Introduzione
In questo documento viene descritto come risolvere i problemi relativi all'utilizzo elevato dello spazio su disco per il file system /dev/vda3 in RCM.
Prerequisiti
Requisiti
Cisco raccomanda la conoscenza di:
- Architettura e amministrazione del sistema di controllo StarOS e User Plane Separation (CUPS).
- Comandi Linux/Unix di base per il monitoraggio dei file system e dell'utilizzo dei dischi.
Componenti usati
Il documento può essere consultato per tutte le versioni software o hardware.
Le informazioni discusse in questo documento fanno riferimento a dispositivi usati in uno specifico ambiente di emulazione. Su tutti i dispositivi menzionati nel documento la configurazione è stata ripristinata ai valori predefiniti. Se la rete è operativa, valutare attentamente eventuali conseguenze derivanti dall'uso dei comandi.
Panoramica
Nelle implementazioni Cisco Ultra Packet Core con Control e User Plane Separation (CUPS), Redundancy Control Manager (RCM) svolge un ruolo critico nelle operazioni e nella gestione dei control plane. L'utilizzo stabile del file system sui nodi RCM è importante per garantire il corretto funzionamento della registrazione, del monitoraggio e della gestione delle sessioni degli abbonati.
L'utilizzo elevato dello spazio su disco nel file system radice (/dev/vda3) può causare instabilità del sistema, errori nelle scritture del log o addirittura riavvii del servizio se non viene selezionata l'opzione. In questo documento vengono descritte l'analisi, le procedure di risoluzione dei problemi e le misure preventive necessarie per risolvere il problema dell'utilizzo intensivo del disco nei nodi RCM.
Analisi e osservazione
Durante il monitoraggio, è stato rilevato che il nodo RCM ha raggiunto il 72% di utilizzo sul file system radice.
Snapshot utilizzo disco
df -kh
Filesystem Size Used Avail Use% Mounted on
tmpfs 6.3G 9.7M 6.3G 1% /run
/dev/vda3 39G 27G 11G 72% /
tmpfs 32G 4.0K 32G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/vda2 488M 48K 452M 1% /var/tmp
/dev/vda1 488M 76K 452M 1% /tmp
In seguito a ulteriori indagini, è stato osservato che i registri sotto /var/log/journal/ erano aumentati in modo significativo. I log generati durante il solo mese di luglio contavano ~3 GB di spazio.
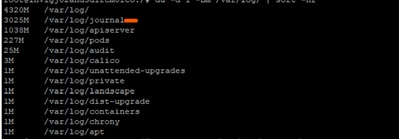
Risoluzione dei problemi del processo
Per tenere sotto controllo l'utilizzo del disco, sono stati eseguiti i passi di implementazione delle modifiche richiesti:
Passaggio 1: Pulizia dei log obsoleti mediante journalctl Vacuum
Conservare solo le ultime 2 settimane dei registri:
sudo journalctl --vacuum-time=2weeks
In alternativa, limitare le dimensioni del giornale (ad esempio, mantenere solo 600 MB):
sudo journalctl --vacuum-size=600M
Passaggio 2: Configurare la conservazione del journal per la prevenzione futura
Modifica configurazione journal:
vi /etc/systemd/journald.conf
Aggiungi/modifica parametro:
MaxRetentionSec=2week
Applica configurazione:
sudo systemctl restart systemd-journald
Passaggio 3 facoltativo: Risolvi errore di riavvio
Durante il riavvio del servizio system-journal nel passaggio 2, viene visualizzato un messaggio di errore:
Error : Failed to allocate directory watch: Too many open files
-
systemd-journald utilizza inotify per controllare le directory dei log per eventuali modifiche.
-
Ogni orologio o monitor imposta un conteggio per determinati limiti del kernel.
Gli attuali limiti definiti nell'RCM problematico sono i seguenti:
cat /proc/sys/fs/inotify/max_user_watches
501120
cat /proc/sys/fs/inotify/max_user_instances
128
ulimit -n
1024
Dall'output raccolto:
- Numero massimo di orologi di identificazione: 501120
- Numero massimo di istanze inotify: 128
Limite descrittore file aperto per journal: 1024
Uno o tutti i valori di output limite potrebbero aver raggiunto la soglia di errore. Abbiamo raccolto il valore corrente utilizzato e lo abbiamo confrontato con il limite di output raccolto:
sudo lsof -p $(pidof systemd-journald) | wc -l
65
echo "Root inotify instances: $(sudo find /proc/*/fd -user root -type l -lname 'anon_inode:inotify' 2>/dev/null | wc -l) / $(cat /proc/sys/fs/inotify/max_user_instances)"
Root inotify instances: 126 / 128
Sembra che la radice stia già utilizzando 126 delle 128 istanze consentite per l'inotify. In questo modo, journald non dispone quasi di spazio per creare una nuova istanza inotify al riavvio.
Per risolvere l'errore: è possibile aumentare il valore max_user_instance e quindi riavviare il servizio:
# Temporarily increase the limit (until next reboot)
echo 256 > /proc/sys/fs/inotify/max_user_instances
sudo systemctl restart systemd-journald
# Temporarily increase the limit (until next reboot)
echo 256 > /proc/sys/fs/inotify/max_user_instances
sudo systemctl restart systemd-journald
Verifica successiva alla modifica
Dopo l'applicazione delle modifiche, l'utilizzo del disco è sceso al 61%, ripristinando il normale stato operativo del nodo.
df -kh
Filesystem Size Used Avail Use% Mounted on
tmpfs 6.3G 9.7M 6.3G 1% /run
/dev/vda3 39G 23G 15G 61% /
tmpfs 32G 4.0K 32G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/vda2 488M 48K 452M 1% /var/tmp
/dev/vda1 488M 76K 452M 1% /tmp
Suggerimento
-
Implementare la stessa configurazione in tutti i nodi RCM della distribuzione per mantenere l'utilizzo del disco entro limiti di sicurezza.
-
Posizionare sempre RCM di destinazione in modalità standby prima di eseguire le modifiche per evitare l'impatto sul traffico in tempo reale.
-
Monitoraggio periodico dell'utilizzo di /dev/vda3 e della crescita dei log di journal nell'ambito dei controlli proattivi dello stato del sistema.
 Feedback
Feedback