StarOS VNF를 위한 CEPH 중단 영향 분석
다운로드 옵션
편견 없는 언어
본 제품에 대한 문서 세트는 편견 없는 언어를 사용하기 위해 노력합니다. 본 설명서 세트의 목적상, 편견 없는 언어는 나이, 장애, 성별, 인종 정체성, 민족 정체성, 성적 지향성, 사회 경제적 지위 및 교차성에 기초한 차별을 의미하지 않는 언어로 정의됩니다. 제품 소프트웨어의 사용자 인터페이스에서 하드코딩된 언어, RFP 설명서에 기초한 언어 또는 참조된 서드파티 제품에서 사용하는 언어로 인해 설명서에 예외가 있을 수 있습니다. 시스코에서 어떤 방식으로 포용적인 언어를 사용하고 있는지 자세히 알아보세요.
이 번역에 관하여
Cisco는 전 세계 사용자에게 다양한 언어로 지원 콘텐츠를 제공하기 위해 기계 번역 기술과 수작업 번역을 병행하여 이 문서를 번역했습니다. 아무리 품질이 높은 기계 번역이라도 전문 번역가의 번역 결과물만큼 정확하지는 않습니다. Cisco Systems, Inc.는 이 같은 번역에 대해 어떠한 책임도 지지 않으며 항상 원본 영문 문서(링크 제공됨)를 참조할 것을 권장합니다.
목차
소개
이 문서에서는 Cisco VIM(Virtualized Infrastructure Manager)에서 실행되는 StarOS VNF가 Ceph 스토리지 서비스 손상 시 어떤 영향을 받는지, 그리고 이러한 영향을 줄이기 위해 무엇을 할 수 있는지 설명합니다.Cisco VIM이 인프라로 사용되지만 모든 Openstack 환경에 동일한 이론을 적용할 수 있다는 가정 하에 설명됩니다.
전제 조건
요구 사항
다음 주제에 대한 지식을 보유하고 있으면 유용합니다.
- Cisco StarOS
- Cisco VIM
- Openstack
- 체프
사용된 구성 요소
이 문서의 정보는 다음 소프트웨어 및 하드웨어 버전을 기반으로 합니다.
- StarOS:21.16.c9
- Cisco VIM:3.2.2(Openstack Queens)
이 문서의 정보는 특정 랩 환경의 디바이스를 토대로 작성되었습니다.이 문서에 사용된 모든 디바이스는 초기화된(기본) 컨피그레이션으로 시작되었습니다.네트워크가 작동 중인 경우 모든 명령의 잠재적인 영향을 이해해야 합니다.
약어
| Cisco VIM | Cisco Virtualized Infrastructure Manager |
| VNF | 가상 네트워크 기능 |
| OSD 확인 | CEPH 객체 스토리지 데몬 |
| 스타오스 | Cisco Mobile Packet Core 솔루션의 운영 체제 |
Cisco VIM에서 성공
이 이미지는 Cisco VIM 관리자 가이드에서 가져온 것입니다.Cisco VIM은 Ceph를 스토리지 백엔드로 사용합니다.
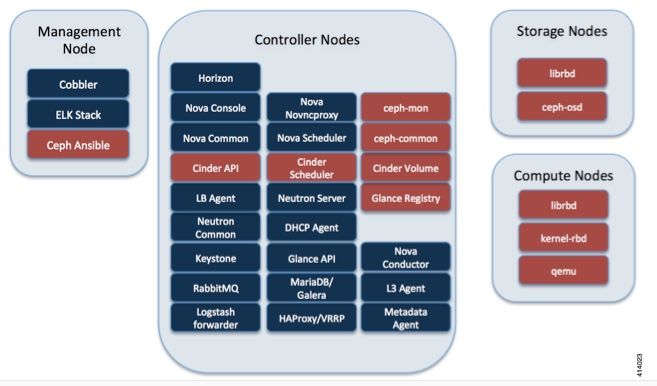
CEPH는 블록 및 개체 스토리지를 모두 지원하므로 VM에 연결할 수 있는 VM 이미지 및 볼륨을 저장하는 데 사용됩니다.스토리지 백엔드에 의존하는 여러 OpenStack 서비스는 다음과 같습니다.
