Inleiding
Dit document beschrijft hoe Instant Message and Presence (IM&P) High Availability werkt in een IM&P-omgeving voor ondernemingen en hoe u problemen kunt oplossen.
Voorwaarden
Vereisten
Cisco raadt kennis van de volgende onderwerpen aan:
- Cisco Unified IP-telefoon 7920
- Cisco Jabber-clients
Gebruikte componenten
- Cisco Unified IM&P 10.0 en hoger
- Cisco Jabber-clients 9.6 en hoger
De informatie in dit document is gemaakt op basis van de componenten in een specifieke laboratoriumomgeving. Alle componenten die in dit document worden gebruikt, zijn gestart met een uitgeschakelde (standaard) configuratie. Als uw netwerk live is, moet u zorgen dat u de potentiële impact van elke opdracht begrijpt.
Hoge beschikbaarheid van IM en Presence (HA)
De IM en Presence Service Server biedt hoge beschikbaarheid of redundantie in de vorm van logische servergroepen in de CUCM-configuratie. Deze configuratie wordt doorgegeven aan IM en Presence en vervolgens gebruikt om redundantie mogelijk te maken in het geval van een IM en Presence Service of serveruitval. Wanneer een HA-gebeurtenis plaatsvindt, worden de sessies van de eindgebruiker verplaatst van de mislukte server naar de back-up. Wanneer de server is hersteld naar een normale status, worden de gebruikerssessies automatisch of handmatig door de beheerder terugverplaatst.
Configuratie van redundantiegroep
De redundantiegroep is het logische serverpaar dat de toewijzing van een server aan de IM en Presence subcluster mogelijk maakt, evenals de configuratie voor HA. Om toegang te krijgen tot dit deel van de configuratie, vind het op de CUCM server webpagina.
Systeem > Aanwezigheidsgroepen
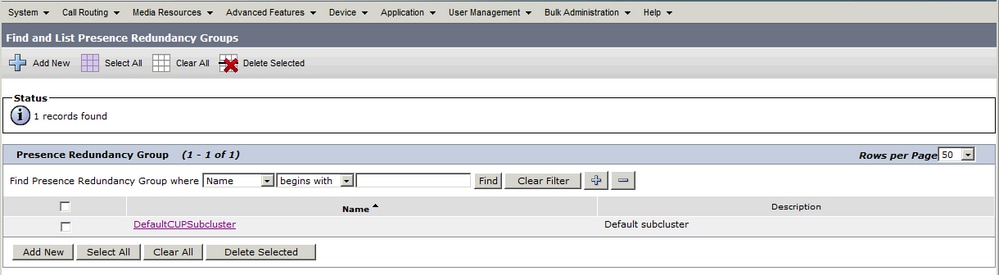
Wanneer de beheerder de IM&P-uitgever toevoegt aan de configuratie System > Server op CUCM en de IM&P-server wordt opgeslagen, wordt de DefaultCUPSubCluster-redundantiegroep gemaakt en wordt de uitgever eraan toegewezen.
