오류 코드 "424-Geo-replication Checksum Mismatch"로 랙 간 복제 실패 문제 해결
다운로드 옵션
편견 없는 언어
본 제품에 대한 문서 세트는 편견 없는 언어를 사용하기 위해 노력합니다. 본 설명서 세트의 목적상, 편견 없는 언어는 나이, 장애, 성별, 인종 정체성, 민족 정체성, 성적 지향성, 사회 경제적 지위 및 교차성에 기초한 차별을 의미하지 않는 언어로 정의됩니다. 제품 소프트웨어의 사용자 인터페이스에서 하드코딩된 언어, RFP 설명서에 기초한 언어 또는 참조된 서드파티 제품에서 사용하는 언어로 인해 설명서에 예외가 있을 수 있습니다. 시스코에서 어떤 방식으로 포용적인 언어를 사용하고 있는지 자세히 알아보세요.
이 번역에 관하여
Cisco는 전 세계 사용자에게 다양한 언어로 지원 콘텐츠를 제공하기 위해 기계 번역 기술과 수작업 번역을 병행하여 이 문서를 번역했습니다. 아무리 품질이 높은 기계 번역이라도 전문 번역가의 번역 결과물만큼 정확하지는 않습니다. Cisco Systems, Inc.는 이 같은 번역에 대해 어떠한 책임도 지지 않으며 항상 원본 영문 문서(링크 제공됨)를 참조할 것을 권장합니다.
목차
소개
이 문서에서는 로컬 랙과 원격 랙 간의 지리적 복제 체크섬 불일치를 해결하기 위한 다양한 조사 방법에 대해 설명합니다.
사전 요구 사항
요구 사항
다음 주제에 대한 지식을 보유하고 있으면 유용합니다.
- SMF(Session Management Function)의 지리적 이중화
- SMF
- TCP(Transmission Control Protocol) 연결 종료
사용되는 구성 요소
이 문서는 특정 소프트웨어 및 하드웨어 버전으로 한정되지 않습니다.
이 문서의 정보는 특정 랩 환경의 디바이스를 토대로 작성되었습니다. 이 문서에 사용된 모든 디바이스는 초기화된(기본) 컨피그레이션으로 시작되었습니다. 현재 네트워크가 작동 중인 경우 모든 명령의 잠재적인 영향을 미리 숙지하시기 바랍니다.
배경 정보
SMF의 지리적 이중화란 무엇입니까?
-
SMF는 액티브-액티브 모드에서 지리적(Geo) 이중화(GR)를 지원합니다.
-
GR 설정은 스탠바이 랙에 데이터를
etcd/cache복제하는 역할도 담당합니다. -
SMF는 기본 인스턴스에서 대기 인스턴스로 데이터가 복제되는 기본/대기 이중화를 지원합니다.
-
기본 인스턴스가 실패하면 대기 인스턴스가 기본 인스턴스가 되어 작업을 인계받습니다.
-
GR을 실현하기 위해 각 사이트에서 트래픽을 능동적으로 처리하고 대기 가 원격 사이트에 대한 백업 역할을 하는 두 개의 기본/대기 쌍을 설정할 수 있습니다.
지리적 복제 포드
-
지리적 복제 Pod는 랙 간/사이트 통신과 랙 내의 POD/BFD를 모니터링하기 위해 도입되었습니다.
-
각 랙/사이트에서 GR-POD 인스턴스 2개 실행
-
액티브-스탠바이 모드에서 2개의 GR POD 기능
-
GR POD는 Proto 노드/VM에 생성됩니다.
