.241.50.80: S 4124514680:4124514680(0) win 29200 <mss 1460,sackOK,timestamp 510537534 0,nop,wscale 7>
...
Phase: 4
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'INSIDE'
Flow type: NO FLOW
I (0) got initial, attempting ownership.
Phase: 5
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'INSIDE'
Flow type: NO FLOW
I (0) am becoming owner
Unidade 2-1 (Encaminhador)
O tráfego de retorno (TCP SYN/ACK) A unidade de interesse é a unidade 2-1, que é a proprietária do direcionador/backup e encaminha o tráfego para a proprietária:
firepower# cluster exec unit unit-2-1 show capture CAPO packet-number 1 trace
1: 12:58:33.359249 802.1Q vlan#202 P0 192.168.241.50.80 > 192.168.240.50.46502: S 4257314722:4257314722(0) ack 1434968588 win 28960 <mss 1460,sackOK,timestamp 520893004 510537534,nop,wscale 7>
...
Phase: 4
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'OUTSIDE'
Flow type: NO FLOW
I (1) got initial, attempting ownership.
Phase: 5
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'OUTSIDE'
Flow type: NO FLOW
I (1) am early redirecting to (0) due to matching action (-1).
Observação 4. Os syslogs de plano de dados FTD mostram a criação e o término da conexão em todas as unidades:
firepower# cluster exec show log | i 46502
unit-1-1(LOCAL):******************************************************
Dec 01 2020 12:58:33: %FTD-6-302013: Built inbound TCP connection 9742 for INSIDE:192.168.240.50/46502 (192.168.240.50/46502) to OUTSIDE:192.168.241.50/80 (192.168.241.50/80)
Dec 01 2020 12:59:02: %FTD-6-302014: Teardown TCP connection 9742 for INSIDE:192.168.240.50/46502 to OUTSIDE:192.168.241.50/80 duration 0:00:28 bytes 2048000440 TCP FINs from INSIDE
unit-2-1:*************************************************************
Dec 01 2020 12:58:33: %FTD-6-302022: Built forwarder stub TCP connection for OUTSIDE:192.168.241.50/80 (192.168.241.50/80) to unknown:192.168.240.50/46502 (192.168.240.50/46502)
Dec 01 2020 12:58:33: %FTD-6-302023: Teardown forwarder TCP connection for OUTSIDE:192.168.241.50/80 to unknown:192.168.240.50/46502 duration 0:00:00 forwarded bytes 0 Forwarding or redirect flow removed to create director or backup flow
Dec 01 2020 12:58:33: %FTD-6-302022: Built director stub TCP connection for INSIDE:192.168.240.50/46502 (192.168.240.50/46502) to OUTSIDE:192.168.241.50/80 (192.168.241.50/80)
Dec 01 2020 12:59:02: %FTD-6-302023: Teardown director TCP connection for INSIDE:192.168.240.50/46502 to OUTSIDE:192.168.241.50/80 duration 0:00:28 forwarded bytes 2048316300 Cluster flow with CLU closed on owner
unit-3-1:*************************************************************
firepower#
Estudo de caso 4. Tráfego assimétrico (o proprietário é o diretor)
Observação 1. As capturas de reinserção/ocultação mostram pacotes nas unidades 1-1 e 2-1 (fluxo assimétrico):
firepower# cluster exec show cap
unit-1-1(LOCAL):******************************************************
capture CCL type raw-data buffer 33554432 interface cluster [Buffer Full - 33554229 bytes]
capture CAPI type raw-data buffer 100000 trace interface INSIDE [Buffer Full - 98974 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPO type raw-data buffer 100000 trace interface OUTSIDE [Buffer Full - 98974 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPI_RH type raw-data reinject-hide buffer 100000 interface INSIDE [Buffer Full - 98974 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPO_RH type raw-data reinject-hide buffer 100000 interface OUTSIDE [Buffer Full - 99924 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
unit-2-1:*************************************************************
capture CCL type raw-data buffer 33554432 interface cluster [Buffer Full - 33552925 bytes]
capture CAPI type raw-data buffer 100000 trace interface INSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPO type raw-data buffer 100000 trace interface OUTSIDE [Buffer Full - 99052 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPI_RH type raw-data reinject-hide buffer 100000 interface INSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPO_RH type raw-data reinject-hide buffer 100000 interface OUTSIDE [Buffer Full - 99052 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
unit-3-1:*************************************************************
capture CCL type raw-data buffer 33554432 interface cluster [Capturing - 227690 bytes]
capture CAPI type raw-data buffer 100000 trace interface INSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPO type raw-data buffer 100000 trace interface OUTSIDE [Capturing - 4754 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPI_RH type raw-data reinject-hide buffer 100000 interface INSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPO_RH type raw-data reinject-hide buffer 100000 interface OUTSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
Observação 2. Análise de flag de conexão para fluxo com porta origem 46916.
firepower# cluster exec show conn
unit-1-1(LOCAL):******************************************************
23 in use, 25 most used
Cluster:
fwd connections: 0 in use, 1 most used
dir connections: 0 in use, 122 most used
centralized connections: 0 in use, 0 most used
VPN redirect connections: 0 in use, 0 most used
Inspect Snort:
preserve-connection: 1 enabled, 0 in effect, 4 most enabled, 1 most in effect
TCP OUTSIDE 192.168.241.50:80 INSIDE 192.168.240.50:46916, idle 0:00:00, bytes 414682616, flags UIO N1
unit-2-1:*************************************************************
21 in use, 271 most used
Cluster:
fwd connections: 1 in use, 2 most used
dir connections: 0 in use, 2 most used
centralized connections: 0 in use, 0 most used
VPN redirect connections: 0 in use, 0 most used
Inspect Snort:
preserve-connection: 0 enabled, 0 in effect, 249 most enabled, 0 most in effect
TCP OUTSIDE 192.168.241.50:80 NP Identity Ifc 192.168.240.50:46916, idle 0:00:00, bytes 0, flags z
unit-3-1:*************************************************************
17 in use, 20 most used
Cluster:
fwd connections: 0 in use, 5 most used
dir connections: 1 in use, 127 most used
centralized connections: 0 in use, 0 most used
VPN redirect connections: 0 in use, 0 most used
Inspect Snort:
preserve-connection: 0 enabled, 0 in effect, 1 most enabled, 0 most in effect
TCP OUTSIDE 192.168.241.50:80 INSIDE 192.168.240.50:46916, idle 0:00:04, bytes 0, flags y
|
Unidade |
Sinalizador |
Nota |
|
Unit-1-1 |
UIO |
· Proprietário do fluxo - A unidade controla o fluxo · Diretor - Como a unidade 3-1 tem "y" e não "Y", isso implica que a unidade 1-1 foi escolhida como o diretor para esse fluxo. Assim, como também é o proprietário, outra unidade (unidade 3-1 neste caso) foi eleita como o proprietário de backup |
|
Unit-2-1 |
z |
· Encaminhador |
|
Unit-3-1 |
y |
- Proprietário do backup |
Isso pode ser visualizado da seguinte maneira:
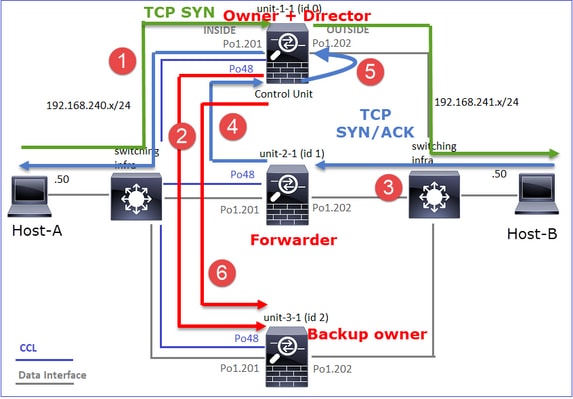
- O pacote TCP SYN chega do Host-A para a unidade 1-1. A unidade 1-1 torna-se o proprietário do fluxo e é eleita como direcionador.
- A Unidade 3-1 é eleita como um proprietário de backup. O proprietário do fluxo envia uma mensagem unicast "cluster add" no UDP 4193 para informar o proprietário do backup sobre o fluxo.
- O pacote TCP SYN/ACK chega do Host-B para a unidade 2-1. O fluxo é assimétrico.
- A Unidade 2-1 encaminha o pacote por meio do CCL para o proprietário (devido ao Cookie TCP SYN).
- O proprietário injeta novamente o pacote na interface OUTSIDE e depois encaminha o pacote para o Host-A.
- Quando a conexão é encerrada, o proprietário envia uma mensagem de exclusão de cluster para remover as informações de fluxo do proprietário do backup.
Observação 3. Capture with trace mostra o tráfego assimétrico e o redirecionamento da unidade 2-1 para a unidade 1-1.
Unidade 2-1 (encaminhador):
firepower# cluster exec unit unit-2-1 show capture CAPO packet-number 1 trace
1: 16:11:33.653164 802.1Q vlan#202 P0 192.168.241.50.80 > 192.168.240.50.46916: S 1331019196:1331019196(0) ack 3089755618 win 28960 <mss 1460,sackOK,timestamp 532473211 522117741,nop,wscale 7>
...
Phase: 4
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'OUTSIDE'
Flow type: NO FLOW
I (1) got initial, attempting ownership.
Phase: 5
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'OUTSIDE'
Flow type: NO FLOW
I (1) am early redirecting to (0) due to matching action (-1).
Observação 4. Os syslogs de plano de dados FTD mostram a criação e o término da conexão em todas as unidades:
- Unidade-1-1 (proprietário)
- Unidade 2-1 (encaminhador)
- Unidade 3-1 (proprietário do backup)
firepower# cluster exec show log | i 46916
unit-1-1(LOCAL):******************************************************
Dec 01 2020 16:11:33: %FTD-6-302013: Built inbound TCP connection 10023 for INSIDE:192.168.240.50/46916 (192.168.240.50/46916) to OUTSIDE:192.168.241.50/80 (192.168.241.50/80)
Dec 01 2020 16:11:42: %FTD-6-302014: Teardown TCP connection 10023 for INSIDE:192.168.240.50/46916 to OUTSIDE:192.168.241.50/80 duration 0:00:09 bytes 1024010016 TCP FINs from INSIDE
unit-2-1:*************************************************************
Dec 01 2020 16:11:33: %FTD-6-302022: Built forwarder stub TCP connection for OUTSIDE:192.168.241.50/80 (192.168.241.50/80) to unknown:192.168.240.50/46916 (192.168.240.50/46916)
Dec 01 2020 16:11:42: %FTD-6-302023: Teardown forwarder TCP connection for OUTSIDE:192.168.241.50/80 to unknown:192.168.240.50/46916 duration 0:00:09 forwarded bytes 1024009868 Cluster flow with CLU closed on owner
unit-3-1:*************************************************************
Dec 01 2020 16:11:33: %FTD-6-302022: Built backup stub TCP connection for INSIDE:192.168.240.50/46916 (192.168.240.50/46916) to OUTSIDE:192.168.241.50/80 (192.168.241.50/80)
Dec 01 2020 16:11:42: %FTD-6-302023: Teardown backup TCP connection for INSIDE:192.168.240.50/46916 to OUTSIDE:192.168.241.50/80 duration 0:00:09 forwarded bytes 0 Cluster flow with CLU closed on owner
Estudo de caso 5. Tráfego assimétrico (o proprietário é diferente do diretor)
Observação 1. As capturas de reinserção/ocultação mostram pacotes nas unidades 1-1 e 2-1 (fluxo assimétrico):
firepower# cluster exec show cap
unit-1-1(LOCAL):******************************************************
capture CCL type raw-data buffer 33554432 interface cluster [Buffer Full - 33553207 bytes]
capture CAPI type raw-data buffer 100000 trace interface INSIDE [Buffer Full - 99396 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPO type raw-data buffer 100000 trace interface OUTSIDE [Buffer Full - 99224 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPI_RH type raw-data reinject-hide buffer 100000 interface INSIDE [Buffer Full - 99396 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPO_RH type raw-data reinject-hide buffer 100000 interface OUTSIDE [Buffer Full - 99928 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
unit-2-1:*************************************************************
capture CCL type raw-data buffer 33554432 interface cluster [Buffer Full - 33554251 bytes]
capture CAPI type raw-data buffer 100000 trace interface INSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPO type raw-data buffer 100000 trace interface OUTSIDE [Buffer Full - 99052 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPI_RH type raw-data reinject-hide buffer 100000 interface INSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPO_RH type raw-data reinject-hide buffer 100000 interface OUTSIDE [Buffer Full - 99052 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
unit-3-1:*************************************************************
capture CCL type raw-data buffer 33554432 interface cluster [Capturing - 131925 bytes]
capture CAPI type raw-data buffer 100000 trace interface INSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPO type raw-data buffer 100000 trace interface OUTSIDE [Capturing - 2592 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPI_RH type raw-data reinject-hide buffer 100000 interface INSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
capture CAPO_RH type raw-data reinject-hide buffer 100000 interface OUTSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.241.50 eq www
Observação 2. Análise de flag de conexão para fluxo com porta origem 4694:
firepower# cluster exec show conn
unit-1-1(LOCAL):******************************************************
23 in use, 25 most used
Cluster:
fwd connections: 0 in use, 1 most used
dir connections: 0 in use, 122 most used
centralized connections: 0 in use, 0 most used
VPN redirect connections: 0 in use, 0 most used
Inspect Snort:
preserve-connection: 1 enabled, 0 in effect, 4 most enabled, 1 most in effect
TCP OUTSIDE 192.168.241.50:80 INSIDE 192.168.240.50:46994, idle 0:00:00, bytes 406028640, flags UIO N1
unit-2-1:*************************************************************
22 in use, 271 most used
Cluster:
fwd connections: 1 in use, 2 most used
dir connections: 0 in use, 2 most used
centralized connections: 0 in use, 0 most used
VPN redirect connections: 0 in use, 0 most used
Inspect Snort:
preserve-connection: 0 enabled, 0 in effect, 249 most enabled, 0 most in effect
TCP OUTSIDE 192.168.241.50:80 NP Identity Ifc 192.168.240.50:46994, idle 0:00:00, bytes 0, flags z
unit-3-1:*************************************************************
17 in use, 20 most used
Cluster:
fwd connections: 2 in use, 5 most used
dir connections: 1 in use, 127 most used
centralized connections: 0 in use, 0 most used
VPN redirect connections: 0 in use, 0 most used
Inspect Snort:
preserve-connection: 0 enabled, 0 in effect, 1 most enabled, 0 most in effect
TCP OUTSIDE 192.168.241.50:80 INSIDE 192.168.240.50:46994, idle 0:00:05, bytes 0, flags Y
|
Unidade |
Sinalizador |
Nota |
|
Unit-1-1 |
UIO |
· Proprietário do fluxo - A unidade controla o fluxo |
|
Unit-2-1 |
z |
· Encaminhador |
|
Unit-3-1 |
Y |
· Proprietário do backup ·Director |
Isso pode ser visualizado da seguinte maneira:
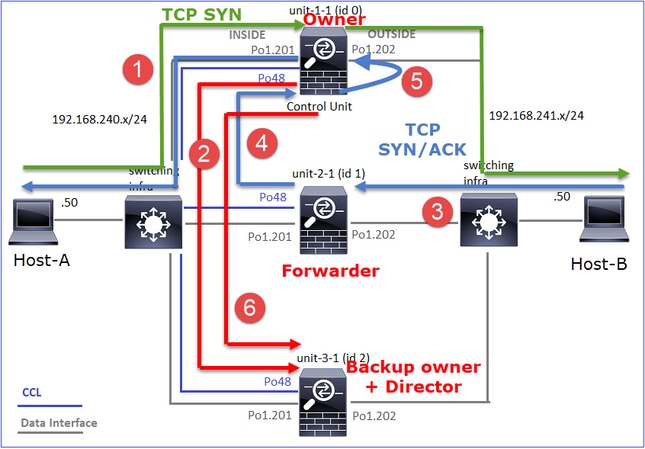
- O pacote TCP SYN chega do Host-A para a unidade 1-1. A unidade 1-1 torna-se o proprietário do fluxo.
