Introducción
Este documento describe cómo resolver el problema de uso de espacio de disco elevado para el sistema de archivos /dev/vda3 en RCM.
Prerequisites
Requirements
Cisco recomienda que tenga conocimiento de:
- Arquitectura y administración del sistema StarOS Control y User Plane Separation (CUPS).
- Comandos Linux/Unix básicos para monitorear el uso del sistema de archivos y del disco.
Componentes Utilizados
Este documento no tiene restricciones específicas en cuanto a versiones de software y de hardware.
La información que contiene este documento se creó a partir de los dispositivos en un ambiente de laboratorio específico. Todos los dispositivos que se utilizan en este documento se pusieron en funcionamiento con una configuración verificada (predeterminada). Si tiene una red en vivo, asegúrese de entender el posible impacto de cualquier comando.
Overview
En las implementaciones de Cisco Ultra Packet Core con separación del plano de usuario y control (CUPS), Redundancy Control Manager (RCM) desempeña un papel fundamental en las operaciones y la gestión del plano de control. La utilización estable del sistema de archivos en los nodos del RCM es importante para garantizar el funcionamiento sin problemas del registro, la supervisión y la administración de la sesión de suscriptor.
La alta utilización del espacio de disco en el sistema de archivos raíz (/dev/vda3) puede causar inestabilidad en el sistema, fallas en las escrituras de registro, o incluso reinicios del servicio si no se marca. En este artículo se describe el análisis, los pasos de solución de problemas y las medidas preventivas para hacer frente a la alta utilización del disco en los nodos RCM.
Análisis y observación
Durante el monitoreo, se encontró que el nodo RCM alcanzó un 72% de utilización en su sistema de archivos raíz.
Instantánea de uso de disco
df -kh
Filesystem Size Used Avail Use% Mounted on
tmpfs 6.3G 9.7M 6.3G 1% /run
/dev/vda3 39G 27G 11G 72% /
tmpfs 32G 4.0K 32G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/vda2 488M 48K 452M 1% /var/tmp
/dev/vda1 488M 76K 452M 1% /tmp
Tras una investigación más detallada, se observó que los registros de las revistas en /var/log/journal/ habían aumentado considerablemente. Los registros generados durante el mes de julio solamente representaron ~3 GB de espacio.
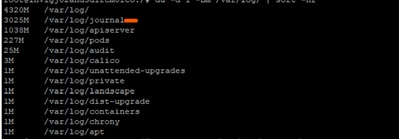
Proceso de Troubleshooting
Para controlar el uso del disco, se aplicaron los pasos de implementación de cambios necesarios:
Paso 1: Limpieza de registros antiguos mediante el vacío de diario
Conservar sólo las últimas 2 semanas de registros:
sudo journalctl --vacuum-time=2weeks
O limite el tamaño del diario (por ejemplo, conserve sólo 600 MB):
sudo journalctl --vacuum-size=600M
Paso 2: Configurar la retención de diario para la prevención futura
Editar configuración de diario:
vi /etc/systemd/journald.conf
Agregar/modificar parámetro:
MaxRetentionSec=2week
Aplicar configuración:
sudo systemctl restart systemd-journald
Paso 3 opcional: Resolver error de reinicio
Mientras reinicia el servicio systemd-journald en el Paso 2, puede obtener un error preocupante:
Error : Failed to allocate directory watch: Too many open files
-
systemd-journald utiliza inotify para inspeccionar los cambios en los directorios de registro.
-
Cada reloj o monitor configura recuentos hacia ciertos límites del núcleo.
Los límites actuales definidos en el RCM problemático son:
cat /proc/sys/fs/inotify/max_user_watches
501120
cat /proc/sys/fs/inotify/max_user_instances
128
ulimit -n
1024
Desde la salida recopilada:
- Max identificar relojes: 501120
- Máximo de instancias de notificación: 128
Límite del descriptor de archivo abierto para diario: 1024
Cualquiera (o todos) de los valores de salida límite podría haber golpeado conduciendo al error. Por lo tanto, recopilamos el valor utilizado actual y lo comparamos con el límite de salida recopilado:
sudo lsof -p $(pidof systemd-journald) | wc -l
65
echo "Root inotify instances: $(sudo find /proc/*/fd -user root -type l -lname 'anon_inode:inotify' 2>/dev/null | wc -l) / $(cat /proc/sys/fs/inotify/max_user_instances)"
Root inotify instances: 126 / 128
Parece que la raíz ya está usando 126 de las 128 instancias de inotify permitidas. Eso deja a journald sin casi espacio para crear una nueva instancia de inotify cuando la reiniciamos.
Para resolver el error: podemos aumentar el valor max_user_instance y luego reiniciar el servicio:
# Temporarily increase the limit (until next reboot)
echo 256 > /proc/sys/fs/inotify/max_user_instances
sudo systemctl restart systemd-journald
# Temporarily increase the limit (until next reboot)
echo 256 > /proc/sys/fs/inotify/max_user_instances
sudo systemctl restart systemd-journald
Verificación posterior al cambio
Después de aplicar los cambios, la utilización del disco cayó al 61%, restaurando el nodo al estado de funcionamiento normal.
df -kh
Filesystem Size Used Avail Use% Mounted on
tmpfs 6.3G 9.7M 6.3G 1% /run
/dev/vda3 39G 23G 15G 61% /
tmpfs 32G 4.0K 32G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/vda2 488M 48K 452M 1% /var/tmp
/dev/vda1 488M 76K 452M 1% /tmp
Recomendación
-
Implemente la misma configuración en todos los nodos RCM de la implementación para mantener la utilización del disco dentro de límites seguros.
-
Coloque siempre el RCM de destino en modo de espera antes de realizar los cambios para evitar el impacto en el tráfico activo.
-
Supervise periódicamente la utilización de /dev/vda3 y el crecimiento del registro de diario como parte de las comprobaciones de estado proactivas del sistema.
 Comentarios
Comentarios