Conhecimento geral útil do HyperFlex
Opções de download
Linguagem imparcial
O conjunto de documentação deste produto faz o possível para usar uma linguagem imparcial. Para os fins deste conjunto de documentação, a imparcialidade é definida como uma linguagem que não implica em discriminação baseada em idade, deficiência, gênero, identidade racial, identidade étnica, orientação sexual, status socioeconômico e interseccionalidade. Pode haver exceções na documentação devido à linguagem codificada nas interfaces de usuário do software do produto, linguagem usada com base na documentação de RFP ou linguagem usada por um produto de terceiros referenciado. Saiba mais sobre como a Cisco está usando a linguagem inclusiva.
Sobre esta tradução
A Cisco traduziu este documento com a ajuda de tecnologias de tradução automática e humana para oferecer conteúdo de suporte aos seus usuários no seu próprio idioma, independentemente da localização. Observe que mesmo a melhor tradução automática não será tão precisa quanto as realizadas por um tradutor profissional. A Cisco Systems, Inc. não se responsabiliza pela precisão destas traduções e recomenda que o documento original em inglês (link fornecido) seja sempre consultado.
Contents
Introduction
Este documento descreve o conhecimento geral sobre o Cisco HyperFlex (HX) que os administradores devem ter ao seu alcance.
Acrônimos usados com frequência
SCVM = Máquina virtual do controlador de armazenamento
VMNIC = Virtual Machine Network Interface Card
VNIC = Virtual Network Interface Card
SED = Unidade de criptografia automática
VM = máquina virtual
HX = HyperFlex
Pedidos de VMNIC do HyperFlex VMware
O posicionamento da VMNIC foi revisado na versão HX 3.5 e posterior.
Pré-pedido da versão 3.5
Antes da versão 3.5, as VNICs eram atribuídas com base nos números de VNIC.
| VNIC | Switch virtual (vSwitch) |
| VNIC 0 e VNIC 1 | vSwitch-hx-inband-mgmt |
| VNIC 2 e VNIC 3 | vSwitch-hx-storage-data |
| VNIC 4 e VNIC 5 | vSwitch-hx-vm-network |
| VNIC 6 e VNIC 7 | vMotion |
Pós-pedido 3.5
Na versão 3.5 e posterior, as VNICs são atribuídas com base no endereço Media Access Control (MAC). Portanto, não há uma ordem de atribuição específica.
Se uma atualização de uma versão anterior a 3.5 para 3.5 ou superior for executada, o pedido de VMNIC será mantido.
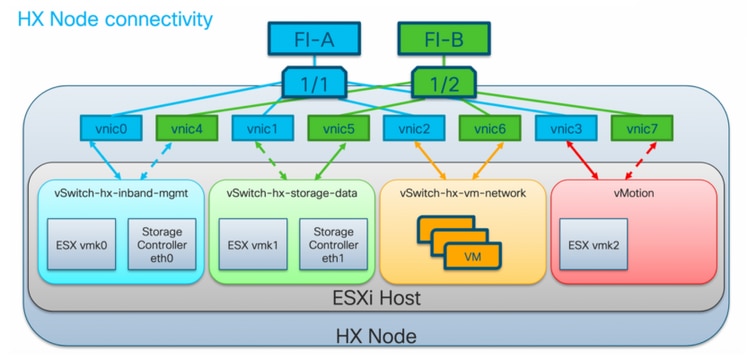
Note: Para o Hyper-V HX, isso não será aplicável, pois o Hyper-V usa um CD (Consistent Device Naming).
SCVM em nó convergente versus nó de computação
Os SCVMs residem nos nós convergentes e de computação e há diferenças entre eles.
