Introducción
Este documento describe cómo utilizar Grafana/Prometheus en Cisco SMF para crear consultas personalizadas con el fin de resolver problemas relacionados con el flujo de llamadas.
Abreviaturas
| SMF |
Función de administración de sesiones |
| UDM |
Gestión de datos unificada |
| AMF |
Función de acceso y movilidad |
| PDU |
Unidad de datos de protocolo |
¿Por qué personalizar las consultas para resolver problemas de flujo de llamadas SMF?
Mientras que los paneles incorporados proporcionan grandes gráficos con respecto a KPI importantes y estadísticas de salud de los nodos, con el fin de utilizar todo el potencial de las consultas de PromQL y grafana para solucionar situaciones de problemas habituales, las consultas personalizadas desempeñan un papel importante. Las consultas y gráficos promql personalizados añaden más versatilidad y comodidad para aislar un fallo específico.
Ventajas de los paneles incorporados:
- Grafana proporciona una interfaz gráfica fácil de usar para navegar por las estadísticas de SMF.
- Hay paneles de grafana incorporados disponibles para comprobar la mayoría de los KPI y estadísticas.
Ejemplo:
Panel SMF 5G
- Tasa de fallos/éxito de creación de PDU 5G
- Tasa de fallos/éxitos de creación de PDN 4G
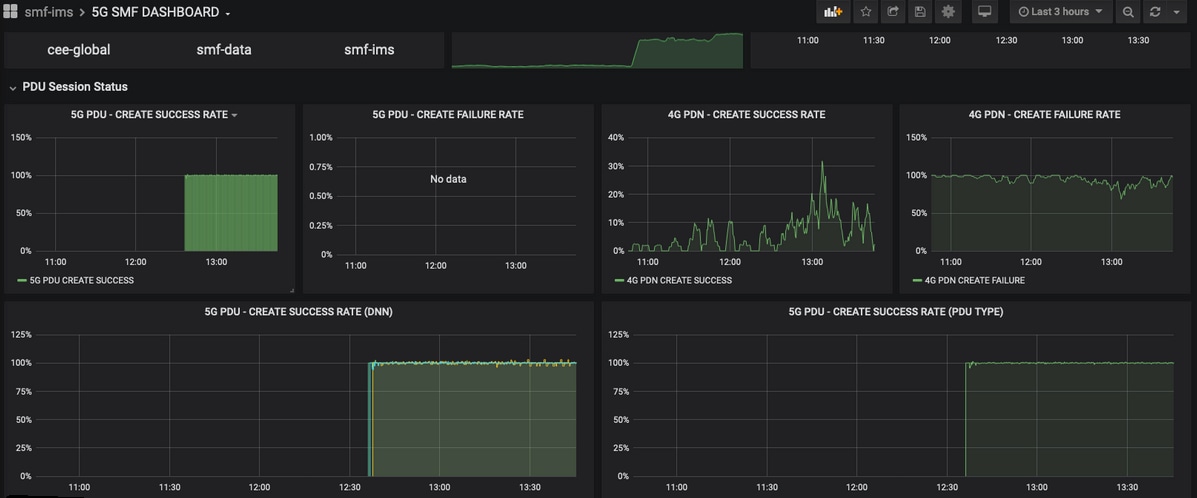
- Tasa de éxito por procedimiento

- Porcentaje de causa por fallo de procedimiento.
- Porcentaje de motivo de desconexión.
- Porcentaje de causa de solicitud HTTP y respuesta correspondiente.