- A Unidade 3-1 é eleita como direcionadora e proprietária de backup. O proprietário do fluxo envia uma mensagem unicast "cluster add" no UDP 4193 para informar o proprietário do backup sobre o fluxo.
- O pacote TCP SYN/ACK chega do Host-B para a unidade 2-1. O fluxo é assimétrico
- A Unidade 2-1 encaminha o pacote por meio do CCL para o proprietário (devido ao Cookie TCP SYN).
- O proprietário injeta novamente o pacote na interface OUTSIDE e depois encaminha o pacote para o Host-A.
- Quando a conexão é encerrada, o proprietário envia uma mensagem de exclusão de cluster para remover as informações de fluxo do proprietário do backup.
Observação 3. Capture with trace mostra o tráfego assimétrico e o redirecionamento da unidade 2-1 para a unidade 1-1.
Unidade-1-1 (proprietário):
firepower# cluster exec show cap CAPI packet-number 1 trace
unit-1-1(LOCAL):******************************************************
…
Phase: 4
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'INSIDE'
Flow type: NO FLOW
I (0) got initial, attempting ownership.
Phase: 5
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'INSIDE'
Flow type: NO FLOW
I (0) am becoming owner
Unidade 2-1 (encaminhador):
firepower# cluster exec unit unit-2-1 show cap CAPO packet-number 1 trace
1: 16:46:44.232074 802.1Q vlan#202 P0 192.168.241.50.80 > 192.168.240.50.46994: S 2863659376:2863659376(0) ack 2879616990 win 28960 <mss 1460,sackOK,timestamp 534583774 524228304,nop,wscale 7>
…
Phase: 4
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'OUTSIDE'
Flow type: NO FLOW
I (1) got initial, attempting ownership.
Phase: 5
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'OUTSIDE'
Flow type: NO FLOW
I (1) am early redirecting to (0) due to matching action (-1).
Observação 4. Os syslogs de plano de dados FTD mostram a criação e o término da conexão em todas as unidades:
- Unidade-1-1 (proprietário)
- Unidade 2-1 (encaminhador)
- Unidade 3-1 (proprietário/diretor de backup)
firepower# cluster exec show log | i 46994
unit-1-1(LOCAL):******************************************************
Dec 01 2020 16:46:44: %FTD-6-302013: Built inbound TCP connection 10080 for INSIDE:192.168.240.50/46994 (192.168.240.50/46994) to OUTSIDE:192.168.241.50/80 (192.168.241.50/80)
Dec 01 2020 16:46:53: %FTD-6-302014: Teardown TCP connection 10080 for INSIDE:192.168.240.50/46994 to OUTSIDE:192.168.241.50/80 duration 0:00:09 bytes 1024000440 TCP FINs from INSIDE
unit-2-1:*************************************************************
Dec 01 2020 16:46:44: %FTD-6-302022: Built forwarder stub TCP connection for OUTSIDE:192.168.241.50/80 (192.168.241.50/80) to unknown:192.168.240.50/46994 (192.168.240.50/46994)
Dec 01 2020 16:46:53: %FTD-6-302023: Teardown forwarder TCP connection for OUTSIDE:192.168.241.50/80 to unknown:192.168.240.50/46994 duration 0:00:09 forwarded bytes 1024000292 Cluster flow with CLU closed on owner
unit-3-1:*************************************************************
Dec 01 2020 16:46:44: %FTD-6-302022: Built director stub TCP connection for INSIDE:192.168.240.50/46994 (192.168.240.50/46994) to OUTSIDE:192.168.241.50/80 (192.168.241.50/80)
Dec 01 2020 16:46:53: %FTD-6-302023: Teardown director TCP connection for INSIDE:192.168.240.50/46994 to OUTSIDE:192.168.241.50/80 duration 0:00:09 forwarded bytes 0 Cluster flow with CLU closed on owner
Para os próximos estudos de caso, a topologia usada é baseada em um cluster com conjuntos em linha:
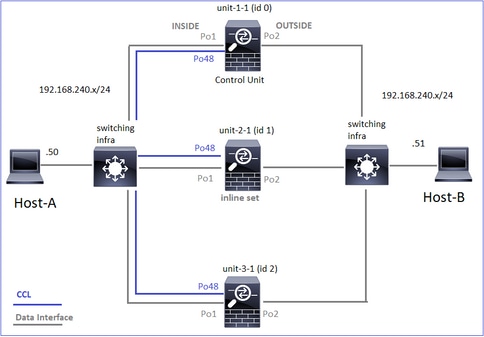
Estudo de caso 6. Tráfego assimétrico (em linha, o proprietário é o diretor)
Observação 1. As capturas de reinserção/ocultação mostram pacotes nas unidades 1-1 e 2-1 (fluxo assimétrico). Além disso, o proprietário é a unidade 2-1 (há pacotes dentro e fora dela). Interfaces para as capturas reject-hide, enquanto a unidade 1-1 tem apenas FORA):
firepower# cluster exec show cap
unit-1-1(LOCAL):******************************************************
capture CCL type raw-data buffer 33554432 interface cluster [Buffer Full - 33553253 bytes]
capture CAPO type raw-data trace interface OUTSIDE [Buffer Full - 523432 bytes]
match tcp host 192.168.240.50 host 192.168.240.51 eq www
capture CAPI type raw-data trace interface INSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.240.51 eq www
capture CAPO_RH type raw-data reinject-hide interface OUTSIDE [Buffer Full - 523432 bytes]
match tcp host 192.168.240.50 host 192.168.240.51 eq www
capture CAPI_RH type raw-data reinject-hide interface INSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.240.51 eq www
unit-2-1:*************************************************************
capture CCL type raw-data buffer 33554432 interface cluster [Buffer Full - 33554312 bytes]
capture CAPO type raw-data trace interface OUTSIDE [Buffer Full - 523782 bytes]
match tcp host 192.168.240.50 host 192.168.240.51 eq www
capture CAPI type raw-data trace interface INSIDE [Buffer Full - 523782 bytes]
match tcp host 192.168.240.50 host 192.168.240.51 eq www
capture CAPO_RH type raw-data reinject-hide interface OUTSIDE [Buffer Full - 524218 bytes]
match tcp host 192.168.240.50 host 192.168.240.51 eq www
capture CAPI_RH type raw-data reinject-hide interface INSIDE [Buffer Full - 523782 bytes]
match tcp host 192.168.240.50 host 192.168.240.51 eq www
unit-3-1:*************************************************************
capture CCL type raw-data buffer 33554432 interface cluster [Capturing - 53118 bytes]
capture CAPO type raw-data trace interface OUTSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.240.51 eq www
capture CAPI type raw-data trace interface INSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.240.51 eq www
capture CAPO_RH type raw-data reinject-hide interface OUTSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.240.51 eq www
capture CAPI_RH type raw-data reinject-hide interface INSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.240.51 eq www
Observação 2. Análise de flag de conexão para fluxo com porta origem 51844.
firepower# cluster exec show conn addr 192.168.240.51
unit-1-1(LOCAL):******************************************************
30 in use, 102 most used
Cluster:
fwd connections: 1 in use, 1 most used
dir connections: 2 in use, 122 most used
centralized connections: 3 in use, 39 most used
VPN redirect connections: 0 in use, 0 most used
Inspect Snort:
preserve-connection: 0 enabled, 0 in effect, 4 most enabled, 1 most in effect
TCP OUTSIDE 192.168.240.51:80 NP Identity Ifc 192.168.240.50:51844, idle 0:00:00, bytes 0, flags z
unit-2-1:*************************************************************
23 in use, 271 most used
Cluster:
fwd connections: 0 in use, 2 most used
dir connections: 4 in use, 26 most used
centralized connections: 0 in use, 14 most used
VPN redirect connections: 0 in use, 0 most used
Inspect Snort:
preserve-connection: 0 enabled, 0 in effect, 249 most enabled, 0 most in effect
TCP OUTSIDE 192.168.240.51:80 INSIDE 192.168.240.50:51844, idle 0:00:00, bytes 231214400, flags b N
unit-3-1:*************************************************************
20 in use, 55 most used
Cluster:
fwd connections: 0 in use, 5 most used
dir connections: 1 in use, 127 most used
centralized connections: 0 in use, 24 most used
VPN redirect connections: 0 in use, 0 most used
Inspect Snort:
preserve-connection: 0 enabled, 0 in effect, 1 most enabled, 0 most in effect
TCP OUTSIDE 192.168.240.51:80 INSIDE 192.168.240.50:51844, idle 0:00:01, bytes 0, flags y
|
Unidade |
Sinalizador |
Nota |
|
Unit-1-1 |
z |
· Encaminhador |
|
Unit-2-1 |
b N |
· Proprietário do fluxo - A unidade controla o fluxo |
|
Unit-3-1 |
y |
· Proprietário do backup |
Isso pode ser visualizado da seguinte maneira:
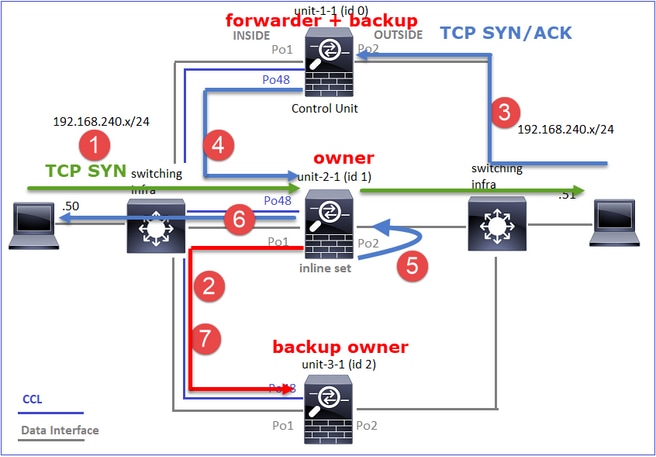
- O pacote TCP SYN chega do Host-A para a unidade 2-1. A unidade 2-1 torna-se o proprietário do fluxo e é eleita como direcionador.
