Procedimientos de Copia de Seguridad y Restauración para Varios Componentes Ultra-M - CPS
Opciones de descarga
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Introducción
En este documento se describen los pasos necesarios para realizar una copia de seguridad y restaurar una máquina virtual en una configuración Ultra-M que aloja las funciones de red virtual de CPS de llamadas.
Antecedentes
Ultra-M es una solución de núcleo de paquetes móviles virtualizados, preempaquetada y validada, diseñada para simplificar la implementación de funciones de red virtual (VNF). La solución Ultra-M consta de los siguientes tipos de máquinas virtuales (VM):
- Controlador de servicios elástico (ESC)
- Cisco Policy Suite (CPS)
La arquitectura de alto nivel de Ultra-M y los componentes involucrados son como se muestra en esta imagen.
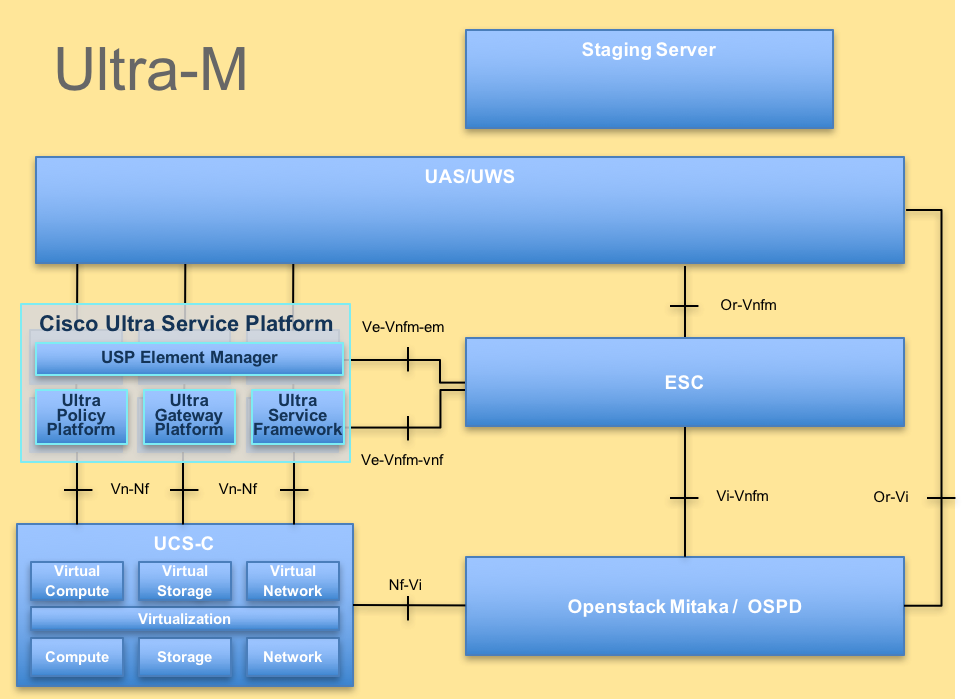

Nota: Se considera la versión Ultra M 5.1.x para definir los procedimientos en este documento. Este documento está dirigido al personal de Cisco que está familiarizado con la plataforma Cisco Ultra-M.
