Analisi dell'impatto delle interruzioni Ceph per StarOS VNF
Opzioni per il download
Linguaggio senza pregiudizi
La documentazione per questo prodotto è stata redatta cercando di utilizzare un linguaggio senza pregiudizi. Ai fini di questa documentazione, per linguaggio senza di pregiudizi si intende un linguaggio che non implica discriminazioni basate su età, disabilità, genere, identità razziale, identità etnica, orientamento sessuale, status socioeconomico e intersezionalità. Le eventuali eccezioni possono dipendere dal linguaggio codificato nelle interfacce utente del software del prodotto, dal linguaggio utilizzato nella documentazione RFP o dal linguaggio utilizzato in prodotti di terze parti a cui si fa riferimento. Scopri di più sul modo in cui Cisco utilizza il linguaggio inclusivo.
Informazioni su questa traduzione
Cisco ha tradotto questo documento utilizzando una combinazione di tecnologie automatiche e umane per offrire ai nostri utenti in tutto il mondo contenuti di supporto nella propria lingua. Si noti che anche la migliore traduzione automatica non sarà mai accurata come quella fornita da un traduttore professionista. Cisco Systems, Inc. non si assume alcuna responsabilità per l’accuratezza di queste traduzioni e consiglia di consultare sempre il documento originale in inglese (disponibile al link fornito).
Sommario
Introduzione
In questo documento viene descritto come StarOS VNF, in esecuzione su Cisco Virtualized Infrastructure Manager (VIM), subisce un impatto quando il servizio di storage Ceph è compromesso e cosa è possibile fare per mitigarne l'impatto. Si basa sul presupposto che Cisco VIM sia utilizzato come infrastruttura, ma la stessa teoria può essere applicata a qualsiasi ambiente Openstack.
Prerequisito
Requisiti
Cisco raccomanda la conoscenza dei seguenti argomenti:
- Cisco StarOS
- Cisco VIM
- Openstack
- Ceph
Componenti usati
Le informazioni fornite in questo documento si basano sulle seguenti versioni software e hardware:
- StarOS: 21.16.c9
- Cisco VIM: 3.2.2 (Openstack Queens)
Le informazioni discusse in questo documento fanno riferimento a dispositivi usati in uno specifico ambiente di emulazione. Su tutti i dispositivi menzionati nel documento la configurazione è stata ripristinata ai valori predefiniti. Se la rete è operativa, valutare attentamente eventuali conseguenze derivanti dall'uso dei comandi.
Abbreviazioni
| Cisco VIM | Cisco Virtualized Infrastructure Manager |
| VNF | Funzione di rete virtuale |
| Ceph OSD | Ceph Object Storage Daemon |
| StarOS | Sistema operativo per soluzione Cisco Mobile Packet Core |
Ceph in Cisco VIM
Questa immagine è tratta dalla Cisco VIM Administrator Guide. Cisco VIM utilizza Ceph come back-end di archiviazione.
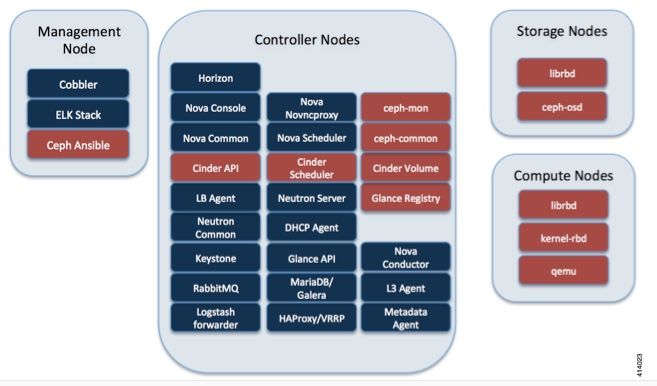
La tecnologia Ceph supporta lo storage di blocchi e oggetti ed è quindi utilizzata per archiviare immagini VM e volumi che possono essere collegati alle VM. I servizi OpenStack che dipendono dal back-end di storage includono:
- Glance (OpenStack image service): utilizza Ceph per archiviare le immagini.