-
GR POD에서 2개의 VIP(가상 IP 주소) 사용
-
POD 간 통신을 위한 내부 VIP(랙 내)
-
랙 간/사이트 GR POD 통신을 위한 외부 VIP
-
GR POD에 대해 구성된 VIP가 Proto 노드/VM 중 하나에서 활성화될 수 있음
-
Active GR POD를 재시작하면 VIP가 다른 Proto 노드/VM으로 전환되고 다른 Proto 노드/VM에서 실행되는 Standby GR POD가 Active 상태가 될 수 있습니다
GR 포드 참조 구성:
smf# show running-config instance instance-id 1 endpoint geo
Thu Oct 20 06:25:25.319 UTC+00:00
instance instance-id 1
endpoint geo
replicas 1
nodes 2
interface geo-internal
vip-ip a.b.c.d vip-port 7001
exit
interface geo-external
vip-ip Y.Y.Y.Y vip-port 7002
exit
exit
exit
활성 지오 포드 및 대기 지오 포드 식별
활성 Geo Pod를 식별하려면 Geo Pod 로그에서 오류 또는 이벤트를 확인해야 합니다.
활성 포드:
user@smf-ims-master-1:~$ kubectl logs georeplication-pod-0 -n smf-smfix1|tail -3
[ERROR] [grcacachepod.go:339] [gr_deferred_sync.application.app] Periodic Sync: Total time taken to sync IPAM cache pod data: 500.563723ms”
[ERROR] [GeoAdminStreamClient.go:276] [gr_pod.geo_admin_client.app] no one waiting for received response for txnID:CP0XXXOKCP0XXX-SMF-IMS-smfix1111163550 of host=geo-admin-pod2
스탠바이 포드:
user@cp0xxx-smf-ims-master-1:~$ kubectl logs georeplication-pod-1 -n smf-smfix1|tail -3
[ERROR] [gr_pod.geo_replication_client_stream] Counters => not an active geo pod
[ERROR] [gr_pod.geo_replication_client_stream] Counters => not an active geo pod
[ERROR] [gr_pod.geo_replication_client_stream] Counters => not an active geo pod
GR POD의 기능
GR 포드 사이트 전반에 걸쳐 ETCD 및 캐시 포드 데이터 복제
ETCD 및 캐시 포드 데이터에 대한 복제 세부 정보를 보려면 CLI를 사용하십시오.
[cp0xxx-smf-ims/smfix1] smf# show georeplication checksum instance-id 1
Thu Oct 20 07:11:52.409 UTC+00:00
checksum-details
-- ---- --------
ID Type Checksum
-- ---- -------
1 ETCD 1666249907
IPAM CACHE 1666249907
NRFMgmt CACHE 1666249907
ETCD에서 사이트 로컬 인스턴스 역할 유지
[ERROR] [gr_pod.gradmin] updateEntryInEtcd: Updating etcd entries for keys : Instance.2, with role as PRIMARY
[ERROR] [gr_pod.gradmin] updateEntryInEtcd: Updating etcd entries for keys : Instance.1, with role as STANDBY
로컬 사이트 상태 모니터링(POD 상태/BFD 상태)
[cp0xxx-smf-ims/smfix1] smf# show running-config geomonitor podmonitor pods smf-service
Thu Oct 20 07:36:41.280 UTC+00:00
geomonitor podmonitor pods smf-service
retryCount 2
retryInterval 900
retryFailOverInterval 500
failedReplicaPercent 60
사이트 역할
PRIMARY : 사이트가 준비되었으며 지정된 인스턴스에 대한 트래픽을 능동적으로 가져옵니다.
STANDBY: 사이트는 대기 상태이며, 트래픽을 가져올 준비가 되었지만 지정된 인스턴스에 대한 트래픽은 가져오지 않습니다.
STANDBY_ERROR: 사이트가 문제가 있으며, 활성 상태가 아니며, 지정된 인스턴스에 대한 트래픽을 가져올 준비가 되지 않았습니다.
FAILOVER_INIT: 사이트가 장애 조치를 시작했으며 애플리케이션이 활동을 완료하기 위해 2s의 버퍼 시간을 갖는 트래픽을 가져올 수 있는 상태가 아닙니다.
FAILOVER_COMPLETE: 사이트가 장애 조치를 완료했으며 피어 사이트에 지정된 인스턴스의 장애 조치에 대해 알리려고 했습니다. 버퍼 시간(2초)
FAILBACK_STARTED: 수동 장애 조치는 지정된 인스턴스에 대한 원격 사이트로부터의 지연과 함께 트리거됩니다.