Wanneer gemaakt, ziet de Redundantiegroep er als volgt uit:
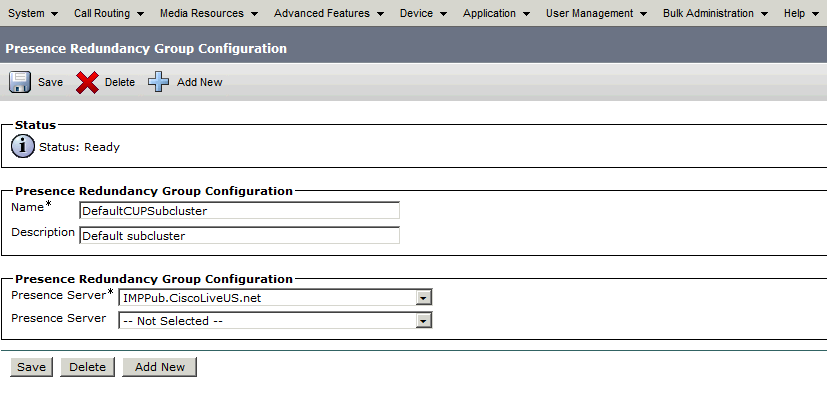
Deze Redundantiegroep wordt vertaald naar de IM en Presence subcluster. In de huidige staat van de configuratie van de Redundantiegroep in CUCM, zou dit zijn wat het zou zijn als in de IM en Presence Cluster Topology webpagina:
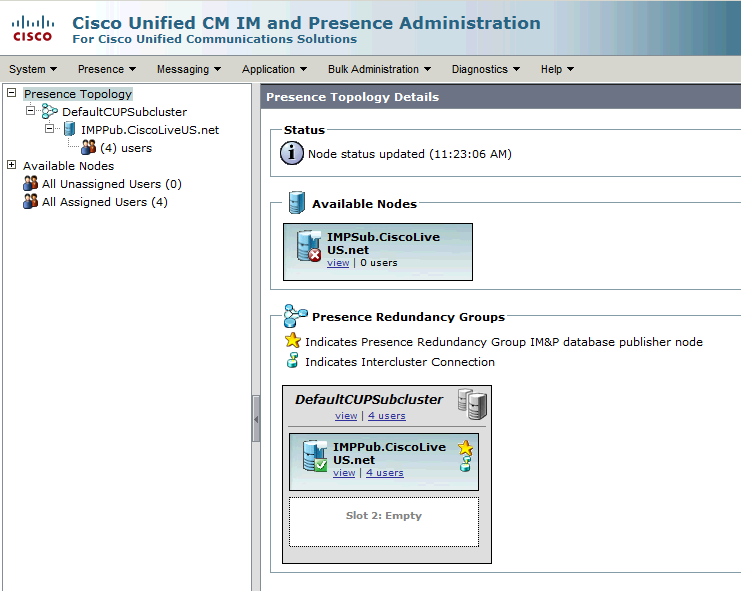
U ziet dat de IM&P Publisher wordt toegewezen aan de DefaultCUPSubcluster en dat de Subscriber-server dat niet is. Dit komt doordat de IM&P Subscriber server niet is toegewezen aan de Redundantie Group in de CUCM-configuratie.
Wijs de abonnee toe aan de redundantiegroep.
Als u de Subscriber-server aan de Redundantie-groep wilt toewijzen, kiest u de Subscriber-server in het vervolgkeuzemenu en slaat u de configuratiewijziging op.
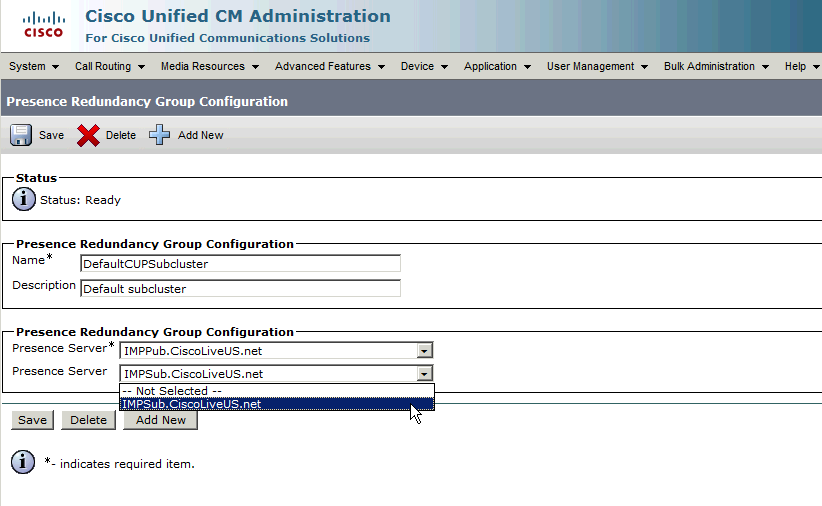
Nadat de IM&P-abonnee is toegevoegd aan de redundantiegroep:
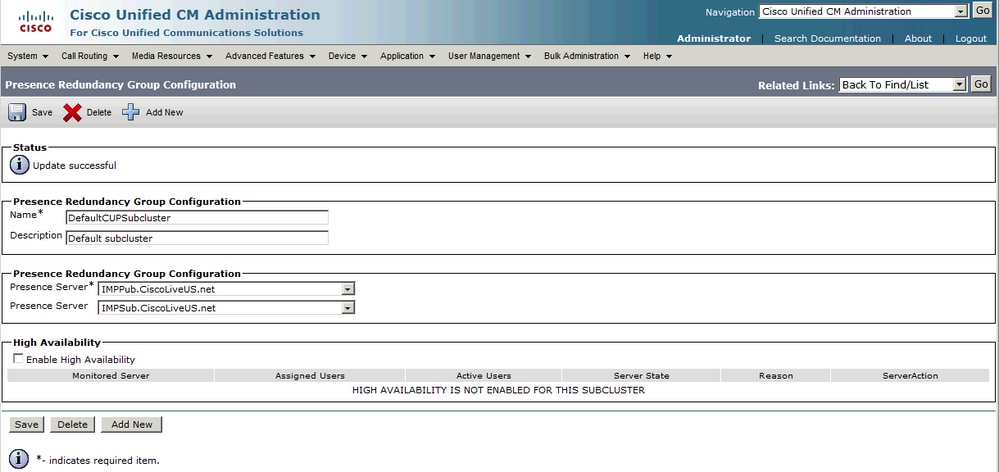
U ziet na de toevoeging van het secundaire knooppunt (de abonnee) dat de optie Hoge beschikbaarheid kan worden geselecteerd. Om High Availability in te schakelen, hoeft u alleen het aanvinkvakje Enable High Availability te kiezen en de configuratiewijziging op te slaan.
Nadat hoge beschikbaarheid is ingeschakeld:
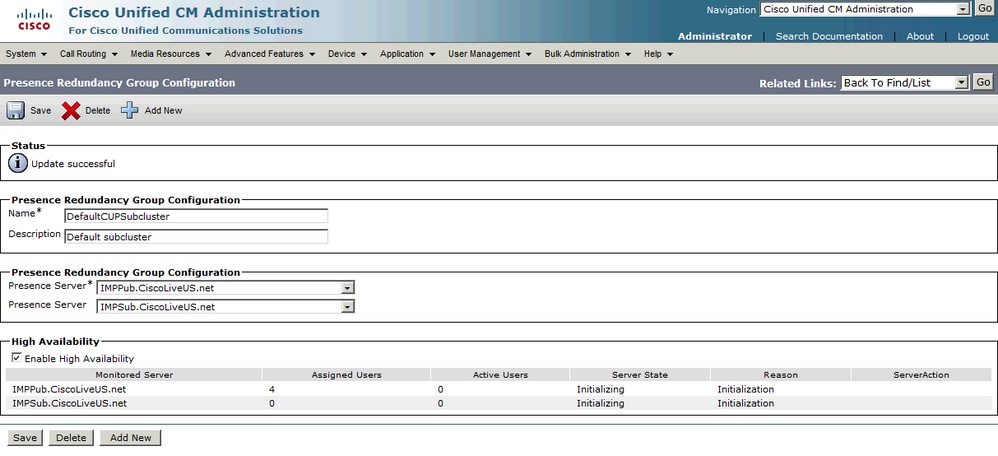
De pagina wordt vervolgens automatisch aangepast aan de serverstatus en de reden. Wanneer de server zich in een initialiseringsstatus bevindt, betekent dit dat de twee servers kunnen communiceren. De servers zouden vervolgens de servicestatus controleren voordat de status overgaat naar de status Normaal. Als de twee servers met elkaar kunnen verbinden en alle bewaakte services op beide zijn ingeschakeld, dan krijgt u een Normaal-Normale status. Dit betekent dat alle bewaakte services actief zijn op de IM&P servers.