- Cinder (OpenStack storage service): utilizza Ceph per creare volumi che possono essere collegati alle VM.
- Nova (OpenStack compute service) - Utilizza Ceph per connettersi ai volumi creati da Cinder.
In molti casi, viene creato un volume in Ceph per /flash e /hd-raid per StarOS VNF, come nell'esempio riportato di seguito.
openstack volume create --image `glance image-list | grep up-image | awk '{print $2}'` --size 16 --type LUKS up1-flash-boot
openstack volume create --size 20 --type LUKS up1-hd-raid
Elementi fondamentali del meccanismo di monitoraggio in seno al CEPPH
Ecco la spiegazione del documento Ceph riguardo al monitoraggio:
Ogni Daemon Ceph OSD controlla il battito cardiaco degli altri Daemon Ceph OSD a intervalli casuali inferiori a ogni 6 secondi. Se un daemon Ceph OSD adiacente non mostra un heartbeat entro un periodo di tolleranza di 20 secondi, il daemon Ceph OSD potrebbe considerare inattivo il daemon Ceph OSD adiacente e restituirlo a un Ceph Monitor, che aggiorna la mappa del cluster di Ceph. Per impostazione predefinita, due daemon Ceph OSD di host diversi devono segnalare ai Ceph Monitor che un altro daemon Ceph OSD è inattivo prima che i Ceph Monitor riconoscano che il daemon Ceph OSD segnalato è inattivo.
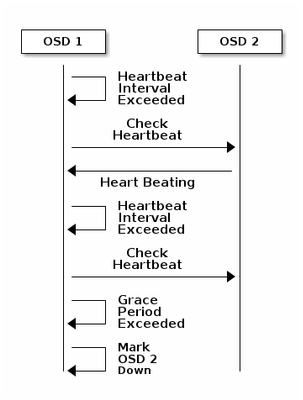
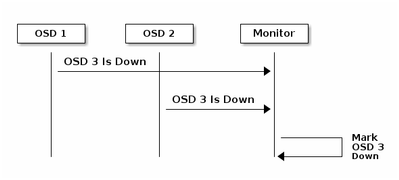
In generale, sono necessari circa 20 secondi per rilevare l'OSD e aggiornare la mappa cluster di Ceph, solo dopo che questa VNF può utilizzare un nuovo OSD. Durante questo periodo di tempo il disco, I/O è bloccato.
Impatto del blocco dell'I/O su StarOS VNF
Se l'I/O del disco è bloccato per più di 120 secondi, StarOS VNF si riavvia. È disponibile un controllo specifico per i processi xfssyncd/md0 e xfs_db correlati al riavvio intenzionale di I/O su disco e StarOS quando rileva un blocco su questi processi per più di 120 secondi.
Registro console di debug StarOS:
[ 1080.859817] INFO: task xfssyncd/md0:25787 blocked for more than 120 seconds.
