Risolvere i problemi relativi alla replica tra rack con codice di errore "424-Geo-replication Checksum Mismatch"
Opzioni per il download
Linguaggio senza pregiudizi
La documentazione per questo prodotto è stata redatta cercando di utilizzare un linguaggio senza pregiudizi. Ai fini di questa documentazione, per linguaggio senza di pregiudizi si intende un linguaggio che non implica discriminazioni basate su età, disabilità, genere, identità razziale, identità etnica, orientamento sessuale, status socioeconomico e intersezionalità. Le eventuali eccezioni possono dipendere dal linguaggio codificato nelle interfacce utente del software del prodotto, dal linguaggio utilizzato nella documentazione RFP o dal linguaggio utilizzato in prodotti di terze parti a cui si fa riferimento. Scopri di più sul modo in cui Cisco utilizza il linguaggio inclusivo.
Informazioni su questa traduzione
Cisco ha tradotto questo documento utilizzando una combinazione di tecnologie automatiche e umane per offrire ai nostri utenti in tutto il mondo contenuti di supporto nella propria lingua. Si noti che anche la migliore traduzione automatica non sarà mai accurata come quella fornita da un traduttore professionista. Cisco Systems, Inc. non si assume alcuna responsabilità per l’accuratezza di queste traduzioni e consiglia di consultare sempre il documento originale in inglese (disponibile al link fornito).
Sommario
Introduzione
In questo documento vengono descritti vari metodi di analisi per risolvere i problemi di mancata corrispondenza del checksum di replica geografica tra rack locali e remoti.
Prerequisiti
Requisiti
Cisco raccomanda la conoscenza dei seguenti argomenti:
- Ridondanza geografica nella funzione di gestione delle sessioni (SMF)
- SMF
- Terminazione connessione Transmission Control Protocol (TCP)
Componenti usati
Il documento può essere consultato per tutte le versioni software o hardware.
Le informazioni discusse in questo documento fanno riferimento a dispositivi usati in uno specifico ambiente di emulazione. Su tutti i dispositivi menzionati nel documento la configurazione è stata ripristinata ai valori predefiniti. Se la rete è operativa, valutare attentamente eventuali conseguenze derivanti dall'uso dei comandi.
Premesse
Che cos'è la ridondanza geografica in SMF?
-
SMF supporta la ridondanza geografica (geografica)- (GR) in modalità attivo-attivo.
-
L'installazione GRE è anche responsabile della replica dei
etcd/cachedati sul rack in standby. -
SMF supporta la ridondanza primaria/standby in cui i dati vengono replicati dall'istanza primaria all'istanza di standby.
-
Se l'istanza primaria ha esito negativo, l'istanza in standby diventa la principale e assume il controllo dell'operazione.
-
Per ottenere il riconoscimento GRE, è possibile impostare due coppie principali/standby in cui ciascun sito elabora attivamente il traffico e lo standby funge da backup per il sito remoto.
Pod di replica geografica
-
Il POD di replica geografica è stato introdotto per la comunicazione tra rack/sito e per monitorare POD/BFD all'interno del rack
-
Due istanze di GR-POD vengono eseguite su ogni rack/sito
-
Due POD GR in modalità di standby attivo
-
I POD GRE vengono generati sul nodo Proto/VM
-
Il POD GRE utilizza due indirizzi IP virtuali (VIP)
-
Interno-VIP per comunicazione inter-POD (all'interno del rack)
-
External-VIP per comunicazione POD GRE/Inter-Rack
-
I VIP configurati per POD GRE possono essere attivi su uno dei nodi Proto/VM
-
Quando si riavvia il POD GR attivo, VIP passa a un altro nodo Proto/VM e il POD GR standby viene eseguito sull'altro nodo Proto/VM può diventare Attivo
Configurazione di riferimento per il pod GRE:
smf# show running-config instance instance-id 1 endpoint geo
Thu Oct 20 06:25:25.319 UTC+00:00
instance instance-id 1
endpoint geo
replicas 1
nodes 2
interface geo-internal
vip-ip a.b.c.d vip-port 7001
exit
interface geo-external
vip-ip Y.Y.Y.Y vip-port 7002
exit
exit
exit
Identificare il GeoPod attivo e il GeoPod in standby
Per identificare il geo pod attivo, è necessario verificare la presenza di errori o eventi nei registri geo pod.