Abreviaturas
| VNF | Función de red virtual |
| ESC | Controlador de servicio elástico |
| FREGAR | Método de procedimiento |
| OSD | Discos de almacenamiento de objetos |
| HDD | Disco duro |
| SSD | Unidad de estado sólido |
| VIM | Administrador de infraestructura virtual |
| VM | Máquina virtual |
| UUID | Identificador único universal |
Procedimiento de backup
Copia de seguridad OSPD
1. Compruebe el estado de la pila de OpenStack y la lista de nodos.
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack stack list --nested
[stack@director ~]$ ironic node-list
[stack@director ~]$ nova list
2. Compruebe si todos los servicios en la nube están cargados, activos y en ejecución desde el nodo OSP-D.
[stack@director ~]$ systemctl list-units "openstack*" "neutron*" "openvswitch*"
UNIT LOAD ACTIVE SUB DESCRIPTION
neutron-dhcp-agent.service loaded active running OpenStack Neutron DHCP Agent
neutron-openvswitch-agent.service loaded active running OpenStack Neutron Open vSwitch Agent
neutron-ovs-cleanup.service loaded active exited OpenStack Neutron Open vSwitch Cleanup Utility
neutron-server.service loaded active running OpenStack Neutron Server
openstack-aodh-evaluator.service loaded active running OpenStack Alarm evaluator service
openstack-aodh-listener.service loaded active running OpenStack Alarm listener service
openstack-aodh-notifier.service loaded active running OpenStack Alarm notifier service
openstack-ceilometer-central.service loaded active running OpenStack ceilometer central agent
openstack-ceilometer-collector.service loaded active running OpenStack ceilometer collection service
openstack-ceilometer-notification.service loaded active running OpenStack ceilometer notification agent
openstack-glance-api.service loaded active running OpenStack Image Service (code-named Glance) API server
openstack-glance-registry.service loaded active running OpenStack Image Service (code-named Glance) Registry server
openstack-heat-api-cfn.service loaded active running Openstack Heat CFN-compatible API Service
openstack-heat-api.service loaded active running OpenStack Heat API Service
openstack-heat-engine.service loaded active running Openstack Heat Engine Service
openstack-ironic-api.service loaded active running OpenStack Ironic API service
openstack-ironic-conductor.service loaded active running OpenStack Ironic Conductor service
openstack-ironic-inspector-dnsmasq.service loaded active running PXE boot dnsmasq service for Ironic Inspector
openstack-ironic-inspector.service loaded active running Hardware introspection service for OpenStack Ironic
openstack-mistral-api.service loaded active running Mistral API Server
openstack-mistral-engine.service loaded active running Mistral Engine Server
openstack-mistral-executor.service loaded active running Mistral Executor Server
openstack-nova-api.service loaded active running OpenStack Nova API Server
openstack-nova-cert.service loaded active running OpenStack Nova Cert Server
openstack-nova-compute.service loaded active running OpenStack Nova Compute Server
openstack-nova-conductor.service loaded active running OpenStack Nova Conductor Server
openstack-nova-scheduler.service loaded active running OpenStack Nova Scheduler Server
openstack-swift-account-reaper.service loaded active running OpenStack Object Storage (swift) - Account Reaper
openstack-swift-account.service loaded active running OpenStack Object Storage (swift) - Account Server
openstack-swift-container-updater.service loaded active running OpenStack Object Storage (swift) - Container Updater
openstack-swift-container.service loaded active running OpenStack Object Storage (swift) - Container Server
openstack-swift-object-updater.service loaded active running OpenStack Object Storage (swift) - Object Updater
openstack-swift-object.service loaded active running OpenStack Object Storage (swift) - Object Server
openstack-swift-proxy.service loaded active running OpenStack Object Storage (swift) - Proxy Server
openstack-zaqar.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server
openstack-zaqar@1.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server Instance 1
openvswitch.service loaded active exited Open vSwitch
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, for example, generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
37 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
3. Confirme que dispone de suficiente espacio en disco antes de realizar el proceso de copia de seguridad. Se espera que este tarball tenga al menos 3,5 GB.
[stack@director ~]$df -h
4. Ejecute estos comandos como el usuario raíz para realizar una copia de seguridad de los datos desde el nodo de la nube inferior a un archivo llamado undercloud-backup-[timestamp].tar.gz y transferirlo al servidor de copia de seguridad.
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql
[root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql
/etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack
tar: Removing leading `/' from member names
Respaldo de ESC
1. ESC, a su vez, trae a colación la función de red virtual (VNF) interactuando con VIM.
2. ESC tiene redundancia 1:1 en la solución Ultra-M. Hay 2 máquinas virtuales ESC implementadas y admiten un único fallo en Ultra-M. Por ejemplo, recupere el sistema si hay un solo fallo en el sistema.
Nota: Si se produce más de un fallo, no se admite y puede ser necesario volver a implementar el sistema.
Detalles de la copia de seguridad ESC:
- Configuración en ejecución
- ConfD CDB DB
- Registros ESC
- configuración de Syslog
3. La frecuencia de la copia de seguridad de la base de datos de ESC es complicada y debe manejarse cuidadosamente mientras ESC monitorea y mantiene las diversas máquinas de estado para las diversas VM de VNF implementadas. Se recomienda que estas copias de seguridad se realicen después de estas actividades en un sitio/POD/VNF determinado.
4. Verifique que el estado de ESC sea bueno usando la secuencia de comandos health.sh.
[root@auto-test-vnfm1-esc-0 admin]# escadm status
0 ESC status=0 ESC Primary Healthy
[root@auto-test-vnfm1-esc-0 admin]# health.sh
esc ui is disabled -- skipping status check
esc_monitor start/running, process 836
esc_mona is up and running ...
vimmanager start/running, process 2741
vimmanager start/running, process 2741
esc_confd is started
tomcat6 (pid 2907) is running... [ OK ]
postgresql-9.4 (pid 2660) is running...
ESC service is running...
