IGRP 소개
목차
소개
이 문서에서는 IGRP(Interior Gateway Routing Protocol)를 소개합니다. 이 문서는 두 가지 용도로 사용됩니다. 하나는 IGRP 기술을 사용하고 평가하고 구현하는 데 관심이 있는 사용자를 위해 IGRP 기술을 소개하는 것이고, 다른 하나는 IGRP에 구현된 몇 가지 흥미로운 아이디어와 개념을 더 널리 알리는 것입니다. IGRP 설정 방법에 대한 자세한 내용은 IGRP 설정, Cisco IGRP 구현 및 IGRP 명령을 참조하세요.
IGRP의 목표
IGRP 프로토콜을 사용하면 여러 게이트웨이에서 라우팅을 조정할 수 있습니다. 목표는 다음과 같습니다.
-
매우 크거나 복잡한 네트워크에서도 안정적인 라우팅 과도 경로로도 라우팅 루프가 발생하지 않아야 합니다.
-
네트워크 토폴로지 변경에 신속하게 대응
-
오버헤드가 적습니다. 즉, IGRP 자체는 작업에 실제로 필요한 것보다 더 많은 대역폭을 사용하지 않아야 합니다.
-
트래픽이 대략적으로 동일한 경우 여러 병렬 경로 간에 트래픽을 분할합니다.
-
서로 다른 경로에 있는 트래픽의 오류율 및 수준을 고려합니다.
IGRP의 현재 구현에서는 TCP/IP에 대한 라우팅을 처리합니다. 그러나 기본 설계는 다양한 프로토콜을 처리할 수 있도록 되어 있습니다.
모든 라우팅 문제를 해결할 수 있는 툴은 없습니다. 일반적으로 라우팅 문제는 여러 부분으로 나뉩니다. IGRP와 같은 프로토콜은 "내부 게이트웨이 프로토콜"(IGP)이라고 합니다. 단일 관리 또는 긴밀하게 조정된 관리에서 단일 네트워크 세트 내에서 사용하도록 설계되었습니다. 이러한 네트워크 집합은 "외부 게이트웨이 프로토콜"(EGP)에 의해 연결됩니다. IGP는 네트워크 토폴로지에 대한 상당한 세부 사항을 추적하도록 설계되었습니다. IGP 설계의 우선 순위는 최적의 경로를 생성하고 변화에 신속하게 대응하는 데 있습니다. EGP는 다른 시스템의 오류 또는 의도적인 잘못된 표시로부터 한 네트워크 시스템을 보호하기 위한 것입니다. BGP는 이러한 외부 게이트웨이 프로토콜 중 하나입니다. EGP 설계의 우선 순위는 안정성 및 관리 제어에 있습니다. EGP에서 최적 경로가 아닌 적절한 경로를 생성하는 것으로 충분한 경우가 많습니다.
IGRP는 Xerox의 Routing Information Protocol, Berkeley의 RIP 및 Dave Mills의 Hello와 같은 이전 프로토콜과 몇 가지 유사성이 있습니다. 이 프로토콜은 주로 더 크고 복잡한 네트워크에 맞게 설계된다는 점에서 다릅니다. 이전 세대 프로토콜에서 가장 널리 사용되는 RIP와의 자세한 비교는 RIP와의 비교 섹션을 참조하십시오.
이러한 이전 프로토콜과 마찬가지로 IGRP는 거리 벡터 프로토콜입니다. 이러한 프로토콜에서 게이트웨이는 인접 게이트웨이와만 라우팅 정보를 교환합니다. 이 라우팅 정보에는 네트워크의 나머지 부분에 대한 요약 정보가 포함되어 있습니다. 모든 게이트웨이가 함께 모여 분산 알고리즘의 양에 따라 최적화 문제를 해결하고 있음을 수학적으로 보여줄 수 있다. 각 게이트웨이는 문제의 일부만 해결하면 되고 전체 데이터의 일부만 받으면 된다.
IGRP의 주요 대안은 EIGRP(Enhanced IGRP)와 SPF(shortest-path first)라는 알고리즘 클래스입니다. OSPF에서는 이 개념을 사용합니다. OSPF에 대한 자세한 내용은 OSPF Design Guide를 참조하십시오. OSPF 플러딩 기법을 기반으로 하며, 각 게이트웨이는 다른 모든 게이트웨이의 모든 인터페이스 상태에 대한 최신 정보를 유지합니다. 각 게이트웨이는 전체 네트워크에 대한 데이터를 사용하여 최적화 문제를 그 관점에서 독립적으로 해결합니다. 각 접근 방식에는 이점이 있습니다. 어떤 상황에서는 SPF가 변화에 더 빠르게 대응할 수 있습니다. 라우팅 루프를 방지하기 위해 IGRP는 특정 종류의 변경 후 몇 분 동안 새 데이터를 무시해야 합니다. SPF에는 각 게이트웨이의 정보가 직접 있으므로 이러한 라우팅 루프를 방지할 수 있습니다. 따라서 새로운 정보를 즉시 처리할 수 있습니다. 그러나 SPF는 내부 데이터 구조 및 게이트웨이 간 메시지 모두에서 IGRP보다 훨씬 많은 데이터를 처리해야 합니다.
라우팅 문제
IGRP는 여러 네트워크를 연결하는 게이트웨이에 사용하기 위한 것입니다. 네트워크가 패킷 기반 기술을 사용한다고 가정합니다. 사실상 게이트웨이는 패킷 스위치 역할을 합니다. 한 네트워크에 연결된 시스템이 다른 네트워크의 시스템으로 패킷을 전송하려는 경우, 게이트웨이로 패킷을 전달합니다. 목적지가 게이트웨이에 연결된 네트워크 중 하나에 있는 경우 게이트웨이는 패킷을 목적지로 전달합니다. 목적지가 더 먼 경우 게이트웨이는 목적지에 더 가까운 다른 게이트웨이로 패킷을 전달합니다. 게이트웨이는 라우팅 테이블을 사용하여 패킷으로 수행할 작업을 결정합니다. 다음은 라우팅 테이블의 간단한 예입니다. (예제에 사용된 주소는 Rutgers University에서 가져온 IP 주소입니다. 기본 라우팅 문제는 다른 프로토콜에서도 유사하지만, 이 설명에서는 IP 라우팅에 IGRP가 사용되는 것으로 가정합니다.)
그림 1
network gateway interface ------- ------- --------- 128.6.4 none ethernet 0 128.6.5 none ethernet 1 128.6.21 128.6.4.1 ethernet 0 128.121 128.6.5.4 ethernet 1 10 128.6.5.4 ethernet 1
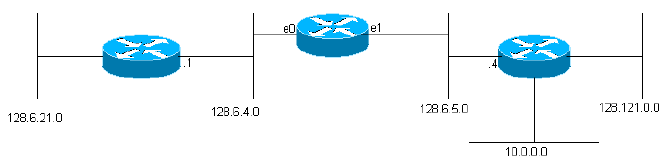
(보시다시피 실제 IGRP 라우팅 테이블에는 각 게이트웨이에 대한 추가 정보가 있습니다.) 이 게이트웨이는 0과 1이라는 두 개의 이더넷에 연결되어 있습니다. 이 이더넷에는 IP 네트워크 번호(실제 서브넷 번호) 128.6.4와 128.6.5가 제공되었습니다. 따라서 이러한 특정 네트워크에 대해 주소가 지정된 패킷은 해당 이더넷 인터페이스를 사용하여 목적지로 직접 전송할 수 있습니다. 근처에 128.6.4.1과 128.6.5.4라는 두 개의 게이트웨이가 있습니다. 128.6.4와 128.6.5 이외의 네트워크에 대한 패킷은 해당 게이트웨이 중 하나 또는 다른 게이트웨이로 전달됩니다. 라우팅 테이블은 어떤 네트워크를 위해 어떤 게이트웨이를 사용해야 하는지를 나타냅니다. 예를 들어, 네트워크 10의 호스트로 주소가 지정된 패킷은 게이트웨이 128.6.5.4로 전달되어야 합니다. 이 게이트웨이가 네트워크 10에 더 가까이 있기를 바랍니다. 즉, 네트워크 10에 대한 최상의 경로가 이 게이트웨이를 통과하기를 바랍니다. IGRP의 주요 목적은 게이트웨이가 이와 같은 라우팅 테이블을 구축하고 유지 관리할 수 있도록 하는 것입니다.
IGRP 요약
위에서 언급한 것처럼 IGRP는 게이트웨이가 다른 게이트웨이와 정보를 교환하여 라우팅 테이블을 구축할 수 있도록 하는 프로토콜입니다. 게이트웨이는 직접 연결된 모든 네트워크에 대한 항목으로 시작합니다. 인접 게이트웨이와 라우팅 업데이트를 교환하여 다른 네트워크에 대한 정보를 가져옵니다. 가장 간단한 경우, 게이트웨이는 각 네트워크로 가는 가장 좋은 방법을 나타내는 하나의 경로를 찾습니다. 경로는 패킷을 보내야 하는 다음 게이트웨이, 사용해야 하는 네트워크 인터페이스, 메트릭 정보로 구성됩니다. 메트릭 정보는 경로가 얼마나 우수한지를 특징짓는 숫자 집합이다. 이렇게 하면 게이트웨이가 여러 게이트웨이에서 수신한 경로를 비교하고 사용할 경로를 결정할 수 있습니다. 둘 이상의 경로 간에 트래픽을 분할하는 것이 적합한 경우가 종종 있습니다. IGRP는 둘 이상의 경로가 동등하게 양호한 경우 이를 수행합니다. 사용자는 경로가 거의 동일한 경우 트래픽을 분할하도록 구성할 수도 있습니다. 이 경우 더 나은 메트릭을 가진 경로를 따라 더 많은 트래픽이 전송됩니다. 9600bps 회선과 19200BPS 회선으로 트래픽을 분할할 수 있으며, 19200 회선은 9600BPS 회선보다 약 2배 많은 트래픽을 얻게 됩니다.
IGRP에서 사용하는 메트릭은 다음과 같습니다.
-
위상 지연 시간
-
경로의 가장 좁은 대역폭 세그먼트의 대역폭
-
경로의 채널 점유율
-
경로의 신뢰성
토폴로지 지연 시간은 언로드된 네트워크를 가정할 때 해당 경로를 따라 목적지로 가는 데 걸리는 시간입니다. 물론 네트워크가 로드되면 추가 지연이 발생합니다. 그러나 실제 지연을 측정하려고 시도하는 것이 아니라 채널 점유율 수치를 사용하여 부하를 처리합니다. 경로 대역폭은 경로에서 가장 느린 링크의 초당 비트 수입니다. 채널 점유율은 현재 사용 중인 대역폭의 양을 나타냅니다. 측정되며, 부하에 따라 변경됩니다. 신뢰도는 현재 오류 비율을 나타냅니다. 손상되지 않은 상태로 대상에 도착하는 패킷의 비율입니다. 측정됩니다.