참고: 캐시/ETCD 복제 및 CDL 복제는 모든 역할에서도 수행됩니다. GR 링크가 다운되거나 정기 하트비트가 실패할 경우 GR 트리거는 일시 중단됩니다.
GR 트리거
랙에서 GR 인스턴스 역할을 확인하는 CLI
Show role instance id 1
Show role instance id 2
CLI에서 대기 오류에서 대기로 역할 재설정
Geo reset-role instance-id <1/2> role standby
CLI에서 스탠바이에서 스탠바이로 역할 전환 오류
Geo switch-role instance-id <1/2> role standby failback-interval 0
CLI에서 Standby에서 Primary로 역할 전환
이 스위치 역할을 시작하려면 인스턴스 중 하나를 Primary로 하는 랙에서 CLI를 트리거해야 합니다.
Geo switch-role instance-id <1/2> role standby failback-interval 0
참고: 맑은 날 시나리오: 랙 1-인스턴스 1-기본, 인스턴스 2-대기, 랙 2-인스턴스 1-스탠바이, 인스턴스 2-기본
비 오는 날 시나리오: Rack1-Instance 1 및 Instance 2-Primary, Rack2-Instance 1 및 Instance 2-StandBy입니다.
TCP 연결 종료
TCP 프로토콜은 연결 지향 프로토콜입니다. 즉, 각 끝의 애플리케이션 프로그램이 메시지 교환을 완료할 때까지 연결이 설정되고 유지됩니다. TCP는 IP(인터넷 프로토콜)에서 작동합니다.
TCP 핸드셰이크는 3-Way-Handshake라고도 합니다. 클라이언트 시스템에서 서버 시스템으로 연결이 시작되면 데이터가 전송되기 전에 클라이언트와 서버는 SYN 및 ACK 패킷을 교환합니다.
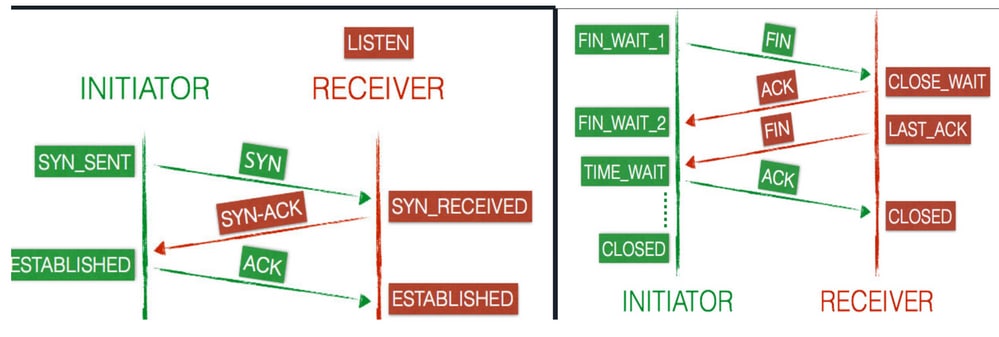 전송 제어 프로토콜: 클라이언트 및 서버 연결 상태
전송 제어 프로토콜: 클라이언트 및 서버 연결 상태
연결은 그 수명 내내 일련의 상태를 통해 진행됩니다. 상태는 다음과 같습니다. LISTEN, SYN-SENT, SYN-RECEIVED, ESTABLISHED, FIN-WAIT-1, FIN-WAIT-2,CLOSE-WAIT,CLOSING, LAST-ACK TIME-WAITCLOSED, 그리고 허구적 상태를 말합니다.
- 새 TCP 연결이 열리면 클라이언트(개시자)가 서버(수신기)에
SYN패킷을 전송하고 서버(수신기)의 상태를 로SYN-SENT업데이트합니다. - 그러면 서버는 연결 상태
SYN-ACK를 (으)로 변경하는 응답을 클라이언트로 보냅니다SYN-RECEIVED.
- 클라이언트가 로
ACK응답하고 연결이 양쪽 엔드포인트ESTABLISHED에 있는 것으로 표시되므로 이제 클라이언트와 서버는 데이터를 전송할 준비가 되었습니다.
