procedimiento de desclúster de ASR 9000 nV
Opciones de descarga
-
ePub (827.0 KB)
Visualice en diferentes aplicaciones en iPhone, iPad, Android, Sony Reader o Windows Phone -
Mobi (Kindle) (526.2 KB)
Visualice en dispositivo Kindle o aplicación Kindle en múltiples dispositivos
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Contenido
Introducción
En este documento se describen algunas de las funciones del clúster de nV de ASR 9000 y cómo desagrupar.
El procedimiento se probó en un entorno real con clientes de Cisco que ya se han decidido por el proceso de desagrupación que se explica en este documento.
Prerequisites
Requirements
Cisco recomienda que tenga conocimiento sobre estos temas:
- IOS XR
- plataforma ASR 9000
- función de clúster nV
Componentes Utilizados
La información de este documento se basa en la plataforma ASR 9000 que ejecuta IOS XR 5.x.
La información que contiene este documento se creó a partir de los dispositivos en un ambiente de laboratorio específico. Todos los dispositivos que se utilizan en este documento se pusieron en funcionamiento con una configuración verificada (predeterminada). Si tiene una red en vivo, asegúrese de entender el posible impacto de cualquier comando.
Antecedentes
La unidad empresarial de productos (BU) anunció el fin de venta (EOS) de nV Cluster en la plataforma ASR 9000: Anuncio de fin de venta y fin del ciclo de vida del clúster de Cisco nV
Como puede leer en el anuncio, el último día para pedir este producto es el 15 de enero de 2018, y la última versión admitida para el clúster de nV es IOS-XR 5.3.x.
Los hitos que se deben tener en cuenta se enumeran en esta tabla:

Fundamentos y consideraciones sobre clústeres ASR9k nV
El objetivo de esta sección es proporcionar una breve actualización de las configuraciones y conceptos del clúster necesarios para comprender las siguientes secciones de este documento.
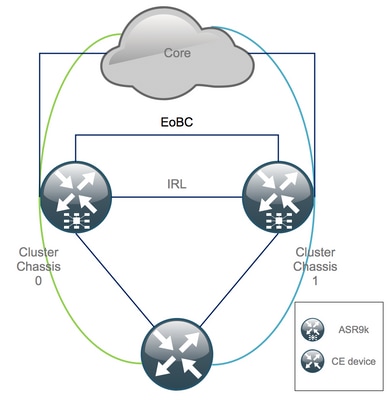
Canal fuera de banda Ethernet (EOBC)
El canal Ethernet fuera de banda extiende el plano de control entre los dos chasis ASR9k e idealmente consta de 4 interconexiones que crean una malla entre el procesador de switch de ruta (RSP) de diferentes chasis. Esta configuración proporciona redundancia adicional en caso de fallo del enlace EOBC. El protocolo de detección de enlaces unidireccionales (UDLD) garantiza el reenvío de datos bidireccional y detecta rápidamente los fallos de los enlaces. El mal funcionamiento de todos los links EOBC afecta seriamente el sistema de clúster y puede tener consecuencias graves que se presentan más adelante en la sección Escenarios de nodo dividido.
Enlaces entre bastidores (IRL)
Los enlaces entre bastidores amplían el plano de datos entre los dos chasis ASR9k. Idealmente, sólo los paquetes de inserción de protocolo y punt de protocolo atraviesan la IRL, excepto para los servicios de enlace único, o durante las fallas de red. En teoría, todos los sistemas finales son de doble conexión con un enlace a ambos chasis ASR9K. De manera similar a los links EOBC, el UDLD se ejecuta sobre la IRL también para monitorear el estado de reenvío bidireccional de los links.
Se puede definir un umbral IRL para evitar que la IRL congestionada descarte paquetes en caso de falla de la LC, por ejemplo. Si el número de links IRL cae por debajo del umbral configurado para ese chasis, todas las interfaces del chasis se desactivan y cierran por error. Básicamente, esto aísla el chasis afectado y garantiza que todo el tráfico fluye a través del otro chasis.
