Análise de impacto de interrupção de Ceph para StarOS VNF
Opções de download
Linguagem imparcial
O conjunto de documentação deste produto faz o possível para usar uma linguagem imparcial. Para os fins deste conjunto de documentação, a imparcialidade é definida como uma linguagem que não implica em discriminação baseada em idade, deficiência, gênero, identidade racial, identidade étnica, orientação sexual, status socioeconômico e interseccionalidade. Pode haver exceções na documentação devido à linguagem codificada nas interfaces de usuário do software do produto, linguagem usada com base na documentação de RFP ou linguagem usada por um produto de terceiros referenciado. Saiba mais sobre como a Cisco está usando a linguagem inclusiva.
Sobre esta tradução
A Cisco traduziu este documento com a ajuda de tecnologias de tradução automática e humana para oferecer conteúdo de suporte aos seus usuários no seu próprio idioma, independentemente da localização. Observe que mesmo a melhor tradução automática não será tão precisa quanto as realizadas por um tradutor profissional. A Cisco Systems, Inc. não se responsabiliza pela precisão destas traduções e recomenda que o documento original em inglês (link fornecido) seja sempre consultado.
Contents
Introduction
Este documento descreve como o VNF do StarOS, executado no Cisco Virtualized Infrastructure Manager (VIM), é afetado quando o serviço de armazenamento do Ceph é prejudicado, e o que pode ser feito para atenuar o impacto. Ele é explicado supondo que o Cisco VIM seja usado como uma infraestrutura, mas a mesma teoria pode ser aplicada a qualquer ambiente Openstack.
Pré-requisito
Requirements
A Cisco recomenda que você tenha conhecimento destes tópicos:
- Cisco StarOS
- Cisco VIM
- Openstack
- Ceph
Componentes Utilizados
As informações neste documento são baseadas nestas versões de software e hardware:
- StarOS: 21.16.c9
- Cisco VIM: 3.2.2 (Filas do Openstack)
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. Se a rede estiver ativa, certifique-se de que você entenda o impacto potencial de qualquer comando.
Abreviaturas
| Cisco VIM | Cisco Virtualized Infrastructure Manager |
| VNF | Função de rede virtual |
| Ceph OSD | Daemon De Armazenamento De Objeto Ceph |
| StarOS | Sistema operacional para a solução Cisco Mobile Packet Core |
Ceph no Cisco VIM
Esta imagem aqui é extraída do Cisco VIM Administrator Guide. O Cisco VIM usa Ceph como back-end de armazenamento.
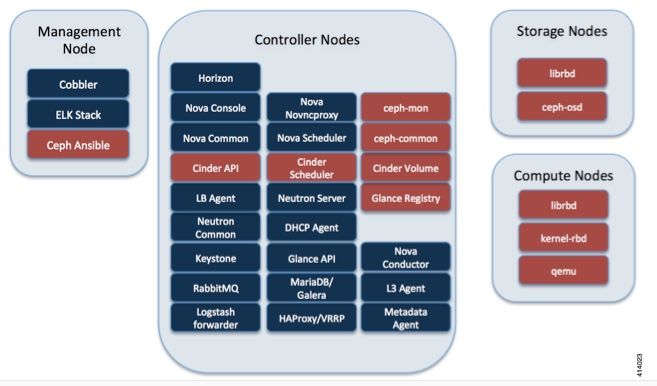
O Ceph suporta armazenamento de bloco e objeto e, portanto, é usado para armazenar imagens e volumes de VM que podem ser conectados a VMs. Vários serviços do OpenStack que dependem do back-end de armazenamento incluem:
- Glance (OpenStack image service) — Usa Ceph para armazenar imagens.
- Cinder (OpenStack Storage Service) — Usa Ceph para criar volumes que podem ser conectados a VMs.
- Nova (serviço de computação OpenStack) — Usa Ceph para se conectar aos volumes criados pela Cinder.
Em muitos casos, um volume é criado em Ceph para /flash e /hd-raid para VNF do StarOS, como o exemplo aqui.
openstack volume create --image `glance image-list | grep up-image | awk '{print $2}'` --size 16 --type LUKS up1-flash-boot
openstack volume create --size 20 --type LUKS up1-hd-raid
Conceitos básicos do mecanismo de monitoramento no Ceph
Aqui está a explicação do documento da Ceph sobre o monitoramento:
Cada daemon do Ceph OSD verifica a pulsação de outros Daemons do Ceph OSD em intervalos aleatórios menores que a cada 6 segundos. Se um daemon Ceph OSD vizinho não mostrar uma pulsação dentro de um período de graça de 20 segundos, o Daemon Ceph OSD pode considerar o daemon Ceph OSD vizinho inativo e relatá-lo de volta a um monitor Ceph, que atualiza o mapa do cluster Ceph. Por padrão, dois daemons do Ceph OSD de hosts diferentes devem informar aos Monitores Ceph que outro Daemon do Ceph OSD está inoperante antes que os Monitores Ceph confirmem que o Daemon do Ceph OSD relatado está inoperante.