이러한 정보는 메트릭의 일부로 사용되지 않지만, 두 가지 추가 정보가 함께 전달됩니다. 홉 수 및 MTU. 홉 수는 패킷이 목적지에 도달하기 위해 거쳐야 하는 게이트웨이 수입니다. MTU는 프래그먼트화 없이 전체 경로를 따라 전송할 수 있는 최대 패킷 크기입니다. (즉, 경로에 포함된 모든 네트워크의 MTU 최소값입니다.)
메트릭 정보를 기반으로 경로에 대한 단일 "복합 메트릭"이 계산됩니다. 복합 메트릭은 다양한 메트릭 구성 요소의 효과를 해당 경로의 "양호"를 나타내는 단일 숫자로 결합합니다. 가장 좋은 경로를 결정하는 데 실제로 사용되는 복합 메트릭입니다.
각 게이트웨이는 주기적으로 전체 라우팅 테이블을 인접한 모든 게이트웨이로 브로드캐스트합니다(split horizon 규칙 때문에 일부 검열이 수행됨). 게이트웨이가 다른 게이트웨이에서 이 브로드캐스트를 가져오면 테이블을 기존 테이블과 비교합니다. 모든 새 대상 및 경로가 게이트웨이의 라우팅 테이블에 추가됩니다. 브로드캐스트의 경로가 기존 경로와 비교됩니다. 새로운 경로가 더 나은 경우 기존 경로를 대체할 수 있습니다. 방송 내의 정보는 또한 채널 점유율 및 기존의 경로들에 대한 다른 정보를 업데이트하기 위해 사용된다. 이 일반적인 절차는 모든 거리 벡터 프로토콜에서 사용하는 것과 유사합니다. 수학 문헌에서는 벨만-포드 알고리즘으로 언급하고 있다. 기존 거리 벡터 프로토콜인![]() RIP를 설명하는 기본 절차의 자세한 개발 내용은 RFC 1058을 참조하십시오.
RIP를 설명하는 기본 절차의 자세한 개발 내용은 RFC 1058을 참조하십시오.
IGRP에서는 일반적인 Bellman-Ford 알고리즘이 세 가지 중요한 측면에서 수정됩니다. 첫째, 단순한 메트릭 대신 메트릭의 벡터를 사용하여 경로를 특성화합니다. 둘째, 메트릭이 가장 작은 단일 경로를 선택하는 대신, 메트릭이 지정된 범위에 속하는 여러 경로로 트래픽이 분할됩니다. 셋째, 토폴로지가 변경되는 상황에서 안정성을 제공하기 위해 몇 가지 기능이 도입되었습니다.
복합 메트릭을 기준으로 최상의 경로가 선택됩니다.
[(K1 / Be) + (K2 * Dc)] r
여기서 K1, K2 = 상수, Be = 언로드된 경로 대역폭 x (1 - 채널 점유), Dc = 위상 지연, r = 신뢰성입니다.
가장 작은 합성 메트릭을 갖는 경로가 최상의 경로가 될 것이다. 동일한 대상에 대해 여러 경로가 있는 경우 게이트웨이는 둘 이상의 경로를 통해 패킷을 라우팅할 수 있습니다. 이는 각 데이터 경로에 대한 복합 메트릭에 따라 수행됩니다. 예를 들어, 한 경로의 복합 메트릭이 1이고 다른 경로의 복합 메트릭이 3인 경우 복합 메트릭이 1인 데이터 경로를 통해 전송되는 패킷의 3배가 됩니다.
메트릭 정보의 벡터를 사용하는 데에는 두 가지 이점이 있다. 첫 번째는 동일한 데이터 집합에서 여러 유형의 서비스를 지원할 수 있는 기능을 제공한다는 것입니다. 두 번째 장점은 정확성이 향상된다는 것입니다. 단일 메트릭을 사용하면 일반적으로 지연이 발생한 것처럼 처리됩니다. 경로의 각 링크가 총 메트릭에 추가됩니다. 대역폭이 낮은 링크가 있는 경우 일반적으로 큰 지연으로 표시됩니다. 그러나 대역폭 제한이 지연의 방식을 누적하지는 않습니다. 대역폭을 별도의 구성 요소로 처리하면 대역폭을 올바르게 처리할 수 있습니다. 유사하게, 로드는 별개의 채널 점유 번호에 의해 처리될 수 있다.
IGRP는 루프를 포함하는 일반적인 그래프 토폴로지를 안정적으로 처리할 수 있는 컴퓨터 네트워크를 상호 연결하는 시스템을 제공합니다. 시스템은 전체 경로 메트릭 정보를 유지 관리합니다. 즉, 게이트웨이가 연결된 다른 모든 네트워크에 대한 경로 매개변수를 파악합니다. 트래픽은 병렬 경로를 통해 분산될 수 있으며 여러 경로 매개변수를 전체 네트워크에서 동시에 계산할 수 있습니다.
RIP와 비교
이 섹션에서는 IGRP를 RIP와 비교합니다. 이 비교는 RIP가 IGRP와 유사한 용도로 널리 사용되므로 유용합니다. 그러나, 이렇게 하는 것은 완전히 공평하지 않다. RIP는 IGRP와 동일한 목표를 모두 충족하도록 설계되지 않았습니다. RIP는 합리적으로 균일한 기술을 갖춘 소규모 네트워크에서 사용하도록 설계되었습니다. 그러한 응용 분야에서는 일반적으로 적당하다.
IGRP와 RIP의 가장 기본적인 차이점은 메트릭 구조입니다. 안타깝게도 이는 단순히 RIP로 개조될 수 있는 변경이 아닙니다. IGRP에 있는 새로운 알고리즘과 데이터 구조가 필요합니다.
RIP는 간단한 "홉 수" 메트릭을 사용하여 네트워크를 설명합니다. 모든 경로가 지연, 대역폭 등으로 설명되는 IGRP와 달리 RIP에서는 1~15의 숫자로 설명됩니다. 일반적으로 이 숫자는 대상에 도달하기 전에 경로가 통과하는 게이트웨이 수를 나타내는 데 사용됩니다. 이는 느린 직렬 회선과 이더넷이 구분되지 않는다는 것을 의미합니다. RIP의 일부 구현에서는 시스템 관리자가 지정된 홉을 두 번 이상 계산하도록 지정할 수 있습니다. 느린 네트워크는 큰 홉 수로 나타낼 수 있습니다. 하지만 최대값이 15까지이기 때문에, 이 일은 많이 할 수 없습니다. 예를 들어 이더넷이 1로 표시되고 56Kb 줄이 3으로 표시되는 경우 하나의 경로에 최대 5개의 56Kb 줄이 있거나 최대 15개를 초과할 수 있습니다. 사용 가능한 네트워크 속도의 전체 범위를 나타내고 대규모 네트워크를 지원하기 위해 Cisco에서 실시한 연구에 따르면 24비트 메트릭이 필요하다고 합니다. 최대 메트릭이 너무 작으면 시스템 관리자에게 다음과 같은 불쾌한 선택 사항이 표시됩니다. 그는 빠른 경로와 느린 경로를 구분할 수 없거나 네트워크 전체를 한도에 맞출 수 없습니다. 실제로 현재 많은 국가 네트워크가 충분히 크기 때문에 모든 홉을 한 번만 계산해도 RIP에서 처리할 수 없습니다. RIP는 이러한 네트워크에 사용할 수 없습니다.
분명한 응답은 더 큰 메트릭을 허용하도록 RIP를 수정하는 것입니다. 불행히도 이것은 작동하지 않습니다. 모든 거리 벡터 프로토콜과 마찬가지로 RIP는 '무한대로 세는' 문제가 있다. 이 내용은 RFC 1058에 더 자세히 설명되어 있습니다![]() . 토폴로지가 변경되면 가짜 경로가 도입됩니다. 이러한 가상 경로와 연결된 메트릭은 15에 도달할 때까지 서서히 증가하며, 이 시점에서 경로가 제거됩니다. 15는 트리거된 업데이트가 사용된다고 가정할 때 이 프로세스가 상당히 빠르게 통합될 수 있는 충분히 작은 최대치입니다. 24비트 메트릭을 허용하도록 RIP를 수정한 경우, 최대 2**24까지 메트릭을 계산할 수 있을 만큼 루프가 오래 유지됩니다. 이는 허용되지 않습니다. IGRP는 가짜 경로가 유입되지 않도록 설계된 기능을 갖추고 있습니다. 이러한 기능은 섹션 5.2에서 설명합니다. 이러한 기능을 도입하거나 SPF와 같은 프로토콜로 변경하지 않고 복잡한 네트워크를 처리하는 것은 현실적이지 않습니다.
. 토폴로지가 변경되면 가짜 경로가 도입됩니다. 이러한 가상 경로와 연결된 메트릭은 15에 도달할 때까지 서서히 증가하며, 이 시점에서 경로가 제거됩니다. 15는 트리거된 업데이트가 사용된다고 가정할 때 이 프로세스가 상당히 빠르게 통합될 수 있는 충분히 작은 최대치입니다. 24비트 메트릭을 허용하도록 RIP를 수정한 경우, 최대 2**24까지 메트릭을 계산할 수 있을 만큼 루프가 오래 유지됩니다. 이는 허용되지 않습니다. IGRP는 가짜 경로가 유입되지 않도록 설계된 기능을 갖추고 있습니다. 이러한 기능은 섹션 5.2에서 설명합니다. 이러한 기능을 도입하거나 SPF와 같은 프로토콜로 변경하지 않고 복잡한 네트워크를 처리하는 것은 현실적이지 않습니다.
IGRP는 단순히 허용되는 메트릭의 범위를 늘리는 것 이상의 역할을 합니다. 메트릭을 재구성하여 지연, 대역폭, 신뢰성 및 로드를 설명합니다. RIP와 같은 단일 메트릭에서 이러한 고려 사항을 나타낼 수 있지만, IGRP가 취하는 접근 방식이 잠재적으로 더 정확합니다. 예를 들어, 단일 메트릭을 사용하면 여러 개의 연속된 빠른 링크가 느린 단일 링크와 동일한 것처럼 보입니다. 이는 지연이 주요 관심사인 인터랙티브 트래픽의 경우일 수 있습니다. 그러나 대량 데이터 전송에서 가장 큰 문제는 대역폭이며, 메트릭을 함께 추가하는 것은 올바른 접근 방식이 아닙니다. IGRP는 지연과 대역폭을 별도로 처리하여 지연을 누적하지만 대역폭의 최소값을 사용합니다. 신뢰성 및 부하의 효과를 단일 성분 메트릭에 통합하는 방법을 보는 것은 쉽지 않다.