Nota: La configuración predeterminada es equivalente a nv edge data minimum 1 backup-rack-interfaces que significa que si ninguna IRL está en el estado de reenvío, el backup Designated Shelf Controller (DSC) se aísla.
Escenarios de nodo dividido
En esta subsección puede encontrar los diferentes escenarios de error que se pueden encontrar al tratar con clústeres ASR9k:
IRL descendente
Este es el único escenario de nodo dividido que se puede esperar durante la desagrupación en clústeres, o si uno de los chasis cae por debajo del umbral IRL y se aísla como consecuencia.
EOBC inactivo
Los dos chasis del ASR9k no pueden actuar como uno sin el plano de control ampliado proporcionado por los enlaces EOBC. Hay balizas periódicas que se intercambian a través de los links IRL para que cada chasis sea consciente de que el otro chasis está activo. Como consecuencia, uno de los chasis, normalmente el chasis con Backup-DSC, se queda fuera de servicio y se reinicia. El chasis DSC de respaldo permanece en el loop de inicio mientras reciba las balizas del chasis DSC primario sobre la IRL.
Cerebro partido
En el escenario de cerebro dividido, los enlaces IRL y EOBC han caído y cada chasis se declara como Primary-DSC. Los dispositivos de red vecinos de repente ven ID de router duplicados para IGP y BGP que pueden causar problemas graves en la red.
Paquetes
Muchos clientes utilizan paquetes en el extremo y en el núcleo para simplificar la configuración del clúster ASR9K y facilitar el aumento del ancho de banda en el futuro. Esto podría causar problemas al desagrupar debido a que diferentes miembros del paquete se conectan a diferentes chasis. Estos enfoques son posibles:
- Cree nuevos paquetes para todas las interfaces conectadas al chasis 1 (Backup-DSC).
- Introduzca la agregación de enlaces de varios chasis (MCLAG).
Dominio L2
La división del clúster podría separar potencialmente el dominio L2, si no hay ningún switch en el acceso que interconecte los dos chasis independientes. Para evitar el tráfico de agujeros negros, debe ampliar el dominio L2, lo que se puede hacer si configura conexiones locales L2 en la IRL anterior, pseudocables (PW) entre el chasis o hacer uso de cualquier otra tecnología de red privada virtual (L2VPN) de capa 2. A medida que la topología del dominio de bridge cambia con la desagrupación, tenga en cuenta la posible creación de loop cuando seleccione la tecnología L2VPN de su elección.
Es probable que el routing estático en el acceso hacia una interfaz de interfaz virtual de grupo de puentes (BVI) en el clúster ASR9K se convierta en una solución basada en el protocolo de router en espera en caliente (HSRP) que utilice la dirección IP de BVI anterior como IP virtual.
Servicios de enlace único
Los servicios de enlace único tienen un tiempo de inactividad prolongado durante el procedimiento de desclustering.
Acceso de administración
Durante el proceso de desclustering, existe un tiempo corto en el que ambos chasis están aislados, al menos cuando se realiza la transición del routing estático (BVI) al routing estático (HSRP) para no tener un routing inesperado y asimétrico.
Debe comprobar cómo funcionan la consola y el acceso a la administración fuera de banda antes de bloquearse.
procedimiento de desclustering de ASR9000
El estado inicial
Suponga que en el estado inicial el chasis 0 está activo, mientras que el chasis 1 es de respaldo (por razones de simplicidad). En la vida real podría ser al revés o incluso RSP1 en el chasis 0 podría estar activo.
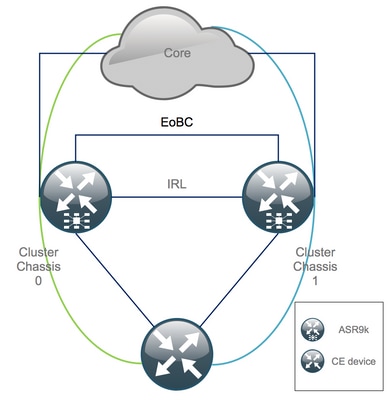
Lista de comprobación antes de la ventana de mantenimiento (MW)
- Prepare las nuevas configuraciones de chasis 0 y 1 de ASR9K (Admin-Config + Config).