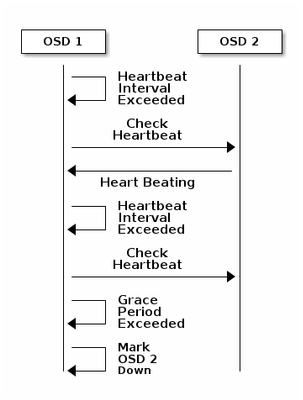
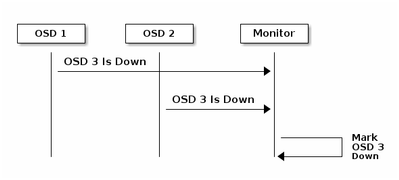
Portanto, em geral, leva cerca de 20 segundos para detectar OSD e o mapa de cluster do Ceph é atualizado, somente depois que esse VNF pode usar um novo OSD. Durante esse tempo, o I/O é bloqueado.
Impacto do bloqueio de E/S no StarOS VNF
Se a E/S do disco estiver bloqueada por mais de 120 segundos, o VNF do StarOS será reinicializado. Há uma verificação específica para os processos xfssyncd/md0 e xfs_db relacionados à I/O do disco e o StarOS reinicializa intencionalmente quando detecta um travamento nesses processos por mais de 120 segundos.
Log do console de depuração do StarOS:
[ 1080.859817] INFO: task xfssyncd/md0:25787 blocked for more than 120 seconds.
[ 1080.862844] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
[ 1080.866184] xfssyncd/md0 D ffff880c036a8290 0 25787 2 0x00000000
[ 1080.869321] ffff880aacf87d30 0000000000000046 0000000100000a9a ffff880a00000000
[ 1080.872665] ffff880aacf87fd8 ffff880c036a8000 ffff880aacf87fd8 ffff880aacf87fd8
[ 1080.876100] ffff880c036a8298 ffff880aacf87fd8 ffff880c0f2f3980 ffff880c036a8000
[ 1080.879443] Call Trace:
[ 1080.880526] [<ffffffff8123d62e>] ? xfs_trans_commit_iclog+0x28e/0x380
[ 1080.883288] [<ffffffff810297c9>] ? default_spin_lock_flags+0x9/0x10
[ 1080.886050] [<ffffffff8157fd7d>] ? _raw_spin_lock_irqsave+0x4d/0x60
[ 1080.888748] [<ffffffff812301b3>] _xfs_log_force_lsn+0x173/0x2f0
[ 1080.891375] [<ffffffff8104bae0>] ? default_wake_function+0x0/0x20
[ 1080.894010] [<ffffffff8123dc15>] _xfs_trans_commit+0x2a5/0x2b0
[ 1080.896588] [<ffffffff8121ff64>] xfs_fs_log_dummy+0x64/0x90
[ 1080.899079] [<ffffffff81253cf1>] xfs_sync_worker+0x81/0x90
[ 1080.901446] [<ffffffff81252871>] xfssyncd+0x141/0x1e0
[ 1080.903670] [<ffffffff81252730>] ? xfssyncd+0x0/0x1e0
[ 1080.905871] [<ffffffff81071d5c>] kthread+0x8c/0xa0
[ 1080.908815] [<ffffffff81003364>] kernel_thread_helper+0x4/0x10
[ 1080.911343] [<ffffffff81580805>] ? restore_args+0x0/0x30
[ 1080.913668] [<ffffffff81071cd0>] ? kthread+0x0/0xa0
[ 1080.915808] [<ffffffff81003360>] ? kernel_thread_helper+0x0/0x10
[ 1080.918411] **** xfssyncd/md0 stuck, resetting card
Mas não se limita ao temporizador de 120 segundos. Se a E/S do disco for bloqueada por um tempo, mesmo menos de 120 segundos, a VNF poderá ser reinicializada por vários motivos. A saída aqui é um exemplo que mostra uma reinicialização devido ao problema de E/S do disco, às vezes um travamento contínuo de tarefas do StarOS, e assim por diante. Depende da temporização de E/S de disco ativa em relação ao problema de armazenamento.
[ 2153.370758] Hangcheck: hangcheck value past margin!
[ 2153.396850] ata1.01: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x6 frozen
[ 2153.396853] ata1.01: failed command: WRITE DMA EXT
--- skip ---
SYSLINUX 3.53 0x5d037742 EBIOS Copyright (C) 1994-2007 H. Peter Anvin
Basicamente, uma E/S de bloqueio longo pode ser considerada um problema crítico para a VNF do StarOS e deve ser minimizada o máximo possível.