- A Unidade 3-1 é escolhida como a proprietária do backup. O proprietário do fluxo envia uma mensagem unicast "cluster add" no UDP 4193 para informar o proprietário do backup sobre o fluxo.
- O pacote TCP SYN/ACK chega do Host-B para a unidade 1-1. O fluxo é assimétrico.
- A unidade 1-1 encaminha o pacote através da CCL para o direcionador (unidade 2-1).
- A Unidade 2-1 também é a proprietária e injeta novamente o pacote na interface EXTERNA.
- A unidade 2-1 encaminha o pacote para o host A.
- Quando a conexão é encerrada, o proprietário envia uma mensagem de exclusão de cluster para remover as informações de fluxo do proprietário do backup.
Observação 3. Capture with trace mostra o tráfego assimétrico e o redirecionamento da unidade 1-1 para a unidade 2-1.
Unidade-2-1 (proprietário/diretor):
firepower# cluster exec unit unit-2-1 show cap CAPI packet-number 1 trace
1: 18:10:12.842912 192.168.240.50.51844 > 192.168.240.51.80: S 4082593463:4082593463(0) win 29200 <mss 1460,sackOK,timestamp 76258053 0,nop,wscale 7>
Phase: 1
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'INSIDE'
Flow type: NO FLOW
I (1) got initial, attempting ownership.
Phase: 2
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'INSIDE'
Flow type: NO FLOW
I (1) am becoming owner
Unidade 1-1 (encaminhador):
firepower# cluster exec show cap CAPO packet-number 1 trace
unit-1-1(LOCAL):******************************************************
1: 18:10:12.842317 192.168.240.51.80 > 192.168.240.50.51844: S 2339579109:2339579109(0) ack 4082593464 win 28960 <mss 1460,sackOK,timestamp 513139467 76258053,nop,wscale 7>
Phase: 1
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'OUTSIDE'
Flow type: NO FLOW
I (0) am asking director (1).
Tráfego de retorno (TCP SYN/ACK)
Unidade-2-1 (proprietário/diretor):
firepower# cluster exec unit unit-2-1 show cap CAPO packet-number 2 trace
2: 18:10:12.843660 192.168.240.51.80 > 192.168.240.50.51844: S 2339579109:2339579109(0) ack 4082593464 win 28960 <mss 1460,sackOK,timestamp 513139467 76258053,nop,wscale 7>
Phase: 1
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'OUTSIDE'
Flow type: FULL
I (1) am owner, update sender (0).
Phase: 2
Type: FLOW-LOOKUP
Subtype:
Result: ALLOW
Config:
Additional Information:
Found flow with id 7109, using existing flow
Observação 4. Os syslogs de plano de dados FTD mostram a criação e o término da conexão em todas as unidades:
- Unidade-1-1 (proprietário)
- Unidade 2-1 (encaminhador)
- Unidade 3-1 (proprietário/diretor de backup)
firepower# cluster exec show log | include 51844
unit-1-1(LOCAL):******************************************************
Dec 02 2020 18:10:12: %FTD-6-302022: Built forwarder stub TCP connection for OUTSIDE:192.168.240.51/80 (192.168.240.51/80) to unknown:192.168.240.50/51844 (192.168.240.50/51844)
Dec 02 2020 18:10:22: %FTD-6-302023: Teardown forwarder TCP connection for OUTSIDE:192.168.240.51/80 to unknown:192.168.240.50/51844 duration 0:00:09 forwarded bytes 1024001740 Cluster flow with CLU closed on owner
unit-2-1:*************************************************************
Dec 02 2020 18:10:12: %FTD-6-302303: Built TCP state-bypass connection 7109 from INSIDE:192.168.240.50/51844 (192.168.240.50/51844) to OUTSIDE:192.168.240.51/80 (192.168.240.51/80)
Dec 02 2020 18:10:22: %FTD-6-302304: Teardown TCP state-bypass connection 7109 from INSIDE:192.168.240.50/51844 to OUTSIDE:192.168.240.51/80 duration 0:00:09 bytes 1024001888 TCP FINs
unit-3-1:*************************************************************
Dec 02 2020 18:10:12: %FTD-6-302022: Built backup stub TCP connection for INSIDE:192.168.240.50/51844 (192.168.240.50/51844) to OUTSIDE:192.168.240.51/80 (192.168.240.51/80)
Dec 02 2020 18:10:22: %FTD-6-302023: Teardown backup TCP connection for INSIDE:192.168.240.50/51844 to OUTSIDE:192.168.240.51/80 duration 0:00:09 forwarded bytes 0 Cluster flow with CLU closed on owner
Estudo de caso 7. Tráfego assimétrico (em linha, o proprietário é diferente do diretor)
O proprietário é a unidade 2-1 (há pacotes nas interfaces INSIDE e OUTSIDE para as capturas de reinserção/ocultação, enquanto a unidade 3-1 tem apenas no OUTSIDE):
firepower# cluster exec show cap
unit-1-1(LOCAL):******************************************************
capture CCL type raw-data buffer 33554432 interface cluster [Capturing - 13902 bytes]
capture CAPO type raw-data trace interface OUTSIDE [Capturing - 90 bytes]
match tcp host 192.168.240.50 host 192.168.240.51 eq www
capture CAPI type raw-data trace interface INSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.240.51 eq www
capture CAPO_RH type raw-data reinject-hide interface OUTSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.240.51 eq www
capture CAPI_RH type raw-data reinject-hide interface INSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.240.51 eq www
unit-2-1:*************************************************************
capture CCL type raw-data buffer 33554432 interface cluster [Buffer Full - 33553936 bytes]
capture CAPO type raw-data trace interface OUTSIDE [Buffer Full - 523126 bytes]
match tcp host 192.168.240.50 host 192.168.240.51 eq www
capture CAPI type raw-data trace interface INSIDE [Buffer Full - 523126 bytes]
match tcp host 192.168.240.50 host 192.168.240.51 eq www
capture CAPO_RH type raw-data reinject-hide interface OUTSIDE [Buffer Full - 524230 bytes]
match tcp host 192.168.240.50 host 192.168.240.51 eq www
capture CAPI_RH type raw-data reinject-hide interface INSIDE [Buffer Full - 523126 bytes]
match tcp host 192.168.240.50 host 192.168.240.51 eq www
unit-3-1:*************************************************************
capture CCL type raw-data buffer 33554432 interface cluster [Buffer Full - 33553566 bytes]
capture CAPO type raw-data trace interface OUTSIDE [Buffer Full - 523522 bytes]
match tcp host 192.168.240.50 host 192.168.240.51 eq www
capture CAPI type raw-data trace interface INSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.240.51 eq www
capture CAPO_RH type raw-data reinject-hide interface OUTSIDE [Buffer Full - 523432 bytes]
match tcp host 192.168.240.50 host 192.168.240.51 eq www
capture CAPI_RH type raw-data reinject-hide interface INSIDE [Capturing - 0 bytes]
match tcp host 192.168.240.50 host 192.168.240.51 eq www
Observação 2. Análise de flag de conexão para fluxo com porta origem 59210.
firepower# cluster exec show conn addr 192.168.240.51
unit-1-1(LOCAL):******************************************************
25 in use, 102 most used
Cluster:
fwd connections: 0 in use, 1 most used
dir connections: 2 in use, 122 most used
centralized connections: 0 in use, 39 most used
VPN redirect connections: 0 in use, 0 most used
Inspect Snort:
preserve-connection: 0 enabled, 0 in effect, 4 most enabled, 1 most in effect
TCP OUTSIDE 192.168.240.51:80 INSIDE 192.168.240.50:59210, idle 0:00:03, bytes 0, flags Y
unit-2-1:*************************************************************
21 in use, 271 most used
Cluster:
fwd connections: 0 in use, 2 most used
dir connections: 0 in use, 28 most used
centralized connections: 0 in use, 14 most used
VPN redirect connections: 0 in use, 0 most used
Inspect Snort:
preserve-connection: 0 enabled, 0 in effect, 249 most enabled, 0 most in effect
TCP OUTSIDE 192.168.240.51:80 INSIDE 192.168.240.50:59210, idle 0:00:00, bytes 610132872, flags b N
unit-3-1:*************************************************************
19 in use, 55 most used
Cluster:
fwd connections: 1 in use, 5 most used
dir connections: 0 in use, 127 most used
centralized connections: 0 in use, 24 most used
VPN redirect connections: 0 in use, 0 most used
Inspect Snort:
preserve-connection: 0 enabled, 0 in effect, 1 most enabled, 0 most in effect
TCP OUTSIDE 192.168.240.51:80 NP Identity Ifc 192.168.240.50:59210, idle 0:00:00, bytes 0, flags z
|
Unidade |
Sinalizador |
Nota |
|
Unit-1-1 |
Y |
· Diretor/proprietário do backup |
|
Unit-2-1 |
b N |
· Proprietário do fluxo - A unidade controla o fluxo |
|
Unit-3-1 |
z |
· Encaminhador |
Isso pode ser visualizado da seguinte maneira:
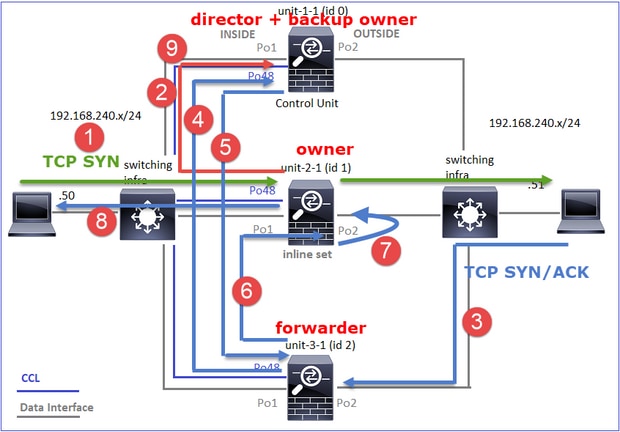
- O pacote TCP SYN chega do Host-A para a unidade 2-1. A unidade 2-1 torna-se o proprietário do fluxo e a unidade 1-1 é eleita como direcionador
- A Unidade-1-1 é eleita a proprietária do backup (já que é o direcionador). O proprietário do fluxo envia uma mensagem unicast "cluster add" no UDP 4193 para. informe o proprietário do backup sobre o fluxo.
- O pacote TCP SYN/ACK chega do Host-B para a unidade 3-1. O fluxo é assimétrico.
- A unidade 3-1 encaminha o pacote através da CCL para o direcionador (unidade 1-1).
- A Unidade-1-1 (direcionador) sabe que o proprietário é a Unidade-2-1, envia o pacote de volta ao encaminhador (Unidade-3-1) e o notifica de que o proprietário é a Unidade-2-1.
- A unidade 3-1 envia o pacote para a unidade 2-1 (proprietário).
- A unidade 2-1 injeta novamente o pacote na interface EXTERNA.
- A unidade 2-1 encaminha o pacote para o host A.
- Quando a conexão é encerrada, o proprietário envia uma mensagem de exclusão de cluster para remover as informações de fluxo do proprietário do backup.
Note: É importante que a etapa 2 (pacote através do CCL) ocorra antes da etapa 4 (tráfego de dados). Em um caso diferente (por exemplo, condição de corrida), o diretor não está ciente do fluxo. Assim, como é um conjunto em linha, encaminha o pacote para o destino. Se as interfaces não estiverem em um conjunto em linha, o pacote de dados será descartado.
A observação 3. Capture with trace mostra o tráfego assimétrico e as trocas pelo CCL:
Tráfego de encaminhamento (TCP SYN)
Unidade-2-1 (proprietário):
firepower# cluster exec unit unit-2-1 show cap CAPI packet-number 1 trace
1: 09:19:49.760702 192.168.240.50.59210 > 192.168.240.51.80: S 4110299695:4110299695(0) win 29200 <mss 1460,sackOK,timestamp 130834570 0,nop,wscale 7>
Phase: 1
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'INSIDE'
Flow type: NO FLOW
I (1) got initial, attempting ownership.
Phase: 2
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'INSIDE'
Flow type: NO FLOW
I (1) am becoming owner
Tráfego de retorno (TCP SYN/ACK)
A unidade 3-1 (ID 2 - encaminhador) envia o pacote pela CCL para a unidade 1-1 (ID 0 - direcionador):
firepower# cluster exec unit unit-3-1 show cap CAPO packet-number 1 trace
1: 09:19:49.760336 192.168.240.51.80 > 192.168.240.50.59210: S 4209225081:4209225081(0) ack 4110299696 win 28960 <mss 1460,sackOK,timestamp 567715984 130834570,nop,wscale 7>
Phase: 1
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'OUTSIDE'
Flow type: NO FLOW
I (2) am asking director (0).