Active VIM = OPENSTACK
ESC Operation Mode=OPERATION
/opt/cisco/esc/esc_database is a mountpoint
============== ESC HA (Primary) with DRBD =================
DRBD_ROLE_CHECK=0
MNT_ESC_DATABSE_CHECK=0
VIMMANAGER_RET=0
ESC_CHECK=0
STORAGE_CHECK=0
ESC_SERVICE_RET=0
MONA_RET=0
ESC_MONITOR_RET=0
=======================================
ESC HEALTH PASSED
5. Realice la copia de seguridad de la configuración en ejecución y transfiera el archivo al servidor de copia de seguridad.
[root@auto-test-vnfm1-esc-0 admin]# /opt/cisco/esc/confd/bin/confd_cli -u admin -C
admin connected from 127.0.0.1 using console on auto-test-vnfm1-esc-0.novalocal
auto-test-vnfm1-esc-0# show running-config | save /tmp/running-esc-12202017.cfg
auto-test-vnfm1-esc-0#exit
[root@auto-test-vnfm1-esc-0 admin]# ll /tmp/running-esc-12202017.cfg
-rw-------. 1 tomcat tomcat 25569 Dec 20 21:37 /tmp/running-esc-12202017.cfg
Base de datos ESC de backup
1. Inicie sesión en la máquina virtual ESC y ejecute este comando antes de realizar la copia de seguridad.
[admin@esc ~]# sudo bash
[root@esc ~]# cp /opt/cisco/esc/esc-scripts/esc_dbtool.py /opt/cisco/esc/esc-scripts/esc_dbtool.py.bkup
[root@esc esc-scripts]# sudo sed -i "s,'pg_dump,'/usr/pgsql-9.4/bin/pg_dump," /opt/cisco/esc/esc-scripts/esc_dbtool.py
#Set ESC to mainenance mode
[root@esc esc-scripts]# escadm op_mode set --mode=maintenance
2. Compruebe el modo ESC y asegúrese de que está en modo de mantenimiento.
[root@esc esc-scripts]# escadm op_mode show
3. Copia de seguridad de la base de datos utilizando la herramienta de restauración de copia de seguridad de la base de datos disponible en ESC.
[root@esc scripts]# sudo /opt/cisco/esc/esc-scripts/esc_dbtool.py backup --file scp://<username>:<password>@<backup_vm_ip>:<filename>
4. Vuelva a establecer ESC en Modo de operación y confirme el modo.
[root@esc scripts]# escadm op_mode set --mode=operation
[root@esc scripts]# escadm op_mode show
5. Acceda al directorio de archivos de comandos y recopile los registros.
[root@esc scripts]# /opt/cisco/esc/esc-scripts
sudo ./collect_esc_log.sh
6. Para crear una instantánea del ESC, primero apague el ESC.
shutdown -r now
7. Desde OSPD, cree una instantánea de la imagen.
nova image-create --poll esc1 esc_snapshot_27aug2018
8. Compruebe que se ha creado la instantánea.
openstack image list | grep esc_snapshot_27aug2018
9. Inicie el ESC desde OSPD.
nova start esc1
10. Repita el mismo procedimiento en la máquina virtual ESC en espera y transfiera los registros al servidor de respaldo.
11. Recopile la copia de seguridad de la configuración de syslog en VMS ESC y transfiérala al servidor de copia de seguridad.
[admin@auto-test-vnfm2-esc-1 ~]$ cd /etc/rsyslog.d
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/00-escmanager.conf
00-escmanager.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/01-messages.conf
01-messages.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/02-mona.conf
02-mona.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.conf
rsyslog.conf
Copia de seguridad de CPS
Paso 1. Cree una copia de seguridad del Administrador de clústeres de CPS.
Utilice este comando para ver las instancias nova y observe el nombre de la instancia de VM del administrador de agrupamiento:
nova list
Detenga el Cluman de ESC.
/opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli vm-action STOP <vm-name>
Paso 2. Verifique que el Administrador de clústeres esté en estado SHUTOFF.
admin@esc1 ~]$ /opt/cisco/esc/confd/bin/confd_cli admin@esc1> show esc_datamodel opdata tenants tenant Core deployments * state_machine
Paso 3. Cree una imagen nova snapshot como se muestra en este comando:
nova image-create --poll <cluman-vm-name> <snapshot-name>
Nota: Asegúrese de que dispone de suficiente espacio en disco para la instantánea.
.Important - En caso de que la VM se vuelva inalcanzable después de la creación de la instantánea, verifique el estado de la VM usando el comando nova list. Si está en estado SHUTOFF, debe iniciar la VM manualmente.