- Prepare las nuevas configuraciones del sistema final (extremo del cliente (CE), firewall (FW), switches, etc.).
- Prepare las nuevas configuraciones del sistema central (nodos P, nodos Provider Edge (PE), Route Reflector (RR), etc.).
- Verifique las nuevas configuraciones, guárdelas en el dispositivo y de forma remota en un servidor TFTP (Trivial File Transfer Protocol).
- Defina las pruebas de alcance que deben ejecutarse antes/durante/después del MW.
- Recopile las salidas del plano de control para el protocolo de gateway interior (IGP), el protocolo de gateway fronterizo (BGP), el switching de etiquetas multiprotocolo (MPLS), el protocolo de distribución de etiquetas (LDP), etc. para realizar la comparación antes y después.
- Abra una solicitud de servicio proactiva con Cisco.
Paso 1. Inicie sesión en el clúster ASR9000 y compruebe la configuración actual
1. Verifique la ubicación del chasis principal - de respaldo. En este ejemplo, el chasis principal es 0:
RP/0/RSP0/CPU0:Cluster(admin)# show dsc --------------------------------------------------------- Node ( Seq) Role Serial# State --------------------------------------------------------- 0/RSP0/CPU0 ( 1279475) ACTIVE FOX1441GPND PRIMARY-DSC <<< Primary DSC in Ch1 0/RSP1/CPU0 ( 1223769) STANDBY FOX1432GU2Z NON-DSC 1/RSP0/CPU0 ( 0) ACTIVE FOX1432GU2Z BACKUP-DSC 1/RSP1/CPU0 ( 1279584) STANDBY FOX1441GPND NON-DSC
2. Verifique que todas las tarjetas de línea (LC)/RSPs estén en estado "IOS XR RUN":
RP/0/RSP0/CPU0:Cluster# sh platform Node Type State Config State ----------------------------------------------------------------------------- 0/RSP0/CPU0 A9K-RSP440-TR(Active) IOS XR RUN PWR,NSHUT,MON 0/RSP1/CPU0 A9K-RSP440-TR(Standby) IOS XR RUN PWR,NSHUT,MON 0/0/CPU0 A9K-MOD80-SE IOS XR RUN PWR,NSHUT,MON 0/0/0 A9K-MPA-4X10GE OK PWR,NSHUT,MON 0/0/1 A9K-MPA-20X1GE OK PWR,NSHUT,MON 0/1/CPU0 A9K-MOD80-TR IOS XR RUN PWR,NSHUT,MON 0/1/0 A9K-MPA-20X1GE OK PWR,NSHUT,MON 0/2/CPU0 A9K-40GE-E IOS XR RUN PWR,NSHUT,MON 1/RSP0/CPU0 A9K-RSP440-TR(Active) IOS XR RUN PWR,NSHUT,MON 1/RSP1/CPU0 A9K-RSP440-SE(Standby) IOS XR RUN PWR,NSHUT,MON 1/1/CPU0 A9K-MOD80-SE IOS XR RUN PWR,NSHUT,MON 1/1/1 A9K-MPA-2X10GE OK PWR,NSHUT,MON 1/2/CPU0 A9K-MOD80-SE IOS XR RUN PWR,NSHUT,MON 1/2/0 A9K-MPA-20X1GE OK PWR,NSHUT,MON 1/2/1 A9K-MPA-4X10GE OK PWR,NSHUT,MON
Paso 2. Configuración del umbral IRL mínimo para el chasis en espera
El chasis en espera es el chasis con BACKUP-DSC y se retira del servicio y primero se desagrupa. En este ejemplo, BACKUP-DSC se encuentra en el chasis 1.
