Solucionar problemas de error de replicación entre bastidores con código de error "424-Geo-replication Checksum Mismatch"
Opciones de descarga
-
ePub (371.0 KB)
Visualice en diferentes aplicaciones en iPhone, iPad, Android, Sony Reader o Windows Phone -
Mobi (Kindle) (171.7 KB)
Visualice en dispositivo Kindle o aplicación Kindle en múltiples dispositivos
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Contenido
Introducción
Este documento describe varios métodos de investigación para resolver problemas de discrepancia de suma de comprobación de replicación geográfica entre los racks local y remoto.
Prerequisites
Requirements
Cisco recomienda que tenga conocimiento sobre estos temas:
- Redundancia geográfica en la función de gestión de sesiones (SMF)
- SMF
- Terminación de la conexión del protocolo de control de transmisión (TCP)
Componentes Utilizados
Este documento no tiene restricciones específicas en cuanto a versiones de software y de hardware.
La información que contiene este documento se creó a partir de los dispositivos en un ambiente de laboratorio específico. Todos los dispositivos que se utilizan en este documento se pusieron en funcionamiento con una configuración verificada (predeterminada). Si tiene una red en vivo, asegúrese de entender el posible impacto de cualquier comando.
Antecedentes
¿Qué es la geo-redundancia en SMF?
-
SMF admite la redundancia geográfica (Geo)-geográfica (GR) en modo activo-activo.
-
La configuración de GR también es responsable de la replicación de
etcd/cachedatos en el rack en espera. -
SMF admite redundancia primaria/en espera en la que los datos se replican desde la instancia primaria a la instancia en espera.
-
Si la instancia principal falla, la instancia en espera se convierte en la principal y asume la operación.
-
Para lograr GR, se pueden configurar dos pares primario/en espera donde cada sitio procesa activamente el tráfico y el modo en espera actúa como respaldo para el sitio remoto.
Grupo de dispositivos de replicación geográfica
-
El POD de replicación geográfica se introduce para la comunicación entre racks/sitios y para supervisar POD/BFD dentro del rack
-
Dos instancias de GR-POD ejecutadas en cada rack/sitio
-
Dos GR POD funcionan en modo activo-en espera
-
Los POD GR se generan en el nodo Proto/VM
-
GR POD utiliza dos direcciones IP virtuales (VIP)
-
VIP interno para la comunicación entre POD (dentro del rack)
-
VIP externo para la comunicación de POD GR entre rack/sitio
-
Los VIP configurados para GR POD pueden estar activos en uno de los nodos/VM de Proto
-
Cuando se reinicia el grupo de dispositivos GR activo, VIP se conmuta a otro nodo/VM de Proto y el grupo de dispositivos GR en espera que se ejecuta en el otro nodo/VM de Proto se puede activar
Configuración de referencia de GR Pod:
smf# show running-config instance instance-id 1 endpoint geo
Thu Oct 20 06:25:25.319 UTC+00:00
instance instance-id 1
endpoint geo
replicas 1
nodes 2
interface geo-internal
vip-ip a.b.c.d vip-port 7001
exit
interface geo-external
vip-ip Y.Y.Y.Y vip-port 7002
exit
exit
exit
Identificar el grupo de dispositivos geográficos activo y el grupo de dispositivos geográficos en espera
Para identificar el grupo de dispositivos geográficos activo, debe comprobar si hay errores o eventos en los registros del grupo de dispositivos geográficos.
