Qué es el clúster de Expressway y cómo funciona
Opciones de descarga
-
ePub (935.3 KB)
Visualice en diferentes aplicaciones en iPhone, iPad, Android, Sony Reader o Windows Phone -
Mobi (Kindle) (838.4 KB)
Visualice en dispositivo Kindle o aplicación Kindle en múltiples dispositivos
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Contenido
Introducción
Este documento describe cómo se diseñan los clústeres de Expressway para ampliar la resistencia y la capacidad de una instalación de Expressway.
Antecedentes
Capacidad. El clúster de Expressway puede aumentar la capacidad de una implementación de Expressway por un factor máximo de cuatro, en comparación con un solo Expressway. Los pares de Expressway de un clúster comparten el uso de ancho de banda, así como el enrutamiento, la zona, FindMe y otra configuración.
Resistencia. El clúster de Expressway puede proporcionar redundancia mientras Expressway se encuentra en modo de mantenimiento o en caso de que no se pueda acceder a él debido a una red o a una interrupción del suministro eléctrico, o por otro motivo. Los extremos pueden registrarse en cualquiera de los pares de un clúster. Si los extremos pierden la conexión con su par inicial, pueden volver a registrarse en otro del clúster.
Especificaciones
Expressway puede formar parte de un clúster de hasta seis Expressway. Cuando crea un clúster, designa un par como el principal, desde el cual su configuración se replica a los otros pares. Todos los pares de Expressway del clúster deben tener las mismas capacidades de enrutamiento. Si cualquier Expressway puede enrutar una llamada a un destino, se supone que todos los pares de Expressway de ese clúster pueden enrutar una llamada a ese destino.
Capacidad
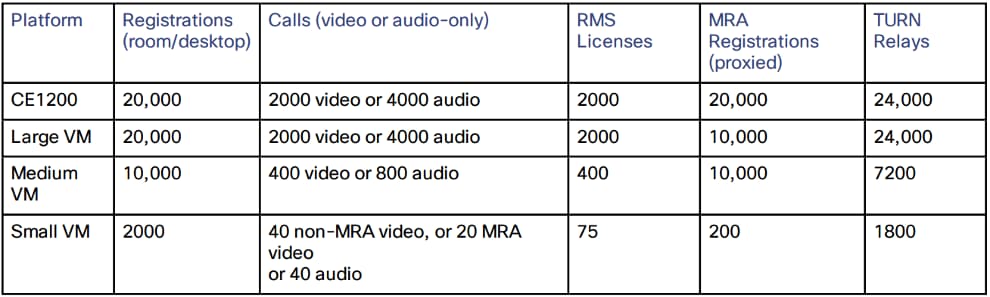
No hay aumento de capacidad después de cuatro iguales. Por lo tanto, en un clúster de seis pares, por ejemplo, la quinta y sexta Expressway no agregan capacidad de llamada adicional al clúster. La resistencia se mejora con los pares adicionales, pero no con la capacidad.
- En el caso de las máquinas virtuales pequeñas (VM), el clúster es solo para redundancia y no para escalabilidad, y no se obtiene ninguna ganancia de capacidad del clúster.
- En la siguiente imagen se muestra la configuración del clúster basada en la capacidad en 4 pares:
Elementos importantes de la página

Requirements
- Conocimientos básicos de Secure Shell (SSH)
- Un clúster debe contener sólo nodos de Expressway-C o sólo nodos de Expressway-E.
- Todos los pares deben utilizar la misma versión de software.
- Todos los pares utilizan una plataforma de hardware, un dispositivo o una máquina virtual (VM), con capacidades equivalentes.
- Expressway admite un retraso de ida y vuelta de hasta 80 ms.
- El modo H323 está habilitado en cada par.
- Todos los pares tienen instalado el mismo conjunto de claves de opción, con las siguientes excepciones:
- Para Video Control Server (VCS): Licencias de llamadas transversales y no transversales
- Para Expressway: Sesiones multimedia
- Para Expressway: Licencias de registro de sistema de sala y sistema de escritorio
Todas las demás claves de licencia deben ser idénticas en cada par.
- No debe haber traducción de direcciones de red (NAT) entre los pares del clúster.
Nota: Si Expressway-E utiliza un único controlador de interfaz de red (NIC), debe usar una IP pública. Si Expressway-E utiliza una NIC dual, se debe utilizar la interfaz interna para crear el clúster.
- Se debe configurar la dirección IP, el servicio de nombres de dominio (DNS) y el protocolo de tiempo de la red (NTP).
