Introduction
Ce document décrit le fonctionnement de la haute disponibilité de la messagerie instantanée et de la présence (IM&P) dans un environnement d'entreprise IM&P et comment la dépanner.
Conditions préalables
Exigences
Cisco vous recommande de prendre connaissance des rubriques suivantes :
- Cisco Unified IM&P
- Clients Cisco Jabber
Composants utilisés
- Cisco Unified IM&P 10.0 et versions ultérieures
- Clients Cisco Jabber 9.6 et versions ultérieures
Les informations de ce document ont été créées à partir des composants d’un environnement de travaux pratiques spécifique. Tous les composants utilisés dans ce document ont démarré avec une configuration effacée (par défaut). Si votre réseau est en ligne, assurez-vous de bien comprendre l’incidence possible des commandes.
Messagerie instantanée et haute disponibilité de présence (HA)
Le serveur de services de messagerie instantanée et de présence offre une haute disponibilité ou une redondance sous la forme de groupes de serveurs logiques dans la configuration CUCM. Cette configuration est transmise à IM and Presence, puis utilisée pour permettre la redondance en cas de panne du serveur ou du service IM and Presence. Lorsqu'un événement de haute disponibilité se produit, les sessions de l'utilisateur final sont déplacées du serveur défaillant vers la sauvegarde. Une fois le serveur restauré à l'état normal, les sessions utilisateur sont automatiquement ou manuellement redéplacées par l'administrateur.
Configuration du groupe de redondance
Le groupe de redondance est la paire de serveurs logiques qui permet l'affectation d'un serveur au sous-cluster IM and Presence, ainsi que la configuration de HA. Pour accéder à cette partie de la configuration, recherchez-la sur la page Web du serveur CUCM.
Système > Groupes de redondance de présence
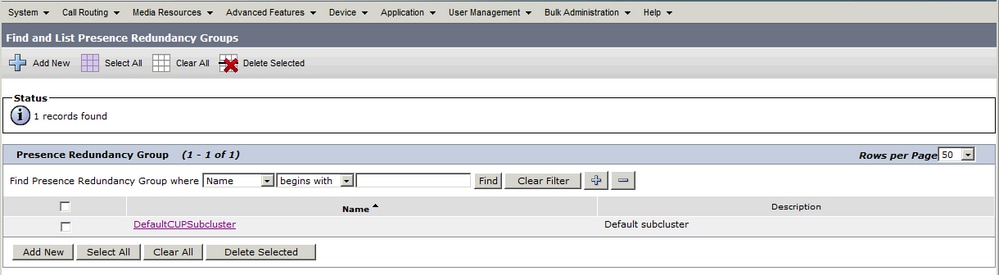
Lorsque l'administrateur ajoute le serveur de publication IM&P à la configuration System > Server sur CUCM et que le serveur IM&P est enregistré, le groupe de redondance DefaultCUPSubCluster est créé avec le serveur de publication qui lui est affecté.