Unidade-1-1 (direcionador) - A Unidade-1-1 (ID 0) sabe que o proprietário do fluxo é a unidade-2-1 (ID 1) e envia o pacote pelo CCL de volta para a unidade-3-1 (ID 2 - encaminhador):
firepower# cluster exec show cap CAPO packet-number 1 trace
unit-1-1(LOCAL):******************************************************
1: 09:19:49.761038 192.168.240.51.80 > 192.168.240.50.59210: S 4209225081:4209225081(0) ack 4110299696 win 28960 <mss 1460,sackOK,timestamp 567715984 130834570,nop,wscale 7>
Phase: 1
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'OUTSIDE'
Flow type: STUB
I (0) am director, valid owner (1), update sender (2).
A unidade 3-1 (ID 2 - encaminhador) obtém o pacote através da CCL e o envia para a unidade 2-1 (ID 1 - proprietário):
firepower# cluster exec unit unit-3-1 show cap CAPO packet-number 2 trace
...
2: 09:19:49.761008 192.168.240.51.80 > 192.168.240.50.59210: S 4209225081:4209225081(0) ack 4110299696 win 28960 <mss 1460,sackOK,timestamp 567715984 130834570,nop,wscale 7>
Phase: 1
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'OUTSIDE'
Flow type: STUB
I (2) am becoming forwarder to (1), sender (0).
O proprietário injeta novamente e encaminha o pacote para o destino:
firepower# cluster exec unit unit-2-1 show cap CAPO packet-number 2 trace
2: 09:19:49.775701 192.168.240.51.80 > 192.168.240.50.59210: S 4209225081:4209225081(0) ack 4110299696 win 28960 <mss 1460,sackOK,timestamp 567715984 130834570,nop,wscale 7>
Phase: 1
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'OUTSIDE'
Flow type: FULL
I (1) am owner, sender (2).
Observação 4. Os syslogs de plano de dados FTD mostram a criação e o término da conexão em todas as unidades:
- Unidade 1-1 (diretor/proprietário do backup)
- Unidade-2-1 (proprietário)
- Unidade 3-1 (encaminhador)
firepower# cluster exec show log | i 59210
unit-1-1(LOCAL):******************************************************
Dec 03 2020 09:19:49: %FTD-6-302022: Built director stub TCP connection for INSIDE:192.168.240.50/59210 (192.168.240.50/59210) to OUTSIDE:192.168.240.51/80 (192.168.240.51/80)
Dec 03 2020 09:19:59: %FTD-6-302023: Teardown director TCP connection for INSIDE:192.168.240.50/59210 to OUTSIDE:192.168.240.51/80 duration 0:00:09 forwarded bytes 0 Cluster flow with CLU closed on owner
unit-2-1:*************************************************************
Dec 03 2020 09:19:49: %FTD-6-302303: Built TCP state-bypass connection 14483 from INSIDE:192.168.240.50/59210 (192.168.240.50/59210) to OUTSIDE:192.168.240.51/80 (192.168.240.51/80)
Dec 03 2020 09:19:59: %FTD-6-302304: Teardown TCP state-bypass connection 14483 from INSIDE:192.168.240.50/59210 to OUTSIDE:192.168.240.51/80 duration 0:00:09 bytes 1024003336 TCP FINs
unit-3-1:*************************************************************
Dec 03 2020 09:19:49: %FTD-6-302022: Built forwarder stub TCP connection for OUTSIDE:192.168.240.51/80 (192.168.240.51/80) to unknown:192.168.240.50/59210 (192.168.240.50/59210)
Dec 03 2020 09:19:59: %FTD-6-302023: Teardown forwarder TCP connection for OUTSIDE:192.168.240.51/80 to unknown:192.168.240.50/59210 duration 0:00:09 forwarded bytes 1024003188 Cluster flow with CLU closed on owner
Troubleshooting
Introdução à Solução de Problemas de Cluster
Os problemas de cluster podem ser categorizados em:
- Problemas do plano de controle (problemas relacionados à estabilidade do cluster)
- Problemas do plano de dados (problemas relacionados ao tráfego de trânsito)
Problemas do plano de dados do cluster
Problemas comuns de NAT/PAT
Considerações importantes sobre configuração
- Os pools de Conversão de Endereço de Porta (PAT) devem ter pelo menos o mesmo número de IPs disponíveis que o número de unidades no cluster, preferencialmente mais IPs do que nós de cluster.
- Os comandos default xlate per-session devem ser mantidos, a menos que haja um motivo específico para desativá-los. Qualquer xlate PAT criado para uma conexão que tenha xlate por sessão desabilitado é sempre tratado pela unidade de nó de controle no cluster, o que pode causar degradação de desempenho.
Uso de intervalo de pool PAT alto devido ao tráfego originado de portas baixas que causa desequilíbrio de IP de cluster
O FTD divide um IP PAT em intervalos e tenta manter o xlate no mesmo intervalo de origem. Esta tabela mostra como uma porta de origem é convertida em uma porta global dentro do mesmo intervalo de origem.
|
Porta Src Original |
Porta Src Traduzida |
|
1-511 |
1-511 |
|
512-1023 |
512-1023 |
|
1024-65535 |
1024-65535 |
Quando um intervalo de portas de origem estiver cheio e um novo xlate PAT precisar ser alocado desse intervalo, o FTD se moverá para o próximo IP para alocar novas conversões para esse intervalo de portas de origem.
Sintomas:
Problemas de conectividade para tráfego de NAT que atravessa o cluster
Verificação:
# show nat pool
Os registros do plano de dados do FTD mostram o esgotamento do pool do PAT:
Dec 9 09:00:00 192.0.2.10 FTD-FW %ASA-3-202010: PAT pool exhausted. Unable to create TCP connection from Inside:192.0.2.150/49464 to Outside:192.0.2.250/20015
Dec 9 09:00:00 192.0.2.10 FTD-FW %ASA-3-202010: PAT pool exhausted. Unable to create TCP connection from Inside:192.0.2.148/54141 to Outside:192.0.2.251/443
Atenuação:
Configure o intervalo de porta plana NAT e inclua portas de reserva.
Além disso, no pós-6.7/9.15.1, você pode acabar com a distribuição de bloco de porta desbalanceada apenas quando os nós saem/ingressam no cluster com enorme tráfego em segundo plano que está sujeito ao PAT. A única maneira de se recuperar sozinha é quando os blocos de porta são liberados para serem redistribuídos pelos nós.
Com a distribuição baseada em blocos de portas, quando um nó é alocado com, digamos, 10 blocos de portas, como pb-1, pb-2 ... pb-10. O nó sempre inicia com o primeiro bloco de portas disponível e aloca uma porta aleatória dele até que ele se esgote. A alocação é movida para o próximo bloco de porta somente quando todos os blocos de porta até aquele ponto estão esgotados.
Por exemplo, se um host estabelece 512 conexões, a unidade aloca portas mapeadas para todas essas 512 conexões de pb-1 aleatoriamente. Agora, com todas essas 512 conexões ativas, quando o host estabelece a 513ª conexão desde que o pb-1 está esgotado, ele se move para o pb-2 e aloca uma porta aleatória a partir dele. Novamente, das 513 conexões, suponha que a 10ª conexão tenha terminado e limpado uma porta disponível em pb-1. Nesse ponto, se o host estabelecer a 514ª conexão, a unidade de cluster alocará uma porta mapeada de pb-1 e não de pb-2 porque pb-1 agora tem uma porta livre (que foi liberada como parte da 10ª remoção de conexão).
A parte importante a ser lembrada é que a alocação acontece a partir do primeiro bloco de porta disponível com portas livres, de modo que os últimos blocos de porta estejam sempre disponíveis para redistribuição em um sistema normalmente carregado. Além disso, o PAT é normalmente usado para conexões de curta duração. A probabilidade de um bloco de portas se tornar disponível em um tempo mais curto é muito alta. Assim, o tempo necessário para que a distribuição do pool se torne equilibrada pode melhorar com a distribuição do pool baseada em bloco de porta.
No entanto, caso todos os blocos de porta, de pb-1 a pb-10, estejam esgotados ou cada bloco de porta contenha uma porta para uma conexão de longa duração, os blocos de porta nunca são liberados rapidamente e são redistribuídos. Nesse caso, a abordagem menos perturbadora consiste em:
- Identificar nós com excesso de blocos de porta (show nat pool cluster summary).
- Identifique os blocos de porta menos usados nesse nó (show nat pool ip <addr> detail).
- Limpe xlates para esses blocos de porta (clear xlate global <addr> gport 'start-end') para disponibilizá-los para redistribuição.
aviso: Isso interrompe as conexões relevantes.
Não é possível navegar para sites de canal duplo (como webmail, bancos, etc.) ou para sites de SSO quando ocorre o redirecionamento para um destino diferente.
Sintomas:
Não é possível navegar para sites de canal duplo (como webmail, sites de bancos e assim por diante). Quando um usuário se conecta a um site que exige que o cliente abra um segundo soquete/conexão e a segunda conexão é submetida a hash para um membro do cluster diferente daquele para o qual foi aplicado o hash da primeira conexão, e o tráfego usa um pool IP PAT, o tráfego é redefinido pelo servidor à medida que ele recebe a conexão de um endereço IP público diferente.
Verificação:
Faça capturas de cluster de plano de dados para ver como o fluxo de trânsito afetado é tratado. Nesse caso, uma redefinição de TCP vem do site de destino.
Mitigação (pré-6.7/9.15.1):
- Observe se algum aplicativo de várias sessões usa vários endereços IP mapeados.
- Use o comando show nat pool cluster summary para verificar se o pool está distribuído uniformemente.
- Use o comando cluster exec show conn para verificar se o tráfego tem a carga balanceada corretamente.
- Use o comando show nat pool cluster ip <address> detail para verificar o uso do pool de IP sticky.
- Ative o 305021 syslog (6.7/9.15) para ver quais conexões não conseguiram usar o IP sticky.
- Para resolver, adicione mais IPs ao pool PAT ou ajuste o algoritmo de balanceamento de carga nos switches conectados.
Sobre o algoritmo de balanceamento de carga do canal ether:
- Para não FP9300 e se a autenticação ocorrer por meio de um servidor: Ajuste o algoritmo de balanceamento de carga do canal ether no switch adjacente de IP/Porta de Origem e IP/Porta de Destino para IP de Origem e IP de Destino.
- Para não FP9300 e se a autenticação ocorrer por meio de vários servidores: Ajuste o algoritmo de balanceamento de carga do canal ether no switch adjacente de IP/Porta de Origem e IP/Porta de Destino para IP de Origem.
- Para FP9300: No chassi FP9300, o algoritmo de balanceamento de carga é fixado como source-dest-port source-dest-ip source-dest-mac e não pode ser alterado. A solução, nesse caso, é usar o FlexConfig para adicionar comandos xlate per-session deny à configuração do FTD para forçar o tráfego de determinados endereços IP de destino (para aplicativos problemáticos/incompatíveis) a ser manipulado apenas pelo nó de controle no cluster dentro do chassi. A solução alternativa vem com estes efeitos colaterais:
- Sem balanceamento de carga do tráfego convertido de maneira diferente (tudo vai para o nó de controle).
- Potencial de execução de slots xlate (e afetar adversamente a conversão NAT para outro tráfego no nó de controle).
- Escalabilidade reduzida do cluster dentro do chassi.
Baixo desempenho de cluster devido a todo o tráfego enviado para o nó de controle devido a IPs PAT insuficientes nos pools.
Sintomas:
Não há IPs PAT suficientes no cluster para alocar um IP livre para os nós de dados e, portanto, todo o tráfego sujeito à configuração PAT é encaminhado ao nó de controle para processamento.
Verificação:
Use o comando show nat pool cluster para ver as alocações para cada unidade e confirmar que todos possuem pelo menos um IP no pool.
Atenuação:
Para versões anteriores a 6.7/9.15.1, certifique-se de que você tenha um pool PAT de tamanho pelo menos igual ao número de nós no cluster. Em versões posteriores à 6.7/9.15.1 com o pool PAT, você aloca blocos de porta de todos os IPs do pool PAT. Se o uso do pool PAT for realmente alto, o que leva ao esgotamento frequente do pool, você precisará aumentar o tamanho do pool PAT (consulte a seção FAQ).
Baixo desempenho devido a todo o tráfego enviado para o nó de controle porque os xlates não estão habilitados por sessão.
Sintomas:
Muitos fluxos de backup UDP de alta velocidade são processados pelo nó de controle do cluster, o que pode afetar o desempenho.
Background:
Somente as conexões que usam xlates ativadas por sessão podem ser processadas por um nó de dados que usa PAT. Use o comando show run all xlate para ver a configuração por sessão xlate.
Habilitado por sessão significa que o xlate é desativado imediatamente quando a conexão associada é desativada. Isso ajuda a melhorar o desempenho da conexão por segundo quando as conexões estão sujeitas ao PAT. Os xlates que não são por sessão ficam ativos por mais 30 segundos após a conexão ser interrompida e, se a taxa de conexão for alta o suficiente, as portas TCP/UDP de 65k disponíveis em cada IP global podem ser usadas em um curto período de tempo.
Por padrão, todo o tráfego TCP é habilitado por xlate e somente o tráfego DNS UDP é habilitado por sessão. Isso significa que todo o tráfego UDP não-DNS é encaminhado ao nó de controle para processamento.
