Introduzione
In questo documento viene descritto come IM&P (Instant Message and Presence) High Availability funziona in un ambiente IM&P aziendale e come risolverlo.
Prerequisiti
Requisiti
Cisco raccomanda la conoscenza dei seguenti argomenti:
- Cisco Unified IM&P
- Client Cisco Jabber
Componenti usati
- Cisco Unified IM&P 10.0 e versioni successive
- Cisco Jabber client 9.6 e versioni successive
Le informazioni discusse in questo documento fanno riferimento a componenti usati in uno specifico ambiente di emulazione. Su tutti i componenti menzionati nel documento la configurazione è stata ripristinata ai valori predefiniti. Se la rete è operativa, valutare attentamente eventuali conseguenze derivanti dall'uso dei comandi.
IM e Presence High Availability (HA)
Il server dei servizi di messaggistica immediata e presenza offre alta disponibilità o ridondanza sotto forma di gruppi di server logici nella configurazione CUCM. Questa configurazione viene passata a IM e Presence e quindi utilizzata per consentire la ridondanza in caso di errore di un servizio di messaggistica immediata e presenza o di un server. Quando si verifica un evento HA, le sessioni dell'utente finale vengono spostate dal server in cui si è verificato l'errore al backup. Una volta ripristinato lo stato normale del server, le sessioni utente vengono quindi spostate automaticamente o manualmente dall'amministratore.
Configurazione gruppo di ridondanza
Il gruppo di ridondanza è la coppia di server logici che consente l'assegnazione di un server al sottocluster IM e Presenza, nonché la configurazione per HA. Per accedere a questa parte della configurazione, individuarla nella pagina Web del server CUCM.
Sistema > Gruppi di ridondanza di presenza
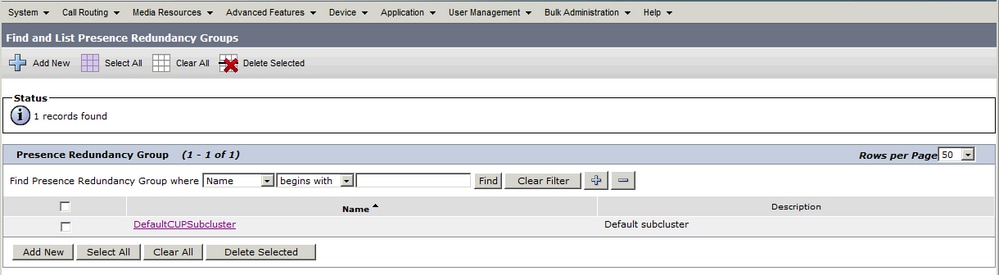
Quando l'amministratore aggiunge il server di pubblicazione IM&P alla configurazione System > Server in CUCM e il server IM&P viene salvato, il gruppo di ridondanza DefaultCUPSubCluster viene creato con il server di pubblicazione assegnato.