Une fois créé, le groupe de redondance se présente comme suit :
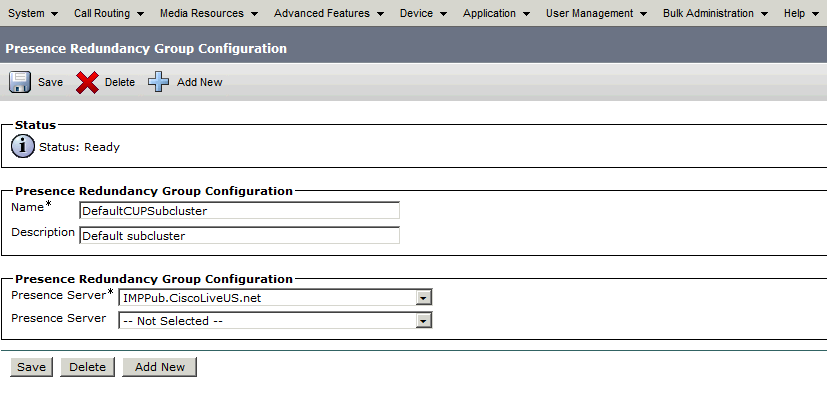
Ce groupe de redondance se traduit par le sous-cluster IM and Presence. Dans l'état actuel de la configuration du groupe de redondance dans CUCM, voici à quoi ressemblerait la page Web de la topologie de cluster de présence et de messagerie instantanée :
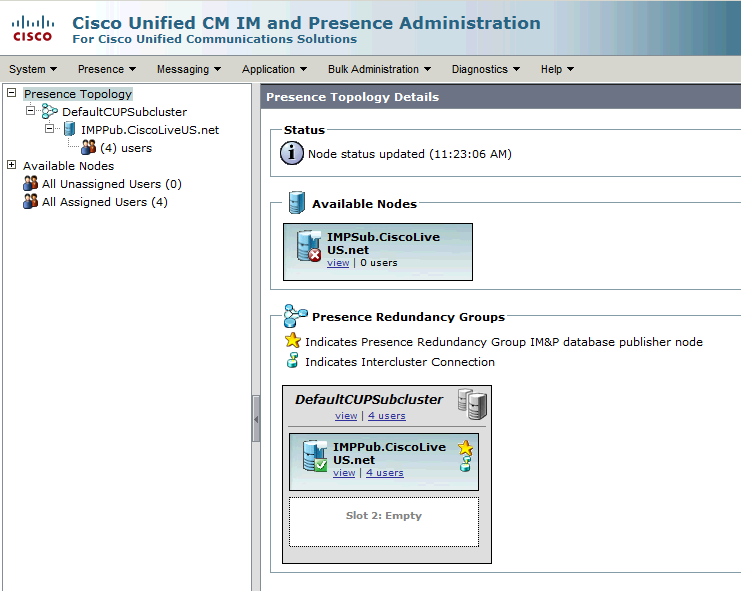
Vous voyez que le serveur de publication IM&P est affecté au sous-cluster DefaultCUPSubcluster et que le serveur Abonné ne l'est pas. En effet, le serveur de l'abonné IM&P n'est pas affecté au groupe de redondance dans la configuration CUCM.
Attribuez l'abonné au groupe de redondance.
Afin d'attribuer le serveur d'abonné au groupe de redondance, choisissez simplement le serveur d'abonné dans le menu déroulant, puis enregistrez la modification de configuration.
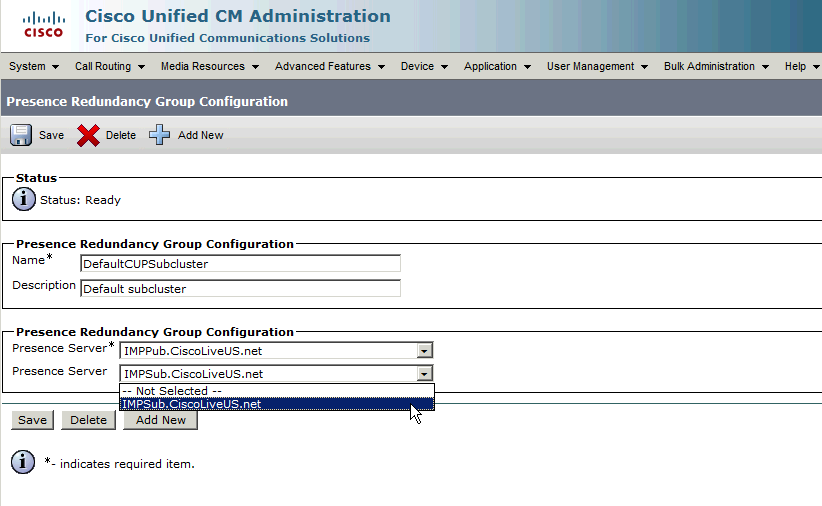
