소개
이 문서에서는 RCM의 /dev/vda3 파일 시스템에 대한 높은 디스크 공간 사용률 문제를 해결하는 방법에 대해 설명합니다.
사전 요구 사항
요구 사항
Cisco에서는 다음 사항에 대해 알고 있는 것이 좋습니다.
- StarOS 제어 및 CUPS(User Plane Separation) 시스템 아키텍처 및 관리.
- 파일 시스템 및 디스크 사용량 모니터링을 위한 기본 Linux/Unix 명령
사용되는 구성 요소
이 문서는 특정 소프트웨어 및 하드웨어 버전으로 한정되지 않습니다.
이 문서의 정보는 특정 랩 환경의 디바이스를 토대로 작성되었습니다. 이 문서에 사용된 모든 디바이스는 초기화된(기본) 컨피그레이션으로 시작되었습니다. 현재 네트워크가 작동 중인 경우 모든 명령의 잠재적인 영향을 미리 숙지하시기 바랍니다.
개요
Control 및 CUPS(User Plane Separation)가 있는 Cisco Ultra Packet Core 구축에서는 RCM(Redundancy Control Manager)이 컨트롤 플레인 운영 및 관리에 중요한 역할을 합니다. RCM 노드의 안정적인 파일 시스템 활용은 로깅, 모니터링 및 가입자 세션 관리의 원활한 기능을 보장하는 데 중요합니다.
루트 파일 시스템(/dev/vda3)의 디스크 공간 사용률이 높으면 시스템이 불안정해지거나, 로그 쓰기가 실패하거나, 선택하지 않은 경우 서비스가 다시 시작될 수 있습니다. RCM 노드의 높은 디스크 사용률을 해결하기 위한 분석, 문제 해결 단계 및 예방 조치에 대해 간략하게 설명합니다(영문).
분석 및 관찰
모니터링 중에 RCM 노드의 루트 파일 시스템 사용률이 72%에 달하는 것으로 나타났습니다.
디스크 사용률 스냅샷
df -kh
Filesystem Size Used Avail Use% Mounted on
tmpfs 6.3G 9.7M 6.3G 1% /run
/dev/vda3 39G 27G 11G 72% /
tmpfs 32G 4.0K 32G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/vda2 488M 48K 452M 1% /var/tmp
/dev/vda1 488M 76K 452M 1% /tmp
추가 조사에서 /var/log/journal/ 아래의 저널 로그가 크게 증가했습니다. 7월 한 달 동안 생성된 로그만 ~3GB의 공간을 차지했습니다.
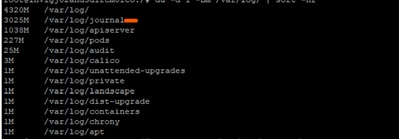
문제 해결 프로세스
디스크 사용률을 제어하려면 필요한 변경 구현 단계를 적용했습니다.
1단계: journalctl Vacuum을 사용하여 오래된 로그 정리
마지막 2주의 로그만 보존:
sudo journalctl --vacuum-time=2weeks
또는 저널 크기를 제한합니다(예: 600MB만 유지).
sudo journalctl --vacuum-size=600M
2단계: 향후 방지를 위한 저널드 보존 구성
저널드 구성 편집:
vi /etc/systemd/journald.conf
매개 변수 추가/수정:
MaxRetentionSec=2week
컨피그레이션 적용:
sudo systemctl restart systemd-journald
선택 사항 3단계: 재시작 오류 해결
2단계에서 systemd-jourald 서비스를 다시 시작하는 동안 다음과 같은 문제가 발생할 수 있습니다.
Error : Failed to allocate directory watch: Too many open files
-
systemd-jourald는 inotify를 사용하여 로그 디렉터리에서 변경 사항을 확인합니다.
-
각 시계 또는 모니터는 특정 커널 제한에 대한 카운트를 설정합니다.
문제가 되는 RCM에 정의된 현재 제한은 다음과 같습니다.
cat /proc/sys/fs/inotify/max_user_watches
501120
cat /proc/sys/fs/inotify/max_user_instances
128
ulimit -n
1024
수집된 출력에서:
- 최대 식별 시계 수: 501120
- 최대 inotify 인스턴스 수: 128
journald에 대한 열린 파일 설명자 제한: 1024
출력 값 제한 중 하나(또는 모두)가 오류로 이어질 수 있습니다. 따라서 현재 사용된 값을 수집하고 이를 수집된 출력 한계와 비교했습니다.
sudo lsof -p $(pidof systemd-journald) | wc -l
65
echo "Root inotify instances: $(sudo find /proc/*/fd -user root -type l -lname 'anon_inode:inotify' 2>/dev/null | wc -l) / $(cat /proc/sys/fs/inotify/max_user_instances)"
Root inotify instances: 126 / 128
-
현재 inotify 인스턴스: 126
-
현재 열린 파일 설명자: 65
루트에서 이미 허용된 inotify 인스턴스 128개 중 126개를 사용하고 있는 것 같습니다. 그러면 저널을 다시 시작할 때 새로 inotify 인스턴스를 만들 수 있는 공간이 거의 없습니다.
오류를 해결하려면 다음을 수행합니다. max_user_instances 값을 늘린 다음 서비스를 재시작할 수 있습니다.
# Temporarily increase the limit (until next reboot)
echo 256 > /proc/sys/fs/inotify/max_user_instances
sudo systemctl restart systemd-journald
# Temporarily increase the limit (until next reboot)
echo 256 > /proc/sys/fs/inotify/max_user_instances
sudo systemctl restart systemd-journald
변경 후 확인
변경 사항을 적용한 후 디스크 사용률이 61%로 떨어졌으며, 노드가 정상 작동 상태로 복원되었습니다.
df -kh
Filesystem Size Used Avail Use% Mounted on
tmpfs 6.3G 9.7M 6.3G 1% /run
/dev/vda3 39G 23G 15G 61% /
tmpfs 32G 4.0K 32G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/vda2 488M 48K 452M 1% /var/tmp
/dev/vda1 488M 76K 452M 1% /tmp
권장 사항
-
안전 한도 내에서 디스크 사용률을 유지하기 위해 구축의 모든 RCM 노드에 동일한 컨피그레이션을 구현합니다.
-
라이브 트래픽에 영향을 주지 않도록 변경을 수행하기 전에 항상 대상 RCM을 대기 모드로 설정합니다.
-
사전 대응적 시스템 상태 점검의 일환으로 /dev/vda3 활용률 및 저널릿 로그 증가를 정기적으로 모니터링합니다.
 피드백
피드백