Una volta creato, il gruppo di ridondanza ha il seguente aspetto:
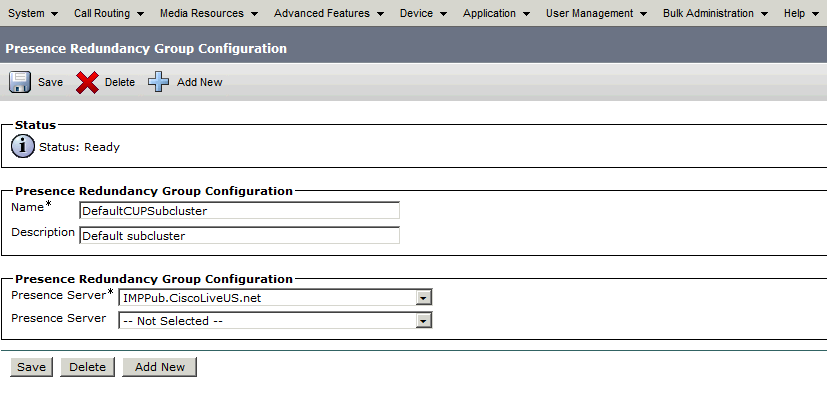
Questo gruppo di ridondanza viene convertito nel cluster IM e Presence. Nello stato corrente della configurazione del gruppo di ridondanza in CUCM, questo è l'aspetto che avrebbe nella pagina Web della topologia cluster di presenza e messaggistica immediata:
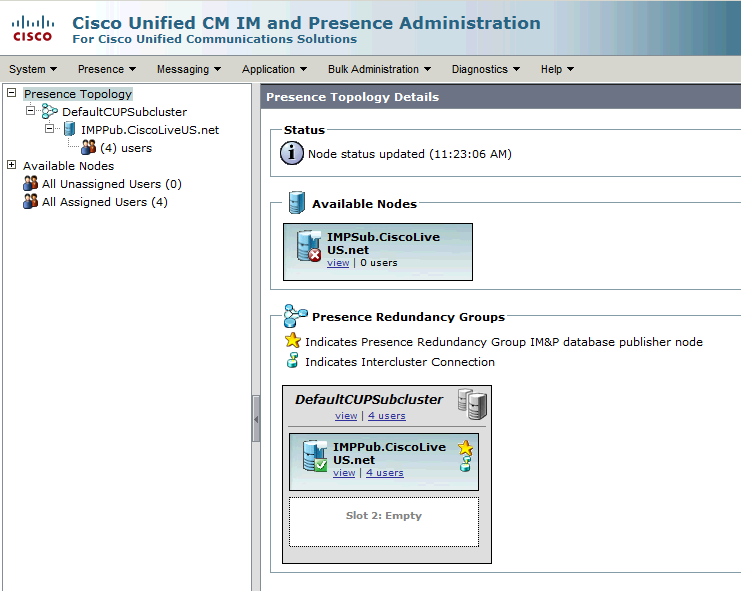
Il server di pubblicazione IM&P è assegnato al sottocluster DefaultCUPSe il server sottoscrittore no. Il server IM&P Subscriber non è assegnato al gruppo di ridondanza nella configurazione CUCM.
Assegnare il Sottoscrittore al gruppo di ridondanza.
Per assegnare il server Subscriber al gruppo di ridondanza, è sufficiente scegliere il server Subscriber dal menu a discesa, quindi salvare la modifica della configurazione.
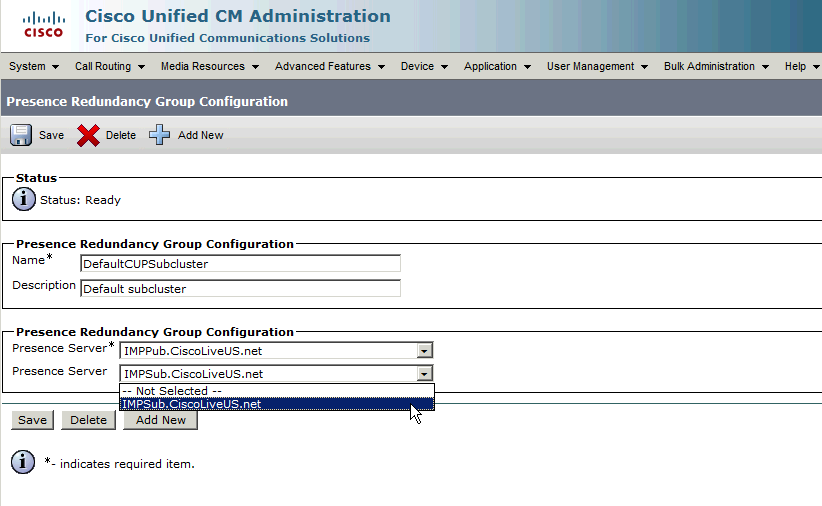