[ 1080.862844] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
[ 1080.866184] xfssyncd/md0 D ffff880c036a8290 0 25787 2 0x00000000
[ 1080.869321] ffff880aacf87d30 0000000000000046 0000000100000a9a ffff880a00000000
[ 1080.872665] ffff880aacf87fd8 ffff880c036a8000 ffff880aacf87fd8 ffff880aacf87fd8
[ 1080.876100] ffff880c036a8298 ffff880aacf87fd8 ffff880c0f2f3980 ffff880c036a8000
[ 1080.879443] Call Trace:
[ 1080.880526] [<ffffffff8123d62e>] ? xfs_trans_commit_iclog+0x28e/0x380
[ 1080.883288] [<ffffffff810297c9>] ? default_spin_lock_flags+0x9/0x10
[ 1080.886050] [<ffffffff8157fd7d>] ? _raw_spin_lock_irqsave+0x4d/0x60
[ 1080.888748] [<ffffffff812301b3>] _xfs_log_force_lsn+0x173/0x2f0
[ 1080.891375] [<ffffffff8104bae0>] ? default_wake_function+0x0/0x20
[ 1080.894010] [<ffffffff8123dc15>] _xfs_trans_commit+0x2a5/0x2b0
[ 1080.896588] [<ffffffff8121ff64>] xfs_fs_log_dummy+0x64/0x90
[ 1080.899079] [<ffffffff81253cf1>] xfs_sync_worker+0x81/0x90
[ 1080.901446] [<ffffffff81252871>] xfssyncd+0x141/0x1e0
[ 1080.903670] [<ffffffff81252730>] ? xfssyncd+0x0/0x1e0
[ 1080.905871] [<ffffffff81071d5c>] kthread+0x8c/0xa0
[ 1080.908815] [<ffffffff81003364>] kernel_thread_helper+0x4/0x10
[ 1080.911343] [<ffffffff81580805>] ? restore_args+0x0/0x30
[ 1080.913668] [<ffffffff81071cd0>] ? kthread+0x0/0xa0
[ 1080.915808] [<ffffffff81003360>] ? kernel_thread_helper+0x0/0x10
[ 1080.918411] **** xfssyncd/md0 stuck, resetting card
Ma non è limitato al timer di 120 secondi; se l'I/O del disco viene bloccato per un certo periodo, anche se meno di 120 secondi, il VNF può riavviarsi per una serie di motivi. L'output riportato di seguito è un esempio di riavvio causato da un problema di I/O del disco, a volte un arresto anomalo continuo delle attività StarOS e così via. Dipende dalla tempistica dell'I/O su disco attivo rispetto ai problemi di storage.
[ 2153.370758] Hangcheck: hangcheck value past margin!
[ 2153.396850] ata1.01: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x6 frozen
[ 2153.396853] ata1.01: failed command: WRITE DMA EXT
--- skip ---
SYSLINUX 3.53 0x5d037742 EBIOS Copyright (C) 1994-2007 H. Peter Anvin
Fondamentalmente, un I/O a lungo blocco può essere considerato un problema critico per StarOS VNF e deve essere minimizzato il più possibile.
Scenari di I/O con blocchi lunghi
In base alla ricerca effettuata in più installazioni presso i clienti e a test di laboratorio, sono stati identificati due scenari principali che possono causare un lungo blocco di I/O in Ceph.
Meccanismo timer ritardo
Tra i servizi OSD è presente un meccanismo di heartbeat che consente di rilevare l'arresto dei servizi OSD. In base al valore osd_heartbeat_trace (20 secondi per impostazione predefinita), l'OSD viene rilevato come non riuscito.
Esiste inoltre un meccanismo di timer lento: in caso di fluttuazione o flap nello stato OSD, il timer di tolleranza viene regolato automaticamente (allungato). In questo modo il valore di osd_heartbeat_trace potrebbe aumentare.
In una situazione normale, la grazia del battito cardiaco è di 20 secondi
2019-01-09 16:58:01.715155 mon.ceph-XXXXX [INF] osd.2 failed (root=default,host=XXXXX) (2 reporters from different host after 20.000047 >= grace 20.000000)
Ma dopo più flap di rete di un nodo di storage, diventa un valore maggiore.
2019-01-10 16:44:15.140433 mon.ceph-XXXXX [INF] osd.2 failed (root=default,host=XXXXX) (2 reporters from different host after 256.588099 >= grace 255.682576)
Nell'esempio precedente, sono necessari 256 secondi per rilevare che l'OSD è inattivo.
Errore hardware scheda RAID
Ceph potrebbe non essere in grado di rilevare tempestivamente i guasti hardware della scheda RAID. Il guasto della scheda RAID si traduce in una sorta di blocco dell'OSD. In questo caso, dopo alcuni minuti viene rilevato che l'OSD è inattivo e ciò è sufficiente per riavviare StarOS VNF.
Quando la scheda RAID si blocca, alcuni core della CPU assumono il 100% dello stato operativo.