Baccello attivo:
user@smf-ims-master-1:~$ kubectl logs georeplication-pod-0 -n smf-smfix1|tail -3
[ERROR] [grcacachepod.go:339] [gr_deferred_sync.application.app] Periodic Sync: Total time taken to sync IPAM cache pod data: 500.563723ms”
[ERROR] [GeoAdminStreamClient.go:276] [gr_pod.geo_admin_client.app] no one waiting for received response for txnID:CP0XXXOKCP0XXX-SMF-IMS-smfix1111163550 of host=geo-admin-pod2
Proiettore di standby:
user@cp0xxx-smf-ims-master-1:~$ kubectl logs georeplication-pod-1 -n smf-smfix1|tail -3
[ERROR] [gr_pod.geo_replication_client_stream] Counters => not an active geo pod
[ERROR] [gr_pod.geo_replication_client_stream] Counters => not an active geo pod
[ERROR] [gr_pod.geo_replication_client_stream] Counters => not an active geo pod
Funzionalità di GRE POD
I pod GRE replicano l'ETCD e i dati dei pod cache nel sito
Per visualizzare i dettagli di replica per i dati ETCD e cache-pod, utilizzare CLI:
[cp0xxx-smf-ims/smfix1] smf# show georeplication checksum instance-id 1
Thu Oct 20 07:11:52.409 UTC+00:00
checksum-details
-- ---- --------
ID Type Checksum
-- ---- -------
1 ETCD 1666249907
IPAM CACHE 1666249907
NRFMgmt CACHE 1666249907
Gestisci ruoli istanze locali del sito in ETCD
[ERROR] [gr_pod.gradmin] updateEntryInEtcd: Updating etcd entries for keys : Instance.2, with role as PRIMARY
[ERROR] [gr_pod.gradmin] updateEntryInEtcd: Updating etcd entries for keys : Instance.1, with role as STANDBY
Monitoraggio dello stato del sito locale (stato POD/stato BFD)
[cp0xxx-smf-ims/smfix1] smf# show running-config geomonitor podmonitor pods smf-service
Thu Oct 20 07:36:41.280 UTC+00:00
geomonitor podmonitor pods smf-service
retryCount 2
retryInterval 900
retryFailOverInterval 500
failedReplicaPercent 60
Ruoli sito
PRIMARY : Il sito è pronto e gestisce attivamente il traffico per l'istanza specificata.
STANDBY: Il sito è in standby, pronto per ricevere traffico ma non accetta il traffico per un'istanza specifica.
STANDBY_ERROR: Il sito è in un problema, non è attivo e non è pronto a ricevere traffico per un'istanza specifica.
FAILOVER_INIT: Il sito ha iniziato il failover e non è in grado di gestire il traffico. Il tempo di buffer per il completamento dell'attività dell'applicazione è di 2 secondi.
FAILOVER_COMPLETE: Il sito ha completato il failover e ha tentato di informare il sito peer sul failover per l'istanza specificata. tempo di buffer di 2s.
FAILBACK_STARTED: Il failover manuale viene attivato con un ritardo dal sito remoto per un'istanza specifica.

Nota: Cache/ETCD Replication e CDL Replication si verificano anche in tutti i ruoli. Se i collegamenti GR sono inattivi o l'heartbeat periodico non riesce, i trigger GR vengono sospesi.
GR-Trigger
CLI per verificare i ruoli dell'istanza GRE sul rack
Show role instance id 1
Show role instance id 2
CLI per reimpostare il ruolo dall'errore di standby allo standby
Geo reset-role instance-id <1/2> role standby
Errore CLI-switch ruolo da standby a standby
Geo switch-role instance-id <1/2> role standby failback-interval 0
Ruolo CLI-switch da standby a primario
Per avviare questo ruolo dello switch, è necessario attivare la CLI dal rack che ha una delle istanze come primaria.
Geo switch-role instance-id <1/2> role standby failback-interval 0
Nota: Scenario di domenica: Rack1-Instance1-Principale, Instance2-Standby; Rack2-Instance1-StandBy, Instance2-Primario.
Scenario Rainy Day: Rack1-Istanza 1 e Istanza 2-Principale; Rack2-Istanza 1 e Istanza 2-StandBy.
Terminazione connessione TCP
Il protocollo TCP è un protocollo orientato alla connessione, il che significa che viene stabilita e mantenuta una connessione fino a quando i programmi applicativi a ciascuna estremità non hanno terminato lo scambio di messaggi. Il protocollo TCP funziona con il protocollo Internet (IP).
L'handshake TCP è anche noto come handshake a 3 vie. Quando viene avviata una connessione tra il computer client e il computer server, il client e il server scambiano i pacchetti SYN e ACK prima di trasmettere i dati.