- Glance(OpenStack 이미지 서비스) — Ceph를 사용하여 이미지를 저장합니다.
- Cinder(OpenStack 스토리지 서비스) — Ceph를 사용하여 VM에 연결할 수 있는 볼륨을 생성합니다.
- Nova(OpenStack 컴퓨팅 서비스) — Ceph를 사용하여 Cinder에서 생성한 볼륨에 연결합니다.
대부분의 경우 여기의 예와 같이 StarOS VNF용 /flash 및 /hd-raid에 볼륨이 생성됩니다.
openstack volume create --image `glance image-list | grep up-image | awk '{print $2}'` --size 16 --type LUKS up1-flash-boot
openstack volume create --size 20 --type LUKS up1-hd-raid
CEPH에서 모니터링 메커니즘의 기초
다음은 모니터링에 대한 Ceph 문서의 설명입니다.
각 Ceph OSD 데몬은 6초마다 간격으로 다른 Ceph OSD 데몬의 하트비트를 임의 간격으로 확인합니다.인접한 Ceph OSD 데몬이 20초 유예 기간 내에 하트비트를 표시하지 않으면 Ceph OSD 데몬은 인접한 Ceph OSD 데몬을 다운된 것으로 간주하여 Ceph 클러스터 맵을 업데이트하는 Ceph Monitor에 다시 보고할 수 있습니다.기본적으로 서로 다른 호스트의 두 CEPH OSD 데몬은 Ceph Monitor가 보고된 OSD 데몬이 다운되었음을 승인하기 전에 다른 CEPH OSD 데몬이 다운되었음을 Ceph Monitor에 보고해야 합니다.
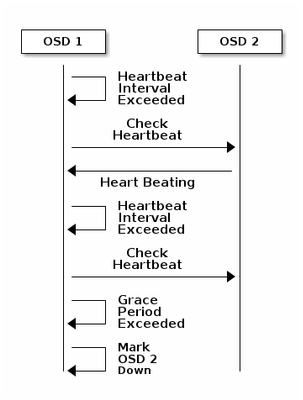
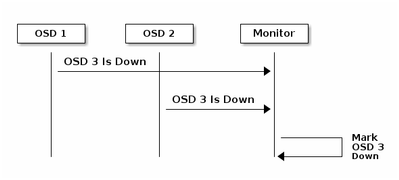
따라서 일반적으로 OSD가 다운되고 Ceph 클러스터 맵이 업데이트되는 데 약 20초가 소요되며, 이 VNF가 새 OSD를 사용할 수 있어야 합니다.이 시간 동안 I/O가 차단됩니다.
StarOS VNF에 대한 I/O 차단 영향
디스크 I/O가 120초 이상 차단되면 StarOS VNF가 재부팅됩니다.디스크 I/O 및 StarOS와 관련된 xfssyncd/md0 및 xfs_db 프로세스가 120초 이상 이 프로세스에서 중단된 것을 탐지할 때 의도적으로 재부팅됩니다.
StarOS 디버그 콘솔 로그:
[ 1080.859817] INFO: task xfssyncd/md0:25787 blocked for more than 120 seconds.