Status normale redundantiegroep:
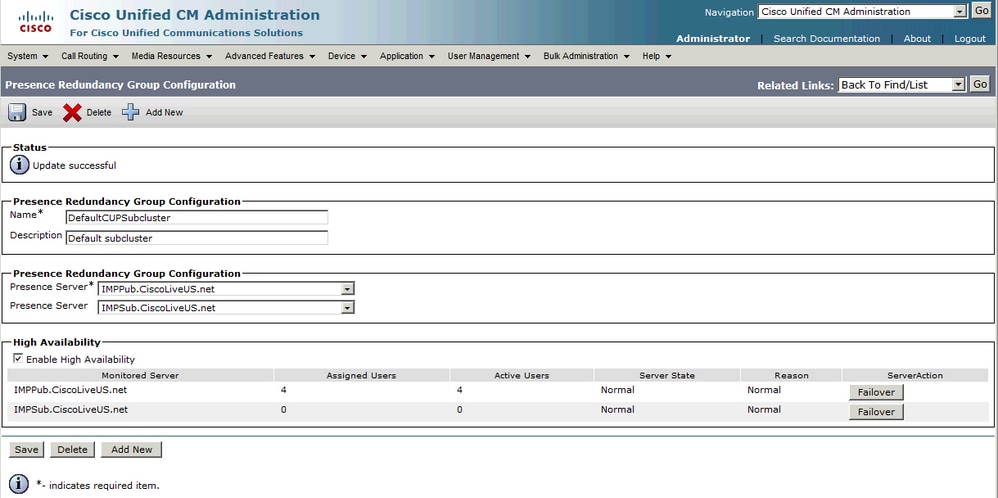
Normal-Normal Hoge Beschikbaarheidsstaat in de de Topologiepagina van IM&P:
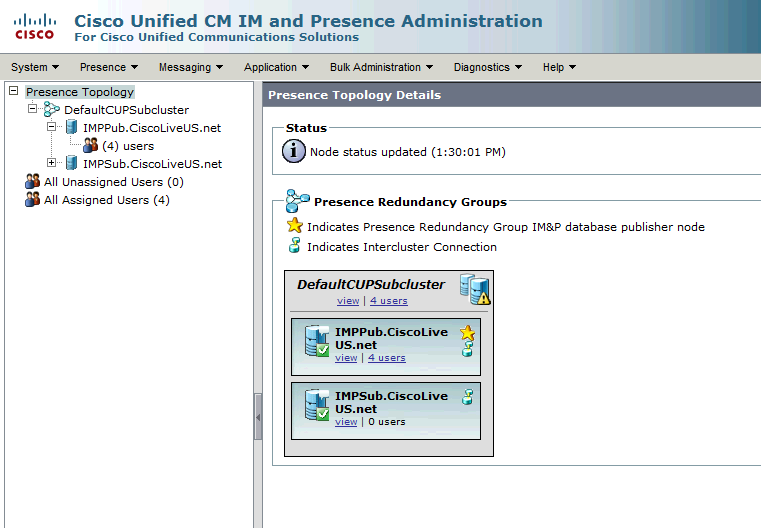
Gemonitorde IM- en Presence-services
Aangezien u verschillende implementatiemodellen zou kunnen hebben: IM Only, IM met SIP/XMPP Federation, IM met Compliance, IM met persistente chat, Remote Call Control Only, enzovoort, is de feitelijke lijst van welke van deze te monitoren processen dynamisch. Standaard worden deze items altijd gevolgd wanneer HA is ingeschakeld:
- IDS-database
- Aanwezigheidsmotor (indien geactiveerd)
- XCP router
De Server Recovery Manager controleert of naleving (Message Archiver), persistent chat (Text Conference Manager), SIP federatie (SIP Federation Connection Manager), XMPP federation (XMPP Federation Connection Manager) zijn geconfigureerd en geactiveerd.
Als deze services zowel worden geconfigureerd als geactiveerd, controleert de Server Recovery Manager (SRM) deze services ook.
Waarschuwing: voordat u doorgaat met het opnieuw opstarten van een of meer van de gecontroleerde services, moet u de hoge beschikbaarheid uitschakelen van de Presence Redundantie Groepen op de CUCM-server. Hetzelfde geldt wanneer een herstart van een of meer van de IM&P-knooppunten wordt uitgevoerd.