Verificação:
Use este comando para verificar a conexão e a distribuição de pacotes entre as unidades de cluster:
firepower# show cluster info conn-distribution
firepower# show cluster info packet-distribution
firepower# show cluster info load-monitor
Use o comando cluster exec show conn para ver quais nós de cluster possuem as conexões UDP.
firepower# cluster exec show conn
Use este comando para entender o uso do pool nos nós do cluster.
firepower# cluster exec show nat pool ip| in UDP
Atenuação:
Configure o PAT por sessão (comando per-session permit udp) para o tráfego de interesse (por exemplo, UDP). Para o ICMP, não é possível alterar o PAT multissessão padrão, portanto, o tráfego do ICMP é sempre manipulado pelo nó de controle quando há um PAT configurado.
A distribuição do pool PAT torna-se desbalanceada à medida que os nós saem/ingressam no cluster.
Sintomas:
- Problemas de conectividade desde a alocação de IP PAT podem se tornar desequilibrados ao longo do tempo devido às unidades que saem e ingressam no cluster.
- Em post-6.7/9.15.1, pode haver casos em que o nó recém-unido não pode obter blocos de porta suficientes. Um nó que não tenha nenhum bloco de porta redireciona o tráfego para o nó de controle. Um nó que tenha pelo menos um bloco de portas trata o tráfego e o descarta quando o pool estiver esgotado.
Verificação:
- Os syslogs do plano de dados mostram mensagens como:
%ASA-3-202010: NAT pool exhausted. Unable to create TCP connection from inside:192.0.2.1/2239 to outside:192.0.2.150/80
- Use o comando show nat pool cluster summary para identificar a distribuição do pool.
- Use o comando cluster exec show nat pool ip <addr> detail para entender o uso do pool nos nós do cluster.
Atenuação:
- Para versões anteriores a 6.7/9.15.1, algumas soluções alternativas são descritas no bug da Cisco ID CSCvd10530
- Na versão pós-6.7/9.15.1, use o comando clear xlate global <ip> gport <start-end> para limpar manualmente alguns dos blocos de porta em outros nós para redistribuição aos nós necessários.
Sintomas:
Principais problemas de conectividade para o tráfego que é PATed pelo cluster. Isso ocorre porque o plano de dados FTD, por design, não envia GARP para endereços NAT globais.
Verificação:
A tabela ARP dos dispositivos conectados diretamente mostra diferentes os endereços MAC da interface de dados do cluster após uma alteração do nó de controle:
root@kali2:~/tests# arp -a
? (192.168.240.1) at f4:db:e6:33:44:2e [ether] on eth0
root@kali2:~/tests# arp -a
? (192.168.240.1) at f4:db:e6:9e:3d:0e [ether] on eth0
Atenuação:
Configure o MAC estático (virtual) nas interfaces de dados do cluster.
Conexões sujeitas a falha de PAT
Sintomas:
Problemas de conectividade para o tráfego que é PATed pelo cluster.
Verificação/Mitigação:
- Verifique se a configuração foi replicada corretamente.
- Verifique se o pool está distribuído uniformemente.
- Verifique se a propriedade do pool é válida.
- Nenhum contador de falhas incrementa no contador de cluster show asp.
- Certifique-se de que os fluxos do direcionador/encaminhador sejam criados com as informações apropriadas.
- Valide se os extratos de backup são criados, atualizados e limpos conforme esperado.
- Validar se os xlates são criados e encerrados de acordo com o comportamento "por sessão".
- Ative "debug nat 2" para obter uma indicação de erros. Observe que essa saída pode ser muito ruidosa, por exemplo:
firepower# debug nat 2
nat: no free blocks available to reserve for 192.168.241.59, proto 17
nat: no free blocks available to reserve for 192.168.241.59, proto 17
nat: no free blocks available to reserve for 192.168.241.58, proto 17
nat: no free blocks available to reserve for 192.168.241.58, proto 17
nat: no free blocks available to reserve for 192.168.241.57, proto 17
Para interromper a depuração:
firepower# un all
- Ative a conexão e os syslogs relacionados a NAT para correlacionar as informações a uma conexão com falha.
Aprimoramentos de PAT de clustering de ASA e FTD (pós-9.15 e 6.7)
O que mudou? A operação PAT foi reprojetada. Os IPs individuais não são mais distribuídos para cada um dos membros do cluster. Em vez disso, os IPs PAT são divididos em blocos de porta e distribuídos uniformemente (tanto quanto possível) entre os membros do cluster, em combinação com a operação de adesão de IP.
O novo design trata dessas limitações (consulte a seção anterior):
- Os aplicativos de várias sessões são afetados devido à falta de adesão ao IP em todo o cluster.
- O requisito é ter um pool PAT de tamanho pelo menos igual ao número de nós no cluster.
- A distribuição do pool PAT torna-se desbalanceada à medida que os nós saem/ingressam no cluster.
- Não há syslogs para indicar o desequilíbrio do pool PAT.
Tecnicamente, em vez dos intervalos de porta padrão 1-511, 512-1023 e 1024-65535, agora há 1024-65535 como o intervalo de porta padrão para PAT. Esse intervalo padrão pode ser estendido para incluir o intervalo de portas privilegiadas de 1 a 1023 para PAT regular (opção include-reserve).
Este é um exemplo de uma configuração de pool PAT no FTD 6.7. Para obter detalhes adicionais, verifique a seção relacionada no Guia de configuração:
Informações adicionais de Troubleshooting sobre PAT
Syslogs de Plano de Dados FTD (Pós-6.7/9.15.1)
Um syslog de invalidação de adesão é gerado quando todas as portas são esgotadas no IP de adesão em um nó de cluster, e a alocação passa para o próximo IP disponível com portas livres, por exemplo:
%ASA-4-305021: Ports exhausted in pre-allocated PAT pool IP 192.0.2.100 for host 198.51.100.100 Allocating from new PAT pool IP 203.0.113.100.
Um syslog de desequilíbrio de Pool é gerado em um nó quando ele ingressa no cluster e não recebe nenhum compartilhamento ou uma parte desigual de blocos de porta, por exemplo:
%ASA-4-305022: Cluster unit ASA-4 has been allocated 0 port blocks for PAT usage. All units should have at least 32 port blocks.
%ASA-4-305022: Cluster unit ASA-4 has been allocated 12 port blocks for PAT usage. All units should have at least 32 port blocks.
comandos show
Status de distribuição do pool:
Na saída show nat pool cluster summary, para cada endereço IP de PAT, não deve haver uma diferença de mais de 1 bloco de porta nos nós em um cenário de distribuição balanceado. Exemplos de uma distribuição de bloco de porta balanceada e desbalanceada.
firepower# show nat pool cluster summary
port-blocks count display order: total, unit-1-1, unit-2-1, unit-3-1
IP OUTSIDE:ip_192.168.241.57-59 192.168.241.57 (126 - 42 / 42 / 42)
IP OUTSIDE:ip_192.168.241.57-59 192.168.241.58 (126 - 42 / 42 / 42)
IP OUTSIDE:ip_192.168.241.57-59 192.168.241.59 (126 - 42 / 42 / 42)
Distribuição desequilibrada:
firepower# show nat pool cluster summary
port-blocks count display order: total, unit-1-1, unit-4-1, unit-2-1, unit-3-1
IP outside:src_map 192.0.2.100 (128 - 32 / 22 / 38 / 36)
Status de propriedade do pool:
Na saída show nat pool cluster, não deve haver um único bloco de porta com proprietário ou backup como UNKNOWN. Se houver um, isso indica um problema com a comunicação de propriedade do pool. Exemplo:
firepower# show nat pool cluster | in
[3072-3583], owner unit-4-1, backup <UNKNOWN>
[56832-57343], owner <UNKNOWN>, backup <UNKNOWN>
[10240-10751], owner unit-2-1, backup <UNKNOWN>
Contabilização das atribuições de portas em blocos de portas:
O comando show nat pool é aprimorado com opções adicionais para exibir informações detalhadas, bem como saída filtrada.
Exemplo:
firepower# show nat pool detail
TCP PAT pool INSIDE, address 192.168.240.1, range 1-1023, allocated 0
TCP PAT pool INSIDE, address 192.168.240.1, range 1024-65535, allocated 18
UDP PAT pool INSIDE, address 192.168.240.1, range 1-1023, allocated 0
UDP PAT pool INSIDE, address 192.168.240.1, range 1024-65535, allocated 20
TCP PAT pool OUTSIDE, address 192.168.241.1, range 1-1023, allocated 0
TCP PAT pool OUTSIDE, address 192.168.241.1, range 1024-65535, allocated 18
UDP PAT pool OUTSIDE, address 192.168.241.1, range 1-1023, allocated 0
UDP PAT pool OUTSIDE, address 192.168.241.1, range 1024-65535, allocated 20
UDP PAT pool OUTSIDE, address 192.168.241.58
range 1024-1535, allocated 512
range 1536-2047, allocated 512
range 2048-2559, allocated 512
range 2560-3071, allocated 512
...
unit-2-1:*************************************************************
UDP PAT pool OUTSIDE, address 192.168.241.57
range 1024-1535, allocated 512 *
range 1536-2047, allocated 512 *
range 2048-2559, allocated 512 *
‘*’ indica que é um bloco de porta de backup
Para resolver isso, use o comando clear xlate global <ip> gport <start-end> para limpar manualmente alguns dos blocos de porta em outros nós para redistribuição aos nós necessários.
Redistribuição de blocos de porta acionada manualmente:
- Em uma rede de produção com tráfego constante, quando um nó sai e reingressa no cluster (provavelmente devido a um retorno de rastreamento), pode haver casos em que ele não pode obter uma parte igual do pool ou, no pior dos casos, não pode obter nenhum bloco de porta.
- Use o comando show nat pool cluster summary para identificar qual nó possui mais blocos de porta do que o necessário.
- Nos nós que possuem mais blocos de porta, use o comando show nat pool ip <addr> detail para descobrir os blocos de porta com o menor número de alocações.
- Use o comando clear xlate global <address> gport <start-end> para limpar as conversões criadas a partir desses blocos de porta, de modo que fiquem disponíveis para redistribuição nos nós necessários, por exemplo:
firepower# show nat pool detail | i 19968
range 19968-20479, allocated 512
range 19968-20479, allocated 512
range 19968-20479, allocated 512
firepower# clear xlate global 192.168.241.57 gport 19968-20479
INFO: 1074 xlates deleted
Perguntas frequentes (FAQ) para PAT pós-6.7/9.15.1
P. Caso você tenha o número de IPs disponíveis para o número de unidades disponíveis no cluster, ainda é possível usar 1 IP por unidade como uma opção?
R. Não mais, e não há como alternar entre esquemas de distribuição de pool baseados em endereços IP e baseados em blocos de portas.
O esquema mais antigo de distribuição de pool baseado em endereço IP resultou em falhas de aplicativo em várias sessões, em que várias conexões (que fazem parte de uma única transação de aplicativo) de um host são balanceadas em diferentes nós do cluster e, portanto, convertidas por diferentes endereços IP mapeados, o que leva o servidor de destino a vê-las como origens de diferentes entidades.
E, com o novo esquema de distribuição baseado em bloco de portas, mesmo que agora você possa trabalhar com um único endereço IP PAT, é sempre recomendável ter endereços IP PAT suficientes com base no número de conexões que precisam ser PATed.
P. Você ainda pode ter um pool de endereços IP para o pool PAT do cluster?
R. Sim, você pode. Os blocos de porta de todos os IPs do pool PAT são distribuídos pelos nós do cluster.
P. Se você usa um número de endereços IP para o pool PAT, o mesmo bloco de portas é fornecido a cada membro para cada endereço IP?
R. Não, cada IP é distribuído independentemente.
P. Todos os nós de cluster têm todos os IPs públicos, mas apenas um subconjunto de portas? Se esse for o caso, é garantido que toda vez que o IP de origem usar o mesmo IP público?
R. Isso está correto, cada IP PAT é parcialmente de propriedade de cada nó. Se um IP público escolhido for esgotado em um nó, um syslog será gerado indicando que o IP sticky não pode ser preservado e a alocação será movida para o próximo IP público disponível. Seja uma implantação autônoma, de alta disponibilidade ou de cluster, a adesão ao IP está sempre na base do melhor esforço, dependendo da disponibilidade do pool.
P. Tudo se baseia em um único endereço IP no pool PAT, mas não se aplica se mais de um endereço IP no pool PAT for usado?
R. Ele também se aplica a vários endereços IP no pool PAT. Os blocos de porta de cada IP no Pool PAT são distribuídos pelos nós de cluster. Cada endereço IP no pool PAT é dividido entre todos os membros no cluster. Portanto, se você tiver uma classe C de endereços no pool PAT, cada membro do cluster terá pools de portas de cada um dos endereços do pool PAT.
