Risoluzione dei problemi quando Element Manager viene eseguito in modalità standalone
Opzioni per il download
Linguaggio senza pregiudizi
La documentazione per questo prodotto è stata redatta cercando di utilizzare un linguaggio senza pregiudizi. Ai fini di questa documentazione, per linguaggio senza di pregiudizi si intende un linguaggio che non implica discriminazioni basate su età, disabilità, genere, identità razziale, identità etnica, orientamento sessuale, status socioeconomico e intersezionalità. Le eventuali eccezioni possono dipendere dal linguaggio codificato nelle interfacce utente del software del prodotto, dal linguaggio utilizzato nella documentazione RFP o dal linguaggio utilizzato in prodotti di terze parti a cui si fa riferimento. Scopri di più sul modo in cui Cisco utilizza il linguaggio inclusivo.
Informazioni su questa traduzione
Cisco ha tradotto questo documento utilizzando una combinazione di tecnologie automatiche e umane per offrire ai nostri utenti in tutto il mondo contenuti di supporto nella propria lingua. Si noti che anche la migliore traduzione automatica non sarà mai accurata come quella fornita da un traduttore professionista. Cisco Systems, Inc. non si assume alcuna responsabilità per l’accuratezza di queste traduzioni e consiglia di consultare sempre il documento originale in inglese (disponibile al link fornito).
Sommario
Introduzione
In questo documento viene illustrato come risolvere i problemi quando Element Manager viene eseguito in modalità autonoma.
Prerequisiti
Requisiti
Cisco raccomanda la conoscenza dei seguenti argomenti:
- StarOs
- Architettura di base Ultra-M
Componenti usati
Le informazioni fornite in questo documento si basano sulla versione Ultra 5.1.x.
Le informazioni discusse in questo documento fanno riferimento a dispositivi usati in uno specifico ambiente di emulazione. Su tutti i dispositivi menzionati nel documento la configurazione è stata ripristinata ai valori predefiniti. Se la rete è operativa, valutare attentamente eventuali conseguenze derivanti dall'uso dei comandi.
Premesse
Ultra-M è una soluzione di base di pacchetti mobili preconfezionata e convalidata, progettata per semplificare l'installazione di VNF. OpenStack è Virtualized Infrastructure Manager (VIM) per Ultra-M ed è costituito dai seguenti tipi di nodi:
- Calcola
- Disco Object Storage - Compute (OSD - Compute)
- Controller
- Piattaforma OpenStack - Director (OSPD)
L'architettura di alto livello di Ultra-M e i componenti coinvolti sono illustrati in questa immagine:
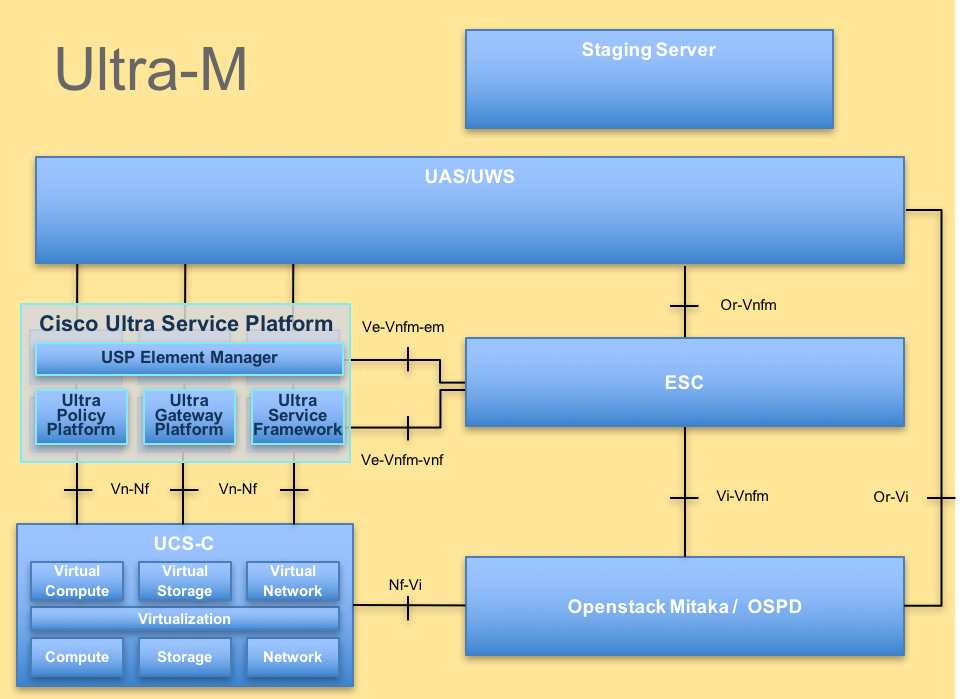 Architettura UltraM
Architettura UltraM
Questo documento è destinato al personale Cisco che ha familiarità con la piattaforma Cisco Ultra-M e descrive i passaggi richiesti da eseguire a livello OpenStack e StarOS VNF al momento della sostituzione del server dei controller.