내 생각에 IGRP의 큰 장점 중 하나는 컨피그레이션의 용이성입니다. 물리적인 의미가 있는 양을 직접적으로 나타낼 수 있다. 인터페이스 종류, 회선 속도 등에 따라 자동으로 설정이 가능하다는 의미다. 단일 구성 요소 메트릭으로 메트릭은 여러 가지 다른 것의 효과를 통합하기 위해 "요리해야" 할 가능성이 더 높습니다.
다른 혁신은 라우팅 프로토콜보다 알고리즘과 데이터 구조가 더 중요합니다. 예를 들어 IGRP는 여러 경로 간의 트래픽 분할을 지원하는 알고리즘 및 데이터 구조를 지정합니다. 이를 수행하는 RIP의 구현을 설계할 수 있습니다. 그러나 일단 라우팅을 재구현하면 RIP를 고수할 이유가 없습니다.
지금까지 모든 네트워크 프로토콜에 대한 라우팅을 지원할 수 있는 기술인 "일반 IGRP"에 대해 설명했습니다. 그러나 이 섹션에서는 특정 TCP/IP 구현에 대해 조금 더 언급할 필요가 있습니다. 이것이 바로 RIP와 비교될 구현입니다.
RIP 업데이트 메시지는 라우팅 테이블의 스냅샷만 포함합니다. 즉, 여러 대상 및 메트릭 값이 있으며, 그 외에는 거의 없습니다. IGRP의 IP 구현에는 추가 구조가 있습니다. 먼저, 업데이트 메시지는 "자동 시스템 번호"로 식별됩니다. 이 용어는 Arpanet 전통에서 나온 것으로, 구체적인 의미가 있습니다. 그러나 대부분의 네트워크에서 동일한 네트워크에서 여러 가지 다른 라우팅 시스템을 실행할 수 있다는 의미입니다. 이는 여러 조직의 네트워크가 통합되는 곳에 유용합니다. 각 조직은 고유의 라우팅을 유지할 수 있습니다. 각 업데이트에 레이블이 지정되므로 게이트웨이는 올바른 업데이트에만 집중하도록 구성할 수 있습니다. 특정 게이트웨이는 여러 자동 시스템으로부터 업데이트를 수신하도록 구성됩니다. 이들은 통제된 방식으로 시스템 간에 정보를 전달합니다. 라우팅 보안 문제에 대한 완벽한 해결책은 아닙니다. 모든 게이트웨이는 모든 자동 시스템의 업데이트를 수신하도록 구성할 수 있습니다. 그러나 네트워크 관리자 간에 신뢰할 수 있는 라우팅 정책을 구현하는 데 매우 유용한 툴입니다.
IGRP 업데이트 메시지에 대한 두 번째 구조적 기능은 기본 경로가 IGRP에서 처리되는 방식에 영향을 줍니다. 대부분의 라우팅 프로토콜은 기본 경로의 개념을 가지고 있습니다. 전 세계의 모든 네트워크가 업데이트 라우팅에 나열되는 것은 현실적이지 않은 경우가 많습니다. 일반적으로 게이트웨이 집합에는 조직 내 네트워크에 대한 자세한 라우팅 정보가 필요합니다. 조직 외부의 대상에 대한 모든 트래픽은 몇 가지 경계 게이트웨이 중 하나로 전송될 수 있습니다. 이러한 경계 게이트웨이에는 더 자세한 정보가 있을 수 있습니다. 최상의 경계 게이트웨이로 향하는 경로는 "기본 경로"입니다. 내부 라우팅 업데이트에 구체적으로 나열되지 않은 목적지로 가는 데 사용된다는 점에서 기본값입니다. RIP 및 일부 다른 라우팅 프로토콜은 기본 경로에 대한 정보를 실제 네트워크처럼 순환합니다. IGRP는 다른 접근 방식을 사용합니다. 기본 경로에 대한 단일 위조 항목이 아니라 IGRP를 통해 실제 네트워크가 기본값이 될 후보로 플래그될 수 있습니다. 이는 해당 네트워크에 대한 정보를 업데이트 메시지의 특수 외부 섹션에 배치함으로써 구현됩니다. 그러나 이러한 네트워크와 관련된 기능을 켜는 것으로 간주하는 것이 좋습니다. 주기적으로 IGRP는 모든 후보 기본 경로를 스캔하고 메트릭이 가장 낮은 경로를 실제 기본 경로로 선택합니다.
잠재적으로 이러한 기본값 접근 방식은 대부분의 RIP 구현에서 취한 접근 방식보다 다소 더 유연합니다. 일반적으로 RIP 게이트웨이는 특정 메트릭을 사용하여 기본 경로를 생성하도록 설정할 수 있습니다. 이는 경계 게이트웨이에서 수행된다는 의도입니다.
자세한 설명
이 섹션에서는 IGRP에 대한 자세한 설명을 제공합니다.
전체 설명
게이트웨이가 처음 켜지면 해당 라우팅 테이블이 초기화됩니다. 운영자가 콘솔 터미널에서 실행하거나 컨피그레이션 파일에서 정보를 읽는 방식으로 이 작업을 수행할 수 있습니다. 게이트웨이에 연결된 각 네트워크에 대한 설명이 제공되며, 여기에는 링크에 따른 토폴로지 지연(예: 단일 비트가 링크를 통과하는 데 걸리는 시간) 및 링크의 대역폭이 포함됩니다.
그림 2
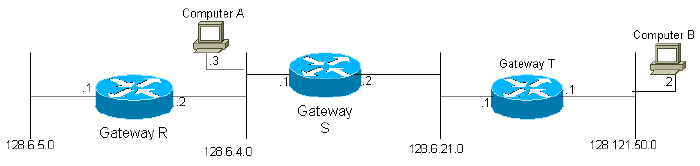
예를 들어, 위 다이어그램에서 게이트웨이 S는 해당 인터페이스를 통해 네트워크 2 및 3에 연결되어 있다고 할 수 있습니다. 따라서 처음에 게이트웨이 2는 네트워크 2와 3의 모든 대상 컴퓨터에 연결할 수 있다는 사실만 알고 있습니다. 모든 게이트웨이는 초기화된 정보와 다른 게이트웨이에서 수집된 정보를 인접 게이트웨이에 주기적으로 전송하도록 프로그래밍됩니다. 따라서 게이트웨이 S는 게이트웨이 R과 T로부터 업데이트를 받고 게이트웨이 R을 통해 네트워크 1의 컴퓨터와 게이트웨이 T를 통해 네트워크 4의 컴퓨터에 연결할 수 있음을 알게 됩니다. 게이트웨이 S는 전체 라우팅 테이블을 전송하므로 다음 주기 게이트웨이 T는 게이트웨이 S를 통해 네트워크 1에 연결할 수 있음을 알게 됩니다. 시스템의 모든 네트워크에 대한 정보가 결국 시스템의 모든 게이트웨이에 도달하여 네트워크가 완전히 연결되었다는 것만 제공한다는 것을 쉽게 알 수 있습니다.
그림 3
________ Network 1
|
gw A --nw2-- gw C
| / |
| / |
nw3 nw4 nw5
| / |
| / |
gw B gw D
_|_____________|____ Network 6
각 게이트웨이는 복합 메트릭을 계산하여 대상 컴퓨터에 대한 데이터 경로의 선호도를 결정합니다. 예를 들어, 위 다이어그램에서 네트워크 6의 대상에 대해 게이트웨이 A(gw A)는 게이트웨이 B와 C를 통해 두 경로에 대한 메트릭 함수를 계산합니다. 경로는 다음 홉만으로 정의됩니다. 실제로 A에서 네트워크 6으로 연결되는 세 가지 경로가 있습니다.
-
B에 직접 연결
-
C로, B로
-
C로, D로
그러나 게이트웨이 A는 C와 관련된 두 경로 중에서 선택할 필요는 없습니다. A의 라우팅 테이블에는 C에 대한 경로를 나타내는 단일 항목이 있습니다. 메트릭은 C에서 최종 목적지로 가는 가장 좋은 방법을 나타냅니다. A가 C에게 패킷을 보내면 B를 쓸지 D를 쓸지를 결정하는 것은 C에게 달려있다.
식 1
각 데이터 경로에 대해 계산된 복합 메트릭 함수는 다음과 같습니다.
[(K1 / Be) + (K2 * Dc)] r
여기서 r = 부분 신뢰성(다음 홉에서 성공적으로 수신된 전송의 %), Dc = 복합 지연, Be = 유효 대역폭: 언로드된 대역폭 x(1 - 채널 점유), K1 및 K2 = 상수.
수식 2
원칙적으로 복합 지연, Dc는 아래에 표시된 바와 같이 결정될 수 있다:
Dc = Ds + Dcir + Dt
여기서 Ds = 스위칭 지연, Dcir = 회로 지연(전파 지연 1비트), DT = 전송 지연(1500비트 메시지의 no-load 지연)입니다.
그러나 실제로는 각 네트워크 기술 유형에 대한 표준 지연 수치가 사용됩니다. 예를 들어 이더넷 및 특정 비트 속도의 직렬 회선에 대한 표준 지연 수치가 있습니다.
다음은 위의 네트워크 6 다이어그램에서 게이트웨이 A의 라우팅 테이블이 어떻게 표시되는지를 보여 주는 예입니다. (단순화를 위해 메트릭 벡터의 개별 구성 요소는 표시되지 않습니다.)
라우팅 테이블 예:
| 네트워크 | 인터페이스 | 다음 게이트웨이 | 메트릭 |
|---|---|---|---|
| 1 | NW 1 | 없음 | 직접 연결됨 |
| 2 | NW 2 | 없음 | 직접 연결됨 |
| 3 | NW 3 | 없음 | 직접 연결됨 |
| 4 | NW 2 | C | 1270 |
| NW 3 | B | 1180 | |
| 5 | NW 2 | C | 1270 |
| NW 3 | B | 2130 | |
| 6 | NW 2 | C | 2040 |
| NW 3 | B | 1180 |
이웃과 정보를 교환하여 라우팅 테이블을 구축하는 기본 프로세스는 Bellman-Ford 알고리즘으로 설명됩니다. 이 알고리즘은 RIP(RFC 1058)와 같은 이전 프로토콜에서 사용되어 왔습니다. 더 복잡한 네트워크를 처리하기 위해 IGRP는 기본 Bellman-Ford 알고리즘에 세 가지 기능을 추가합니다.
-
단순한 메트릭이 아니라 메트릭의 벡터가 경로 특성을 지정하는 데 사용됩니다. 단일 복합 메트릭은 위의 수학식 1에 따라 이 벡터로부터 계산될 수 있다. 벡터를 사용하면 등식 1에서 여러 가지 다른 계수를 사용하여 게이트웨이가 다양한 유형의 서비스를 수용할 수 있습니다. 또한 단일 메트릭보다 네트워크의 특성을 더 정확하게 표현할 수 있습니다.