P. Funciona com o CGNAT?
R. Sim, o CGNAT também é suportado. O CGNAT, também conhecido como alocação de bloco PAT tem um tamanho de bloco padrão de '512' que pode ser modificado através da CLI do tamanho de alocação de bloco xlate. No caso de PAT dinâmico regular (não CGNAT), o tamanho do bloco é sempre '512', que é fixo e não configurável.
P. Se a unidade deixar o cluster, o nó de controle atribui o intervalo de blocos de porta a outras unidades ou o mantém consigo mesmo?
R. Cada bloco de porta tem um proprietário e um backup. Toda vez que um xlate é criado a partir de um bloco de portas, ele também é replicado para o nó de backup de bloco de portas. Quando um nó deixa o cluster, o nó de backup possui todos os blocos de porta e todas as conexões atuais. O nó de backup, já que se tornou o proprietário desses blocos de porta adicionais, escolhe um novo backup para eles e replica todos os xlates atuais para esse nó para lidar com cenários de falha.
P. Que medidas podem ser tomadas com base nesse alerta para reforçar a fidelidade?
R. Há duas razões possíveis pelas quais não é possível preservar a viscosidade.
Motivo 1: O tráfego tem balanceamento de carga incorreto devido ao qual um dos nós vê um número maior de conexões do que outros, o que leva à exaustão de IP difícil em particular. Isso pode ser solucionado se você garantir que o tráfego seja distribuído uniformemente pelos nós de cluster. Por exemplo, em um cluster FPR41xx, ajuste o algoritmo de balanceamento de carga em switches conectados. Em um cluster FPR9300, assegure um número igual de blades no chassi.
Motivo 2: O uso do pool PAT é realmente alto, o que leva à exaustão frequente do pool. Para lidar com isso, aumente o tamanho do pool PAT.
P. Como é tratado o suporte à palavra-chave extended? Ele mostra um erro e impede que todo o comando NAT seja adicionado durante a atualização, ou remove a palavra-chave estendida e mostra um aviso?
A. A opção estendida PAT não é suportada no cluster do ASA 9.15.1/FP 6.7 em diante. A opção de configuração não é removida de nenhum CLI/ASDM/CSM/FMC. Quando configurado (direta ou indiretamente através de uma atualização), você é notificado com uma mensagem de aviso e a configuração é aceita, mas você não vê a funcionalidade estendida do PAT em ação.
P. É o mesmo número de conversões que as conexões simultâneas?
R. Em versões anteriores a 6.7/9.15.1, embora tenha sido de 1 a 65535, como as portas de origem nunca são muito usadas no intervalo de 1 a 1024, isso o torna efetivamente 1024-65535 (64512 conns). Na implementação pós-6.7/9.15.1 com 'flat' como comportamento padrão, é 1024-65535. Mas se você quiser usar o 1-1024, poderá usar a opção "include-reserve".
P. Se o nó ingressar no cluster de volta, ele terá o nó de backup antigo como backup e esse nó de backup fornecerá o bloco de porta antigo a ele?
R. Depende da disponibilidade de blocos de porta naquele momento. Quando um nó deixa o cluster, todos os seus blocos de porta são movidos para o nó de backup. Em seguida, é o nó de controle que acumula blocos de porta livres e os distribui aos nós necessários.
P. Se houver uma alteração no estado do nó de controle, um novo nó de controle escolhido, a alocação do bloco PAT será mantida ou os blocos de porta serão realocados com base no novo nó de controle?
R. O novo nó de controle tem uma compreensão de quais blocos foram alocados e quais estão livres e começam a partir daí.
P. O número máximo de xlates é igual ao número máximo de conexões simultâneas com esse novo comportamento?
R. Sim. O número máximo de xlates depende da disponibilidade de portas PAT. Não tem nada a ver com o número máximo de conexões simultâneas. Se você permitir apenas 1 endereço, terá 65535 conexões possíveis. Se precisar de mais, você precisa alocar mais endereços IP. Se houver endereços/portas suficientes, você poderá atingir o máximo de conexões simultâneas.
P. Qual é o processo de alocação de bloco de porta quando um novo membro de cluster é adicionado? O que acontece se um membro do cluster for adicionado devido à reinicialização?
A. Os blocos de porta são sempre distribuídos pelo nó de controle. Os blocos de porta são alocados para um novo nó somente quando há blocos de porta livres. Blocos de porta livres significam que nenhuma conexão é servida através de qualquer porta mapeada dentro do bloco de porta.
Além disso, ao reingressar, cada nó recalcula o número de blocos que pode ter. Se um nó contiver mais blocos do que deveria, ele liberará esses blocos de porta adicionais para o nó de controle quando eles se tornarem disponíveis. O nó de controle os aloca ao nó de dados recém-unido.
P. Ele é compatível apenas com protocolos TCP e UDP ou SCTP também?
R. O SCTP nunca foi suportado com PAT dinâmico. Para o tráfego SCTP, a recomendação é usar apenas um objeto de rede estática NAT.
P. Se um nó ficar sem portas de bloqueio, ele descartará pacotes e não usará o próximo bloco IP disponível?
R. Não, não cai imediatamente. Usa blocos de porta disponíveis do próximo IP PAT. Se todos os blocos de porta em todos os IPs PAT estiverem esgotados, ele descartará o tráfego.
P. Para evitar a sobrecarga do nó de controle em uma janela de atualização de cluster, é melhor selecionar um novo controle manualmente antes (por exemplo, na metade de uma atualização de cluster de 4 unidades), em vez de esperar que todas as conexões sejam tratadas no nó de controle?
R. O controle deve ser atualizado por último. Isso ocorre porque, quando o nó de controle executa a versão mais recente, ele não inicia a distribuição do pool, a menos que todos os nós executem a versão mais recente. Além disso, quando uma atualização é executada, todos os nós de dados com uma versão mais recente ignoram mensagens de distribuição de pool de um nó de controle se ele executar uma versão mais antiga.
Para explicar isso em detalhes, considere uma implantação de cluster com 4 nós A, B, C e D com A como controle. Estas são as etapas típicas de atualização sem interrupções:
- Faça o download de uma nova versão em cada um dos nós.
- Recarregue a unidade "D". Todas as conexões, xlates são movidas para o nó de backup.
- A unidade "D" surge e:
a. Processa a configuração do PAT
b. Divide cada IP PAT em blocos de porta
c. Tem todos os blocos de porta no estado não atribuído
d. Ignora a versão mais antiga das mensagens PAT do cluster recebidas do controle
e. Redireciona todas as conexões PAT para o Primário.
4. Da mesma forma, ative outros nós com a nova versão.
5. Recarregar o comando da unidade "A". Como não há backup para controle, todas as conexões existentes são descartadas
6. O novo controle inicia a distribuição dos blocos de portas no formato mais recente
7. A unidade "A" retoma funções e pode aceitar e atuar sobre mensagens de distribuição de blocos portuários
Manipulação de Fragmentos
Sintoma:
Em implantações de cluster entre sites, pacotes fragmentados que devem ser tratados em um site específico (tráfego local de site) ainda podem ser enviados para as unidades em outros sites, já que um desses sites pode ter o proprietário do fragmento.
Na lógica de cluster, há uma função adicional definida para conexões com pacotes fragmentados: proprietário do fragmento.
Para pacotes fragmentados, as unidades de cluster que recebem um fragmento determinam o proprietário do fragmento com base em um hash do endereço IP origem do fragmento, do endereço IP destino e do ID do pacote. Todos os fragmentos são encaminhados ao proprietário do fragmento pelo link de controle do cluster. Os fragmentos podem ter balanceamento de carga em diferentes unidades de cluster, pois somente o primeiro fragmento inclui a 5 tuplas usada no hash de balanceamento de carga do switch. Outros fragmentos não contêm as portas origem e destino e podem ter a carga balanceada para outras unidades de cluster. O proprietário do fragmento reagrupa temporariamente o pacote para que possa determinar o direcionador com base em um hash do endereço IP e das portas de origem/destino. Se for uma nova conexão, o proprietário do fragmento se tornará o proprietário da conexão. Se for uma conexão existente, o proprietário do fragmento encaminhará todos os fragmentos ao proprietário da conexão pelo link de controle do cluster. Em seguida, o proprietário da conexão reagrupa todos os fragmentos.
Considere esta topologia com o fluxo de uma solicitação de eco ICMP fragmentada do cliente para o servidor:
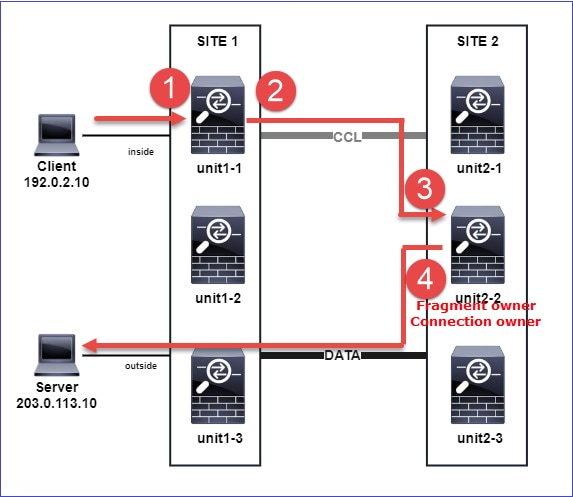
Para entender a ordem das operações, há capturas de pacotes em todo o cluster nas interfaces de link de controle interno, externo e de cluster configuradas com a opção de rastreamento. Além disso, uma captura de pacotes com a opção de reinserção/ocultação é configurada na interface interna.
firepower# cluster exec capture capi interface inside trace match icmp any any
firepower# cluster exec capture capir interface inside reinject-hide trace match icmp any any
firepower# cluster exec capture capo interface outside trace match icmp any any
firepower# cluster exec capture capccl interface cluster trace match icmp any any
Ordem das operações no cluster:
1. a unidade 1-1 no local 1 recebe os pacotes de solicitação de eco ICMP fragmentados.
firepower# cluster exec show cap capir
unit-1-1(LOCAL):******************************************************
2 packets captured
1: 20:13:58.227801 802.1Q vlan#10 P0 192.0.2.10 > 203.0.113.10 icmp: echo request
2: 20:13:58.227832 802.1Q vlan#10 P0
2 packets shown
2. a unidade 1-1 seleciona a unidade 2-2 no local 2 como o proprietário do fragmento e envia pacotes fragmentados para ela.
O endereço MAC destino dos pacotes enviados da unidade 1-1 para a unidade 2-2 é o endereço MAC do link CCL na unidade 2-2.
firepower# show cap capccl packet-number 1 detail
7 packets captured
1: 20:13:58.227817 0015.c500.018f 0015.c500.029f 0x0800 Length: 1509
192.0.2.10 > 203.0.113.10 icmp: echo request (wrong icmp csum) (frag 46772:1475@0+) (ttl 3)
1 packet shown
firepower# show cap capccl packet-number 2 detail
7 packets captured
2: 20:13:58.227832 0015.c500.018f 0015.c500.029f 0x0800 Length: 637
192.0.2.10 > 203.0.113.10 (frag 46772:603@1480) (ttl 3)
1 packet shown
firepower# cluster exec show interface po48 | i MAC
unit-1-1(LOCAL):******************************************************
MAC address 0015.c500.018f, MTU 1500
unit-1-2:*************************************************************
MAC address 0015.c500.019f, MTU 1500
unit-2-2:*************************************************************
MAC address 0015.c500.029f, MTU 1500
unit-1-3:*************************************************************
MAC address 0015.c500.016f, MTU 1500
unit-2-1:*************************************************************
MAC address 0015.c500.028f, MTU 1500
unit-2-3:*************************************************************
MAC address 0015.c500.026f, MTU 1500
3. a unidade 2-2 recebe, reagrupa os pacotes fragmentados e torna-se a proprietária do fluxo.
firepower# cluster exec unit unit-2-2 show capture capccl packet-number 1 trace
11 packets captured
1: 20:13:58.231845 192.0.2.10 > 203.0.113.10 icmp: echo request
Phase: 1
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'inside'
Flow type: NO FLOW
I (2) received a FWD_FRAG_TO_FRAG_OWNER from (0).
Phase: 2
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'inside'
Flow type: NO FLOW
I (2) have reassembled a packet and am processing it.
Phase: 3
Type: CAPTURE
Subtype:
Result: ALLOW
Config:
Additional Information:
MAC Access list
Phase: 4
Type: ACCESS-LIST
Subtype:
Result: ALLOW
Config:
Implicit Rule
Additional Information:
MAC Access list
Phase: 5
Type: ROUTE-LOOKUP
Subtype: No ECMP load balancing
Result: ALLOW
Config:
Additional Information:
Destination is locally connected. No ECMP load balancing.
Found next-hop 203.0.113.10 using egress ifc outside(vrfid:0)
Phase: 6
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'inside'
Flow type: NO FLOW
I (2) am becoming owner
Phase: 7
Type: ACCESS-LIST
Subtype: log
Result: ALLOW
Config:
access-group CSM_FW_ACL_ global
access-list CSM_FW_ACL_ advanced trust ip any any rule-id 268435460 event-log flow-end
access-list CSM_FW_ACL_ remark rule-id 268435460: PREFILTER POLICY: igasimov_prefilter1
access-list CSM_FW_ACL_ remark rule-id 268435460: RULE: r1
Additional Information:
...