Nó convergido
Reservas de recursos da CPU
Como os SCVMs fornecem funcionalidade crítica da plataforma de dados distribuídos Cisco HX, o instalador do HyperFlex configurará reservas de recursos de CPU para as VMs do controlador. Essa reserva garante que as VMs controladoras terão recursos da unidade central de processamento (CPU) em um nível mínimo, em situações em que os recursos físicos da CPU do host do hipervisor ESXi estão sendo bastante consumidos pelas VMs convidadas. Essa é uma garantia flexível, o que significa que na maioria das situações os SCVMs não estão usando todos os recursos de CPU reservados, permitindo, portanto, que as VMs convidadas os usem. A tabela a seguir detalha a reserva de recursos da CPU das VMs do controlador de armazenamento:
| Número de vCPU | Ações | Reserva | Limite |
| 8 | Baixa | 10800 MHZ | Ilimitado |
Reservas de recursos de memória
Como os SCVMs fornecem funcionalidade crítica da plataforma de dados distribuídos Cisco HX, o instalador do HyperFlex configurará reservas de recursos de memória para as VMs do controlador. Essa reserva garante que as VMs do controlador terão recursos de memória em um nível mínimo, em situações em que os recursos de memória física do host do hipervisor ESXi estão sendo bastante consumidos pelas VMs convidadas. A tabela a seguir detalha a reserva de recursos de memória das VMs do controlador de armazenamento:
| Modelos de servidor | Quantidade de memória de convidado | Reservar toda a memória do convidado |
| HX 220c-M5SX HXAF 220c-M5SX HX 220c-M4S HXAF220c-M4S |
48 GB | Yes |
| HX 240c-M5SX HXAF 240c-M5SX HX240c-M4SX HXAF240c-M4SX |
72 GB | Yes |
| HX240c-M5L | 78 GB | Yes |
Nó de computação
Os nós somente de computação têm um SCVM leve. Ele é configurado com apenas 1 vCPU de 1024 MHz e 512 MB de reserva de memória.
A finalidade de ter o nó de computação é principalmente manter as configurações do vCluster Distributed Resource Scheduler™ (DRS), para garantir que o DRS não mova as VMs do usuário de volta para nós convergentes.
Cenários de cluster não saudáveis
Um cluster HX pode se tornar não saudável nos seguintes cenários.
Cenário 1: Nó para baixo
Um cluster entra em um estado não saudável quando um nó fica inativo. Espera-se que um nó esteja inoperante durante uma atualização de cluster ou quando um servidor é colocado no modo de manutenção.
root@SpringpathController:~# stcli cluster storage-summary --detail
<snip>
current ensemble size:3
# of caching failures before cluster shuts down:2
minimum cache copies remaining:2
minimum data copies available for some user data:2
current healing status:rebuilding/healing is needed, but not in progress yet. warning: insufficient node or space resources may prevent healing. storage node 10.197.252.99is either down or initializing disks.
minimum metadata copies available for cluster metadata:2
# of unavailable nodes:1
# of nodes failure tolerable for cluster to be available:0
health state reason:storage cluster is unhealthy. storage node 10.197.252.99 is unavailable.
# of node failures before cluster shuts down:2
# of node failures before cluster goes into readonly:2
# of persistent devices failures tolerable for cluster to be available:1
# of node failures before cluster goes to enospace warn trying to move the existing data:na
# of persistent devices failures before cluster shuts down:2
# of persistent devices failures before cluster goes into readonly:2
# of caching failures before cluster goes into readonly:na
# of caching devices failures tolerable for cluster to be available:1
resiliencyInfo:
messages:
----------------------------------------
Storage cluster is unhealthy.
----------------------------------------
Storage node 10.197.252.99 is unavailable.
----------------------------------------
state: 2
nodeFailuresTolerable: 0
cachingDeviceFailuresTolerable: 1
persistentDeviceFailuresTolerable: 1
zoneResInfoList: None
spaceStatus: normal
totalCapacity: 3.0T
totalSavings: 5.17%
usedCapacity: 45.9G
zkHealth: online
clusterAccessPolicy: lenient
dataReplicationCompliance: non_compliant
dataReplicationFactor: 3
Cenário 2: Disco desativado
Um cluster entra em um estado não saudável quando um disco não está disponível. A condição deve apagar quando os dados são distribuídos para outros discos.
root@SpringpathController:~# stcli cluster storage-summary --detail
<snip>
current ensemble size:3
# of caching failures before cluster shuts down:2
minimum cache copies remaining:2
minimum data copies available for some user data:2
current healing status:rebuilding/healing is needed, but not in progress yet. warning: insufficient node or space resources may prevent healing. storage node is either down or initializing disks.
minimum metadata copies available for cluster metadata:2
# of unavailable nodes:1
# of nodes failure tolerable for cluster to be available:0
health state reason:storage cluster is unhealthy. persistent device disk [5000c5007e113d8b:0000000000000000] on node 10.197.252.99 is unavailable.