-
메트릭이 가장 작은 단일 경로를 선택하는 대신, 지정된 범위에 속하는 메트릭과 함께 여러 경로로 트래픽이 분할됩니다. 이를 통해 여러 경로를 병렬로 사용할 수 있어 어떤 단일 경로보다 더 큰 유효 대역폭을 제공합니다. 차이 V는 네트워크 관리자가 지정합니다. 최소 복합 메트릭 M이 있는 모든 경로가 유지됩니다. 또한 메트릭이 V x M 미만인 모든 경로는 유지됩니다. 트래픽은 복합 메트릭에 반비례하여 여러 경로로 분산됩니다.
-
이러한 분산 개념에는 몇 가지 문제가 있다. 분산값이 1보다 크고, 패킷 루핑으로 이어지지 않는 전략 마련이 어렵다. Cisco 릴리스 8.2에서는 분산 기능이 구현되지 않습니다. (어떤 릴리스에서 기능이 제거되었는지 잘 모르겠습니다.) 이 효과의 효과는 분산이 영구적으로 1로 설정되는 것이다.
-
토폴로지가 변경되는 상황에서 안정성을 제공하기 위해 몇 가지 기능이 도입되었습니다. 이러한 기능은 라우팅 루프를 방지하고 "무한대로 계산"하는 것을 방지하기 위한 것으로, 이러한 유형의 응용 프로그램에 대해 포드 유형 알고리즘을 사용하려는 이전의 시도를 특징화했습니다. 주요 안정성 기능은 "holddowns", "triggered updates", "split horizon" 및 "pieration"입니다. 이에 대해서는 아래에서 자세히 설명합니다.
트래픽 분할(지점 2)은 다소 미묘한 위험을 야기합니다. 차이 V는 게이트웨이가 서로 다른 속도의 병렬 경로를 사용할 수 있도록 설계되었습니다. 예를 들어 이중화를 위해 19200 BPS 회선과 병렬로 실행되는 9600 BPS 회선이 있을 수 있습니다. 분산 V가 1이면 최상의 경로만 사용된다. 따라서 9600 BPS 라인은 19200 BPS 라인이 합리적인 신뢰성을 가질 경우 사용되지 않습니다. 그러나 여러 경로가 동일한 경우 로드가 여러 경로 간에 공유됩니다. 분산을 높이면 트래픽이 최상의 경로와 거의 동일한 다른 경로로 분할되도록 할 수 있습니다. 편차가 충분히 크므로 트래픽이 두 행 간에 분할됩니다. 위험은 충분히 큰 분산을 가지고, 경로가 단지 느려지는 것이 아니라, 실제로 "잘못된 방향으로" 허용된다는 것이다. 따라서 트래픽이 "업스트림"으로 전송되지 않도록 하는 추가 규칙이 있어야 합니다. 원격 복합 메트릭(다음 홉에서 계산된 복합 메트릭)이 게이트웨이에서 계산된 복합 메트릭보다 큰 경로를 따라 트래픽이 전송되지 않습니다. 일반적으로 시스템 관리자는 병렬 경로를 사용해야 하는 특정 상황을 제외하고 분산을 1보다 높게 설정하지 않는 것이 좋습니다. 이 경우 분산은 "올바른" 결과를 제공하도록 신중하게 설정됩니다.
IGRP는 여러 "서비스 유형" 및 여러 프로토콜을 처리하기 위한 것입니다. 서비스 유형은 경로를 평가하는 방법을 수정하는 데이터 패킷의 사양입니다. 예를 들어, TCP/IP 프로토콜을 사용하면 패킷이 높은 대역폭, 낮은 지연 또는 높은 신뢰성의 상대적 중요도를 지정할 수 있습니다. 일반적으로 대화형 애플리케이션은 낮은 지연을 지정하는 반면, 대량 전송 애플리케이션은 높은 대역폭을 지정합니다. 이러한 요건은 Eq에서 사용하기에 적합한 K1과 K2의 상대적인 값을 결정한다. 1. 지원하려는 패킷의 각 사양 조합을 "서비스 유형"이라 합니다. 각 서비스 유형에 대해 파라미터 K1 및 K2의 세트가 선택되어야 한다. 라우팅 테이블은 서비스 유형별로 보관됩니다. Eq로 정의된 복합 메트릭에 따라 경로가 선택되고 순서가 지정되므로 이렇게 됩니다. 1. 서비스 유형별로 다릅니다. 그림 7에 설명된 대로 이러한 모든 라우팅 테이블의 정보를 결합하여 게이트웨이에서 교환하는 라우팅 업데이트 메시지를 생성합니다.
안정성 기능
이 섹션에서는 보류, 트리거된 업데이트, 스플릿 호라이즌(split horizon) 및 중독에 대해 설명합니다. 이러한 기능은 게이트웨이가 잘못된 경로를 선택하지 못하도록 설계되었습니다. RFC 1058에 설명된![]() 것처럼, 게이트웨이 또는 네트워크의 장애로 인해 경로를 사용할 수 없게 될 때 이 문제가 발생할 수 있습니다. 기본적으로 인접한 게이트웨이는 장애를 탐지합니다. 그런 다음 기존 경로를 사용할 수 없는 것으로 표시하는 라우팅 업데이트를 전송합니다. 그러나 업데이트가 네트워크의 일부 영역에 전혀 도달하지 못하거나 특정 게이트웨이에 도달하는 것이 지연될 수 있습니다. 여전히 이전 경로가 좋다고 생각하는 게이트웨이는 해당 정보를 계속 확산하여 실패한 경로를 시스템에 재입력할 수 있습니다. 결국 이 정보는 네트워크를 통해 전파되어 이를 재주입한 게이트웨이로 다시 돌아갑니다. 순환 경로가 생성됩니다.
것처럼, 게이트웨이 또는 네트워크의 장애로 인해 경로를 사용할 수 없게 될 때 이 문제가 발생할 수 있습니다. 기본적으로 인접한 게이트웨이는 장애를 탐지합니다. 그런 다음 기존 경로를 사용할 수 없는 것으로 표시하는 라우팅 업데이트를 전송합니다. 그러나 업데이트가 네트워크의 일부 영역에 전혀 도달하지 못하거나 특정 게이트웨이에 도달하는 것이 지연될 수 있습니다. 여전히 이전 경로가 좋다고 생각하는 게이트웨이는 해당 정보를 계속 확산하여 실패한 경로를 시스템에 재입력할 수 있습니다. 결국 이 정보는 네트워크를 통해 전파되어 이를 재주입한 게이트웨이로 다시 돌아갑니다. 순환 경로가 생성됩니다.
사실 대책들 사이에 약간의 중복이 있습니다. 애초에 잘못된 경로를 막을 수 있는 보류 및 트리거된 업데이트가 충분해야 하는 것이 원칙이다. 그러나 실무상 여러 종류의 통신 실패로 불충분할 수 있다. 수평선 분할 및 경로 중독은 어떤 경우에도 라우팅 루프를 방지하기 위한 것입니다.
일반적으로 새 라우팅 테이블은 정기적으로(시스템 관리자가 조정할 수 있지만 기본적으로 90초마다) 인접한 게이트웨이로 전송됩니다. 트리거된 업데이트는 일부 변경에 대한 응답으로 즉시 전송되는 새 라우팅 테이블입니다. 가장 중요한 변화는 경로 제거입니다. 이 문제는 시간 초과가 만료되었거나(인접한 게이트웨이 또는 회선이 작동 중지되었을 수 있음) 경로의 다음 게이트웨이에서 업데이트 메시지가 해당 경로를 더 이상 사용할 수 없음을 나타내기 때문에 발생할 수 있습니다. 게이트웨이 G는 경로를 더 이상 사용할 수 없음을 감지하면 즉시 업데이트를 트리거합니다. 이 업데이트는 해당 경로를 사용할 수 없는 것으로 표시합니다. 이 업데이트가 인접 게이트웨이에 도달할 때 발생하는 상황을 고려하십시오. 인접 디바이스의 경로가 다시 G를 가리킬 경우 인접 디바이스는 경로를 제거해야 합니다. 그러면 네이버가 업데이트 등을 트리거합니다. 따라서 오류가 발생하면 업데이트 메시지의 물결이 트리거됩니다. 이 흐름은 경로가 실패한 게이트웨이 또는 네트워크를 통과한 네트워크의 해당 부분에 전파됩니다.
트리거된 업데이트는 업데이트 흐름이 모든 적절한 게이트웨이에 즉시 도달하도록 보장할 수 있으면 충분합니다. 하지만 두 가지 문제가 있습니다. 먼저, 업데이트 메시지가 포함된 패킷은 네트워크의 일부 링크에 의해 삭제되거나 손상될 수 있습니다. 둘째, 트리거된 업데이트가 즉시 발생하지 않습니다. 트리거된 업데이트를 아직 받지 않은 게이트웨이가 잘못된 시간에 정기적인 업데이트를 실행하여, 이미 트리거된 업데이트를 받은 네이버에 잘못된 경로가 다시 삽입될 수 있습니다. 보류 작업은 이러한 문제를 해결하도록 설계되었습니다. 보류 규칙은 경로가 제거되면 일정 기간 동안 동일한 대상에 대해 새 경로가 허용되지 않음을 나타냅니다. 이렇게 하면 트리거된 업데이트가 다른 모든 게이트웨이에 도달할 수 있는 시간을 제공하므로, 새 경로가 기존 게이트웨이를 다시 삽입하는 게이트웨이가 아닌 것을 확인할 수 있습니다. 보류 기간은 트리거된 업데이트의 흐름이 네트워크 전반으로 이동할 수 있도록 충분히 길어야 합니다. 또한 삭제된 패킷을 처리하려면 몇 가지 정규 브로드캐스트 주기를 포함해야 합니다. 트리거된 업데이트 중 하나가 삭제되거나 손상된 경우 어떻게 되는지 생각해 보십시오. 해당 업데이트를 실행한 게이트웨이는 다음 정기 업데이트에서 또 다른 업데이트를 실행합니다. 이렇게 하면 초기 전파 흔적을 놓친 네이버에서 트리거된 업데이트 전파가 다시 시작됩니다.