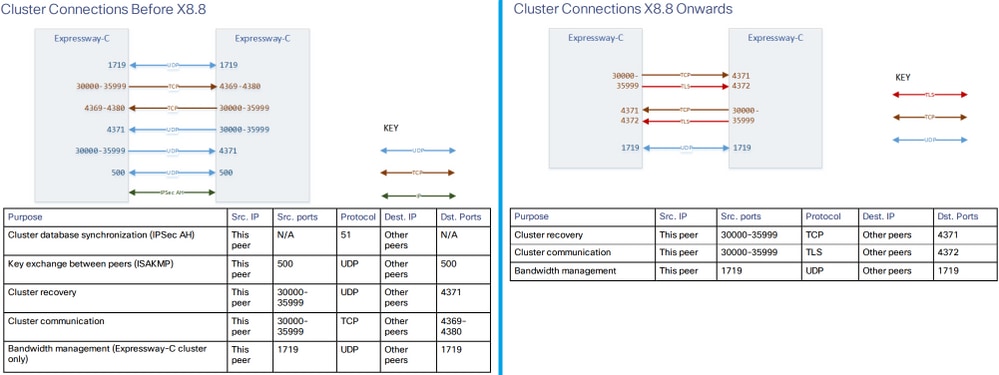
Conexiones y puertos del clúster
Configuraciones
Crear un nuevo clúster
- Abra la interfaz web de Expressway.
- Vaya a System > Clustering.
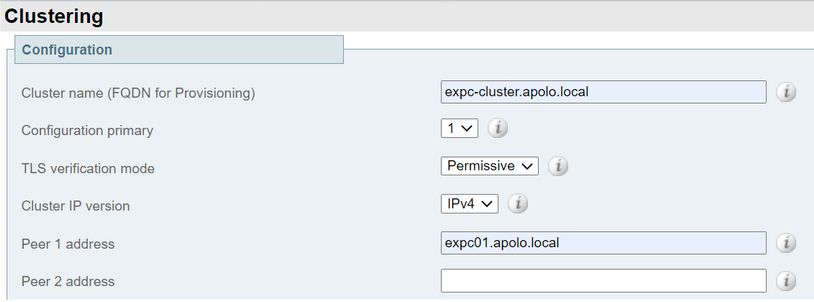
- Introduzca los siguientes valores:
Nota: Primero debe crear un clúster de un par (primario) y reiniciar el primario, antes de agregar otros pares. Puede agregar más pares después de haber establecido un clúster de uno.
Configuración principal: 1
Versión de IP del clúster: Elija IPv4 o IPv6 para que coincida con el esquema de direcciones de red.
Opciones del modo de verificación TLS: Permiso (valor predeterminado) o Aplicar.
Permisivo significa que los pares no validan los certificados de los demás cuando se establecen las conexiones de seguridad de la capa de transporte (TLS) dentro del clúster.
La aplicación es más segura, pero requiere que cada par tenga un certificado válido y que todos los demás pares confíen en la Autoridad de certificación (CA).
Dirección de par 1: Introduzca la dirección de esta Expressway (el par principal). Si el modo de verificación TLS está establecido en Aplicar, debe especificar un nombre de dominio completo (FQDN) que coincida con el nombre común (CN) del sujeto o un nombre alternativo del sujeto (SAN) en el certificado de este par.
- Seleccione Guardar.
- Reiniciar el servidor.
- Navegue hasta Mantenimiento > Opciones de reinicio, luego seleccione Reiniciar y confirme Aceptar.
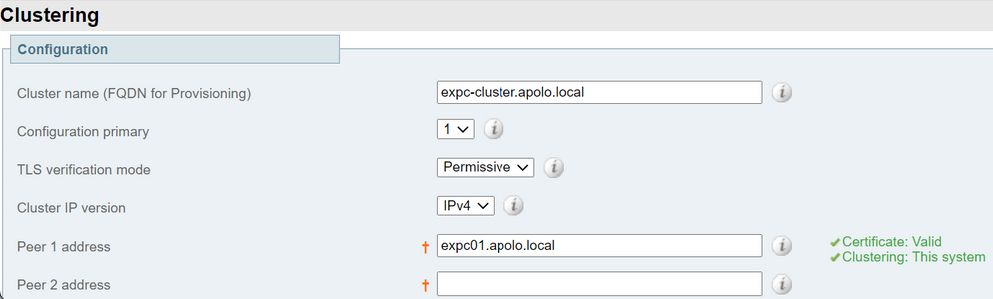
- Valide que el certificado es válido, como se muestra en la siguiente imagen:
Agregar pares adicionales al clúster
Para agregar un par adicional, siga los siguientes pasos:
- Vaya a System > Clustering en Expressway principal.
- En el primer campo vacío, introduzca la dirección del nuevo par de Expressway.
- Seleccione Guardar.
- El Peer 1 debe indicar Este sistema. El nuevo peer debe indicar Unknown y luego con una actualización debe indicar Failed porque aún no se ha unido completamente al cluster.
- Navegue hasta System > Clustering en uno de los peers subordinados que ya están en el cluster, y edite los siguientes campos:

- Repita el paso anterior para cada uno de los pares subordinados que ya están en el clúster.
- Seleccione Guardar.
- Expressway genera una alarma de falla de comunicación de clúster. La alarma se borra después del reinicio necesario.
- Reinicie Expressway.
- Después del reinicio, espere aproximadamente 2 minutos; esta es la frecuencia con la que se copia la configuración desde la configuración primaria.