Une fois l'abonné IM&P ajouté au groupe de redondance :
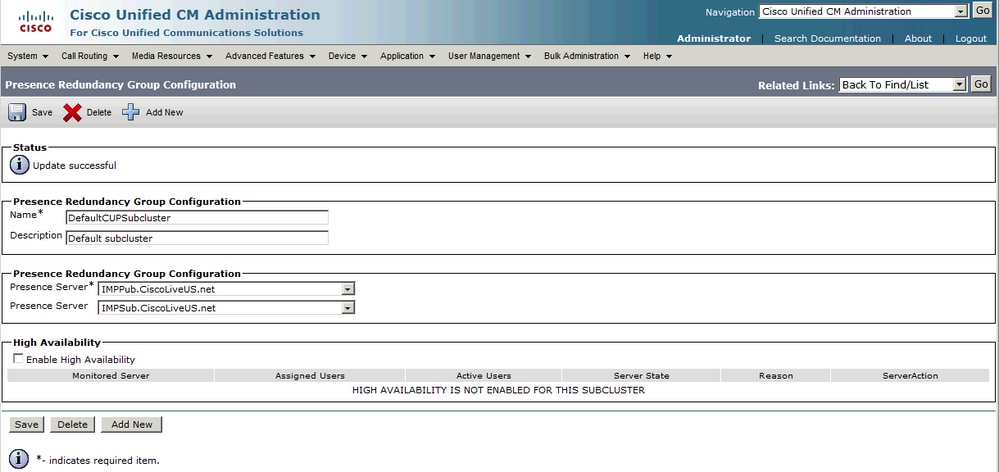
Après l'ajout du noeud secondaire (l'abonné), vous voyez que l'option Haute disponibilité peut être sélectionnée. Pour activer la haute disponibilité, il vous suffit de cocher la case Enable High Availability et d'enregistrer la modification de configuration.
Une fois la haute disponibilité activée :
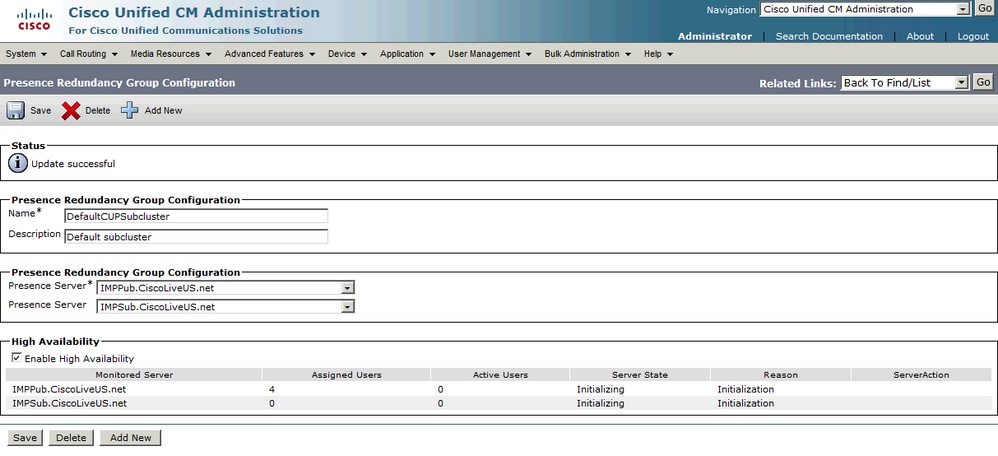
La page actualise ensuite automatiquement l'état et la raison du serveur. Lorsque le serveur est dans un état d'initialisation, cela signifie que les deux serveurs peuvent communiquer. Les serveurs vérifient ensuite l'état du service avant que l'état ne passe à l'état Normal. Si les deux serveurs peuvent se connecter l'un à l'autre et que tous les services surveillés sont actifs sur les deux, vous obtiendrez un état Normal-Normal. Cela signifie que tous les services surveillés sont actifs sur les serveurs IM&P.
