Analyse d'impact des pannes Ceph pour StarOS VNF
Options de téléchargement
-
ePub (279.1 KB)
Consulter à l’aide de différentes applications sur iPhone, iPad, Android ou Windows Phone -
Mobi (Kindle) (179.5 KB)
Consulter sur un appareil Kindle ou à l’aide d’une application Kindle sur plusieurs appareils
Langage exempt de préjugés
Dans le cadre de la documentation associée à ce produit, nous nous efforçons d’utiliser un langage exempt de préjugés. Dans cet ensemble de documents, le langage exempt de discrimination renvoie à une langue qui exclut la discrimination en fonction de l’âge, des handicaps, du genre, de l’appartenance raciale de l’identité ethnique, de l’orientation sexuelle, de la situation socio-économique et de l’intersectionnalité. Des exceptions peuvent s’appliquer dans les documents si le langage est codé en dur dans les interfaces utilisateurs du produit logiciel, si le langage utilisé est basé sur la documentation RFP ou si le langage utilisé provient d’un produit tiers référencé. Découvrez comment Cisco utilise le langage inclusif.
À propos de cette traduction
Cisco a traduit ce document en traduction automatisée vérifiée par une personne dans le cadre d’un service mondial permettant à nos utilisateurs d’obtenir le contenu d’assistance dans leur propre langue. Il convient cependant de noter que même la meilleure traduction automatisée ne sera pas aussi précise que celle fournie par un traducteur professionnel.
Contenu
Introduction
Ce document décrit comment la VNF de StarOS, qui s'exécute sur Cisco Virtualized Infrastructure Manager (VIM), est affectée en cas de défaillance du service de stockage Ceph, et ce qui peut être fait pour atténuer l'impact. Il est expliqué en supposant que Cisco VIM est utilisé comme infrastructure, mais la même théorie peut être appliquée à tout environnement Openstack.
Prérequis
Conditions requises
Cisco vous recommande de prendre connaissance des rubriques suivantes :
- Cisco StarOS
- VIM Cisco
- OpenStack
- Céphane
Composants utilisés
Les informations contenues dans ce document sont basées sur les versions de matériel et de logiciel suivantes :
- StarOS : 21.16.c9
- VIM Cisco : 3.2.2 (Reines d'Openstack)
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. Si votre réseau est en ligne, assurez-vous de bien comprendre l’incidence possible des commandes.
Abréviations
| VIM Cisco | Gestionnaire d'infrastructure virtualisée Cisco |
| VNF | Fonction de réseau virtuel |
| CEH OSD | Démon de stockage d'objets Ceph |
| StarOS | Système d'exploitation pour la solution Cisco Mobile Packet Core |
Ceph dans Cisco VIM
Cette image est tirée du Guide de l'administrateur Cisco VIM. Cisco VIM utilise Ceph comme serveur principal de stockage.
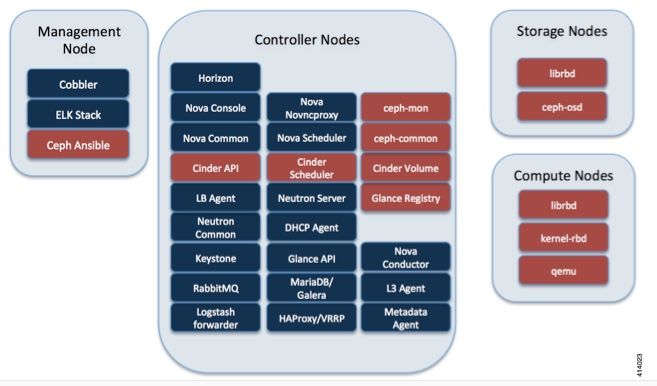
Ceph prend en charge le stockage des blocs et des objets et est donc utilisé pour stocker les images et les volumes de VM qui peuvent être attachés aux machines virtuelles. Plusieurs services OpenStack qui dépendent du serveur principal de stockage incluent :
- Glance (OpenStack image service) : utilise Ceph pour stocker des images.