# of node failures before cluster shuts down:2
# of node failures before cluster goes into readonly:2
# of persistent devices failures tolerable for cluster to be available:1
# of node failures before cluster goes to enospace warn trying to move the existing data:na
# of persistent devices failures before cluster shuts down:2
# of persistent devices failures before cluster goes into readonly:2
# of caching failures before cluster goes into readonly:na
# of caching devices failures tolerable for cluster to be available:1
resiliencyInfo:
messages:
----------------------------------------
Storage cluster is unhealthy.
----------------------------------------
Persistent Device Disk [5000c5007e113d8b:0000000000000000] on node 10.197.252.99 is unavailable.
----------------------------------------
state: 2
nodeFailuresTolerable: 0
cachingDeviceFailuresTolerable: 1
persistentDeviceFailuresTolerable: 1
zoneResInfoList: None
spaceStatus: normal
totalCapacity: 3.0T
totalSavings: 8.82%
usedCapacity: 45.9G
zkHealth: online
clusterAccessPolicy: lenient
dataReplicationCompliance: non_compliant
dataReplicationFactor: 3
Cenário 3: Nenhum nó nem disco desativado
Um cluster pode entrar em um estado não saudável quando nem um nó nem um disco estão inativos. Essa condição ocorre se a reconstrução estiver em andamento.
root@SpringpathController:~# stcli cluster storage-summary --detail
<snip>
resiliencyDetails:
current ensemble size:5
# of caching failures before cluster shuts down:3
minimum cache copies remaining:3
minimum data copies available for some user data:2
current healing status:rebuilding is in progress, 98% completed. minimum metadata copies available for cluster metadata:2
time remaining before current healing operation finishes:7 hr(s), 15 min(s), and 34 sec(s)
# of unavailable nodes:0
# of nodes failure tolerable for cluster to be available:1
health state reason:storage cluster is unhealthy.
# of node failures before cluster shuts down:2
# of node failures before cluster goes into readonly:2
# of persistent devices failures tolerable for cluster to be available:1
# of node failures before cluster goes to enospace warn trying to move the existing data:na
# of persistent devices failures before cluster shuts down:2
# of persistent devices failures before cluster goes into readonly:2
# of caching failures before cluster goes into readonly:na
# of caching devices failures tolerable for cluster to be available:2
resiliencyInfo:
messages:
Storage cluster is unhealthy.
state: 2
nodeFailuresTolerable: 1
cachingDeviceFailuresTolerable: 2
persistentDeviceFailuresTolerable: 1
zoneResInfoList: None
spaceStatus: normal
totalCapacity: 225.0T
totalSavings: 42.93%
usedCapacity: 67.7T
clusterAccessPolicy: lenient
dataReplicationCompliance: non_compliant
dataReplicationFactor: 3
Como verificar um cluster SED usando a CLI (Command Line Interface, interface de linha de comando)
Se o acesso ao HX Connect não estiver disponível, o CLI pode ser usado para verificar se o cluster é SED.