- Valide el estado de la base de datos del clúster.

- Asegúrese de que la configuración se replique en un par subordinado.

Aplicar verificación TLS
Precaución: Antes de continuar, compruebe que las SAN de certificado contienen los FQDN que se encuentran en los campos de dirección N del par. Debe ver mensajes de estado verdes para el clúster y el certificado junto a cada campo de dirección antes de continuar.


- En el peer primario, establezca el modo de verificación TLS en Enforce.
Precaución: Se muestra una advertencia si algún certificado no es válido e impide que el clúster funcione correctamente en el modo de verificación TLS forzada.
- El nuevo modo de verificación de TLS se replica en todo el clúster.
- Verifique que el modo de verificación de TLS esté ahora Enforce en el otro par.
- Seleccione Save y reinicie el par principal.
- Una vez que el par primario esté nuevamente en línea, reinicie cada par uno por uno.
- Espere a que el clúster se estabilice y valide que el estado de Agrupación en clústeres y Certificado es verde para todos los pares.

Cambiar el par principal
Nota: Puede realizar este proceso incluso si no se puede acceder al par principal actual.
- En la nueva Expressway principal, navegue hasta System > Clustering.
- En el menú desplegable Configuration primary, seleccione el número de ID de la entrada de peer que dice This system.
- Seleccione Guardar.
Nota: Mientras se realiza este proceso, ignore las alarmas de Expressway que informen de la discordancia principal del clúster o del error de replicación del clúster.
- En todos los demás pares de Expressway, comience con el par principal antiguo (si aún está accesible).
- Vaya a System > Clustering.
- En el menú desplegable Configuration primary, seleccione el número de ID de la nueva Expressway principal.
- Seleccione Guardar.
- Confirme que se ha aceptado el cambio en la configuración principal, navegue hasta System > Clustering y actualice la página.
- Si alguna Expressway no ha aceptado el cambio, repita el mismo procedimiento.
- Valide que el estado de la base de datos del clúster sea Activo.
Cambiar clúster para usar FQDN
Nota: Mientras se realiza este procedimiento, las comunicaciones entre peers se ven afectadas temporalmente, esto significa que se espera ver alarmas que persisten hasta que los cambios se completen y el clúster acuerde las nuevas direcciones.
- Inicie sesión en todos los pares del clúster y navegue hasta System > Clustering.
- Elija qué dirección de peer se cambia. se recomienda comenzar con la dirección del par 1.
- En cada par del clúster, siga el siguiente procedimiento:
- Cambie el campo de dirección de peer elegido de la dirección IP a su FQDN.
- Seleccione Guardar.
- Cambie al par identificado por la dirección de par cambiada y reinicie el servidor.
- Espere a que se resuelvan las alarmas de clúster transitorias.
- Elija la siguiente dirección de peer que desea cambiar y, a continuación, repita los pasos 3 - 7.
- Repita este procedimiento hasta que haya cambiado todas las direcciones de peer y reiniciado todos los peers.
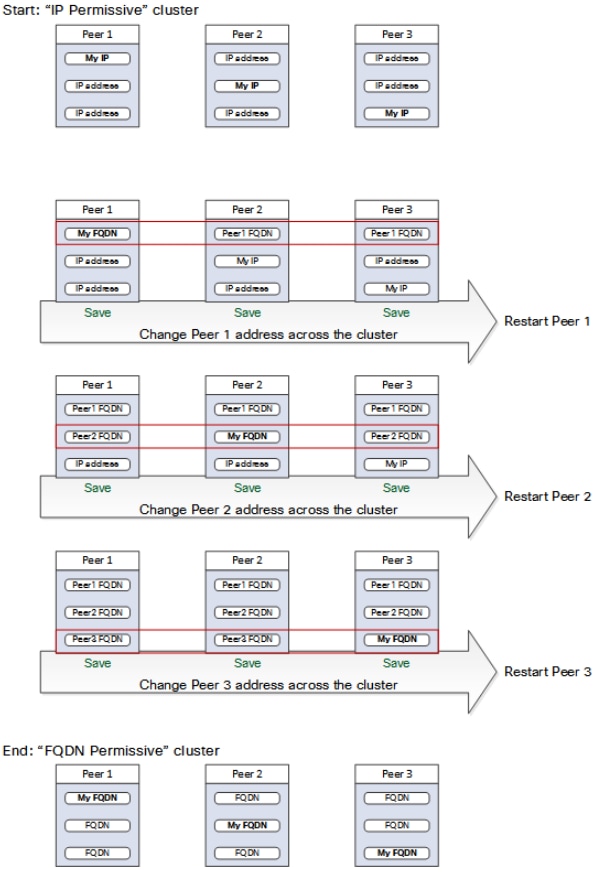
Asignación de direcciones de clúster para Expressway-E
Para implementaciones seguras como Mobile and Remote Access (MRA), cada par de Expressway-E debe tener un certificado con una SAN que contenga su FQDN público. El FQDN se asigna en el DNS público a la dirección IP pública de Expressway-E.