Dopo l'aggiunta del sottoscrittore IM&P al gruppo di ridondanza:
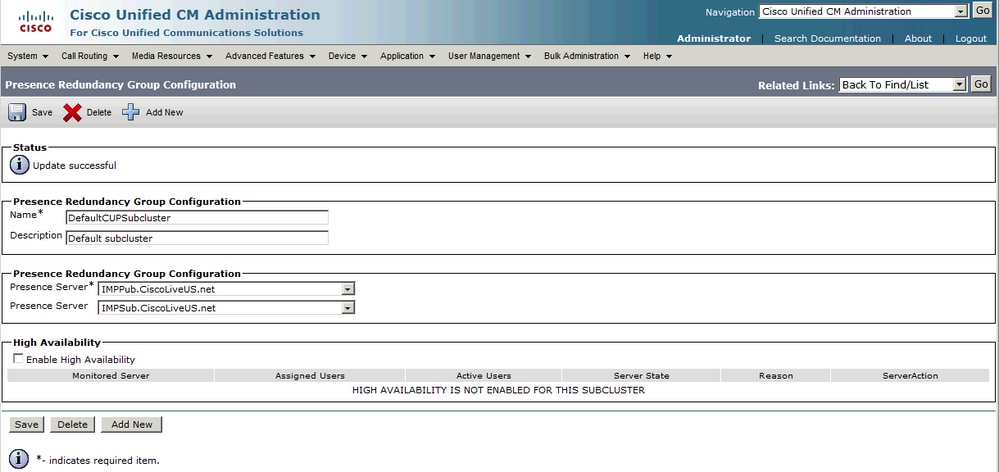
Dopo l'aggiunta del nodo secondario (il sottoscrittore) è possibile selezionare l'opzione Alta disponibilità. Per abilitare l'alta disponibilità, è sufficiente selezionare la casella di controllo Abilita alta disponibilità e salvare la modifica della configurazione.
Dopo l'attivazione della disponibilità elevata:
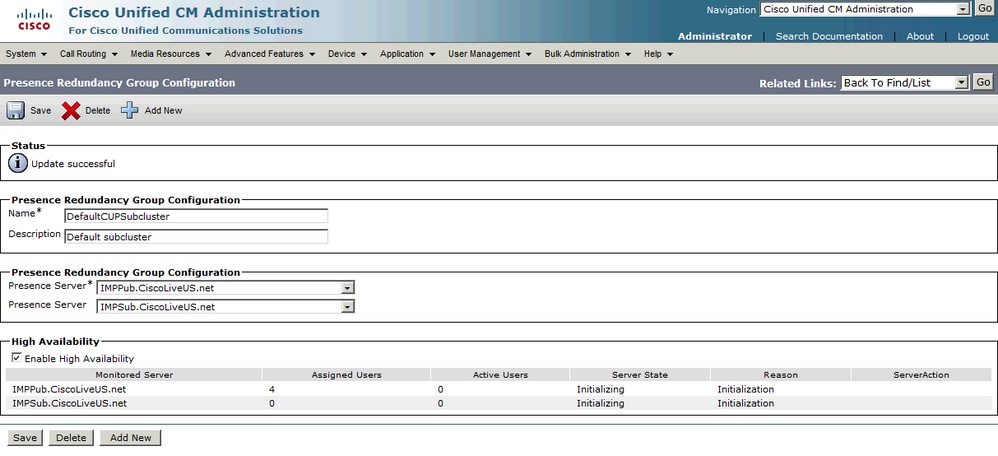
La pagina quindi aggiorna automaticamente lo stato e il motivo del server. Quando il server è in uno stato di inizializzazione, i due server sono in grado di comunicare. I server verificheranno quindi lo stato del servizio prima che lo stato passi allo stato Normale. Se i due server sono in grado di connettersi tra loro e tutti i servizi monitorati sono attivi su entrambi, lo stato sarà Normale. Ciò significa che tutti i servizi monitorati sono attivi sui server IM&P.