Paso 4. Vea la lista de imágenes con este comando: nova image-list
Imagen 1: Ejemplo de salida

Paso 5. Cuando se crea una instantánea, la imagen de la instantánea se almacena en OpenStack Glance. Para almacenar la instantánea en un almacén de datos remoto, descargue la instantánea y transfiera el archivo en OSPD a (/home/stack/CPS_BACKUP).
Para descargar la imagen, utilice este comando en OpenStack:
glance image-download –-file For example: glance image-download –-file snapshot.raw 2bbfb51c-cd05-4b7c-ad77-8362d76578db
Paso 6. Enumere las imágenes descargadas como se muestra en este comando:
ls —ltr *snapshot*
Example output: -rw-r--r--. 1 root root 10429595648 Aug 16 02:39 snapshot.raw
Paso 7. Almacene la instantánea de la máquina virtual del administrador de clústeres para restaurarla en el futuro.
2. Realice una copia de seguridad de la configuración y la base de datos.
1. config_br.py -a export --all /var/tmp/backup/ATP1_backup_all_$(date +\%Y-\%m-\%d).tar.gz OR 2. config_br.py -a export --mongo-all /var/tmp/backup/ATP1_backup_mongoall$(date +\%Y-\%m-\%d).tar.gz 3. config_br.py -a export --svn --etc --grafanadb --auth-htpasswd --haproxy /var/tmp/backup/ATP1_backup_svn_etc_grafanadb_haproxy_$(date +\%Y-\%m-\%d).tar.gz 4. mongodump - /var/qps/bin/support/env/env_export.sh --mongo /var/tmp/env_export_$date.tgz 5. patches - cat /etc/broadhop/repositories, check which patches are installed and copy those patches to the backup directory /home/stack/CPS_BACKUP on OSPD 6. backup the cronjobs by taking backup of the cron directory: /var/spool/cron/ from the Pcrfclient01/Cluman. Then move the file to CPS_BACKUP on the OSPD.
Verifique desde crontab-l si se necesita alguna otra copia de seguridad.
Transfiera todas las copias de seguridad a OSPD /home/stack/CPS_BACKUP.
3. Copia de seguridad del archivo yaml de ESC principal.
/opt/cisco/esc/confd/bin/netconf-console --host 127.0.0.1 --port 830 -u <admin-user> -p <admin-password> --get-config > /home/admin/ESC_config.xml
Transfiera el archivo en OSPD /home/stack/CPS_BACKUP.
4. Haga una copia de seguridad de las entradas crontab -l.
Cree un archivo de texto con crontab -l y envíelo a una ubicación remota (en OSPD /home/stack/CPS_BACKUP).
5. Tome una copia de seguridad de los archivos de ruta del cliente LB y PCRF.
Collect and scp the configurations from both LBs and Pcrfclients route -n /etc/sysconfig/network-script/route-*
Procedimiento de restauración
Recuperación OSPD
El procedimiento de recuperación OSPD se realiza en base a estas suposiciones.
1. copia de seguridad OSPD está disponible desde el antiguo servidor OSPD.
2. La recuperación OSPD se puede hacer en el nuevo servidor que es el reemplazo del antiguo servidor OSPD en el sistema. .
Recuperación ESC
1. La máquina virtual ESC es recuperable si la máquina virtual está en estado de error o apagado, realice un reinicio completo para activar la máquina virtual afectada. Ejecute estos pasos para recuperar ESC.
2. Identifique la VM que está en estado ERROR o Apagado, una vez identificada reinicie por hardware la VM ESC. En este ejemplo, está reiniciando auto-test-vnfm1-ESC-0.
[root@tb1-baremetal scripts]# nova list | grep auto-test-vnfm1-ESC-
| f03e3cac-a78a-439f-952b-045aea5b0d2c | auto-test-vnfm1-ESC-0 | ACTIVE | - | running | auto-testautovnf1-uas-orchestration=172.31.12.11; auto-testautovnf1-uas-management=172.31.11.3 |
| 79498e0d-0569-4854-a902-012276740bce | auto-test-vnfm1-ESC-1 | ACTIVE | - | running | auto-testautovnf1-uas-orchestration=172.31.12.15; auto-testautovnf1-uas-management=172.31.11.15 |
[root@tb1-baremetal scripts]# [root@tb1-baremetal scripts]# nova reboot --hard f03e3cac-a78a-439f-952b-045aea5b0d2c\
Request to reboot server <Server: auto-test-vnfm1-ESC-0> has been accepted.