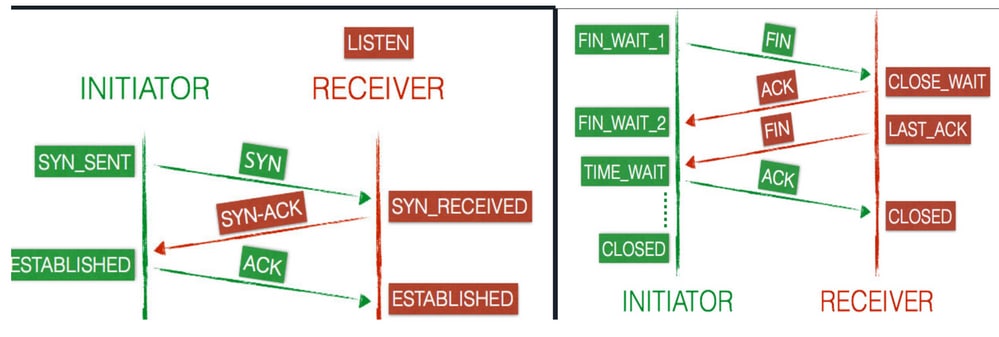 Transmission Control Protocol: stati di connessione client e server
Transmission Control Protocol: stati di connessione client e server
Una connessione passa attraverso una serie di stati per tutta la sua durata. Gli stati sono: LISTEN, SYN-SENT SYN-RECEIVED, ESTABLISHED, FIN-WAIT-1, FIN-WAIT-2,CLOSE-WAIT,CLOSING, LAST-ACK, TIME-WAITe lo stato fittizio CLOSED.
- Quando viene aperta una nuova connessione TCP, il client (iniziatore) invia un
SYNpacchetto al server (ricevente) e ne aggiorna lo stato inSYN-SENT. - Il server invia quindi un messaggio di risposta al client,
SYN-ACKche cambia il proprio stato di connessione inSYN-RECEIVED.
- Il client risponde con un
ACKe la connessione è contrassegnata comeESTABLISHEDsu entrambi gli endpoint, ora il client e il server sono pronti per trasferire i dati.
- Il client invia un
FINpacchetto al server e ne aggiorna lo stato inFIN-WAIT-1. - Il server riceve la richiesta di terminazione dal client e risponde con un
ACKmessaggio. Dopo la risposta, il server entra in unoCLOSE-WAITstato. - Non appena il client riceve la risposta dal server, passa allo
FIN-WAIT-2stato. - Il server si trova ancora nello
CLOSE-WAITstato e viene associato in modo indipendente a un'istruzione FIN, che aggiorna lo stato aLAST-ACK. - Ora il client riceve la richiesta di terminazione e risponde con un
ACK, che determina unoTIME-WAITstato. - Il server è ora terminato e imposta la connessione su
CLOSEDimmediatamente. - Il client rimane nello stato
TIME-WAITattivo per un massimo di quattro minuti, prima della connessione, diCLOSED.
Problema
Scenario 1. Checksum della replica geografica per l'istanza con ID 1 con cache di Gestione indirizzi IP e checksum della cache di NRFMgmt non corrispondenti
Lo stato della replica geografica di smfix1/smfix2 è non riuscito (replica tra rack sul sito remoto non riuscita).
ERRORE: Comando Admin non riuscito [pod internal-gr-pod-1, URL http://X.X.0.0:15290/commands] con codice 424, messaggio non riuscito: checksum di replica non corrispondente.
Il problema è stato osservato il 23 agosto alle 00:36:19 come "Replica tra rack non riuscita".
From CEE alerts:
Inter_Rack_Replication 9ca45362a049 critical 08-23T00:36:19 System
Inter rack replication to Remote Site failed
Da questo output della CLI, è possibile vedere che l'ID istanza 1 non corrisponde al checksum per la gestione degli indirizzi IP (IPAM) e la cache NRF.