Stato del gruppo di ridondanza normale:
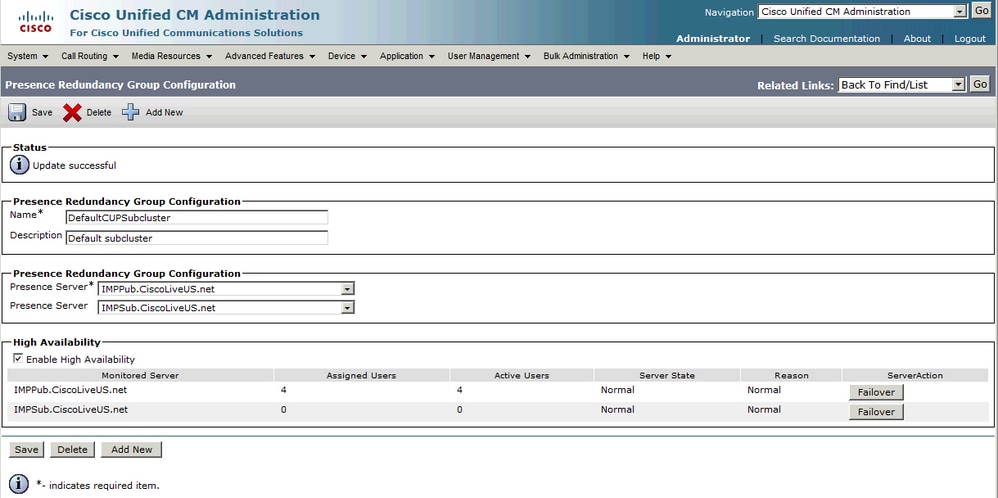
Stato normale-normale alta disponibilità nella pagina Topologia IM&P:
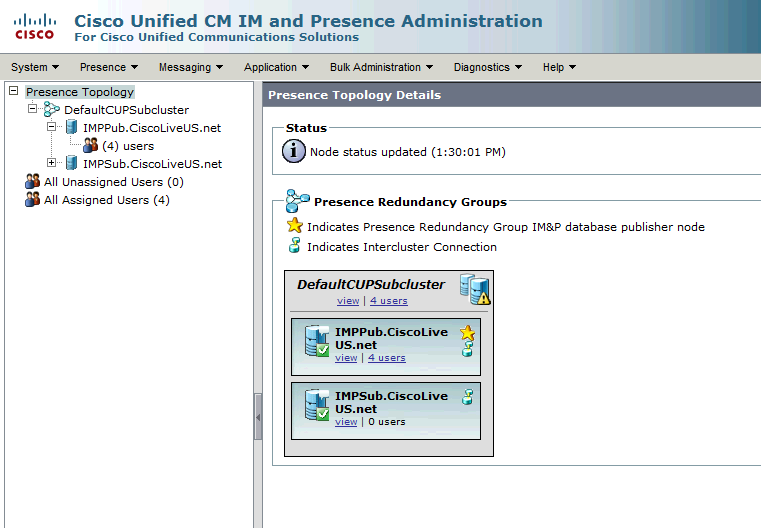
Servizi di messaggistica istantanea e presenza monitorati
Poiché è possibile disporre di diversi modelli di distribuzione: solo messaggistica immediata, messaggistica immediata con federazione SIP/XMPP, messaggistica immediata con conformità, messaggistica immediata con chat persistente, solo controllo delle chiamate remote e così via, l'elenco effettivo dei processi da monitorare è dinamico. Per impostazione predefinita, questi elementi vengono sempre monitorati quando è abilitata l'opzione HA:
- Database IDS
- Motore presenza (se attivato)
- Router XCP
Server Recovery Manager verifica se la conformità (Message Archiver), la chat persistente (Text Conference Manager), la federazione SIP (SIP Federation Connection Manager), la federazione XMPP (XMPP Federation Connection Manager) sono configurate e attivate.
Se sono entrambi configurati e attivati, Server Recovery Manager (SRM) esegue il monitoraggio anche di tali servizi.
Attenzione: prima di procedere con il riavvio di uno o più servizi monitorati, è necessario disabilitare l'alta disponibilità dai gruppi di ridondanza di presenza sul server CUCM. Lo stesso vale quando viene eseguito il riavvio di uno o più nodi IM&P.