[root@tb1-baremetal scripts]#
3. Si se elimina la máquina virtual ESC y debe volver a activarse. Utilice esta secuencia de pasos.
[stack@pod1-ospd scripts]$ nova list |grep ESC-1
| c566efbf-1274-4588-a2d8-0682e17b0d41 | vnf1-ESC-ESC-1 | ACTIVE | - | running | vnf1-UAS-uas-orchestration=172.16.11.14; vnf1-UAS-uas-management=172.16.10.4 |
[stack@pod1-ospd scripts]$ nova delete vnf1-ESC-ESC-1
Request to delete server vnf1-ESC-ESC-1 has been accepted.
4. Si la máquina virtual ESC es irrecuperable y requiere la restauración de la base de datos, restaure la base de datos a partir de la copia de seguridad realizada anteriormente.
5. Para la restauración de la base de datos ESC, debe asegurarse de que el servicio esc se detiene antes de restaurar la base de datos; para ESC HA, ejecute primero en la VM secundaria y, a continuación, en la VM principal.
# service keepalived stop
6. Compruebe el estado del servicio ESC y asegúrese de que todo esté detenido en las VM primarias y secundarias para HA.
# escadm status
7. Ejecute el archivo de comandos para restaurar la base de datos. Como parte de la restauración de la base de datos a la nueva instancia de ESC creada, la herramienta también puede promover una de las instancias para que sea una ESC primaria, montar su carpeta de base de datos en el dispositivo drbd y puede iniciar la base de datos PostgreSQL.
# /opt/cisco/esc/esc-scripts/esc_dbtool.py restore --file scp://<username>:<password>@<backup_vm_ip>:<filename>
8. Reinicie el servicio ESC para completar la restauración de la base de datos. Para la ejecución de HA en ambas VM, reinicie el servicio keepalived.
# service keepalived start
9. Una vez restaurada y ejecutándose correctamente la máquina virtual, asegúrese de que toda la configuración específica de syslog se haya restaurado desde la copia de seguridad anterior conocida y correcta. asegúrese de que se restaure en todas las máquinas virtuales ESC.
[admin@auto-test-vnfm2-esc-1 ~]$
[admin@auto-test-vnfm2-esc-1 ~]$ cd /etc/rsyslog.d
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/00-escmanager.conf
00-escmanager.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/01-messages.conf
01-messages.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/02-mona.conf
02-mona.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.conf
rsyslog.conf
10. Si es necesario reconstruir el ESC a partir de la instantánea de OSPD, utilice este comando con el uso de la instantánea tomada durante la copia de seguridad.
nova rebuild --poll --name esc_snapshot_27aug2018 esc1
11. Compruebe el estado del ESC después de completar la reconstrucción.
nova list --fileds name,host,status,networks | grep esc
12. Compruebe el estado de ESC con este comando.
health.sh
Copy Datamodel to a backup file
/opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli get esc_datamodel/opdata > /tmp/esc_opdata_`date +%Y%m%d%H%M%S`.txt
Cuando ESC no puede iniciar la VM
- En algunos casos, ESC puede fallar al iniciar la VM debido a un estado inesperado. Una solución alternativa es realizar un switchover de ESC reiniciando el ESC principal. El cambio a ESC puede tardar aproximadamente un minuto. Ejecute health.sh en el nuevo ESC principal para verificar que está activo. Cuando el ESC se convierte en principal, el ESC puede corregir el estado de la VM e iniciar la VM. Puesto que esta operación está programada, debe esperar entre 5 y 7 minutos para que se complete.
- Puede supervisar /var/log/esc/yangesc.log y /var/log/esc/escmanager.log. Si NO ve que la VM se recupera después de 5-7 minutos, el usuario tendría que ir y hacer la recuperación manual de las VM afectadas.
- Una vez restaurada y ejecutándose correctamente la máquina virtual, asegúrese de que se haya restaurado toda la configuración específica de syslog desde la copia de seguridad anterior conocida y correcta. Asegúrese de que se restaure en todas las máquinas virtuales ESC
root@abautotestvnfm1em-0:/etc/rsyslog.d# pwd
/etc/rsyslog.d
root@abautotestvnfm1em-0:/etc/rsyslog.d# ll
total 28
drwxr-xr-x 2 root root 4096 Jun 7 18:38 ./
drwxr-xr-x 86 root root 4096 Jun 6 20:33 ../]
-rw-r--r-- 1 root root 319 Jun 7 18:36 00-vnmf-proxy.conf
-rw-r--r-- 1 root root 317 Jun 7 18:38 01-ncs-java.conf
-rw-r--r-- 1 root root 311 Mar 17 2012 20-ufw.conf
-rw-r--r-- 1 root root 252 Nov 23 2015 21-cloudinit.conf
-rw-r--r-- 1 root root 1655 Apr 18 2013 50-default.conf
root@abautotestvnfm1em-0:/etc/rsyslog.d# ls /etc/rsyslog.conf
rsyslog.conf
Recuperación de CPS
Restaure la VM del Administrador de clústeres en OpenStack.
