Procedura di ripristino in caso di errore del cluster Ultra-M AutoVNF - vEPC
Opzioni per il download
Linguaggio senza pregiudizi
La documentazione per questo prodotto è stata redatta cercando di utilizzare un linguaggio senza pregiudizi. Ai fini di questa documentazione, per linguaggio senza di pregiudizi si intende un linguaggio che non implica discriminazioni basate su età, disabilità, genere, identità razziale, identità etnica, orientamento sessuale, status socioeconomico e intersezionalità. Le eventuali eccezioni possono dipendere dal linguaggio codificato nelle interfacce utente del software del prodotto, dal linguaggio utilizzato nella documentazione RFP o dal linguaggio utilizzato in prodotti di terze parti a cui si fa riferimento. Scopri di più sul modo in cui Cisco utilizza il linguaggio inclusivo.
Informazioni su questa traduzione
Cisco ha tradotto questo documento utilizzando una combinazione di tecnologie automatiche e umane per offrire ai nostri utenti in tutto il mondo contenuti di supporto nella propria lingua. Si noti che anche la migliore traduzione automatica non sarà mai accurata come quella fornita da un traduttore professionista. Cisco Systems, Inc. non si assume alcuna responsabilità per l’accuratezza di queste traduzioni e consiglia di consultare sempre il documento originale in inglese (disponibile al link fornito).
Sommario
Introduzione
In questo documento vengono descritti i passaggi necessari per ripristinare il guasto di Ultra Automation Services (UAS) o del cluster AutoVNF in una configurazione Ultra-M che ospita le funzioni di rete virtuale (VNF) StarOS.
Premesse
Ultra-M è una soluzione mobile packet core preconfezionata e convalidata, progettata per semplificare l'installazione delle VNF.
La soluzione Ultra-M è costituita dai tipi di macchine virtuali (VM) citati:
- Auto-IT
- Distribuzione automatica
- UAS o AutoVNF
- Gestore elementi
- Elastic Services Controller (ESC)
- Funzione di controllo (CF)
- Funzione Session (SF)
L'architettura di alto livello di Ultra-M e i componenti coinvolti sono illustrati in questa immagine:
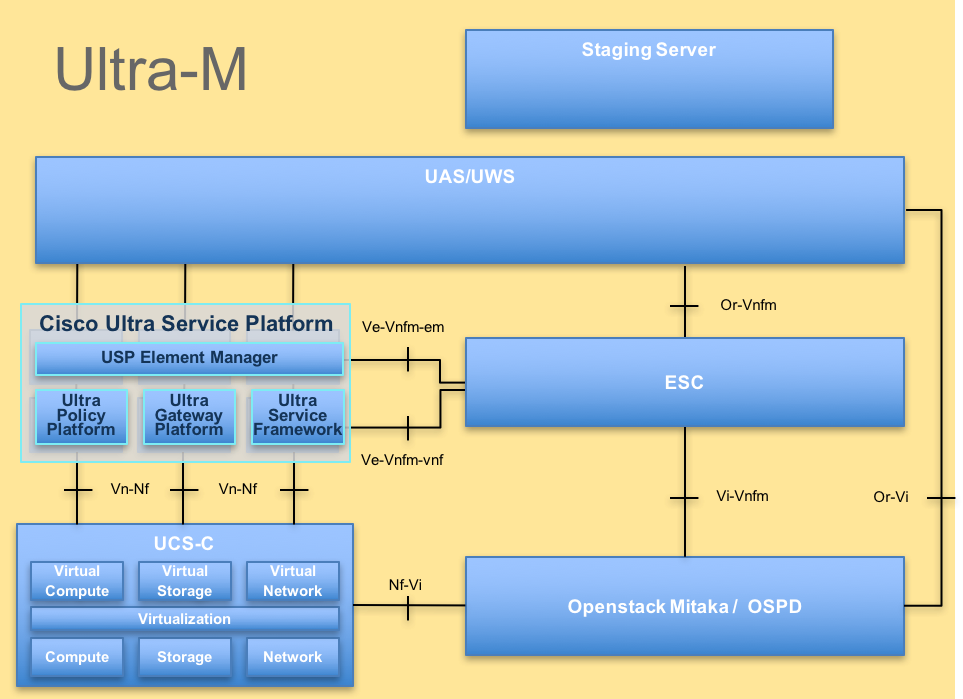 Architettura UltraM
Architettura UltraM
Questo documento è destinato al personale Cisco che ha familiarità con la piattaforma Cisco Ultra-M.