Gebruikersfailover-proces
Wanneer een failover plaatsvindt (automatisch of handmatig), is het belangrijkste te onthouden punt dat de gebruikersaccount niet van de ene server naar de andere wordt verplaatst, maar alleen de gebruikerssessie in Presence Engine wordt verplaatst. In pre-10 versies van IM en Presence, werd de gebruikerstoewijzing verplaatst van één server aan andere. Deze gebruikersbeweging was erg duur voor serverresources en werd toegevoegd aan de belasting die op de server lag. In 10.x en later, blijft de gebruiker gehuisvest op de server waaraan zij worden toegewezen, en de backend gebruikerszitting in de Presence Engine wordt verplaatst van de mislukte knooppunt naar de functionele knooppunt. De gebruiker hoeft Jabber niet te verlaten en opnieuw in te loggen wanneer de wijziging gebeurt met Server Recovery Manager (SRM).
Jabber-client opnieuw inloggen-timer
Om de gebruikerssessie na een failover-gebeurtenis volledig actief te laten worden op de secundaire IM&P-knooppunt, moet de gebruiker proberen in te loggen op die server via SOAP (Client Profile Agent). Dit gebeurt automatisch met het eenmalige wachtwoord dat uit de IMDB-database wordt doorgegeven. Omdat logins zeer duur zijn voor resources op de IM en Presence server, moet er een manier zijn om logins te verstikken wanneer er een failover-gebeurtenis optreedt. Met deze throttle of buffer kunnen alle gebruikers inloggen op het secundaire knooppunt zonder serviceonderbreking voor gebruikers op het secundaire knooppunt. De mechanismen die worden gebruikt om gebruikerslogins te beperken, zijn de serviceparameters Client Re-Login Lower Limit en Client Re-Login Upper Limit Server Recovery Manager (SRM).
Client Re-Login Lower Limit - de parameter die de minimale hoeveelheid tijd (in seconden) definieert die de Jabber-client wacht voordat de client probeert in te loggen op de secundaire server in het geval van een HA-gebeurtenis.
Client Re-Login Upper Limit - de parameter die de maximale tijd (in seconden) definieert die de Jabber-client wacht voordat de client probeert in te loggen op de secundaire server in het geval van een HA-gebeurtenis.
De Jabber-client ontvangt deze parameters bij inloggen op de server en caches de waarden voor toekomstig gebruik. Wanneer u een HA-gebeurtenis van de IM&P-server ontvangt, kiest de client een willekeurig aantal seconden tussen de bovenste en onderste limieten en wacht op die hoeveelheid tijd voordat de Jabber-client probeert in te loggen op de secundaire. Wanneer de timer is verlopen, probeert de client vervolgens via SOAP in te loggen op het secundaire knooppunt.
Fallback-types van IM en Presence
Als er sprake is van een gebruikersfailover, moet er een gebruikersfeedback zijn wanneer de service wordt hersteld op de probleemserver. Er zijn twee soorten serverfallback:
Handmatige feedback
Handmatige uitval (standaardconfiguratie voor Server Recovery Manager) vindt plaats wanneer de service is hersteld en de redundantiegroep de uitwijkknop inschakelt. Wanneer deze knop is geselecteerd, worden de gebruikerssessies die naar het secundaire knooppunt zijn verplaatst, teruggezet naar het hoofdknooppunt. De Jabber-client past vervolgens de boven- en ondergrens voor het opnieuw inloggen voor de fall-back toe.
