Introducción
Este documento describe la disponibilidad general de la correspondencia de documentos de índice (IDM).
Overview
El IDM es una técnica avanzada de clasificación de datos de DLP que mejora significativamente la capacidad de la organización para proteger eficazmente los documentos que contienen datos confidenciales.
Con IDM, las organizaciones pueden indexar y tomar huellas digitales del contenido de los documentos que contienen sus datos confidenciales. Al crear un repositorio de huellas digitales de estos datos, nuestro producto de prevención de pérdida de datos (DLP) puede identificar de forma eficaz documentos completos o parcialmente coincidentes durante la evaluación del contenido.
La ventaja de IDM sobre la coincidencia tradicional de patrones usando expresiones regulares y palabras clave es significativa. En lugar de buscar coincidencias con cualquier dato que pueda parecerse a datos confidenciales, IDM le permite comparar con sus datos confidenciales reales. Este enfoque selectivo reduce el número de incidentes de DLP de poca importancia y permite a las organizaciones centrar sus operaciones y recursos de seguridad en investigaciones de gran valor.
¿En qué se diferencia IDM de EDM?
IDM (Indexed Document Match) y EDM (Exact Document Match) difieren en términos del tipo de datos que identifican.
EDM se centra específicamente en la toma de huellas dactilares de datos tabulares, que son datos estructurados organizados en un formato de tabla. Esto significa que EDM está diseñado para manejar datos con una estructura específica, como bases de datos u hojas de cálculo. Por ejemplo, una organización puede utilizar EDM para tomar las huellas digitales de una tabla de tarjetas de crédito corporativa, asegurándose de que solo esas tarjetas de crédito corporativas están supervisadas y protegidas.
Por otro lado, IDM se utiliza para indexar y tomar huellas digitales de documentos de forma libre, que son datos no estructurados que no utilizan un formato específico. IDM es capaz de procesar y tomar huellas digitales de documentos que no están organizados en una estructura similar a una tabla, como archivos de texto, PDF o documentos de Word.
En resumen, la IDM se utiliza para la toma de huellas digitales de datos no estructurados, mientras que la EDM se utiliza para la toma de huellas digitales de datos estructurados.
¿Cuáles son los casos prácticos más comunes para utilizar IDM?
Algunos escenarios comunes incluyen la toma de huellas dactilares y la protección de la propiedad intelectual, como repositorios de código fuente, presentaciones de patentes o información corporativa confidencial como formularios de empleados de RR. HH., documentos corporativos y documentos legales.
¿Genera IDM huellas digitales basadas en el archivo o su contenido textual?
IDM indexa y toma huellas digitales del contenido textual del documento en lugar del archivo en sí. Esto permite que IDM coincida parcialmente con el contenido evaluado, incluso si algunos de los datos confidenciales se copian y pegan en un nuevo archivo. Dispone de la flexibilidad necesaria para especificar el grado de coincidencia necesario para desencadenar una infracción, seleccionando las opciones de una lista predefinida (20%, 60%, 80%).
¿Cómo utilizar IDM?
Indexed Document Match (IDM) in Umbrella funciona mediante la generación de huellas digitales de hash del texto extraído de documentos confidenciales. Estas huellas digitales son usadas por las diversas exploraciones de DLP multimodo para identificar total o parcialmente el contenido de los documentos. Para generar estas impresiones dactilares, debe descargar y utilizar la herramienta DLP Indexer de Cisco de forma local.
El indizador, una interfaz de línea de comandos, extrae texto de los documentos, realiza operaciones de huellas dactilares e indización y, a continuación, genera hashes en el texto indizado. Posteriormente, la herramienta carga las huellas digitales codificadas en Umbrella o Secure Access.
El resultado del uso de la herramienta de indización es un nuevo tipo de identificador de datos IDM que se utiliza en la clasificación de datos personalizada. Estas clasificaciones se aplican tanto con reglas de DLP en tiempo real como con reglas de DLP de la API SaaS para proteger eficazmente los datos en reposo y los datos en movimiento.
 20327456127636
20327456127636
¿Se puede programar la herramienta DLP Indexer para que tome huellas digitales de los datos nuevos periódicamente?
La herramienta Indexador se puede ejecutar en modo de supervisión como un proceso en segundo plano. Este modo permite que el indizador DLP vuelva a indizar automáticamente a intervalos regulares, lo que garantiza que los datos de origen se actualicen regularmente en Umbrella sin necesidad de operación manual.
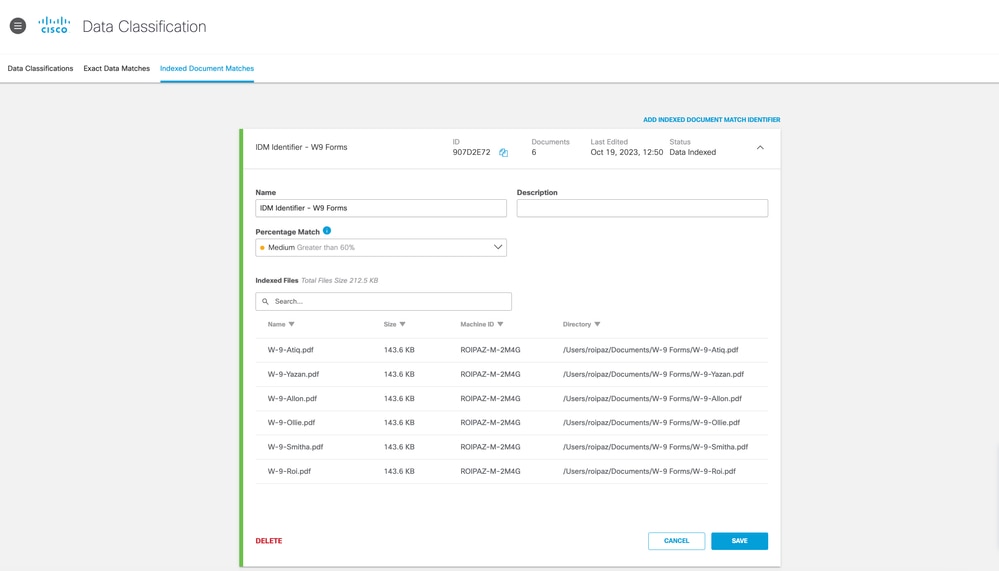
¿Dónde se accede a IDM y se descarga la herramienta DLP Indexer?
- Inicie sesión en el panel de Umbrella.
- Vaya a Políticas > Componentes de política > Clasificación de datos > Clasificación de datos.
- Haga clic en la ficha Coincidencia de documento indexado.
- En esta sección, puede crear identificadores IDM y descargar el indizador DLP.
¿Qué tipos de archivos son compatibles con IDM?
IDM es compatible con todos los tipos de archivos compatibles con DLP. Puede encontrar una lista completa de los tipos de archivo admitidos en la documentación. Vale la pena mencionar que IDM también soporta caracteres Unicode.
¿Qué limitaciones se deben tener en cuenta al utilizar IDM?
La cantidad total de texto indexado para todos los identificadores de datos IDM de una organización no debe exceder 1 GB. La ficha Coincidencias de documentos indizados de la página Clasificación de datos muestra advertencias cuando se alcanza la cuota asignada.
¿Dónde puedo encontrar más información?
Documentación general
 Comentarios
Comentarios