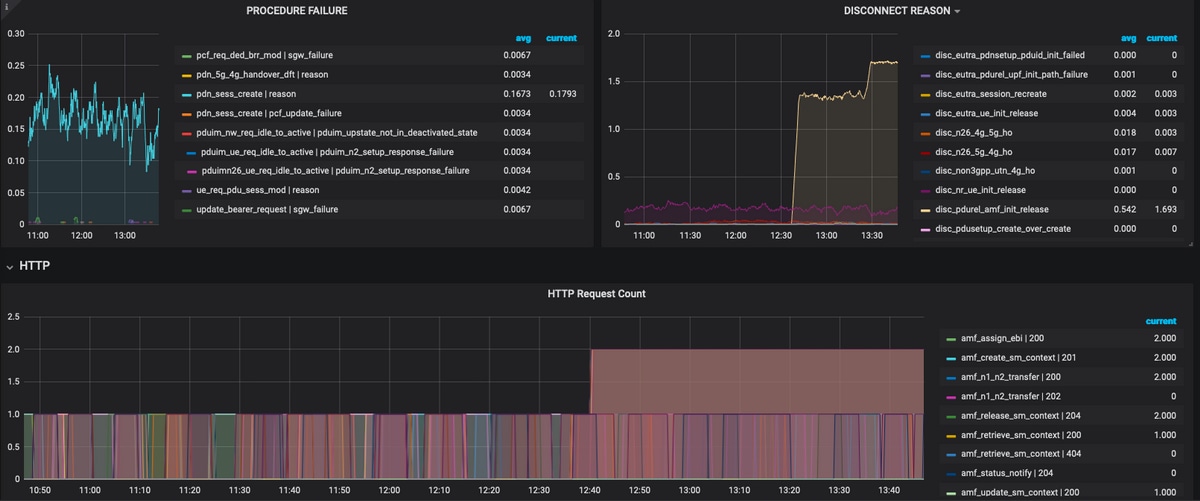
Para resolver problemas adicionales:
- El panel y los paneles disponibles se centran principalmente en porcentajes y KPI. Mientras investiga más a fondo, es posible que deba examinar los detalles granulares para identificar el escenario y el mensaje concretos que desencadenaron esta falla.
- Las consultas personalizadas que utilicen expresiones regulares específicas ayudarán a correlacionar estas estadísticas y aislar el desencadenante.
- Estas consultas se pueden utilizar para trazar gráficos en grafana SMF o en grafana offline con el volcado de métricas del paquete tac-debug.
- Se puede utilizar el rango de métricas asociadas con diferentes servicios y también se puede filtrar a través de pares clave/valor de etiqueta para resolver problemas del escenario específico.
Grafana y Prometeo
Grafana
"Grafana es un software de visualización y análisis de código abierto. Le permite consultar, visualizar, alertar y explorar sus métricas sin importar dónde se almacenen".
Cisco SMF utiliza grafana incorporado para trazar los datos estadísticos en tiempo real de los contenedores de aplicaciones.
Prometeo
Prometheus proporciona un modelo de datos multidimensional con datos de series de tiempo identificados por pares de nombre y clave/valor métrico y un lenguaje de consulta flexible llamado PromQL para acceder a estos datos.
Prometheus se utiliza para recopilar estadísticas/contadores de los microservicios.
Métricas: Son los identificadores de las estadísticas de las series temporales.
Etiquetas: Las métricas están compuestas por etiquetas. ¿Cuáles son básicamente los pares clave-valor? Las combinaciones de etiquetas para una métrica determinada identifican una instancia concreta de datos de series temporales
Ejemplo: 
La métrica "smf_service_stats" resaltada en verde, tiene muchas etiquetas resaltadas en amarillo.
Utilizando estos pares clave/valor de etiqueta, se puede seleccionar una serie de datos determinada.
Consulta PromQL
Prometheus proporciona un lenguaje de consulta funcional llamado PromQL. Las funciones incorporadas están disponibles en PromQl (p. ej. Sum(), by(), count() etc) nos permite seleccionar datos de series de tiempo particulares en un formato gráfico o tabular.
Ejemplo:
sum(smf_service_stats{status="success"}) by (procedure_type)
Este ejemplo selecciona datos de la métrica smf_service_stats por procedure_type donde status = "success"
sum (calcular suma sobre dimensiones)
by(Agrupa la salida por etiquetas)
Los filtros se pueden utilizar dentro de la suma mediante pares de clave/valor de etiqueta para filtrar aún más los gráficos.