Paso 1. Copie la instantánea de la VM del administrador de clústeres en el blade del controlador como se muestra en este comando:
ls —ltr *snapshot*
Example output: -rw-r--r--. 1 root root 10429595648 Aug 16 02:39 snapshot.raw
Paso 2. Cargue la imagen de instantánea en OpenStack desde el almacén de datos:
glance image-create --name --file --disk-format qcow2 --container-format bare
Paso 3. Verifique si la instantánea se carga con un comando Nova como se muestra en este ejemplo:
nova image-list
Imagen 2: Ejemplo de salida

Paso 4. Dependiendo de si existe o no la VM del administrador de clústeres, puede optar por crear el clúster o reconstruir el clúster:
· Si la instancia de la VM del Administrador de clústeres no existe, cree la VM de Cluster con un comando Heat o Nova, como se muestra en este ejemplo:
Cree la máquina virtual Cluman con ESC.
/opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli edit-config /opt/cisco/esc/cisco-cps/config/gr/tmo/gen/<original_xml_filename>
El clúster PCRF puede originarse con la ayuda del comando anterior y luego restaurar las configuraciones del administrador de clústeres a partir de las copias de seguridad tomadas con config_br.py restore, mongorestore from dump take in backup.
delete - nova boot --config-drive true --image "" --flavor "" --nic net-id=",v4-fixed-ip=" --nic net-id="network_id,v4-fixed-ip=ip_address" --block-device-mapping "/dev/vdb=2edbac5e-55de-4d4c-a427-ab24ebe66181:::0" --availability-zone "az-2:megh-os2-compute2.cisco.com" --security-groups cps_secgrp "cluman"
· Si existe la instancia de la VM del Administrador de clústeres, utilice un comando nova rebuild para reconstruir la instancia de la VM de Cluster con la instantánea cargada, como se muestra a continuación:
nova rebuild <instance_name> <snapshot_image_name>
Por ejemplo:
nova rebuild cps-cluman-5f3tujqvbi67 cluman_snapshot
Paso 5. Enumere todas las instancias como se indica y compruebe que la nueva instancia del gestor de agrupamientos se ha creado y se está ejecutando:
nova list
Imagen 3. Ejemplo de salida

Restaure los parches más recientes en el sistema.
1. Copy the patch files to cluster manager which were backed up in OSPD /home/stack/CPS_BACKUP 2. Login to the Cluster Manager as a root user. 3. Untar the patch by executing this command: tar -xvzf [patch name].tar.gz 4. Edit /etc/broadhop/repositories and add this entry: file:///$path_to_the plugin/[component name] 5. Run build_all.sh script to create updated QPS packages: /var/qps/install/current/scripts/build_all.sh 6. Shutdown all software components on the target VMs: runonall.sh sudo monit stop all 7. Make sure all software components are shutdown on target VMs: statusall.sh
Nota: Todos los componentes de software deben mostrar No supervisado como estado actual.
8. Update the qns VMs with the new software using reinit.sh script: /var/qps/install/current/scripts/upgrade/reinit.sh 9. Restart all software components on the target VMs: runonall.sh sudo monit start all 10. Verify that the component is updated, run: about.sh
Restaure los Cronjobs.
1. Mueva el archivo de respaldo de OSPD a Cluman/Pcrfclient01.
2. Ejecute el comando para activar el cronjob desde la copia de seguridad.
#crontab Cron-backup
3. Verifique si los trabajos de crono han sido activados por este comando.
#crontab -l
Restaure las VM individuales del clúster.
Para volver a implementar la máquina virtual pcrfclient01:
Paso 1. Inicie sesión en la máquina virtual del administrador de clústeres como usuario raíz.
Paso 2. Recordar el UUID del repositorio SVN usando este comando:
svn info http://pcrfclient02/repos | grep UUID
El comando puede generar el UUID del repositorio.
Por ejemplo: UUID del repositorio: ea50bbd2-5726-46b8-b807-10f4a7424f0e
Paso 3. Importe la copia de seguridad de los datos de configuración del Creador de políticas en el Administrador de clústeres, como se muestra en este ejemplo:
config_br.py -a import --etc-oam --svn --stats --grafanadb --auth-htpasswd --users /mnt/backup/oam_backup_27102016.tar.gz
Nota: muchas implementaciones ejecutan un trabajo cron que realiza copias de seguridad de los datos de configuración de forma regular. Consulte Copia de seguridad del repositorio de Subversion para más detalles.