[cp0xxx-smf-ims/smfix1] smf# show georeplication checksum instance-id 1
Mon Sep 5 08:38:27.762 UTC+00:00
checksum-details
-- --- --------
ID Type Checksum
-- ---- --------
1 ETCD 1662367102
IPAM CACHE 1662367102
NRFMgmtCACHE 1662367102
[cp0xxx-smf-ims/smfix2] smf# show georeplication checksum instance-id 1
Mon Sep 5 08:38:30.767 UTC+00:00
checksum-details
-- ---- --------
ID Type Checksum
-- ---- --------
1 ETCD 1662367102
IPAM CACHE 1661214831
NRFMgmtCACHE 1661214831
Scenario 2. Checksum della replica geografica per l'istanza con ID 2 non corrispondente al checksum ETCD
[cp0xxx-smf-ims/smfix1] smf# show georeplication checksum instance-id 2
Mon Sep 5 08:38:37.852 UTC+00:00
checksum-details
-- ---- --------
ID Type Checksum
-- ---- --------
2 ETCD 1661214828
IPAM CACHE 1662367107
NRFMgmtCACHE 1662367107
[cp0xxx-smf-ims/smfix2] smf# show georeplication checksum instance-id 2
Mon Sep 5 08:38:39.118 UTC+00:00
checksum-details
-- ---- -------
ID Type Checksum
-- ---- --------
2 ETCD 1662367107
IPAM CACHE 1662367107
NRFMgmtCACHE 1662367107
Scenario 3. Errore di connessione TCP con il sito remoto
Registri-smfix1-rack1:
Dai registri del POD GRE è possibile osservare che il checkpoint della cache di aggiornamento è stato arrestato, che la replica immediata non è riuscita e che non è disponibile alcun host remoto.
2022/08/23 00:34:00.035 [ERROR] [grreplicationclient.go:201] [gr_pod.geo_replication_client_stream.app] HandleImmediateReplication failed: [RPCNoRemoteHostAvailable] No remote host available for this request
2022/08/23 00:34:02.086 [ERROR] [grreplicationclient.go:466] [gr_pod.geo_replication_client_stream.app] Stream disconnected, closing logQueueCounter=0xc0093b08b0
2022/08/23 00:34:04.124 [ERROR] [GeoAdminStreamClient.go:215] [gr_pod.geo_admin_client.app] ADMIN(geo-admin-pod2) : exit outgoing request loop stream closed
2022/08/23 00:34:43.623 [ERROR] [grreplicationclient.go:270] [gr_pod.geo_replication_client_stream.app] Update etcd checkpointing stopped for grinstance: 1
Log di Rack2-smfix2:
Dai registri dei POD GRE è possibile osservare un errore di Stream disconnected e una differenza di checksum della CACHE superiore al previsto.
2022/08/23 00:34:06.497 [ERROR] [grreplicationserver.go:62] [gr_pod.geo_replication_server_stream.app] Stream disconnected, closing logQueueCounter=0xc001b85d08
2022/08/23 00:34:06.497 [ERROR] [grreplicationserver.go:314] [gr_pod.geo_replication_server_stream.app] handleCachePodSyncRequests : Stream closed of connection=0xc002ee08f0
2022/08/23 00:34:56.751 [ERROR] [grpodcommands.go:455] [gr_pod.cli_command.app] compareChecksumData: CACHE checksum difference is more then expected, local checksum [1661214831] remote checksum [1661214892]
2022/08/23 00:34:56.678 [ERROR] [etcdAuditReplHandler.go:196] [gr_pod.application.app] SyncETCDData periodic sync : For ETCD [C.GR.1.] key, the remote site data size is: [10833]
2022/08/23 00:36:56.757 [ERROR] [grpodcommands.go:455] [gr_pod.cli_command.app] compareChecksumData: CACHE checksum difference is more then expected, local checksum [1661214831] remote checksum [1661215012]
Scenario 4. Errore DIMM osservato sul server che ospita il nodo master
L'errore ECC viene rilevato sul nodo master-1 che ospita geo-replication-pod-0 nello stesso momento dell'errore di disconnessione del flusso.
CP0XXX-Server9-02# scope sel
CP0XXX-Server9-02 /sel # show entries
Time Severity Description
----------------------- ------------- ----------------------------------------
2022-08-23 00:33:59 UTC Informational "DDR4_P1_E1_ECC: Memory sensor, read 1 correctable ECC errors on CPU1 DIMM E1 was asserted"
2022-08-22 22:59:45 UTC Informational "DDR4_P1_E1_ECC: Memory sensor, read 1 correctable ECC errors on CPU1 DIMM E1 was asserted"
- La comunicazione tra il pod di replica geografica sul rack 1 e il pod di replica geografica sul rack 2 è interrotta.
-
L'errore DIMM si verifica su uno dei nodi master che ha causato il blocco della connessione tra Rack1 e Rack2.
-
Da Rack1 Geo-replication-pod non è stato in grado di replicare o inviare alcuna richiesta a Rack2, viene visualizzato l'errore Host remoto non disponibile.
-
Dall'output del comando netstat su Rack1 e Rack2 per la porta 7002, è stato rilevato che il socket Rack1 è bloccato nello stato FIN_WAIT1 e il socket Rack2 è bloccato nello stato SYN_RECV.