Cenários longos de E/S de bloqueio
Com base na pesquisa de implantações de vários clientes e testes de laboratório, há dois cenários principais identificados que podem causar um longo bloqueio de I/O no Ceph.
Mecanismo de temporizador retardado
Há um mecanismo de pulsação entre OSDs, para detectar OSD inativo. Com base no valor osd_heartbeat_Grace (20 segundos por padrão), o OSD é detectado como falha.
E há um mecanismo de temporizador retardado, quando há uma flutuação ou oscilação no status do OSD, o temporizador de tolerância é automaticamente ajustado (torna-se mais longo). Isso pode tornar o valor osd_heartbeat_Grace maior.
Na situação normal, a graça do heartbeat é de 20 segundos
2019-01-09 16:58:01.715155 mon.ceph-XXXXX [INF] osd.2 failed (root=default,host=XXXXX) (2 reporters from different host after 20.000047 >= grace 20.000000)
No entanto, após vários flaps de rede de um nó de armazenamento, ele se torna um valor maior.
2019-01-10 16:44:15.140433 mon.ceph-XXXXX [INF] osd.2 failed (root=default,host=XXXXX) (2 reporters from different host after 256.588099 >= grace 255.682576)
No exemplo acima, leva 256 segundos para detectar OSD como inativo.
Falha de hardware da placa RAID
O Ceph pode não ser capaz de detectar a falha de hardware da placa RAID em tempo hábil. A falha na placa RAID termina com um tipo de situação de travamento OSD. Nesse caso, o OSD inativo é detectado após alguns minutos, o que é suficiente para reinicializar o VNF do StarOS.
Quando a placa RAID trava, alguns núcleos da CPU levam 100% em status de espera.
%Cpu20 : 2.6 us, 7.9 sy, 0.0 ni, 0.0 id, 89.4 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu21 : 0.0 us, 0.3 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu22 : 31.3 us, 5.1 sy, 0.0 ni, 63.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu23 : 0.0 us, 0.0 sy, 0.0 ni, 28.1 id, 71.9 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu24 : 0.0 us, 0.0 sy, 0.0 ni, 0.0 id,100.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu25 : 0.0 us, 0.0 sy, 0.0 ni, 0.0 id,100.0 wa, 0.0 hi, 0.0 si, 0.0 st
E ele come todos os núcleos da CPU gradualmente e o OSD também cai gradualmente com algum intervalo de tempo.
2019-01-01 17:08:05.267629 mon.ceph-XXXXX [INF] Marking osd.2 out (has been down for 602 seconds)
2019-01-01 17:09:25.296955 mon.ceph-XXXXX [INF] Marking osd.4 out (has been down for 603 seconds)
2019-01-01 17:11:10.351131 mon.ceph-XXXXX [INF] Marking osd.7 out (has been down for 604 seconds)
2019-01-01 17:16:40.426927 mon.ceph-XXXXX [INF] Marking osd.10 out (has been down for 603 seconds)
Em paralelo, solicitações lentas são detectadas em ceph.log.
2019-01-01 16:57:26.743372 mon.XXXXX [WRN] Health check failed: 1 slow requests are blocked > 32 sec. Implicated osds 2 (REQUEST_SLOW)
2019-01-01 16:57:35.129229 mon.XXXXX [WRN] Health check update: 3 slow requests are blocked > 32 sec. Implicated osds 2,7,10 (REQUEST_SLOW)
2019-01-01 16:57:38.055976 osd.7 osd.7 [WRN] 1 slow requests, 1 included below; oldest blocked for > 30.216236 secs
2019-01-01 16:57:39.048591 osd.2 osd.2 [WRN] 1 slow requests, 1 included below; oldest blocked for > 30.635122 secs
-----skip-----
2019-01-01 17:06:22.124978 osd.7 osd.7 [WRN] 78 slow requests, 1 included below; oldest blocked for > 554.285311 secs
2019-01-01 17:06:25.114453 osd.4 osd.4 [WRN] 19 slow requests, 1 included below; oldest blocked for > 546.221508 secs
2019-01-01 17:06:26.125459 osd.7 osd.7 [WRN] 78 slow requests, 1 included below; oldest blocked for > 558.285789 secs
2019-01-01 17:06:27.125582 osd.7 osd.7 [WRN] 78 slow requests, 1 included below; oldest blocked for > 559.285915 secs
O gráfico aqui mostra quanto tempo as solicitações de I/O são bloqueadas com um cronograma. O gráfico é criado com o plotamento dos registros de solicitações lentas em ceph.log. Isso mostra que o tempo de bloqueio está ficando mais longo com o tempo.