État du groupe de redondance normal-normal :
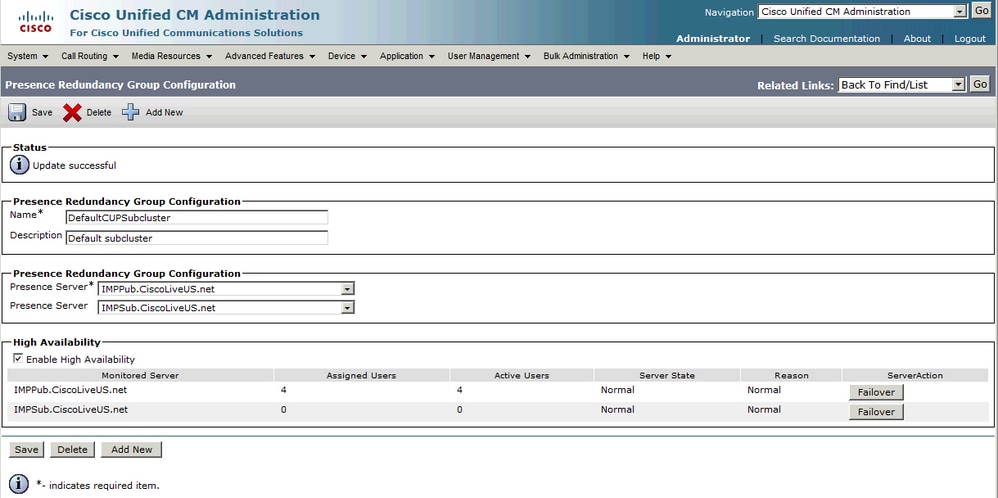
État de haute disponibilité normal-normal dans la page Topologie IM&P :
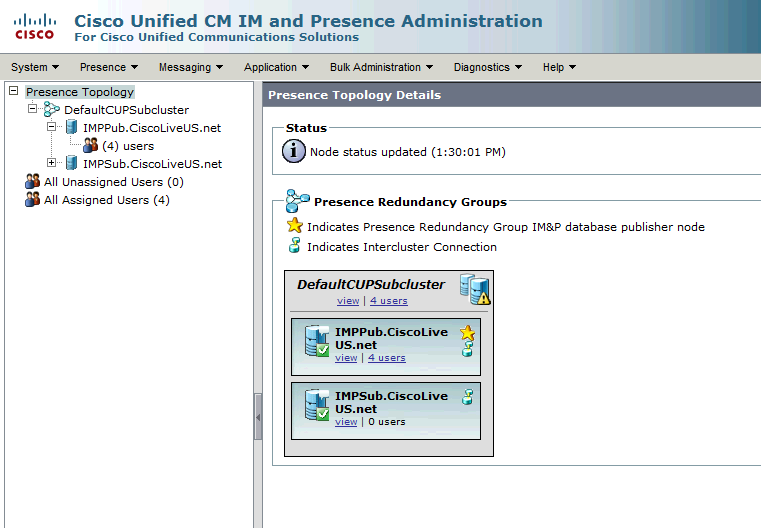
Services de messagerie instantanée et de présence surveillés
Étant donné que vous pouvez avoir différents modèles de déploiement : messagerie instantanée uniquement, messagerie instantanée avec fédération SIP/XMPP, messagerie instantanée avec conformité, messagerie instantanée avec conversation permanente, contrôle d'appel à distance uniquement, etc., la liste réelle de ces processus à surveiller est dynamique. Par défaut, ces éléments sont toujours surveillés lorsque la haute disponibilité est activée :
- base de données IDS
- Presence Engine (si activé)
- Routeur XCP
Le Gestionnaire de récupération du serveur vérifie si la conformité (Message Archiver), la conversation permanente (Text Conference Manager), la fédération SIP (SIP Federation Connection Manager), la fédération XMPP (XMPP Federation Connection Manager) sont configurées et activées.
S'ils sont configurés et activés, le Gestionnaire de récupération du serveur (SRM) surveille également ces services.
Attention : avant de redémarrer un ou plusieurs des services surveillés, vous devez désactiver la haute disponibilité à partir des groupes de redondance de présence sur le serveur CUCM. Il en va de même lorsqu'un redémarrage d'un ou de plusieurs noeuds IM&P est effectué.