[ 1080.862844] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
[ 1080.866184] xfssyncd/md0 D ffff880c036a8290 0 25787 2 0x00000000
[ 1080.869321] ffff880aacf87d30 0000000000000046 0000000100000a9a ffff880a00000000
[ 1080.872665] ffff880aacf87fd8 ffff880c036a8000 ffff880aacf87fd8 ffff880aacf87fd8
[ 1080.876100] ffff880c036a8298 ffff880aacf87fd8 ffff880c0f2f3980 ffff880c036a8000
[ 1080.879443] Call Trace:
[ 1080.880526] [<ffffffff8123d62e>] ? xfs_trans_commit_iclog+0x28e/0x380
[ 1080.883288] [<ffffffff810297c9>] ? default_spin_lock_flags+0x9/0x10
[ 1080.886050] [<ffffffff8157fd7d>] ? _raw_spin_lock_irqsave+0x4d/0x60
[ 1080.888748] [<ffffffff812301b3>] _xfs_log_force_lsn+0x173/0x2f0
[ 1080.891375] [<ffffffff8104bae0>] ? default_wake_function+0x0/0x20
[ 1080.894010] [<ffffffff8123dc15>] _xfs_trans_commit+0x2a5/0x2b0
[ 1080.896588] [<ffffffff8121ff64>] xfs_fs_log_dummy+0x64/0x90
[ 1080.899079] [<ffffffff81253cf1>] xfs_sync_worker+0x81/0x90
[ 1080.901446] [<ffffffff81252871>] xfssyncd+0x141/0x1e0
[ 1080.903670] [<ffffffff81252730>] ? xfssyncd+0x0/0x1e0
[ 1080.905871] [<ffffffff81071d5c>] kthread+0x8c/0xa0
[ 1080.908815] [<ffffffff81003364>] kernel_thread_helper+0x4/0x10
[ 1080.911343] [<ffffffff81580805>] ? restore_args+0x0/0x30
[ 1080.913668] [<ffffffff81071cd0>] ? kthread+0x0/0xa0
[ 1080.915808] [<ffffffff81003360>] ? kernel_thread_helper+0x0/0x10
[ 1080.918411] **** xfssyncd/md0 stuck, resetting card
그러나 120초 타이머로 제한되지 않습니다. 디스크 입출력이 잠시 차단되면 120초 미만이라도 다양한 이유로 VNF가 재부팅될 수 있습니다.이 출력은 디스크 I/O 문제, 때때로 연속적인 StarOS 작업 충돌 등으로 인해 재부팅되는 예를 보여줍니다.활성 디스크 I/O와 스토리지 문제의 시기에 따라 달라집니다.
[ 2153.370758] Hangcheck: hangcheck value past margin!
[ 2153.396850] ata1.01: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x6 frozen
[ 2153.396853] ata1.01: failed command: WRITE DMA EXT
--- skip ---
SYSLINUX 3.53 0x5d037742 EBIOS Copyright (C) 1994-2007 H. Peter Anvin
기본적으로 장시간의 차단 I/O는 StarOS VNF의 중요한 문제로 간주될 수 있으며 최대한 최소화해야 합니다.
장시간의 I/O 시나리오
여러 고객 구축 및 랩 테스트의 연구 결과에 따르면 Ceph에서 I/O를 장기간 차단할 수 있는 두 가지 주요 시나리오가 있습니다.
러기 타이머 메커니즘
OSD 간에 OSD의 작동이 중지되었음을 감지하는 하트비트 메커니즘이 있습니다.osd_heartbeat_grace 값(기본적으로 20초)에 따라 OSD는 실패한 것으로 탐지됩니다.
또한 OSD 상태에 변동 또는 플랩 상태가 있을 경우 유예 타이머가 자동으로 조정됩니다(더 길어질 수 있음). 이로 인해 osd_heartbeat_grace 값이 커질 수 있습니다.
정상적인 상황에서는 하트비트 그레이스가 20초입니다.
2019-01-09 16:58:01.715155 mon.ceph-XXXXX [INF] osd.2 failed (root=default,host=XXXXX) (2 reporters from different host after 20.000047 >= grace 20.000000)
그러나 스토리지 노드의 여러 네트워크 플랩이 발생하면 더 큰 가치가 됩니다.
2019-01-10 16:44:15.140433 mon.ceph-XXXXX [INF] osd.2 failed (root=default,host=XXXXX) (2 reporters from different host after 256.588099 >= grace 255.682576)
따라서 위의 예에서는 OSD가 다운된 것을 탐지하는 데 256초가 소요됩니다.
RAID 카드 하드웨어 장애
CEPH가 적시에 RAID 카드 하드웨어 장애를 탐지하지 못할 수 있습니다.RAID 카드 장애가 발생하면 OSD 중단 상황이 발생합니다.이 경우, 몇 분 후에 OSD 다운이 감지되어 StarOS VNF가 재부팅됩니다.
RAID 카드가 정지되면 일부 CPU 코어는 100%의 상태를 유지합니다.