Nota: Si simplemente desea agrupar en clúster los pares de Cisco Expressway-E y no necesita la verificación de TLS entre ellos, puede formar el clúster con las direcciones IP privadas de los nodos. No es necesario el clúster de asignación de direcciones.
Las asignaciones de direcciones de clúster son pares FQDN:IP que se comparten alrededor del clúster, un par para cada par. Los peers consultan la Tabla de mapeo antes de consultar DNS y, si encuentran una coincidencia, no consultan DNS.
Si decide aplicar TLS, los pares también deben leer los nombres del campo SAN de los certificados de los demás y comparar cada nombre con el lado FQDN de la asignación.
Se recomienda encarecidamente que introduzca las asignaciones en el par principal. Las asignaciones de direcciones se replican dinámicamente a través del clúster. Para configurar el Mapping de Direcciones, siga el siguiente procedimiento:
- Cambie a System > Clustering en el peer primario y cambie el menú desplegable Cluster address mapping enabled a On (el valor predeterminado es Off). Se muestran los campos Asignación de direcciones de clúster.
- Edite las asignaciones para que los FQDN públicos de los pares de Expressway-E correspondan con las direcciones IP de sus NIC internas.
- Seleccione Guardar.

Precaución: No intente utilizar el DNS público para asignar los FQDN públicos de los pares a sus direcciones IP privadas, esta acción puede interrumpir la conectividad externa.
Clúster con NIC única
Si desea que los pares de Expressway-E de un clúster comprueben las identidades de los demás con certificados, puede permitir que utilicen DNS para resolver los FQDN de los pares del clúster en sus direcciones IP públicas. Esta es una manera perfectamente aceptable de formar un clúster si los nodos de Expressway-E tienen:
- Sólo una NIC
- No hay NAT estática configurada
- Direcciones IP enrutables
Resolución de problemas
¿Qué activa un restablecimiento de fábrica?
Si borra todos los campos de dirección de peer de la página de clustering y guarda la configuración, Expressway realiza un restablecimiento de fábrica de forma predeterminada la próxima vez que reinicie el sistema. Esto significa que se elimina toda la configuración, excepto la configuración de red básica para la interfaz de red de área local 1 (LAN1), que incluye toda la configuración realizada después de borrar los campos y el siguiente reinicio.
Consejo: Si necesita evitar el restablecimiento de fábrica, restaure los campos de dirección del par del clúster. Reemplace las direcciones de peer originales en el mismo orden y luego guarde la configuración para borrar el banner.
El restablecimiento de fábrica se activa automáticamente cuando se reinicia el par, para eliminar los datos confidenciales y la configuración del clúster. El restablecimiento borra toda la configuración excepto la siguiente información básica de red:
Nota: Si utiliza la opción de NIC dual, tenga en cuenta que cualquier configuración de LAN2 se elimina por completo mediante el restablecimiento.
- Direcciones IP · Cuentas y contraseñas de administrador y raíz
- claves SSH
- Teclas de opción
- Acceso seguro al protocolo de transferencia de hipertexto (HTTPS) habilitado
- Acceso SSH habilitado
Nota: A partir de la versión X12.6, el restablecimiento de fábrica quita del par el certificado del servidor, la clave privada asociada y la configuración del almacén de confianza de la CA. En versiones anteriores del software Expressway, esta configuración se conserva.
Fallo de restablecimiento de fábrica
El restablecimiento de fábrica puede fallar, esto puede suceder si Expressway es una instalación nueva de Open Virtualization Appliance (OVA) y no se ha actualizado.
Para solucionar este problema, siga cualquiera de las siguientes opciones:
- Actualice todos los nodos a la misma versión de software con el archivo tar.gz. Al final del proceso de actualización, reinicie el servidor, lo que activará el restablecimiento de fábrica.
- Cargue el archivo tar.gz directamente en la carpeta de restablecimiento de fábrica con WinSCP (/mnt/harddisk/factory-reset/). A continuación, reinicie para iniciar el restablecimiento de fábrica o ejecute el restablecimiento de fábrica desde la CLI.
Nota: Asegúrese de realizar las copias de seguridad adecuadas antes de realizar una actualización, cambiar el certificado o cuando aparezca una advertencia de restablecimiento de fábrica.
Secuencia de reinicio
Si es necesario reiniciar el clúster o cualquier par, siga los siguientes pasos:
- Reinicie el par principal y espere a que se pueda acceder a través de la interfaz web.
- Validar el estado de replicación del clúster en el primario y el estado de todos los pares. Espere unos minutos, actualice las interfaces web del par ocasionalmente.
- Reinicie otros pares, si es necesario, de uno en uno. Cada vez, espere unos minutos después de que esté accesible y valide su estado de replicación.
Nota: Es posible que deba esperar unos 5 minutos después de realizar cualquier cambio de clúster para que los pares de Expressway notifiquen el estado correcto.