트리거된 업데이트 및 보류 조합은 만료된 경로를 제거하고 다시 삽입되지 않도록 충분히 해야 합니다. 그러나, 어떤 추가 예방 조치는 어쨌든 할 가치가 있다. 매우 손실 많은 네트워크와 파티셔닝된 네트워크를 허용합니다. IGRP에서 요구하는 추가 예방 조치는 수평선과 경로 중독입니다. 갈라진 지평선은 그것이 왔던 방향으로 경로를 되돌려 보내는 것은 결코 이치에 맞지 않는다는 관찰로부터 발생한다. 다음과 같은 상황을 고려하십시오.
network 1 network 2
-------------X-----------------X
gateway A gateway B
게이트웨이 A는 B에게 네트워크 1에 대한 경로가 있음을 알립니다. B가 A에 업데이트를 전송할 때 네트워크 1을 언급할 이유는 없습니다. A가 1에 가까우므로 B를 거치는 것을 고려할 이유가 없습니다. 분할 대상 기간 규칙에서는 각 네이버(실제로 각 네이버 네트워크)에 대해 별도의 업데이트 메시지를 생성해야 한다고 말합니다. 지정된 네이버에 대한 업데이트에서는 해당 네이버를 가리키는 경로를 생략해야 합니다. 이 규칙은 인접한 게이트웨이 간의 루프를 방지합니다. 예: 네트워크 1에 대한 A의 인터페이스가 실패했다고 가정해 보겠습니다. 스플릿 호라이즌 규칙이 없으면 B는 A에게 1에 도달할 수 있다고 말할 것입니다. A는 더 이상 실제 경로를 가지고 있지 않기 때문에 해당 경로를 선택할 수 있습니다. 이 경우 A와 B는 모두 1에 대한 경로를 갖지만 A는 B를 가리키고 B는 A를 가리킵니다. 물론 트리거된 업데이트와 중단은 이러한 현상이 발생하지 않도록 방지해야 합니다. 하지만 정보를 보낸 곳으로 다시 보낼 이유가 없기 때문에 split horizon은 어쨌든 할 가치가 있습니다. 스플릿 호라이즌은 루프를 방지하는 역할 외에도 업데이트 메시지의 크기를 줄입니다.
Split horizon은 인접한 게이트웨이 간의 루프를 방지해야 합니다. 경로 중독은 더 큰 고리를 끊기 위한 것이다. 기존 경로의 메트릭이 충분히 증가한 것을 업데이트에서 표시하는 경우 루프가 발생합니다. 그 노선은 제거해서 보류해야 한다. 현재 규칙은 복합 메트릭이 1.1배 이상 증가하는 경우 경로가 제거되는 것입니다. 채널 점유율 또는 신뢰도의 변화로 인해 작은 메트릭 변화가 발생할 수 있으므로 복합 메트릭이 증가해도 경로 제거가 트리거되는 것은 안전하지 않습니다. 따라서 1.1의 요인은 단지 휴리스틱에 불과하다. 정확한 값은 중요하지 않습니다. 작은 루프는 트리거된 업데이트와 지연으로 인해 방지되므로 이 규칙은 매우 큰 루프만 해제하면 됩니다.
보류 사용 안 함
릴리스 8.2부터 Cisco 코드에서는 보류 해제 옵션을 제공합니다. 노선변경의 단점은 기존 노선이 실패했을 때 새로운 노선의 채택을 지연시킨다는 점이다. 기본 매개변수를 사용하면 변경 후 라우터가 새 경로를 채택하기까지 몇 분 정도 걸릴 수 있습니다. 다만, 앞서 설명한 이유로 단순히 홀드다운을 제거하는 것만으로는 안전하지 않다. RFC 1058에 설명된 대로 결과는 최대 무한대로 계산됩니다. 우리는 경로 중독의 더 강력한 버전으로, 더 이상 홀드다운이 무한대로 카운트를 멈출 필요가 없다는 것을 추측하지만 증명할 수 없다. 따라서 홀드다운을 비활성화하면 더 강력한 형태의 경로 중독이 가능해집니다. split horizon 및 triggered 업데이트가 여전히 유효합니다.
더 강력한 형태의 경로 중독은 홉 수에 근거한다. 경로에 대한 홉 수가 증가하면 경로가 제거됩니다. 이렇게 하면 여전히 유효한 경로가 제거됩니다. 네트워크의 다른 곳에서 어떤 것이 변경되어 경로가 이제 게이트웨이를 하나 더 통과하는 경우 홉 수는 증가합니다. 이 경우 경로는 여전히 유효합니다. 그러나 이 경우를 라우팅 루프에서 구별하는 완전히 안전한 방법은 없습니다(count to infinity). 따라서 가장 안전한 방법은 홉 수가 증가할 때마다 경로를 제거하는 것입니다. 경로가 여전히 합법적인 경우 다음 업데이트에 의해 다시 설치되며, 트리거된 업데이트로 인해 시스템의 다른 위치에 경로가 재설치됩니다.
일반적으로, 거리 벡터 알고리즘1은 새로운 경로를 쉽게 채택한다. 그 문제는 시스템에서 오래된 것들을 완전히 제거하는 것이다. 따라서 의심스러운 경로를 제거하는데 지나치게 공격적인 규칙은 안전해야 한다.
업데이트 프로세스 세부사항
그림 4~8에 설명된 프로세스 집합은 단일 네트워크 프로토콜(예: TCP/IP, DECnet 또는 ISO/OSI 프로토콜)을 처리하기 위한 것입니다. 그러나 프로토콜 세부사항은 TCP/IP에 대해서만 제공됩니다. 하나의 게이트웨이가 둘 이상의 프로토콜을 따르는 데이터를 처리할 수 있다. 각 프로토콜은 주소 구조와 패킷 형식이 다르기 때문에 그림 4 ~ 8을 구현하는 데 사용되는 컴퓨터 코드는 일반적으로 각 프로토콜마다 다릅니다. 그림 4에 설명된 프로세스는 그림 4의 세부 참고 사항에 설명된 대로 가장 많이 달라질 것입니다. 그림 5 ~ 8에 설명된 프로세스는 동일한 일반적인 구조를 갖습니다. 프로토콜 간의 주요 차이점은 라우팅 업데이트 패킷의 형식이며, 특정 프로토콜과 호환되도록 설계되어야 합니다.
대상의 정의는 프로토콜마다 다를 수 있습니다. 여기에 설명된 방법은 개별 호스트로의 라우팅, 네트워크로의 라우팅 또는 보다 복잡한 계층적 주소 체계에 사용할 수 있습니다. 사용되는 라우팅 유형은 프로토콜의 주소 지정 구조에 따라 달라집니다. 현재 TCP/IP 구현에서는 IP 네트워크로의 라우팅만 지원합니다. 따라서 "대상"은 IP 네트워크 또는 서브넷 번호를 의미합니다. 서브넷 정보는 연결된 네트워크에만 보관됩니다.
그림 4~7은 게이트웨이에서 사용되는 다양한 라우팅 프로세스의 의사 코드를 보여줍니다. 프로그램이 시작되면 각 인터페이스를 설명하는 허용 가능한 프로토콜과 매개변수가 입력됩니다.
게이트웨이는 나열된 특정 프로토콜만 처리합니다. 목록에 없는 프로토콜을 사용하는 시스템의 모든 통신은 무시됩니다. 데이터 입력은 다음과 같습니다.
-
게이트웨이가 연결되는 네트워크입니다.
-
각 네트워크의 언로드된 대역폭.
-
각 네트워크의 토폴로지 지연.
-
각 네트워크의 신뢰성.
-
각 네트워크의 채널 점유율.
-
각 네트워크의 MTU.
각 데이터 경로에 대한 메트릭 함수는 식 1에 따라 계산됩니다. 처음 세 항목은 합리적으로 영구적입니다. 이러한 기능은 기본 네트워크 기술의 기능이며 부하에 의존하지 않습니다. 컨피그레이션 파일에서 또는 직접 연산자 입력으로 설정할 수 있습니다. IGRP는 측정된 지연을 사용하지 않습니다. 이론과 경험 모두 측정된 지연을 사용하는 프로토콜이 안정적인 라우팅을 유지하는 것이 매우 어렵다는 것을 시사한다. 두 가지 측정 매개변수가 있습니다. 안정성 및 채널 점유율. 신뢰성은 네트워크 인터페이스 하드웨어 또는 펌웨어가 보고한 오류율을 기반으로 합니다.
이러한 입력 외에도 라우팅 알고리즘에는 여러 라우팅 매개변수에 대한 값이 필요합니다. 여기에는 타이머 값, 차이 및 보류 사용 여부가 포함됩니다. 이는 일반적으로 컨피그레이션 파일 또는 연산자 입력에 의해 지정됩니다. (Cisco 릴리스 8.2부터는 분산이 영구적으로 1로 설정됩니다.)
초기 정보가 입력되면 게이트웨이의 작업은 네트워크 인터페이스 중 하나에 데이터 패킷이 도착하거나 타이머가 만료되는 등의 이벤트에 의해 트리거됩니다. 그림 4 ~ 7에 설명된 프로세스는 다음과 같이 트리거됩니다.
-
패킷이 도착하면 그림 4에 따라 처리됩니다. 그러면 패킷이 다른 인터페이스로 전송되거나 폐기되거나 추가 처리를 위해 수락됩니다.
-
패킷이 추가 처리를 위해 게이트웨이에 수락되면, 본 명세서에서 설명되지 않은 프로토콜 특정 방식으로 분석된다. 패킷이 라우팅 업데이트인 경우 그림 5에 따라 처리됩니다.
-
그림 6은 타이머에 의해 트리거된 이벤트를 보여줍니다. 타이머는 초당 한 번 인터럽트를 생성하도록 설정되어 있습니다. 인터럽트가 발생하면, Fig.6과 같은 처리를 실행한다.
-
그림 7은 라우팅 업데이트 서브루틴을 보여줍니다. 이 서브루틴에 대한 호출은 그림 5와 6에 나와 있습니다.
-
또한 Fig.8은 Fig.5와 Fig.7에서 언급하는 메트릭 연산의 세부 사항을 보여주고 있다.
경로 전파 및 만료를 제어하는 4개의 중요한 시간 상수가 있습니다. 이러한 시간 상수는 시스템 관리자가 설정할 수 있습니다. 그러나 기본값이 있습니다. 이러한 시간 상수는 다음과 같습니다.
-
Broadcast time(브로드캐스트 시간) - 업데이트가 연결된 모든 인터페이스의 모든 게이트웨이에 의해 자주 브로드캐스트됩니다. 기본값은 90초에 한 번입니다.
-
Invalid time(유효하지 않은 시간) - 이 시간 내에 지정된 경로에 대한 업데이트가 수신되지 않은 경우, 시간 초과된 것으로 간주됩니다. 업데이트가 포함된 패킷이 네트워크에 의해 삭제될 수 있는 가능성을 허용하려면 브로드캐스트 시간의 몇 배가 되어야 합니다. 기본값은 브로드캐스트 시간의 3배입니다.
-
Hold time(보류 시간) - 대상에 연결할 수 없는 경우(또는 메트릭이 증가하여 중독이 발생한 경우), 대상이 "holddown"으로 전환됩니다. 이 상태 동안에는 이 시간 동안 동일한 대상에 대해 새 경로가 허용되지 않습니다. 보류 시간은 이 상태가 지속되는 시간을 나타냅니다. 방송 시간의 몇 배가 되어야 합니다. 기본값은 브로드캐스트 시간의 3배 + 10초입니다. (보류 비활성화 섹션에 설명된 것처럼, 보류 비활성화가 가능합니다.)