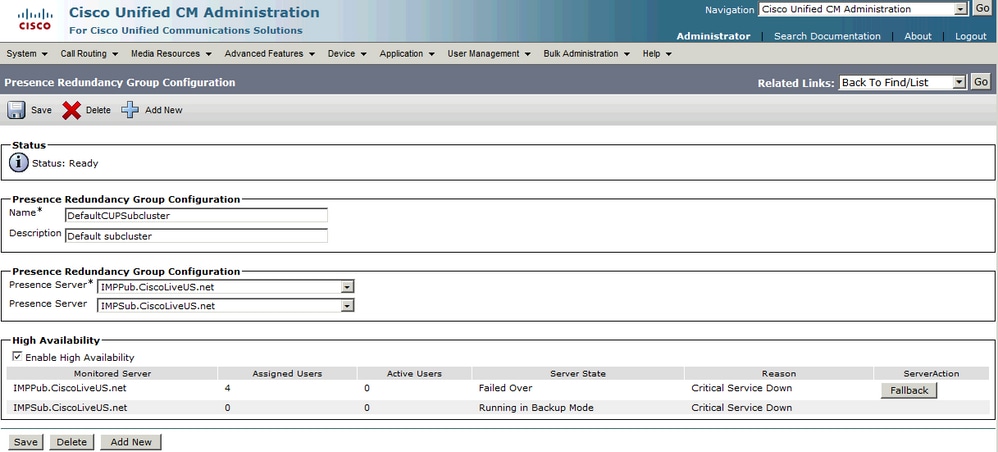
Automatische fallback
Automatische fallback vindt plaats wanneer de server de services bewaakt en de Server Recovery Manager (SRM) service automatisch fallback gebruikers naar hun startpunten. De sleutel in deze configuratie is dat de Server Recovery Manager (SRM) service 30 minuten wacht voordat een mislukte service/server actief blijft voordat een automatische back wordt gestart. Nadat deze uptime van 30 minuten is ingesteld, worden gebruikerssessies terugverplaatst naar hun startpunten. De Jabber-client past vervolgens de boven- en ondergrens voor het opnieuw inloggen voor de fall-back toe.

Opmerking: automatische fallback is niet de standaardconfiguratie, maar kan worden ingeschakeld. Als u automatische fallback wilt inschakelen, wijzigt u de parameter Enable Automatic Fallback in de Service Parameters van Server Recovery Manager om True te waarderen.
Problemen oplossen
Deze sectie bevat informatie voor het troubleshooten van de configuratie.
Wanneer het oplossen van problemen Hoge beschikbaarheid op de IM&P Service Server, zijn er twee belangrijke timers die u in overweging moet houden.
- De servers wisselen elke 60 seconden 4 keepalives uit. Als er na de 60 seconden geen respons is, is de Cisco Service Recovery Manager (SRM) van mening dat het knooppunt zonder respons off-line is gegaan en een Fail Over-opdracht activeert. Zoals het volgende fragment laat zien, gebeurde de laatste hartslag 62 seconden geleden.
2021-05-13 02:48:48,244 INFO[HS]rsrm.RsrmHeartBeatHandler - RsrmHeartBeatHandler: peer down, time since last heartbeat[s]= 62
2021-05-13 02:48:48,244 INFO [HS] rsrm.RsrmAutomaticFallback - RsrmAutomaticFallback: peer states vector changed to [Normal,Running in Backup Mode]
Tip: voor dit scenario, als u enige latentie in uw netwerk hebt gevonden, wordt aanbevolen om de hartslagtijd timer te verhogen van 60 tot 90 seconden.
Ga naar de CUCM-webpagina voor beheer > Systeem > Configuratie van serviceparameters > Selecteer de IM&P-server> Selecteer Cisco Recovery Manager Settings. Op de Keep Alive (Heartbeat) time-out, verhoog het aantal naar 90 seconden.
- De IM&P Subscriber server wacht 90 seconden. Als het detecteert dat een of meer van de gecontroleerde services is uitgeschakeld, neemt de Subscriber-server het over.
Te verzamelen logbestanden voor probleemoplossing
- Server Recover Manager (SRM) logbestanden van voor en na de failover-gebeurtenis (debug niveau indien mogelijk).
- De output van de opdracht via IM&P opdrachtregel voert sql selectie * uit ondernemingensubcluster uit.
- In de ondernemingensubclustertabel in IM&P staat de Redundantie Group-configuratie.
- De output van de opdracht via IM&P opdrachtregel voert sql selecteerde * uit enterprisenode.
- In de ondernemingstabel worden de nodegegevens en de subclustertoewijzing van de knooppunt weergegeven.
- Als het failover wordt geproduceerd door een service die wordt gestopt, verzamel dan:
- Systeemlogboeken voor de gebeurtenisviewer
- Toepassingslogs voor Event Viewer
- Logbestanden vanaf de service die worden gestopt.
 Feedback
Feedback