Ejemplo 1:
sum(smf_disconnect_stats{namespace="smf-data",reason=~"disc_eutra.*"})by(reason, rat_type)
Aquí se selecciona el espacio de nombres smf-data y, como motivo, se considerará toda la razón de desconexión que comience por disk_eutra (es decir, razones de desconexión 4G).
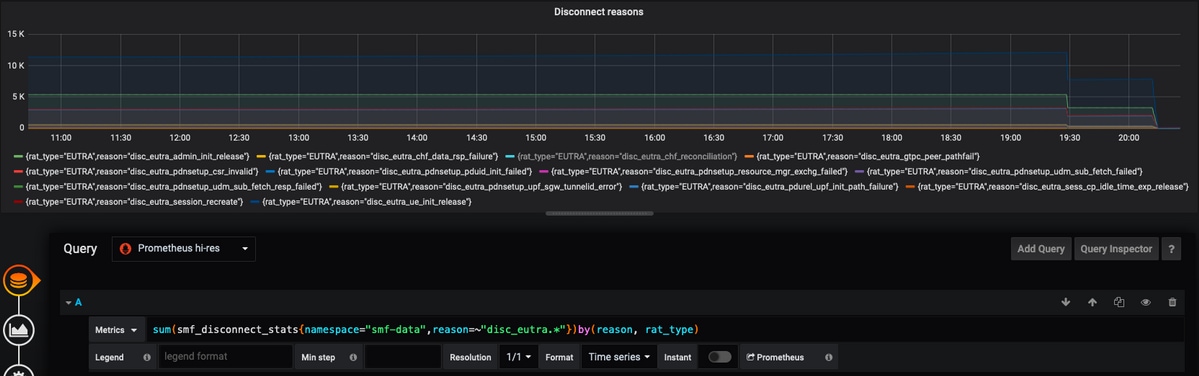
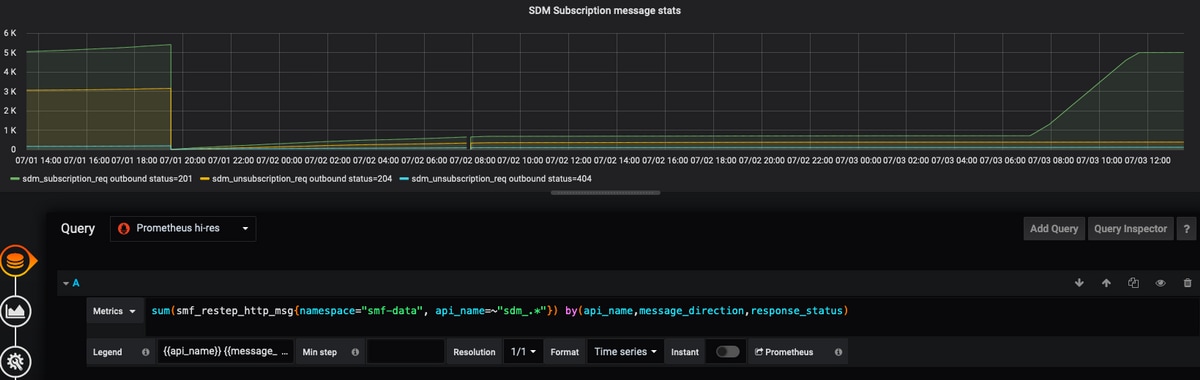
Ejemplo 2:
sum(smf_restep_http_msg{namespace="smf-data", api_name=~"sdm_.*"}) by(api_name,message_direction,response_status,response_cause)
Esta consulta trazará los mensajes de suscripción sdm SMF - UDM con la causa de respuesta.
¿Cómo se crea un panel y un panel?
Para agregar un nuevo panel.
Paso 1. Navegue hasta Crear > Panel, como se muestra en esta imagen.