Alarmas y advertencias
Las alarmas de los errores de clúster se muestran en el formato: Error de replicación del clúster: (detalles) es necesaria la sincronización manual de la configuración, a continuación se muestran algunos ejemplos:
- Error de replicación del clúster: se requiere la sincronización manual de la configuración.
- Error de replicación del clúster: no se puede encontrar el archivo de configuración principal o del mismo nivel de este subordinado, se requiere la sincronización manual de la configuración.
- Error de replicación del clúster: la ID principal de la configuración es incoherente; se requiere la sincronización manual de la configuración.
- Error de replicación del clúster: la configuración de este par entra en conflicto con la configuración del primario; se requiere la sincronización manual de la configuración.
Si una Expressway subordinada informa la alarma mencionada, siga el siguiente procedimiento:
- Inicie sesión como admin en un SSH u otra interfaz CLI.
- Ejecute el siguiente comando: xcommand ForceConfigUpdate
Nota: Asegúrese de realizar las copias de seguridad adecuadas antes de realizar una actualización, cambiar el certificado o cuando aparezca una advertencia de restablecimiento de fábrica.
- Este comando elimina la configuración de Expressway subordinada y, a continuación, la obliga a actualizar su configuración desde Expressway principal.
Si el problema persiste, podría estar relacionado con la clave de cifrado por peer de clúster. Suele ocurrir cuando los pares se actualizan en el orden incorrecto, los pares subordinados no se sincronizan con el primario. Por lo tanto, si xcommand forceconfigupdate no funciona, siga el siguiente procedimiento:
- Inicie sesión en el par principal y confirme que se encuentra en buen estado.
- Asegúrese de que la configuración del clúster muestre que este par es el principal.
- Actualice el primario de nuevo, utilice el mismo paquete que utilizó originalmente para actualizar.
La alarma de replicación se borra después de que el peer primario se haya actualizado y reiniciado. Esto sucede normalmente dentro de los diez minutos después del reinicio, pero podría ser hasta veinte minutos después del reinicio.
Alarmas comunes
Configuración de clúster no válida: El modo H.323 debe estar activado; el clustering utiliza comunicaciones H.323 entre peers.
Para que esta alarma se borre, asegúrese de que el modo H.323 esté encendido, navegue hasta Configuración > Protocolos > H.323.
Error de base de datos de Expressway: Póngase en contacto con su representante de soporte técnico de Cisco.
Para resolver este tipo de alarma, siga el siguiente procedimiento:
- Tome una instantánea del sistema y proporciónesela a su representante de soporte técnico.
- Quite Expressway del clúster.
- Restaure la base de datos de Expressway a partir de una copia de seguridad realizada anteriormente en Expressway.
- Vuelva a agregar Expressway al clúster.
Un segundo método es posible si la base de datos no se recupera:
- Tome una instantánea del sistema y proporciónela al Technical Assistance Center (TAC).
- Quite Expressway del clúster.
- Inicie sesión como root y ejecute el siguiente comando clusterdb_destroy_and_purge_data.sh.
- Restaure la base de datos de Expressway a partir de una copia de seguridad realizada anteriormente en Expressway.
- Vuelva a agregar Expressway al clúster.
Nota: Asegúrese de realizar las copias de seguridad adecuadas antes de realizar una actualización, cambiar el certificado o cuando aparezca una advertencia de restablecimiento de fábrica.
Precaución: clusterdb_destroy_and_purge_data.sh es tan peligroso como parece: utilice esta opción como último recurso.
Problemas relacionados con System Key
Nota: La siguiente información se aplica a la versión X14 en adelante.
No se pudieron actualizar las alarmas de archivo clave que se producen en Expressways en un escenario de nodo único.
Siga el siguiente procedimiento para resolver este tipo de alarma:
- Inicie sesión como administrador a través de la CLI (disponible de forma predeterminada a través de SSH y a través del puerto serie en las versiones de hardware).
- Ejecute el siguiente comando: xCommand ForceSystemKeyUpdate.
No se pudieron actualizar las alarmas de archivo clave que se producen en Expressways en un escenario de clúster.
Siga el siguiente procedimiento para resolver este tipo de alarma:
- Inicie sesión en el nodo como administrador a través de la CLI (disponible de forma predeterminada a través de SSH y a través del puerto serie en las versiones de hardware) donde no se active esta alarma.
- Ejecute el siguiente comando: xCommand ForceSystemKeyUpdate.
Detalles de registros
Al igual que cualquier otro registro en Expressway, puede habilitar los registros de diagnóstico con volcados TCP.