- 클라이언트는 패킷을
FIN서버로 전송하고 해당 상태를 로 업데이트합니다FIN-WAIT-1. - 서버는 클라이언트로부터 종료 요청을 수신하고 로 응답한다
ACK. 응답 후 서버는 상태가CLOSE-WAIT됩니다. - 클라이언트가 서버에서 응답을 받는 즉시 상태로
FIN-WAIT-2이동합니다. - 서버는 여전히
CLOSE-WAIT상태이며 독립적으로 상태를 로 업데이트하는 FIN과 함께LAST-ACK진행됩니다. - 이제 클라이언트가 종료 요청을 받고
ACK로 응답하면 상태가TIME-WAIT됩니다. - 이제 서버가 완료되고 연결이 즉시 (으)로
CLOSED설정됩니다. - 클라이언트는 최대 4분 동안
TIME-WAIT연결 전 상태로CLOSED유지됩니다.
문제
시나리오 1. 인스턴스 ID 1의 지리적 복제 체크섬이 IPAM 캐시 및 NRFMgmt 캐시 체크섬 불일치를 가집니다.
smfix1/smfix2 지리적 복제 상태가 실패했습니다(원격 사이트로의 랙 간 복제 실패).
오류: 관리자 명령이 실패했습니다[pod internal-gr-pod-1, URL http://X.X.0.0:15290/commands]. 코드 424, 메시지 실패: 복제 체크섬이 일치하지 않습니다.
이 문제는 8월 23일 0시 36분 19초에 "랙 간 복제 실패"로 관찰되었습니다.
From CEE alerts:
Inter_Rack_Replication 9ca45362a049 critical 08-23T00:36:19 System
Inter rack replication to Remote Site failed
이 CLI 출력에서 instance-id 1에 IPAM(IP 주소 관리) 및 NRF 캐시에 대한 체크섬 불일치가 있음을 확인할 수 있습니다.
[cp0xxx-smf-ims/smfix1] smf# show georeplication checksum instance-id 1
Mon Sep 5 08:38:27.762 UTC+00:00
checksum-details
-- --- --------
ID Type Checksum
-- ---- --------
1 ETCD 1662367102
IPAM CACHE 1662367102
NRFMgmtCACHE 1662367102
[cp0xxx-smf-ims/smfix2] smf# show georeplication checksum instance-id 1
Mon Sep 5 08:38:30.767 UTC+00:00
checksum-details
-- ---- --------
ID Type Checksum
-- ---- --------
1 ETCD 1662367102
IPAM CACHE 1661214831
NRFMgmtCACHE 1661214831
시나리오 2. 인스턴스 ID 2의 지리적 복제 체크섬이 ETCD 체크섬 불일치를 가집니다.
[cp0xxx-smf-ims/smfix1] smf# show georeplication checksum instance-id 2
Mon Sep 5 08:38:37.852 UTC+00:00
checksum-details
-- ---- --------
ID Type Checksum
-- ---- --------
2 ETCD 1661214828
IPAM CACHE 1662367107
NRFMgmtCACHE 1662367107
[cp0xxx-smf-ims/smfix2] smf# show georeplication checksum instance-id 2
Mon Sep 5 08:38:39.118 UTC+00:00
checksum-details
-- ---- -------
ID Type Checksum
-- ---- --------
2 ETCD 1662367107
IPAM CACHE 1662367107
NRFMgmtCACHE 1662367107
시나리오 3. 원격 사이트와의 TCP 연결 설정 실패
랙 1-smfix1-logs:
GR Pod 로그에서 Update cache pod checkpoint가 중지되고, 즉시 복제가 실패하고, 사용 가능한 원격 호스트가 없음을 확인할 수 있습니다.