- Cinder (OpenStack storage service) : utilise Ceph pour créer des volumes pouvant être attachés à des machines virtuelles.
- Nova (OpenStack computing service) : utilise Ceph pour se connecter aux volumes créés par Cinder.
Dans de nombreux cas, un volume est créé dans Ceph pour /flash et /hd-raid pour StarOS VNF comme dans l'exemple ici.
openstack volume create --image `glance image-list | grep up-image | awk '{print $2}'` --size 16 --type LUKS up1-flash-boot
openstack volume create --size 20 --type LUKS up1-hd-raid
Principes de base du mécanisme de surveillance de la CEPD
Voici l'explication du document de la CEPE concernant la surveillance :
Chaque démon d'OSD Ceph vérifie la pulsation des autres démons d'OSD Ceph à des intervalles aléatoires inférieurs à toutes les 6 secondes. Si un démon d’OSD de Ceph voisin n’affiche pas de pulsation dans un délai de grâce de 20 secondes, le démon d’OSD de Ceph peut considérer le démon d’OSD voisin comme désactivé et le rapporter à un Moniteur de Ceph, qui met à jour la carte de cluster de Ceph. Par défaut, deux démons d'OSD Ceph provenant de différents hôtes doivent signaler aux Moniteurs Ceph qu'un autre démon d'OSD Ceph est en panne avant que les Moniteurs Ceph reconnaissent que le démon d'OSD Ceph signalé est en panne.
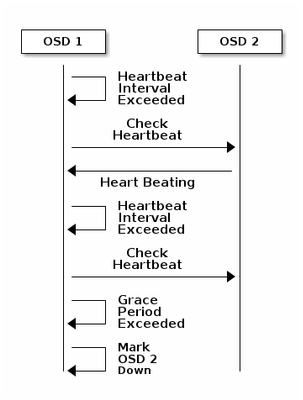
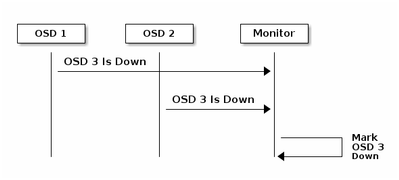
En règle générale, il faut environ 20 secondes pour détecter OSD et mettre à jour la carte de cluster Ceph, seulement après que ce VNF puisse utiliser un nouveau OSD. Pendant ce temps, le disque est bloqué.
Impact du blocage des E/S sur la VNF StarOS
Si les E/S du disque sont bloquées pendant plus de 120 secondes, StarOS VNF redémarre. Il y a une vérification spécifique pour les processus xfssyncd/md0 et xfs_db qui sont liés aux E/S de disque et StarOS redémarre intentionnellement lorsqu'il détecte un blocage sur ces processus pendant plus de 120 secondes.
Journal de console de débogage StarOS :
[ 1080.859817] INFO: task xfssyncd/md0:25787 blocked for more than 120 seconds.