# Check if the cluster is SED capable
root@SpringpathController:~# cat /etc/springpath/sed_capability.conf sed_capable_cluster=False
# Check if the cluster is SED enabled root@SpringpathController:~# cat /etc/springpath/sed.conf sed_encryption_state=unknown
root@SpringpathController:~# /usr/share/springpath/storfs-appliance/sed-client.sh -l WWN,Slot,Supported,Enabled,Locked,Vendor,Model,Serial,Size 5002538c40a42d38,1,0,0,0,Samsung,SAMSUNG_MZ7LM240HMHQ-00003,S3LKNX0K406548,228936 5000c50030278d83,25,1,1,0,MICRON,S650DC-800FIPS,ZAZ15QDM0000822150Z3,763097 500a07511d38cd36,2,1,1,0,MICRON,Micron_5100_MTFDDAK960TCB_SED,17261D38CD36,915715 500a07511d38efbe,4,1,1,0,MICRON,Micron_5100_MTFDDAK960TCB_SED,17261D38EFBE,915715 500a07511d38f350,7,1,1,0,MICRON,Micron_5100_MTFDDAK960TCB_SED,17261D38F350,915715 500a07511d38eaa6,3,1,1,0,MICRON,Micron_5100_MTFDDAK960TCB_SED,17261D38EAA6,915715 500a07511d38ce80,6,1,1,0,MICRON,Micron_5100_MTFDDAK960TCB_SED,17261D38CE80,915715 500a07511d38e4fc,5,1,1,0,MICRON,Micron_5100_MTFDDAK960TCB_SED,17261D38E4FC,915715
Modo de manutenção HX versus Modo de manutenção ESXi
Quando as atividades de manutenção precisam ser executadas em um servidor que faça parte de um cluster HX, o Modo de Manutenção HX deve ser usado em vez do Modo de Manutenção ESXi. O SCVM é desligado com facilidade quando o Modo de manutenção HX é usado enquanto é desligado abruptamente quando o Modo de manutenção ESXi é usado.
Enquanto um nó estiver no modo de manutenção, ele será considerado inativo, ou seja, falha de 1 nó.
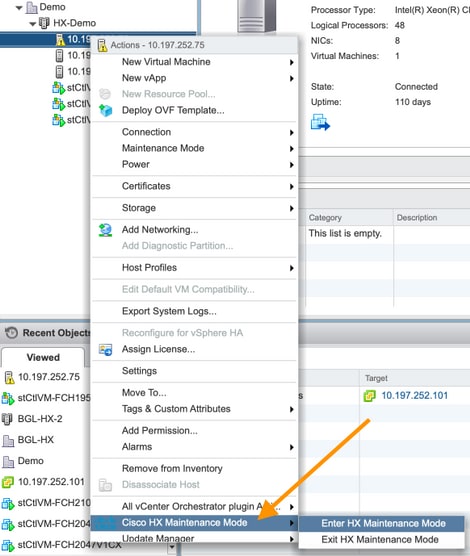
Certifique-se de que o cluster seja exibido como saudável antes de mover outro nó para o modo de manutenção.
root@SpringpathController:~# stcli cluster storage-summary --detail
<snip>
current ensemble size:3
# of caching failures before cluster shuts down:3
minimum cache copies remaining:3
minimum data copies available for some user data:3
minimum metadata copies available for cluster metadata:3
# of unavailable nodes:0
# of nodes failure tolerable for cluster to be available:1
health state reason:storage cluster is healthy.
# of node failures before cluster shuts down:3
# of node failures before cluster goes into readonly:3
# of persistent devices failures tolerable for cluster to be available:2
# of node failures before cluster goes to enospace warn trying to move the existing data:na
# of persistent devices failures before cluster shuts down:3
# of persistent devices failures before cluster goes into readonly:3
# of caching failures before cluster goes into readonly:na
# of caching devices failures tolerable for cluster to be available:2
resiliencyInfo:
messages:
Storage cluster is healthy.
state: 1
nodeFailuresTolerable: 1
cachingDeviceFailuresTolerable: 2
<snip>
Perguntas mais freqüentes
Onde os SCVMs estão instalados nos servidores Cisco HyperFlex M4 e M5?
O local SCVM é diferente entre os servidores Cisco Hyperflex M4 e M5. A tabela abaixo lista a localização do SCVM e fornece outras informações úteis.
| Servidor Cisco HX | ESXi | SCVM sda |
Unidade de estado sólido (SSD) em cache | SSD das famílias sdb1 e sdb2 |
| HX 220 M4 | Secure Digital (cartões SD) | 3,5G em cartões SD | Slot 2 | Slot 1 |
| HX 240 M4 | Cartões SD | No SSD controlado por PCH (o esxi controla isso) | Slot 1 | SSD controlado por PCH |
| HX 220 M5 | Unidade M.2 | Unidade M.2 | Slot 2 | Slot 1 |
| HX 240 M5 | Unidade M.2 | Unidade M.2 | Slot traseiro SSD | Slot 1 |
Quantos nós com falha um cluster pode tolerar?