Abbreviazioni
In questo articolo vengono utilizzate le abbreviazioni seguenti:
| VNF | Funzione di rete virtuale |
| EM | Gestione elementi |
| VIP | Virtual IP Address |
| CLI | Riga di comando |
Problema: EM può finire in questo stato come sembra da Ultra-M Health Manager
EM: 1 is not part of HA-CLUSTER,EM is running in standalone mode
A seconda della versione, possono essere presenti 2 o 3 EM in esecuzione sul sistema.
Nel caso in cui si disponga di 3 EM, due di essi sarebbero funzionali e il terzo solo per poter avere il cluster Zookeeper. Tuttavia, non viene utilizzato.
Se uno dei due moduli funzionali non dovesse funzionare o non fosse raggiungibile, l'unità operativa sarebbe in modalità indipendente.
Se sono stati distribuiti 2 moduli EM, nel caso in cui uno di essi non funzioni o non sia raggiungibile, i moduli EM rimanenti possono essere in modalità standalone.
In questo documento viene spiegato cosa verificare in questo caso e come eseguire il ripristino.
Procedure di risoluzione dei problemi e ripristino
Passaggio 1. Verificare lo stato degli EM.
Connettersi all'indirizzo VIP EM e verificare che il nodo si trovi in questo stato:
root@em-0:~# ncs_cli -u admin -C
admin connected from 127.0.0.1 using console on em-0
admin@scm# show ems
EM VNFM ID SLA SCM PROXY
3 up down up
admin@scm#
Quindi, da qui, potete vedere che c'è solo una voce in SCM - ed è la voce per il nostro nodo.
Se si riesce a collegarsi all'altro EM, è possibile visualizzare qualcosa come:
root@em-1# ncs_cli -u admin -C admin connected from 127.0.0.1 using
admin connected from 127.0.0.1 using console on em-1
admin@scm# show ems
% No entries found.
A seconda del problema riscontrato in EM, NCS CLI non è accessibile o il nodo può essere riavviato.
Passaggio 2. Controllare i log in /var/log/em sul nodo che non fa parte del cluster.
Controllare i registri nel nodo in stato di problema. Quindi, per il campione menzionato, si naviga em-1 /var/log/em/zookeeper logs:
...
2018-02-01 09:52:33,591 [myid:4] - INFO [main:QuorumPeerMain@127] - Starting quorum peer
2018-02-01 09:52:33,619 [myid:4] - INFO [main:NIOServerCnxnFactory@89] - binding to port 0.0.0.0/0.0.0.0:2181
2018-02-01 09:52:33,627 [myid:4] - INFO [main:QuorumPeer@1019] - tickTime set to 3000
2018-02-01 09:52:33,628 [myid:4] - INFO [main:QuorumPeer@1039] - minSessionTimeout set to -1
2018-02-01 09:52:33,628 [myid:4] - INFO [main:QuorumPeer@1050] - maxSessionTimeout set to -1
2018-02-01 09:52:33,628 [myid:4] - INFO [main:QuorumPeer@1065] - initLimit set to 5
2018-02-01 09:52:33,641 [myid:4] - INFO [main:FileSnap@83] - Reading snapshot /var/lib/zookeeper/data/version-2/snapshot.5000000b3
2018-02-01 09:52:33,665 [myid:4] - ERROR [main:QuorumPeer@557] - Unable to load database on disk
java.io.IOException: The current epoch, 5, is older than the last zxid, 25769803777
at org.apache.zookeeper.server.quorum.QuorumPeer.loadDataBase(QuorumPeer.java:539)
at org.apache.zookeeper.server.quorum.QuorumPeer.start(QuorumPeer.java:500)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.runFromConfig(QuorumPeerMain.java:153)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.initializeAndRun(QuorumPeerMain.java:111)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.main(QuorumPeerMain.java:78)
2018-02-01 09:52:33,671 [myid:4] - ERROR [main:QuorumPeerMain@89] - Unexpected exception, exiting abnormally
java.lang.RuntimeException: Unable to run quorum server
at org.apache.zookeeper.server.quorum.QuorumPeer.loadDataBase(QuorumPeer.java:558)
at org.apache.zookeeper.server.quorum.QuorumPeer.start(QuorumPeer.java:500)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.runFromConfig(QuorumPeerMain.java:153)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.initializeAndRun(QuorumPeerMain.java:111)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.main(QuorumPeerMain.java:78)
Caused by: java.io.IOException: The current epoch, 5, is older than the last zxid, 25769803777
at org.apache.zookeeper.server.quorum.QuorumPeer.loadDataBase(QuorumPeer.java:539)
Passaggio 3. Verificare che lo snapshot in questione esista.