Phase: 19
Type: FLOW-CREATION
Subtype:
Result: ALLOW
Config:
Additional Information:
New flow created with id 1719, packet dispatched to next module
...
Result:
input-interface: cluster(vrfid:0)
input-status: up
input-line-status: up
output-interface: outside(vrfid:0)
output-status: up
output-line-status: up
Action: allow
1 packet shown
firepower# cluster exec unit unit-2-2 show capture capccl packet-number 2 trace
11 packets captured
2: 20:13:58.231875
Phase: 1
Type: CLUSTER-EVENT
Subtype:
Result: ALLOW
Config:
Additional Information:
Input interface: 'inside'
Flow type: NO FLOW
I (2) received a FWD_FRAG_TO_FRAG_OWNER from (0).
Result:
input-interface: cluster(vrfid:0)
input-status: up
input-line-status: up
Action: allow
1 packet shown
4. a unidade 2-2 permite os pacotes com base na política de segurança e os envia, através da interface externa, do local 2 para o local 1.
firepower# cluster exec unit unit-2-2 show cap capo
2 packets captured
1: 20:13:58.232058 802.1Q vlan#20 P0 192.0.2.10 > 203.0.113.10 icmp: echo request
2: 20:13:58.232058 802.1Q vlan#20 P0
Observações/avisos:
- Diferentemente da função de diretor, o proprietário do fragmento não pode ser localizado em um site específico. O proprietário do fragmento é determinado pela unidade que recebe originalmente os pacotes fragmentados de uma nova conexão e pode ser localizada em qualquer local.
- Como um proprietário de fragmento também pode se tornar o proprietário da conexão, para encaminhar os pacotes ao host de destino, ele deve ser capaz de resolver a interface de saída e encontrar os endereços IP e MAC do host de destino ou o próximo salto. Isso pressupõe que o(s) próximo(s) salto(s) também deve(m) ter o acesso ao host de destino.
- Para remontar os pacotes fragmentados, o ASA/FTD mantém um módulo de remontagem de fragmentos IP para cada interface nomeada. Para exibir os dados operacionais do módulo de remontagem de fragmentos IP, use o comando show fragment:
Interface: insideEm implantações de cluster, o proprietário do fragmento ou o proprietário da conexão coloca os pacotes fragmentados na fila de fragmentos. O tamanho da fila de fragmentos é limitado pelo valor do contador Size (por padrão 200) configurado com o comando fragment size <size> <nameif>. Quando o tamanho da fila de fragmentos atinge 2/3 do Tamanho, o limite da fila de fragmentos é considerado excedido e todos os novos fragmentos que não fazem parte da cadeia de fragmentos atual são descartados. Nesse caso, o limiar de fila de Fragmento excedido é incrementado e a mensagem de syslog FTD-3-209006 é gerada.
Configuration: Size: 200, Chain: 24, Timeout: 5, Reassembly: virtual
Run-time stats: Queue: 0, Full assembly: 0
Drops: Size overflow: 0, Timeout: 0,
Chain overflow: 0, Fragment queue threshold exceeded: 0,
Small fragments: 0, Invalid IP len: 0,
Reassembly overlap: 0, Fraghead alloc failed: 0,
SGT mismatch: 0, Block alloc failed: 0,
Invalid IPV6 header: 0, Passenger flow assembly failed: 0
firepower# show fragment inside
Interface: inside
Configuration: Size: 200, Chain: 24, Timeout: 5, Reassembly: virtual
Run-time stats: Queue: 133, Full assembly: 0
Drops: Size overflow: 0, Timeout: 8178,
Chain overflow: 0, Fragment queue threshold exceeded: 40802,
Small fragments: 0, Invalid IP len: 0,
Reassembly overlap: 9673, Fraghead alloc failed: 0,
SGT mismatch: 0, Block alloc failed: 0,
Invalid IPV6 header: 0, Passenger flow assembly failed: 0
%FTD-3-209006: Fragment queue threshold exceeded, dropped TCP fragment from 192.0.2.10/21456 to 203.0.113.10/443 on inside interface.
Como solução alternativa, aumente o tamanho no Firepower Management Center > Dispositivos > Gerenciamento de dispositivo > [Editar dispositivo] > Interfaces > [Interface] > Avançado > Configuração de segurança > Substituir configuração de fragmento padrão, salve a configuração e implante as políticas. Em seguida, monitore o contador de filas na saída do comando show fragment e a ocorrência da mensagem de syslog FTD-3-209006.
Problemas da ACI
Problemas de conectividade intermitentes através do cluster devido à verificação de checksum L4 ativo no pod da ACI
Sintoma:
- Problemas de conectividade intermitentes através do cluster ASA/FTD implantado em um pod ACI.
- Se houver apenas 1 unidade no cluster, os problemas de conectividade não serão observados.
- Os pacotes enviados de uma unidade de cluster para uma ou mais unidades no cluster não são visíveis nas capturas FXOS e de plano de dados das unidades de destino.
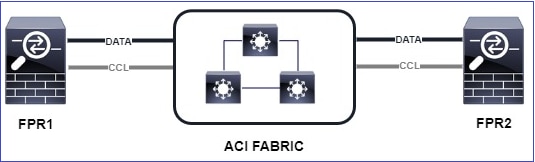
Atenuação
- O tráfego redirecionado sobre o link de controle de cluster não tem um checksum L4 correto e esse é o comportamento esperado. Os switches no caminho do link de controle de cluster não devem verificar a soma de verificação L4. Os switches que verificam a soma de verificação L4 podem fazer com que o tráfego seja descartado. Verifique a configuração do switch de estrutura da ACI e certifique-se de que nenhum checksum L4 seja executado nos pacotes recebidos ou enviados por meio do link de controle do cluster.
Problemas do plano de controle de cluster
A Unidade Não Pode Ingressar no Cluster
Tamanho de MTU em CCL
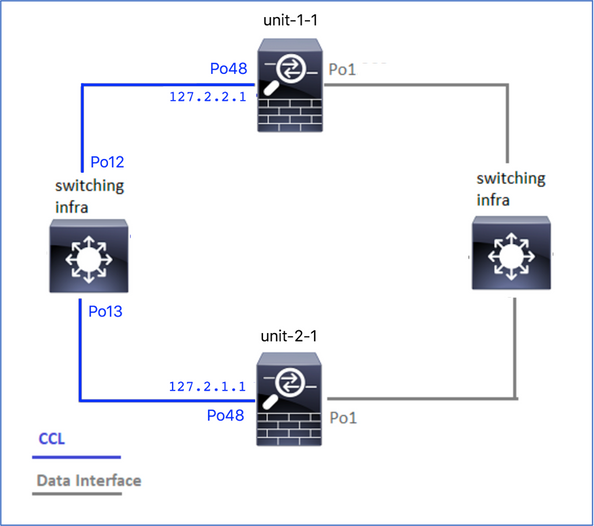
Sintomas:
A unidade não pode ingressar no cluster e esta mensagem é mostrada.
The SECONDARY has left the cluster because application configuration sync is timed out on this unit. Disabling cluster now!
Cluster disable is performing cleanup..done.
Unit unit-2-1 is quitting due to system failure for 1 time(s) (last failure is SECONDARY application configuration sync timeout). Rejoin will be attempted after 5 minutes.
All data interfaces have been shutdown due to clustering being disabled. To recover either enable clustering or remove cluster group configuration.
Verificação/Mitigação:
- Use o comando show interface no FTD, para verificar se o MTU na interface de link de controle de cluster é pelo menos 100 bytes mais alto que o MTU da interface de dados:
firepower# show interface
Interface Port-channel1 "Inside", is up, line protocol is up
Hardware is EtherSVI, BW 40000 Mbps, DLY 10 usec
MAC address 3890.a5f1.aa5e, MTU 9084
Interface Port-channel48 "cluster", is up, line protocol is up
Hardware is EtherSVI, BW 40000 Mbps, DLY 10 usec
Description: Clustering Interface
MAC address 0015.c500.028f, MTU 9184
IP address 127.2.2.1, subnet mask 255.255.0.
- Faça um ping através do CCL, com a opção de tamanho, para verificar se o MTU do CCL está configurado corretamente em todos os dispositivos no caminho.
firepower# ping 127.2.1.1 size 9184
- Use o comando show interface no switch para verificar a configuração da MTU.
Switch# show interface
port-channel12 is up
admin state is up,
Hardware: Port-Channel, address: 7069.5a3a.7976 (bia 7069.5a3a.7976)
MTU 9084 bytes, BW 40000000 Kbit , DLY 10 usec
port-channel13 is up
admin state is up,
Hardware: Port-Channel, address: 7069.5a3a.7967 (bia 7069.5a3a.7967)
MTU 9084 bytes, BW 40000000 Kbit , DLY 10 use
Incompatibilidade de interface entre unidades de cluster
Sintomas:
A unidade não pode ingressar no cluster e esta mensagem é mostrada.
Interface mismatch between cluster primary and joining unit unit-2-1. unit-2-1 aborting cluster join.
Cluster disable is performing cleanup..done.
Unit unit-2-1 is quitting due to system failure for 1 time(s) (last failure is Internal clustering error). Rejoin will be attempted after 5 minutes.
All data interfaces have been shutdown due to clustering being disabled. To recover either enable clustering or remove cluster group configuration.
Verificação/Mitigação:
Faça login na GUI do FCM em cada chassi, navegue até a guia Interfaces e verifique se todos os membros do cluster têm a mesma configuração de interface.
- Interfaces atribuídas ao dispositivo lógico
- Velocidade de administração das interfaces
- Administração duplex das interfaces
- Status da interface
Problema de interface de dados/canal de porta
Dividir cérebro devido a problemas de acessibilidade na CCL
Sintoma:
Há várias unidades de controle no cluster. Considere esta topologia.
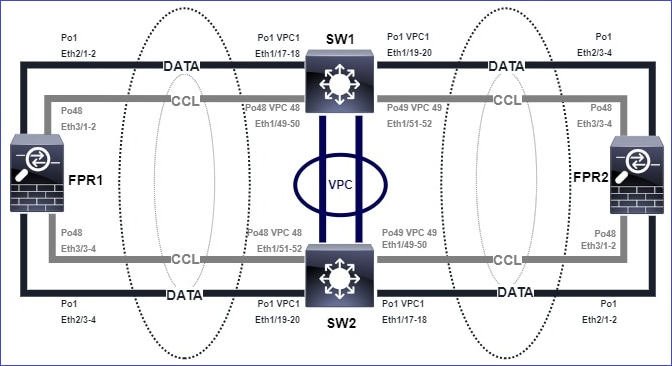
Gabinete 1:
firepower# show cluster info
Cluster ftd_cluster1: On
Interface mode: spanned
This is "unit-1-1" in state PRIMARY
ID : 0
Site ID : 1
Version : 9.15(1)
Serial No.: FLM2103TU5H
CCL IP : 127.2.1.1
CCL MAC : 0015.c500.018f
Last join : 07:30:25 UTC Dec 14 2020
Last leave: N/A
Other members in the cluster:
Unit "unit-1-2" in state SECONDARY
ID : 1
Site ID : 1
Version : 9.15(1)
Serial No.: FLM2103TU4D
CCL IP : 127.2.1.2
CCL MAC : 0015.c500.019f
Last join : 07:30:26 UTC Dec 14 2020
Last leave: N/A
Unit "unit-1-3" in state SECONDARY
ID : 3
Site ID : 1
Version : 9.15(1)
Serial No.: FLM2102THJT
CCL IP : 127.2.1.3
CCL MAC : 0015.c500.016f
Last join : 07:31:49 UTC Dec 14 2020
Last leave: N/A
Gabinete 2:
firepower# show cluster info
Cluster ftd_cluster1: On
Interface mode: spanned
This is "unit-2-1" in state PRIMARY
ID : 4
Site ID : 1
Version : 9.15(1)
Serial No.: FLM2103TUN1
CCL IP : 127.2.2.1
CCL MAC : 0015.c500.028f
Last join : 11:21:56 UTC Dec 23 2020
Last leave: 11:18:51 UTC Dec 23 2020
Other members in the cluster:
Unit "unit-2-2" in state SECONDARY
ID : 2
Site ID : 1
Version : 9.15(1)
Serial No.: FLM2102THR9
CCL IP : 127.2.2.2
CCL MAC : 0015.c500.029f
Last join : 11:18:58 UTC Dec 23 2020
Last leave: 22:28:01 UTC Dec 22 2020
Unit "unit-2-3" in state SECONDARY
ID : 5
Site ID : 1
Version : 9.15(1)
Serial No.: FLM2103TUML
CCL IP : 127.2.2.3
CCL MAC : 0015.c500.026f
Last join : 11:20:26 UTC Dec 23 2020
Last leave: 22:28:00 UTC Dec 22 2020
Verificação:
- Use o comando ping para verificar a conectividade entre os endereços IP do link de controle de cluster (CCL) das unidades de controle.
firepower# ping 127.2.1.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 127.2.1.1, timeout is 2 seconds:
?????