En un estado normal, la sincronización de la base de datos en el nodo maestro se muestra en los registros como el siguiente resultado:
2020-07-21T15:16:50.321-05:00 expc01 replication: UTCTime="2020-07-21 20:16:50,321" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationsynchroniser(270)" Detail="Starting synchronisation"
2020-07-21T15:16:50.330-05:00 expc01 replication: UTCTime="2020-07-21 20:16:50,330" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationutils(750)" AlternateIPAddresses="[u'(10.15.13.15 expc01)', u'(10.15.13.16 expc02)']" ConfigurationMasterIndex="0" LocalPeerIndex="0"
2020-07-21T15:16:50.433-05:00 expc01 replication: UTCTime="2020-07-21 20:16:50,433" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationsynchroniser(257)" Detail="This peer is the cluster master, local configuration has already been replicated to the other peers"
2020-07-21T15:16:50.437-05:00 expc01 replication: UTCTime="2020-07-21 20:16:50,437" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationsynchroniser(336)" Detail="Synchronisation completed successfully"Desde la perspectiva del nodo de peer, se muestra como el siguiente resultado:
2020-07-21T15:16:46.900-05:00 expc02 replication: UTCTime="2020-07-21 20:16:46,899" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationsynchroniser(270)" Detail="Starting synchronisation"
2020-07-21T15:16:46.908-05:00 expc02 replication: UTCTime="2020-07-21 20:16:46,908" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationutils(750)" AlternateIPAddresses="[u'(10.15.13.15 expc01)', u'(10.15.13.16 expc02)']" ConfigurationMasterIndex="0" LocalPeerIndex="1"
2020-07-21T15:16:46.947-05:00 expc02 replication: UTCTime="2020-07-21 20:16:46,946" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationsynchroniser(254)" Detail="This peer is not the cluster master, local configuration is already up to date"
2020-07-21T15:16:46.950-05:00 expc02 replication: UTCTime="2020-07-21 20:16:46,950" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationsynchroniser(336)" Detail="Synchronisation completed successfully"Una Desconexión de Peer se muestra en el siguiente resultado:
2020-08-12T14:57:43.353-05:00 expc01 UTCTime="2020-08-12 19:57:43,353" Module="developer.clusterdb.cdb" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.159.0>" Detail="Processed mnesia_down event from accessible node" Node="clusterdb@expc02.apolo.local"
2020-08-12T14:57:43.354-05:00 expc01 UTCTime="2020-08-12 19:57:43,353" Module="developer.clusterdb.cdb" Level="ERROR" Node="clusterdb@expc01.apolo.local" PID="<0.159.0>" Detail="Inconsistent Database" Context="from mnesia system - mnesia down" Node="clusterdb@expc02.apolo.local"
2020-08-12T14:57:43.354-05:00 expc01 UTCTime="2020-08-12 19:57:43,354" Module="developer.clusterdb.cdb" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.159.0>" Detail="Connecting database on mnesia running_partitioned_network event" Node="clusterdb@expc02.apolo.local"
2020-08-12T14:57:43.354-05:00 expc01 UTCTime="2020-08-12 19:57:43,354" Module="developer.clusterdb.cdb" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.14215.425>" Detail="Ready to perform node connection transaction" Node="clusterdb@expc02.apolo.local"
2020-08-12T14:57:43.354-05:00 expc01 UTCTime="2020-08-12 19:57:43,354" Module="developer.clusterdb.cdb" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.14215.425>" Detail="Running node connection transaction" Node="clusterdb@expc02.apolo.local"
2020-08-12T14:57:43.354-05:00 expc01 UTCTime="2020-08-12 19:57:43,354" Module="developer.clusterdb.synchronise" Level="WARN" Node="clusterdb@expc01.apolo.local" PID="<0.14215.425>" Detail="Failed connecting to node" Node="clusterdb@expc02.apolo.local" Reason="{ badrpc, { EXIT, { aborted, { noproc, { gen_server, call, [ kernel_safe_sup, { start_child, { dets_sup, { dets_sup, start_link, }, permanent, 1000, supervisor, [ dets_sup ] } }, infinity ] } } } } }"
2020-08-12T14:57:43.524-05:00 expc01 alarm: Level="WARN" Event="Alarm Raised" Id="20006" UUID="0f96695e-d954-4f6f-85c1-2ef1eae6f764" Severity="warning" Detail="Cluster database communication failure: The database is unable to replicate with one or more of the cluster peers" UTCTime="2020-08-12 19:57:43,524"
2020-08-12T14:57:43.771-05:00 expc01 alarm: Level="WARN" Event="Alarm Raised" Id="20004" UUID="3bca6888-f622-11df-93be-07cc953d7b99" Severity="warning" Detail="Cluster communication failure: The system is unable to communicate with one or more of the cluster peers" UTCTime="2020-08-12 19:57:43,771"