2022/08/23 00:34:00.035 [ERROR] [grreplicationclient.go:201] [gr_pod.geo_replication_client_stream.app] HandleImmediateReplication failed: [RPCNoRemoteHostAvailable] No remote host available for this request
2022/08/23 00:34:02.086 [ERROR] [grreplicationclient.go:466] [gr_pod.geo_replication_client_stream.app] Stream disconnected, closing logQueueCounter=0xc0093b08b0
2022/08/23 00:34:04.124 [ERROR] [GeoAdminStreamClient.go:215] [gr_pod.geo_admin_client.app] ADMIN(geo-admin-pod2) : exit outgoing request loop stream closed
2022/08/23 00:34:43.623 [ERROR] [grreplicationclient.go:270] [gr_pod.geo_replication_client_stream.app] Update etcd checkpointing stopped for grinstance: 1
Rack2-smfix2-log:
GR Pod 로그에서 스트림 연결 끊김 오류를 관찰할 수 있으며 CACHE 체크섬 차이가 예상보다 큽니다.
2022/08/23 00:34:06.497 [ERROR] [grreplicationserver.go:62] [gr_pod.geo_replication_server_stream.app] Stream disconnected, closing logQueueCounter=0xc001b85d08
2022/08/23 00:34:06.497 [ERROR] [grreplicationserver.go:314] [gr_pod.geo_replication_server_stream.app] handleCachePodSyncRequests : Stream closed of connection=0xc002ee08f0
2022/08/23 00:34:56.751 [ERROR] [grpodcommands.go:455] [gr_pod.cli_command.app] compareChecksumData: CACHE checksum difference is more then expected, local checksum [1661214831] remote checksum [1661214892]
2022/08/23 00:34:56.678 [ERROR] [etcdAuditReplHandler.go:196] [gr_pod.application.app] SyncETCDData periodic sync : For ETCD [C.GR.1.] key, the remote site data size is: [10833]
2022/08/23 00:36:56.757 [ERROR] [grpodcommands.go:455] [gr_pod.cli_command.app] compareChecksumData: CACHE checksum difference is more then expected, local checksum [1661214831] remote checksum [1661215012]
시나리오 4. 마스터 노드를 호스팅하는 서버에서 DIMM 오류가 발생했습니다.
스트림 연결 끊김 오류와 비슷한 시간에 지역 복제 포드-0을 호스팅하는 마스터 1 노드에 ECC 오류가 표시됩니다.
CP0XXX-Server9-02# scope sel
CP0XXX-Server9-02 /sel # show entries
Time Severity Description
----------------------- ------------- ----------------------------------------
2022-08-23 00:33:59 UTC Informational "DDR4_P1_E1_ECC: Memory sensor, read 1 correctable ECC errors on CPU1 DIMM E1 was asserted"
2022-08-22 22:59:45 UTC Informational "DDR4_P1_E1_ECC: Memory sensor, read 1 correctable ECC errors on CPU1 DIMM E1 was asserted"
- Rack1의 Geo-replication-pod와 Rack2의 Geo-replication-pod 간의 통신이 끊어졌습니다.
-
DIMM 오류가 마스터 노드 중 하나에서 발생하여 스트림 연결이 Rack1과 Rack2 사이에서 다운됩니다.
-
Rack1 Geo-replication-pod에서 Rack2에 요청을 복제하거나 전송할 수 없었으므로 Remote Host not available(원격 호스트를 사용할 수 없음) 오류가 발생합니다.
-
7002 포트에 대한 Rack1 및 Rack2의 netstat 명령 출력에서 Rack1 소켓이 FIN_WAIT1 상태로 고정되었고 Rack2 소켓이 SYN_RECV 상태로 고정되었음을 확인했습니다.
-
서버 측, 즉 Rack2에서는 소켓이 SYNC_RECV 상태로 고정되며 새로 생성된 연결도 SYNC_RECV 상태로 전환되어 서로 통신할 수 없습니다.