Con esta configuración, si el número de IRL cae por debajo del umbral mínimo configurado (1 en este caso), se cierran todas las interfaces en el rack especificado (rack de respaldo - chasis 1 en este caso):
RP/0/RSP0/CPU0:Cluster(admin-config)# nv edge data min 1 spec rack 1 RP/0/RSP0/CPU0:Cluster(admin-config)# commit
Paso 3. Apague todas las interfaces IRL y verifique las interfaces de desactivación por error en el chasis 1
1. Cierra todas las IRL existentes. En este ejemplo, puede ver un apagado manual de la interfaz en ambos chasis (Ten0/x/x/x activo y Ten1/x/x/x en espera):
RP/0/RSP0/CPU0:Cluster(config)# interface Ten0/x/x/x shut interface Ten0/x/x/x shut […] interface Ten1/x/x/x shut interface Ten1/x/x/x shut […] commit
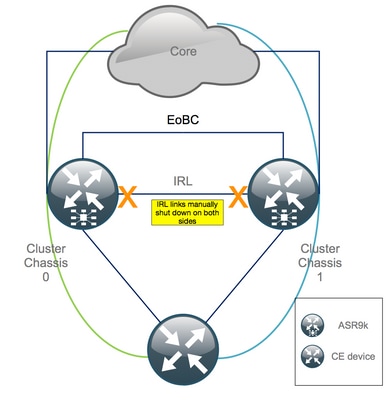
2. Verifique que todas las IRL configuradas estén inactivas:
RP/0/RSP0/CPU0:Cluster# show nv edge data forwarding location
Un ejemplo de <location> es 0/RSP0/CPU0.
Después de un apagado de todas las IRL, el chasis 1 debe estar completamente aislado del plano de datos moviendo todas las interfaces externas al estado error-disabled.
3. Verifique que todas las interfaces externas en el chasis 1 estén en el estado err-disabled y que todo el tráfico fluye a través del chasis 0:
RP/0/RSP0/CPU0:Cluster# show error-disable
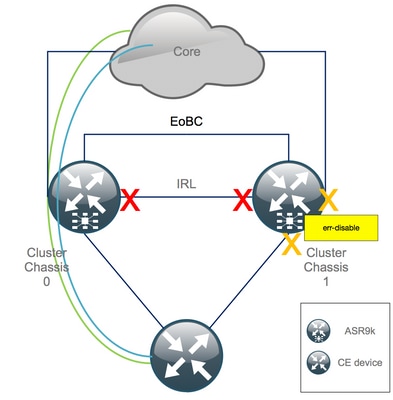
Paso 4. Cierre todos los enlaces EOBC y compruebe su estado
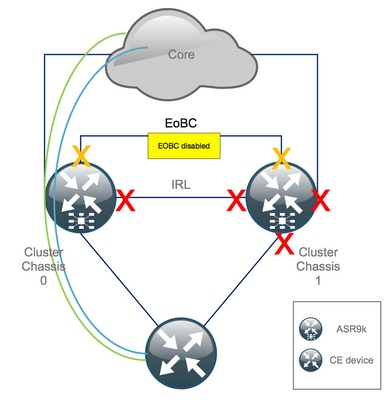
1. Cierre los enlaces EOBC en todos los RSP:
RP/0/RSP0/CPU0:Cluster(admin-config)# nv edge control control-link disable 0 loc 0/RSP0/CPU0 nv edge control control-link disable 1 loc 0/RSP0/CPU0 nv edge control control-link disable 0 loc 1/RSP0/CPU0 nv edge control control-link disable 1 loc 1/RSP0/CPU0 nv edge control control-link disable 0 loc 0/RSP1/CPU0 nv edge control control-link disable 1 loc 0/RSP1/CPU0 nv edge control control-link disable 0 loc 1/RSP1/CPU0 nv edge control control-link disable 1 loc 1/RSP1/CPU0 commit
2. Verifique que todos los links EOBC estén inactivos:
RP/0/RSP0/CPU0:Cluster# show nv edge control control-link-protocols location 0/RSP0/CPU0
Después de este paso, los chasis de clúster están completamente aislados entre sí en términos de control y plano de datos. El chasis 1 tiene todos sus links en el estado err-disable.
Nota: A partir de ahora, las configuraciones deben realizarse en el chasis 1 a través de la consola RSP y solo afectan al chasis local.