2020-08-12T14:57:53.872-05:00 expc01 tvcs: UTCTime="2020-08-12 19:57:53,871" Module="network.h323" Level="INFO": Action="Sent" Dst-ip="10.15.13.16" Dst-port="1719" Detail="Sending RAS SCI SeqNum=52319 Retransmit=True"
2020-08-12T14:57:54.872-05:00 expc01 tvcs: UTCTime="2020-08-12 19:57:54,871" Module="network.h323" Level="INFO": Action="Sent" Dst-ip="10.15.13.16" Dst-port="1719" Detail="Sending RAS LRQ SeqNum=52320 Retransmit=True"
2020-08-12T14:57:56.872-05:00 expc01 tvcs: UTCTime="2020-08-12 19:57:56,871" Module="network.h323" Level="INFO": Action="Sent" Dst-ip="10.15.13.16" Dst-port="1719" Detail="Sending RAS LRQ SeqNum=52320 Retransmit=True"
2020-08-12T14:57:57.871-05:00 expc01 tvcs: UTCTime="2020-08-12 19:57:57,871" Module="network.h323" Level="INFO": Action="Sent" Dst-ip="10.15.13.16" Dst-port="1719" Detail="Sending RAS SCI SeqNum=52319 Retransmit=True"
2020-08-12T14:57:58.871-05:00 expc01 tvcs: Event="External Server Communications Failure" Reason="gatekeeper timed out" Service="NeighbourGatekeeper" Detail="name:10.15.13.16:1719" Level="1" UTCTime="2020-08-12 19:57:58,871"
2020-08-12T14:57:58.871-05:00 expc01 tvcs: UTCTime="2020-08-12 19:57:58,871" Module="network.h323" Level="INFO": Action="Sent" Dst-ip="10.15.13.16" Dst-port="1719" Detail="Sending RAS LRQ SeqNum=52320 Timeout=True"
2020-08-12T14:57:59.601-05:00 expc01 UTCTime="2020-08-12 19:57:59,601" Module="developer.clusterdb.peernameresolver" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.145.0>" Detail="Triggering forced peer update of peers which failed DNS and queueing next run" Queue-Time-ms="300000"
2020-08-12T14:58:01.871-05:00 expc01 tvcs: UTCTime="2020-08-12 19:58:01,871" Module="network.h323" Level="INFO": Action="Sent" Dst-ip="10.15.13.16" Dst-port="1719" Detail="Sending RAS SCI SeqNum=52319 Timeout=True"
Cambiar a TLS Forzoso en el nodo Maestro se muestra en el siguiente resultado:
2020-08-12T15:13:24.970-05:00 expc01 UTCTime="2020-08-12 20:13:24,969" Module="developer.cdbtable.cdb.clusterConfiguration" Level="DEBUG" Node="clusterdb@expc01.apolo.local" PID="<0.345.0>" Detail="Inserting into table" TableName="clusterConfiguration"
2020-08-12T15:13:24.976-05:00 expc01 UTCTime="2020-08-12 20:13:24,975" Event="System Configuration Changed" Node="clusterdb@expc01.apolo.local" PID="<0.345.0>" Detail="xconfiguration clusterConfiguration tls_verify - changed from: Permissive to: Enforcing"
2020-08-12T15:13:24.976-05:00 expc01 httpd[15060]: web: Event="System Configuration Changed" Detail="configuration/cluster/tls_verify - changed from: 'Permissive' to: 'Enforcing'" Src-ip="10.15.13.30" Src-port="53155" User="admin" Level="1" UTCTime="2020-08-12 20:13:24"
2020-08-12T15:13:24.979-05:00 expc01 management: UTCTime="2020-08-12 20:13:24,978" Module="developer.management.databasemanager" Level="INFO" CodeLocation="databasemanager(312)" Detail="Cluster configuration change detected"
2020-08-12T15:13:24.980-05:00 expc01 UTCTime="2020-08-12 20:13:24,980" Module="developer.cdbtable.cdb.clusterConfiguration" Level="DEBUG" Node="clusterdb@expc01.apolo.local" PID="<0.345.0>" Detail="Inserting into table" TableName="clusterConfiguration"
2020-08-12T15:13:24.986-05:00 expc01 management: UTCTime="2020-08-12 20:13:24,986" Module="developer.management.databasemanager" Level="INFO" CodeLocation="databasemanager(405)" Detail="TLS Verify change status" Startup="False" New="True"
2020-08-12T15:13:25.022-05:00 expc01 UTCTime="2020-08-12 20:13:25,022" Event="System Configuration Changed" Node="clusterdb@expc01.apolo.local" PID="<0.557.0>" Detail="xconfiguration alternatesConfiguration - Changed"
2020-08-12T15:13:25.022-05:00 expc01 UTCTime="2020-08-12 20:13:25,022" Module="developer.clusterdb.peernameresolver" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.145.0>" Detail="Notifying databasemanager (Management Framework)"
2020-08-12T15:13:25.022-05:00 expc01 UTCTime="2020-08-12 20:13:25,022" Module="developer.clusterdb.alternatesmanager" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.142.0>" Detail="alternate peer changed info recieved"
2020-08-12T15:13:25.031-05:00 expc01 UTCTime="2020-08-12 20:13:25,031" Event="System Configuration Changed" Node="clusterdb@expc01.apolo.local" PID="<0.557.0>" Detail="xconfiguration alternatesConfiguration - Changed"