-
Flush time(플러시 시간) - 이 시간 내에 지정된 대상에 대한 업데이트가 수신되지 않은 경우 해당 항목이 라우팅 테이블에서 제거됩니다. 유효하지 않은 시간과 플러시 시간의 차이를 확인합니다. 잘못된 시간이 지나면 경로가 시간 초과되어 제거됩니다. 대상에 대한 나머지 경로가 없는 경우 대상에 연결할 수 없습니다. 그러나 대상에 대한 데이터베이스 항목은 남아 있습니다. 유보조치를 시행하기 위해서는 유보해야 한다. 플러시 시간이 지나면 데이터베이스 항목이 테이블에서 제거됩니다. 유효하지 않은 시간과 보류 시간을 더한 시간보다 다소 길어야 합니다. 기본값은 브로드캐스트 시간의 7배입니다.
이러한 수치는 다음과 같은 주요 데이터 구조를 전제로 한다. 이러한 데이터 구조의 별도의 집합은 게이트웨이에서 지원하는 각 프로토콜에 대해 유지됩니다. 각 프로토콜 내에서 각 서비스 유형별로 별도의 데이터 구조 집합이 유지되어 지원됩니다.
시스템에 알려진 각 대상에 대해 대상에 대한 경로 목록(null일 수 있음), 보류 만료 시간 및 마지막 업데이트 시간이 있습니다. 마지막 업데이트 시간은 이 대상에 대한 경로가 다른 게이트웨이의 업데이트에 마지막으로 포함된 시간을 나타냅니다. 각 경로에 대한 업데이트 시간도 유지됩니다. 목적지에 대한 마지막 경로가 제거되면 보류 기능이 비활성화되지 않는 한 목적지는 보류 상태가 됩니다(자세한 내용은 보류 기능 비활성화 섹션 참조). holddown expiration time은 holddown이 만료되는 시간을 나타냅니다. 0이 아닌 것은 대상이 보류 중임을 나타냅니다. 계산 시간을 절약하기 위해서는 각 목적지에 대해 '최상 메트릭'을 유지하는 것도 좋다. 이는 목적지에 대한 모든 경로에 대한 복합 메트릭스의 최소값입니다.
대상에 대한 각 경로에는 경로의 다음 홉 주소, 사용할 인터페이스, 경로를 특징화하는 메트릭 벡터(토폴로지 지연, 대역폭, 안정성 및 채널 점유 포함)가 있습니다. 홉 수, MTU, 정보 소스, 원격 복합 메트릭, 수식 1에 따라 이러한 숫자로 계산된 복합 메트릭 등 다른 정보도 각 경로와 연결됩니다. 마지막 업데이트 시간도 있습니다. 정보 소스는 해당 경로에 대한 최신 업데이트가 어디서 왔는지 나타냅니다. 실제로 이 주소는 다음 홉의 주소와 동일합니다. 마지막 업데이트 시간은 이 경로에 대한 최신 업데이트가 도착한 시간입니다. 시간 초과된 경로를 만료하는 데 사용됩니다.
IGRP 업데이트 메시지에는 세 가지 부분이 있습니다. 내부, 시스템("이 자율 시스템"을 의미하지만 내부는 아님) 및 외부 내부 섹션은 서브넷에 대한 경로입니다. 일부 서브넷 정보는 포함되지 않습니다. 한 네트워크의 서브넷만 포함됩니다. 업데이트가 전송되는 주소와 연결된 네트워크입니다. 일반적으로 업데이트는 각 인터페이스에서 브로드캐스트되므로, 이는 브로드캐스트가 전송되는 네트워크일 뿐입니다. (IGRP 요청에 응답하고 IGRP를 가리키기 위해 발생하는 다른 경우도 있습니다.) 주요 네트워크(예: 비 서브넷)는 외부로 특별히 플래그가 지정되지 않은 한 업데이트 메시지의 시스템 부분에 배치됩니다.
다른 게이트웨이에서 학습한 경우 업데이트 메시지의 외부 부분에 해당 정보가 도착하면 네트워크에 외부 플래그가 지정됩니다. Cisco의 구현을 통해 시스템 관리자는 특정 네트워크를 외부로 선언할 수도 있습니다. 외부 경로는 "후보자 기본값"이라고도 합니다. 이는 목적지에 대한 명시적 경로가 없을 때 사용할, 기본값으로 적절한 것으로 간주되는 게이트웨이를 통과하는 경로입니다. 예를 들어 Rutgers에서는 Rutgers를 지역 네트워크에 연결하는 게이트웨이를 구성하여 NSFnet 백본에 대한 경로에 외부 플래그를 지정합니다. Cisco의 구현에서는 가장 작은 메트릭을 가진 외부 경로를 선택하여 기본 경로를 선택합니다.
다음 섹션에서는 그림 4 ~ 8의 특정 부분을 명확히 설명하고자 합니다.
패킷 라우팅
그림 4는 입력 패킷의 전반적인 처리를 설명합니다. 이는 단순히 용어를 명확히 하기 위해 사용됩니다. IP 게이트웨이가 수행하는 작업에 대한 완전한 설명은 아닙니다.
이 프로세스에서는 지원되는 프로토콜 목록과 게이트웨이가 초기화될 때 입력한 인터페이스 정보를 사용합니다. 패킷 처리의 세부사항은 패킷에 사용된 프로토콜에 따라 다릅니다. 이는 A단계에서 결정됩니다. A단계는 그림 4에서 모든 프로토콜이 공유하는 유일한 부분입니다. 프로토콜 유형이 알려지면 프로토콜 유형에 적합한 그림 4의 구현이 사용됩니다. 패킷 내용의 세부사항은 프로토콜의 사양에 따라 설명됩니다. 프로토콜의 규격은 패킷의 목적지를 판단하는 절차, 목적지와 게이트웨이의 고유 주소를 비교하여 게이트웨이 자체가 목적지인지 판단하는 절차, 패킷이 브로드캐스트인지 판단하는 절차, 목적지가 특정 네트워크에 속하는지 판단하는 절차를 포함한다. 이러한 절차는 그림 4의 B단계와 C단계에서 사용됩니다. D단계의 테스트를 수행하려면 라우팅 테이블에 나열된 대상을 검색해야 합니다. 대상에 대한 라우팅 테이블에 항목이 있고 해당 대상이 하나 이상의 사용 가능한 경로와 연결된 경우 테스트가 충족됩니다. 이 단계와 다음 단계에서 사용되는 대상 및 경로 데이터는 지원되는 서비스 유형별로 별도로 유지됩니다. 따라서 이 단계는 패킷에 의해 지정된 서비스 유형을 결정하고, 이 단계와 다음 단계에 사용할 해당 데이터 구조 집합을 선택하는 것으로 시작합니다.
경로는 원격 복합 메트릭이 복합 메트릭보다 작은 경우 D 및 E 단계의 용도로 사용할 수 있습니다. 원격 복합 메트릭이 해당 복합 메트릭보다 큰 경로는 다음 홉이 메트릭에 의해 측정된 대로 목적지에서 "더 멀리" 있는 경로입니다. 이를 "업스트림 경로"라고 합니다. 일반적으로 메트릭을 사용하면 업스트림 경로를 선택할 수 없게 됩니다. 상류로 가는 길은 결코 최고가 될 수 없다는 것을 쉽게 알 수 있다. 그러나 큰 분산을 허용하면 최상의 경로 이외의 경로를 사용할 수 있습니다. 그 중 일부는 상류에 있을 수 있습니다.
E단계에서는 사용할 경로를 계산합니다. 원격 복합 메트릭이 해당 복합 메트릭보다 작지 않은 경로는 고려되지 않습니다. 하나 이상의 경로가 허용될 경우, 이러한 경로는 라운드 로빈 교대의 가중된 형태로 사용된다. 경로가 사용되는 빈도는 합성 메트릭에 반비례한다.
라우팅 업데이트 수신
그림 5는 인접 게이트웨이에서 수신한 라우팅 업데이트의 처리 과정을 보여줍니다. 이러한 업데이트는 단일 대상에 대한 정보를 제공하는 항목 목록으로 구성됩니다. 여러 서비스 유형을 수용하기 위해 동일한 대상에 대해 둘 이상의 엔트리가 단일 라우팅 업데이트에서 발생할 수 있습니다. 이러한 항목은 그림 5에 설명된 대로 각각 개별적으로 처리됩니다. 항목이 업데이트의 외부 섹션에 있는 경우 이 프로세스의 결과로 추가된 대상에 대해 외부 플래그가 설정됩니다.
그림 5에 설명된 전체 프로세스는 게이트웨이가 지원하는 서비스 유형별로 해당 서비스 유형과 관련된 대상/경로 정보 집합을 사용하여 한 번씩 반복해야 합니다. 이는 그림 5의 가장 바깥쪽 루프에 나와 있습니다. 서비스 유형별로 전체 라우팅 업데이트를 한 번씩 처리해야 합니다. (현재 IGRP 구현에서는 여러 유형의 서비스를 지원하지 않으므로 가장 바깥쪽 루프가 실제로 구현되지 않습니다.)
단계 A에서는 경로에 대한 기본 허용성 테스트가 수행됩니다. 여기에는 대상에 대한 합리성 테스트가 포함되어야 합니다. Impossible("Martian") 네트워크 번호는 거부되어야 합니다. (자세한 내용은 RFC 1009![]() 및 RFC 1122
및 RFC 1122![]() 를 참조하십시오.) 또한 참조하는 대상이 보류 중인 경우(예: 보류 만료 시간이 0이 아니고 현재 시간보다 이후인 경우) 업데이트가 거부됩니다.
를 참조하십시오.) 또한 참조하는 대상이 보류 중인 경우(예: 보류 만료 시간이 0이 아니고 현재 시간보다 이후인 경우) 업데이트가 거부됩니다.
B단계에서는 라우팅 테이블을 검색하여 이 항목이 이미 알려진 경로를 설명하는지 확인합니다. 라우팅 테이블의 경로는 연결된 대상, 경로의 일부로 나열된 다음 홉, 경로에 사용될 출력 인터페이스 및 정보 소스(일반적으로 다음 홉과 같은 경우 업데이트가 시작된 주소)에 의해 정의됩니다. 업데이트 패킷의 항목은 대상이 항목에 나열되고, 출력 인터페이스가 업데이트가 들어온 인터페이스이며, 다음 홉 및 정보 소스가 업데이트를 보낸 게이트웨이(이하 "소스") 주소인 경로를 설명합니다.
스텝 H와 스텝 T에서는, 그림 7에 기재된 갱신 처리를 스케줄링한다. 이 프로세스는 그림 5에 설명된 전체 프로세스가 끝난 후에 실제로 실행될 것입니다. 즉, 그림 7에 설명된 업데이트 프로세스는 그림 5에 설명된 처리 중 여러 번 트리거되더라도 한 번만 수행됩니다. 또한 네트워크가 빠르게 변경되는 경우 업데이트가 너무 자주 실행되지 않도록 주의해야 합니다.