%Cpu20 : 2.6 us, 7.9 sy, 0.0 ni, 0.0 id, 89.4 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu21 : 0.0 us, 0.3 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu22 : 31.3 us, 5.1 sy, 0.0 ni, 63.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu23 : 0.0 us, 0.0 sy, 0.0 ni, 28.1 id, 71.9 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu24 : 0.0 us, 0.0 sy, 0.0 ni, 0.0 id,100.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu25 : 0.0 us, 0.0 sy, 0.0 ni, 0.0 id,100.0 wa, 0.0 hi, 0.0 si, 0.0 st
Inoltre, mangia tutti i core della CPU gradualmente e anche l'OSD si abbassa gradualmente con un certo intervallo di tempo.
2019-01-01 17:08:05.267629 mon.ceph-XXXXX [INF] Marking osd.2 out (has been down for 602 seconds)
2019-01-01 17:09:25.296955 mon.ceph-XXXXX [INF] Marking osd.4 out (has been down for 603 seconds)
2019-01-01 17:11:10.351131 mon.ceph-XXXXX [INF] Marking osd.7 out (has been down for 604 seconds)
2019-01-01 17:16:40.426927 mon.ceph-XXXXX [INF] Marking osd.10 out (has been down for 603 seconds)
In parallelo, vengono rilevate richieste lente in ceph.log.
2019-01-01 16:57:26.743372 mon.XXXXX [WRN] Health check failed: 1 slow requests are blocked > 32 sec. Implicated osds 2 (REQUEST_SLOW)
2019-01-01 16:57:35.129229 mon.XXXXX [WRN] Health check update: 3 slow requests are blocked > 32 sec. Implicated osds 2,7,10 (REQUEST_SLOW)
2019-01-01 16:57:38.055976 osd.7 osd.7 [WRN] 1 slow requests, 1 included below; oldest blocked for > 30.216236 secs
2019-01-01 16:57:39.048591 osd.2 osd.2 [WRN] 1 slow requests, 1 included below; oldest blocked for > 30.635122 secs
-----skip-----
2019-01-01 17:06:22.124978 osd.7 osd.7 [WRN] 78 slow requests, 1 included below; oldest blocked for > 554.285311 secs
2019-01-01 17:06:25.114453 osd.4 osd.4 [WRN] 19 slow requests, 1 included below; oldest blocked for > 546.221508 secs
2019-01-01 17:06:26.125459 osd.7 osd.7 [WRN] 78 slow requests, 1 included below; oldest blocked for > 558.285789 secs
2019-01-01 17:06:27.125582 osd.7 osd.7 [WRN] 78 slow requests, 1 included below; oldest blocked for > 559.285915 secs
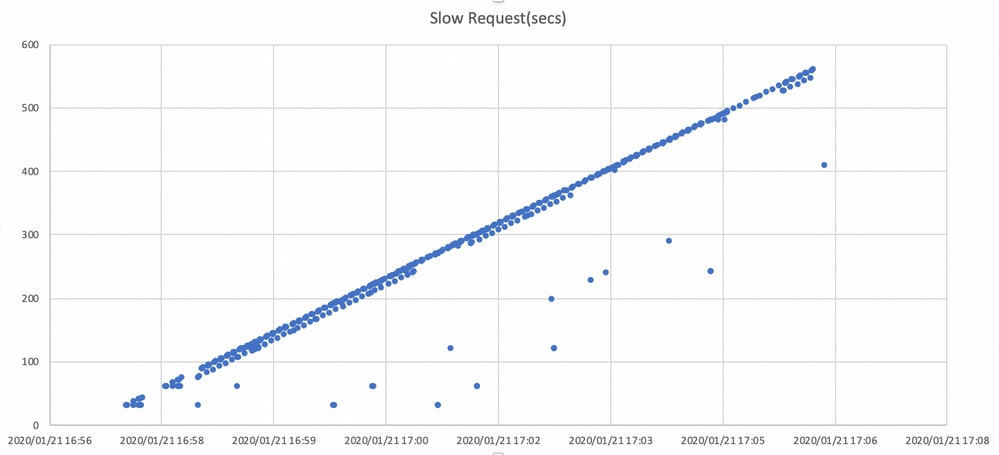
Il grafico mostra la durata del blocco delle richieste di I/O con una cronologia. Il grafico viene creato tracciando i log delle richieste lente in ceph.log. Ciò dimostra che il tempo di blocco sta diventando sempre più lungo.