Nota: Per definire le procedure descritte in questo documento, viene presa in considerazione la release di Ultra M 5.1.x.
Abbreviazioni
| VNF | Funzione di rete virtuale |
| CF | Funzione di controllo |
| SF | Funzione di servizio |
| ESC | Elastic Service Controller |
| MOP | Metodo di procedura |
| OSD | Dischi Object Storage |
| HDD | Unità hard disk |
| SSD | Unità a stato solido |
| VIM | Virtual Infrastructure Manager |
| VM | Macchina virtuale |
| EM | Gestione elementi |
| UAS | Ultra Automation Services |
| UUID | Identificatore univoco universale |
Flusso di lavoro del piano di mobilità
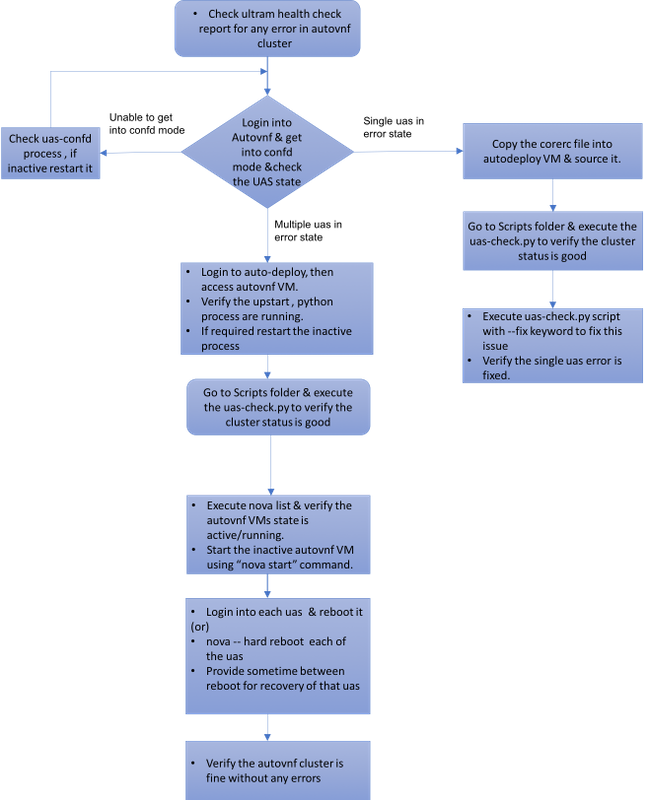
Caso 1. Ripristino di un singolo errore del cluster UAS
Controllo dello stato
1. Ultra-M Manager esegue il controllo dello stato del nodo Ultra-M. Passare alla directory /var/log/cisco/ultram-health/ grep per il report UAS.
-
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | XXX | AutoVNF Cluster FAILED : Node: 172.16.180.12, Status: error, Role: NA
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
2. Lo stato previsto del cluster UAS sarà quello illustrato, in cui tutte e tre le UAS sono attive.
[stack@pod1-ospd ~]# ssh ubuntu@10.1.1.1
password:
ubuntu@autovnf1-uas:~$ ncs_cli -u admin -C
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.12 alive NA
Impossibile connettersi al server config quando si tenta di connettersi a UAS
1. In alcuni casi, non sarà possibile connettersi al server confd.
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ confd_cli -u admin -C
Failed to connect to server
2. Controllare lo stato del processo di configurazione automatica.
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ sudo initctl status uas-confd
uas-confd stop/waiting
3. Se il server config non viene eseguito, riavviare il servizio.
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ sudo initctl start uas-confd
uas-confd start/running, process 7970
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 172.16.180.9 using ssh on autovnf1-uas-0
Ripristina UAS da stato di errore
1. In caso di errore di un AutoVNF tra il cluster, il cluster UAS visualizza uno degli UAS in stato di errore.
[stack@pod1-ospd ~]# ssh ubuntu@10.1.1.1
password:
ubuntu@autovnf1-uas:~$ ncs_cli -u admin -C
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.12 alive error
2. Copiare il file corerc (rc file del VNF) da /home/stack nel server OSPD per la distribuzione automatica e fornirlo come origine.
3. Controllare lo stato di UAS/AutoVNF utilizzando lo script uas-check.py . autovnf1 è il nome di AutoVNF.
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts/uas-check.py auto-vnf autovnf1
2017-11-17 14:52:20,186 - INFO: Check of AutoVNF cluster started
2017-11-17 14:52:22,172 - INFO: Found 2 AutoVNF instance(s), 3 expected
2017-11-17 14:52:22,172 - INFO: Instance 'autovnf1-uas-2' is missing
2017-11-17 14:52:22,172 - INFO: Check completed, AutoVNF cluster has recoverable errors
4. Recuperare l'UAS con l'uso dello script uas-check.py e aggiungere la parola chiave —fix.
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts/uas-check.py auto-vnf autovnf1 --fix
2017-11-17 14:52:27,493 - INFO: Check of AutoVNF cluster started
2017-11-17 14:52:29,215 - INFO: Found 2 AutoVNF instance(s), 3 expected
2017-11-17 14:52:29,215 - INFO: Instance 'autovnf1-uas-2' is missing
2017-11-17 14:52:29,215 - INFO: Check completed, AutoVNF cluster has recoverable errors
2017-11-17 14:52:29,386 - INFO: Creating instance 'autovnf1-uas-2' and attaching volume 'autovnf1-uas-vol-2'
2017-11-17 14:52:47,600 - INFO: Created instance 'autovnf1-uas-2'
5. L'UAS appena creato è attivo e fa parte del cluster.
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.13 alive NA
Caso 2. Tutti e tre gli UAS (AutoVNF) sono in stato di errore
1. Ultra-M Manager esegue il controllo dello stato del nodo Ultra-M.
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | XXX | AutoVNF Cluster FAILED : Node: 172.16.180.12, Status: error, Role: NA,Node: 172.16.180.9, Status: error, Role: NA,Node: 172.16.180.10, Status: error, Role: NA
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
2. Come osservato nell'output, Ultra-M Manager segnala un errore per AutoVNF e mostra che tutte e tre le UAS del cluster sono in stato di errore.
Controllare lo stato di integrità di UAS con lo script uas-check.py
1. Accedere alla distribuzione automatica e verificare se è possibile accedere a AutoVNF UAS e ottenere lo stato.
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts$ ./uas-check.py auto-vnf autovnf1 --os-tenant-name core
2017-12-05 11:41:09,834 - INFO: Check of AutoVNF cluster started
2017-12-05 11:41:11,342 - INFO: Found 3 ACTIVE AutoVNF instances
2017-12-05 11:41:11,343 - INFO: Check completed, AutoVNF cluster is fine
2. Da Auto-Deploy, Secure Shell (SSH) al nodo AutoVNF ed entrare in modalità confd. Controllare lo stato con show uas.
ubuntu@auto-deploy-iso-590-uas-0:~$ ssh ubuntu@172.16.180.9
password:
autovnf1-uas-1#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
----------------------------
172.16.180.9 error NA
172.16.180.10 error NA
172.16.180.12 error NA
3. Si consiglia di controllare lo stato in tutti e tre i nodi UAS.
Controllare lo stato delle VM a livello di OpenStack
Controllare lo stato delle VM AutoVNF nell'elenco delle macchine virtuali. Se necessario, eseguire il comando nova start per avviare la VM arrestata.