Grupo de dispositivos activo:
user@smf-ims-master-1:~$ kubectl logs georeplication-pod-0 -n smf-smfix1|tail -3
[ERROR] [grcacachepod.go:339] [gr_deferred_sync.application.app] Periodic Sync: Total time taken to sync IPAM cache pod data: 500.563723ms”
[ERROR] [GeoAdminStreamClient.go:276] [gr_pod.geo_admin_client.app] no one waiting for received response for txnID:CP0XXXOKCP0XXX-SMF-IMS-smfix1111163550 of host=geo-admin-pod2
Grupo de dispositivos en espera:
user@cp0xxx-smf-ims-master-1:~$ kubectl logs georeplication-pod-1 -n smf-smfix1|tail -3
[ERROR] [gr_pod.geo_replication_client_stream] Counters => not an active geo pod
[ERROR] [gr_pod.geo_replication_client_stream] Counters => not an active geo pod
[ERROR] [gr_pod.geo_replication_client_stream] Counters => not an active geo pod
Funcionalidades de GR POD
Los grupos GR replican los datos del grupo ETCD y de la caché en el sitio
Para ver los detalles de replicación de ETCD y datos de grupo de memoria caché, utilice CLI:
[cp0xxx-smf-ims/smfix1] smf# show georeplication checksum instance-id 1
Thu Oct 20 07:11:52.409 UTC+00:00
checksum-details
-- ---- --------
ID Type Checksum
-- ---- -------
1 ETCD 1666249907
IPAM CACHE 1666249907
NRFMgmt CACHE 1666249907
Mantener roles de instancias locales del sitio en ETCD
[ERROR] [gr_pod.gradmin] updateEntryInEtcd: Updating etcd entries for keys : Instance.2, with role as PRIMARY
[ERROR] [gr_pod.gradmin] updateEntryInEtcd: Updating etcd entries for keys : Instance.1, with role as STANDBY
Supervisión del estado del sitio local (estado de POD/estado de BFD)
[cp0xxx-smf-ims/smfix1] smf# show running-config geomonitor podmonitor pods smf-service
Thu Oct 20 07:36:41.280 UTC+00:00
geomonitor podmonitor pods smf-service
retryCount 2
retryInterval 900
retryFailOverInterval 500
failedReplicaPercent 60
Funciones del sitio
PRIMARY : El sitio está listo y toma tráfico de forma activa para la instancia en cuestión.
STANDBY: El sitio está en espera, listo para recibir tráfico pero no recibe tráfico para una instancia determinada.
STANDBY_ERROR: El sitio está en problemas, no está activo y no está listo para recibir tráfico para una instancia determinada.
FAILOVER_INIT: El sitio ha comenzado a conmutar por error y no está en condiciones de tomar tráfico, tiempo de búfer de 2 segundos para que la aplicación complete su actividad.
FAILOVER_COMPLETE: El sitio ha completado la conmutación por error e intentó informar al sitio del mismo nivel acerca de la conmutación por error para la instancia determinada. tiempo de búfer de 2 segundos.
FAILBACK_STARTED: La conmutación por fallo manual se activa con un retraso del sitio remoto para una instancia determinada.

Nota: La replicación de caché/ETCD y la replicación de CDL se producirían incluso en todas las funciones. Si los links GR están inactivos/los latidos periódicos fallan, los disparadores GR se suspenden.
GR-Triggers
CLI para verificar las funciones de instancia GR en rack
Show role instance id 1
Show role instance id 2
CLI para restablecer el rol de error en espera a estado en espera
Geo reset-role instance-id <1/2> role standby
Error CLI al cambiar el rol de espera a en espera
Geo switch-role instance-id <1/2> role standby failback-interval 0
CLI para cambiar la función de espera a principal
Para iniciar esta función de switch, debe activar la CLI desde el rack que tiene una de las instancias como principal.
Geo switch-role instance-id <1/2> role standby failback-interval 0
Nota: Escenario de Sunny Day: Rack1-Instance1-Primary, Instance2-Standby; Rack2-Instance1-StandBy, Instance2-Primary.
Escenario de día lluvioso: Rack1-Instance 1 e Instance 2-Primary; Rack2-Instance 1 e Instance 2-StandBy.
Terminación de la conexión TCP
El protocolo TCP es un protocolo orientado a la conexión, lo que significa que se establece y se mantiene una conexión hasta que los programas de aplicación de cada extremo hayan finalizado el intercambio de mensajes. TCP funciona con el protocolo de Internet (IP).
El protocolo de enlace TCP también se conoce como protocolo de enlace de 3 vías. Cuando se inicia una conexión desde el equipo cliente al equipo servidor, el cliente y el servidor intercambian paquetes SYN y ACK antes de que se transmitan los datos.
