Resolución de Problemas cuando el Administrador de Elementos se ejecuta en Modo Independiente
Opciones de descarga
-
ePub (190.6 KB)
Visualice en diferentes aplicaciones en iPhone, iPad, Android, Sony Reader o Windows Phone -
Mobi (Kindle) (191.9 KB)
Visualice en dispositivo Kindle o aplicación Kindle en múltiples dispositivos
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Contenido
Introducción
Este documento proporciona un resumen sobre cómo resolver problemas cuando el gestor de elementos se ejecuta en modo independiente.
Prerequisites
Requirements
Cisco recomienda que tenga conocimiento sobre estos temas:
- StarOs
- Arquitectura básica Ultra M
Componentes Utilizados
La información en este documento se basa en la versión Ultra 5.1.x.
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. Si tiene una red en vivo, asegúrese de entender el posible impacto de cualquier comando.
Antecedentes
Ultra-M es una solución de núcleo de paquetes móviles virtualizada validada y empaquetada previamente diseñada para simplificar la implementación de VNF. OpenStack es el Virtualized Infrastructure Manager (VIM) para Ultra-M y consta de estos tipos de nodos:
- Informática
- Disco de almacenamiento de objetos - Compute (OSD - Compute)
- Controlador
- Plataforma OpenStack: Director (OSPD)
La arquitectura de alto nivel de Ultra-M y los componentes involucrados se ilustran en esta imagen:
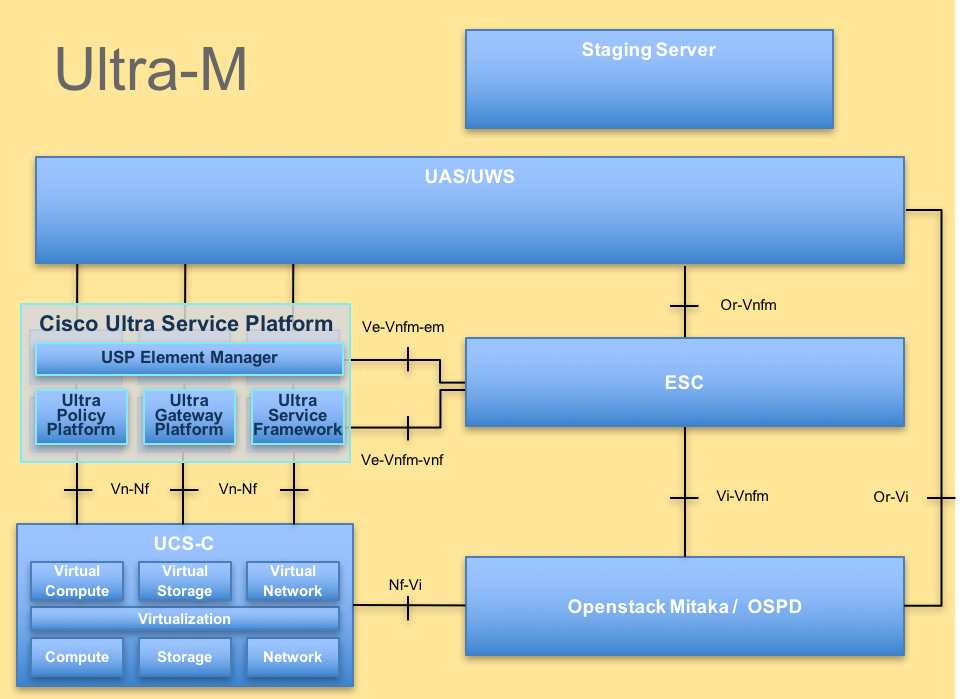 Arquitectura UltraM
Arquitectura UltraM
Este documento está dirigido al personal de Cisco familiarizado con la plataforma Cisco Ultra-M y detalla los pasos necesarios para llevarse a cabo en el nivel VNF de OpenStack y StarOS en el momento del reemplazo del servidor controlador.
Abreviaturas
Estas abreviaturas se utilizan en este artículo:
| VNF | Función de red virtual |
| EM | Administrador de elementos |
| VIP | Dirección IP virtual |
| CLI | Línea de comandos |
Problema: EM puede terminar en este estado como parece desde Ultra M Health Manager
EM: 1 is not part of HA-CLUSTER,EM is running in standalone mode
Depende de la versión, puede haber 2 o 3 EM que se ejecuten en el sistema.
En el caso de que tenga implementada 3 EM, dos de ellas funcionarían y la tercera, sólo para poder tener el clúster Zookeeper. Sin embargo, no se utiliza.
En caso de que uno de los dos EM funcionales no funcione o no sea accesible, el EM en funcionamiento estaría en modo autónomo.
En caso de que haya implementado 2 EM, en caso de que uno de ellos no funcione o no esté disponible, el resto de EM puede estar en modo independiente.
Este documento explica qué buscar si esto sucede y cómo recuperarse.
Solución de problemas y pasos de recuperación
Paso 1. Verifique el estado de los EM.
Conéctese al VIP de EM y verifique que el nodo se encuentre en este estado:
root@em-0:~# ncs_cli -u admin -C
admin connected from 127.0.0.1 using console on em-0
admin@scm# show ems
EM VNFM ID SLA SCM PROXY
3 up down up
admin@scm#
Así que, desde aquí, pueden ver que sólo hay una entrada en SCM - y esa es la entrada para nuestro nodo.
Si consigue conectarse con el otro EM, puede ver algo como:
root@em-1# ncs_cli -u admin -C admin connected from 127.0.0.1 using
admin connected from 127.0.0.1 using console on em-1
admin@scm# show ems
% No entries found.
Según cuál sea el problema en el EM, no se puede acceder a la CLI de NCS o se puede reiniciar el nodo.