Success rate is 0 percent (0/5)
- Verifique a tabela ARP.
firepower# show arp
cluster 127.2.2.3 0015.c500.026f 1
cluster 127.2.2.2 0015.c500.029f 1
- Nas unidades de controle, configure e verifique capturas nas interfaces CCL.
firepower# capture capccl interface cluster
firepower# show capture capccl | i 127.2.1.1
2: 12:10:57.652310 arp who-has 127.2.1.1 tell 127.2.2.1
41: 12:11:02.652859 arp who-has 127.2.1.1 tell 127.2.2.1
74: 12:11:07.653439 arp who-has 127.2.1.1 tell 127.2.2.1
97: 12:11:12.654018 arp who-has 127.2.1.1 tell 127.2.2.1
126: 12:11:17.654568 arp who-has 127.2.1.1 tell 127.2.2.1
151: 12:11:22.655148 arp who-has 127.2.1.1 tell 127.2.2.1
174: 12:11:27.655697 arp who-has 127.2.1.1 tell 127.2.2.1
Atenuação:
- Certifique-se de que as interfaces de canal de porta CCL estejam conectadas a interfaces de canal de porta separadas no switch.
- Quando canais de porta virtual (vPC) são usados em switches Nexus, verifique se as interfaces de canal de porta CCL estão conectadas a vPC diferentes e se a configuração vPC não tem status de consistência com falha.
- Certifique-se de que as interfaces de canal de porta CCL estejam no mesmo domínio de broadcast e que a VLAN CCL seja criada e permitida nas interfaces.
Este é um exemplo de configuração de switch:
Nexus# show run int po48-49
interface port-channel48
description FPR1
switchport access vlan 48
vpc 48
interface port-channel49
description FPR2
switchport access vlan 48
vpc 49
Nexus# show vlan id 48
VLAN Name Status Ports
---- ----------- --------- -------------------------------
48 CCL active Po48, Po49, Po100, Eth1/53, Eth1/54
VLAN Type Vlan-mode
---- ----- ----------
48 enet CE
1 Po1 up success success 10,20
48 Po48 up success success 48
49 Po49 up success success 48
Nexus1# show vpc brief
Legend:
(*) - local vPC is down, forwarding via vPC peer-link
vPC domain id : 1
Peer status : peer adjacency formed ok
vPC keep-alive status : peer is alive
Configuration consistency status : success
Per-vlan consistency status : success
Type-2 consistency status : success
vPC role : primary
Number of vPCs configured : 3
Peer Gateway : Disabled
Dual-active excluded VLANs : -
Graceful Consistency Check : Enabled
Auto-recovery status : Disabled
Delay-restore status : Timer is off.(timeout = 30s)
Delay-restore SVI status : Timer is off.(timeout = 10s)
vPC Peer-link status
---------------------------------------------------------------------
id Port Status Active vlans
-- ---- ------ --------------------------------------------------
1 Po100 up 1,10,20,48-49,148
vPC status
----------------------------------------------------------------------
id Port Status Consistency Reason Active vlans
-- ---- ------ ----------- ------ ------------
1 Po1 up success success 10,20
48 Po48 up success success 48
49 Po49 up success success 48
Cluster desabilitado devido a interfaces de canal de porta de dados suspensas
Sintoma:
Uma ou mais interfaces de canal de porta de dados estão suspensas. Quando uma interface de dados habilitada administrativamente é suspensa, todas as unidades de cluster no mesmo chassi são removidas do cluster devido à falha de verificação de integridade da interface.
Considere esta topologia:
Verificação:
- Verifique o console da unidade de controle.
firepower#
Beginning configuration replication to SECONDARY unit-2-2
End Configuration Replication to SECONDARY.
Asking SECONDARY unit unit-2-2 to quit because it failed interface health check 4 times (last failure on Port-channel1). Clustering must be manually enabled on the unit to rejoin.
- Verifique a saída dos comandos show cluster history e show cluster info trace module hc nas unidades afetadas.
firepower# Unit is kicked out from cluster because of interface health check failure.
Cluster disable is performing cleanup..done.
All data interfaces have been shutdown due to clustering being disabled. To recover either enable clustering or remove cluster group configuration.
Cluster unit unit-2-1 transitioned from SECONDARY to DISABLED
firepower# show cluster history
==========================================================================
From State To State Reason
==========================================================================
12:59:37 UTC Dec 23 2020
ONCALL SECONDARY_COLD Received cluster control message
12:59:37 UTC Dec 23 2020
SECONDARY_COLD SECONDARY_APP_SYNC Client progression done
13:00:23 UTC Dec 23 2020
SECONDARY_APP_SYNC SECONDARY_CONFIG SECONDARY application configuration sync done
13:00:35 UTC Dec 23 2020
SECONDARY_CONFIG SECONDARY_FILESYS Configuration replication finished
13:00:36 UTC Dec 23 2020
SECONDARY_FILESYS SECONDARY_BULK_SYNC Client progression done
13:01:35 UTC Dec 23 2020
SECONDARY_BULK_SYNC DISABLED Received control message DISABLE (interface health check failure)
firepower# show cluster info trace module hc
Dec 23 13:01:36.636 [INFO]cluster_fsm_clear_np_flows: The clustering re-enable timer is started to expire in 598000 ms.
Dec 23 13:01:32.115 [INFO]cluster_fsm_disable: The clustering re-enable timer is stopped.
Dec 23 13:01:32.115 [INFO]Interface Port-channel1 is down
- Verifique a saída do comando show port-channel summary no shell de comando fxos.
FPR2(fxos)# show port-channel summary
Flags: D - Down P - Up in port-channel (members)
I - Individual H - Hot-standby (LACP only)
s - Suspended r - Module-removed
S - Switched R - Routed
U - Up (port-channel)
M - Not in use. Min-links not met
--------------------------------------------------------------------------
Group Port-Channel Type Protocol Member Ports
--------------------------------------------------------------------------
1 Po1(SD) Eth LACP Eth2/1(s) Eth2/2(s) Eth2/3(s) Eth2/4(s)
48 Po48(SU) Eth LACP Eth3/1(P) Eth3/2(P) Eth3/3(P) Eth3/4(P)
Atenuação:
- Certifique-se de que todos os chassis tenham o mesmo nome de grupo de cluster e senha.
- Certifique-se de que as interfaces port-channel tenham interfaces membro físicas ativadas administrativamente com a mesma configuração de duplex/velocidade em todos os chassis e switches.
- Em clusters entre locais, certifique-se de que a mesma interface de canal de porta de dados em todos os chassis esteja conectada à mesma interface de canal de porta no switch.
- Quando canais de porta virtual (vPC) são usados em switches Nexus, certifique-se de que a configuração do vPC não tenha um status de consistência com falha.
- Em clusters entre locais, assegure-se de que a mesma interface de canal de porta de dados em todos os chassis esteja conectada ao mesmo vPC.
Problemas de estabilidade de cluster
Traceback de FXOS
Sintoma:
A unidade deixa o cluster.
Verificação/Mitigação:
- Use o comando show cluster history para ver quando a unidade saiu do cluster.
firepower# show cluster history
- Use esses comandos para verificar se o FXOS tinha um traceback.
FPR4150# connect local-mgmt
FPR4150 (local-mgmt)# dir cores
- Colete o arquivo de núcleo gerado na hora em que a unidade deixou o cluster e forneça-o ao TAC.
Disco cheio
Caso a utilização do disco na partição /ngfw de uma unidade de cluster atinja 94%, a unidade sai do cluster. A verificação de utilização do disco ocorre a cada 3 segundos:
> show disk
Filesystem Size Used Avail Use% Mounted on
rootfs 81G 421M 80G 1% /
devtmpfs 81G 1.9G 79G 3% /dev
tmpfs 94G 1.8M 94G 1% /run
tmpfs 94G 2.2M 94G 1% /var/volatile
/dev/sda1 1.5G 156M 1.4G 11% /mnt/boot
/dev/sda2 978M 28M 900M 3% /opt/cisco/config
/dev/sda3 4.6G 88M 4.2G 3% /opt/cisco/platform/logs
/dev/sda5 50G 52M 47G 1% /var/data/cores
/dev/sda6 191G 191G 13M 100% /ngfw
cgroup_root 94G 0 94G 0% /dev/cgroups
Nesse caso, a saída do comando show cluster history mostra:
15:36:10 UTC May 19 2021
PRIMARY Event: Primary unit unit-1-1 is quitting
due to diskstatus Application health check failure, and
primary's application state is down
or
14:07:26 CEST May 18 2021
SECONDARY DISABLED Received control message DISABLE (application health check failure)
Outra maneira de verificar a falha é:
firepower# show cluster info health
Member ID to name mapping:
0 - unit-1-1(myself) 1 - unit-2-1
0 1
Port-channel48 up up
Ethernet1/1 up up
Port-channel12 up up
Port-channel13 up up
Unit overall healthy healthy
Service health status:
0 1
diskstatus (monitor on) down down
snort (monitor on) up up
Cluster overall healthy
Além disso, se o disco for ~100%, a unidade pode ter dificuldades para se juntar de volta ao cluster até que haja algum espaço em disco liberado.
Proteção contra estouro
A cada 5 minutos, cada unidade de cluster verifica o local e a unidade peer quanto à utilização da CPU e da memória. Se a utilização for maior que os limites do sistema (CPU LINA 50% ou memória LINA 59%), uma mensagem informativa será exibida em:
- Syslogs (FTD-6-748008)
- Arquivo log/cluster_trace.log, por exemplo:
firepower# more log/cluster_trace.log | i CPU
May 20 16:18:06.614 [INFO][CPU load 87% | memory load 37%] of module 1 in chassis 1 (unit-1-1) exceeds overflow protection threshold [CPU 50% | Memory 59%]. System may be oversubscribed on member failure.
May 20 16:18:06.614 [INFO][CPU load 87% | memory load 37%] of chassis 1 exceeds overflow protection threshold [CPU 50% | Memory 59%]. System may be oversubscribed on chassis failure.
May 20 16:23:06.644 [INFO][CPU load 84% | memory load 35%] of module 1 in chassis 1 (unit-1-1) exceeds overflow protection threshold [CPU 50% | Memory 59%]. System may be oversubscribed on member failure.
A mensagem indica que, em caso de falha de uma unidade, os outros recursos da(s) unidade(s) podem ter excesso de assinaturas.
Modo simplificado
Comportamento em versões anteriores à versão 6.3 do FMC:
- Registre cada nó de cluster individualmente no FMC.
- Em seguida, você forma um cluster lógico no FMC.
- Para cada nova adição de nó de cluster, você deve registrar o nó manualmente.
FMC após o 6.3:
- O recurso do modo simplificado permite registrar todo o cluster no FMC em uma etapa (basta registrar qualquer nó do cluster).
|
Gerente mínimo suportado |
Dispositivos gerenciados |
Mín. de Dispositivos Gerenciados com Suporte Versão Necessária |
Notas |
|
CVP 6.3 |
Clusters de FTD somente em FP9300 e FP4100 |
6.2.0 |
Este é um recurso apenas do FMC |
aviso: Depois que o cluster for formado no FTD, você precisará aguardar o início do registro automático. Você não deve tentar registrar os nós do cluster manualmente (Adicionar dispositivo), mas use a opção Reconciliar.
Sintoma:
Falhas de registro de nó
- Se o registro do nó de controle falhar por algum motivo, o cluster será excluído do FMC.
Atenuação:
Se o registro do nó de dados falhar por algum motivo, há duas opções:
- A cada implantação no cluster, o FMC verifica se há nós de cluster que precisam ser registrados e, em seguida, inicia o registro automático desses nós.
- Há uma opção Reconciliar disponível na guia de resumo do cluster (link Dispositivos > Gerenciamento de dispositivos > guia Cluster > Exibir status do cluster). Quando a ação Reconciliar é acionada, o FMC inicia o registro automático dos nós que precisam ser registrados.
Informações Relacionadas
- Organização por clusters para o Firepower Threat Defense
- Cluster ASA para o chassi Firepower 4100/9300
- Sobre clusters no chassi do Firepower 4100/9300
- Mergulho profundo na organização por clusters do NGFW Firepower - BRKSEC-3032
- Analisar as capturas do Firepower Firewall para solucionar problemas de rede com eficiência
Histórico de revisões
| Revisão | Data de publicação | Comentários |
|---|---|---|
5.0 |
23-Dec-2025
|
Atualizações de estilo, cabeçalhos. |
2.0 |
28-Jun-2023
|
Texto Alt adicionado.
Idioma com tendência substituído.
Requisitos de marca atualizados, SEO, tradução automática, requisitos de estilo, gramática e formatação. |
1.0 |
26-Jan-2021
|
Versão inicial |
Colaborado por engenheiros da Cisco
- Anita PietrzykEngenheiro do Cisco TAC
- Ilkin GasimovEngenheiro do Cisco TAC
- Mikis ZafeiroudisEngenheiro do Cisco TAC
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)