Processo di failover utente
Quando si esegue un failover (automatico o manuale), è importante ricordare che l'account utente non viene spostato da un server all'altro, ma viene spostata solo la sessione utente in Presence Engine. Nelle versioni precedenti alla 10 di IM e Presence, l'assegnazione utente è stata spostata da un server all'altro. Questo spostamento dell'utente è stato molto costoso per le risorse del server e aggiunto al carico che era sul server. Nella versione 10.X e successive, l'utente rimane nel server a cui è assegnato e la sessione utente back-end nel motore di presenza viene spostata dal nodo con errori al nodo funzionale. L'utente non deve uscire da Jabber e accedere nuovamente quando la modifica avviene con Server Recovery Manager (SRM).
Timer di nuovo accesso client Jabber
Affinché la sessione utente diventi completamente attiva sul nodo IM&P secondario dopo un evento di failover, l'utente deve tentare di accedere a tale server tramite SOAP (Client Profile Agent). Questa operazione viene eseguita automaticamente con la password temporanea passata dal database IMDB. Poiché i costi di accesso sono molto elevati per le risorse dei server di messaggistica immediata e presenza, è necessario disporre di un modo per limitare i login quando si verifica un evento di failover. Questa limitazione o buffer consente a tutti gli utenti di accedere al nodo secondario senza interruzioni del servizio per gli utenti del nodo secondario. I meccanismi utilizzati per limitare i login degli utenti sono i parametri del servizio Client Re-Login Lower Limit e Client Re-Login Upper Limit Server Recovery Manager (SRM).
Limite inferiore di re-login client: parametro che definisce il periodo di tempo minimo (in secondi) che il client Jabber attende prima di tentare di accedere al server secondario nel caso di un evento HA.
Limite massimo di re-login del client: il parametro che definisce il periodo di tempo massimo (in secondi) che il client Jabber attende prima di tentare di accedere al server secondario in caso di evento HA.
Il client Jabber riceve questi parametri al momento dell'accesso al server e memorizza nella cache i valori per utilizzi futuri. Quando si riceve un evento HA dal server IM&P, il client sceglie un numero casuale di secondi tra i limiti superiore e inferiore e attende tale periodo di tempo prima che il client Jabber tenti di accedere al database secondario. Una volta scaduto il timer, il client tenta di eseguire il login SOAP al nodo secondario.
Tipi di fallback di messaggistica immediata e presenza
In caso di failover dell'utente, è necessario eseguire il fallback dell'utente quando il servizio viene ripristinato sul server che presenta problemi. Esistono due tipi di fallback del server:
Fallback manuale
Il fallback manuale (configurazione predefinita per Server Recovery Manager) ha luogo quando il servizio è stato ripristinato e il gruppo di ridondanza consente il pulsante Fallback. Quando questo pulsante è selezionato, le sessioni utente che sono state spostate nel nodo secondario vengono spostate di nuovo nel nodo locale. Il client Jabber applica quindi il re-log nei limiti superiore e inferiore per il fallback.