Passare a /var/lib/zookeeper/data/version-2 e verificare che sia presente un'istantanea rossa nel passaggio 2.
300000042 log.500000001 snapshot.300000041 snapshot.40000003b
ubuntu@em-1:/var/lib/zookeeper/data/version-2$ ls -la
total 424
drwxrwxr-x 2 zk zk 4096 Jan 30 12:12 .
drwxr-xr-x 3 zk zk 4096 Feb 1 10:33 ..
-rw-rw-r-- 1 zk zk 1 Jan 30 12:12 acceptedEpoch
-rw-rw-r-- 1 zk zk 1 Jan 30 12:09 currentEpoch
-rw-rw-r-- 1 zk zk 1 Jan 30 12:12 currentEpoch.tmp
-rw-rw-r-- 1 zk zk 67108880 Jan 9 20:11 log.300000042
-rw-rw-r-- 1 zk zk 67108880 Jan 30 10:45 log.400000024
-rw-rw-r-- 1 zk zk 67108880 Jan 30 12:09 log.500000001
-rw-rw-r-- 1 zk zk 67108880 Jan 30 12:11 log.5000000b4
-rw-rw-r-- 1 zk zk 69734 Jan 6 05:14 snapshot.300000041
-rw-rw-r-- 1 zk zk 73332 Jan 29 09:21 snapshot.400000023
-rw-rw-r-- 1 zk zk 73877 Jan 30 11:43 snapshot.40000003b
-rw-rw-r-- 1 zk zk 84116 Jan 30 12:09 snapshot.5000000b3 ---> HERE, you see it
ubuntu@em-1:/var/lib/zookeeper/data/version-2$
Passaggio 4. Operazioni di ripristino.
1. Abilitare la modalità di debug in modo che EM interrompa il riavvio.
ubuntu@em-1:~$ sudo /opt/cisco/em-scripts/enable_debug_mode.sh
Potrebbe essere necessario riavviare nuovamente la VM (in questo caso, non è necessario eseguire alcuna operazione)
2. Spostare i dati dell'amministratore delle cassette postali.
In /var/lib/zookeeper/data è presente la cartella denominata versione-2 che contiene lo snapshot del database. L'errore sopra riportato indica che il caricamento non è riuscito in modo da essere rimosso.
ubuntu@em-1:/var/lib/zookeeper/data$ sudo mv version-2 old ubuntu@em-1:/var/lib/zookeeper/data$ ls -la total 20 .... -rw-r--r-- 1 zk zk 2 Feb 1 10:33 myid drwxrwxr-x 2 zk zk 4096 Jan 30 12:12 old --> so you see now old folder and you do not see version-2 -rw-rw-r-- 1 zk zk 4 Feb 1 10:33 zookeeper_server.pid ..
3. Riavviare il nodo.
sudo reboot
4. Disabilitare nuovamente la modalità di debug.
ubuntu@em-1:~$ sudo /opt/cisco/em-scripts/disable_debug_mode.sh
Tali procedure consentiranno al servizio di riesaminare il problema EM.
Contributo dei tecnici Cisco
- Snezana MitrovicCisco TAC Engineer
 Feedback
Feedback