2020-08-12T15:13:25.192-05:00 expc01 management: UTCTime="2020-08-12 20:13:25,192" Module="developer.diagnostics.alarmmanager" Level="INFO" CodeLocation="alarmmanager(173)" Detail="Raising alarm" UUID="e2b8e3d1-b731-4d7d-b606-4682a8f0c2e6" Parameters="null"
2020-08-12T15:13:25.195-05:00 expc01 management: Level="WARN" Event="Alarm Raised" Id="20007" UUID="e2b8e3d1-b731-4d7d-b606-4682a8f0c2e6" Severity="warning" Detail="Restart required: Cluster configuration has been changed, however a restart is required for this to take effect" UTCTime="2020-08-12 20:13:25,194"
Desde la perspectiva del nodo de peer, se muestra en el siguiente resultado:
2020-08-12T15:13:24.976-05:00 expc02 UTCTime="2020-08-12 20:13:24,976" Event="System Configuration Changed" Node="clusterdb@expc02.apolo.local" PID="<0.390.0>" Detail="xconfiguration clusterConfiguration tls_verify - changed from: Permissive to: Enforcing"
2020-08-12T15:13:24.979-05:00 expc02 management: UTCTime="2020-08-12 20:13:24,978" Module="developer.management.databasemanager" Level="INFO" CodeLocation="databasemanager(312)" Detail="Cluster configuration change detected"
2020-08-12T15:13:24.982-05:00 expc02 management: UTCTime="2020-08-12 20:13:24,982" Module="developer.management.databasemanager" Level="INFO" CodeLocation="databasemanager(405)" Detail="TLS Verify change status" Startup="False" New="True"
2020-08-12T15:13:25.040-05:00 expc02 UTCTime="2020-08-12 20:13:25,040" Module="developer.clusterdb.peernameresolver" Level="INFO" Node="clusterdb@expc02.apolo.local" PID="<0.136.0>" Detail="Notifying databasemanager (Management Framework)"
2020-08-12T15:13:25.040-05:00 expc02 UTCTime="2020-08-12 20:13:25,040" Module="developer.clusterdb.alternatesmanager" Level="INFO" Node="clusterdb@expc02.apolo.local" PID="<0.143.0>" Detail="alternate peer changed info recieved"
2020-08-12T15:13:25.041-05:00 expc02 UTCTime="2020-08-12 20:13:25,041" Event="System Configuration Changed" Node="clusterdb@expc02.apolo.local" PID="<0.543.0>" Detail="xconfiguration alternatesConfiguration - Changed"
2020-08-12T15:13:25.042-05:00 expc02 UTCTime="2020-08-12 20:13:25,042" Event="System Configuration Changed" Node="clusterdb@expc02.apolo.local" PID="<0.543.0>" Detail="xconfiguration alternatesConfiguration - Changed"
2020-08-12T15:13:25.046-05:00 expc02 UTCTime="2020-08-12 20:13:25,046" Module="developer.clusterdb.alternatesmanager" Level="INFO" Node="clusterdb@expc02.apolo.local" PID="<0.143.0>" Detail="alternate peer changed info recieved"
2020-08-12T15:13:25.047-05:00 expc02 UTCTime="2020-08-12 20:13:25,046" Module="developer.clusterdb.peernameresolver" Level="INFO" Node="clusterdb@expc02.apolo.local" PID="<0.136.0>" Detail="Notifying databasemanager (Management Framework)"
2020-08-12T15:13:25.047-05:00 expc02 UTCTime="2020-08-12 20:13:25,047" Event="System Configuration Changed" Node="clusterdb@expc02.apolo.local" PID="<0.543.0>" Detail="xconfiguration alternatesConfiguration - Changed"
2020-08-12T15:13:25.049-05:00 expc02 UTCTime="2020-08-12 20:13:25,049" Event="System Configuration Changed" Node="clusterdb@expc02.apolo.local" PID="<0.543.0>" Detail="xconfiguration alternatesConfiguration - Changed"
2020-08-12T15:13:25.136-05:00 expc02 management: UTCTime="2020-08-12 20:13:25,136" Module="developer.diagnostics.alarmmanager" Level="INFO" CodeLocation="alarmmanager(173)" Detail="Raising alarm" UUID="e2b8e3d1-b731-4d7d-b606-4682a8f0c2e6" Parameters="null"
2020-08-12T15:13:25.139-05:00 expc02 management: Level="WARN" Event="Alarm Raised" Id="20007" UUID="e2b8e3d1-b731-4d7d-b606-4682a8f0c2e6" Severity="warning" Detail="Restart required: Cluster configuration has been changed, however a restart is required for this to take effect" UTCTime="2020-08-12 20:13:25,139"
Vídeos
Los siguientes vídeos podrían ser útiles:
Cómo crear y agregar un par a un clúster de Expressway
Quitar un par de un clúster de Expressway
Corregir el error de replicación de Expressway "Conflictos de configuración del par con principal"
Procedimiento de reinicio del clúster de Expressway
Cómo actualizar un clúster de ExpresswayGeneración de CSR para MRA/ Clustered Expressways
Historial de revisiones
| Revisión | Fecha de publicación | Comentarios |
|---|---|---|
1.0 |
02-Jul-2021
|
Versión inicial |
Con la colaboración de ingenieros de Cisco
- Jefferson Madriz
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)