%Cpu20 : 2.6 us, 7.9 sy, 0.0 ni, 0.0 id, 89.4 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu21 : 0.0 us, 0.3 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu22 : 31.3 us, 5.1 sy, 0.0 ni, 63.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu23 : 0.0 us, 0.0 sy, 0.0 ni, 28.1 id, 71.9 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu24 : 0.0 us, 0.0 sy, 0.0 ni, 0.0 id,100.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu25 : 0.0 us, 0.0 sy, 0.0 ni, 0.0 id,100.0 wa, 0.0 hi, 0.0 si, 0.0 st
또한 모든 CPU 코어를 점진적으로 소모하며 OSD도 시간이 약간 부족한 상태에서 점차 축소되고 있습니다.
2019-01-01 17:08:05.267629 mon.ceph-XXXXX [INF] Marking osd.2 out (has been down for 602 seconds)
2019-01-01 17:09:25.296955 mon.ceph-XXXXX [INF] Marking osd.4 out (has been down for 603 seconds)
2019-01-01 17:11:10.351131 mon.ceph-XXXXX [INF] Marking osd.7 out (has been down for 604 seconds)
2019-01-01 17:16:40.426927 mon.ceph-XXXXX [INF] Marking osd.10 out (has been down for 603 seconds)
동시에 ceph.log에서 느린 요청이 탐지됩니다.
2019-01-01 16:57:26.743372 mon.XXXXX [WRN] Health check failed: 1 slow requests are blocked > 32 sec. Implicated osds 2 (REQUEST_SLOW)
2019-01-01 16:57:35.129229 mon.XXXXX [WRN] Health check update: 3 slow requests are blocked > 32 sec. Implicated osds 2,7,10 (REQUEST_SLOW)
2019-01-01 16:57:38.055976 osd.7 osd.7 [WRN] 1 slow requests, 1 included below; oldest blocked for > 30.216236 secs
2019-01-01 16:57:39.048591 osd.2 osd.2 [WRN] 1 slow requests, 1 included below; oldest blocked for > 30.635122 secs
-----skip-----
2019-01-01 17:06:22.124978 osd.7 osd.7 [WRN] 78 slow requests, 1 included below; oldest blocked for > 554.285311 secs
2019-01-01 17:06:25.114453 osd.4 osd.4 [WRN] 19 slow requests, 1 included below; oldest blocked for > 546.221508 secs
2019-01-01 17:06:26.125459 osd.7 osd.7 [WRN] 78 slow requests, 1 included below; oldest blocked for > 558.285789 secs
2019-01-01 17:06:27.125582 osd.7 osd.7 [WRN] 78 slow requests, 1 included below; oldest blocked for > 559.285915 secs
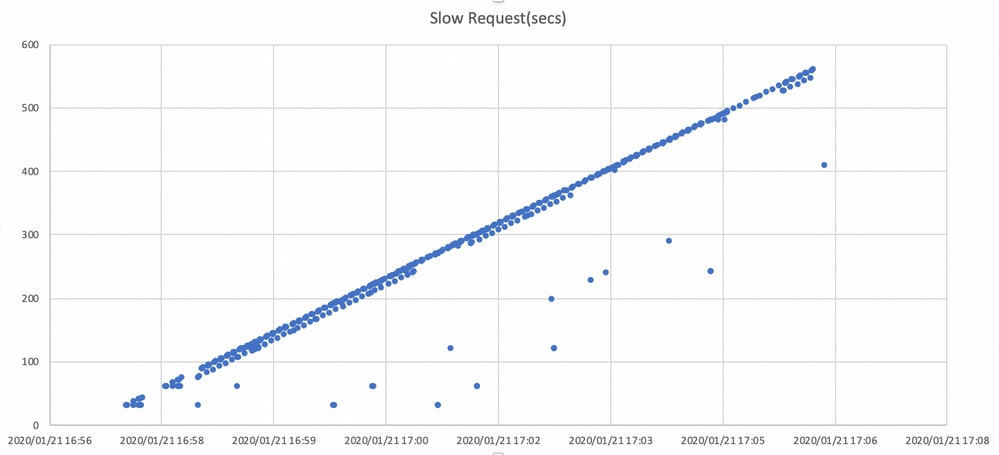
이 그래프에서는 타임라인으로 I/O 요청을 차단하는 기간을 보여줍니다.그래프는 ceph.log에서 느린 요청 로그를 플로팅하여 생성됩니다.시간이 지남에 따라 차단 시간이 길어지고 있음을 보여 줍니다.