Paso 5. Inicie sesión en el RSP activo del chasis 1 y elimine la configuración anterior
Borre la configuración existente en el chasis 1:
RP/1/RSP0/CPU0:Cluster(config)# commit replace RP/1/RSP0/CPU0:Cluster(admin-config)# commit replace
Nota: Primero debe reemplazar la configuración para la configuración en ejecución y solo después borrar la configuración en ejecución admin. Esto se debe al hecho de que la eliminación del umbral IRL en la configuración de ejecución del administrador "no cierra" todas las interfaces externas. Esto podría causar problemas debido a los ID de router duplicados, etc.
Paso 6. Chasis de arranque 1 en modo ROMMON
1. Establezca el registro de configuración para arrancar en ROMMON:
RP/1/RSP0/CPU0:Cluster(admin)# config-register boot-mode rom-monitor location all
2. Verifique las variables de inicio:
RP/1/RSP0/CPU0:Cluster(admin)# show variables boot
3. Recargue ambos RSP del chasis 1:
RP/1/RSP0/CPU0:Cluster# admin reload location all
Después de este paso, normalmente, el chasis 1 se inicia en ROMMON.
Paso 7. Desconfigurar variables de cliente en chasis 1 en ROMMON en ambos RSP
Advertencia: el técnico de campo debe eliminar todos los enlaces EOBC antes de continuar.
Sugerencia: También existe una alternativa para establecer variables de clúster de sistema. Consulte la sección Apéndice 2: Establecer la variable de clúster sin iniciar el sistema en rommon.
1. El procedimiento estándar requiere conectar el cable de consola al RSP activo en el chasis 1, y desconfigurar y sincronizar la variable ROMMON del clúster:
unset CLUSTER_RACK_ID sync
2. Restablezca los registros de configuración a 0x102:
confreg 0x102 reset
El RSP activo está configurado.
3. Conecte el cable de la consola al RSP en espera del chasis 1. Idealmente, los 4 RSPs del clúster tienen acceso a la consola durante la ventana de mantenimiento.
Nota: Las acciones descritas en este paso deben realizarse en ambos RSP del chasis 1. El RSP activo se debe iniciar primero.
Paso 8. Arranque del chasis 1 como sistema independiente y configúrelo en consecuencia
Idealmente, la nueva configuración o varios fragmentos de configuración se almacenan en cada chasis ASR9k y se cargan después de la desagrupación en clúster. La sintaxis de configuración correcta se debe probar previamente en el laboratorio. Si no es así, configure la consola y las interfaces MGMT primero, antes de completar la configuración en el chasis 1 ya sea a través de copiar y pegar en Virtual Teletype (VTY) o cargue la configuración remotamente desde un servidor TFTP.
Nota: los comandos load config y commit mantienen todas las interfaces apagadas, lo que permite una preparación de servicio controlada. load config y commit replace, sustituye completamente la configuración y activa las interfaces. Por lo tanto, se recomienda utilizar load config y commit.
Adapte la configuración de los sistemas finales conectados (FW, switches, etc.) y los dispositivos de núcleo (P, PE, RR, etc.) al chasis 1.
Paso 9. Restauración de los servicios principales en el chasis 1
- Desactive manualmente las interfaces de núcleo primero.
- Verifique LDP, Sistema Intermedio a Sistema Intermedio (IS-IS o ISIS), adyacencias/pares BGP.
- Verifique las tablas de ruteo y asegúrese de que se hayan intercambiado todos los prefijos.
Advertencia: Tenga cuidado con los temporizadores como el bit de sobrecarga de ISIS (OL), el retraso de HSRP, el retraso de actualización de BGP, etc. antes de pasar a la conmutación por fallo.