Processus de basculement utilisateur
Lorsqu'un basculement a lieu (automatique ou manuel), le point principal à retenir est que le compte d'utilisateur n'est pas déplacé d'un serveur à l'autre, mais que seule la session utilisateur dans Presence Engine est déplacée. Dans les versions antérieures à 10 de IM and Presence, l'affectation d'utilisateur a été déplacée d'un serveur à l'autre. Ce déplacement de l'utilisateur a coûté très cher aux ressources du serveur, et a ajouté à la charge qui se trouvait sur le serveur. Dans la version 10.X et les versions ultérieures, l'utilisateur reste hébergé sur le serveur auquel il est affecté et la session d'utilisateur back-end dans Presence Engine est déplacée du noeud défaillant vers le noeud fonctionnel. L'utilisateur n'a pas besoin de quitter Jabber et de se reconnecter lorsque la modification se produit avec le Gestionnaire de récupération du serveur (SRM).
Temporisateur de reconnexion du client Jabber
Pour que la session utilisateur soit entièrement active sur le noeud IM&P secondaire après un événement de basculement, l'utilisateur doit tenter de se connecter à ce serveur via SOAP (Client Profile Agent). Cela se produit automatiquement avec le mot de passe à usage unique transmis à partir de la base de données IMDB. Les connexions étant extrêmement coûteuses pour les ressources du serveur IM and Presence, il doit exister un moyen de limiter les connexions lorsqu'un événement de basculement se produit. Cette limitation ou cette mémoire tampon permet à tous les utilisateurs de se connecter au noeud secondaire sans interruption de service pour les utilisateurs sur le noeud secondaire. Les mécanismes utilisés pour limiter les connexions des utilisateurs sont les paramètres de service Client Re-Login Lower Limit et Client Re-Login Upper Limit Server Recovery Manager (SRM).
Client Re-Login Lower Limit : paramètre définissant la durée minimale (en secondes) pendant laquelle le client Jabber attend avant de tenter de se connecter au serveur secondaire en cas d'événement HA.
Limite supérieure de reconnexion du client - paramètre qui définit la durée maximale (en secondes) pendant laquelle le client Jabber attend avant de tenter de se connecter au serveur secondaire en cas d'événement de haute disponibilité.
Le client Jabber reçoit ces paramètres lors de la connexion au serveur et met en cache les valeurs pour une utilisation ultérieure. Lorsque vous recevez un événement haute disponibilité du serveur IM&P, le client choisit un nombre aléatoire de secondes entre les limites supérieure et inférieure et attend ce délai avant que le client Jabber ne tente de se connecter au serveur secondaire. Une fois le délai expiré, le client tente alors de se connecter au noeud secondaire via le protocole SOAP.
Types de secours IM et Presence
En cas de basculement de l'utilisateur, il doit y avoir un secours de l'utilisateur lorsque le service est restauré sur le serveur problématique. Il existe deux types de reprise de serveur :
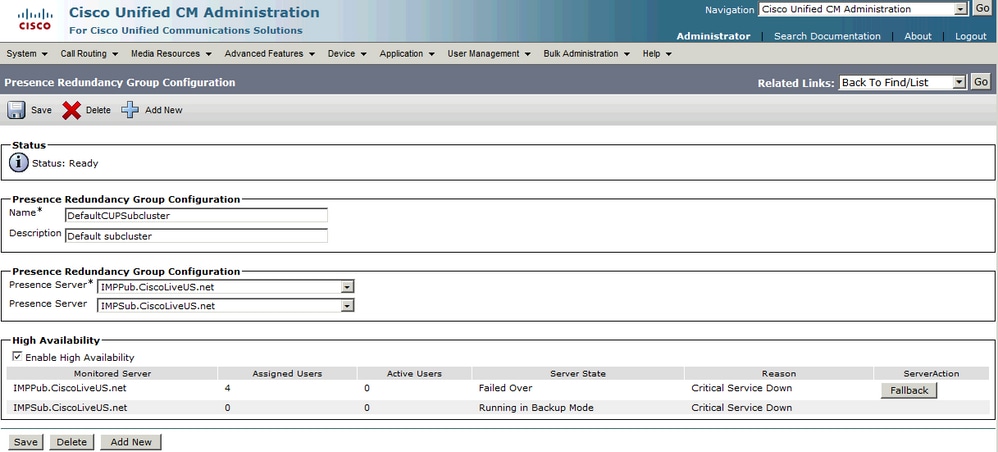
Reprise manuelle
La reprise manuelle (configuration par défaut pour Server Recovery Manager) a lieu lorsque le service a été restauré et que le groupe de redondance autorise le bouton de reprise. Lorsque ce bouton est sélectionné, les sessions utilisateur qui ont été déplacées vers le noeud secondaire sont déplacées vers leur noeud d'accueil. Le client Jabber applique ensuite les limites supérieure et inférieure de reconnexion pour la reprise.