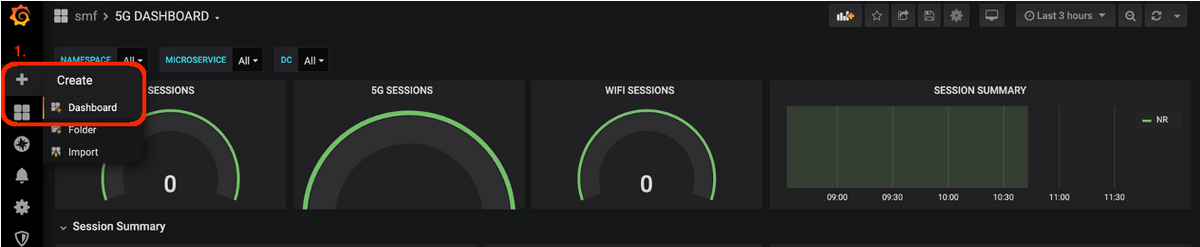
Para agregar el nuevo panel- Agregar consulta.
Paso 2. Navegue hasta la opción Agregar panel en la parte superior para agregar un nuevo panel.
Paso 3. Seleccione el botón Agregar Consulta.
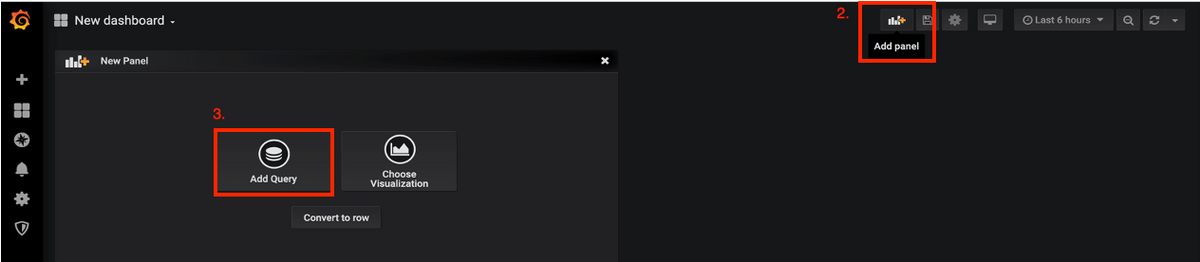
Seleccione Tipo de consulta: Prometeo de alta resolución.
Paso 4. Seleccione Prometheus hi-res opción en Consulta Lista desplegable.
Paso 5. Luego agregue la consulta promql en el cuadro dado.
Paso 6. Guarde el panel.
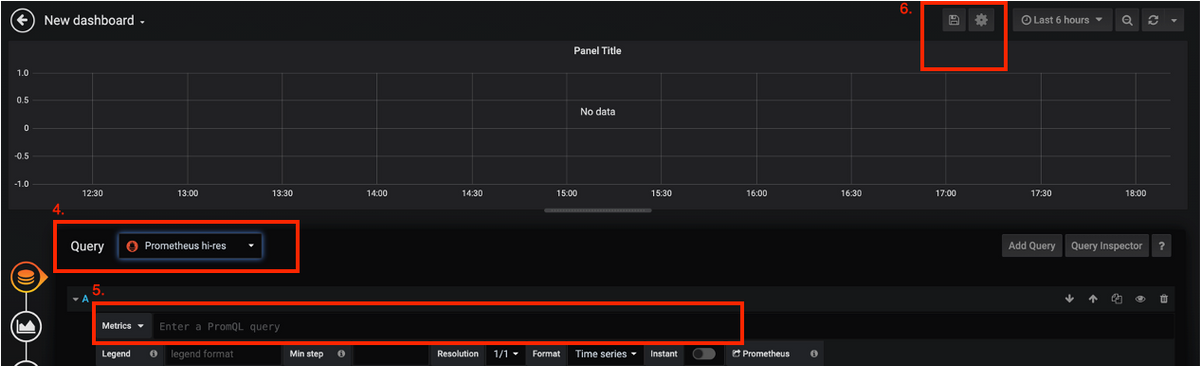
Ejemplo: Utilizar la consulta y los gráficos personalizados para solucionar problemas
Fallo de establecimiento de sesión de PDU - Fallo de respuesta N1N2
Paso 1. Observación de inmersión de KPI e identificar la sesión de PDU que genera la falla.