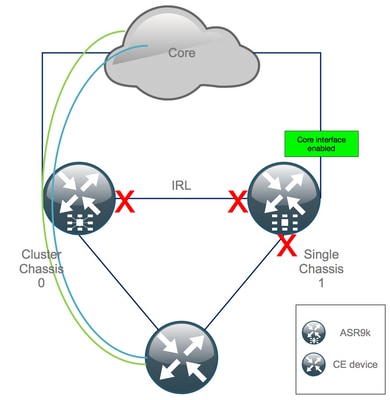
Paso 10. Conmutación por error: inicie sesión en el RSP activo del chasis 0 y coloque todas las interfaces en estado de desactivación por error
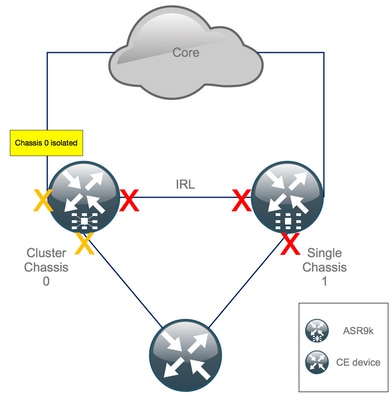
Precaución: los siguientes pasos provocan la interrupción del servicio. Las interfaces descendentes del chasis 1 siguen desactivadas, mientras que el chasis 0 está aislado
El tiempo en espera predeterminado es igual a 180 segundos (3x60 segundos) y representa el peor caso para la convergencia BGP. Hay varias opciones de diseño y funciones BGP que permiten un tiempo de convergencia mucho más rápido, como el Seguimiento de Siguiente Salto BGP. Suponga que hay diferentes proveedores de 3rd presentes en el núcleo que se comportan de manera diferente que Cisco IOS XR, eventualmente necesita acelerar la convergencia BGP manualmente con un software cerrado de las vecindades BGP entre el chasis 0 y el RR, o similar, antes de activar el failover:
RP/0/RSP0/CPU0:Cluster(admin-config)# nv edge data minimum 1 specific rack 0 RP/0/RSP0/CPU0:Cluster(admin-config)# commit
Dado que todas las IRL están inactivas, el chasis 0 debe estar aislado y todas las interfaces externas deben pasar al estado error-disabled.
Verifique que todas las interfaces externas en el chasis 0 estén en el estado err-disabled:
RP/0/RSP0/CPU0:Cluster# show error-disable
El chasis 1 se ha reconfigurado como un cuadro independiente, por lo que no debe haber ninguna interfaz inhabilitada por error. Lo único que queda por hacer en el chasis 1 es activar las interfaces en el perímetro.
Paso 11. Restauración del lado sur en el chasis 1
1. no cierre todas las interfaces de acceso.
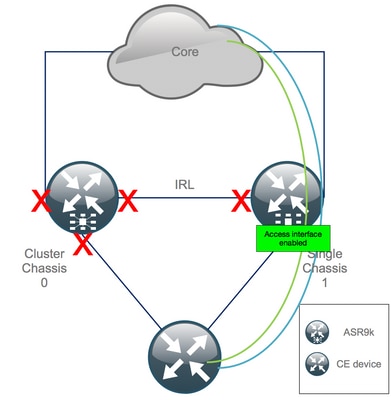
Mantenga el link de interconexión (IRL anterior) apagado por ahora.
2. Verifique las adyacencias/peers/DB IGP y BGP. Mientras que los IGPs y el BGP convergen, usted espera ver alguna pérdida de tráfico en sus pings desde el PE remoto.
Paso 12. Inicie sesión en el RSP activo del chasis 0 y elimine la configuración
Borre la configuración existente en el chasis activo:
RP/0/RSP0/CPU0:Cluster(config)# commit replace RP/0/RSP0/CPU0:Cluster(admin-config)# commit replace
Nota: primero debe reemplazar la configuración para la configuración en ejecución y solo después borrar la configuración en ejecución admin. Esto se debe al hecho de que la eliminación del umbral IRL en la configuración de ejecución de administración no cierra todas las interfaces externas. Esto podría causar problemas debido a los ID de router duplicados, etc.
Paso 13. Chasis de arranque 0 en ROMMON
1. Establezca el registro de configuración para arrancar en ROMMON:
RP/0/RSP0/CPU0:Cluster(admin)# config-register boot-mode rom-monitor location all
2. Verifique las variables de inicio:
RP/0/RSP0/CPU0:Cluster# admin show variables boot
3. Recargue ambos RSP del chasis en espera:
RP/0/RSP0/CPU0:Cluster# admin reload location all
Después de este paso, normalmente, el chasis 0 se inicia en el modo ROMMON.