O número de falhas que um cluster pode tolerar dependerá do Fator de Replicação e da Política de Acesso.
Clusters com 5 ou mais nós
Quando o fator de replicação (RF) é 3 e a política de acesso é definida como Lenient, se dois nós falharem, o cluster ainda estará em um estado de leitura/gravação. Se três nós falharem, o cluster será desligado.
| Fator de replicação | Política de acesso | Número de nós com falha | ||
| Leitura/gravação | Somente leitura | Fechamento | ||
| 3 | Lenient | 2 | — | 3 |
| 3 | Rígido | 1 | 2 | 3 |
| 2 | Lenient | 1 | — | 2 |
| 2 | Rígido | — | 1 | 2 |
Clusters com 3 e 4 nós
Quando o RF é 3 e a política de acesso é definida como Lenient ou Strict, se um único nó falhar, o cluster ainda estará em um estado de leitura/gravação. Se 2 nós falharem, o cluster será desligado.
| Fator de replicação | Política de acesso | Número de nós com falha | ||
| Leitura/gravação | Somente leitura | Fechamento | ||
| 3 | Lenient ou Strict | 1 | — | 2 |
| 2 | Lenient | 1 | — | 2 |
| 2 | Rígido | — | 1 | 2 |
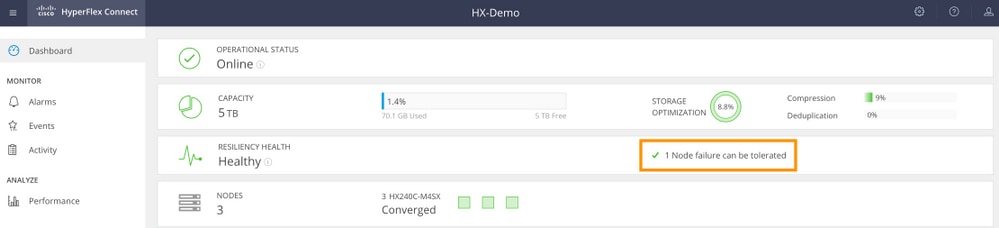
Exemplo de um cluster de 3 nós (RF: 3, Política de acesso: Lenient)
Exemplo de Interface Gráfica de Usuário (GUI)
Exemplo de CLI
root@SpringpathController:~# stcli cluster storage-summary --detail
<snip>
current ensemble size:3
# of caching failures before cluster shuts down:3
minimum cache copies remaining:3
minimum data copies available for some user data:3
minimum metadata copies available for cluster metadata:3
# of unavailable nodes:0
# of nodes failure tolerable for cluster to be available:1
health state reason:storage cluster is healthy.
# of node failures before cluster shuts down:3
# of node failures before cluster goes into readonly:3
# of persistent devices failures tolerable for cluster to be available:2
# of node failures before cluster goes to enospace warn trying to move the existing data:na
# of persistent devices failures before cluster shuts down:3
# of persistent devices failures before cluster goes into readonly:3
# of caching failures before cluster goes into readonly:na
# of caching devices failures tolerable for cluster to be available:2
resiliencyInfo:
messages:
Storage cluster is healthy.
state: 1
<snip>
clusterAccessPolicy: lenient
O que acontece se um dos SCVMs for desligado? As VMs continuam funcionando?
aviso: Esta não é uma operação suportada em um SCVM. Isso é apenas para fins de demonstração.
Note: Certifique-se de que apenas um SCVM esteja desativado por vez. Além disso, certifique-se de que o cluster esteja íntegro antes que um SCVM seja desligado. Esse cenário destina-se apenas a demonstrar que as VMs e os armazenamentos de dados devem funcionar, mesmo que uma SCVM esteja inativa ou indisponível.
As VMs continuarão funcionando normalmente. Abaixo está um exemplo de saída em que o SCVM foi desligado, mas os datastores permaneceram montados e disponíveis.