Paso 4. Para generar los archivos de almacenamiento de VM en el Administrador de clústeres con las configuraciones más recientes, ejecute este comando:
/var/qps/install/current/scripts/build/build_svn.sh
Paso 5. Para implementar la máquina virtual pcrfclient01, realice una de estas acciones:
En OpenStack, utilice la plantilla HEAT o el comando Nova para volver a crear la máquina virtual. Para obtener más información, consulte la Guía de instalación de CPS para OpenStack.
Paso 6. Vuelva a establecer la sincronización primaria/secundaria SVN entre pcrfclient01 y pcrfclient02 con pcrfclient01 como el principal mediante la ejecución de esta serie de comandos.
Si SVN ya está sincronizado, no ejecute estos comandos.
Para verificar si SVN está sincronizado, ejecute este comando desde pcrfclient02.
Si se devuelve un valor, SVN ya está sincronizado:
/usr/bin/svn propget svn:sync-from-url --revprop -r0 http://pcrfclient01/repos
Ejecute estos comandos desde pcrfclient01:
/bin/rm -fr /var/www/svn/repos /usr/bin/svnadmin create /var/www/svn/repos /usr/bin/svn propset --revprop -r0 svn:sync-last-merged-rev 0 http://pcrfclient02/repos-proxy-sync /usr/bin/svnadmin setuuid /var/www/svn/repos/ "Enter the UUID captured in step 2" /etc/init.d/vm-init-client / var/qps/bin/support/recover_svn_sync.sh
Paso 7. Si pcrfclient01 es también la máquina virtual del árbitro, ejecute estos pasos:
a) Crear los scripts de inicio/detención de mongodb basados en la configuración del sistema. No todas las implementaciones tienen configuradas todas estas bases de datos.
Nota: Consulte /etc/broadhop/mongoConfig.cfg para determinar qué bases de datos deben configurarse.
cd /var/qps/bin/support/mongo build_set.sh --session --create-scripts build_set.sh --admin --create-scripts build_set.sh --spr --create-scripts build_set.sh --balance --create-scripts build_set.sh --audit --create-scripts build_set.sh --report --create-scripts
b) Iniciar el proceso mongo:
/usr/bin/systemctl start sessionmgr-XXXXX
c) Espere a que se inicie el árbitro y, a continuación, ejecute diagnostics.sh —get_replica_status para comprobar el estado del conjunto de réplicas.
Para volver a implementar la máquina virtual pcrfclient02:
Paso 1. Inicie sesión en la máquina virtual del administrador de clústeres como usuario raíz.
Paso 2. Para generar los archivos de almacenamiento de VM en el Administrador de clústeres con las configuraciones más recientes, ejecute este comando:
/var/qps/install/current/scripts/build/build_svn.sh
Paso 3. Para implementar la máquina virtual pcrfclient02, realice una de estas acciones:
En OpenStack, utilice la plantilla HEAT o el comando Nova para volver a crear la máquina virtual. Para obtener más información, consulte la Guía de instalación de CPS para OpenStack.
Paso 4. Secure shell to the pcrfclient01:
ssh pcrfclient01
Paso 5. Ejecute este script para recuperar los repos de SVN de pcrfclient01:
/var/qps/bin/support/recover_svn_sync.sh
Para volver a implementar una máquina virtual sessionManager:
Paso 1. Inicie sesión en la máquina virtual del administrador de clústeres como usuario raíz.
Paso 2. Para implementar la máquina virtual sessionmgr y reemplazar la máquina virtual dañada o que ha fallado, realice una de estas acciones:
En OpenStack, utilice la plantilla HEAT o el comando Nova para volver a crear la máquina virtual. Para obtener más información, consulte la Guía de instalación de CPS para OpenStack.
Paso 3. Cree los scripts de inicio/detención de mongodb basados en la configuración del sistema.
No todas las implementaciones tienen configuradas todas estas bases de datos. Consulte /etc/broadhop/mongoConfig.cfg para determinar qué bases de datos deben configurarse.
cd /var/qps/bin/support/mongo build_set.sh --session --create-scripts build_set.sh --admin --create-scripts build_set.sh --spr --create-scripts build_set.sh --balance --create-scripts build_set.sh --audit --create-scripts build_set.sh --report --create-scripts
Paso 4. Proteja el shell en la máquina virtual sessionmgr e inicie el proceso mongo:
ssh sessionmgrXX /usr/bin/systemctl start sessionmgr-XXXXX
Paso 5. Espere a que se inicien los miembros y a que se sincronicen los miembros secundarios y, a continuación, ejecute diagnostics.sh —get_replica_status para comprobar el estado de la base de datos.