Paso 14. Desconfigurar variables de clúster en chasis 0 en ROMMON en ambos RSP
1. Conecte el cable de la consola al RSP activo en el chasis 0.
2. Desconfigurar y sincronizar la variable ROMMON del clúster:
unset CLUSTER_RACK_ID sync
3. Restablezca los registros de configuración a 0x102:
confreg 0x102 reset
El RSP activo está configurado.
4. Conecte el cable de la consola al RSP en espera en el chasis 0.
Nota: Las acciones descritas en este paso deben realizarse en ambos RSP del chasis 1. El RSP activo se debe iniciar primero.
Paso 15. Arranque el chasis 0 como sistema independiente y configúrelo en consecuencia
Idealmente, la nueva configuración o varios fragmentos de configuración se almacenan en cada chasis ASR9k y se cargan después de la desagrupación en clúster. La sintaxis de configuración correcta se debe probar previamente en el laboratorio. Si no es así, configure la consola y las interfaces MGMT primero, antes de completar la configuración en el chasis 0 a través de VTY (Copiar y Pegar) o cargue la configuración remotamente desde un servidor TFTP.
Nota: los comandos load config y commit mantienen todas las interfaces apagadas, lo que permite una preparación de servicio controlada. load config y commit replace, sustituye completamente la configuración y activa las interfaces. Por lo tanto, se recomienda utilizar load config y commit.
Adapte la configuración de los sistemas finales conectados (FW, switches, etc.) y los dispositivos de núcleo (P, PE, RR, etc.) al chasis 0.
Paso 16. Restauración de los servicios principales en el chasis 0
- Desactive manualmente las interfaces de núcleo primero.
- Verifique las adyacencias/pares LDP, ISIS, BGP.
- Verifique que las tablas de ruteo y asegúrese de que se hayan intercambiado todos los prefijos.
Advertencia: Tenga cuidado con los temporizadores como ISIS OL-Bit, retraso HSRP, retraso BGP Update, etc. antes de pasar a la conmutación por fallas.
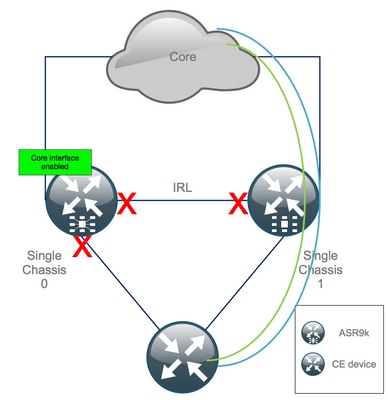
Paso 17. Restauración del lado sur en el chasis 0
1. no cierre todas las interfaces de acceso.
2. Verificar adyacencias/peers/DB IGP y BGP
3. Asegúrese de que el link entre chasis (IRL anterior) esté habilitado, si es necesario para la extensión L2, etc.
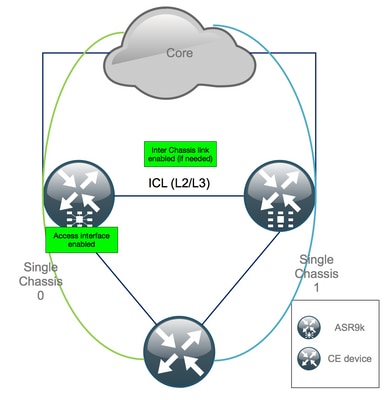
Apéndice 1: Configuración de chasis único
Cambios de configuración general
Esta configuración del router debe modificarse en uno de los chasis:
- Direcciones de Interfaz de Loopback.
- Numeración de interfaces (por ejemplo, Te1/x/x/x -> Te0/x/x/x).
- Descripciones de interfaz.
- Direccionamiento de la interfaz (al dividir los paquetes existentes).
- Nuevas BVI (cuando el dominio L2 tiene doble conexión).
- Extensión L2 (cuando el dominio L2 tiene doble conexión).
- HSRP para ruteo estático en acceso.
- ID de router BGP/Open Shortest Path First (OSPF)/LDP.
- Distinguidores de ruta BGP.
- Peerings BGP.
- Tipo de red OSPF.