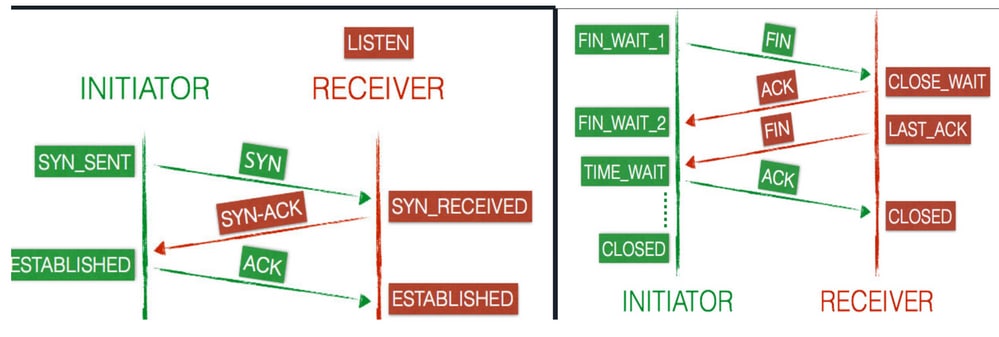 Protocolo de control de transmisión: estados de conexión de cliente y servidor
Protocolo de control de transmisión: estados de conexión de cliente y servidor
Una conexión progresa a través de una serie de estados durante toda su vida útil. Los estados son: LISTEN, SYN-SENT, SYN-RECEIVED, ESTABLISHED, FIN-WAIT-1, FIN-WAIT-2,CLOSE-WAIT,CLOSING, LAST-ACK, y el estado ficticio TIME-WAIT CLOSED.
- Cuando se abre una nueva conexión TCP, el cliente (iniciador) envía un
SYNpaquete al servidor (receptor) y actualiza su estado aSYN-SENT. - A continuación, el servidor envía un mensaje
SYN-ACKen respuesta al cliente que cambia su estado de conexión aSYN-RECEIVED.
- El cliente responde con un
ACKy la conexión se marca comoESTABLISHEDen ambos terminales, ahora el cliente y el servidor están listos para transferir datos.
- El cliente envía un
FINpaquete al servidor y actualiza su estado aFIN-WAIT-1. - El servidor recibe la solicitud de terminación del cliente y responde con un
ACK. Después de la respuesta, el servidor entra en unCLOSE-WAITestado. - Tan pronto como el cliente recibe la respuesta del servidor, pasa al
FIN-WAIT-2estado. - El servidor aún está en el
CLOSE-WAITestado y va independientemente con un FIN, que actualiza el estado aLAST-ACK. - Ahora el cliente recibe la solicitud de terminación y responde con un
ACK, lo que da como resultado unTIME-WAITestado. - El servidor ha finalizado y establece la conexión en
CLOSEDinmediatamente. - El cliente permanece en el
TIME-WAITestado durante un máximo de cuatro minutos, antes de que se produzca la conexiónCLOSED.
Problema
Escenario 1. La suma de comprobación de replicación geográfica para el Id. de instancia 1 tiene caché de IPAM y discordancia de suma de comprobación de caché de NRFMgmt
error en el estado de replicación geográfica smfix1/smfix2 (error en la replicación entre bastidores en sitio remoto).
ERROR: Error del comando Admin [pod internal-gr-pod-1, URL http://X.X.0.0:15290/commands] con código 424, error del mensaje: discordancia de checksum de replicación.
El problema se observó el 23 de agosto a las 00:36:19 como "Error en la replicación entre bastidores".
From CEE alerts:
Inter_Rack_Replication 9ca45362a049 critical 08-23T00:36:19 System
Inter rack replication to Remote Site failed
En este resultado de CLI, puede ver que instance-id 1 tiene discrepancia de suma de comprobación para la administración de direcciones IP (IPAM) y la memoria caché NRF.
[cp0xxx-smf-ims/smfix1] smf# show georeplication checksum instance-id 1
Mon Sep 5 08:38:27.762 UTC+00:00
checksum-details
-- --- --------
ID Type Checksum
-- ---- --------
1 ETCD 1662367102
IPAM CACHE 1662367102
NRFMgmtCACHE 1662367102
[cp0xxx-smf-ims/smfix2] smf# show georeplication checksum instance-id 1
Mon Sep 5 08:38:30.767 UTC+00:00
checksum-details
-- ---- --------
ID Type Checksum
-- ---- --------
1 ETCD 1662367102
IPAM CACHE 1661214831
NRFMgmtCACHE 1661214831
Situación 2. La suma de comprobación de replicación geográfica para el ID de instancia 2 tiene una discordancia de suma de comprobación ETCD
[cp0xxx-smf-ims/smfix1] smf# show georeplication checksum instance-id 2
Mon Sep 5 08:38:37.852 UTC+00:00
checksum-details
-- ---- --------
ID Type Checksum
-- ---- --------
2 ETCD 1661214828
IPAM CACHE 1662367107
NRFMgmtCACHE 1662367107
[cp0xxx-smf-ims/smfix2] smf# show georeplication checksum instance-id 2
Mon Sep 5 08:38:39.118 UTC+00:00
checksum-details
-- ---- -------
ID Type Checksum
-- ---- --------
2 ETCD 1662367107
IPAM CACHE 1662367107
NRFMgmtCACHE 1662367107
Situación 3. Falla de establecimiento de conexión TCP con sitio remoto
Registros de Rack1-smfix1:
En los registros de GR Pod, puede observar que se ha detenido el punto de control del grupo de memoria caché de actualización, ha fallado la replicación inmediata y no hay ningún host remoto disponible.