K단계는 업데이트 패킷의 현재 엔트리에 의해 기술된 목적지가 라우팅 테이블에 이미 존재하는 경우에 수행된다. K는 업데이트 패킷의 데이터에서 계산된 새 복합 메트릭을 대상에 대한 최상의 복합 메트릭과 비교합니다. 최상의 복합 메트릭은 현재 다시 계산되지 않으므로, 고려 중인 경로가 라우팅 테이블에 이미 있는 경우 이 테스트에서는 동일한 경로에 대한 새 메트릭과 이전 메트릭을 비교할 수 있습니다.
L단계는 기존 최상의 복합 메트릭보다 더 나쁜 경로에 대해 수행됩니다. 여기에는 기존 경로보다 더 나쁜 새 경로와 복합 메트릭이 증가한 기존 경로가 모두 포함됩니다. L단계에서는 새 경로가 허용되는지 테스트합니다. 이 테스트에서는 새 경로가 유지할 수 있는지 여부와 경로 중독에 대한 테스트를 모두 구현합니다. 허용되려면 지연 값이 연결할 수 없는 대상(현재 IP 구현의 경우 24비트 필드의 모든 대상)을 나타내는 특수 값이 아니어야 하며, 복합 메트릭(그림 8에 지정된 대로 계산됨)이 허용되어야 합니다. 복합 메트릭을 사용할 수 있는지 확인하려면 대상에 대한 다른 모든 경로의 복합 메트릭과 비교합니다. M은 이것들의 최소가 되도록 하세요. 새 경로는 < V X M인 경우 허용됩니다. 여기서 V는 게이트웨이가 초기화될 때 설정된 분산입니다. V = 1(CISCO 릴리스 8.2에서는 항상 TRUE)이면 기존 메트릭보다 더 나쁜 메트릭을 사용할 수 없습니다. 여기에는 한 가지 예외가 있습니다. 경로가 이미 있고 대상에 대한 유일한 경로인 경우, 메트릭이 10% 이상 증가하지 않은 경우(또는 홉 수가 증가하지 않은 경우 보류 기능이 비활성화된 경우) 경로가 유지됩니다.
V단계는 경로에 대한 새로운 정보가 복합 메트릭이 감소될 것임을 나타낼 때 수행된다. 목적지 D에 대한 모든 경로의 복합 메트릭을 비교합니다. 이 비교에서는 라우팅 테이블에 나타나는 메트릭 대신 P에 대한 새 복합 메트릭이 사용됩니다. 최소 복합 메트릭 M이 계산됩니다. 그런 다음 D에 대한 모든 경로가 다시 검사됩니다. 임의의 경로에 대한 조합 메트릭이 M x V를 초과하면 해당 경로가 제거됩니다. V는 게이트웨이가 초기화될 때 입력된 분산입니다. (Cisco 릴리스 8.2부터는 분산이 영구적으로 1로 설정됩니다.)
주기적 처리
그림 6에 설명된 프로세스는 1초에 한 번 트리거됩니다. 라우팅 테이블의 다양한 타이머를 검사하여 만료된 타이머가 있는지 확인합니다. 이러한 타이머는 위에서 설명합니다.
U단계에서는 Fig.7에서 설명한 과정을 활성화시킨다.
라우팅 테이블에 저장된 복합 메트릭은 채널 점유율에 따라 결정되며, 측정값에 따라 시간이 지남에 따라 변경됩니다. 정기적으로 인터페이스를 통해 측정된 트래픽의 이동 평균을 사용하여 채널 점유율이 다시 계산됩니다. 새로 계산된 값이 기존 값과 다를 경우 해당 인터페이스와 관련된 모든 복합 메트릭을 조정해야 합니다. 라우팅 테이블에 표시된 모든 경로를 검사합니다. 다음 홉에서 인터페이스 "I"를 사용하는 모든 경로의 복합 메트릭이 다시 계산됩니다. 이는 경로 메트릭의 일부로서 라우팅 테이블에 저장된 값의 최대값과 인터페이스의 새로 계산된 채널 점유율을 채널 점유율로 사용하여 수학식 1에 따라 수행됩니다.
업데이트 메시지 생성
그림 7에서는 게이트웨이가 다른 게이트웨이로 전송할 업데이트 메시지를 생성하는 방법을 설명합니다. 게이트웨이에 연결된 각 네트워크 인터페이스에 대해 별도의 메시지가 생성됩니다. 그런 다음 이 메시지는 인터페이스를 통해 연결할 수 있는 다른 모든 게이트웨이에 전송됩니다(J단계). 일반적으로 이 작업은 메시지를 브로드캐스트로 전송하여 수행됩니다. 그러나 네트워크 기술 또는 프로토콜에서 브로드캐스트를 허용하지 않는 경우 각 게이트웨이에 개별적으로 메시지를 보내야 할 수 있습니다.
일반적으로 메시지는 G단계에서 라우팅 테이블의 각 대상에 대한 항목을 추가하여 작성됩니다. 각 서비스 유형과 연결된 대상/경로 데이터를 사용해야 합니다. 최악의 경우 각 서비스 유형에 대한 각 대상에 대한 업데이트에 새 항목이 추가됩니다. 그러나 G단계에서 업데이트 메시지에 엔트리를 추가하기 전에 이미 부가된 엔트리들이 스캐닝된다. 새 항목이 업데이트 메시지에 이미 있으면 다시 추가되지 않습니다. 대상과 다음 홉 게이트웨이가 동일한 경우 새 엔트리가 기존 엔트리와 복제됩니다.
간소화를 위해 의사 코드는 한 가지를 생략합니다. IGRP 업데이트 메시지에는 세 가지 부분이 있습니다. 내부, 시스템, 외부 모두 목적지에 3개의 루프가 있습니다. 첫 번째는 업데이트가 전송되는 네트워크의 서브넷만 포함합니다. 두 번째는 외부로 플래그되지 않은 모든 주요 네트워크(예: 비서브넷)를 포함합니다. 세 번째는 외부 플래그가 지정된 모든 주요 네트워크를 포함합니다.
E단계에서는 split horizon test를 구현합니다. 일반적인 경우, 이 테스트는 업데이트가 전송되는 인터페이스와 동일한 인터페이스에서 최상의 경로가 나가는 경로에 대해 실패합니다. 그러나 업데이트가 특정 대상으로 전송되는 경우(예: 다른 게이트웨이의 IGRP 요청에 대한 응답 또는 "point-to-point IGRP"의 일부), 최상의 경로가 원래 해당 대상에서 가져온 경우(해당 "정보 소스"가 대상과 동일함)에만 split horizon이 실패하고 출력 인터페이스가 요청이 들어온 경로와 동일합니다.
계산 메트릭 정보
그림 8은 게이트웨이가 수신한 업데이트 메시지에서 메트릭 정보를 처리하는 방법과 게이트웨이가 전송하는 업데이트 메시지에 대해 메트릭 정보를 생성하는 방법을 설명합니다. 항목은 대상에 대한 하나의 특정 경로를 기반으로 합니다. 대상에 대한 경로가 두 개 이상인 경우 복합 메트릭이 최소인 경로가 선택됩니다. 하나 이상의 경로에 최소 복합 메트릭이 있는 경우 임의의 연결 끊기 규칙이 사용됩니다. (대부분의 프로토콜에서 이는 다음 홉 게이트웨이의 주소를 기반으로 합니다.)
그림 4 — 수신 패킷 처리
Data packet arrives using interface I
A Determine protocol used by packet
If protocol is not supported
then discard packet
B If destination address matches any of gateway's addresses
or the broadcast address
then process packet in protocol-specific way
C If destination is on a directly-connected network
then send packet direct to the destination, using
the encapsulation appropriate to the protocol and link type
D If there are no paths to the destination in the routing
table, or all paths are upstream
then send protocol-specific error message and discard the packet
E Choose the next path to use. If there are more than
one, alternate round-robin with frequency proportional
to inverse of composite metric.
Get next hop from path chosen in previous step.
Send packet to next hop, using encapsulation appropriate
to protocol and data link type.
그림 5 — 수신 라우팅 업데이트 처리
Routing update arrives from source S
For each type of service supported by gateway
Use routing data associated with this type of service
For each destination D shown in update
A If D is unacceptable or in holddown
then ignore this entry and continue loop with next destination D
B Compute metrics for path P to D via S (see Fig 8)
If destination D is not already in the routing table
then Begin
Add path P to the routing table, setting last
update times for P and D to current time.
H Trigger an update
Set composite metric for D and P to new composite
metric computed in step B.
End
Else begin (dest. D is already in routing table)
K Compare the new composite metric for P with best
existing metric for D.
New > old:
L If D is shown as unreachable in the update,
or holddowns are enabled and
the new composite metric >
(the existing metric for D) * V
[use 1.1 instead of V if V = 1,
as it is as of Cisco release 8.2]
O or holddowns are disabled and
P has a new hop count > old hop count
then Begin
Remove P from routing table if present
If P was the last route to D
then Unless holddowns are disabled
Set holddown time for D to
current time + holddown time
T and Trigger an update
End
else Begin
Compute new best composite metric for D
Put the new metric information into the
entry for P in the routing table
Add path P to the routing table if it
was not present.
Set last update times for P and D to
current time.
End
New <= OLD:
V Set composite metric for D and P to new
composite metric computed in step B.
If any other paths to D are now outside the
variance, remove them.
Put the new metric information into the
entry for P in the routing table
Set last update times for P and D to
current time.
End
End of for
End of for
그림 6 — 주기적 처리
Process is activated by regular clock, e.g. once per second
For each path P in the routing table (except directly
connected interfaces)
If current time < P'S LAST UPDATE TIME + INVALID TIME
THEN CONTINUE WITH THE NEXT PATH P
Remove P from routing table
If P was the last route to D
then Set metric for D to inaccessible
Unless holddowns are disabled,
Start holddown timer for D and
Trigger an update
else Recompute the best metric for D
End of for
For each destination D in the routing table
If D's metric is inaccessible
then Begin
Clear all paths to D
If current time >= D's last update time + flush time
then Remove entry for D
End
End of for
For each network interface I attached to the gateway
R Recompute channel occupancy and error rate
S If channel occupancy or error rate has changed,
then recompute metrics
End of for
At intervals of broadcast time
U Trigger update
그림 7 — 업데이트 생성
Process is caused by "trigger update"
For each network interface I attached to the gateway
Create empty update message
For each type of service S supported
Use path/destination data for S
For each destination D
E If any paths to D have a next hop reached through I
then continue with the next destination
If any paths to D with minimal composite metric are
already in the update message
then continue with the next destination
G Create an entry for D in the update message, using
metric information from a path with minimal
composite metric (see Fig. 8)
End of for
End of for
J If there are any entries in the update message
then send it out interface I
End of for
그림 8 — 메트릭 계산의 세부 정보
이 섹션에서는 도착하는 라우팅 업데이트에서 메트릭 및 홉 수를 계산하는 절차에 대해 설명합니다. 이 기능의 입력은 라우팅 업데이트 패킷의 특정 목적지에 대한 항목입니다. 출력은 복합 메트릭을 계산하는 데 사용할 수 있는 메트릭의 벡터와 홉 개수입니다. 이 경로를 라우팅 테이블에 추가하면 메트릭의 전체 벡터가 테이블에 입력됩니다. 다음 정의에 사용된 인터페이스 매개변수는 라우팅 업데이트가 도착한 인터페이스에 대해 게이트웨이가 초기화될 때 설정된 매개변수입니다. 단, 채널 점유 및 신뢰도는 인터페이스를 통해 측정된 트래픽의 이동 평균을 기반으로 합니다.