[ 1080.862844] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
[ 1080.866184] xfssyncd/md0 D ffff880c036a8290 0 25787 2 0x00000000
[ 1080.869321] ffff880aacf87d30 0000000000000046 0000000100000a9a ffff880a00000000
[ 1080.872665] ffff880aacf87fd8 ffff880c036a8000 ffff880aacf87fd8 ffff880aacf87fd8
[ 1080.876100] ffff880c036a8298 ffff880aacf87fd8 ffff880c0f2f3980 ffff880c036a8000
[ 1080.879443] Call Trace:
[ 1080.880526] [<ffffffff8123d62e>] ? xfs_trans_commit_iclog+0x28e/0x380
[ 1080.883288] [<ffffffff810297c9>] ? default_spin_lock_flags+0x9/0x10
[ 1080.886050] [<ffffffff8157fd7d>] ? _raw_spin_lock_irqsave+0x4d/0x60
[ 1080.888748] [<ffffffff812301b3>] _xfs_log_force_lsn+0x173/0x2f0
[ 1080.891375] [<ffffffff8104bae0>] ? default_wake_function+0x0/0x20
[ 1080.894010] [<ffffffff8123dc15>] _xfs_trans_commit+0x2a5/0x2b0
[ 1080.896588] [<ffffffff8121ff64>] xfs_fs_log_dummy+0x64/0x90
[ 1080.899079] [<ffffffff81253cf1>] xfs_sync_worker+0x81/0x90
[ 1080.901446] [<ffffffff81252871>] xfssyncd+0x141/0x1e0
[ 1080.903670] [<ffffffff81252730>] ? xfssyncd+0x0/0x1e0
[ 1080.905871] [<ffffffff81071d5c>] kthread+0x8c/0xa0
[ 1080.908815] [<ffffffff81003364>] kernel_thread_helper+0x4/0x10
[ 1080.911343] [<ffffffff81580805>] ? restore_args+0x0/0x30
[ 1080.913668] [<ffffffff81071cd0>] ? kthread+0x0/0xa0
[ 1080.915808] [<ffffffff81003360>] ? kernel_thread_helper+0x0/0x10
[ 1080.918411] **** xfssyncd/md0 stuck, resetting card
Mais il n'est pas limité au compteur de 120 secondes, si les E/S disque sont bloquées pendant un certain temps, même moins de 120 secondes, VNF peut redémarrer pour diverses raisons. Le résultat ici est un exemple qui montre un redémarrage en raison d'un problème d'E/S disque, parfois d'un crash continu de tâche StarOS, etc. Cela dépend de la synchronisation des E/S du disque actif par rapport au problème de stockage.
[ 2153.370758] Hangcheck: hangcheck value past margin!
[ 2153.396850] ata1.01: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x6 frozen
[ 2153.396853] ata1.01: failed command: WRITE DMA EXT
--- skip ---
SYSLINUX 3.53 0x5d037742 EBIOS Copyright (C) 1994-2007 H. Peter Anvin
En gros, une longue E/S bloquante peut être considérée comme un problème critique pour StarOS VNF et doit être réduite autant que possible.
Scénarios d'E/S de blocage long
D'après les recherches effectuées sur plusieurs déploiements de clients et les tests en laboratoire, il existe deux scénarios principaux qui peuvent provoquer un blocage prolongé des E/S dans Ceph.
Mécanisme Laggy Timer
Il existe un mécanisme de pulsation entre les OSD, pour détecter l'OSD hors service. En fonction de la valeur osd_heartbeat_grace (20 secondes par défaut), l'OSD est détecté comme ayant échoué.
Et il y a un mécanisme de temporisation lagge, quand il y a une fluctuation ou un rabat dans l'état OSD le compteur de grâce est automatiquement ajusté (devient plus long). Cela peut rendre la valeur osd_heartbeat_grace plus grande.
Dans une situation normale, la grâce de pulsation est de 20 secondes
2019-01-09 16:58:01.715155 mon.ceph-XXXXX [INF] osd.2 failed (root=default,host=XXXXX) (2 reporters from different host after 20.000047 >= grace 20.000000)
Mais après plusieurs volets réseau d'un noeud de stockage, il devient une valeur plus importante.
2019-01-10 16:44:15.140433 mon.ceph-XXXXX [INF] osd.2 failed (root=default,host=XXXXX) (2 reporters from different host after 256.588099 >= grace 255.682576)
Dans l'exemple ci-dessus, il faut 256 secondes pour détecter OSD comme désactivé.
Panne matérielle de la carte RAID
Il se peut que Ceph ne soit pas en mesure de détecter rapidement les défaillances matérielles des cartes RAID. La défaillance de la carte RAID se termine par une sorte de blocage OSD. Dans ce cas, OSD down est détecté après quelques minutes, ce qui est suffisant pour redémarrer StarOS VNF.
Lorsque la carte RAID est suspendue, certains coeurs de CPU prennent 100 % sur l'état wa.