[stack@pod1-ospd ultram-health]$ nova list | grep autovnf
| 83870eed-b4e9-47b3-976d-cc3eddecf866 | autovnf1-uas-0 | ACTIVE | - | Running | orchestr=172.16.180.12; mgmt=172.16.181.6
| 201d9ce5-538c-42f7-a46c-fc8cdef1eabf | autovnf1-uas-1 | ACTIVE | - | Running | orchestr=172.16.180.10; mgmt=172.16.181.5
| 6c6d25cd-21b6-42b9-87ff-286220faa2ff | autovnf1-uas-2 | ACTIVE | - | Running | orchestr=172.16.180.9; mgmt=172.16.181.13
Controlla la vista Zookeeper
1. Controllare lo stato del responsabile dello zoo per verificare la modalità di guida.
ubuntu@autovnf1-uas-0:/var/log/upstart$ /opt/cisco/usp/packages/zookeeper/current/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/cisco/usp/packages/zookeeper/current/bin/../conf/zoo.cfg
Mode: leader
2. Il responsabile della zookeeper normalmente dovrebbe essere attivo.
Risoluzione dei problemi di AutoVNF - Processi e attività
1. Identificare il motivo dello stato di errore dei nodi. Per eseguire AutoVNF, è necessario che sia attivo e in esecuzione un insieme di processi, come illustrato di seguito:
AutoVNF
uws-ae
uas-confd
cluster_manager
uas_manager
ubuntu@autovnf1-uas-0:~$ sudo initctl list | grep uas
uas-confd stop/waiting ====> this is not good, the uas-confd process is not running
uas_manager start/running, process 2143
root@autovnf1-uas-1:/home/ubuntu# sudo initctl list
....
uas-confd start/running, process 1780
....
autovnf start/running, process 1908
....
....
uws-ae start/running, process 1909
....
....
cluster_manager start/running, process 1827
....
.....
uas_manager start/running, process 1697
......
......
2. Verificare che i seguenti processi python siano in esecuzione:
uas_manager.py
cluster_manager.py
usp_autovnf.py
root@autovnf1-uas-1:/home/ubuntu# ps -aef | grep pyth
root 1819 1697 0 Jun13 ? 00:00:50 python /opt/cisco/usp/uas/manager/uas_manager.py
root 1858 1827 0 Jun13 ? 00:09:21 python /opt/cisco/usp/uas/manager/cluster_manager.py
root 1908 1 0 Jun13 ? 00:01:00 python /opt/cisco/usp/uas/autovnf/usp_autovnf.py
root 25662 24750 0 13:16 pts/7 00:00:00 grep --color=auto pyth
3. Se uno dei processi previsti non è in stato avvio/esecuzione, riavviare il processo e controllare lo stato. Se viene ancora visualizzato in stato Errore, seguire la procedura descritta nella sezione successiva per risolvere il problema.
Correggi per più UAS in stato di errore
1. nova —Riavvio hardware <nome della VM> dall'OSPD, attendere il ripristino della VM prima di procedere con il successivo UAS. Eseguirlo su tutte le VM UAS.
o
2. Accedere a ciascuna delle UAS e usare il riavvio sudo. Attendere il ripristino e procedere con le altre VM UAS.
Per i registri delle transazioni, controllare:
/var/log/upstart/autovnf.log
show logs xxx | display xml
Il problema verrà risolto e UAS verrà ripristinato dallo stato di errore.
1. Verificare lo stesso utilizzando la relazione ultram_health_check.
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | :-) |
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
Contributo dei tecnici Cisco
- Partheeban RajagopalCisco Advanced Services
- Padmaraj RamanoudjamCisco Advanced Services
 Feedback
Feedback