영향을 완화하는 방법
CEPH 스토리지에서 로컬 디스크로 이동
영향을 완화하는 가장 간단한 방법은 Ceph 스토리지에서 로컬 디스크로 이동하는 것입니다.StarOS는 2개의 디스크 /flash 및 /hd-raid를 사용하므로 /flash만 로컬 디스크로 이동할 수 있으므로 StarOS VNF가 Ceph 문제에 더욱 강력해집니다.Ceph와 같은 공유 스토리지를 사용하는 부정적인 측면은 문제가 발생할 때 이 스토리지를 사용하는 모든 VNF가 동시에 영향을 받습니다.로컬 디스크를 사용하면 영향을 받는 노드에서만 실행 중인 VNF로 스토리지 문제의 영향을 최소화할 수 있습니다.이전 섹션에서 설명한 시나리오는 로컬 디스크에는 적용되지 않도록 Ceph에만 적용됩니다.그러나 로컬 디스크의 대칭 이동은 StarOS 이미지, 컨피그레이션, 코어 파일, 청구 레코드와 같은 디스크 콘텐츠를 VM을 재구축할 때 보존할 수 없다는 것입니다.VNF 자동 복구 메커니즘에도 영향을 줄 수 있습니다.
컨피그레이션 조정
StarOS VNF 관점에서 앞서 언급한 차단 I/O 시간을 최소화하기 위해 다음과 같은 새로운 Ceph 매개변수를 사용하는 것이 좋습니다.
<기본 설정>
"mon_osd_adjust_heartbeat_grace": "true",
"osd_client_watch_timeout": "30",
"osd_max_markdown_count": "5",
"osd_heartbeat_grace": "20",
<새 설정>
"mon_osd_adjust_heartbeat_grace": "false",
"osd_client_watch_timeout": "10",
"osd_max_markdown_count": "1",
"osd_heartbeat_grace": "10",
구성 요소:
- 러기 타이머 메커니즘이 비활성화되어 자동 조정 기능이 없습니다.
- 하트비트 유예 시간이 단축됩니다.
- OSD는 즉시 다운(지난 600초 동안 기본적으로 5회)
새 매개 변수는 Lab에서 테스트되며, OSD의 작동 중지 탐지 시간이 약 10초 미만으로 감소하며 원래 Ceph의 기본 컨피그레이션으로 약 30초였습니다.
RAID 카드 하드웨어 문제 모니터링
RAID 카드 하드웨어 시나리오의 경우 I/O가 차단되는 동안 OSD가 간헐적으로 작동하는 상황이 발생하므로 문제의 특성상 적시에 탐지하기 어려울 수 있습니다.이에 대한 단일 해결 방법은 없지만 서버 하드웨어 로그에서 RAID 카드 장애를 모니터링하거나 일부 스크립트에서 ceph.log에 느린 요청 로그를 모니터링하고 영향을 받는 OSD를 사전 대응적으로 다운시키는 등의 작업을 수행하는 것이 좋습니다.
CEPH_OSD_RESEVED_PCORES 튜닝
이는 언급된 시나리오와 관련이 없지만 I/O 작업이 많아 Ceph 성능에 문제가 있는 경우 CEPH_OSD_RESEVED_PCORES 값을 늘리면 Ceph I/O 성능이 향상될 수 있습니다.기본적으로 Cisco VIM의 CEPH_OSD_RESEVED_PCORES는 2로 구성되며 증가할 수 있습니다.
Cisco 엔지니어가 작성
- Tomonobu OkadaCisco TAC 엔지니어
- Satoshi KinoshitaCisco TAC 엔지니어
 피드백
피드백지원 문의
- 지원 케이스 접수

- (시스코 서비스 계약 필요)