-
커널이 포트에 대한 SYN 패킷을 받았지만(즉, LISTENING 모드) 다른 쪽 끝은 ACK로 응답하지 않았기 때문에 연결이 SYN_RECV 상태입니다.
smfix2-Master-2에 지역 외부 VIP(Y.Y.Y.Y:7002)가 설치되어 있지만 원격 호스트(SMFIX1) TCP 연결 상태가 ESTABLISHED 상태가 아닌 SYN_RECV 상태에서 중단되었습니다. a.b.c.d 및 a.b.c.e는 Master-1 및 2개의 smfix1(Rack1) IP입니다.
user@cp0xxx-smf-ims-master-2:~$ netstat -anp | grep 7002
tcp 0 0 Y.Y.Y.Y:7002 0.0.0.0:* LISTEN -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:35542 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:47046 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:36248 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:42686 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:38248 SYN_RECV -
원격 피어의 smfix1(Rack1)에 대한 외부 Geo VIP TCP 연결 상태가 FIN-WAIT1 상태입니다.
user@cp0xxx-smf-ims-master-1:~$ netstat -anp | grep 7002
tcp 0 0 a.b.c.d 0.0.0.0:* LISTEN -
tcp 0 1 a.b.c.d:60866 Y.Y.Y.Y:7002 FIN_WAIT1 -
tcp 0 1 a.b.c.d:52274 Y.Y.Y.Y:7002 FIN_WAIT1 -
tcp 0 1 a.b.c.d:59674 Y.Y.Y.Y:7002 FIN_WAIT1 -
tcp 0 1 a.b.c.d:47926 Y.Y.Y.Y:7002 FIN_WAIT1 -
솔루션
랙 1:
-
먼저 대기 Geo Pod를 삭제하고 Pod가 복구될 때까지 기다린 다음 Active Geo Pod를 삭제합니다. 마스터 VIP에 로그인하고 GR Pod를 삭제합니다.
kubectl delete pod-n
랙 2:
- 먼저 대기 Geo Pod를 삭제하고 Pod가 복구될 때까지 기다린 다음 Active Geo Pod를 삭제합니다.
-
CLI에서 지리적 복제 상태를 확인하고, 지리적 포드를 삭제하도록 게시합니다.
show georeplication-status
- Rack1 및 Rack2에 Geo Pod 삭제를 게시하면 외부 Geo VIP IP가 표시됩니다. TCP 포트는 ESTABLISHED 상태로 이동합니다.
- GeoReplacement 상태 "통과".
- 랙 전반의 복제 상태에서 체크섬 불일치가 나타나지 않습니다.
smfix2(랙2):
user@cp0xxx-smf-ims-master-1:~$ sudo netstat -anp | grep 7002 | grep -v aa
tcp 0 0 Y.Y.Y.Y:7002 0.0.0.0:* LISTEN 36854
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:46402 ESTABLISHED 36854/grpod
tcp 0 0 Y.Y.Y.Y:7002 1a.b.c.e:54708 ESTABLISHED 36854/grpod
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:55152 ESTABLISHED 36854/grpod
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:46530 ESTABLISHED 36854/grpod
tcp 0 0 10.59.0.0:7002 10.59.0.0:46532 ESTABLISHED 36854/grpod
smfix1(랙1):
user@cp0xxx-smf-ims-master-1:~$ sudo netstat -anp | grep 7002 | grep -v aa
tcp 0 0 a.b.c.d 0.0.0.0:* LISTEN 53932/grpod
tcp 0 0 a.b.c.d:46530 Y.Y.Y.Y:7002 ESTABLISHED 53932/grpod
tcp 0 0 a.b.c.d:46402 Y.Y.Y.Y:7002 ESTABLISHED 53932/grpod
tcp 0 17 a.b.c.d:46532 Y.Y.Y.Y:7002 ESTABLISHED 53932/grpod
2. 지리적 복제 상태
[okcp0xx-smf-ims/smfix1] smf# show georeplication-status
result "pass"
[okcp0xx-smf-ims/smfix2] smf# show georeplication-status
result "pass"
개정 이력
| 개정 | 게시 날짜 | 의견 |
|---|---|---|
1.0 |
05-Dec-2022
|
최초 릴리스 |
Cisco 엔지니어가 작성
- 마나사 G 캄비Cisco TAC 엔지니어
- 크리슈나 키쇼어 D VCisco 기술 리더
 피드백
피드백지원 문의
- 지원 케이스 접수

- (시스코 서비스 계약 필요)