-
지연 = 패킷 + 인터페이스 토폴로지 지연의 지연
-
Bandwidth = max(패킷의 대역폭, 인터페이스 대역폭)
-
신뢰성 = min(패킷으로부터의 신뢰성, 인터페이스 신뢰성)
-
채널 점유 = max(패킷의 채널 점유, 인터페이스 채널 점유)
(Max는 대역폭 메트릭이 역형식으로 저장되므로 대역폭에 사용됩니다. 개념상 최소 대역폭을 원합니다.) 인터페이스 채널 점유가 변경될 때마다 유효 채널 점유를 다시 계산해야 하므로 패킷의 원래 채널 점유를 저장해야 합니다.
다음은 메트릭 벡터의 일부가 아니라 경로의 특성으로 라우팅 테이블에 보관됩니다.
-
홉 수 = 패킷의 홉 수
-
MTU = min(패킷의 MTU, 인터페이스 MTU).
-
원격 복합 메트릭 = 패킷의 메트릭 값을 사용하여 수식 1에서 계산됩니다. 즉, 메트릭 구성 요소는 패킷의 구성 요소이며 위에 표시된 대로 업데이트되지 않습니다. 분명히 이것은 위에 나타난 조정이 이루어지기 전에 계산되어야 한다.
-
복합 메트릭스 = 이 절에서 설명한 것처럼 계산된 메트릭스 값을 사용하여 식 1로부터 계산됩니다.
이 섹션의 나머지 부분에서는 전송할 라우팅 업데이트의 메트릭 및 홉 수를 계산하는 절차에 대해 설명합니다.
이 기능은 발신 업데이트 패킷에 넣을 메트릭 정보 및 홉 수를 결정합니다. 사용 가능한 경로가 있는 경우 대상에 대한 특정 경로를 기반으로 합니다. 경로가 없거나 경로가 모두 업스트림이면 대상을 "액세스할 수 없음"이라고 합니다.
If destination is inaccessible, this is indicated by using a specific
value in the delay field. This value is chosen to be larger
than the largest valid delay. For the IP implementation this is
all ones in a 24-bit field.
If destination is directly reachable through one of the interfaces, use
the delay, bandwidth, reliability, and channel occupancy of the
interface. Set hop count to 0.
Otherwise, use the vector of metrics associated with the path in the
routing table. Add one to the hop count from the path in the
routing table.
IP 구현 세부 정보
이 섹션에서는 Cisco IGRP에서 사용하는 패킷 형식에 대해 간략하게 설명합니다. IGP(IP protocol 9)가 있는 IP 데이터그램을 사용하여 IGRP를 보냅니다. 패킷은 헤더로 시작합니다. IP 헤더 바로 다음에 시작됩니다.
unsigned version: 4; /* protocol version number */
unsigned opcode: 4; /* opcode */
uchar edition; /* edition number */
ushort asystem; /* autonomous system number */
ushort ninterior; /* number of subnets in local net */
ushort nsystem; /* number of networks in AS */
ushort nexterior; /* number of networks outside AS */
ushort checksum; /* checksum of IGRP header and data */
업데이트 메시지의 경우 헤더 바로 뒤에 라우팅 정보가 표시됩니다.
버전 번호는 현재 1입니다. 다른 버전 번호가 있는 패킷은 무시됩니다.
opcode는 1 = update 또는 2 = request일 수 있습니다.
메시지 유형을 나타냅니다. 두 메시지 유형의 형식은 다음과 같습니다.
Edition은 라우팅 테이블이 변경될 때마다 증가하는 일련 번호입니다. (이는 위의 의사 코드에서 라우팅 업데이트를 트리거한다고 말하는 조건에서 수행됩니다.) 버전 번호를 사용하면 게이트웨이에서 이미 확인한 정보가 포함된 업데이트를 처리하지 않을 수 있습니다. (현재 구현되지 않았습니다. 즉, 에디션 번호는 정확하게 생성되지만 입력 시 무시됩니다. 패킷이 삭제될 수 있으므로 에디션 번호가 중복 처리를 방지하기에 충분한지 명확하지 않습니다. 에디션과 연결된 모든 패킷이 처리되었는지 확인해야 합니다.)
System은 자동 시스템 번호입니다. Cisco 구현에서는 게이트웨이가 둘 이상의 자율 시스템에 참여할 수 있습니다. 각 시스템은 자체 IGRP 프로토콜을 실행합니다. 개념적으로, 각 자율 시스템에는 완전히 별개의 라우팅 테이블이 있습니다. 하나의 자동 시스템에서 IGRP를 통해 도착하는 경로는 해당 AS에 대한 업데이트에서만 전송됩니다. 이 필드에서는 게이트웨이가 이 메시지를 처리하는 데 사용할 라우팅 테이블 집합을 선택할 수 있습니다. 게이트웨이가 구성되지 않은 AS에 대한 IGRP 메시지를 수신하면 무시됩니다. 실제로 Cisco의 구현 방식을 통해 한 AS에서 다른 AS로 정보를 "유출"할 수 있습니다. 그러나, 나는 그것을 의전의 일부가 아니라 관리 도구로 간주합니다.
Ninterior, nsystem 및 nexterior는 업데이트 메시지의 세 섹션 각각에 있는 항목 수를 나타냅니다. 이 섹션은 위에서 설명했습니다. 섹션 사이에는 다른 경계가 없습니다. 첫 번째 내부 엔트리는 내부, 다음 시스템 엔트리는 시스템, 최종 넥스터는 외부로 간주됩니다.
체크섬은 IP 체크섬으로, UDP 체크섬과 동일한 체크섬 알고리즘을 사용하여 계산됩니다. 체크섬은 IGRP 헤더 및 그 뒤에 오는 모든 라우팅 정보에서 계산됩니다. 체크섬을 계산할 때 체크섬 필드는 0으로 설정됩니다. 체크섬에는 IP 헤더가 포함되지 않으며 UDP 및 TCP와 같은 가상 헤더도 없습니다.
요청
IGRP 요청은 수신자에게 라우팅 테이블을 전송하도록 요청합니다. 요청 메시지에 헤더만 있습니다. version, opcode 및 system 필드만 사용됩니다. 다른 모든 필드는 0입니다. 수신자는 일반 IGRP 업데이트 메시지를 요청자에게 보내야 합니다.
업데이트
IGRP 업데이트 메시지에는 헤더가 포함되어 있고 그 뒤에 바로 라우팅 엔트리가 표시됩니다. 1500바이트 데이터그램(IP 헤더 포함)에 들어갈 만큼 많은 라우팅 엔트리가 포함되어 있습니다. 현재 구조 선언에서는 최대 104개의 엔트리를 허용합니다. 더 많은 항목이 필요한 경우 여러 업데이트 메시지가 전송됩니다. 업데이트 메시지는 단순히 항목별로 처리되기 때문에 여러 개의 독립된 메시지보다는 하나의 단편화된 메시지를 사용하는 것이 유리하지 않다.
다음은 공정순서 입력의 구조입니다.
uchar number[3]; /* 3 significant octets of IP address */
uchar delay[3]; /* delay, in tens of microseconds */
uchar bandwidth[3]; /* bandwidth, in units of 1 Kbit/sec */
uchar mtu[2]; /* MTU, in octets */
uchar reliability; /* percent packets successfully tx/rx */
uchar load; /* percent of channel occupied */
uchar hopcount; /* hop count */
uchar[2] 및 uchar[3]으로 정의된 필드는 일반 IP 네트워크 순서로 16비트 및 24비트 이진 정수입니다.
Number(번호)는 설명할 대상을 정의합니다. IP 주소입니다. 공간을 절약하기 위해 내부 섹션을 제외하고 IP 주소의 처음 3바이트만 주어집니다. 내부 섹션에서는 마지막 3바이트가 주어집니다. 시스템 및 외부 경로의 경우 서브넷을 사용할 수 없으므로 하위 바이트는 항상 0입니다. 내부 경로는 항상 알려진 네트워크의 서브넷이므로 해당 네트워크 번호의 첫 번째 바이트가 제공됩니다.
지연은 10마이크로초 단위입니다. 이것은 10마이크로초에서 168초의 범위를 제공하는데, 이는 충분한 것으로 보인다. 모두 지연되면 네트워크에 연결할 수 없음을 나타냅니다.
대역폭은 1.0e10의 비율로 확장된 초당 비트 수의 역대역폭입니다. 범위는 1200BPS 행에서 10Gbps까지입니다. (즉, 대역폭이 N Kbps인 경우 사용되는 숫자는 10000000/N입니다.)
MTU는 바이트 단위입니다.
신뢰도는 255의 분수로 제공됩니다. 즉, 255는 100%입니다.
부하는 255의 분수로 주어진다.
홉 수는 간단한 수입니다.
대역폭과 지연에 사용되는 약간 이상한 단위 때문에 몇 가지 예는 순서대로 보입니다. 여러 공통 미디어에 사용되는 기본값입니다.
Delay Bandwidth
--------------- -------------------
Satellite 200,000 (2 sec) 20 (500 Mbit)
Ethernet 100 (1 ms) 1,000
1.544 Mbit 2000 (20 ms) 6,476
64 Kbit 2000 156,250
56 Kbit 2000 178,571
10 Kbit 2000 1,000,000
1 Kbit 2000 10,000,000
미터법 계산
다음은 Cisco 버전 8.0(3)에서 복합 메트릭을 실제로 계산하는 방법에 대한 설명입니다.
metric = [K1*bandwidth + (K2*bandwidth)/(256 - load) + K3*delay] *
[K5/(reliability + K4)]
If K5 == 0, the reliability term is not included.
The default version of IGRP has K1 == K3 == 1, K2 == K4 == K5 == 0
관련 정보
개정 이력
| 개정 | 게시 날짜 | 의견 |
|---|---|---|
1.0 |
04-Sep-2002
|
최초 릴리스 |
 피드백
피드백