%Cpu20 : 2.6 us, 7.9 sy, 0.0 ni, 0.0 id, 89.4 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu21 : 0.0 us, 0.3 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu22 : 31.3 us, 5.1 sy, 0.0 ni, 63.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu23 : 0.0 us, 0.0 sy, 0.0 ni, 28.1 id, 71.9 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu24 : 0.0 us, 0.0 sy, 0.0 ni, 0.0 id,100.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu25 : 0.0 us, 0.0 sy, 0.0 ni, 0.0 id,100.0 wa, 0.0 hi, 0.0 si, 0.0 st
Et il consomme tous les coeurs de CPU progressivement et l'OSD est également réduit progressivement avec un certain décalage temporel.
2019-01-01 17:08:05.267629 mon.ceph-XXXXX [INF] Marking osd.2 out (has been down for 602 seconds)
2019-01-01 17:09:25.296955 mon.ceph-XXXXX [INF] Marking osd.4 out (has been down for 603 seconds)
2019-01-01 17:11:10.351131 mon.ceph-XXXXX [INF] Marking osd.7 out (has been down for 604 seconds)
2019-01-01 17:16:40.426927 mon.ceph-XXXXX [INF] Marking osd.10 out (has been down for 603 seconds)
En parallèle, des requêtes lentes sont détectées dans ceph.log.
2019-01-01 16:57:26.743372 mon.XXXXX [WRN] Health check failed: 1 slow requests are blocked > 32 sec. Implicated osds 2 (REQUEST_SLOW)
2019-01-01 16:57:35.129229 mon.XXXXX [WRN] Health check update: 3 slow requests are blocked > 32 sec. Implicated osds 2,7,10 (REQUEST_SLOW)
2019-01-01 16:57:38.055976 osd.7 osd.7 [WRN] 1 slow requests, 1 included below; oldest blocked for > 30.216236 secs
2019-01-01 16:57:39.048591 osd.2 osd.2 [WRN] 1 slow requests, 1 included below; oldest blocked for > 30.635122 secs
-----skip-----
2019-01-01 17:06:22.124978 osd.7 osd.7 [WRN] 78 slow requests, 1 included below; oldest blocked for > 554.285311 secs
2019-01-01 17:06:25.114453 osd.4 osd.4 [WRN] 19 slow requests, 1 included below; oldest blocked for > 546.221508 secs
2019-01-01 17:06:26.125459 osd.7 osd.7 [WRN] 78 slow requests, 1 included below; oldest blocked for > 558.285789 secs
2019-01-01 17:06:27.125582 osd.7 osd.7 [WRN] 78 slow requests, 1 included below; oldest blocked for > 559.285915 secs
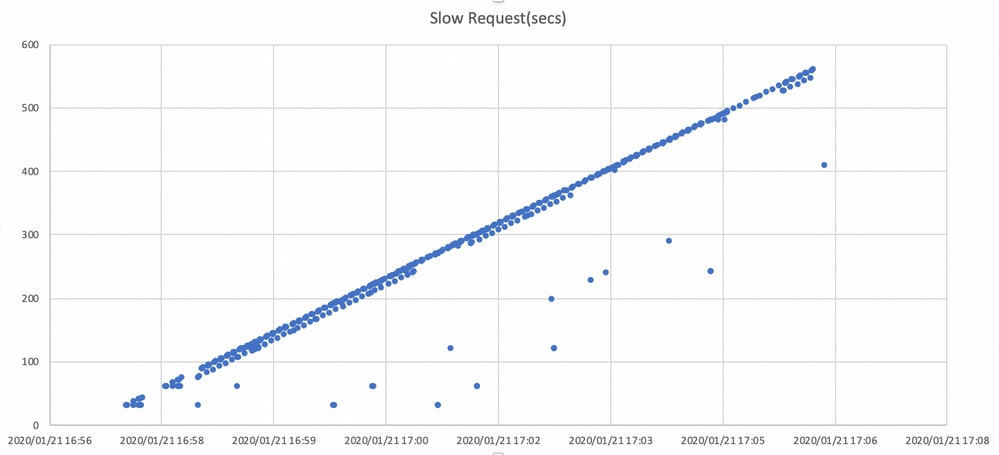
Le graphique ci-dessous indique la durée pendant laquelle les demandes d'E/S sont bloquées avec une chronologie. Le graphique est créé en traçant les journaux de requêtes lentes dans ceph.log. Cela montre que le temps de blocage s'allonge avec le temps.