-
Sul lato server, ossia su Rack2, il socket è bloccato nello stato SYNC_RECV, e la nuova connessione creata passa anche nello stato SYNC_RECV e non è in grado di comunicare tra loro.
-
Lo stato della connessione è SYN_RECV perché il kernel ha ricevuto un pacchetto SYN per una porta, ossia in modalità LISTENING, ma l'altra estremità non ha risposto con ACK.
smfix2-Master-2 ha installato Geo External VIP (Y.Y.Y.Y:7002) ma lo stato di connessione TCP dell'host remoto (SMFIX1) è bloccato nello stato SYN_RECV anziché nello stato DEFINED. a.b.c.d e a.b.c.e sono Master-1 e 2 IP di smfix1 (Rack1).
user@cp0xxx-smf-ims-master-2:~$ netstat -anp | grep 7002
tcp 0 0 Y.Y.Y.Y:7002 0.0.0.0:* LISTEN -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:35542 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:47046 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:36248 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:42686 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:38248 SYN_RECV -
Lo stato della connessione TCP VIP geografica esterna su smfix1 (Rack1) per il peer remoto è in stato FIN-WAIT1:
user@cp0xxx-smf-ims-master-1:~$ netstat -anp | grep 7002
tcp 0 0 a.b.c.d 0.0.0.0:* LISTEN -
tcp 0 1 a.b.c.d:60866 Y.Y.Y.Y:7002 FIN_WAIT1 -
tcp 0 1 a.b.c.d:52274 Y.Y.Y.Y:7002 FIN_WAIT1 -
tcp 0 1 a.b.c.d:59674 Y.Y.Y.Y:7002 FIN_WAIT1 -
tcp 0 1 a.b.c.d:47926 Y.Y.Y.Y:7002 FIN_WAIT1 -
Soluzione
Rack 1:
-
Eliminare innanzitutto il geo pod in standby, attendere che il pod venga ripristinato, quindi eliminare il pod Geo attivo. Accedere al master VIP ed eliminare il pod Geo:
kubectl delete pod-n
Rack 2:
- Eliminare innanzitutto il geo pod in standby, attendere che il pod si riprenda, quindi eliminare il geo pod attivo.
-
Verificare lo stato della replica geografica dalla CLI e inviare l'eliminazione dei GeoPod.
show georeplication-status
- Dopo l'eliminazione del geo pod su Rack1 e Rack2, è possibile visualizzare l'indirizzo IP VIP geografico esterno: La porta TCP passa allo stato STABILITO.
- Stato replica geografica "Superato".
- Nello stato di replica tra i rack non viene rilevata alcuna mancata corrispondenza del checksum.
smfix2 (Rack2):
user@cp0xxx-smf-ims-master-1:~$ sudo netstat -anp | grep 7002 | grep -v aa
tcp 0 0 Y.Y.Y.Y:7002 0.0.0.0:* LISTEN 36854
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:46402 ESTABLISHED 36854/grpod
tcp 0 0 Y.Y.Y.Y:7002 1a.b.c.e:54708 ESTABLISHED 36854/grpod
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:55152 ESTABLISHED 36854/grpod
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:46530 ESTABLISHED 36854/grpod
tcp 0 0 10.59.0.0:7002 10.59.0.0:46532 ESTABLISHED 36854/grpod
smfix1 (Rack1):
user@cp0xxx-smf-ims-master-1:~$ sudo netstat -anp | grep 7002 | grep -v aa
tcp 0 0 a.b.c.d 0.0.0.0:* LISTEN 53932/grpod
tcp 0 0 a.b.c.d:46530 Y.Y.Y.Y:7002 ESTABLISHED 53932/grpod
tcp 0 0 a.b.c.d:46402 Y.Y.Y.Y:7002 ESTABLISHED 53932/grpod
tcp 0 17 a.b.c.d:46532 Y.Y.Y.Y:7002 ESTABLISHED 53932/grpod
2. Stato della replica geografica:
[okcp0xx-smf-ims/smfix1] smf# show georeplication-status
result "pass"
[okcp0xx-smf-ims/smfix2] smf# show georeplication-status
result "pass"
Cronologia delle revisioni
| Revisione | Data di pubblicazione | Commenti |
|---|---|---|
1.0 |
05-Dec-2022
|
Versione iniziale |
Contributo dei tecnici Cisco
- Manasa G KambiCisco TAC Engineer
- Krishna Kishore D VCisco Technical Leader
 Feedback
Feedback