2022/08/23 00:34:00.035 [ERROR] [grreplicationclient.go:201] [gr_pod.geo_replication_client_stream.app] HandleImmediateReplication failed: [RPCNoRemoteHostAvailable] No remote host available for this request
2022/08/23 00:34:02.086 [ERROR] [grreplicationclient.go:466] [gr_pod.geo_replication_client_stream.app] Stream disconnected, closing logQueueCounter=0xc0093b08b0
2022/08/23 00:34:04.124 [ERROR] [GeoAdminStreamClient.go:215] [gr_pod.geo_admin_client.app] ADMIN(geo-admin-pod2) : exit outgoing request loop stream closed
2022/08/23 00:34:43.623 [ERROR] [grreplicationclient.go:270] [gr_pod.geo_replication_client_stream.app] Update etcd checkpointing stopped for grinstance: 1
Rack2-smfix2-logs:
En los registros de GR Pod, puede observar un error de Stream disconnect y una diferencia de suma de comprobación de CACHE mayor de lo esperado.
2022/08/23 00:34:06.497 [ERROR] [grreplicationserver.go:62] [gr_pod.geo_replication_server_stream.app] Stream disconnected, closing logQueueCounter=0xc001b85d08
2022/08/23 00:34:06.497 [ERROR] [grreplicationserver.go:314] [gr_pod.geo_replication_server_stream.app] handleCachePodSyncRequests : Stream closed of connection=0xc002ee08f0
2022/08/23 00:34:56.751 [ERROR] [grpodcommands.go:455] [gr_pod.cli_command.app] compareChecksumData: CACHE checksum difference is more then expected, local checksum [1661214831] remote checksum [1661214892]
2022/08/23 00:34:56.678 [ERROR] [etcdAuditReplHandler.go:196] [gr_pod.application.app] SyncETCDData periodic sync : For ETCD [C.GR.1.] key, the remote site data size is: [10833]
2022/08/23 00:36:56.757 [ERROR] [grpodcommands.go:455] [gr_pod.cli_command.app] compareChecksumData: CACHE checksum difference is more then expected, local checksum [1661214831] remote checksum [1661215012]
Situación 4. Error de DIMM observado en el servidor que aloja el nodo maestro
Se observa un error ECC en el nodo maestro-1 que aloja geo-replication-pod-0 aproximadamente al mismo tiempo que el error de flujo desconectado.
CP0XXX-Server9-02# scope sel
CP0XXX-Server9-02 /sel # show entries
Time Severity Description
----------------------- ------------- ----------------------------------------
2022-08-23 00:33:59 UTC Informational "DDR4_P1_E1_ECC: Memory sensor, read 1 correctable ECC errors on CPU1 DIMM E1 was asserted"
2022-08-22 22:59:45 UTC Informational "DDR4_P1_E1_ECC: Memory sensor, read 1 correctable ECC errors on CPU1 DIMM E1 was asserted"
- La comunicación entre el grupo de dispositivos de replicación geográfica en Rack1 y el grupo de dispositivos de replicación geográfica en Rack2 está interrumpida.
-
Se produce un error de DIMM en uno de los nodos maestros que hizo que la conexión de flujo cayera entre Rack1 y Rack2.
-
Desde Rack1 Geo-replication-pod no pudo replicar o enviar ninguna solicitud a Rack2, sale con el error Host remoto no disponible.
-
A partir de la salida del comando netstat en Rack1 y Rack2 para el puerto 7002 se encontró que el socket Rack1 está atascado en el estado FIN_WAIT1 y el socket Rack2 está atascado en el estado SYN_RECV.