Come mitigare l'impatto?
Sposta su disco locale da archivio cache
Il modo più semplice per ridurre l'impatto consiste nel passare a un disco locale dallo storage Ceph. StarOS utilizza 2 dischi, /flash e /hd-raid, è possibile spostare solo /flash sul disco locale, rendendo StarOS VNF più robusto per i problemi Ceph. Il lato negativo dell'utilizzo di storage condiviso, ad esempio Ceph, è che tutto il VNF che lo utilizza viene influenzato contemporaneamente quando si verifica un problema. Utilizzando il disco locale, l'impatto del problema di storage può essere ridotto al minimo per consentire l'esecuzione di VNF solo sul nodo interessato. Inoltre, gli scenari menzionati nella sezione precedente sono applicabili solo a Ceph e non al disco locale. Ma il lato opposto del disco locale è che il contenuto del disco, come immagine StarOS, configurazione, file core, record di fatturazione, non può essere mantenuto quando la VM viene ridistribuita. Può influire anche sul meccanismo di riparazione automatica VNF.
Ottimizzazione della configurazione della cache
Dal punto di vista di StarOS VNF, si consigliano i seguenti nuovi parametri di Ceph per ridurre al minimo il tempo di blocco I/O sopra indicato.
<impostazioni predefinite>
"mon_osd_adjust_heartbeat_grace": "true",
"osd_client_watch_timeout": "30",
"osd_max_markdown_count": "5",
"osd_heartbeat_grace": "20",
<nuove impostazioni>
"mon_osd_adjust_heartbeat_grace": "false",
"osd_client_watch_timeout": "10",
"osd_max_markdown_count": "1",
"osd_heartbeat_grace": "10",
Esso comprende:
- Il meccanismo del timer ritardato è disattivato, nessuna regolazione automatica
- Il tempo di tolleranza per il battito cardiaco è ridotto
- L'OSD viene contrassegnato immediatamente come non attivo (per impostazione predefinita 5 volte negli ultimi 600 secondi)
I nuovi parametri vengono testati in laboratorio, il tempo di rilevamento per l'OSD è ridotto a circa meno di 10 secondi, inizialmente era di circa 30 secondi con la configurazione predefinita di Ceph.
Problema hardware scheda RAID monitor
Per lo scenario hardware della scheda RAID, può essere ancora difficile rilevare in modo tempestivo la natura del problema, in quanto crea una situazione in cui l'OSD funziona in modo intermittente mentre l'I/O è bloccato. Non esiste un'unica soluzione per questo problema, ma si consiglia di monitorare il log dell'hardware del server per rilevare eventuali guasti della scheda RAID, o il log di richiesta lento in ceph.log da parte di uno script e intraprendere alcune azioni, come ad esempio disattivare in modo proattivo l'OSD interessato.
Regolazione CEPH_OSD_RESEREVED_PCORES
Ciò non è correlato agli scenari citati, ma se si verifica un problema con le prestazioni di Ceph a causa di operazioni di I/O pesanti, l'aumento del valore di CEPH_OSD_RESEREVED_PCORES può migliorare le prestazioni di I/O di Ceph. Per impostazione predefinita, CEPH_OSD_RESEREVED_PCORES su Cisco VIM è configurato come 2 e può essere aumentato.
Contributo dei tecnici Cisco
- Tomonobu OkadaCisco TAC Engineer
- Satoshi KinoshitaCisco TAC Engineer
 Feedback
Feedback