Query: sum by (procedure_type, pdu_type, status, reason) (smf_service_stats{namespace="smf",procedure_type="pdu_sess_create"})
Paso 2. La causa del error es "n1n2_transfer_failure_rsp_code". Echemos un vistazo a los motivos de desconexión:

Query: sum(smf_disconnect_stats{namespace=”smf"}) by (reason)
Paso 3. La razón de desconexión "disk_pdusetup_n1n2_transfer_rsp_failure" indica una respuesta negativa del peer AMF. Dado que la interacción SMF-AMF se produce a través de una interfaz basada en el servicio HTTP, las estadísticas HTTP deben examinarse más a fondo (métrica: smf_restep_http_msg)
Las estadísticas de HTTP indican que durante el fallo SMF ha recibido un código de estado HTTP 401 - No autorizado de AMF
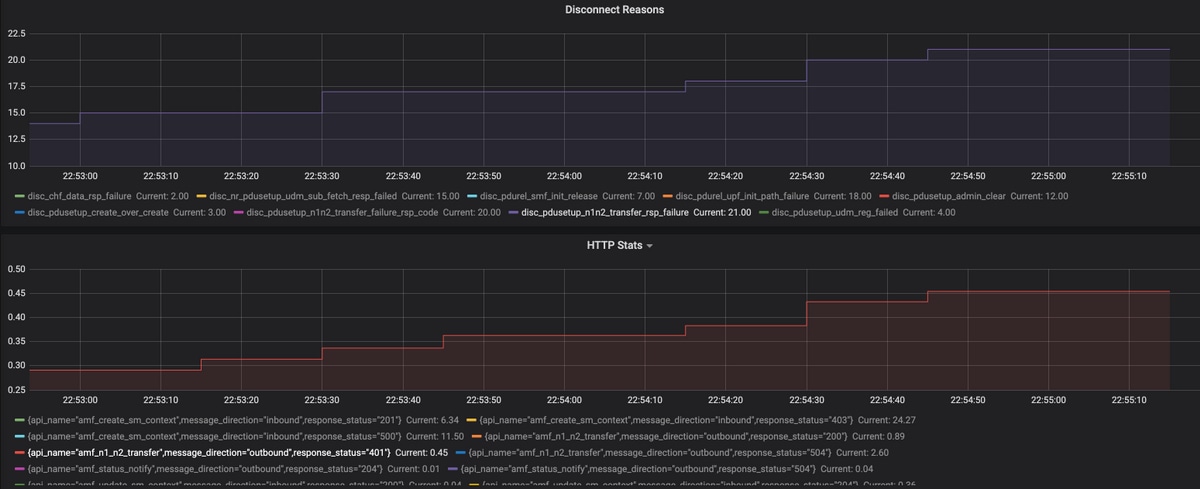
Query: sum(smf_restep_http_msg{namespace="smf"}) by(api_name,message_direction,response_status)
Métricas importantes para solucionar problemas:
smf_disconnect_stats
smf_proto_pfcp_msg_total
smf_service_stats
smf_restep_http_msg
smf_n1_message_stats
smf_proto_pfcp_msg_total
nodemgr_msg_stats
nodemgr_gtpc_msg_stats
chf_message_stats
policy_msg_processing_status
procedure_protocol_total
procedure_service_total
Más información sobre las métricas de SMF:
Como se ha demostrado en estos ejemplos, se pueden trazar sus propios gráficos personalizados como y cuando sea necesario para que el escenario de falla específico correlacione diferentes mensajes y aísle la falla. Tales consultas pueden ser ejecutadas en sistemas locales también después de que los datos de métrica de Tac_debug_pkg estén montados en grafana local.
 Comentarios
Comentarios