Comment atténuer l'impact ?
Déplacer vers le disque local à partir du stockage Ceph
La façon la plus simple d'atténuer l'impact est de se déplacer vers un disque local à partir du stockage Ceph. StarOS utilise 2 disques, /flash et /hd-raid, il est possible de déplacer uniquement /flash vers le disque local, ce qui rend StarOS VNF plus robuste pour les problèmes Ceph. Le côté négatif de l'utilisation du stockage partagé tel que Ceph est que tous les VNF qui l'utilisent sont affectés en même temps lorsqu'un problème survient. En utilisant le disque local, l'impact du problème de stockage peut être réduit au minimum pour que VNF s'exécute sur le noeud affecté uniquement. Et les scénarios mentionnés dans la section précédente ne s'appliquent qu'à Ceph et ne s'appliquent donc pas au disque local. Mais le revers du disque local est que le contenu du disque, tel que l'image StarOS, la configuration, le fichier principal, l'enregistrement de facturation, ne peut pas être conservé lorsque la machine virtuelle est redéployée. Elle peut également avoir un impact sur le mécanisme de réparation automatique VNF.
Réglage de la configuration Ceph
Du point de vue de StarOS VNF, les nouveaux paramètres Ceph suivants sont recommandés pour minimiser le temps d'E/S de blocage mentionné ci-dessus.
<paramètres par défaut>
"mon_osd_adjust_heartbeat_grace": "true",
"osd_client_watch_timeout": "30",
"osd_max_markdown_count": "5",
"osd_heartbeat_grace": "20",
<nouveaux paramètres>
"mon_osd_adjust_heartbeat_grace": "false",
"osd_client_watch_timeout": "10",
"osd_max_markdown_count": "1",
"osd_heartbeat_grace": "10",
Il se compose des éléments suivants :
- Le mécanisme du compteur de laggie est désactivé, pas de réglage automatique
- Le temps de grâce des battements de coeur est raccourci
- L'OSD est immédiatement désactivé (par défaut, 5 fois au cours des 600 dernières secondes)
Les nouveaux paramètres sont testés dans un laboratoire, le temps de détection pour OSD down est réduit à environ moins de 10 secondes, il était à l'origine environ 30 secondes avec la configuration par défaut de Ceph.
Problème matériel de la carte RAID de surveillance
Pour le scénario matériel de la carte RAID, il peut être difficile de détecter rapidement la nature du problème, car cela crée une situation où l'OSD fonctionne de façon intermittente alors que les E/S sont bloquées. Il n'y a pas de solution unique pour cela, mais il est recommandé de surveiller le journal matériel du serveur pour la défaillance de la carte RAID, ou le journal de demande lente dans ceph.log par un script et d'entreprendre certaines actions telles que rendre l'OSD affecté désactivé de manière proactive.
Réglage CEPH_OSD_RESEREVED_PCORES
Ceci n'est pas lié aux scénarios mentionnés, mais s'il y a un problème avec les performances Ceph en raison d'une opération d'E/S intense, augmenter la valeur CEPH_OSD_RESEREVED_PCORES peut améliorer les performances d'E/S Ceph. Par défaut, CEPH_OSD_RESEREVED_PCORES sur Cisco VIM est configuré sur 2 et peut être augmenté.
Contribution d’experts de Cisco
- Tomonobu OkadaCisco TAC Engineer
- Satoshi KinoshitaCisco TAC Engineer
 Commentaires
CommentairesContacter Cisco
- Ouvrir un dossier d’assistance

- (Un contrat de service de Cisco est requis)