Paso 6. Para restaurar la base de datos de Session Manager, utilice uno de estos comandos de ejemplo, dependiendo de si la copia de seguridad se realizó con la opción —mongo-all o —mongo:
• config_br.py -a import --mongo-all --users /mnt/backup/Name of backup or • config_br.py -a import --mongo --users /mnt/backup/Name of backup
Para volver a implementar la VM de Director de políticas (equilibrador de carga):
Paso 1. Inicie sesión en la máquina virtual del administrador de clústeres como usuario raíz.
Paso 2. Para importar la copia de seguridad de los datos de configuración del Generador de directivas en el Administrador de clústeres, ejecute este comando:
config_br.py -a import --network --haproxy --users /mnt/backup/lb_backup_27102016.tar.gz
Paso 3. Para generar los archivos de almacenamiento de VM en el Administrador de clústeres con las configuraciones más recientes, ejecute este comando:
/var/qps/install/current/scripts/build/build_svn.sh
Paso 4. Para implementar la máquina virtual lb01, realice una de estas acciones:
En OpenStack, utilice la plantilla HEAT o el comando Nova para volver a crear la máquina virtual. Para obtener más información, consulte la Guía de instalación de CPS para OpenStack.
Para volver a implementar la máquina virtual de Policy Server (QNS):
Paso 1. Inicie sesión en la máquina virtual del administrador de clústeres como usuario raíz.
Paso 2. Importe la copia de seguridad de los datos de configuración del Creador de políticas en el Administrador de clústeres, como se muestra en este ejemplo:
config_br.py -a import --users /mnt/backup/qns_backup_27102016.tar.gz
Paso 3. Para generar los archivos de almacenamiento de VM en el Administrador de clústeres con las configuraciones más recientes, ejecute este comando:
/var/qps/install/current/scripts/build/build_svn.sh
Paso 4. Para implementar la máquina virtual qns, realice una de estas acciones:
En OpenStack, utilice la plantilla HEAT o el comando Nova para volver a crear la máquina virtual. Para obtener más información, consulte la Guía de instalación de CPS para OpenStack.
Procedimiento general para restaurar la base de datos.
Paso 1. Ejecute este comando para restaurar la base de datos:
config_br.py –a import --mongo-all /mnt/backup/backup_$date.tar.gz where $date is the timestamp when the export was made.
Por ejemplo,
config_br.py –a import --mongo-all /mnt/backup/backup_27092016.tgz
Paso 2. Inicie sesión en la base de datos y compruebe si se está ejecutando y si es accesible:
1. Inicie sesión en el administrador de sesiones:
mongo --host sessionmgr01 --port $port
donde $port es el número de puerto de la base de datos que se va a comprobar. Por ejemplo, 27718 es el puerto Balance predeterminado.
2. Muestre la base de datos ejecutando este comando:
show dbs
3. Cambie el shell mongo a la base de datos ejecutando este comando:
use $db
donde $db es un nombre de base de datos que se muestra en el comando anterior.
El comando use cambia el shell mongo a esa base de datos.
Por ejemplo,
use balance_mgmt
4. Para mostrar las recopilaciones, ejecute este comando:
show collections
5. Para mostrar el número de registros de la recopilación, ejecute este comando:
db.$collection.count() For example, db.account.count()
El ejemplo anterior puede mostrar el número de registros de la cuenta de recopilación en la base de datos Balance (balance_mgmt).
Restauración del Repositorio de Subversion.
Para restaurar los datos de configuración de Policy Builder desde una copia de seguridad, ejecute este comando:
config_br.py –a import --svn /mnt/backup/backup_$date.tgz where, $date is the date when the cron created the backup file.
Restaurar panel de Grafana.
Puede restaurar el tablero de Grafana usando este comando:
config_br.py -a import --grafanadb /mnt/backup/
Validando la restauración.
Después de restaurar los datos, verifique el sistema en funcionamiento ejecutando este comando:
/var/qps/bin/diag/diagnostics.sh
Historial de revisiones
| Revisión | Fecha de publicación | Comentarios |
|---|---|---|
2.0 |
20-Mar-2024
|
Título actualizado, Introducción, Texto alternativo, Traducción automática, Requisitos de estilo y formato. |
1.0 |
21-Sep-2018
|
Versión inicial |
Con la colaboración de ingenieros de Cisco
- Aaditya DeodharCisco Advanced Services
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)