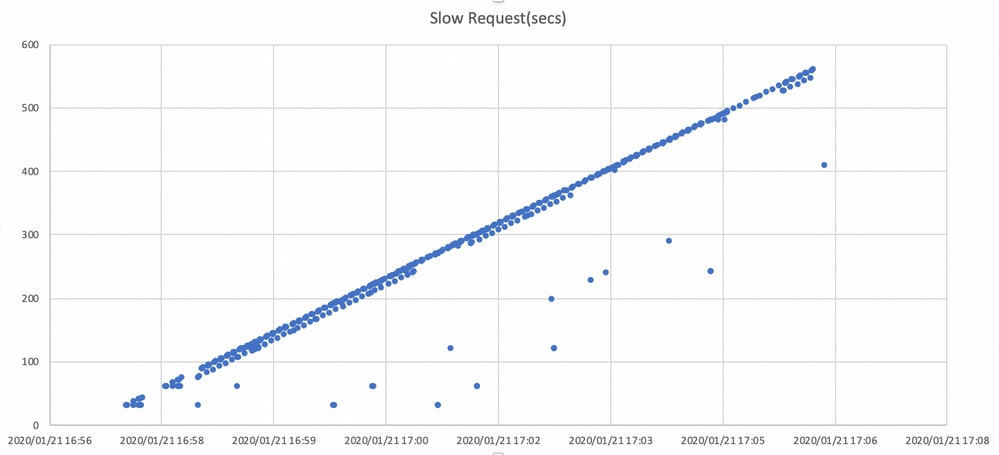
Como atenuar o impacto?
Mover para disco local do armazenamento da Ceph
A maneira mais simples de atenuar o impacto é mover para um disco local do armazenamento da Ceph. O StarOS usa 2 discos, /flash e /hd-raid, é possível mover somente /flash para o disco local, o que torna o VNF do StarOS mais robusto para os problemas do Ceph. O lado negativo do uso do armazenamento compartilhado, como o Ceph, é que todo o VNF que o utiliza é afetado ao mesmo tempo em que ocorre um problema. Usando o disco local, o impacto do problema de armazenamento pode ser minimizado para a VNF sendo executada somente no nó afetado. E os cenários mencionados na seção anterior aplicam-se somente ao Ceph, portanto, não se aplicam ao disco local. Mas o outro lado do disco local é que o conteúdo do disco, como imagem do StarOS, configuração, arquivo central, registro de cobrança, não pode ser reinstalado quando a VM é reimplantada. Ele também pode afetar o mecanismo de autorrecuperação de VNF.
Ajuste Da Configuração Do Ceph
Do ponto de vista da VNF do StarOS, os seguintes novos parâmetros de Ceph são recomendados para minimizar o tempo de I/O de bloqueio mencionado acima.
<configurações padrão>
"mon_osd_adjust_heartbeat_grace": "true",
"osd_client_watch_timeout": "30",
"osd_max_markdown_count": "5",
"osd_heartbeat_grace": "20",
<novas configurações>
"mon_osd_adjust_heartbeat_grace": "false",
"osd_client_watch_timeout": "10",
"osd_max_markdown_count": "1",
"osd_heartbeat_grace": "10",
Ele consiste em:
- O mecanismo do temporizador retardado está desativado, sem ajuste automático
- O tempo de carência do heartbeat é reduzido
- O OSD está marcado como inativo imediatamente (por padrão 5 vezes nos últimos 600 segundos)
Os novos parâmetros são testados em um laboratório, o tempo de detecção de OSD inativo é reduzido para aproximadamente menos de 10 segundos, originalmente foi de cerca de 30 segundos com a configuração padrão de Ceph.
Problema de hardware da placa RAID do monitor
Para o cenário de hardware da placa RAID, pode ser difícil detectar em tempo hábil a natureza do problema, pois cria uma situação em que o OSD está trabalhando intermitentemente enquanto a E/S está bloqueada. Não há uma solução única para isso, mas é recomendável monitorar o registro de hardware do servidor quanto a uma falha na placa RAID ou o registro lento de solicitação no ceph.log por algum script e tomar algumas medidas, como tornar o OSD afetado inativo de forma proativa.
Ajuste CEPH_OSD_RESEREVED_PCORES
Isso não está relacionado aos cenários mencionados, mas se houver um problema com o desempenho do Ceph devido à operação pesada de E/S, aumentar o valor do CEPH_OSD_RESEREVED_PCORES pode melhorar o desempenho de E/S do Ceph. Por padrão, CEPH_OSD_RESEREVED_PCORES no Cisco VIM é configurado como 2 e pode ser aumentado.
Colaborado por engenheiros da Cisco
- Tomonobu OkadaCisco TAC Engineer
- Satoshi KinoshitaCisco TAC Engineer
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)