-
En el lado del servidor, es decir, en Rack2, el socket se atasca en el estado SYNC_RECV, y la conexión recién creada también entra en el estado SYNC_RECV y no puede comunicarse entre sí.
-
La conexión está en estado SYN_RECV porque el kernel ha recibido un paquete SYN para un puerto, es decir, en modo LISTENING, pero el otro extremo no respondió con ACK.
smfix2-Master-2 tiene instalado el VIP externo geográfico (Y.Y.Y.Y:7002), pero el estado de conexión TCP del host remoto (SMFIX1) se bloquea en el estado SYN_RECV en lugar del estado ESTABLISHED. a.b.c.d y a.b.c.e son direcciones IP Master-1 y 2 de smfix1 (rack1).
user@cp0xxx-smf-ims-master-2:~$ netstat -anp | grep 7002
tcp 0 0 Y.Y.Y.Y:7002 0.0.0.0:* LISTEN -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:35542 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:47046 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:36248 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:42686 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:38248 SYN_RECV -
El estado de la conexión TCP Geo VIP externa en smfix1 (Rack1) para el par remoto está en el estado FIN-WAIT1:
user@cp0xxx-smf-ims-master-1:~$ netstat -anp | grep 7002
tcp 0 0 a.b.c.d 0.0.0.0:* LISTEN -
tcp 0 1 a.b.c.d:60866 Y.Y.Y.Y:7002 FIN_WAIT1 -
tcp 0 1 a.b.c.d:52274 Y.Y.Y.Y:7002 FIN_WAIT1 -
tcp 0 1 a.b.c.d:59674 Y.Y.Y.Y:7002 FIN_WAIT1 -
tcp 0 1 a.b.c.d:47926 Y.Y.Y.Y:7002 FIN_WAIT1 -
Solución
Rack1:
-
Primero, elimine el grupo de dispositivos Geo en espera, espere a que el grupo de dispositivos se recupere y, a continuación, elimine el grupo de dispositivos Geo activo. Inicie sesión en Master VIP y elimine el grupo de dispositivos GR:
kubectl delete pod-n
Rack2:
- En primer lugar, elimine el grupo de dispositivos Geo en espera, espere a que se recupere y, a continuación, elimine el grupo de dispositivos Geo activo.
-
Verifique el estado de replicación geográfica desde CLI, publique la eliminación de los grupos de dispositivos geográficos.
show georeplication-status
- Post the Geo pod delete on Rack1 and Rack2, you can see the External Geo VIP IP: El puerto TCP pasa al estado ESTABLISHED.
- Estado de georeplicación "Superado".
- No se observa ninguna discordancia de suma de comprobación en el estado de replicación en los racks.
smfix2 (Rack2):
user@cp0xxx-smf-ims-master-1:~$ sudo netstat -anp | grep 7002 | grep -v aa
tcp 0 0 Y.Y.Y.Y:7002 0.0.0.0:* LISTEN 36854
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:46402 ESTABLISHED 36854/grpod
tcp 0 0 Y.Y.Y.Y:7002 1a.b.c.e:54708 ESTABLISHED 36854/grpod
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:55152 ESTABLISHED 36854/grpod
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:46530 ESTABLISHED 36854/grpod
tcp 0 0 10.59.0.0:7002 10.59.0.0:46532 ESTABLISHED 36854/grpod
smfix1 (Rack1):
user@cp0xxx-smf-ims-master-1:~$ sudo netstat -anp | grep 7002 | grep -v aa
tcp 0 0 a.b.c.d 0.0.0.0:* LISTEN 53932/grpod
tcp 0 0 a.b.c.d:46530 Y.Y.Y.Y:7002 ESTABLISHED 53932/grpod
tcp 0 0 a.b.c.d:46402 Y.Y.Y.Y:7002 ESTABLISHED 53932/grpod
tcp 0 17 a.b.c.d:46532 Y.Y.Y.Y:7002 ESTABLISHED 53932/grpod
2. Estado de la georreplicación:
[okcp0xx-smf-ims/smfix1] smf# show georeplication-status
result "pass"
[okcp0xx-smf-ims/smfix2] smf# show georeplication-status
result "pass"
Historial de revisiones
| Revisión | Fecha de publicación | Comentarios |
|---|---|---|
1.0 |
05-Dec-2022
|
Versión inicial |
Con la colaboración de ingenieros de Cisco
- Manasa G KambiCisco TAC Engineer
- Krishna Kishore D VCisco Technical Leader
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)