Repli Automatique
La reprise automatique a lieu lorsque le serveur surveille les services et que le service Server Recovery Manager (SRM) rétablit automatiquement les utilisateurs sur leurs noeuds d'accueil. La clé de cette configuration est que le service Server Recovery Manager (SRM) attend 30 minutes qu'un service/serveur défaillant reste actif avant de lancer un secours automatique. Une fois cette durée de disponibilité de 30 minutes établie, les sessions utilisateur sont redirigées vers leurs noeuds d'accueil. Le client Jabber applique ensuite les limites supérieure et inférieure de reconnexion pour la reprise.

Remarque : la reprise automatique n'est pas la configuration par défaut, mais elle peut être activée. Pour activer la reprise automatique, attribuez la valeur True au paramètre Enable Automatic Fallback dans les paramètres du service Server Recovery Manager.
Dépannage
Cette section fournit les informations que vous pouvez utiliser afin de dépanner votre configuration.
Lors du dépannage de la haute disponibilité sur le serveur de services IM&P, vous devez tenir compte de deux minuteurs importants.
- Les serveurs échangent 4 messages de veille toutes les 60 secondes. En l'absence de réponse après les 60 secondes, le gestionnaire de récupération des services Cisco (SRM) considère que le noeud qui ne répond pas est hors ligne et déclenche une commande de basculement. Comme le montre l'extrait suivant, la dernière pulsation a eu lieu il y a 62 secondes.
2021-05-13 02:48:48,244 INFO[HS]rsrm.RsrmHeartBeatHandler - RsrmHeartBeatHandler: peer down, time since last heartbeat[s]= 62
2021-05-13 02:48:48,244 INFO [HS] rsrm.RsrmAutomaticFallback - RsrmAutomaticFallback: peer states vector changed to [Normal,Running in Backup Mode]
Conseil : dans ce scénario, si vous avez détecté une certaine latence sur votre réseau, il est recommandé d'augmenter le délai d'expiration du battement de coeur de 60 à 90 secondes.
Accédez à la page Web CUCM Administration > System > Service parameters configuration > Select the IM&P Server> Select Cisco Recovery ManagerSettings. Dans le délai d'attente Keep Alive (Heartbeat), augmentez le nombre à 90 secondes.
- Le serveur de l'abonné IM&P attend 90 secondes. S'il détecte qu'un ou plusieurs des services surveillés sont en panne, le serveur Abonné prend le relais.
Journaux à collecter pour le dépannage
- Le Gestionnaire de restauration du serveur (SRM) consigne les événements avant et après le basculement (niveau de débogage si possible).
- Le résultat de la commande via l'interface de ligne de commande IM&P run sql select * from enterprisesubcluster.
- La table des sous-clusters d'entreprise dans IM&P héberge la configuration du groupe de redondance.
- Le résultat de la commande via l'interface de ligne de commande IM&P run sql select * from enterprisenode.
- La table enterprisenode affiche les informations de noeud et l'affectation de sous-cluster du noeud.
- Si le basculement est produit par un service en cours d'arrêt, collectez :
- Journaux système de l'Observateur
- Journaux d'application Observateur d'événements
- Journaux du service qui sont arrêtés.
 Commentaires
Commentaires