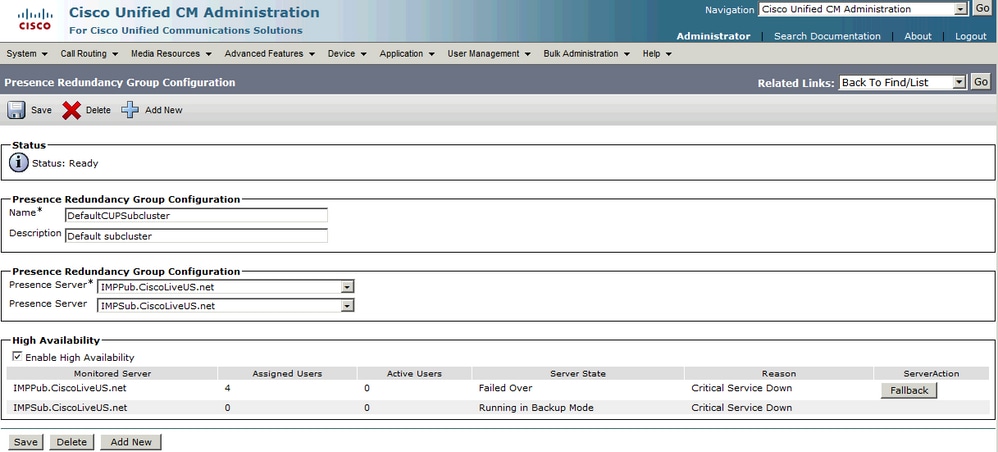
Fallback automatico
Il fallback automatico si verifica quando il server esegue il monitoraggio dei servizi e il servizio Server Recovery Manager (SRM) esegue automaticamente il fallback degli utenti ai nodi ospitati. In questa configurazione è fondamentale che il servizio Server Recovery Manager (SRM) attenda 30 minuti che un servizio o un server in errore rimanga attivo prima che venga avviato un fallback automatico. Una volta stabilito questo tempo di attività di 30 minuti, le sessioni utente vengono spostate nuovamente nei nodi ospitati. Il client Jabber applica quindi il re-log nei limiti superiore e inferiore per il fallback.

Nota: il fallback automatico non è la configurazione predefinita, ma può essere abilitato. Per attivare il fallback automatico, modificare il parametro Enable Automatic Fallback in Server Recovery Manager Service Parameters nel valore True.
Risoluzione dei problemi
Le informazioni contenute in questa sezione permettono di risolvere i problemi relativi alla configurazione.
Per la risoluzione dei problemi di elevata disponibilità sul server dei servizi IM&P, è necessario tenere in considerazione due importanti timer.
- I server scambiano 4 pacchetti keepalive ogni 60 secondi. Se non viene fornita alcuna risposta dopo 60 secondi, Cisco Service Recovery Manager (SRM) considera che il nodo che non risponde è stato disattivato e attiva un comando di failover. Come mostra lo snippet successivo, l'ultimo heartbeat si è verificato 62 secondi fa.
2021-05-13 02:48:48,244 INFO[HS]rsrm.RsrmHeartBeatHandler - RsrmHeartBeatHandler: peer down, time since last heartbeat[s]= 62
2021-05-13 02:48:48,244 INFO [HS] rsrm.RsrmAutomaticFallback - RsrmAutomaticFallback: peer states vector changed to [Normal,Running in Backup Mode]
Suggerimento: per questo scenario, se è stata rilevata una certa latenza nella rete, si consiglia di aumentare il timer del timeout di heartbeat da 60 a 90 secondi.
Passare alla pagina Web di amministrazione CUCM > Sistema > Configurazione parametri servizio > Selezionare il server IM&P> Seleziona impostazioni Cisco Recovery Manager. Nel timeout di Keep Alive (Heartbeat), aumentare il numero a 90 secondi.
- Il server IM&P Subscriber attende 90 secondi. Se viene rilevato che uno o più servizi monitorati sono inattivi, il server del Sottoscrittore ne assume il controllo.
Registri da raccogliere per la risoluzione dei problemi
- I registri di Server Recover Manager (SRM) vengono eseguiti prima e dopo l'evento di failover (livello di debug se possibile).
- L'output del comando tramite l'interfaccia della riga di comando IM&P esegue sql select * da enterprise subcluster.
- La tabella enterprise subcluster in IM&P contiene la configurazione del gruppo di ridondanza.
- L'output del comando tramite l'interfaccia della riga di comando IM&P esegue sql select * da enterprisenode.
- Nella tabella nodo organizzazione vengono visualizzate le informazioni sul nodo e l'assegnazione di sottocampi del nodo.
- Se il failover è prodotto da un servizio arrestato, raccogliere:
- Registri di sistema del Visualizzatore eventi
- Registri applicazioni Visualizzatore eventi
- Registri arrestati dal servizio.
 Feedback
Feedback