- ID de protocolo simple de administración de red (SNMP), etc.
- Lista de control de acceso (ACL), conjuntos de prefijos, protocolo de routing para LLN (redes de bajo consumo y con pérdidas) (RPL), etc.
- Hostname.
Descripción general del paquete
Asegúrese de que todos los paquetes se revisan y se aplican a la nueva configuración de PE dual. Es posible que ya no necesite paquetes y que los dispositivos de equipo en las instalaciones del cliente (CPE) de doble alojamiento se adapten a su configuración, o que necesite MCLAG en los dispositivos PE y mantenga los paquetes hacia los CPE.
Apéndice 2: Definición de la variable de clúster sin iniciar el sistema en ROMMON
También existe una alternativa para establecer las variables de clúster. Las variables de clúster se pueden configurar por adelantado mediante este procedimiento:
RP/0/RSP0/CPU0:xr#run Wed Jul 5 10:19:32.067 CEST # cd /nvram: # ls cepki_key_db classic-rommon-var powerup_info.puf sam_db spm_db classic-public-config license_opid.puf redfs_ocb_force_sync samlog sysmgr.log.timeout.Z # more classic-rommon-var PS1 = rommon ! > , IOX_ADMIN_CONFIG_FILE = , ACTIVE_FCD = 1, TFTP_TIMEOUT = 6000, TFTP_CHECKSUM = 1, TFTP_MGMT_INTF = 1, TFTP_MGMT_BLKSIZE = 1400, TURBOBOOT = , ? = 0, DEFAULT_GATEWAY = 127.1.1.0, IP_SUBNET_MASK = 255.0.0.0, IP_ADDRESS = 127.0.1.0, TFTP_SERVER = 127.1.1.0, CLUSTER_0_DISABLE = 0, CLUSTERSABLE = 0, CLUSTER_1_DISABLE = 0, TFTP_FILE = disk0:asr9k-os-mbi-5.3.4/0x100000/mbiasr9k-rp.vm, BSS = 4097, BSI = 0, BOOT = disk0:asr9k-os-mbi-6.1.3/0x100000/mbiasr9k-rp.vm,1;, CLUSTER_NO_BOOT = , BOOT_DEV_SEQ_CONF = , BOOT_DEV_SEQ_OPER = , CLUSTER_RACK_ID = 1, TFTP_RETRY_COUNT = 4, confreg = 0x2102 # nvram_rommonvar CLUSTER_RACK_ID 0 <<<<<<< to set CLUSTER_RACK_ID=0 # more classic-rommon-var PS1 = rommon ! > , IOX_ADMIN_CONFIG_FILE = , ACTIVE_FCD = 1, TFTP_TIMEOUT = 6000, TFTP_CHECKSUM = 1, TFTP_MGMT_INTF = 1, TFTP_MGMT_BLKSIZE = 1400, TURBOBOOT = , ? = 0, DEFAULT_GATEWAY = 127.1.1.0, IP_SUBNET_MASK = 255.0.0.0, IP_ADDRESS = 127.0.1.0, TFTP_SERVER = 127.1.1.0, CLUSTER_0_DISABLE = 0, CLUSTERSABLE = 0, CLUSTER_1_DISABLE = 0, TFTP_FILE = disk0:asr9k-os-mbi-5.3.4/0x100000/mbiasr9k-rp.vm, BSS = 4097, BSI = 0, BOOT = disk0:asr9k-os-mbi-6.1.3/0x100000/mbiasr9k-rp.vm,1;, CLUSTER_NO_BOOT = , BOOT_DEV_SEQ_CONF = , BOOT_DEV_SEQ_OPER = , TFTP_RETRY_COUNT = 4, CLUSTER_RACK_ID = 0, confreg = 0x2102 #exit RP/0/RSP0/CPU0:xr#
Recargue el router y lo inicia como una caja independiente. Con este paso, puede saltar para iniciar el router desde ROMMON.
Historial de revisiones
| Revisión | Fecha de publicación | Comentarios |
|---|---|---|
1.0 |
05-Apr-2019
|
Versión inicial |
Contribución realizada por
- Robert VerlicAdvanced Services
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)