[root@node1:~] vim-cmd vmsvc/getallvms
Vmid Name File Guest OS Version Annotation
1 stCtlVM-F 9H [SpringpathDS-F 9H] stCtlVM-F 9H/stCtlVM-F 9H.vmx ubuntu64Guest vmx-13
[root@node1:~] vim-cmd vmsvc/power.off 1
Powering off VM:
[root@node1:~] vim-cmd vmsvc/power.getstate 1
Retrieved runtime info
Powered off
[root@node1:~] esxcfg-nas -l
Test is 10.197.252.106:Test from 3203172317343203629-5043383143428344954 mounted available
ReplSec is 10.197.252.106:ReplSec from 3203172317343203629-5043383143428344954 mounted available
New_DS is 10.197.252.106:New_DS from 3203172317343203629-5043383143428344954 mounted available
A versão do hardware VMware no SCVM foi atualizada. E agora?
aviso: Esta não é uma operação suportada em um SCVM. Isso é apenas para fins de demonstração.
Atualizar a versão do hardware VMware editando as configurações de VM em Compatibility > Upgrade VM Compatibility é que o vSphere Web Client NÃO é uma operação suportada em uma SCVM. O SCVM reportará como off-line no HX Connect.
root@SpringpathController0 UE:~# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 2.5G 0 disk `-sda1 8:1 0 2.5G 0 part / sdb 8:16 0 100G 0 disk |-sdb1 8:17 0 64G 0 part /var/stv `-sdb2 8:18 0 24G 0 part /var/zookeeper root@SpringpathController0 UE:~# lsscsi [2:0:0:0] disk VMware Virtual disk 2.0 /dev/sda [2:0:1:0] disk VMware Virtual disk 2.0 /dev/sdb root@SpringpathController0 UE:~# cat /var/log/springpath/diskslotmap-v2.txt 1.11.1:5002538a17221ab0:SAMSUNG:MZIES800HMHP/003:S1N2NY0J201389:EM19:SAS:SSD:763097:Inactive:/dev/sdc 1.11.2:5002538c405537e0:Samsung:SAMSUNG_MZ7LM3T8HMLP-00003:S 98:GXT51F3Q:SATA:SSD:3662830:Inactive:/dev/sdd 1.11.3:5002538c4055383a:Samsung:SAMSUNG_MZ7LM3T8HMLP-00003:S 88:GXT51F3Q:SATA:SSD:3662830:Inactive:/dev/sde 1.11.4:5002538c40553813:Samsung:SAMSUNG_MZ7LM3T8HMLP-00003:S 49:GXT51F3Q:SATA:SSD:3662830:Inactive:/dev/sdf 1.11.5:5002538c4055380e:Samsung:SAMSUNG_MZ7LM3T8HMLP-00003:S 44:GXT51F3Q:SATA:SSD:3662830:Inactive:/dev/sdg 1.11.6:5002538c40553818:Samsung:SAMSUNG_MZ7LM3T8HMLP-00003:S 54:GXT51F3Q:SATA:SSD:3662830:Inactive:/dev/sdh 1.11.7:5002538c405537d1:Samsung:SAMSUNG_MZ7LM3T8HMLP-00003:S 83:GXT51F3Q:SATA:SSD:3662830:Inactive:/dev/sdi 1.11.8:5002538c405537d8:Samsung:SAMSUNG_MZ7LM3T8HMLP-00003:S 90:GXT51F3Q:SATA:SSD:3662830:Inactive:/dev/sdj 1.11.9:5002538c4055383b:Samsung:SAMSUNG_MZ7LM3T8HMLP-00003:S 89:GXT51F3Q:SATA:SSD:3662830:Inactive:/dev/sdk 1.11.10:5002538c4055381f:Samsung:SAMSUNG_MZ7LM3T8HMLP-00003:S 61:GXT51F3Q:SATA:SSD:3662830:Inactive:/dev/sdl 1.11.11:5002538c40553823:Samsung:SAMSUNG_MZ7LM3T8HMLP-00003:S 65:GXT51F3Q:SATA:SSD:3662830:Inactive:/dev/sdm
Caution: Se esta operação foi executada acidentalmente, ligue para o Suporte da Cisco para obter assistência adicional. O SCVM precisará ser reimplantado.
Colaborado por engenheiros da Cisco
- Mohammed Majid HussainCisco CX
- Himanshu SardanaCisco CX
- Avinash ShuklaCisco CX
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)