Paso 2. Verifique los Logs en /var/log/em en el Nodo que no se Une al Clúster.
Verifique los registros en el nodo en el estado del problema. Por lo tanto, para la muestra mencionada, usted navegaría los registros em-1 /var/log/em/zookeeper:
...
2018-02-01 09:52:33,591 [myid:4] - INFO [main:QuorumPeerMain@127] - Starting quorum peer
2018-02-01 09:52:33,619 [myid:4] - INFO [main:NIOServerCnxnFactory@89] - binding to port 0.0.0.0/0.0.0.0:2181
2018-02-01 09:52:33,627 [myid:4] - INFO [main:QuorumPeer@1019] - tickTime set to 3000
2018-02-01 09:52:33,628 [myid:4] - INFO [main:QuorumPeer@1039] - minSessionTimeout set to -1
2018-02-01 09:52:33,628 [myid:4] - INFO [main:QuorumPeer@1050] - maxSessionTimeout set to -1
2018-02-01 09:52:33,628 [myid:4] - INFO [main:QuorumPeer@1065] - initLimit set to 5
2018-02-01 09:52:33,641 [myid:4] - INFO [main:FileSnap@83] - Reading snapshot /var/lib/zookeeper/data/version-2/snapshot.5000000b3
2018-02-01 09:52:33,665 [myid:4] - ERROR [main:QuorumPeer@557] - Unable to load database on disk
java.io.IOException: The current epoch, 5, is older than the last zxid, 25769803777
at org.apache.zookeeper.server.quorum.QuorumPeer.loadDataBase(QuorumPeer.java:539)
at org.apache.zookeeper.server.quorum.QuorumPeer.start(QuorumPeer.java:500)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.runFromConfig(QuorumPeerMain.java:153)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.initializeAndRun(QuorumPeerMain.java:111)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.main(QuorumPeerMain.java:78)
2018-02-01 09:52:33,671 [myid:4] - ERROR [main:QuorumPeerMain@89] - Unexpected exception, exiting abnormally
java.lang.RuntimeException: Unable to run quorum server
at org.apache.zookeeper.server.quorum.QuorumPeer.loadDataBase(QuorumPeer.java:558)
at org.apache.zookeeper.server.quorum.QuorumPeer.start(QuorumPeer.java:500)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.runFromConfig(QuorumPeerMain.java:153)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.initializeAndRun(QuorumPeerMain.java:111)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.main(QuorumPeerMain.java:78)
Caused by: java.io.IOException: The current epoch, 5, is older than the last zxid, 25769803777
at org.apache.zookeeper.server.quorum.QuorumPeer.loadDataBase(QuorumPeer.java:539)
Paso 3. Verificar que exista instantánea en cuestión.
Navegue hasta /var/lib/zookeeper/data/version-2 y verifique que la instantánea que está siendo roja en el paso 2 esté presente.
300000042 log.500000001 snapshot.300000041 snapshot.40000003b
ubuntu@em-1:/var/lib/zookeeper/data/version-2$ ls -la
total 424
drwxrwxr-x 2 zk zk 4096 Jan 30 12:12 .
drwxr-xr-x 3 zk zk 4096 Feb 1 10:33 ..
-rw-rw-r-- 1 zk zk 1 Jan 30 12:12 acceptedEpoch
-rw-rw-r-- 1 zk zk 1 Jan 30 12:09 currentEpoch
-rw-rw-r-- 1 zk zk 1 Jan 30 12:12 currentEpoch.tmp
-rw-rw-r-- 1 zk zk 67108880 Jan 9 20:11 log.300000042
-rw-rw-r-- 1 zk zk 67108880 Jan 30 10:45 log.400000024
-rw-rw-r-- 1 zk zk 67108880 Jan 30 12:09 log.500000001
-rw-rw-r-- 1 zk zk 67108880 Jan 30 12:11 log.5000000b4
-rw-rw-r-- 1 zk zk 69734 Jan 6 05:14 snapshot.300000041
-rw-rw-r-- 1 zk zk 73332 Jan 29 09:21 snapshot.400000023
-rw-rw-r-- 1 zk zk 73877 Jan 30 11:43 snapshot.40000003b
-rw-rw-r-- 1 zk zk 84116 Jan 30 12:09 snapshot.5000000b3 ---> HERE, you see it
ubuntu@em-1:/var/lib/zookeeper/data/version-2$
Paso 4. Pasos de recuperación.
1. Habilite el modo debug para que EM detenga el reinicio.
ubuntu@em-1:~$ sudo /opt/cisco/em-scripts/enable_debug_mode.sh
Es posible que sea necesario reiniciar la máquina virtual una vez más (se haría automáticamente, no es necesario hacer nada)
2. Mueva los datos del zookeeper.
En la carpeta /var/lib/zookeeper/data hay la carpeta llamada version-2 que tiene la instantánea de la base de datos. El error anterior señala la falla de carga para que lo elimine.
ubuntu@em-1:/var/lib/zookeeper/data$ sudo mv version-2 old ubuntu@em-1:/var/lib/zookeeper/data$ ls -la total 20 .... -rw-r--r-- 1 zk zk 2 Feb 1 10:33 myid drwxrwxr-x 2 zk zk 4096 Jan 30 12:12 old --> so you see now old folder and you do not see version-2 -rw-rw-r-- 1 zk zk 4 Feb 1 10:33 zookeeper_server.pid ..
3. Reinicie el nodo.
sudo reboot
4. Inhabilite de nuevo el modo de depuración.
ubuntu@em-1:~$ sudo /opt/cisco/em-scripts/disable_debug_mode.sh
Estos pasos harán que el servicio vuelva a estar en la EM problemática.
Con la colaboración de ingenieros de Cisco
- Snezana MitrovicCisco TAC Engineer
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)